Analyze Watson Assistant Effectiveness¶
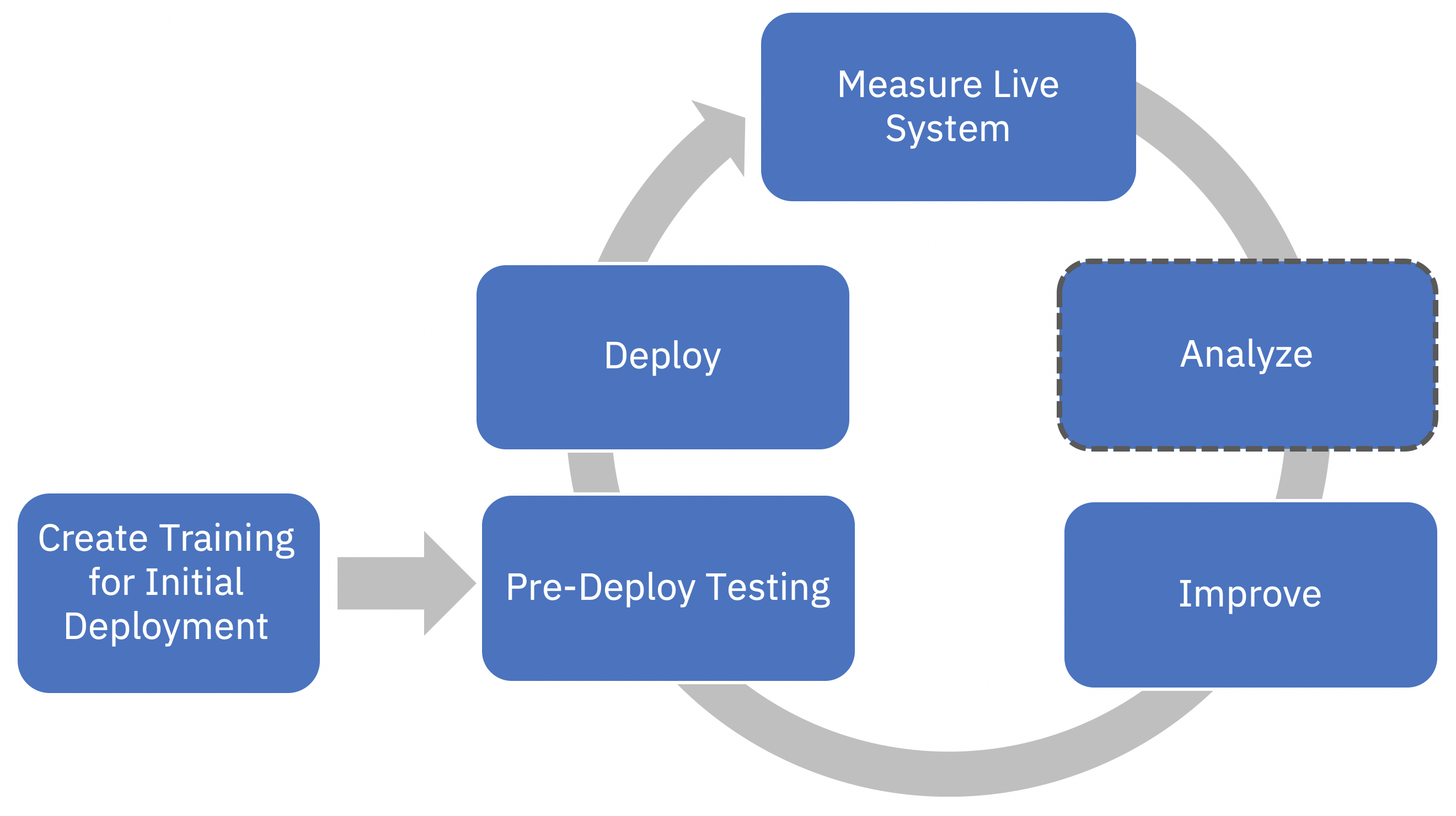
Introduction¶
As described in Watson Assistant Continuous Improvement Best Practices, this notebook will help you understand relative performance of each intent and entity, the confusion between your intents, as well as the root cause of utterance issues. This information helps you prioritize your improvement effort.
The pre-requisite for running this notebook is a collection of annotated utterances. This notebook assumes familiarity with Watson Assistant and concepts such as skills, workspaces, intents and training examples.
Programming language and environment¶
Some familiarity with Python is recommended. This notebook runs on Python 3.6 with the Default Python 3.6 XS environment.
Table of contents¶
- Configuration and setup
1.1 Apply global CSS styles
1.2 Install required Python libraries
1.3 Import functions used in the notebook
1.4 Add project token
1.5 Add annotation file - Load and format data
- Generate summary metrics
3.1 Generate confusion matrix
3.2 Calculate True Positive (TP), False Positive (FP), False Negative (FN), and True Negative (TN)
3.3 Calculate the total number of utterances, as well as the numbers of correct and wrong utterances
3.4 Calculate average helpfulness and its variance over different intents
3.5 Calculate average precision and variance
3.6 Display the summarized results
3.7 Summarize the root cause - Perform intent analysis
4.1 Determine worst overall performing intents
4.2 Determine the worst precision intents
4.3 Determine the worst recall intents
4.4 Determine confused intent pairs - Perform entity analysis
- Perform dialog analysis
- Summary and recommendation
1. Configuration and setup¶
Import the required libraries and functions and add data access credentials.
