请按照以下提示解决使用watsonx.aiRuntime 时可能遇到的常见问题。
排除AutoAI故障
- RAG 实验的AutoAI推断笔记本超出模型限制
- 使用服务 ID 凭证训练AutoAI实验失败
- AutoAI时间序列模型的预测请求可能因新观测数据过多而超时
- AutoAI实验训练数据中的类成员不足
- 无法从Cloud Pak for Data打开需要watsonx.ai的资产
排除部署故障
排除AutoAI故障
请按照以下提示解决使用AutoAI 时可能遇到的常见问题。
运行带有异常预测的AutoAI时间序列实验失败
不再支持预测时间序列实验结果异常的功能。 尝试运行现有实验时,会因缺少运行时库而出错。 例如,您可能会看到以下错误:
The selected environment seems to be invalid: Could not retrieve environment. CAMS error: Missing or invalid asset id
由于不支持异常预测的运行时间,这种行为在意料之中。 这个问题没有解决方法。
RAG 实验的AutoAI推断笔记本超出模型限制
有时,在运行为AutoAIRAG 实验生成的推理笔记时,可能会出现此错误:
MissingValue: No "model_limits" provided. Reason: Model <model-nam> limits cannot be found in the model details.
错误表示缺少用于推断实验所用基础模型的标记限值。 要解决问题,请找到函数 "default_inference_function,并将 "get_max_input_tokens替换为模型的最大标记。 例如:
model = ModelInference(api_client=client, **params['model"])
# model_max_input_tokens = get+max_input_tokens(model=model, params=params)
model_max_input_tokens = 4096
