以下のヒントに従って、watsonx.aiランタイムを使用する際に遭遇する可能性のある一般的な問題を解決してください。
watsonx.aiランタイムサービスインスタンスのトラブルシューティング
AutoAIのトラブルシューティング
- RAG実験のAutoAI推論ノートブックがモデルの限界を超える
- AutoAI実験のトレーニングがサービス ID 認証情報で失敗する
- AutoAI時系列モデルの予測要求が、新しい観測値が多すぎるとタイムアウトすることがある。
- AutoAI実験の学習データにクラスメンバーが足りない
- watsonx.aiを必要とするCloud Pak for Dataのアセットを開くことができません。
デプロイのトラブルシューティング
watsonx.aiランタイムサービスインスタンスのトラブルシューティング
以下のヒントに従って、watsonx.aiRuntime サービスインスタンスを操作する際に遭遇する可能性のある一般的な問題を解決してください。
非アクティブなwatsonx.aiランタイムインスタンス
症状
Prompt Labの[生成]ボタンをクリックしてfoundation modelモデルに推論要求を送信しようとすると、以下のエラーメッセージが表示されます:
'code': 'no_associated_service_instance_error',
'message': 'WML instance {instance_id} status is not active, current status: Inactive'
考えられる原因
watsonx.aiプロジェクトと関連するwatsonx.aiRuntime サービスインスタンスとの関連付けが失われました。
考えられる解決策
watsonx.aiプロジェクトと関連するwatsonx.aiRuntime サービスインスタンス間の関連付けを再作成または更新します。 これを行うには、以下のステップを実行します。
- メインメニューから、Projectsを展開し、View all projectsをクリックします。
- watsonx.aiプロジェクトをクリックします。
- 管理]タブで[サービスと統合]をクリックします。
- 該当するwatsonx.aiRuntime サービスインスタンスが表示されている場合は、インスタンスを選択し、[削除] をクリックして一時的に関連付けを解除します。 削除を確認する。
- Associate serviceをクリックします。
- リストから適切なwatsonx.aiRuntime サービスインスタンスを選択し、「Associate」をクリックします。
AutoAIのトラブルシューティング
AutoAIを使用する際に遭遇する可能性のある一般的な問題を解決するためのヒントをご覧ください。
異常予測を伴うAutoAIの時系列実験の実行は失敗する
時系列実験結果の異常値を予測する機能はサポートされなくなりました。 既存の実験を実行しようとすると、ランタイムライブラリが見つからないというエラーが発生します。 例えば、こんなエラーが表示されるかもしれない:
The selected environment seems to be invalid: Could not retrieve environment. CAMS error: Missing or invalid asset id
異常予測のランタイムはサポートされていないため、この動作は予想される。 この問題の回避策はない。
RAG実験のAutoAI推論ノートブックがモデル限界を超える
AutoAIRAG実験用に生成された推論ノートブックを実行すると、このようなエラーが発生することがあります:
MissingValue: No "model_limits" provided. Reason: Model <model-nam> limits cannot be found in the model details.
このエラーは、実験に使用されたfoundation modelを推論するためのトークンリミットが欠落していることを示している。 問題を解決するには、関数'default_inference_functionを見つけ、'get_max_input_tokensをモデルの最大トークンで置き換える。 例:
model = ModelInference(api_client=client, **params['model"])
# model_max_input_tokens = get+max_input_tokens(model=model, params=params)
model_max_input_tokens = 4096
そのモデルのトークンの最大値は、watsonx.ai で利用可能なサポートされている基礎モデルの表で見つけることができます。
AutoAI実験のトレーニングがサービス ID 認証情報で失敗する
serviceID,の API キーを使用してAutoAI実験をトレーニングする場合、このエラーでトレーニングに失敗することがあります:
User specified in query parameters does not match user from token.
