A continuación se muestran las respuestas a preguntas de resolución de problemas comunes sobre el uso de IBM Watson Machine Learning.
Obtener ayuda y soporte para Watson Machine Learning
Si tiene problemas o preguntas al utilizar Watson Machine Learning, puede obtener ayuda buscando información o formulando preguntas a través de un foro. También puede abrir una incidencia de soporte.
Cuando utilice los foros para formular una pregunta, etiquete la pregunta para que la vean los equipos de desarrollo de Watson Machine Learning .
Si tiene preguntas técnicas sobre Watson Machine Learning, publique su pregunta en Stack Overflow  y etiquete su pregunta con ibm-bluemix y machine-learning.
y etiquete su pregunta con ibm-bluemix y machine-learning.
Para formular preguntas sobre el servicio y obtener instrucciones de iniciación, utilice el foro IBM developerWorks dW Answers . Debe incluir las etiquetas machine-learning y bluemix .
Contenido
Falla el despliegue de un modelo de base personalizado desde un espacio de despliegue
El entrenamiento de un experimento AutoAI falla con las credenciales de ID de servicio
Falla la creación de un trabajo para un flujo SPSS Modeler en un espacio de despliegue
La señal de autorización y el instance_id que se han utilizado en la solicitud no son iguales
La clave pública necesaria para la autenticación no está disponible
Operación que ha excedido el tiempo de espera después de {{timeout}}
La base de datos subyacente ha notificado demasiadas solicitudes
No se ha encontrado el módulo de datos en IBM Federated Learning
La evaluación requiere una configuración de aprendizaje especificada para el modelo
La operación de parche sólo puede modificar la configuración de aprendizaje existente
La operación de parche espera exactamente una operación de sustitución
A la carga útil le faltan los campos necesarios: FIELD o los valores de los campos están dañados
El método de evaluación proporcionado: METHOD no se soporta. Valores soportados: VALUE
Datos insuficientes-es posible que no se calcule la métrica {{name}}
La operación de parche no está permitida, por ejemplo, de tipo
{{$type}}La conexión de datos
{{data}}no es válida para feedback_data_refEl plan actual '{{plan}}' solo permite {{limit}} despliegues
La definición de conexión de base de datos no es válida ({{code}})
Error al extraer la cabecera X-Spark-Service-Instance: ({{message}})
Parámetro de consulta no válido
{{paramName}}valor: {{value}}El formato de token no es válido. Debe utilizar el formato de señal portadora.
Siga estos consejos para resolver problemas comunes que puede encontrar cuando trabaja con Watson Machine Learning.
El entrenamiento de un experimento AutoAI falla con las credenciales de ID de servicio
Si está entrenando un experimento AutoAI utilizando la clave de API para el serviceID, el entrenamiento podría fallar con este error:
User specified in query parameters does not match user from token.
Una forma de resolver este problema es ejecutar el experimento con sus credenciales de usuario. Si desea ejecutar el experimento con credenciales para el servicio, siga estos pasos para actualizar las funciones y políticas para el ID de servicio.
Abra su serviceID en IBM Cloud.
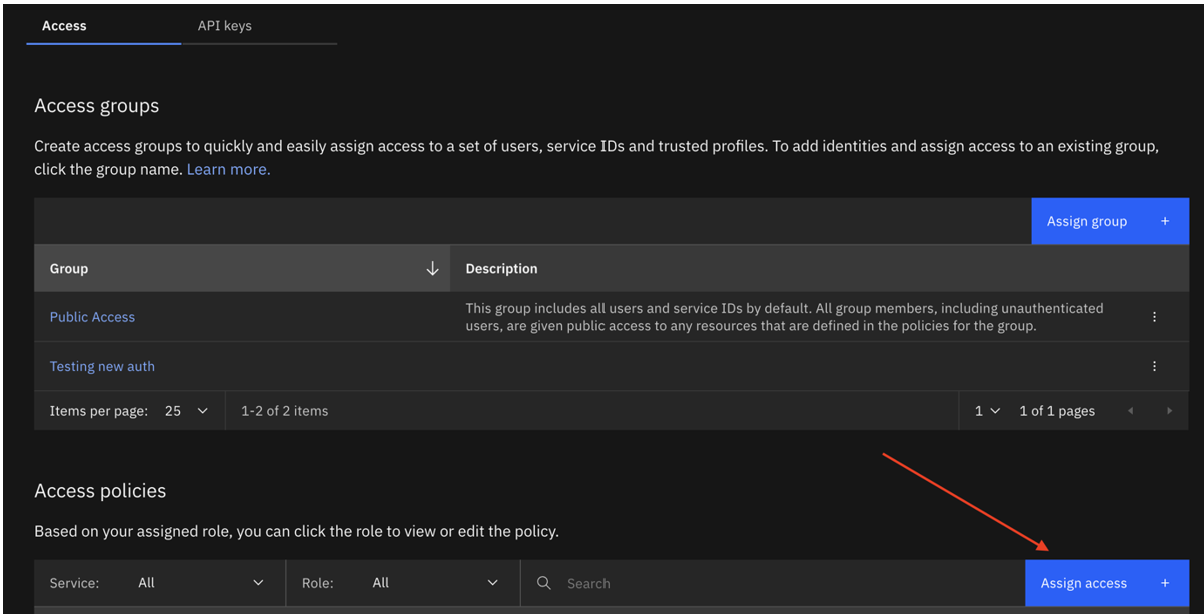
Cree un nuevo serviceID o actualice el ID existente con la siguiente política de acceso:
- Todos los servicios de gestión de cuentas IAM con las funciones de revisor de claves API, creador de claves API de usuario, visualizador, operador y editor. Lo ideal es que creen un nuevo apikey para este ServiceId.