1.1 Import and apply global CSS styles¶
from IPython.display import display, HTML
!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/css/custom.css
HTML(open('custom.css', 'r').read())
1.2 Install Assistant Improve Toolkit¶
Import the libraries used in this notebook.
!pip install --user --upgrade "assistant-improve-toolkit";
1.3 Import functions used in the notebook¶
import pandas as pd
from sklearn.metrics import confusion_matrix
import numpy as np
from collections import OrderedDict
from IPython.display import Markdown as md
import re
import ast
from project_lib import Project
from assistant_improve_toolkit.cos_op import generate_link, generate_excel_effectiveness
from assistant_improve_toolkit.computation_func import round_decimal
from assistant_improve_toolkit.visualize_func import table_styles, make_bar
1.4 Add the project token¶
A project token is used to access data assets from notebooks.
To set a project token:
Open another browser window, go to your Watson Studio Project page, and click the Settings tab. Scroll down to Access tokens and click New token. Give the token a name and the Editor access role.
Click in an empty line in the cell below. Use the menu item with the three vertical dots, and choose Insert project token.
The Insert project token inserts a new cell at the top of the notebook. Copy the inserted string and replace the line
project = Project(project_id='', project_access_token='')with the equivalent string inserted by the menu item.Run the cell.

For more information about project tokens, see Manually add the project token.
1.5 Add annotation file¶
To run the effectiveness analysis, you first need to upload your annotated file:
- Click the Find and Add Data icon in the upper right corner (
 ) and then drop or browse your annotation file.
) and then drop or browse your annotation file. - Copy the file name and add it into
annotation_file = ''.
If you don't have an annotated file, run the following code cell to use our sample data.
# The following code is for using demo annotation data
import requests
print('Loading annotated data from Watson developer cloud GitHub repo ... ', end='')
annotated_data = requests.get("https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/notebook/data/annotation.xlsx").content
project.save_data('annotation.xlsx', annotated_data, overwrite=True)
print('completed!')
# Comment out to use your annotation file
# annotation_file = ''
If you are using your own annoted file, don't forget to change the value of annotation_file below.
annotation_file = 'annotation.xlsx'
2. Load and format data¶
Here, you load the annotated problematic logs for analysis. Remember add your sheet name into sheet_name=''.
column_list = [
'log_id',
'conversation_id',
'timestamp',
'customer_id',
'utterance_text',
'response_text',
'top_intent',
'top_confidence',
'intent_2',
'intent_2_confidence',
'confidence_gap',
'intent_3',
'intent_3_confidence',
'entities',
'is_escalated',
'is_convered',
'not_convered_cause',
'dialog_flow',
'dialog_stack',
'dialog_request_counter',
'dialog_turn_counter',
'correctness',
'helpfulness',
'root_cause',
'correct_intent',
'new_intent',
'add_train',
'missed_entity',
'new_entity',
'new_entity_value',
'new_dialog_logic',
'wrong_dialog_node',
'no_dialog_node_triggered'
]
annotated_data = pd.read_excel(project.get_file(annotation_file), sheet_name='data', names=column_list)
3. Generate summary metrics¶
In this section, you will:
- Generate the confusion matrix
- Calculate
- True Positive (TP), False Positive (FP), False Negative (FN), and True Negative (TN)
- The total number of utterances,
- The average helpfulness and its variance over different intents
- The average precision and variance
- Summarize the possible root causes and display the results
3.1 Generate confusion matrix¶
A confusion matrix is a table that is often used to describe the performance of a classification model.
# Get intent list
annotated_data['top_intent'] = annotated_data['top_intent'].replace(r'^\s+$', np.nan, regex=True)
annotated_data['correct_intent'] = annotated_data['correct_intent'].replace(r'^\s+$', np.nan, regex=True)
intents = pd.unique(annotated_data[['top_intent', 'correct_intent']].values.ravel())
# Remove NaN
intents=sorted(intents[~pd.isnull(intents)])
# add a ground truth column
annotated_data['ground_truth'] = annotated_data['correct_intent'].fillna(annotated_data['top_intent'])
# calculate number of count per intent based on top intent
num_total_per_intent = pd.DataFrame(annotated_data.groupby('top_intent').size(), intents).fillna(0)
# calculate number of count per intent based on ground truth
num_total_per_intent_gt = pd.DataFrame(annotated_data.groupby('ground_truth').size(), intents).fillna(0)
# Generate confusion matrix
confusion_matrix = confusion_matrix(annotated_data['ground_truth'], annotated_data['top_intent'], labels=intents)
3.2 Calculate True Positive (TP), False Positive (FP), False Negative (FN), and True Negative (TN)¶
- True Positives of an intent describe cases where the intent classifier correctly classifies utterances as this intent
- False Positives of an intent describe cases where the intent classifier incorrectly classifies utterances as this intent
- False Negatives of an intent describe cases where the intent classifier fails to identify utterances as this intent
- True Negatives of an intent describe cases where the intent classifier correctly identifies that utterances don't belong to this intent
# Calculate True Positive (TP)
TP = np.diag(confusion_matrix)
# Calculate False Positive (FP)
FP = np.sum(confusion_matrix, axis=0) - TP
# Calculate False Negative (FN)
FN = np.sum(confusion_matrix, axis=1) - TP
# Calculate True Negative (TN)
TN = []
for i in range(len(intents)):
row_del = np.delete(confusion_matrix, i, 0)
col_del = np.delete(row_del, i, 1)
TN.append(sum(sum(col_del)))
3.3 Calculate the total number of utterances, as well as the numbers of correct and wrong utterances¶
# Get total number of utterances
total_num = np.sum(TP+FP)
# Get total number of correctly classified utterances
total_correct = np.sum(TP)
# Get total number of incorrectly classified utterances
total_wrong = np.sum(FP)
3.4 Calculate average helpfulness and its variance over different intents¶
Helpfulness is a metric that identifies responses that may be considered technically correct, but the wording of the response is not satisfying to the user. It could be too long, too general, or just worded awkwardly, thus resulting in an overall ineffective response.
