Acerca de las cookies de este sitio Nuestros sitios web necesitan algunas cookies para funcionar correctamente (necesarias). Además, se pueden utilizar otras cookies con su consentimiento para analizar el uso del sitio, para mejorar la experiencia del usuario y para publicidad. Para obtener más información, consulte sus opciones de. Al visitar nuestro sitio web, acepta que procesemos la información tal y como se describe en ladeclaración de privacidad de IBM. Para facilitar la navegación, sus preferencias de cookies se compartirán entre los dominios web de IBM que se muestran aquí.
Solución de problemas en tiempo de ejecución de watsonx.ai
Última actualización: 21 feb 2025
Siga estos consejos para resolver los problemas más comunes que puede encontrar al trabajar con watsonx.ai Runtime.
Solución de problemas AutoAI
- El cuaderno de inferencia deAutoAI para un experimento RAG supera los límites del modelo
- El entrenamiento de un experimento AutoAI falla con las credenciales de ID de servicio
- La solicitud de predicción para el modelo de series temporales AutoAI puede agotarse con demasiadas observaciones nuevas
- Insuficientes miembros de clase en los datos de entrenamiento para el experimento AutoAI
- No se pueden abrir activos de Cloud Pak for Data que requieren watsonx.ai
Solución de problemas de implantación
Las implantaciones por lotes que utilizan grandes volúmenes de datos como entrada podrían fallar
Las implantaciones con especificaciones de software restringidas fallan tras una actualización
Falla la creación de un trabajo para un flujo de SPSS Modeler en un espacio de despliegue
Solución de problemas AutoAI
Siga estos consejos para resolver los problemas más comunes que puede encontrar al trabajar con AutoAI.
Falla la ejecución de un experimento AutoAI de series temporales con predicción de anomalías
La función para predecir anomalías en los resultados de un experimento de series temporales ya no es compatible. Al intentar ejecutar un experimento existente se producen errores por falta de bibliotecas de tiempo de ejecución. Por ejemplo, puede aparecer este error:
The selected environment seems to be invalid: Could not retrieve environment. CAMS error: Missing or invalid asset id
Este comportamiento es el esperado, ya que no se admiten los tiempos de ejecución para la predicción de anomalías. No existe ninguna solución para este problema.
El cuaderno de inferencia de AutoAI para un experimento RAG supera los límites del modelo
A veces, al ejecutar un cuaderno de inferencia generado para un experimento RAG AutoAI, puede aparecer este error:
MissingValue: No "model_limits" provided. Reason: Model <model-nam> limits cannot be found in the model details.
El error indica que faltan los límites de token para inferir el modelo de base utilizado para el experimento. Para resolver el problema, busque la función " default_inference_functionget_max_input_tokens
model = ModelInference(api_client=client, **params['model"])
# model_max_input_tokens = get+max_input_tokens(model=model, params=params)
model_max_input_tokens = 4096
Puedes encontrar el valor máximo de token para el modelo en la tabla de modelos de fundación soportados disponibles con watsonx.ai.
El entrenamiento de un experimento AutoAI falla con las credenciales de ID de servicio
Si está entrenando un experimento AutoAI utilizando la clave API para el serviceID, el entrenamiento podría fallar con este error:
User specified in query parameters does not match user from token.
Una forma de resolver este problema es ejecutar el experimento con sus credenciales de usuario. Si desea ejecutar el experimento con credenciales para el servicio, siga estos pasos para actualizar las funciones y políticas para el ID de servicio.
- Abra su serviceID en IBM Cloud.