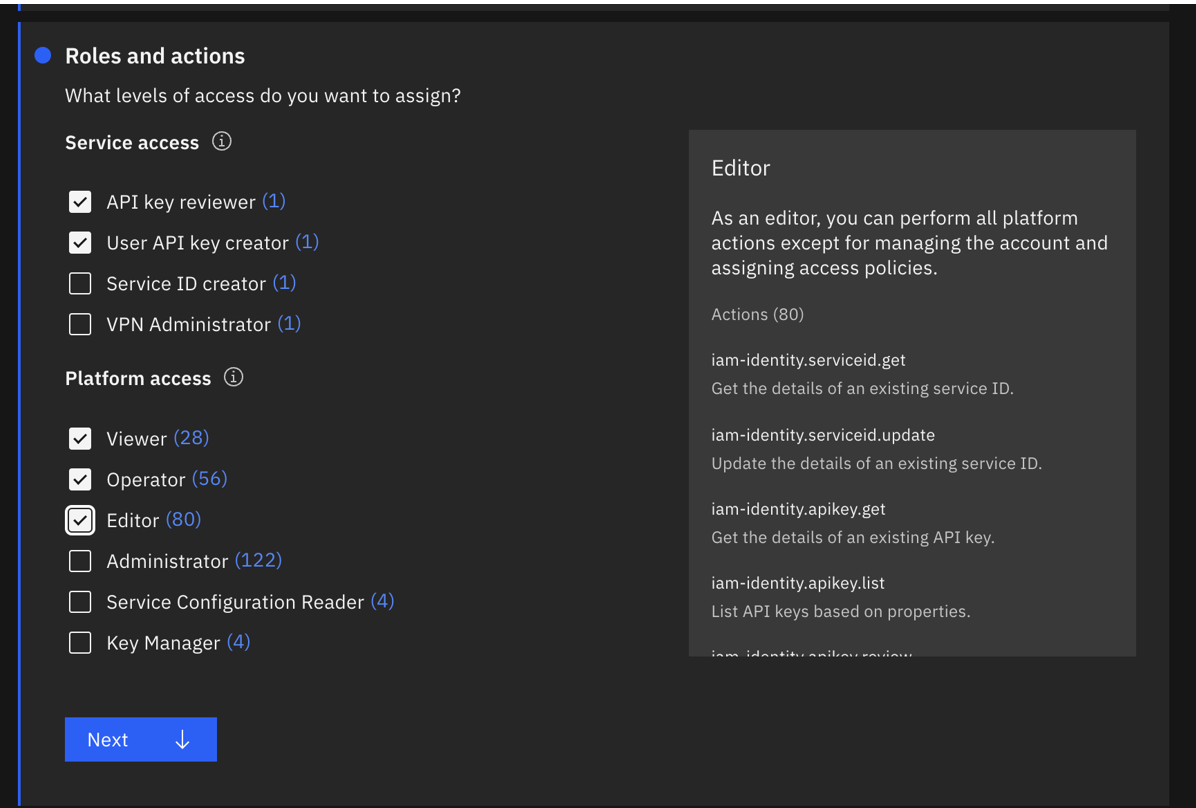
- Todos los servicios de gestión de cuentas IAM con las funciones de revisor de claves API, creador de claves API de usuario, visualizador, operador y editor. Lo ideal es que creen un nuevo apikey para este ServiceId.
La política actualizada tendrá el siguiente aspecto:
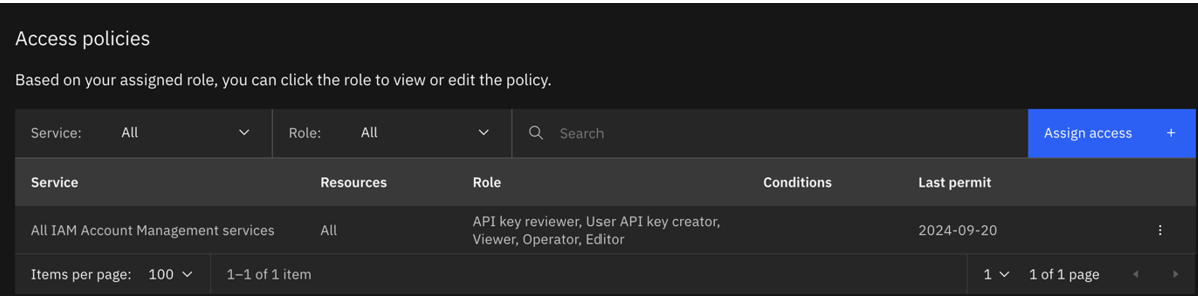
Ejecute de nuevo el entrenamiento con las credenciales para el serviceID actualizado.
