IBM Federated Learning uses SSL secured connections between the parties and the aggregator for communicating the machine learning models. In this setting, the aggregator can still see the unencrypted local and aggregated models.
IBM Federated Learning further includes homomorphic encryption capabilities, to enhance the parties’ data privacy and security in settings where the aggregator operates in an environment which is less trusted, and the parties wish to avoid revealing the local models and the aggregated models to the aggregator.
Homomorphic encryption (HE) is a form of encryption that enables performing computations on the encrypted data without decrypting it. The results of the computations remain in encrypted form which, when decrypted, results in an output that is the same as the output produced had the computations been performed on the unencrypted data.
In federated learning, homomorphic encryption enables the parties to homomorphically encrypt their local model updates before sending them to the aggregator. The aggregator sees only the homomorphically encrypted local model updates, and therefore cannot learn anything from this information. Specifically, the aggregator is not able to reverse-engineer the local model updates to discover information on local training data. The aggregator fuses the local model updates in their encrypted form, obtaining an encrypted aggregated model. Then the aggregator sends the encrypted aggregated model to the parties, which decrypt it and continue with the next round of training.
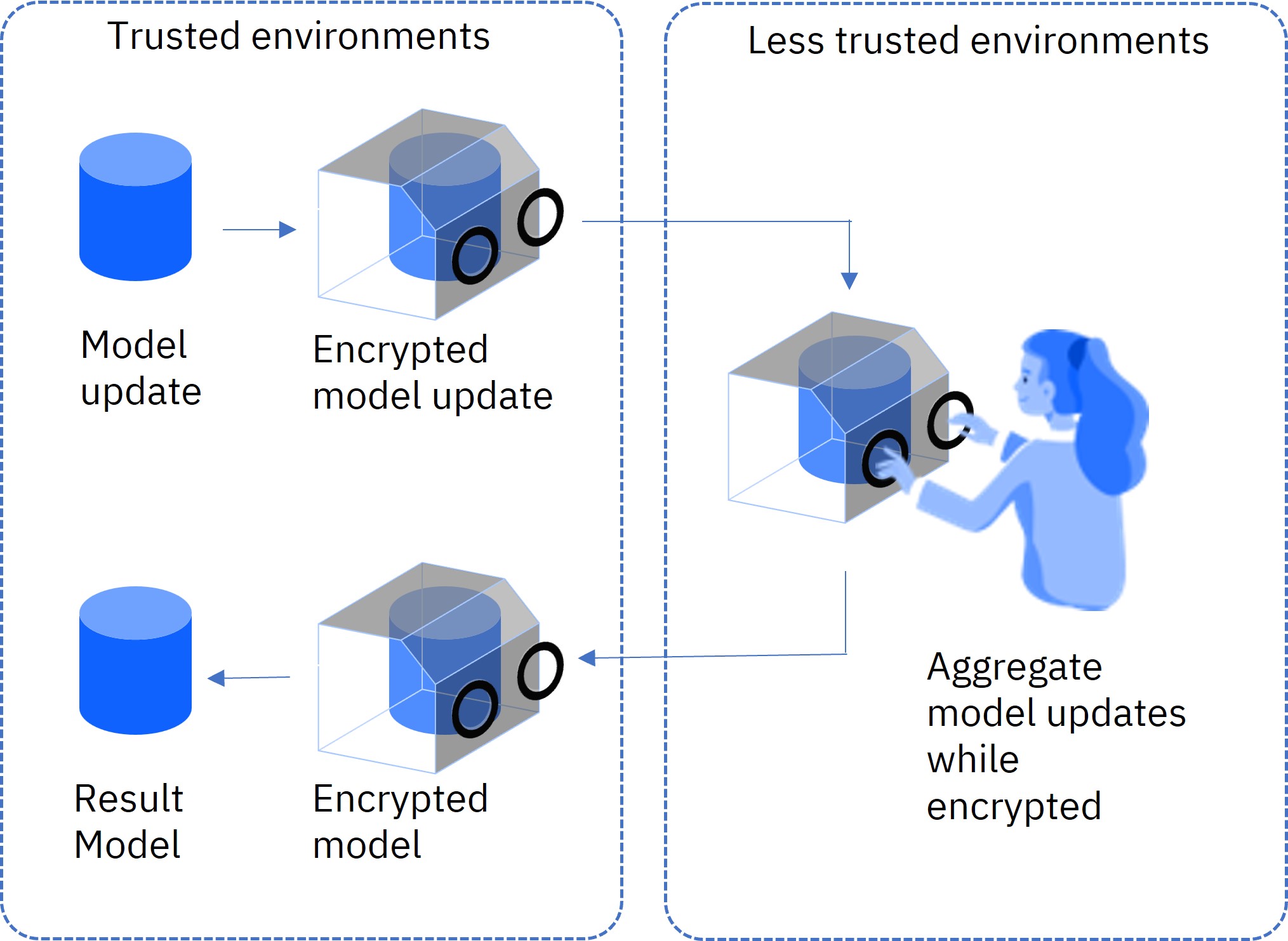
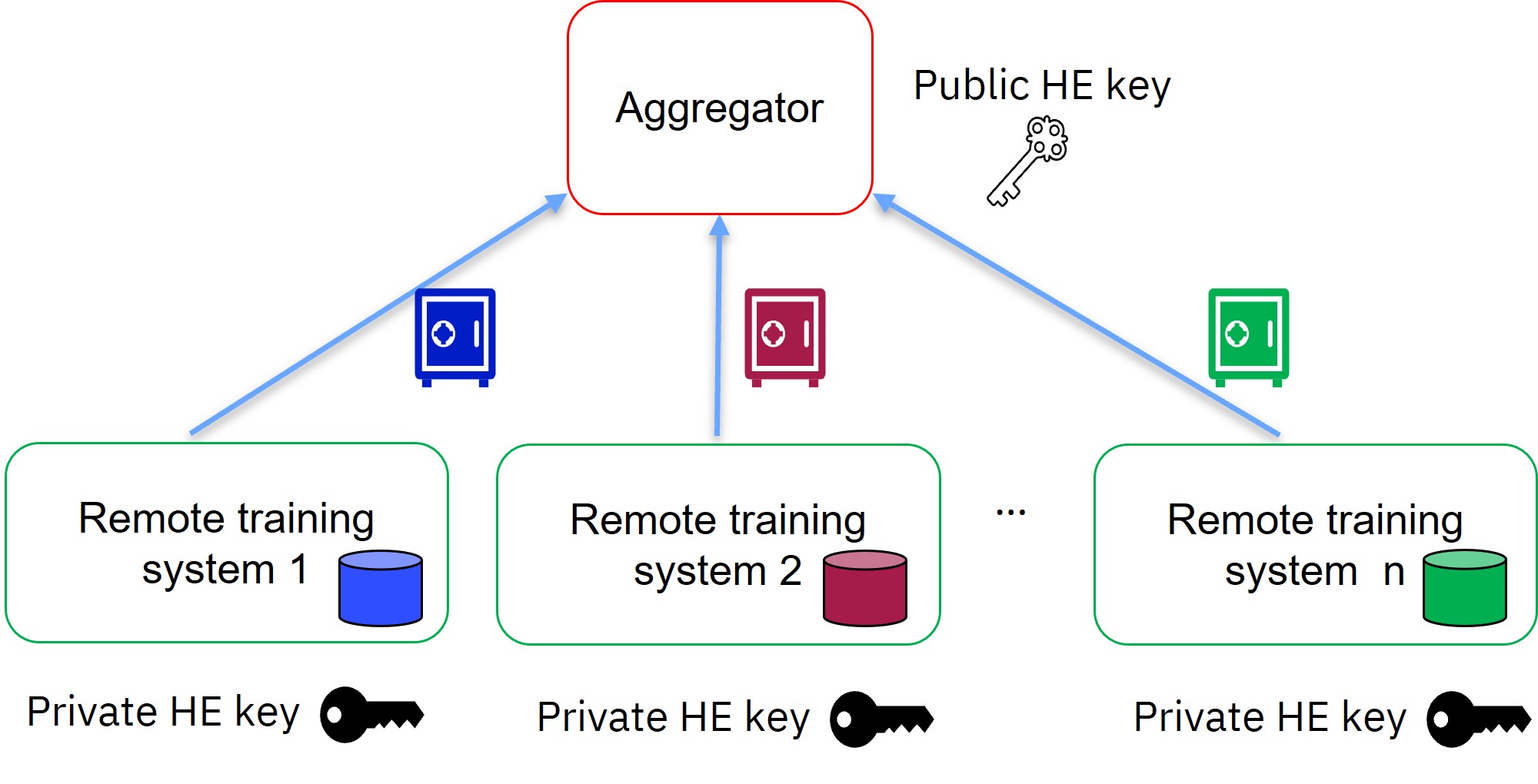
Homomorphic encryption is a form of public key cryptography. It uses a public key for encryption and a private key for decryption. In IBM Federated Learning with homomorphic encryption, the parties (also named “remote training systems”) share the private HE key, and the aggregator has only the public HE key. Each party encrypts its local model update using the public HE key, and sends its encrypted local model update to the aggregator. Since the aggregator does not have the private HE key, it cannot decrypt the encrypted local model updates.