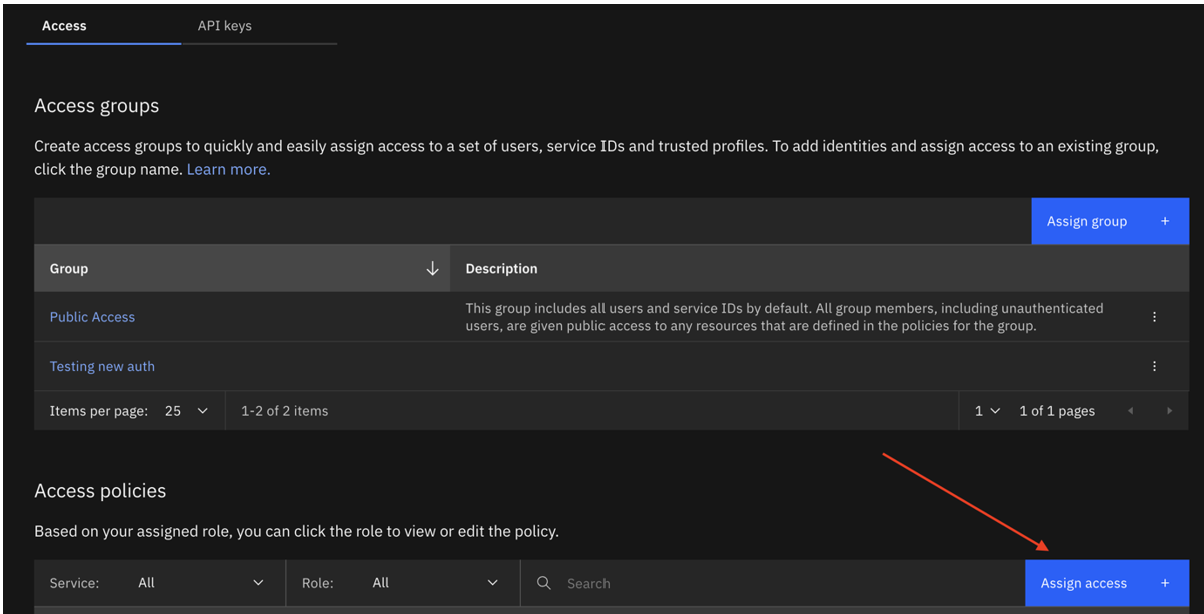
- Cree un nuevo serviceID o actualice el ID existente con la siguiente política de acceso:
- Todos los servicios de gestión de cuentas IAM con las funciones de revisor de claves API, creador de claves API de usuario, visualizador, operador y editor. Lo ideal es que creen una nueva clave de acceso para esta ServiceId.
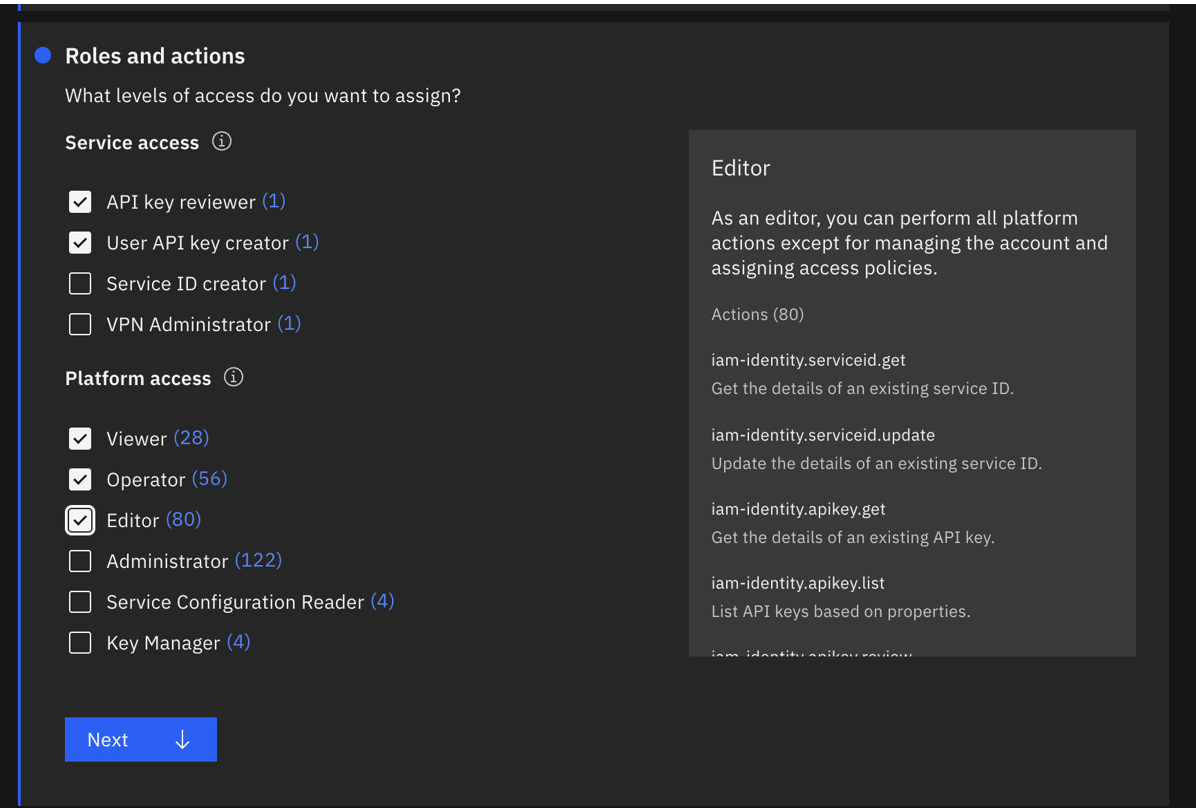
- Todos los servicios de gestión de cuentas IAM con las funciones de revisor de claves API, creador de claves API de usuario, visualizador, operador y editor. Lo ideal es que creen una nueva clave de acceso para esta ServiceId.