この問題を解決する一つの方法は、ユーザー認証情報を使って実験を実行することである。 サービスの認証情報を使って実験を実行したい場合は、以下の手順に従ってサービス ID のロールとポリシーを更新してください。
- serviceID を IBM Cloud で開きます。
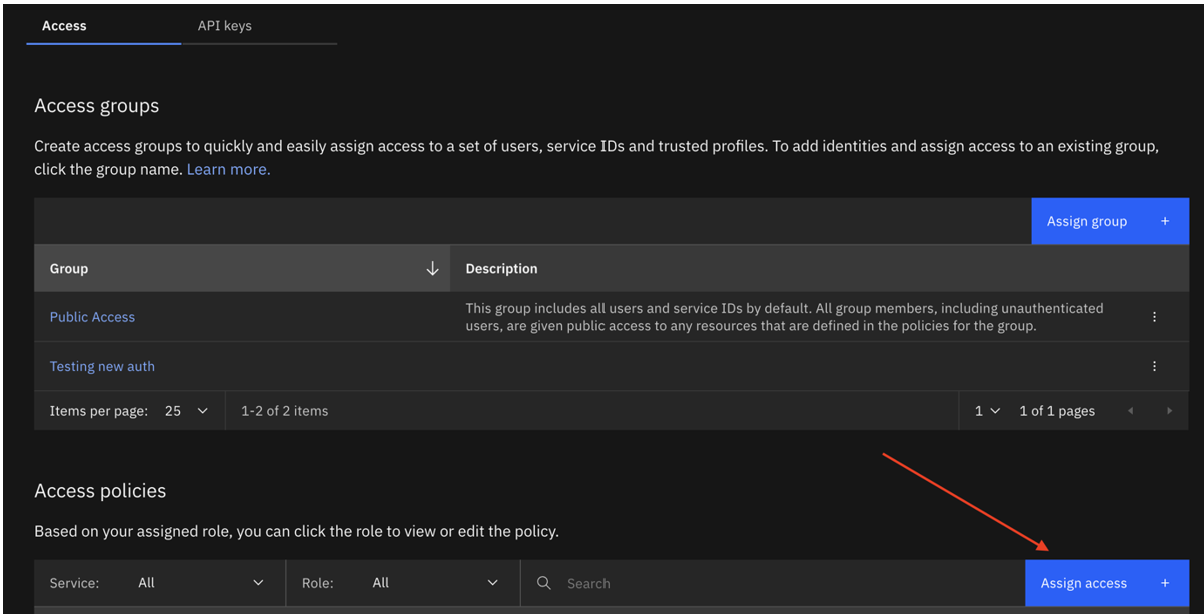
- 新しいserviceIDを作成するか、既存のIDを以下のアクセスポリシーで更新する:
- APIキーのレビュアー、ユーザーAPIキーの作成者、ビュアー、オペレーター、エディターの役割を持つすべてのIAMアカウント管理サービス。 理想的には、この ServiceId 用に新しいAPIキーを作成してもらうのが一番です。
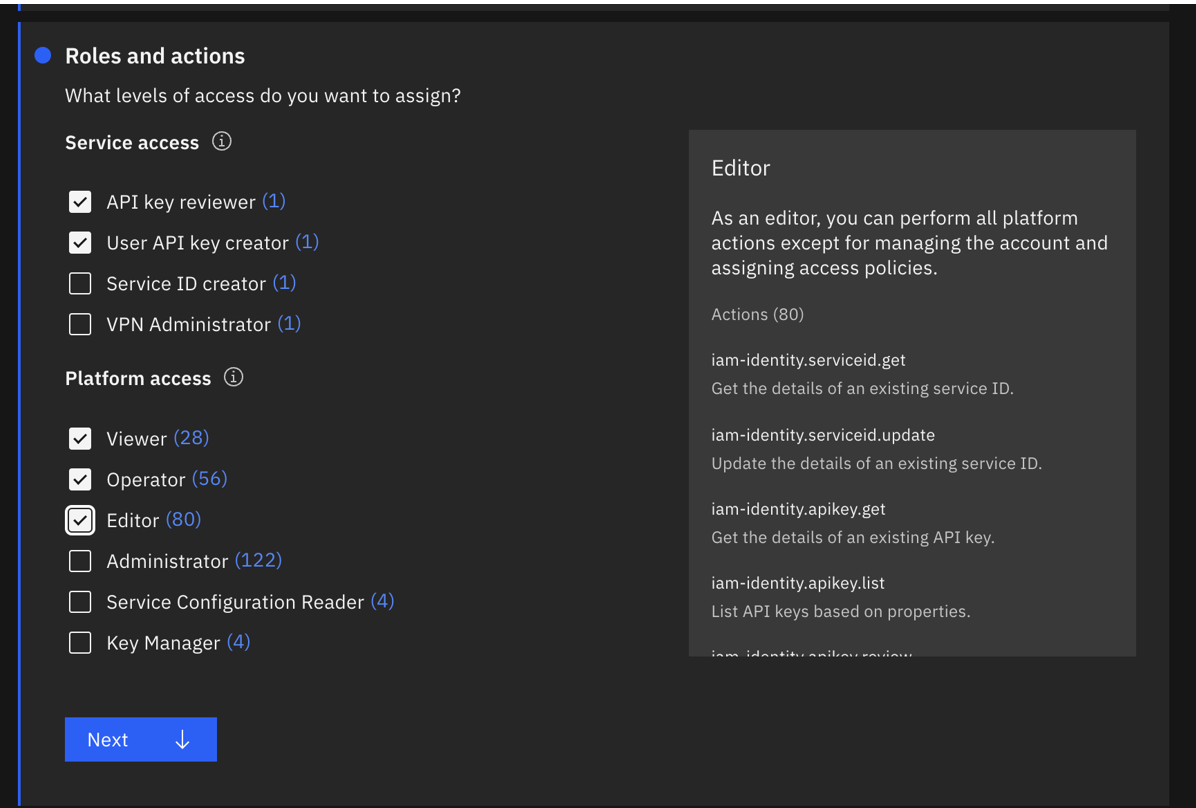
- APIキーのレビュアー、ユーザーAPIキーの作成者、ビュアー、オペレーター、エディターの役割を持つすべてのIAMアカウント管理サービス。 理想的には、この ServiceId 用に新しいAPIキーを作成してもらうのが一番です。
- 更新後のポリシーは以下のようになります。
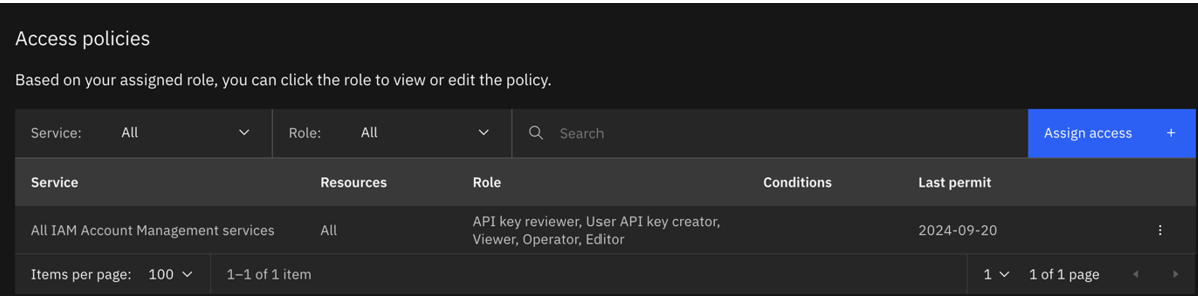
- 更新されたserviceIDの認証情報を使用してトレーニングを再度実行します。
AutoAI時系列モデルの予測要求が、新しい観測値が多すぎるとタイムアウトすることがある
新しいオブザベーションの数が多すぎると、デプロイされたAutoAI時系列モデルの予測要求がタイムアウトすることがあります。 この問題を解決するには、次のいずれかを実行します。
- 新しい観測の数を減らす。
- 新しいオブザベーションを追加して、実験に使用するトレーニング・データを拡張する。 次に、更新されたトレーニングデータを使ってAutoAIの時系列実験を再実行する。
AutoAI エクスペリメントのトレーニング・データ内のクラス・メンバーが不足しています
AutoAI エクスペリメントのトレーニング・データには、クラスごとに少なくとも 4 つのメンバーが必要です。 トレーニング・データのクラス内のメンバー数が不足している場合は、以下のエラーが発生します。
ERROR: ingesting data Message id: AC10011E. Message: Each class must have at least 4 members. The following classes have too few members: ['T'].
