Use AutoAI to create a time series experiment to predict future activity, such as stock prices or temperatures, over a specified date or time range.
Time series overview
A time series experiment is a method of forecasting that uses historical observations to predict future values. The experiment automatically builds many pipelines using machine learning models, such as random forest regression and Support Vector Machines (SVMs), as well as statistical time series models, such as ARIMA and Holt-Winters. Then, the experiment recommends the best pipeline according to the pipeline performance evaluated on a holdout data set or backtest data sets.
Unlike a standard AutoAI experiment, which builds a set of pipelines to completion then ranks them. A time series experiment evaluates pipelines earlier in the process and only completes and test the best-performing pipelines.
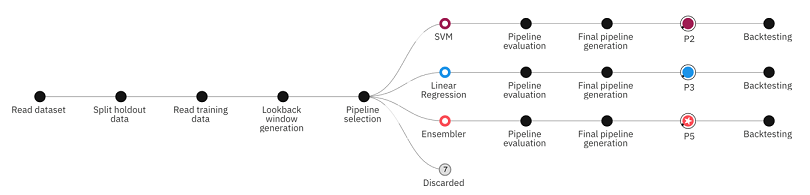
For details on the various stages of training and testing a time series experiment, see Time series implementation details.
Predicting anomalies in a time series experiment
You can configure your time series experiment to predict anomalies (outliers) in your data or predictions. To configure anomaly prediction for your experiment, follow the steps in Creating a time series anomaly prediction model.
Using supporting features to improve predictions
When you configure your time series experiment, you can choose to specify supporting features, also known as exogenous features. Supporting features are features that influence or add context to the prediction target. For example, if you are forecasting ice cream sales, daily temperature would be a logical supporting feature that would make the forecast more accurate.
Leveraging future values for supporting features
If you know the future values for the supporting features, you can leverage those future values when you deploy the model. For example, if you are training a model to forecast future t-shirt sales, you can include promotional discounts as a supporting feature to enhance the prediction. Inputting the future value of the promotion then makes the forecast more accurate.
Data requirements
These are the current data requirements for training a time series experiment:
-
The training data must be a single file in CSV format.
-
The file must contain one or more time series columns and optionally contain a timestamp column. For a list of supported date/time formats, see AutoAI time series implementation details.
-
If the data source contains a timestamp column, ensure that the data is sampled at uniform frequency. That is, the difference in timestamps of adjacent rows is the same. For example, data can be in increments of 1 minute, 1 hour, or one day. The specified timestamp is used to determine the lookback window to improve the model accuracy.
Note:If the file size is larger than 1 GB, sort the data in descending order by the timestamp, and only the first 1 GB is used to train the experiment.
-
If the data source does not contain a timestamp column, ensure that the data is sampled at regular intervals and sorted in ascending order according to the sample date/time. That is, the value in the first row is the oldest, and the value in the last row is the most recent.
Note: If the file size is larger than 1 GB, truncate the file so it is smaller than 1 GB. -
Select what data to use when training the final pipelines. If you choose to include training data only, the generated notebooks will include a cell for retrieving the holdout data used to evaluate each pipeline.
Choose data from your project or upload it from your file system or from the asset browser, then click Continue. Click the preview icon ![]() , after the data source name to review your data. Optionally, you can add a second file as holdout data for testing the trained pipelines.
, after the data source name to review your data. Optionally, you can add a second file as holdout data for testing the trained pipelines.
Configuring a time series experiment
When you configure the details for an experiment, click Yes to Enable time series and complete the experiment details.
| Field | Description |
|---|---|
| Prediction columns | The time series columns that you want to predict based on the previous values. You can specify one or more columns to predict. |
| Date/time column | The column that indicates the date/time at which the time series values occur. |
| Lookback window | A parameter that indicates how many previous time series values are used to predict the current time point. |
| Forecast window | The range that you want to predict based on the data in the lookback window. |
The prediction summary shows you the experiment type and the metric that is selected for optimizing the experiment.
Configuring experiment settings
To configure more details for your time series experiment, click Experiment settings.