- La política actualizada tendrá el siguiente aspecto:
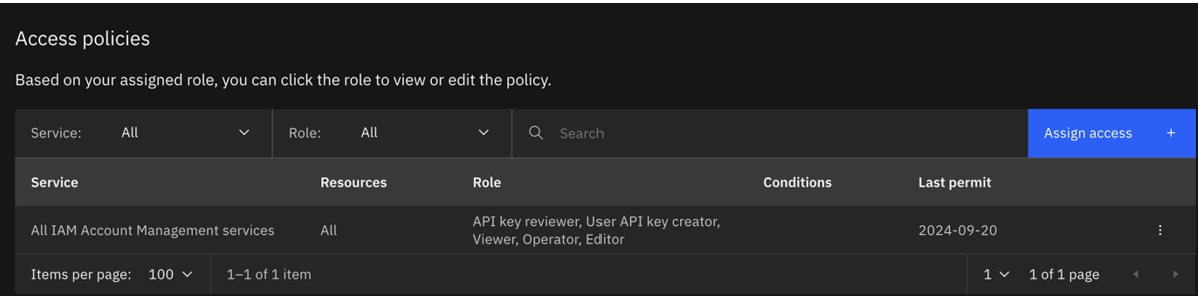
- Vuelva a ejecutar la formación con las credenciales para el serviceID actualizado.
La solicitud de predicción para el modelo de series temporales AutoAI puede agotarse con demasiadas observaciones nuevas
Una solicitud de predicción puede agotarse para un modelo de series temporales AutoAI desplegado si se pasan demasiadas observaciones nuevas. Para solucionar este problema, realice una de las siguientes acciones:
- Reducir el número de nuevas observaciones.
- Amplíe los datos de entrenamiento utilizados para el experimento añadiendo nuevas observaciones. A continuación, vuelva a ejecutar el experimento AutoAI de series temporales con los datos de entrenamiento actualizados.
Miembros de clase insuficientes en los datos de entrenamiento para el experimento AutoAI
Los datos de entrenamiento para un experimento de AutoAI deben tener al menos 4 miembros para cada clase. Si los datos de entrenamiento no tienen un número suficiente de miembros en una clase, se producirá este error:
ERROR: ingesting data Message id: AC10011E. Message: Each class must have at least 4 members. The following classes have too few members: ['T'].
Para resolver el problema, actualice los datos de entrenamiento para eliminar la clase o añadir más miembros.
No se pueden abrir activos de Cloud Pak for Data que requieren watsonx.ai
Si está trabajando en el contexto de Cloud Pak for Data, no podrá abrir activos que requieran un contexto de producto diferente, como watsonx.ai. Por ejemplo, si crea un experimento AutoAI para un patrón RAG utilizando watsonx.ai, no podrá abrir ese activo cuando se encuentre en el contexto Cloud Pak for Data. En el caso de los experimentos AutoAI, puede ver el tipo de entrenamiento en la lista de Activos. Puede abrir experimentos con aprendizaje automático de tipo, pero no con generación aumentada por recuperación de tipo.
Solución de problemas de implantación
Siga estos consejos para resolver los problemas más comunes que puede encontrar al trabajar con implementaciones de watsonx.ai Runtime.
Los despliegues por lotes que utilizan grandes volúmenes de datos como entrada pueden fallar
Si está puntuando un trabajo por lotes que utiliza grandes volúmenes de datos como origen de entrada, es posible que el trabajo falle debido a los valores de tiempo de espera interno. Un síntoma de este problema puede ser un mensaje de error similar al del ejemplo siguiente:
Incorrect input data: Flight returned internal error, with message: CDICO9999E: Internal error occurred: Snowflake sQL logged error: JDBC driver internal error: Timeout waiting for the download of #chunk49(Total chunks: 186) retry=0.