您可以在watsonx.ai 支持的基础模型表中找到模型的最大标记值。
使用服务 ID 凭证训练AutoAI实验失败
If you are training an AutoAI experiment using the API key for the serviceID, training might fail with this error:
User specified in query parameters does not match user from token.
解决这个问题的方法之一是使用用户凭据运行实验。 如果要使用服务凭据运行实验,请按照以下步骤更新服务 ID 的角色和策略。
- 打开您的 serviceID ,网址是 IBM Cloud。
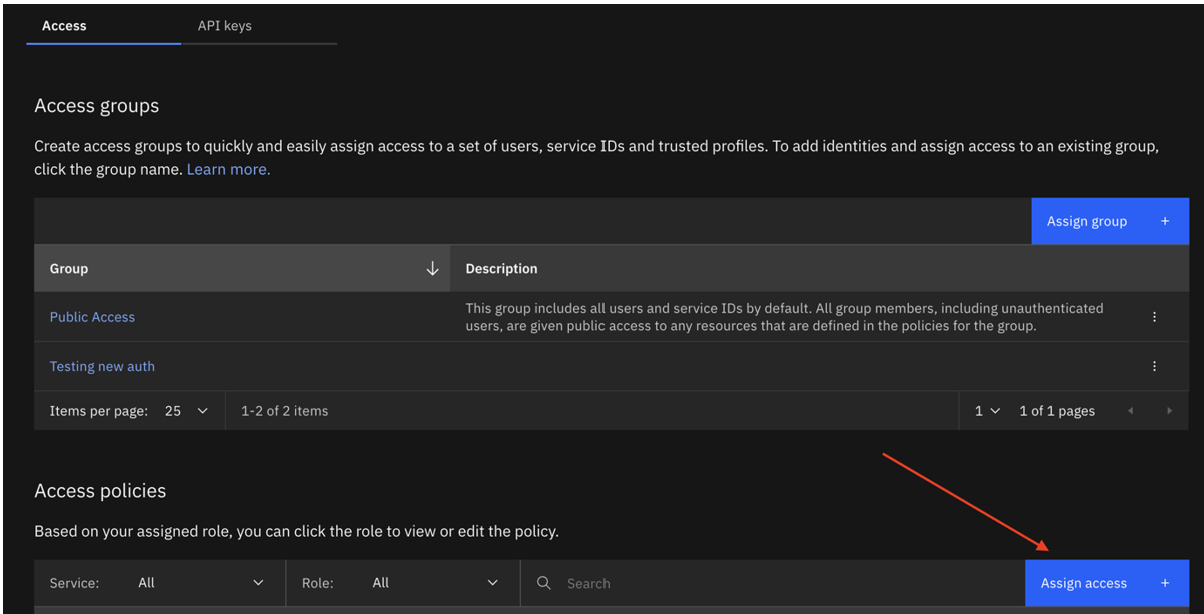
- 使用以下访问策略创建新的serviceID或更新现有 ID:
- 所有 IAM 账户管理服务,包括 API 密钥审核员、用户 API 密钥创建者、查看器、操作员和编辑器。 最好他们能为这个 ServiceId 创建一个新的apikey。
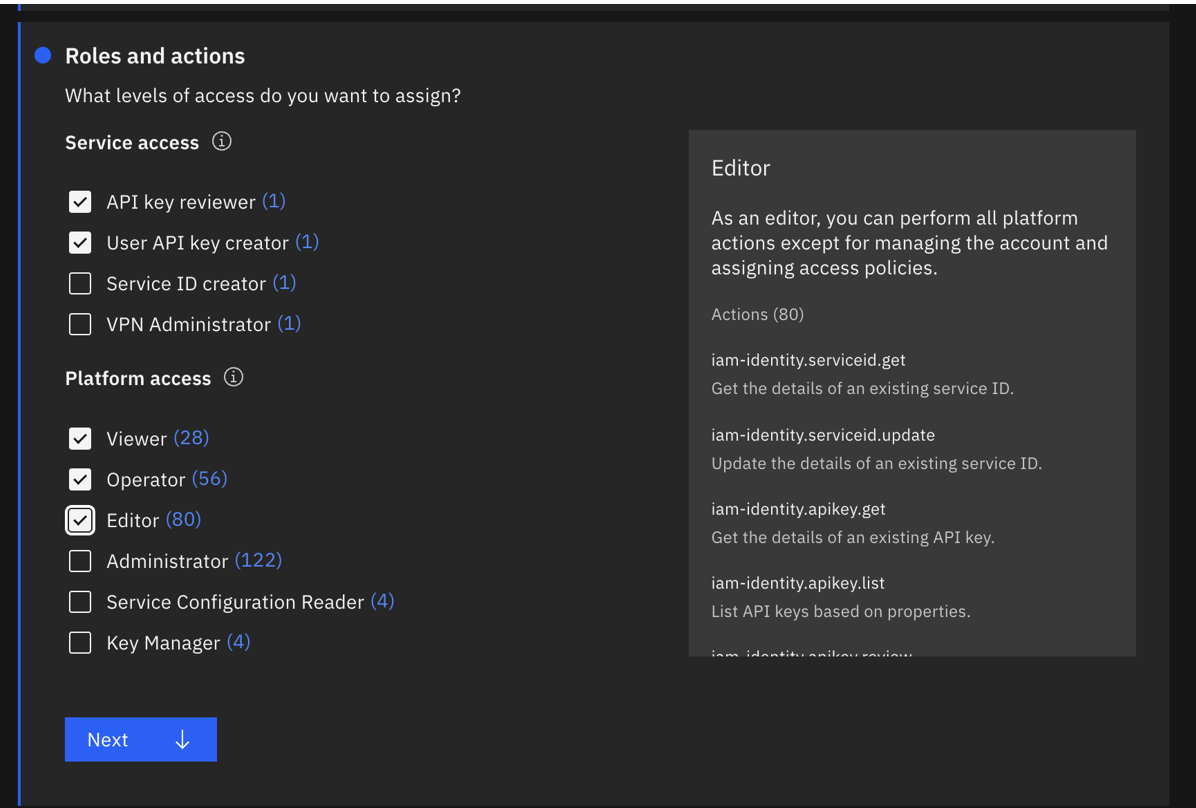
- 所有 IAM 账户管理服务,包括 API 密钥审核员、用户 API 密钥创建者、查看器、操作员和编辑器。 最好他们能为这个 ServiceId 创建一个新的apikey。
- 更新后的政策如下:
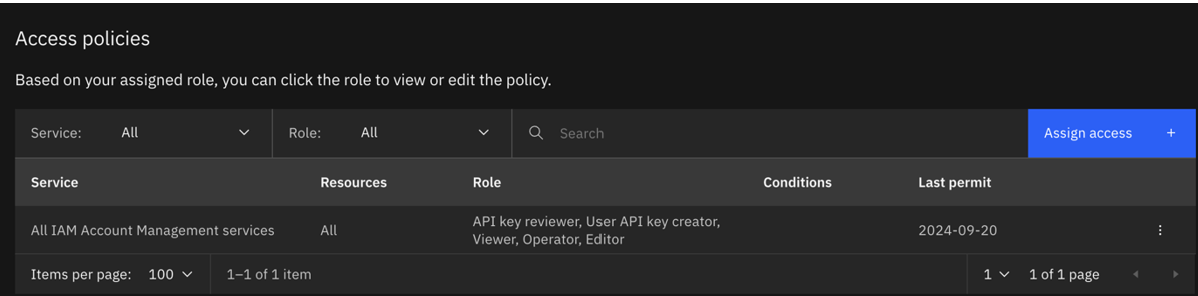
- 使用更新后的serviceID 凭据再次运行培训。
AutoAI时间序列模型的预测请求可能因新观测数据过多而超时
如果传递的新观测值过多,已部署的AutoAI时间序列模型的预测请求可能会超时。 要解决该问题,执行以下其中一个操作:
- 减少新观测数据的数量。
- 添加新的观测数据,扩展用于实验的训练数据。 然后,使用更新的训练数据重新运行AutoAI时间序列实验。