この問題を解決するには、トレーニング・データを更新してクラスを削除するか、さらにメンバーを追加します。
watsonx.aiを必要とするCloud Pak for Dataのアセットを開くことができません
Cloud Pak for Dataコンテキストで作業している場合、watsonx.ai などの別の製品コンテキストを必要とするアセットを開くことはできません。 例えば、watsonx.aiを使用して RAG パターンのAutoAI実験を作成した場合、Cloud Pak for Dataコンテキストではそのアセットを開くことはできません。 AutoAI実験の場合、アセットリストからトレーニングタイプを見ることができる。 タイプ機械学習で実験を開始することはできるが、タイプ検索機能付き生成で実験を開始することはできない。
デプロイのトラブルシューティング
以下のヒントに従って、watsonx.aiRuntime のデプロイメントで遭遇する可能性のある一般的な問題を解決してください。
大量のデータ・ボリュームを入力として使用するバッチ・デプロイメントが失敗することがある
大量のデータを入力ソースとして使用するバッチ・ジョブをスコアリングする場合、内部タイムアウト設定のためにジョブが失敗する可能性があります。 この問題の症状として、以下の例のようなエラー・メッセージが考えられます。
Incorrect input data: Flight returned internal error, with message: CDICO9999E: Internal error occurred: Snowflake sQL logged error: JDBC driver internal error: Timeout waiting for the download of #chunk49(Total chunks: 186) retry=0.
バッチ・デプロイメントのスコアリング時にタイムアウトが発生した場合は、長時間実行されるジョブを処理するようにデータ・ソース照会レベルのタイムアウト制限を構成する必要があります。
データ・ソースの照会レベルのタイムアウト情報は、以下のとおりです。
| データ・ソース | 照会レベルの時間制限 | デフォルトの制限時間 | デフォルトの制限時間の変更 |
|---|---|---|---|
| Apache Cassandra | はい | 10 秒間 | Apache Cassandra 構成ファイルまたは Apache Cassandra 接続 URLで read_timeout_in_ms および write_timeout_in_ms パラメータを設定して、デフォルトの時間制限を変更します。 |
| Cloud Object Storage | いいえ | 該当なし | 該当なし |
| Db2 | はい | 該当なし | QueryTimeout パラメーターを設定して、クライアントが照会の実行の完了を待機する時間 (秒単位) を指定します。この時間を過ぎると、クライアントは実行を取り消してアプリケーションに制御を戻そうとします。 |
| Hive via Execution Engine for Hadoop | はい | 60 分 (3600 秒) | デフォルトの制限時間を変更するには、接続 URLに hive.session.query.timeout プロパティを設定します。 |