General prediction settings
On the General panel for prediction settings, you can optionally change the metric used to optimize the experiment or specify the algorithms to consider or the number of pipelines to generate.
| Field | Description |
|---|---|
| Prediction type | View or change the prediction type based on prediction column for your experiment. For time series experiments, Time series forecast is selected by default. Note: If you change the prediction type, other prediction settings for your experiment are automatically changed. |
| Optimized metric | View or change the recommended optimized metric for your experiment. |
| Optimized algorithm selection | Not supported for time series experiments. |
| Algorithms to include | Select algorithms based on which you want your experiment to create pipelines. Algorithms and pipelines that support the use of supporting features, are indicated by a checkmark. |
| Pipelines to complete | View or change the number of pipelines to generate for your experiment. |
Time series configuration details
On the Time series pane for prediction settings, configure the details for how to train the experiment and generate predictions.
| Field | Description |
|---|---|
| Date/time column | View or change the date/time column for the experiment. |
| Lookback window | View or update the number of previous time series values used to predict the current time point. |
| Forecast window | View or update the range that you want to predict based. |
Configuring data source settings
To configure details for your input data, click Experiment settings and select Data source.
General data source settings
On the General panel for data source settings, you can modify your dataset to interpolate missing values, split your dataset into training and holdout data, and input supporting features.
| Field | Description |
|---|---|
| Duplicate rows | Not supported for time series experiments. |
| Subsample data | Not supported for time series experiments. |
| Text feature engineering | Not supported for time series experiments. |
| Final training data set | Select what data to use when training the final pipelines: just the training data or the training and holdout data. If you choose to include training data only, generated notebooks for this experiment will include a cell for retrieving the holdout data used to evaluate each pipeline. |
| Supporting features | Choose additional columns from your data set as Supporting features to support predictions and increase your model’s accuracy. You can also use future values for Supporting features by enabling Leverage future values of supporting features.
Note: You can only use supporting features with selected algorithms and pipelines. For more information on algorithms and pipelines that support the use of supporting features, see Time series implementation details. |
| Data imputation | Use data imputation to replace missing values in your dataset with substituted values. By enabling this option, you can specify how missing values should be interpolated in your data. To learn more about data imputation, see Data imputation in AutoAI experiments. |
| Training and holdout data | Choose to reserve some data from your training data set to test the experiment. Alternatively, upload a separate file of holdout data. The holdout data file must match the schema of the training data. |
Configuring time series data
To configure the time series data, you can adjust the settings for the time series data that is related to backtesting the experiment. Backtesting provides a means of validating a time-series model by using historical data.
In a typical machine learning experiment, you can hold back part of the data randomly to test the resulting model for accuracy. To validate a time series model, you must preserve the time order relationship between the training data and testing data.
The following steps describe the backtest method:
- The training data length is determined based on the number of backtests, gap length, and holdout size. To learn more about these parameters, see Building a time series experiment.