AutoAI 试验的训练数据中的类成员不足
AutoAI 试验的训练数据必须至少具有每个类的 4 个成员。 如果训练数据在类中的成员数不足,那么您将迂到以下错误:
ERROR: ingesting data Message id: AC10011E. Message: Each class must have at least 4 members. The following classes have too few members: ['T'].
要解决此问题,请更新训练数据以除去类或添加更多成员。
无法从Cloud Pak for Data打开需要watsonx.ai的资产
如果您在Cloud Pak for Data上下文中工作,则无法打开需要不同产品上下文的资产,例如watsonx.ai。 例如,如果使用watsonx.ai 为 RAG 模式创建AutoAI实验,则在Cloud Pak for Data上下文中无法打开该资产。 在AutoAI实验中,您可以从 "资产 "列表中查看训练类型。 您可以使用类型机器学习进行实验,但不能使用类型检索增强生成进行实验。
排除部署故障
请按照以下提示解决您在使用watsonx.aiRuntime 部署时可能遇到的常见问题。
使用大数据卷作为输入的批处理部署可能会失败
如果要对使用大量数据作为输入源的批处理作业进行评分,那么该作业可能会因内部超时设置而失败。 此问题的症状可能是类似于以下示例的错误消息:
Incorrect input data: Flight returned internal error, with message: CDICO9999E: Internal error occurred: Snowflake sQL logged error: JDBC driver internal error: Timeout waiting for the download of #chunk49(Total chunks: 186) retry=0.