| Microsoft SQL Server | はい | 30 秒間 | QUERY_TIMEOUT サーバー構成オプションを設定して、デフォルトの時間制限を変更します。 |
| MongoDB | はい | 30 秒間 | デフォルトの時間制限を変更するには、照会オプションで maxTimeMS パラメーターを設定します。 |
| MySQL | はい | 0 秒 (デフォルトの制限時間なし) | 接続 URL または JDBC ドライバのプロパティで timeout プロパティを設定し、クエリの時間制限を指定します。 |
| Oracle | はい | 30 秒間 | Oracle JDBC ドライバーで QUERY_TIMEOUT パラメーターを設定して、照会が自動的にキャンセルされるまでに実行できる最大時間を指定します。 |
| PostgreSQL | いいえ | 該当なし | queryTimeout プロパティーを設定して、照会を実行できる最大時間を指定します。 queryTimeout プロパティーのデフォルト値は 0です。 |
| Snowflake | はい | 6 時間 | queryTimeout パラメーターを設定して、デフォルトの時間制限を変更します。 |
バッチ・デプロイメントが失敗しないようにするには、データ・セットを区分するか、そのサイズを小さくします。
ファイル・アップロードのセキュリティー
watsonx.aiStudio またはwatsonx.aiRuntime UI 経由でアップロードしたファイルは、悪意のある可能性のあるコンテンツについて検証またはスキャンされません。 コンテンツのセキュリティーを確保するために、アップロードの前にすべてのファイルに対してアンチウィルス・アプリケーションなどのセキュリティー・ソフトウェアを実行することをお勧めします。
制限されたソフトウェア仕様での展開はアップグレード後に失敗する
IBM Cloud Pak for DataData の最新バージョンにアップグレードし、FIPS モードで制約付きソフトウェア仕様を使用して作成された R Shiny アプリケーション資産をデプロイすると、デプロイに失敗します。
たとえば、IBM Cloud Pak for Dataバージョン4.7.0から4.8.4以降にアップグレードすると、'shiny-r3.6および 'shiny-r4.2ソフトウェア仕様を使用するデプロイメントが失敗します。 エラーメッセージが表示される場合がありますError 502 - Bad Gateway。
デプロイメントが失敗しないようにするには、デプロイされた資産の制限された仕様を更新して、最新のソフトウェア仕様を使用します。 詳細については、「古いソフトウェア仕様またはフレームワークの管理」を参照してください。 不要になった場合は、アプリケーションのデプロイメントを削除することもできます。
配置スペースでのSPSS Modelerフローのジョブの作成に失敗する
配置スペースでSPSS Modelerフローのバッチジョブを構成する過程で、データ資産とそれぞれの接続の自動マッピングに失敗することがあります。
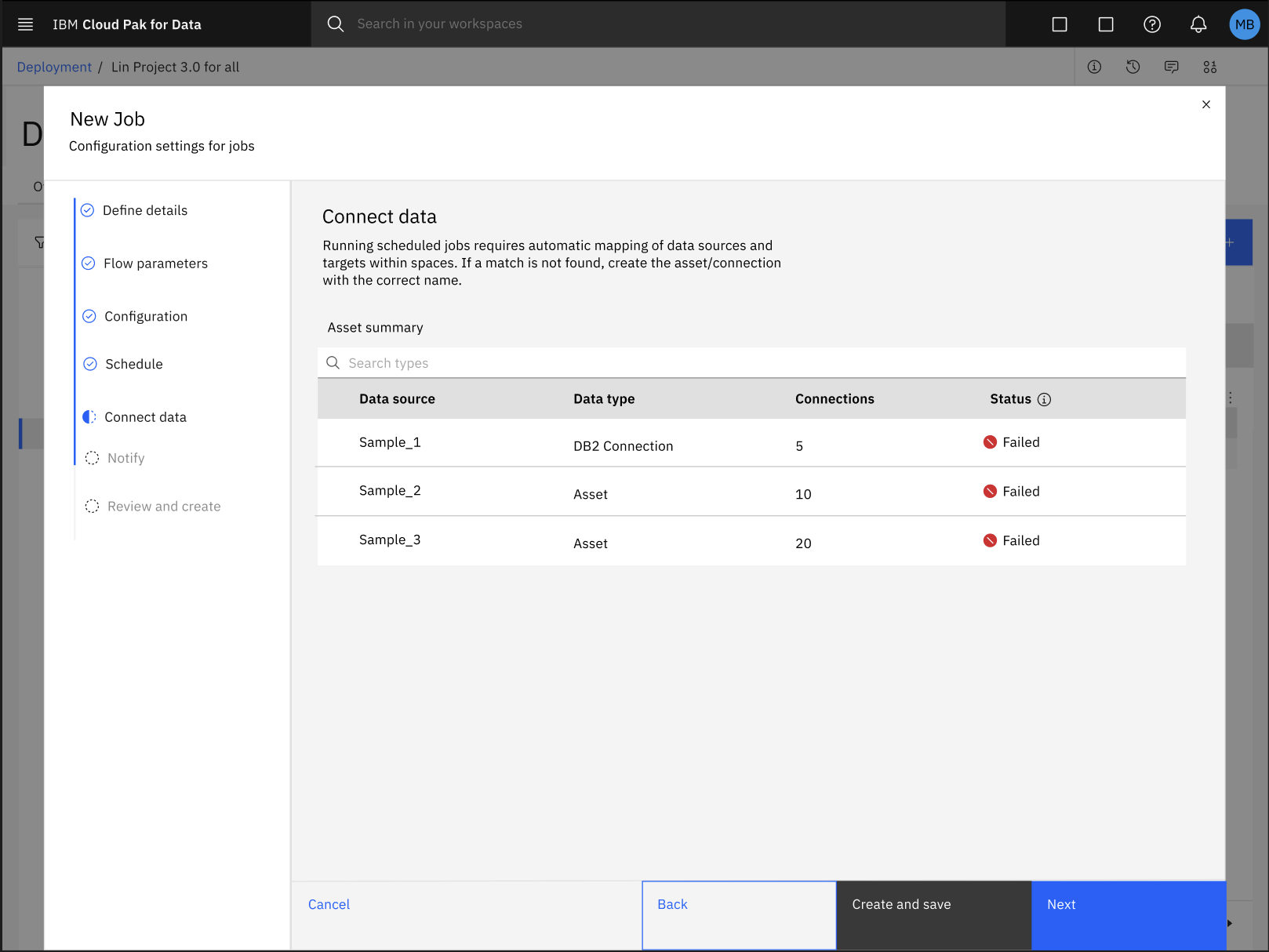
データ資産と接続の自動マッピングのエラーを修正するには、以下の手順に従ってください:
作成をクリックして進行状況を保存し、'新しい仕事設定ダイアログボックスから抜けます。
展開スペースで、ジョブタブをクリックし、SPSS Modelerフロージョブを選択して、ジョブの詳細を確認します。
In the job details page, click the 編集 icon
 to manually update the mapping of your data assets and connections.
to manually update the mapping of your data assets and connections.データ資産と接続のマッピングを更新した後、[新規ジョブ]ダイアログボックスでジョブの設定プロセスを再開できます。 詳細については、 SPSS Modelerフローの展開ジョブの作成を参照してください
配置スペースからのカスタムfoundation modelの配置に失敗する
配置スペースからカスタムfoundation modelの配置を作成する場合、さまざま な理由で配置が失敗する可能性があります。 以下のヒントに従って、配置スペースからカスタム ファウンデーション モデルを 配置するときに発生する可能性のある一般的な問題を解決してください。
ケース1:パラメータ値が範囲外である
配置スペースからカスタムfoundation modelの配置を作成する場合、基本モデルのパラ メータ値が指定された範囲内にあることを確認する必要があります。 詳細については、カスタム基礎モデルのプロパティとパラメータを参照してください。 指定された範囲を超える値を入力すると、エラーが発生することがあります。
例えば、'max_new_tokensパラメータの値は、'max_sequence_length よりも小さくなければならない。 ベースモデルのパラメータ値を更新する際、「max_new_tokens」に「max_sequence_length」の値(2048)以上の値を入力すると、エラーが発生することがあります。
次の画像はエラーメッセージの例である: Value must be an integer between 20 and 1000000000000000 and be greater than 'Max New Tokens'.
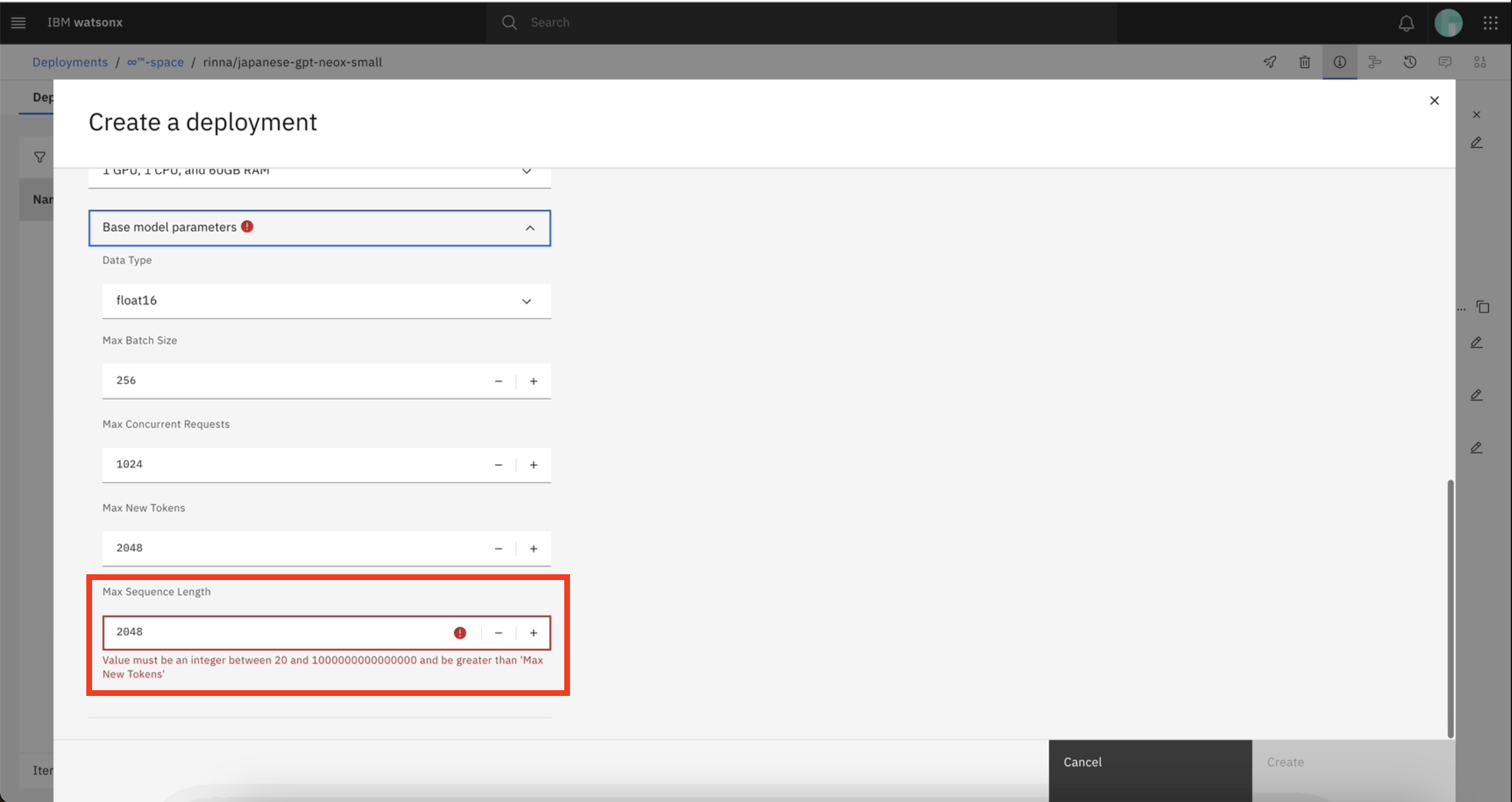
モデル・パラメーターのデフォルト値がエラーになる場合は、管理者に連絡して watsonxaiifm CR 内のモデルのレジストリを変更してください。
ケース2:サポートされていないデータ型
カスタム・foundation modelでサポートされているデータ型を選択する必要があります。 ベースモデルのパラメータ値を更新する際に、デプロイ済みモデルのデータ型をサポートされていないデータ型で更新すると、デプロイに失敗することがあります。
例えば、'LLaMA-Pro-8B-Instruct-GPTQモデルは'float16データ型のみをサポートする。 LLaMA-Pro-8B-Instruct-GPTQモデルを'float16'Enumでデプロイし、'Enumパラメータを'float16から'bfloat16に更新すると、デプロイは失敗します。
カスタムfoundation modelモデルに選択したデータ型がエラーになる場合は、配置の作成時にカスタムfoundation modelのデータ型を上書きするか、管理者に連絡して watsonxaiifm CR 内のモデルのレジストリを変更してください。