Falla el despliegue de un modelo de base personalizado desde un espacio de despliegue
Cuando se crea un despliegue para un modelo de base personalizado desde el espacio de despliegue, el despliegue puede fallar por muchas razones. Siga estos consejos para resolver los problemas habituales que puede encontrar al desplegar sus modelos de base personalizados desde un espacio de despliegue.
Caso 1: Valor del parámetro fuera de rango
Al crear un despliegue para un modelo de base personalizado desde su espacio de despliegue, debe asegurarse de que los valores de los parámetros del modelo base se encuentran dentro del intervalo especificado. Para obtener más información, consulte Propiedades y parámetros de los modelos de cimentación personalizados. Si introduce un valor que está fuera del rango especificado, puede encontrarse con un error.
Por ejemplo, el valor del parámetro max_new_tokens debe ser menor que max_sequence_length. Al actualizar los valores de los parámetros del modelo base, si introduce un valor para max_new_tokens mayor o igual que el valor de max_sequence_length (2048), puede producirse un error.
La siguiente imagen muestra un ejemplo de mensaje de error: Value must be an integer between 20 and 1000000000000000 and be greater than 'Max New Tokens'.
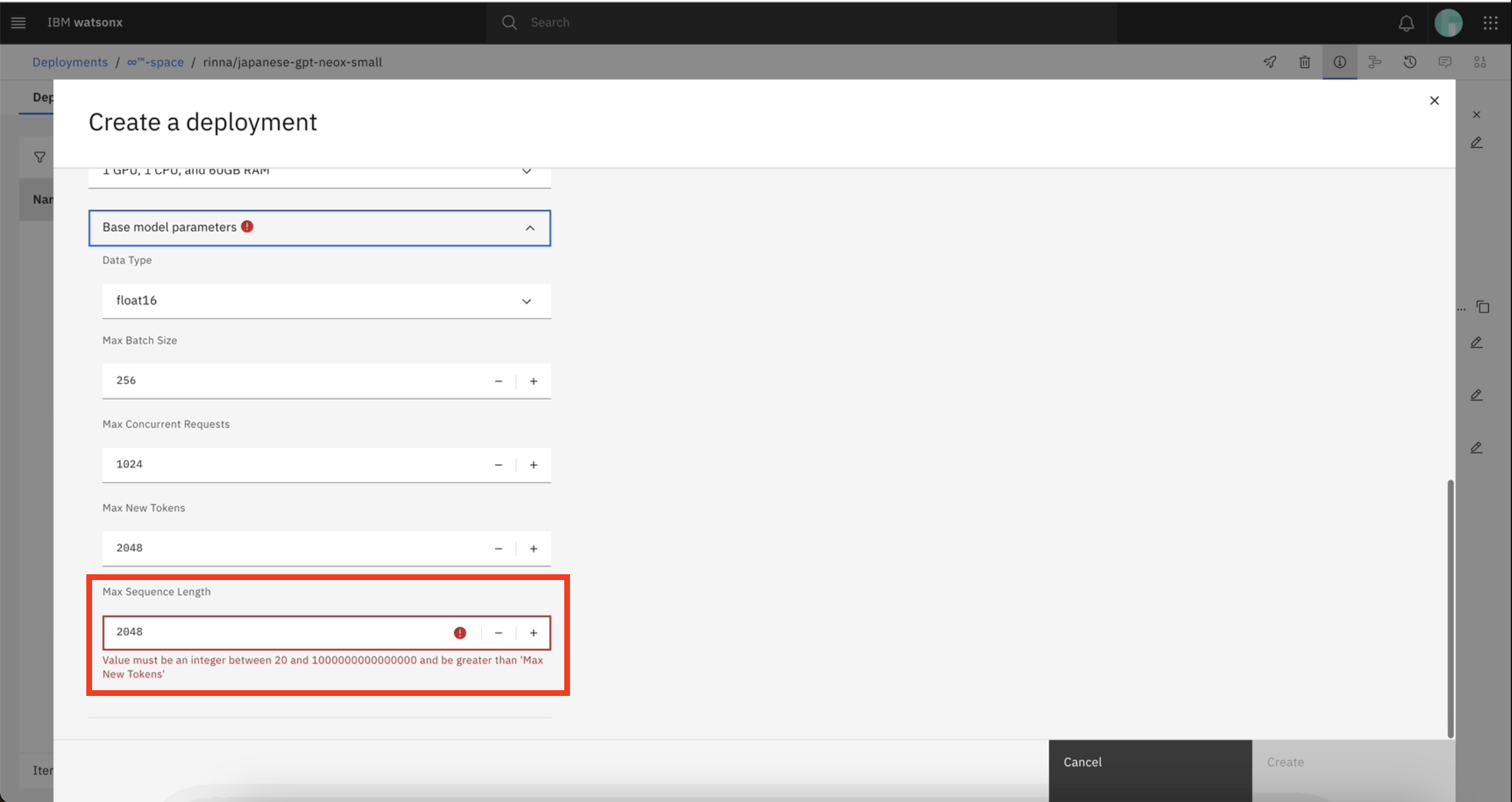
Si los valores por defecto de los parámetros de su modelo dan error, contacte con su administrador para modificar el registro del modelo en el CR watsonxaiifm.