Si el tiempo de espera se produce al puntuar el despliegue por lotes, debe configurar la limitación de tiempo de espera de nivel de consulta de origen de datos para manejar trabajos de larga ejecución.
La información de tiempo de espera de nivel de consulta para orígenes de datos es la siguiente:
| Origen de datos | Limitación de tiempo de nivel de consulta | Límite de tiempo predeterminado | Modificar límite de tiempo predeterminado |
|---|---|---|---|
| Apache Cassandra | Sí | 10 segundos | Establezca los parámetros " |
| Cloud Object Storage | Nee | N/A | N/A |
| Db2 | Sí | N/A | Establezca el parámetro |
| Hive via Execution Engine for Hadoop | Sí | 60 minutos (3600 segundos) | Establezca la propiedad ' |
| Microsoft SQL Server | Sí | 30 segundos | Establezca la opción de configuración del servidor |
| MongoDB | Sí | 30 segundos | Establezca el parámetro |
| MySQL | Sí | 0 segundos (sin límite de tiempo predeterminado) | Establezca la propiedad ' |
| Oracle | Sí | 30 segundos | Establezca el parámetro |
| PostgreSQL | Nee | N/A | Establezca la propiedad |
| Snowflake | Sí | 6 horas | Establezca el parámetro |
Para evitar que los despliegues por lotes fallen, particione el conjunto de datos o disminuya su tamaño.
Seguridad para cargas de archivos
Files you upload through the watsonx.ai Studio or watsonx.ai Runtime UI are not validated or scanned for potentially malicious content. Se recomienda ejecutar software de seguridad, como una aplicación antivirus, en todos los archivos antes de cargarlos para garantizar la seguridad del contenido.
Las implementaciones con especificaciones de software restringidas fallan después de una actualización