ケース3:パラメータ値が大きすぎる
パラメータ「max_sequence_length」と「max_new_token」に非常に大きな値を入力すると、エラーが発生することがある。 例えば、'max_sequence_lengthの値を'1000000000000000とした場合、次のようなエラーメッセージが表示される:
カスタム・foundation modelのデプロイに失敗しました。 max_batch_weight (19596417433) が (prefill) max_sequence_length (10000000000000) に対して十分大きくないため、処理に失敗しました。 操作を再試行してください。 問題が解決しない場合は、IBM サポートに連絡してください。
モデル設定ファイル(config.json)で定義されている値よりも小さい値をパラメータに入力する必要があります。
ケース4:'model.safetensorsファイルがサポートされていないライブラリで保存されている。
foundation modelの「model.safetensorsファイルが、メタデータヘッダでサポートされていないデータ形式を使用している場合、デプロイメントに失敗する可能性があります。
たとえば、Hugging Faceから 'OccamRazor/mpt-7b-storywriter-4bit-128gカスタムfoundation modelをデプロイメント スペースにインポートし、オンライン デプロイメントを作成すると、デプロイメントが失敗する可能性があります。 これは、'OccamRazor/mpt-7b-storywriter-4bit-128gモデル用の'model.safetensorsファイルが、サポートされていないライブラリである'save_pretrainedと一緒に保存されているためである。 次のエラー・メッセージが返される場合があります。
'NoneType'オブジェクトに属性 'get' がないため、操作に失敗しました。
foundation modelがサポートされている'transformersライブラリで保存されていることを確認する必要があります。
ケース5:Llama 3.1モデルの導入に失敗
Llama 3.1モデルのデプロイに失敗したら、モデルの'config.jsonファイルの内容を編集してみてください:
eos_token_idエントリーを見つける。- エントリーの値を配列から整数に変更する。
その後、モデルを再配置してみてください。
オンデマンドで展開される基盤モデルは、 デプロイメント・スペースに展開できません
1 つの配置スペースに配置できるのは、デプロイ オン デマンドfoundation modelモデルのインスタンス 1 つだけです。 選択したモデルが既に配置されている場合、そのモデルが配置されている配置スペースは無効になります。
モデルにより多くのリソースが必要な場合は、デプロイメントをスケーリングすることで、デプロイされたモデル アセットのコピーを増やすことができます。
LightGBM からONNXへのモデル変換に失敗する
サポートされていない目的関数LightGBMをONNX形式に変換すると、 デプロイメントに失敗する可能性があります。 例えば、 lightgbm.Booster 定義でサポートされていない目的関数を使用すると、変換に問題が生じる可能性があります。