Caso 2: Tipo de datos no admitido
Debe asegurarse de seleccionar un tipo de datos compatible con su modelo de base personalizado. Cuando se actualizan los valores de los parámetros del modelo base, si se actualiza el tipo de datos del modelo desplegado con un tipo de datos no soportado, el despliegue puede fallar.
Por ejemplo, el modelo LLaMA-Pro-8B-Instruct-GPTQ sólo admite el tipo de datos float16. Si despliegas el modelo LLaMA-Pro-8B-Instruct-GPTQ con float16 Enum, y luego actualizas el parámetro Enum de float16 a bfloat16, tu despliegue falla.
Si el tipo de datos que ha seleccionado para el modelo de base personalizado da lugar a un error, puede anular el tipo de datos del modelo de base personalizado durante la creación de la implantación o ponerse en contacto con el administrador para modificar el registro del modelo en watsonxaiifm CR.
Caso 3: El valor del parámetro es demasiado grande
Si introduce un valor muy grande para los parámetros max_sequence_length y max_new_token, puede producirse un error. Por ejemplo, si establece el valor de max_sequence_length como 1000000000000000, se encontrará con el siguiente mensaje de error:
Error al desplegar el modelo de base personalizado. La operación falló debido a que 'max_batch_weight (19596417433) not large enough for (prefill) max_sequence_length (1000000000000000)'. Vuelva a intentar la operación. Contacte con el soporte de IBM si el problema persiste.
Debe asegurarse de introducir un valor para el parámetro que sea inferior al valor definido en el archivo de configuración del modelo (config.json).
Caso 4: el archivo model.safetensors se guarda con bibliotecas no compatibles
Si el archivo model.safetensors para su modelo de base personalizado utiliza un formato de datos no compatible en el encabezado de metadatos, su despliegue podría fallar.
Por ejemplo, si importa el modelo de base personalizado OccamRazor/mpt-7b-storywriter-4bit-128g de Hugging Face a su espacio de despliegue y crea un despliegue en línea, su despliegue podría fallar. Esto se debe a que el archivo model.safetensors para el modelo OccamRazor/mpt-7b-storywriter-4bit-128g se guarda con save_pretrained, que es una biblioteca no compatible. Es posible que reciba el mensaje de error siguiente:
La operación ha fallado debido a que el objeto 'NoneType' no tiene atributo 'get'.
Debe asegurarse de que su modelo de base personalizado se guarda con la biblioteca transformers compatible.
Caso 5: Falla la implantación de un modelo Llama 3.1
En su Llama 3.1 falla el despliegue del modelo, intente editar el contenido del archivo config.json de su modelo:
- Busca la entrada
eos_token_id. - Cambia el valor de la entrada de un array a un entero.
A continuación, intente volver a desplegar su modelo.
Falla la creación de un trabajo para un flujo SPSS Modeler en un espacio de despliegue
Durante el proceso de configuración de un trabajo por lotes para su flujo SPSS Modeler en un espacio de despliegue, la asignación automática de activos de datos con su conexión respectiva podría fallar.