Note: The exact definition of helpfulness is subjective and can be defined based on your business goals.
# Get number of utterances that labeled as helpful per class
num_helpfulness_per_intent = annotated_data.loc[annotated_data['helpfulness']== 'Y'].groupby('ground_truth').size()
num_unhelpfulness_per_intent = annotated_data.loc[annotated_data['helpfulness']== 'N'].groupby('ground_truth').size()
# Get number of utterances per class
num_total_per_intent_helpfulness = num_helpfulness_per_intent.add(num_unhelpfulness_per_intent, fill_value=0)
# Get total number of utterances that labeled as helpful
num_helpfulness = sum(num_helpfulness_per_intent)
num_unhelpfulness = sum(num_unhelpfulness_per_intent)
# Calculate averaged helpfulness
avg_help = np.average(num_helpfulness_per_intent.divide(num_total_per_intent_helpfulness, fill_value=0))
# Calculate helpfulness variance
var_help = np.var(num_helpfulness_per_intent.divide(num_total_per_intent_helpfulness, fill_value=0))
# Calculate helpful utterance percentage per intents
percentage_helpful_intent = num_helpfulness_per_intent.divide(num_total_per_intent_helpfulness, fill_value=0)
# Collect invalid intent for helpfulness metric
invalid_intent_helpfulness = list(set(intents) - set(num_total_per_intent_helpfulness.index.tolist()))
3.5 Calculate average precision and variance¶
Precision is a metric measuring the performance of intent classifier.
# Calculate precision by intents
TP_FP = TP+FP
precision_list = pd.DataFrame({'True Positives': TP, 'True&False Positive': TP_FP, 'Intents': intents})
# Remove invalid intent
invalid_intent_precision = precision_list[precision_list['True&False Positive']==0]['Intents']
precision_list = precision_list[precision_list['True&False Positive']>0]
# Calculate precision per intent
precision_list['Precision'] = precision_list['True Positives'] / precision_list['True&False Positive']
# Calculate averaged precision
avg_prec = np.average(precision_list['Precision'])
# Calculate precision variance
var_prec = np.var(precision_list['Precision'])
# print Performance Summary
print('===== Performance Summary =====\n')
print('Number of intents: {}'.format(len(intents)))
print('Number of Utterances: {}'.format(total_num))
print('\n\tTop 5 intents based on count of top detected intent:\n')
for intent, value in num_total_per_intent.sort_values(by=0, ascending=False).head(5)[0].iteritems():
print('\t\t{:<30}\t{}'.format(intent, value))
print('\n\tBottom 5 intents based on count in top detected intent:\n')
for intent, value in num_total_per_intent.sort_values(by=0, ascending=True).head(5)[0].iteritems():
print('\t\t{:<30}\t{}'.format(intent, value))
print('\n\tTop 5 intents based on count of ground truth intent:\n')
for intent, value in num_total_per_intent_gt.sort_values(by=0, ascending=False).head(5)[0].iteritems():
print('\t\t{:<30}\t{}'.format(intent, value))
print('\n\tBottom 5 intents based on count of ground truth intent:\n')
for intent, value in num_total_per_intent_gt.sort_values(by=0, ascending=True).head(5)[0].iteritems():
print('\t\t{:<30}\t{}'.format(intent, value))
print('\nCorrect Classified Utterances: {}'.format(total_correct))
print('Incorrectly Classified Utterances: {}\n'.format(total_wrong))
print('- Helpfulness\n')
print('\tHelpful Utterances: {}'.format(num_helpfulness))
print('\tUnhelpful Utterances: {}'.format(num_unhelpfulness))
print('\tAverage Helpfulness Percentage: {}'.format(round_decimal(avg_help,3)))
print('\tHelpfulness Variance: {}\n'.format(round_decimal(var_help,3)))
print('\tTop 5 best performed intents:\n')
for intent, value in percentage_helpful_intent.sort_values(ascending=False).head(5).iteritems():
print('\t\t{:<30}\t{:4.3f}'.format(intent, round_decimal(value,3)))
print('\n\tTop 5 worst performed intents:\n')
for intent, value in percentage_helpful_intent.sort_values(ascending=True).head(5).iteritems():
print('\t\t{:<30}\t{:4.3f}'.format(intent, round_decimal(value,3)))
print('\n- Precision\n')
print('\tTrue Positive: {}'.format(sum(TP)))
print('\tFalse Positive: {}'.format(sum(FP)))
print('\tFalse Negative: {}'.format(sum(FP)))
print('\tAverage Precision: {}'.format(round_decimal(avg_prec,3)))
print('\tPrecision Variance: {}\n'.format(round_decimal(var_prec,3)))
print('\tTop 5 best performed intents:\n')
for row in precision_list.sort_values(by=['Precision'], ascending=False).head(5).iterrows():
print('\t\t{:<30}\t{:4.3f}'.format(row[1]['Intents'], round_decimal(row[1]['Precision'],3)))
print('\n\tTop 5 worst performed intents:\n')
for row in precision_list.sort_values(by=['Precision'], ascending=True).head(5).iterrows():
print('\t\t{:<30}\t{:4.3f}'.format(row[1]['Intents'], round_decimal(row[1]['Precision'],3)))
if len(invalid_intent_helpfulness) > 0:
print('\n*Note*: the following intents are ignored when calculating Helpfulness due to missing values\n')
for intent in invalid_intent_helpfulness:
print('\t{}'.format(intent))
if len(invalid_intent_precision) > 0:
print('\n*Note*: the following intents are ignored when calculating Precision due to the sum of True and False Positive is zero\n')
for intent in invalid_intent_precision:
print('\t{}'.format(intent))
3.6.2 Visualize precision and helpfulness percentage in a bar graph¶
The red lines on the bars indicate value variances. Note that if your variance is very small, the line may appear as a dot at the top of the bar. Here a smaller variance is preferred which indicates that the performance of your intent classifer is more stable across different intents.