この問題を解決するには LightGBMをONNXに変換する際に、サポートされている目的関数を使用してください。
次のコードサンプルでは、 lightgbm.Booster 定義におけるサポートされていない目的関数を、 convert_lightgbm と互換性のある関数に置き換える方法を示しています。
lgb_model = lightgbm.Booster(model_str=lgb_model.model_to_string().replace('<unsupported_objective_function>', '<compatible_objective_function>'))
PytorchからONNXに変換したディープラーニングモデルをデプロイすると失敗する
When you create an online deployment for a deep learning model that was created in PyTorch and converted to ONNX format, your deployment fails. これは、モデルのバージョンと ONNX オペレータの間に不一致があることが原因である可能性があります。
次のエラー・メッセージが返される場合があります。
UserWarning: onnx-caffe2 のこのバージョンはONNXオペレータセットバージョン9を対象としていますが、インポートしようとしているモデルはバージョン17を使用しています。 とにかくインポートを試みますが、モデルがその間にBC非互換な変更が加えられた演算子を使用している場合、インポートは失敗します。
この問題を解決するには、モデルをエクスポートする際に正しいオペレータのバージョンを設定します。
次のコードサンプルは、正しいオペレータのバージョンを設定する方法を示しています
- torch.onnx.export(model, dummy_input, output_model_onnx, export_params=True)
+ torch.onnx.export(model, dummy_input, output_model_onnx, export_params=True, keep_initializers_as_inputs=True, opset_version=9)
エージェントをAIサービスとして展開すると失敗する
エージェントラボで、すべてのツールオプション(ベクトルインデックスを含む)を有効にしてエージェントを作成し、AIサービスを含むデプロイメントとして保存すると、 デプロイメントの作成に失敗します。
次のエラー・メッセージが返される場合があります。
デプロイメントの作成に失敗しました。 エラー:400。
この問題は、ノートブックで使用されている API キーが、タスク認証を持たない別のアカウントのものである場合に発生します。 APIキーはプロジェクトと同じアカウントのものでなければなりません。
この問題を解決するには、ノートブックで使用されている API キーがプロジェクトと同じアカウントのものであることを確認してください。 APIキーが異なるアカウントのものである場合は、正しいアカウントから新しいAPIキーを作成し、ノートブックを更新してください。