如果对批处理部署进行评分时发生超时,那么必须配置数据源查询级别超时限制以处理长时间运行的作业。
数据源的查询级别超时信息如下所示:
| 数据源 | 查询级别时间限制 | 缺省时间限制 | 修改缺省时间限制 |
|---|---|---|---|
| Apache Cassandra | 是 | 10 秒 | 在Apache Cassandra配置文件或Apache Cassandra连接URL中设置 "read_timeout_in_ms和 "write_timeout_in_ms参数,以更改默认时限。 |
| Cloud Object Storage | False | 不适用 | 不适用 |
| Db2 | 是 | 不适用 | 设置 QueryTimeout 参数以指定客户机在尝试取消执行并将控制权返回给应用程序之前等待查询执行完成的时间量 (以秒计)。 |
| Hive via Execution Engine for Hadoop | 是 | 60 分钟 (3600 秒) | 在连接URL中设置 "hive.session.query.timeout属性,更改默认时限。 |
| Microsoft SQL Server | 是 | 30 秒 | 设置 QUERY_TIMEOUT 服务器配置选项以更改缺省时间限制。 |
| MongoDB | 是 | 30 秒 | 在查询选项中设置 maxTimeMS 参数以更改缺省时间限制。 |
| MySQL | 是 | 0 秒 (无缺省时间限制) | 在连接URL或JDBC驱动程序属性中设置 "timeout属性,为查询指定时间限制。 |
| Oracle | 是 | 30 秒 | 在 Oracle JDBC 驱动程序中设置 QUERY_TIMEOUT 参数,以指定查询在自动取消之前可以运行的最大时间量。 |