make_bar(avg_prec*100, avg_help*100, var_prec*100, var_help*100)

3.7 Summarize the root cause¶
Root causes describe issues caused by an incorrect or absent intent, entity, or dialog response.
3.7.1 Display root causes summary¶
# Group by root causes and display count
root_cause = annotated_data['root_cause'].replace(r'^\s+$', np.nan, regex=True).dropna().value_counts().rename_axis('Root Causes').reset_index(name='Utterances')
# Apply style on dataframe
root_cause.style.set_table_styles(table_styles).set_properties(**{'text-align': 'center'}).set_properties(
subset=['Root Causes'], **{'width': '700px', 'text-align': 'left'}).format(
{'Utterances': lambda x: "{:.0f}".format(x)})
3.7.2 Save the results into a dataframe¶
# Create a dataframe to enclose the statistics computed so far
df = pd.DataFrame(OrderedDict( ( ('Intents', intents), ('True Positives', TP), ('False Positives', FP), ('True Negatives', TN), ('False Negatives', FN), ('Total Utterances (top intent)', num_total_per_intent[0]),('Total Utterances (ground truth)', num_total_per_intent_gt[0]), ('Total Errors', FP + FN))))
4. Perform intent analysis¶
Intent analysis is performed by looking for the dominant patterns of intent errors. An effective way to perform this analysis is to focus on four main categories of errors:
- Worst overall performing intents: these are intents that are most involved in a wrong answer, whether due to precision or recall.
- Worst recall intents: this identifies intents that are being missed most often. This intent should have been given out, but other intent(s) are matching instead. These intents likely need more training examples.
- Worst precision intents: this identifies intents that are frequently matching when they should not be, thus hiding the correct intent(s). These intents likely have training examples that clash with training of other intents.
- Most confused intent pairs: these are pairs of intents that are often confused with each other. These intents likely have training examples that overlap.
4.1 Determine worst overall performing intents¶
These are intents that are most involved in a wrong answer, whether due to precision or recall. Here are the metrics we recommend measuring:
- False Positives of an intent describe cases where the intent classifier incorrectly classifies utterance as this intent.
- False Negatives: of an intent describe cases where the intent classifier fails to classify an utterance as this intent.
# Define expiration time (in seconds) of the generated link
expiration_time = 86400 # 24 hours
# Generate presigned downloadable link from Cloud Object Storage
worstOverallLink = generate_link('WorstOverallIntents.csv', project, expiration=expiration_time)
display(md('<p>'))
display(md('<div style="max-width: 1300px;"><div style="float: left;">View the whole list here: <b><a href="{}" style="color:black" target="_blank">WorstOverallIntents.csv</a></b></div><div style="float: right"> 25 Worst Intents </div></div>'.format(worstOverallLink)))
# Sort dataframe by number of errors and add related columns
worst_overall = df.sort_values('Total Errors', ascending=False)[['Intents','Total Utterances (top intent)','Total Utterances (ground truth)','Total Errors',
'False Positives', 'False Negatives'
]].reset_index(drop=True)
# Save the output CSV file
project.save_data('WorstOverallIntents.csv', worst_overall.to_csv(), overwrite=True)
# Apply style on dataframe table
worst_overall.head(15).style.set_table_styles(table_styles).set_properties(**{'text-align': 'center'}).set_properties(
subset=['Total Utterances (top intent)'], **{'width': '140px'}).set_properties(
subset=['Total Utterances (ground truth)'], **{'width': '160px'}).set_properties(
subset=['Total Errors'], **{'width': '100px'}).set_properties(subset=['Intents'], **{'width': '450px', 'text-align': 'left'})
4.2 Determine the worst precision intents¶
This identifies intents that are frequently matching when they should not be, thus hiding the correct intent(s). These intents likely have training examples that clash with training of other intents. Here are the metrics we recommend measuring:
- True Positives of an intent describe cases where the intent classifier correctly classifies utterance as this intent.
- False Positives of an intent describe cases where the intent classifier incorrectly classifies utterance as this intent.