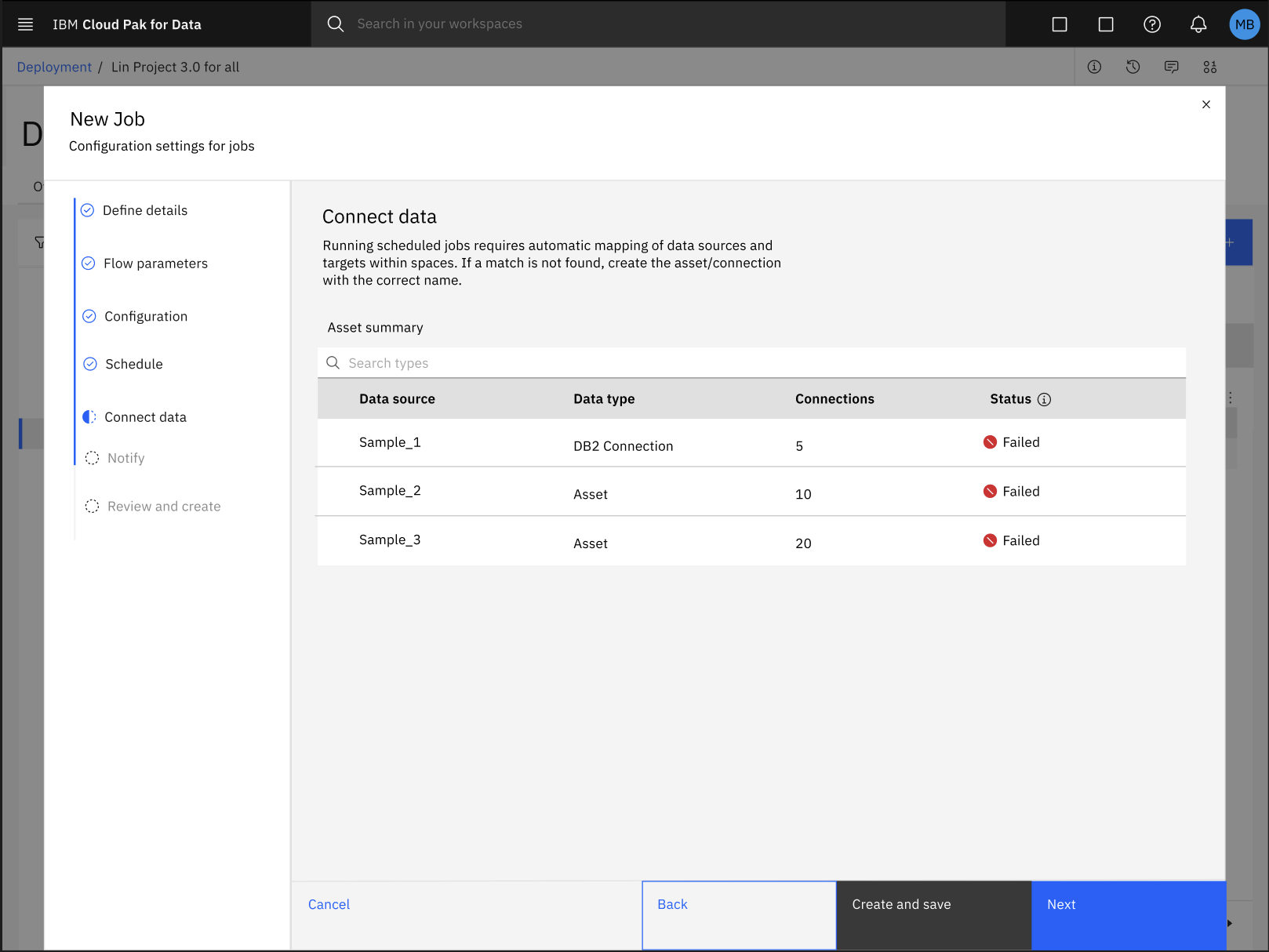
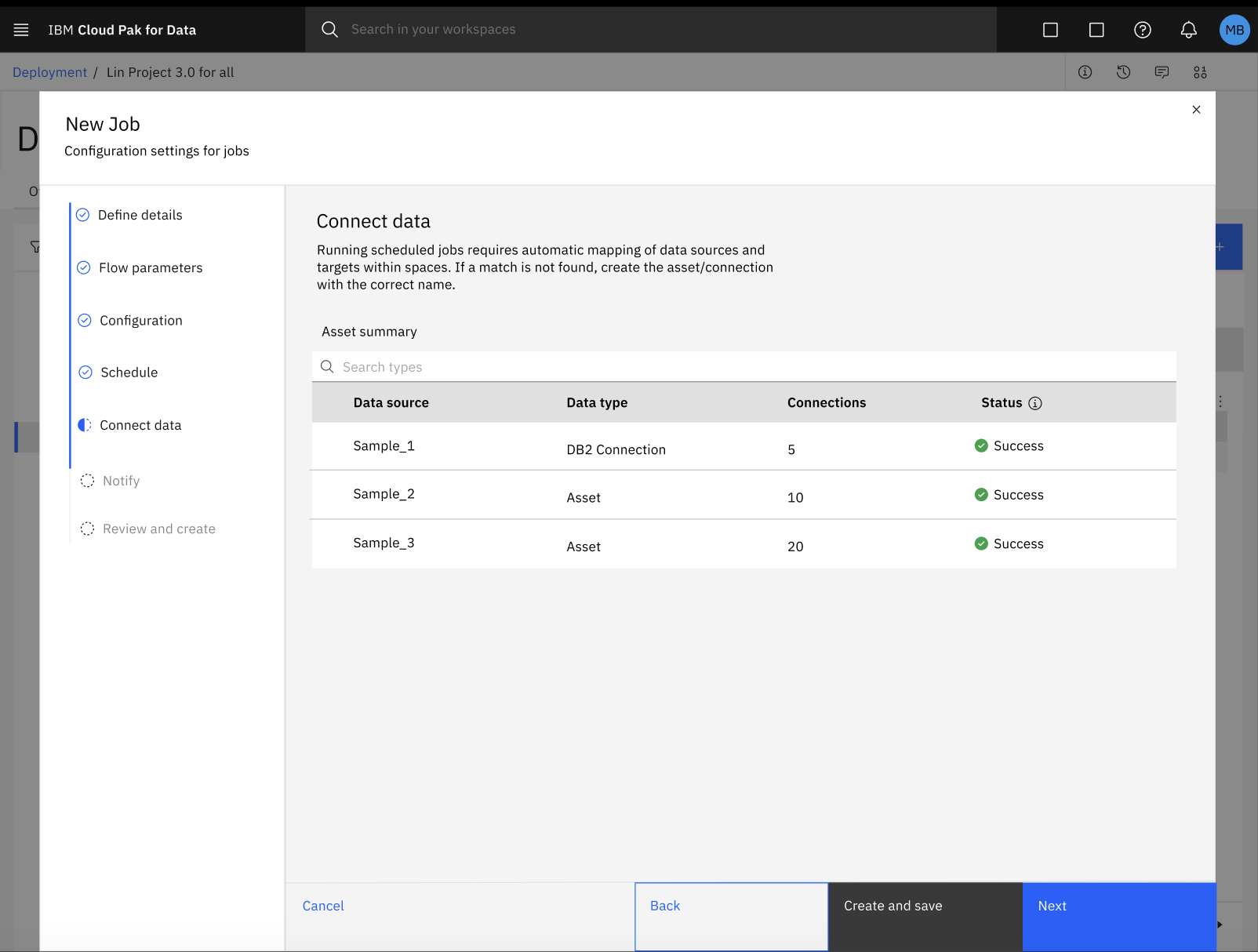
Para solucionar el error con la asignación automática de activos de datos y conexiones, siga estos pasos:
Haga clic en Crear y guardar para guardar su progreso y salir del cuadro de diálogo de configuración Nuevo trabajo.
En su espacio de despliegue, haga clic en la pestaña Trabajos y seleccione su SPSS Modeler para revisar los detalles de su trabajo.
En la página de detalles del trabajo, haga clic en el icono Editar
 para actualizar manualmente la asignación de sus activos de datos y conexiones.
para actualizar manualmente la asignación de sus activos de datos y conexiones.Después de actualizar la asignación de los activos de datos y la conexión, puede reanudar el proceso de configuración del trabajo en el cuadro de diálogo Nuevo trabajo. Para obtener más información, consulte Creación de trabajos de despliegue para SPSS Modeler
Instancia de Watson Machine Learning inactiva
Síntomas
Después de intentar enviar una solicitud de inferencia a un modelo de base pulsando el botón Generar en Prompt Lab, se visualiza el siguiente mensaje de error:
'code': 'no_associated_service_instance_error',
'message': 'WML instance {instance_id} status is not active, current status: Inactive'
Causas posibles
Se ha perdido la asociación entre el proyecto watsonx.ai y la instancia de servicio de Watson Machine Learning relacionada.
Posibles soluciones
Vuelva a crear o renueve la asociación entre el proyecto watsonx.ai y la instancia de servicio de Watson Machine Learning relacionada. Para ello, complete los pasos siguientes:
- En el menú principal, expanda Proyectosy, a continuación, pulse Ver todos los proyectos.
- Pulse el proyecto watsonx.ai .
- En la pestaña Gestionar , pulse Servicios e integraciones.
- Si se lista la instancia de servicio de Watson Machine Learning adecuada, desasóciela temporalmente seleccionando la instancia y, a continuación, pulsando Eliminar. Confirme la eliminación.