- Starting from the oldest data, the experiment is trained using the training data.
- The experiment is evaluated on the first validation data set. If the gap length is non-zero, any data in the gap is skipped over.
- The training data window is advanced by increasing the holdout size and gap length to form a new training set.
- A fresh experiment is trained with this new data and evaluated with the next validation data set.
- The prior two steps are repeated for the remaining backtesting periods.
To adjust the backtesting configuration:
- Open Experiment settings.
- From Data sources, click the Time series.
- (Optional): Adjust the settings as shown in the table.
| Field | Description |
|---|---|
| Number of backtests | Backtesting is similar to cross-validation for date/time periods. Optionally customize the number of backtests for your experiment. |
| Holdout | The size of the holdout set and each validation set for backtesting. The validation length can be adjusted by changing the holdout length. |
| Gap length | The number of time points between the training data set and validation data set for each backtest. When the parameter value is non-zero, the time series values in the gap will not be used to train the experiment or evaluate the current backtest. |
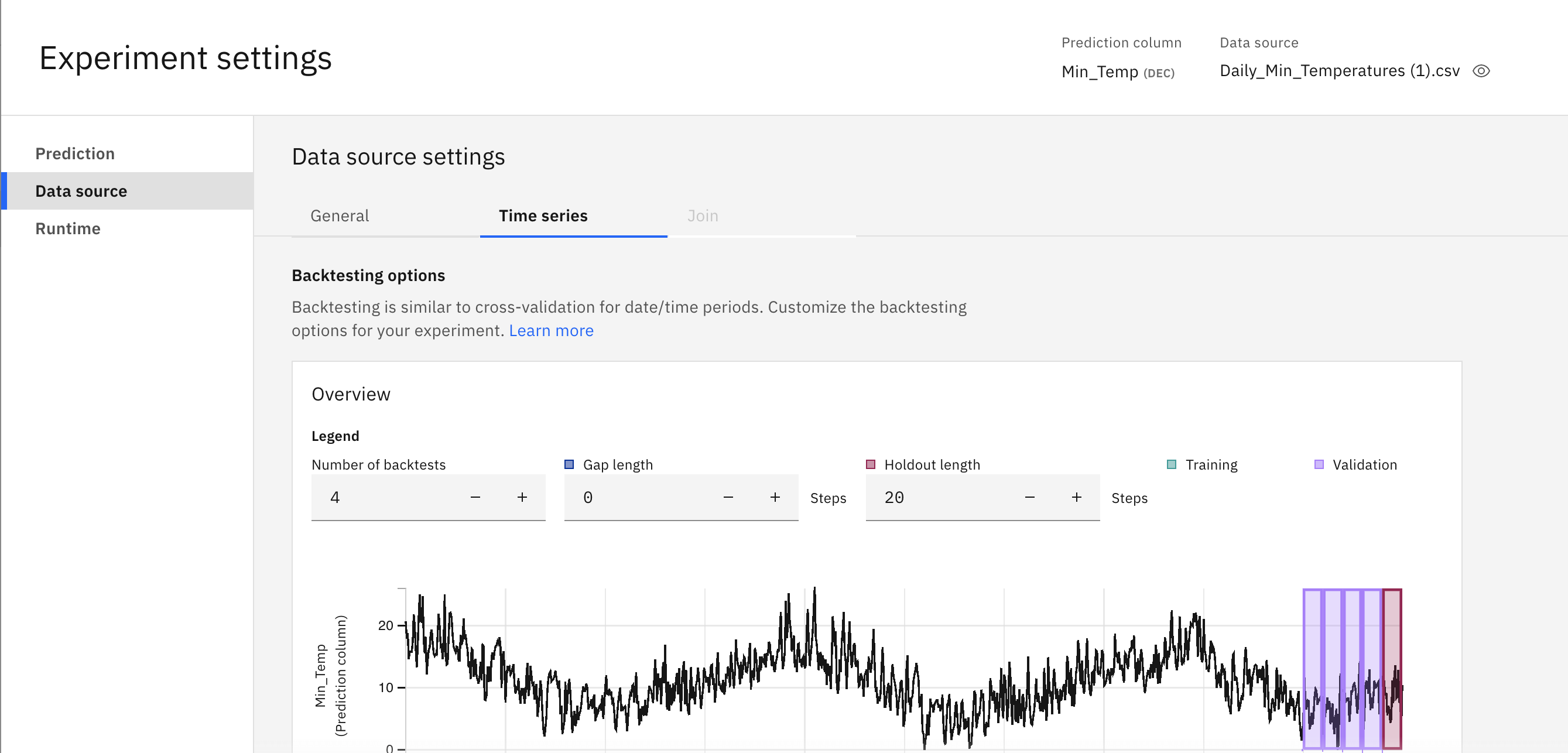
The visualization for the configuration settings illustrates the backtesting flow. The graphic is interactive, so you can manipulate the settings from the graphic or from the configuration fields. For example, by adjusting the gap length, you can see model validation results on earlier time periods of the data without increasing the number of backtests.
Interpreting the experiment results
After you run your time series experiment, you can examine the resulting pipelines to get insights into the experiment details. Pipelines that use Supporting features are indicated by SUP enhancement tag to distinguish them from pipelines that don’t use these features. To view details:
- Hover over nodes on the visualization to get details about the pipelines as they are being generated.
- Toggle to the Progress Map view to see a different view of the training process. You can hover over each node in the process for details.
- After the final pipelines are completed and written to the leaderboard, you can click a pipeline to see the performance details.
- Click View discarded pipelines to view the algorithms that are used for the pipelines that are not selected as top performers.
- Save the experiment code as notebook that you can review.
- Save a particular pipeline as a notebook that you can review.
Watch this video to see how to run a time series experiment and create a model in a Jupyter notebook using training and holdout data.
This video provides a visual method to learn the concepts and tasks in this documentation.
Next steps
- Follow a step-by-step tutorial to train a univariate time series model to predict minimum temperatures by using sample data.
- Follow a step-by-step tutorial to train a time series experiment with supporting features.
- Learn about scoring a deployed time series model.
- Learn about using the API for AutoAI time series experiments.
Additional resources
- For an introduction to forecasting with AutoAI time series experiments, see the blog post Right on time(series): Introducing Watson Studio’s AutoAI Time Series.
- For more information about creating a time series experiment, see this blog post about creating a new time series experiment.
- Read a blog post about adding supporting features to a time series experiment.
- Review a sample notebook for a time series experiment with supporting features.
- Read a blog post about adding supporting features to a time series experiment using the API.
Next steps
- Tutorial: AutoAI univariate time series experiment
- Tutorial: AutoAI supporting features time series experiment
- Time series experiment implementation details
- Scoring a time series model
Parent topic: AutoAI overview