# Calculate precision by intents
TP_FP = TP+FP
percentile_list = pd.DataFrame({'True Positives': TP,'False Positives': FP, 'True&False Positive': TP_FP, 'Intents': intents})
# Remove invalid intent
invalid_intent_precision = percentile_list[percentile_list['True&False Positive']==0]['Intents']
percentile_list = percentile_list[percentile_list['True&False Positive']>0]
# Calculate precision per intent
percentile_list['Precision'] = percentile_list['True Positives'].divide(percentile_list['True&False Positive']).values
percentile_list = percentile_list.join(df[['Total Utterances (top intent)', 'Total Utterances (ground truth)']], on='Intents')
# Generate presigned downloadable link from Cloud Object Storage
worstPrecLink = generate_link('WorstPrecisionIntents.csv', project, expiration=expiration_time)
display(md('<p>'))
display(md('<div style="max-width: 1500px;"><div style="float: left">View the whole list here: <b><a href="{}" style="color:black" target="_blank">WorstPrecisionIntents.csv</a></b></div><div style="float: right"> 25 Worst Intents </div> </div>'.format(worstPrecLink)))
# Sort dataframe by precision and add related columns
worst_prec = percentile_list.sort_values(['Precision', 'False Positives'], ascending=[True, False])[['Intents','Total Utterances (top intent)', 'Total Utterances (ground truth)', 'True Positives',
'False Positives', 'Precision']].reset_index(drop=True)
# Save the output CSV file
project.save_data('WorstPrecisionIntents.csv', worst_prec.to_csv(), overwrite=True)
# Apply style on dataframe table
table = worst_prec.head(25).style.set_table_styles(table_styles).set_properties(**{'text-align': 'center'}).set_properties(
subset=['Total Utterances (top intent)'], **{'width': '140px'}).set_properties(
subset=['Total Utterances (ground truth)'], **{'width': '180px'}).set_properties(
subset=['Intents'], **{'width': '400px', 'text-align': 'left'}).format(
{"Precision": lambda x: "{:.0f}%".format(x*100)}).set_properties(
subset=['Precision'], **{'width': '350px', 'text-align': 'center'}).render()
# Apply CSS style
style = '.meter { height: 6px; width: 50%; position: relative; background: #fff; border-radius: 20px; border-color: rgb(0, 76, 192); border-style: solid; border-width: 1px; float: left; margin-top: 8px; margin-left: 50px;margin-right: 15px; } .meter>span { display: block; height: 100%; background-color: rgb(0, 76, 192); position: relative; overflow: hidden; } '
table = table[:table.find('>') + 1] + style + table[table.find('>') + 1:]
# Insert percentage bar
pattern = r'(data row)(.*?)( col5" >)(.*?)(%)(</td>)'
bar_code = r'<div class="meter" style="float: left;margin-left: 30px;"> <span style="width: \4%"></span> </div><div style="float: left;margin-left: 0px;">'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1\2\3'+bar_code+r'\4\5</div>\6', table)
if len(invalid_intent_precision) > 0:
invalid_note = '<br><b>Note<b>: the following intents are ignored when calculating Precision due to the sum of True Positive and False Positive is zero<p>'
for intent in invalid_intent_precision:
invalid_note += ' {}<br>'.format(intent)
table += invalid_note
# Show table
HTML(table)
4.3 Determine the worst recall intents¶
This identifies intents that are being missed most often. This intent should have been given out, but other intent(s) are matching instead. These intents likely need more training examples.
- True Positives of an intent describe cases where the intent classifier correctly classifies utterance as this intent
- False Negative of an intent describe cases where the intent classifier fails to classify utterance as this intent
# Calculate recall by intents
TP_FN = TP+FN
percentile_recall_list = pd.DataFrame({'True Positives': TP,'False Negatives': FN, 'Intents': intents, 'True Positive&False Negative': TP_FN})
# Remove invalid intent
invalid_intent_recall = percentile_recall_list[percentile_recall_list['True Positive&False Negative']==0]['Intents']
percentile_recall_list = percentile_recall_list[percentile_recall_list['True Positive&False Negative']>0]
# Calculate precision per intent
percentile_recall_list['Recall'] = percentile_recall_list['True Positives'].divide(percentile_recall_list['True Positive&False Negative']).values
percentile_recall_list = percentile_recall_list.join(df[['Total Utterances (top intent)', 'Total Utterances (ground truth)']], on='Intents')
# Generate presigned downloadable link from Cloud Object Storage
worstRecallLink = generate_link('WorstRecallIntents.csv', project, expiration=expiration_time)
display(md('<p>'))
display(md('<div style="max-width: 1300px;"><div style="float: left">View the whole list here: <b><a href="{}" style="color:black" target="_blank">WorstRecallIntents.csv</a></b></div><div style="float: right"> 25 Worst Intents </div></div>'.format(worstRecallLink)))
# Sort dataframe by recall and add related columns
worst_recall = percentile_recall_list.sort_values(['Recall', 'False Negatives'], ascending=[True, False])[['Intents','Total Utterances (top intent)','Total Utterances (ground truth)', 'True Positives', 'False Negatives',
'Recall']].reset_index(drop=True)
# Save the output CSV file
project.save_data('WorstRecallIntents.csv', worst_recall.to_csv(), overwrite=True)
# Apply style on dataframe table
table = worst_recall.head(25).style.set_table_styles(table_styles).set_properties(**{'text-align': 'center'}).set_properties(
subset=['Total Utterances (top intent)'], **{'width': '140px'}).set_properties(
subset=['Total Utterances (ground truth)'], **{'width': '180px'}).set_properties(
subset=['Intents'], **{'width': '400px', 'text-align': 'left'}).format(
{"Recall": lambda x: "{:.0f}%".format(x*100)}).set_properties(
subset=['Recall'], **{'width': '350px', 'text-align': 'center'}).render()
# Apply CSS style
style = '.meter { height: 6px; width: 50%; position: relative; background: #fff; border-radius: 20px; border-color: rgb(0, 76, 192); border-style: solid; border-width: 1px; float: left; margin-top: 8px; margin-left: 50px;margin-right: 15px; } .meter>span { display: block; height: 100%; background-color: rgb(0, 76, 192); position: relative; overflow: hidden; } '
