Measure Watson Assistant Performance¶
Introduction¶
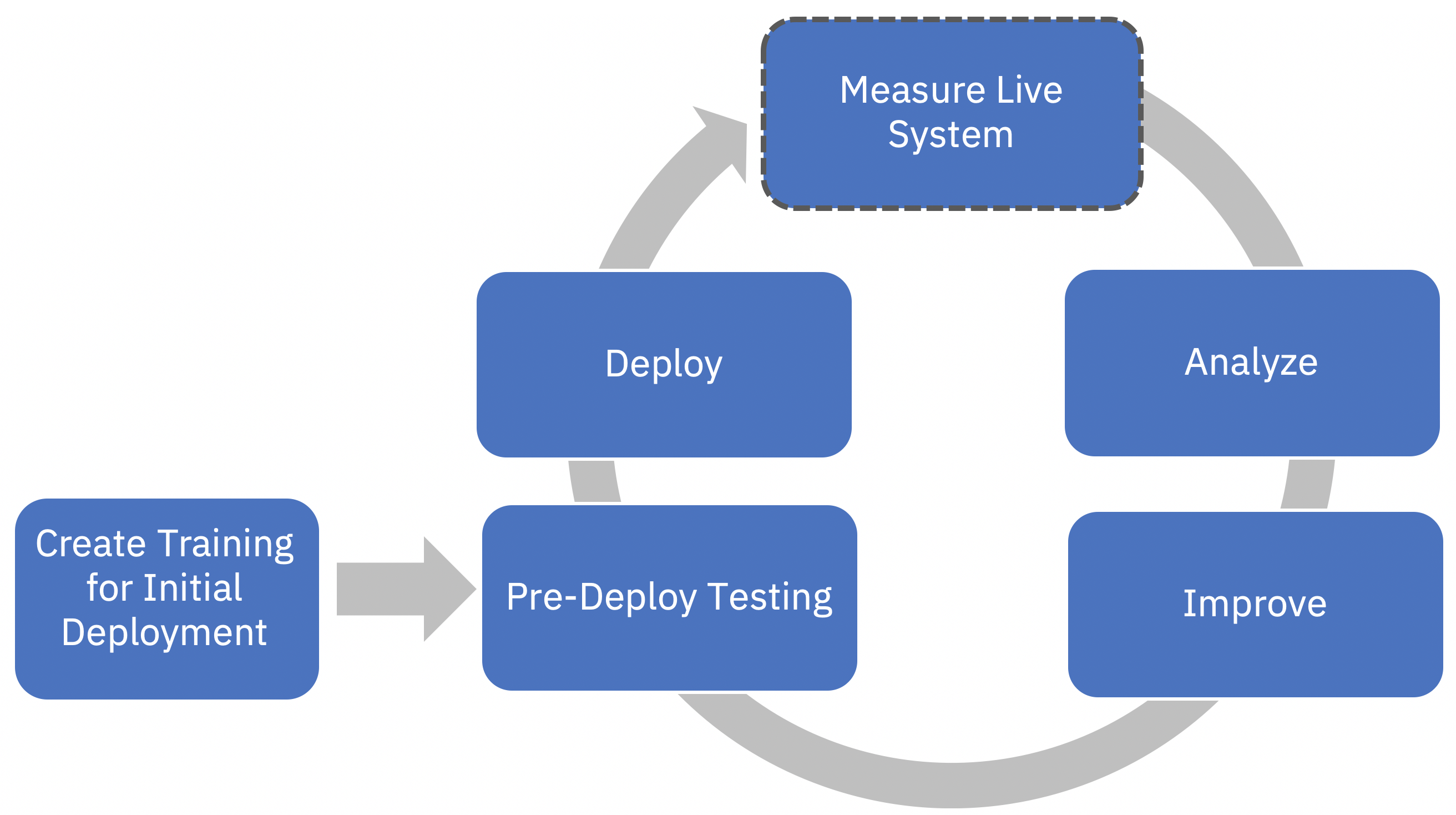
This notebook demonstrates how to setup automated metrics that help you measure, monitor, and understand the behavior of your Watson Assistant system. As described in Watson Assistant Continuous Improvement Best Practices, this is the first step of your continuous improvement process. The goal of this step is to understand where your assistant is doing well vs where it isn’t and to potentially focus your improvement effort to one of the problem areas identified. We define two measures to achieve this goal: Coverage and Effectiveness.
Coverage is the portion of total user messages your assistant is attempting to respond to.
Effectiveness refers to how well your assistant is handling the conversations it is attempting to respond to.
The pre-requisite for running this notebook is Watson Assistant (formerly Watson Conversation). This notebook assumes familiarity with Watson Assistant and concepts such as skills, workspaces, intents and training examples.
Programming language and environment¶
Some familiarity with Python is recommended. This notebook runs on Python 3.7+ environment.