- Pulse Asociar servicio.
- Elija la instancia de servicio de Watson Machine Learning adecuada en la lista y, a continuación, pulse Asociar.
La clave pública necesaria para la autenticación no está disponible.
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a problemas de servicio interno.
Cómo solucionarlo
Póngase en contacto con el equipo de soporte.
Operación que ha excedido el tiempo de espera después de {{timeout}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Se ha excedido el tiempo de espera al realizar la operación solicitada.
Cómo solucionarlo
Intente invocar de nuevo la operación.
Excepción no controlada del tipo {{type}} con {{status}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a problemas de servicio interno.
Cómo solucionarlo
Intente invocar de nuevo la operación. Si vuelve a suceder, póngase en contacto con el equipo de soporte.
Excepción no controlada del tipo {{type}} con {{response}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a problemas de servicio interno.
Cómo solucionarlo
Intente invocar de nuevo la operación. Si vuelve a suceder, póngase en contacto con el equipo de soporte.
Excepción no controlada del tipo {{type}} con {{json}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a problemas de servicio interno.
Cómo solucionarlo
Intente invocar de nuevo la operación. Si vuelve a suceder, póngase en contacto con el equipo de soporte.
Excepción no controlada del tipo {{type}} con {{message}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a problemas de servicio interno.
Cómo solucionarlo
Intente invocar de nuevo la operación. Si vuelve a suceder, póngase en contacto con el equipo de soporte.
No se ha encontrado el objeto solicitado.
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
No se ha encontrado el recurso de solicitud.