table = table[:table.find('>') + 1] + style + table[table.find('>') + 1:]
# Insert percentage bar
pattern = r'(data row)(.*?)( col5" >)(.*?)(%)(</td>)'
bar_code = r'<div class="meter" style="float: left;margin-left: 30px;"> <span style="width: \4%"></span> </div><div style="float: left;margin-left: 0px;">'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1\2\3'+bar_code+r'\4\5</div>\6', table)
if len(invalid_intent_recall) > 0:
invalid_note = '<br><b>Note</b>: the following intents are ignored when calculating Recall due to the sum of True Positive and False Negative is zero<p>'
for intent in invalid_intent_recall:
invalid_note += ' {}<br>'.format(intent)
table += invalid_note
# Show table
HTML(table)
4.4 Determine confused intent pairs¶
Most confused intent pairs: these are pairs of intents that are often confused with each other. Here is a description of the columns you focus on in this section:
- Intent 1, Intent 2: The pair of confused intents
- Incorrectly in Intent 1: Number of utterances where intent 1 was identified instead of intent 2
- Incorrectly in Intent 2: Number of utterances where intent 2 was identified instead of intent 1
# Generate presigned downloadable link from Cloud Object Storage
confusedIntentLink = generate_link('ConfusedIntentPairs.csv', project, expiration=expiration_time)
display(md('<p>'))
display(md('<div style="max-width: 1300px;"><div style="float: left">View the whole list here: <b><a href="{}" style="color:black" target="_blank">ConfusedIntentPairs.csv</a></b></div><div style="float: right"> 25 Worst Intents </div></div>'.format(confusedIntentLink)))
# Calculate confused intents
# Merge two copies of the dataframe on ground truth and intent
copy1 = annotated_data.loc[annotated_data['top_intent']!=annotated_data['ground_truth'], ['ground_truth','top_intent']].groupby(['ground_truth','top_intent']).size().reset_index(name="Count").sort_values(by='Count', ascending = False)
copy2 = annotated_data.loc[annotated_data['top_intent']!=annotated_data['ground_truth'], ['ground_truth','top_intent']].groupby(['ground_truth','top_intent']).size().reset_index(name="Count").sort_values(by='Count', ascending = False)
result = pd.merge(copy1, copy2, left_on='ground_truth', right_on = 'top_intent')
if len(result) == 0:
confused_intents = copy1.rename(columns={'ground_truth':'Intent 1', 'top_intent':'Intent 2', 'Count':'Incorrectly in Intent 2'})
confused_intents['Incorrectly in Intent 1']=0
else:
# Filter and rename columns
confused_intents = result.loc[(result['ground_truth_x']==result['top_intent_y']) & (result['top_intent_x']==result['ground_truth_y'])].rename(columns={'ground_truth_x':'Intent 1', 'top_intent_x':'Intent 2', 'Count_x':'Incorrectly in Intent 2','Count_y':'Incorrectly in Intent 1'}).drop(['ground_truth_y','top_intent_y'], axis=1)
# Sort results
helper = pd.DataFrame(np.sort(confused_intents[['Intent 1', 'Intent 2']], axis=1), confused_intents[['Intent 1', 'Intent 2']].index, confused_intents[['Intent 1', 'Intent 2']].columns)
# Remove duplicates
helper.drop_duplicates(inplace = True)
# Perform an inner join to get most confused intents
most_confused_intents = pd.merge(helper, confused_intents, on=['Intent 1', 'Intent 2'], how = 'inner')
# Calculate 'Total wrong' column
most_confused_intents.insert(loc=0, column='Total Wrong', value=most_confused_intents['Incorrectly in Intent 1']+most_confused_intents['Incorrectly in Intent 2'])
# Get confused intent pairs - sorted by 'Total wrong' column
confused_intent_pairs = most_confused_intents[['Total Wrong','Intent 1', 'Intent 2', 'Incorrectly in Intent 1','Incorrectly in Intent 2']].sort_values(by = 'Total Wrong', ascending = False).reset_index(drop=True)
# Save the output CSV file
project.save_data('ConfusedIntentPairs.csv', confused_intent_pairs.to_csv(), overwrite=True)
# Apply style on dataframe table
table = confused_intent_pairs.head(25).style.set_table_styles(table_styles).set_properties(**{'text-align': 'center'}).set_properties(
subset=['Intent 1', 'Intent 2'], **{'width': '300px', 'text-align': 'left'}).format(
{"Incorrectly in Intent 1": lambda x: "{:.0f}".format(x)}).set_properties(
subset=['Incorrectly in Intent 1','Incorrectly in Intent 2'], **{'width': '250px', 'text-align': 'center'}).render()
# Apply CSS style
style = '.dot {float: left; margin-left: 90px;margin-top: 4px; height: 10px; width: 10px; background-color: #4eaaf7; border-radius: 50%; display: inline-block; } .dot_mid {float: left; margin-left: 85px;margin-top: 4px; height: 10px; width: 10px; background-color: #fff; border-radius: 50%; display: inline-block; border-style: solid; border-width: 3px; border-color: #c819e0; }'
table = table[:table.find('>') + 1] + style + table[table.find('>') + 1:]
# Insert blue dots
pattern = r'(data row)(.*?)( col3" >)(.*?)(</td>)'
dot = r'<span class="dot"></span><div style="float: middle;margin-right: 60px;">'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1\2\3'+dot+r'\4\5</div>', table)
# Insert pink dots
pattern = r'(data row)(.*?)( col4" >)(.*?)(</td>)'
dot = r'<span class="dot_mid"></span><div style="float: middle;margin-right: 60px;">'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1\2\3'+dot+r'\4\5</div>', table)
# Insert blue dot into header
pattern = r'(col_heading level0 col1" >)(.*?)(</th>)'
dot = r'</div><div style="float:left;margin-left: -70px;"><span class="dot"></span></div>'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1<div style="float:left;margin-left: 80px;">\2'+dot+r'\3', table)
# Insert pink dot into header
pattern = r'(col_heading level0 col2" >)(.*?)(</th>)'
dot = r'</div><div style="float:left;margin-left: -65px;"><span class="dot_mid"></span></div>'
regex = re.compile(pattern, re.IGNORECASE)
table = re.sub(pattern, r'\1<div style="float:left;margin-left: 80px;">\2'+dot+r'\3', table)
# Show table
HTML(table)
5. Perform entity analysis¶
Entity analysis highlights the entities and entity values that are particularly problematic, so they can be targeted for further investigation and improvement.