| PostgreSQL | False | 不适用 | 设置 queryTimeout 属性以指定查询可以运行的最大时间量。 queryTimeout 属性的缺省值为 0。 |
| Snowflake | 是 | 6 小时 | 设置 queryTimeout 参数以更改缺省时间限制。 |
要避免批处理部署失败,请对数据集进行分区或减小其大小。
文件上载的安全性
您通过watsonx.aiStudio或watsonx.aiRuntime用户界面上传的文件不会被验证或扫描为潜在恶意内容。 建议您在上载之前对所有文件运行安全软件 (例如防病毒应用程序) ,以确保内容的安全性。
升级后,软件规格受限的部署会失败
如果您升级到最新版本的IBM Cloud Pak for Data,并部署在 FIPS 模式下使用受限软件规范创建的 R Shiny 应用程序资产,您的部署将失败。
例如,从IBM Cloud Pak for Data版本4.7.0升级到4.8.4或更高版本后,使用 "shiny-r3.6和 "shiny-r4.2软件规格的部署会失败。 您可能会收到错误消息Error 502 - Bad Gateway。
为了防止部署失败,请更新已部署资产的受限规范以使用最新的软件规范。 有关更多信息,请参阅管理过时的软件规范或框架。 如果您不再需要应用程序部署,您也可以删除它。
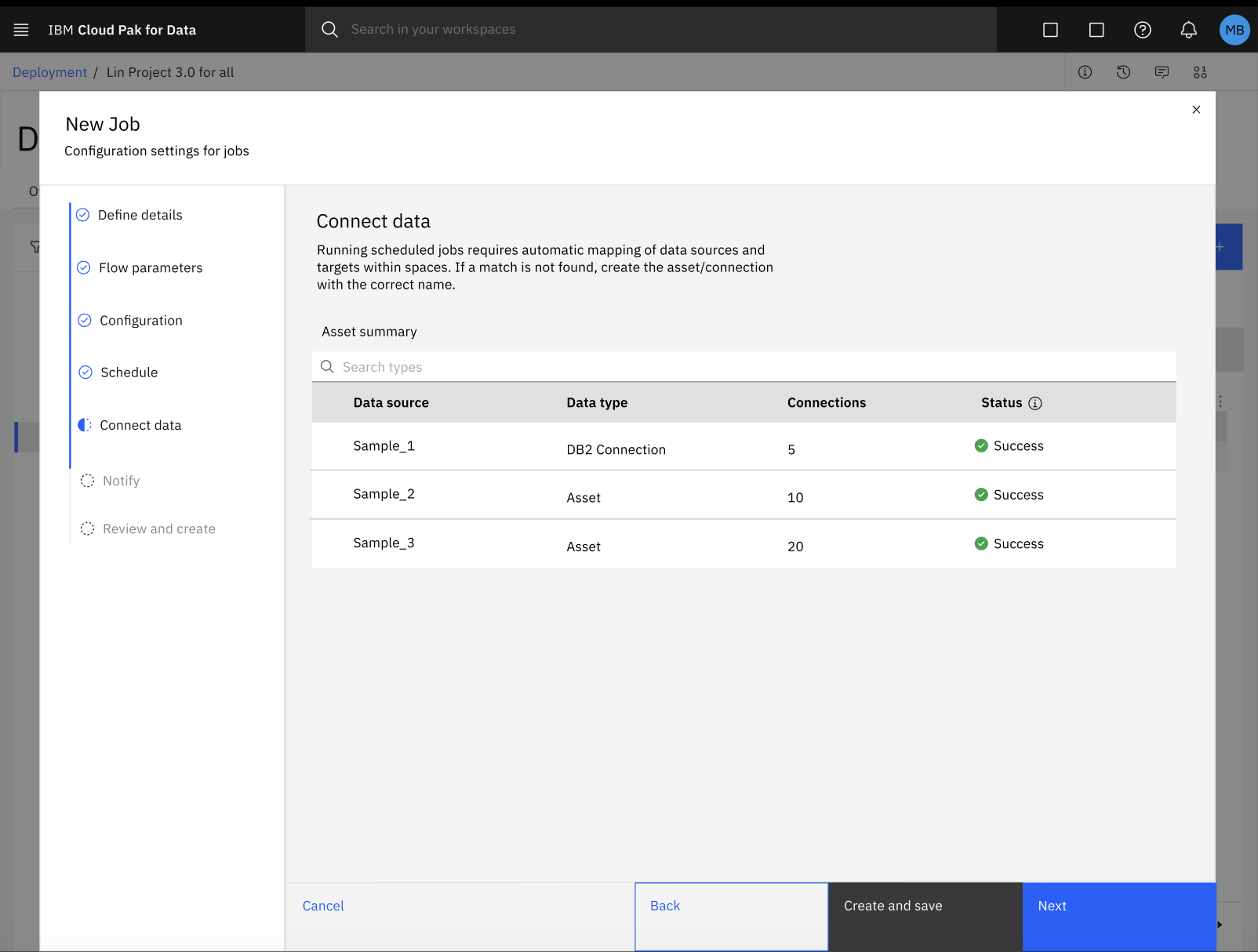
在部署空间中为SPSS Modeler流程创建作业失败
在为部署空间中的SPSS Modeler流程配置批处理作业的过程中,数据资产与其各自连接的自动映射可能会失败。
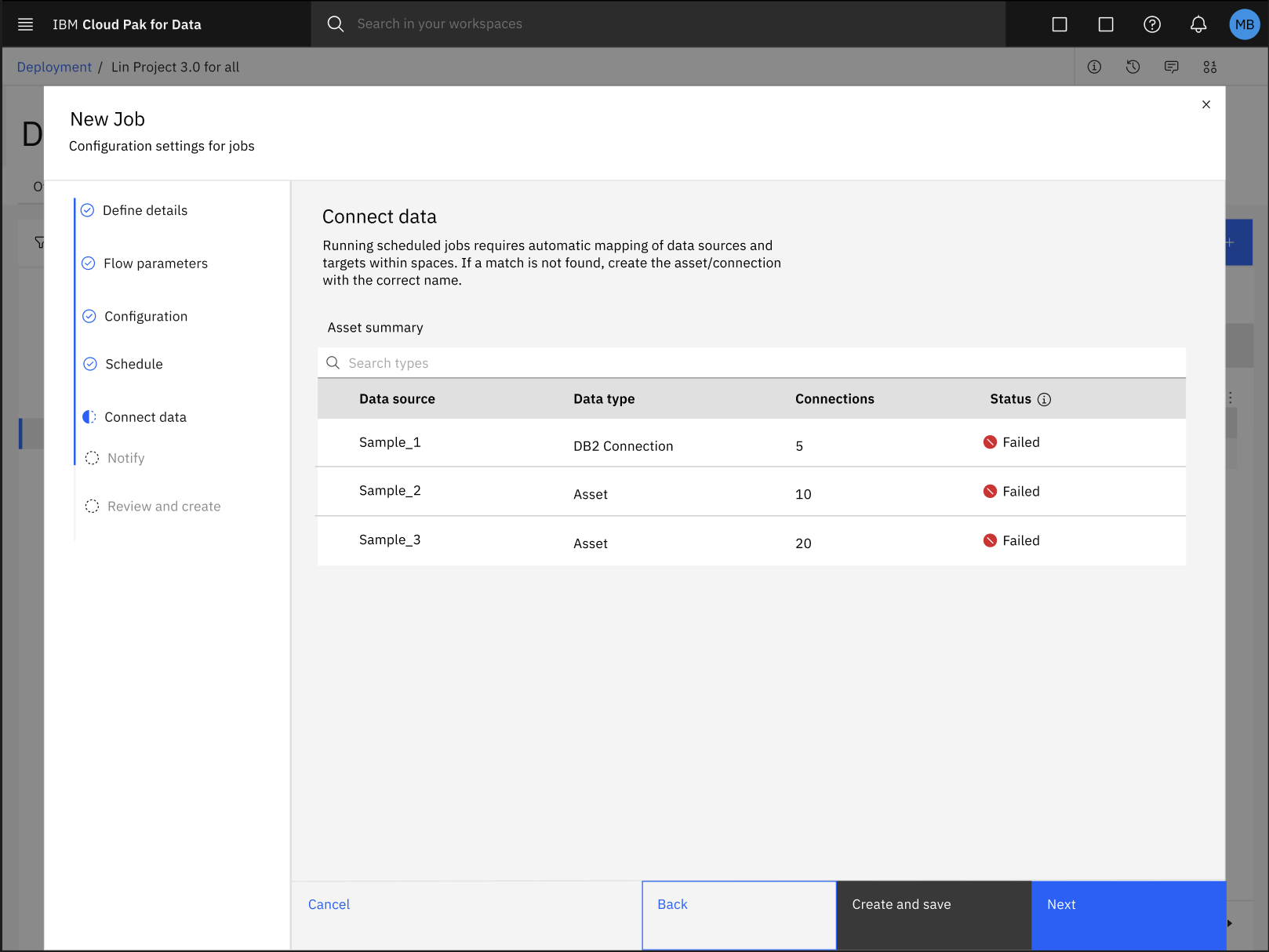
要修复数据资产和连接的自动映射错误,请按照以下步骤操作:
单击创建保存进度并退出新任务配置对话框。
在部署空间中,单击 "作业"选项卡,选择SPSS Modelerflow 作业,查看作业的详细信息。
在“工作详情”页面中,点击 “编辑”图标
 ,手动更新您的数据资产和连接的映射。
,手动更新您的数据资产和连接的映射。更新数据资产和连接的映射后,您可以继续在新任务对话框中配置任务设置。 有关更多信息,请参阅为SPSS Modeler流程创建部署作业
将模型从 LightGBM 转换为ONNX失败
如果您使用不受支持的客观函数将 LightGBM 模型转换为ONNX格式,您的部署可能会失败。 例如,如果在 lightgbm.Booster 定义中使用不支持的目标函数,可能会导致转换问题。
为了解决这个问题,在将 LightGBM 模型转换为ONNX时,请确保使用受支持的客观函数。
以下代码示例展示了如何用与 convert_lightgbm 兼容的函数替换 lightgbm.Booster 定义中不支持的目标函数。
lgb_model = lightgbm.Booster(model_str=lgb_model.model_to_string().replace('<unsupported_objective_function>', '<compatible_objective_function>'))
由于任务凭证被删除,部署作业失败
为了增强安全性,创建部署和运行作业需要任务凭证。 如果您在删除任务凭证后运行部署作业,由于无法使用API令牌更新平台作业服务中的作业状态,因此部署或作业状态将保持为中间状态。
因此,运行时容器将无法生成用户令牌,导致作业无限期停留在 running 状态。
要解决这个问题,您必须重新创建之前删除的任务凭证,并删除处于中间状态的现有部署或作业。