Cómo solucionarlo
Asegúrese de que hace referencia al recurso existente.
La base de datos subyacente ha notificado demasiadas solicitudes.
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
El usuario ha enviado demasiadas solicitudes en un tiempo específico.
Cómo solucionarlo
Intente invocar de nuevo la operación.
La definición de la evaluación no está definida en el artifactModelVersion o despliegue. Se debe especificar " + \n "al menos en uno de los lugares.
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
La configuración de aprendizaje no contiene toda la información necesaria
Cómo solucionarlo
Proporcione definition en learning configuration
La evaluación requiere una configuración de aprendizaje especificada para el modelo.
¿Qué está pasando?
No es posible crear learning iteration.
¿Por qué está pasando?
learning configuration no está definido para el modelo.
Cómo solucionarlo
Cree learning configuration e intente volver a crear learning iteration.
La evaluación requiere que se proporcione la instancia spark en la cabecera X-Spark-Service-Instance
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
learning configuration no tiene la información necesaria.
Cómo solucionarlo
Proporcione spark_service en la configuración de aprendizaje o en la cabecera X-Spark-Service-Instance .
El modelo no contiene ninguna versión.
¿Qué está pasando?
No es posible crear el despliegue o establecer learning configuration.
¿Por qué está pasando?
Este problema puede producirse debido a una incoherencia relacionada con la persistencia del modelo.
Cómo solucionarlo
Intente persistir el modelo de nuevo e intente realizar la acción de nuevo.
No se ha encontrado el módulo de datos en IBM Federated Learning.
¿Qué está pasando?
El manejador de datos para IBM Federated Learning está intentando extraer un módulo de datos de la biblioteca FL, pero no puede encontrarlo. Es posible que vea el siguiente mensaje de error:
ModuleNotFoundError: No module named 'ibmfl.util.datasets'
¿Por qué está pasando?
Posiblemente un DataHandler obsoleto.
Cómo solucionarlo
Revise y actualice el DataHandler para que se ajuste al manejador de datos MNIST más reciente o asegúrese de que las versiones de ejemplo estén actualizadas.
La operación de parche sólo puede modificar la configuración de aprendizaje existente.
¿Qué está pasando?
No es posible invocar el método de la API REST de parches para aplicar parches en la configuración de aprendizaje.
¿Por qué está pasando?
learning configuration no está establecido para este modelo o el modelo no existe.
Cómo solucionarlo
Asegúrese de que el modelo exista y ya tenga definida la configuración de aprendizaje.
La operación de parche espera exactamente una operación de sustitución.
¿Qué está pasando?
No se puede aplicar el parche al despliegue.
¿Por qué está pasando?
La carga útil del parche contiene más de una operación o la operación de parche es distinta a replace.
Cómo solucionarlo
Utilice sólo una operación en la carga útil de parche, que es la operación replace .
A la carga útil le faltan los campos necesarios: FIELD o los valores de los campos están dañados.
¿Qué está pasando?
No es posible procesar la acción relacionada con el acceso al conjunto de datos subyacente.
¿Por qué está pasando?
El acceso al conjunto de datos no se ha definido correctamente.
Cómo solucionarlo
Corrija la definición de acceso del conjunto de datos.
El método de evaluación proporcionado: METHOD no se soporta. Valores soportados: VALUE.
¿Qué está pasando?
No es posible crear una configuración de aprendizaje.
¿Por qué está pasando?
Se ha utilizado un método de evaluación incorrecto para crear la configuración de aprendizaje.
Cómo solucionarlo
Utilice un método de evaluación soportado, que es uno de los siguientes: regression, binary, multiclass.
Sólo puede tener una evaluación activa por modelo. La solicitud no se puede completar debido a la evaluación activa existente: {{url}}
¿Qué está pasando?
No es posible crear otra iteración de aprendizaje.
¿Por qué está pasando?
Sólo puede tener una evaluación en ejecución para el modelo.
Cómo solucionarlo
Consulte la evaluación que ya está en ejecución o espere a que finalice la evaluación e inicie la nueva.
El tipo de despliegue {{type}} no está soportado.
¿Qué está pasando?
No es posible crear el despliegue.
¿Por qué está pasando?
No se ha utilizado un tipo de despliegue soportado.
Cómo solucionarlo
Se debe utilizar un tipo de despliegue soportado.
Entrada incorrecta: ({{message}})
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema se produce debido a un problema con el análisis de JSON.
Cómo solucionarlo
Asegúrese de que se ha pasado el JSON correcto en la solicitud.
Datos insuficientes-no se puede calcular la métrica {{name}}
¿Qué está pasando?
La iteración de aprendizaje ha fallado.
¿Por qué está pasando?
El valor para la métrica con umbral definido no se puede calcular debido a que no hay suficientes datos de comentarios.
Cómo solucionarlo
Revise y mejore los datos del origen de datos feedback_data_ref en learning configuration
Para el tipo {{type}} se debe proporcionar la instancia de spark en la cabecera X-Spark-Service-Instance
¿Qué está pasando?