Si actualiza a una versión más reciente de IBM Cloud Pak for Data e implementa un activo de aplicación R Shiny que se creó utilizando especificaciones de software restringidas en modo FIPS, el despliegue falla.
Por ejemplo, las implantaciones que utilizan especificaciones de software " shiny-r3.6shiny-r4.2Error 502 - Bad Gateway
Para evitar que su implementación falle, actualice la especificación restringida de su activo implementado para utilizar la especificación de software más reciente. Para obtener más información, consulte Gestión de marcos o especificaciones de software obsoletos. También puede eliminar la implementación de su aplicación si ya no la necesita.
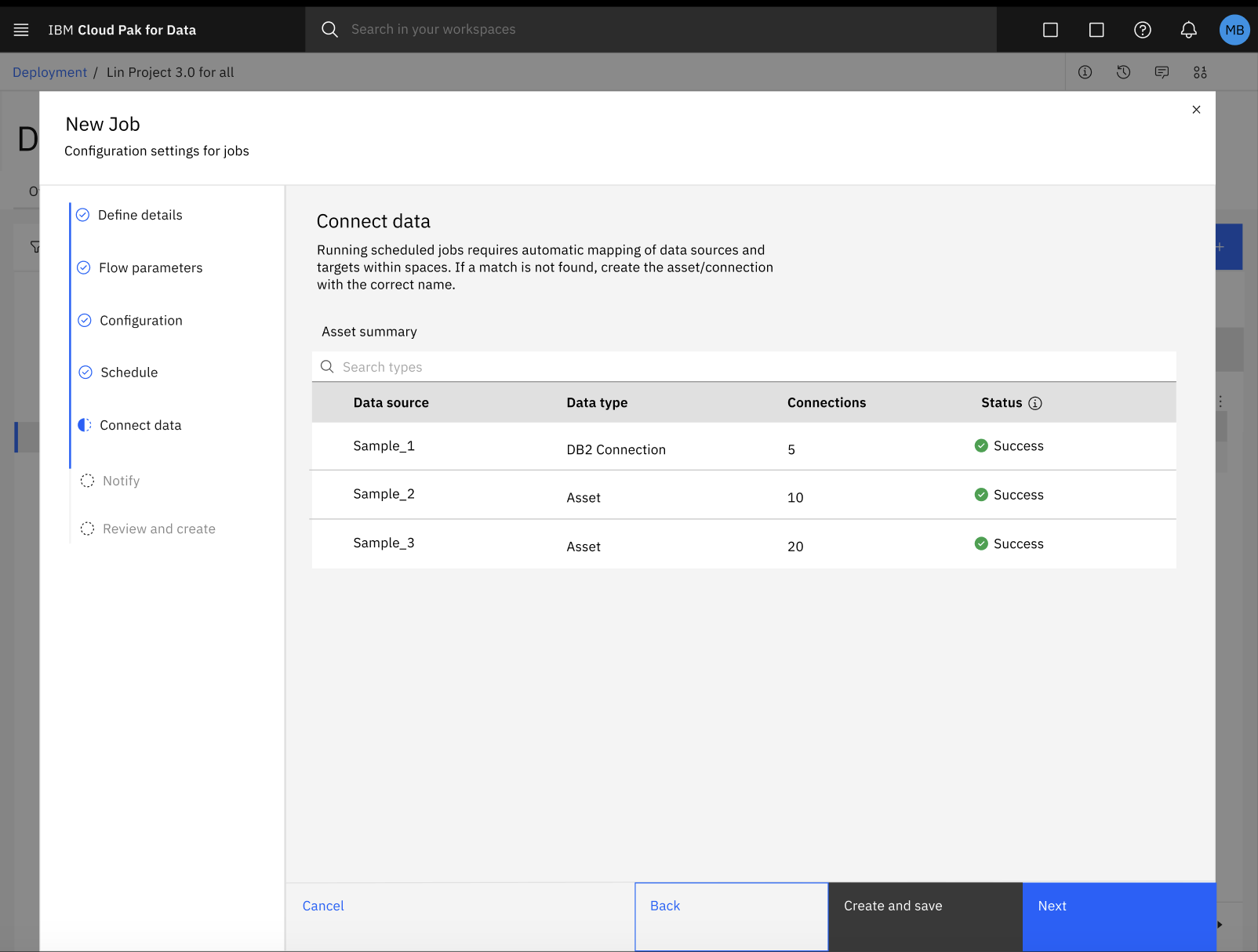
Falla la creación de un trabajo para un flujo de SPSS Modeler en un espacio de despliegue
Durante el proceso de configuración de un trabajo por lotes para su flujo de SPSS Modeler en un espacio de despliegue, puede fallar la asignación automática de activos de datos con su conexión respectiva.
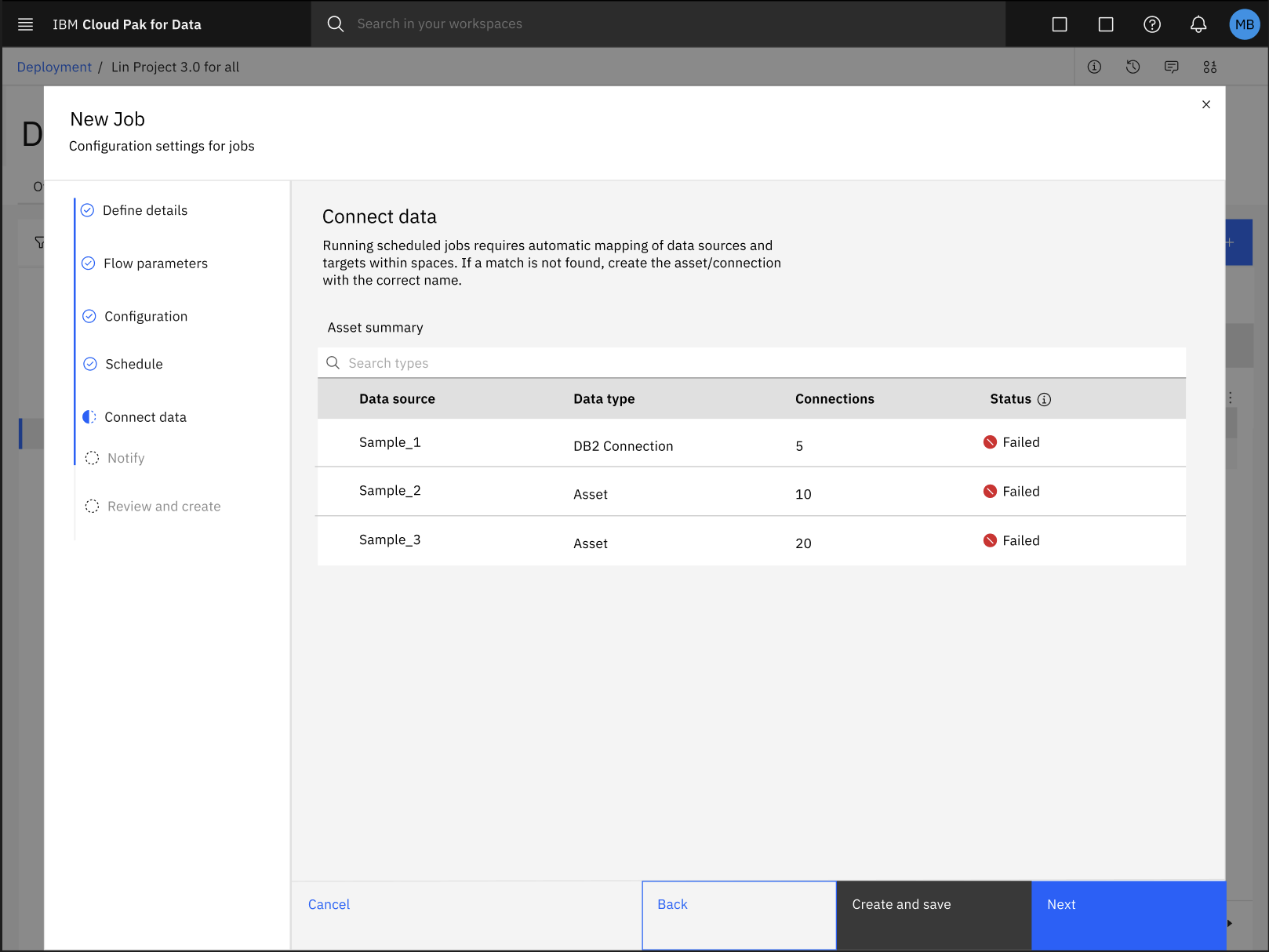
Para solucionar el error con la asignación automática de activos de datos y conexiones, siga estos pasos:
Haga clic en Crear para guardar su progreso y salir del cuadro de diálogo Configuración de nuevo trabajo.
En su espacio de despliegue, haga clic en la pestaña Trabajos y seleccione su trabajo de flujo de SPSS Modeler para revisar los detalles de su trabajo.
En la página de detalles del trabajo, haga clic en el icono Editar
 para actualizar manualmente la asignación de sus activos de datos y conexiones.
para actualizar manualmente la asignación de sus activos de datos y conexiones.Tras actualizar la asignación de los activos de datos y la conexión, puede reanudar el proceso de configuración del trabajo en el cuadro de diálogo Nuevo trabajo. Para obtener más información, consulte Creación de trabajos de despliegue para flujos de SPSS Modeler