# Get missed entity data from annotated_data dataframe
all_entities = annotated_data['missed_entity'].dropna().reset_index(drop = True)
# Convert the value into dict object
try:
all_entities = all_entities.apply(lambda x: ast.literal_eval(x))
except:
print("Malformed JSON annotation for entities, please check your annotation")
for annotation in all_entities:
print(annotation)
raise
# There are multiple entities in a single column. Separate them so that there is only a single entity in a column
# Separate entities into different columns
entities_sep = pd.DataFrame(all_entities.values.tolist(), all_entities.index).add_prefix('entity_')
# Append all non-empty entities to a Series
series1 = pd.Series(dtype=object)
for col in entities_sep.columns:
series1 = series1.append(entities_sep[entities_sep[col].notnull()][col])
missed_entity_df = series1.to_frame('entities').reset_index(drop = True)
# Extract 'Entity' and 'Entity value' from dictionary to missed_entity
missed_entity_df['Entity'] = missed_entity_df['entities'].apply(lambda x: x['entity'])
missed_entity_df['Entity Value'] = missed_entity_df['entities'].apply(lambda x: x['value'])
missed_entity_df['Synonym'] = missed_entity_df['entities'].apply(lambda x: x['synonym'])
missed_entity = missed_entity_df[['Entity','Entity Value','Synonym']]
# Calculate the number of times an entity with a value was missed
missed_entity['Value Missed Count']=missed_entity.groupby(['Entity','Entity Value'])['Entity'].transform('count')
# Calculate the total number of times an entity was missed
missed_entity['Total Missed']= missed_entity.groupby(['Entity'])['Entity'].transform('count')
# Remove duplicates
missed_entity.drop_duplicates(keep = 'first', inplace=True)#sort_values(by='missed_entity')
# Create a pivot table with counts
df_pivot = pd.pivot_table(missed_entity, ['Value Missed Count'], ['Entity', 'Total Missed', 'Entity Value'])
# Sort the table by total missed count
missed_entities_all = df_pivot.reset_index().sort_values(['Total Missed','Entity','Value Missed Count'], ascending=False)
# Get the first 25 entities in a list
cols = missed_entities_all['Entity'].unique()[:25]
# Set index of dataframe
missed_entities_all = missed_entities_all.reset_index(drop = True).set_index(['Entity','Total Missed','Entity Value'])
idx = pd.IndexSlice
# Save the output CSV file
project.save_data('EntitiesMissed.csv', missed_entities_all.to_csv(), overwrite=True)
# Generate presigned downloadable link from Cloud Object Storage
entitiesMissedLink = generate_link('EntitiesMissed.csv', project, expiration=expiration_time)
display(md('<p>'))
display(md('<div style="max-width: 800px;"><div style="float: left">View the whole list here: <b><a href="{}" style="color:black" target="_blank">EntitiesMissed.csv</a></b></div><div style="float: right"> </div></div>'.format(entitiesMissedLink)))
# Show the first 25 most missed entities
with pd.option_context('display.max_rows', None, 'display.max_columns', 1):
display(missed_entities_all.loc[idx[cols, :, :],:])
6. Perform dialog analysis¶
Dialog analysis highlights instances where dialog problems were the root cause of the ineffectiveness. Dialog could be the problem because either the wrong response condition was triggered or because there was no response condition in place to handle the user message. These situations are used as candidates for improvement.