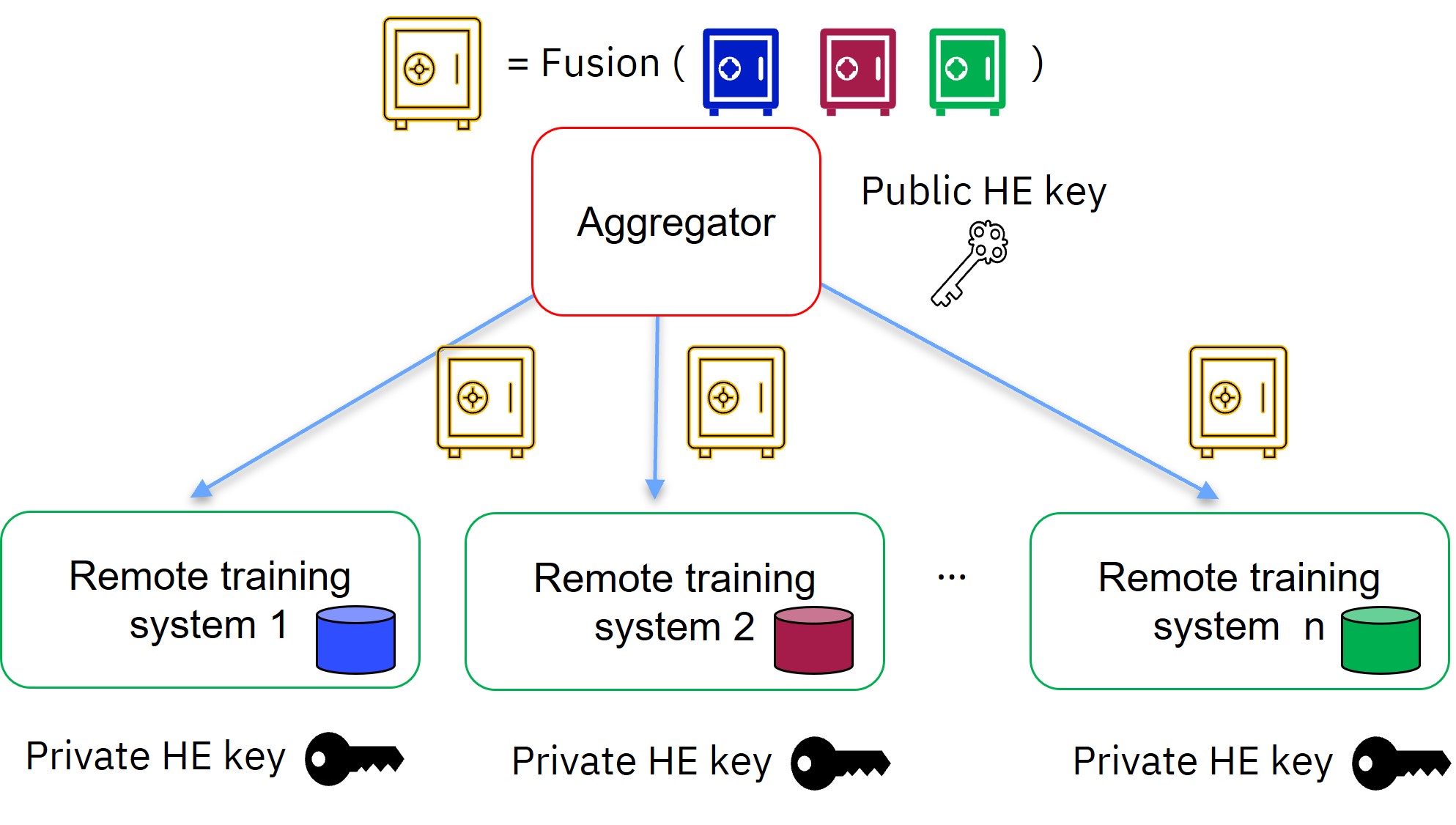
The aggregator uses its public HE key to fuse the encrypted local model updates into a new encrypted aggregated model. This encrypted aggregated model is sent to the parties, which decrypt it using their private HE key, and continue the model training process.
IBM Federated Learning makes it easy to use homomorphic encryption in model training, by specifying simple parameters in the configurations of the aggregator and the parties. IBM Federated Learning includes a mechanism that generates and distributes automatically and securely homomorphic encryption keys among the parties participating in a training experiment.