Falla la conversión de un modelo de LightGBM a ONNX
Si utiliza una función objetivo no compatible para convertir sus modelos LightGBM al formato ONNX, su implantación podría fallar. Por ejemplo, si utiliza una función objetivo no compatible en la definición de lightgbm.Booster
Para resolver este problema, asegúrese de que utiliza una función objetivo compatible cuando convierta los modelos LightGBM a ONNX.
El siguiente ejemplo de código muestra cómo sustituir la función objetivo no compatible en la definición de lightgbm.Boosterconvert_lightgbm
lgb_model = lightgbm.Booster(model_str=lgb_model.model_to_string().replace('<unsupported_objective_function>', '<compatible_objective_function>'))
Se produce un error al ejecutar una tarea de implementación debido a que se han eliminado las credenciales de la tarea
Para mayor seguridad, se requieren credenciales de tareas para crear implementaciones y ejecutar trabajos. Si ejecuta un trabajo de implementación después de eliminar sus credenciales de tarea, el estado de la implementación o del trabajo permanece en un estado intermedio debido a la falta de disponibilidad del token de API, que es necesario para actualizar el estado del trabajo en el servicio de trabajos de la plataforma.
Como resultado, el pod de tiempo de ejecución no podrá generar un token de usuario, lo que provocará que el trabajo permanezca en el estado de " running
Para resolver este problema, debe volver a crear las credenciales de la tarea que eliminó anteriormente y eliminar la implementación o el trabajo existente que permanece en un estado intermedio.
¿Fue útil el tema?
0/1000