# Get dialog data from annotated_data dataframe
wrong_node_df = annotated_data['wrong_dialog_node'].value_counts().rename_axis('Node Name').reset_index(name='Node Count')
table = ''
if len(wrong_node_df) > 0:
# Add a new column with reason for 'wrong dialog node'
wrong_node_df.insert(loc=0, column='Dialog', value='Wrong node response triggered')
# Find the number of times 'wrong node response' was triggered
wrong_node_df['Utterances'] = wrong_node_df.groupby('Dialog')['Node Count'].transform(sum)
else:
print('No annotation data for \'Wrong node response triggered\'')
if len(annotated_data['no_dialog_node_triggered'].dropna()) > 0:
# Find the number of times 'no node response' was triggered
wrong_node_df.loc[len(wrong_node_df)] = ['No node response triggered', 'N/A', 0, annotated_data['no_dialog_node_triggered'].value_counts()['Y']]
else:
print('No annotation data for \'No node response triggered\'')
if len(wrong_node_df) > 0:
# Create a pivot table with counts
table = pd.pivot_table(wrong_node_df, ['Node Count'], ['Dialog','Utterances','Node Name']).to_html()
HTML(table)
7. Summary and recommendation¶
This notebook shows you the following summary metrics based on your assessment:
- The overall precision and helpfulness of your assistant’s responses
- Intent analysis
- Entity analysis
- Dialog analysis
To improve the performance of your assistant service, based on the above results, we provide the following recommendations and resources:
Recommendations:¶
Entity
- Use Synonym Recommender to improve the top missed entitied indentified in Entity Analysis.
- Check and add the newly marked entities from entity sheet in recommendation.xlsx into your skill or workspace and use Synonym Recommender to enrich the list of various entity values.
- Check and import newly identified entity values, from entity_value sheet in recommendation.xlsx, into your skill or workspace.
- Check and import the missed entity value synonyms, from synonym sheet in recommendation.xlsx, into your skill or workspace.
Intent
- Use intent Conflict Resolver to improve the top confused intent pair indentified in Confused Intent Analysis.
- Check and import newly marked intent training utterance list, from intent sheet in recommendation.xlsx, into your skill or workspace.
Dialog
- Check the top problematic dialog nodes identified in Dialog Analysis.
After those updates have been performed, you have the option to continue focusing your improvement efforts on any trouble spots identified during the Analyze phase.
For more information, please check Watson Assistant Continuous Improvement Best Practices.
Create the recommendation.xlsx file now.
# Collect newly identified entities for training
new_entity = annotated_data['new_entity'].dropna().reset_index(drop = True)
# Convert the value into dict object
new_entity = new_entity.apply(lambda x: ast.literal_eval(x))
# Separate entities into different columns
new_entity_sep = pd.DataFrame(new_entity.values.tolist(), new_entity.index).add_prefix('entity_')
# Append all non-empty entities to a Series
series1 = pd.Series(dtype=object)
for col in new_entity_sep.columns:
series1 = series1.append(new_entity_sep[new_entity_sep[col].notnull()][col])
new_entity = series1.to_frame('entities').reset_index(drop = True)
# Extract 'Entity' and 'Entity value' from dictionary to missed_entity
new_entity['Entity'] = new_entity['entities'].apply(lambda x: x['entity']).drop_duplicates()
# Collect newly identified entity values for training
new_entity_value = annotated_data['new_entity_value'].dropna().reset_index(drop = True)
# Convert the value into dict object
new_entity_value = new_entity_value.apply(lambda x: ast.literal_eval(x))
# Separate entities into different columns
new_entity_value_sep = pd.DataFrame(new_entity_value.values.tolist(), new_entity_value.index).add_prefix('entity_')
# Append all non-empty entities to a Series
series1 = pd.Series(dtype=object)
for col in new_entity_value_sep.columns:
series1 = series1.append(new_entity_value_sep[new_entity_value_sep[col].notnull()][col])
new_entity_value = series1.to_frame('entities').reset_index(drop = True)
# Extract 'Entity' and 'Entity value' from dictionary to missed_entity
new_entity_value['Entity'] = new_entity_value['entities'].apply(lambda x: x['entity'])
new_entity_value['Entity Value'] = new_entity_value['entities'].apply(lambda x: x['value'])
new_entity_value = new_entity_value[['Entity', 'Entity Value']].drop_duplicates()
try:
missed_entity
except NameError:
new_entity_synonym = pd.DataFrame(columns=['Entity','Entity Value','Synonym'])
print('No missing entity in annotation')
else:
# Collect newly identified synonyms for training
new_entity_synonym = missed_entity[['Entity','Entity Value','Synonym']].drop_duplicates()
# Collect utterance marked as adding for training
new_train_utterance = annotated_data.loc[annotated_data['add_train'] == 'Y'][['utterance_text','top_intent']].reset_index(drop = True)
generate_excel_effectiveness([new_entity['Entity'], new_entity_value, new_entity_synonym, new_train_utterance], ['entity', 'entity_value','synonym', 'intent'], filename = 'recommendation.xlsx', project_io = project)
recommendation_link = generate_link('recommendation.xlsx', project, expiration=expiration_time)
display(md('### Resources:'))
display(md('- <a id="improvement_recommendation"></a>Improvement recommendation: <a href="{}" target="_blank">recommendation.xlsx</a>'.format(recommendation_link)))
Authors¶
Zhe Zhang, Ph.D. in Computer Science, is a Data Scientist for IBM Watson AI. Zhe has a research background in Natural Language Processing, Sentiment Analysis, Text Mining, and Machine Learning. His research has been published at leading conferences and journals including ACL and EMNLP.
Sherin Varughese is a Data Scientist for IBM Watson AI. Sherin has her graduate degree in Business Intelligence and Data Analytics and has experience in Data Analysis, Warehousing and Machine Learning.
Acknowledgement¶
The authors would like to thank the following members of the IBM Research and Watson Assistant teams for their contributions and reviews of the notebook: Matt Arnold, Adam Benvie, Kyle Croutwater, Eric Wayne.
Copyright © 2021 IBM. This notebook and its source code are released under the terms of the MIT License.