No se puede crear el despliegue
¿Por qué está pasando?
Los despliegues batch y streaming necesitan que se proporcione la instancia spark
Cómo solucionarlo
Proporcione la instancia spark en la cabecera X-Spark-Service-Instance
La acción {{action}} ha fallado con el mensaje {{message}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema se produce debido a un problema con la invocación del servicio subyacente.
Cómo solucionarlo
Si el mensaje proporciona una sugerencia para solucionar el problema, siga la sugerencia. De lo contrario, póngase en contacto con el equipo de soporte.
La vía de acceso {{path}} no está permitida. La única vía de acceso permitida para la secuencia de parches es /status
¿Qué está pasando?
El despliegue de secuencia no se puede aplicar un parche.
¿Por qué está pasando?
Se ha utilizado una vía de acceso incorrecta para aplicar el parche al despliegue stream.
Cómo solucionarlo
Aplique un parche en el despliegue de stream con la opción de vía de acceso soportada, que es /status (permite iniciar/detener el proceso de secuencias).
La operación de parche no está permitida, por ejemplo, de tipo {{$type}}
¿Qué está pasando?
El despliegue no se puede parchear.
¿Por qué está pasando?
Se está aplicando el parche a un tipo de despliegue incorrecto.
Cómo solucionarlo
Aplique el parche al tipo de despliegue stream.
La conexión de datos {{data}} no es válida para feedback_data_ref
¿Qué está pasando?
No se puede crear learning configuration para el modelo.
¿Por qué está pasando?
El origen de datos soportado no se ha utilizado cuando se ha definido feedback_data_ref .
Cómo solucionarlo
Utilice sólo el tipo de origen de datos soportado dashdb.
La vía de acceso {{path}} no está permitida. La única vía de acceso permitida para el modelo de parche es /deployed_version/url o /deployed_version/href para V2
¿Qué está pasando?
No hay ninguna opción para aplicar parches al modelo.
¿Por qué está pasando?
Se ha utilizado una vía de acceso incorrecta durante la aplicación del parche al modelo.
Cómo solucionarlo
Modelo de parche con vía de acceso soportada que puede utilizar para actualizar la versión del modelo desplegado.
Error de análisis: {{msg}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
La carga útil solicitada no se puede analizar correctamente.
Cómo solucionarlo
Asegúrese de que la carga útil de la solicitud sea correcta y se pueda analizar correctamente.
El entorno de ejecución para el modelo seleccionado: {{env}} no está soportado para learning configuration. Entornos soportados:[{{supported_envs}}].
¿Qué está pasando?
No hay ninguna opción para crear learning configuration.
¿Por qué está pasando?
El modelo para el que se ha intentado crear learning_configuration no se soporta.
Cómo solucionarlo
Cree learning configuration para el modelo, que tiene el tiempo de ejecución soportado.
El plan actual '{{plan}}' solo permite {{limit}} despliegues
¿Qué está pasando?
No es posible crear el despliegue.
¿Por qué está pasando?
El plan actual ha alcanzado el límite de despliegues.
Cómo solucionarlo
Actualice al plan que no tiene dicha limitación.
La definición de conexión de base de datos no es válida ({{code}})
¿Qué está pasando?
No es posible utilizar la función learning configuration .
¿Por qué está pasando?
La definición de conexión de base de datos no es válida.
Cómo solucionarlo
Intente solucionar el problema descrito por code devuelto por la base de datos subyacente.
Problemas al conectar {{system}} subyacente
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a un problema durante la conexión con el sistema subyacente. Puede ser un problema de red temporal.
Cómo solucionarlo
Intente invocar de nuevo la operación. Si vuelve a recibir un error, póngase en contacto con el equipo de soporte.
Error al extraer la cabecera X-Spark-Service-Instance: ({{message}})
¿Qué está pasando?
Este problema puede producirse si la API REST que requiere credenciales de Spark no se puede invocar.
¿Por qué está pasando?
Este problema puede producirse debido a un problema con la descodificación o el análisis de credenciales de Spark base-64 .
Cómo solucionarlo
Asegúrese de que las credenciales de Spark correctas se hayan codificado correctamente en base-64 . Para obtener más información, consulte la documentación de .
Esta función está prohibida para usuarios no beta.
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
La API REST que se ha invocado está en beta.
Cómo solucionarlo
Si le interesa participar, póngase en lista de espera. Los detalles se pueden encontrar en la documentación.
{{code}} {{message}}
¿Qué está pasando?
La API REST no se puede invocar correctamente.
¿Por qué está pasando?
Este problema puede producirse debido a un problema con la invocación del servicio subyacente.
Cómo solucionarlo
Si el mensaje proporciona una sugerencia para solucionar el problema, siga la sugerencia. De lo contrario, póngase en contacto con el equipo de soporte.
Se ha superado el límite de tasa.
¿Qué está pasando?
Se ha superado el límite de tasa.
¿Por qué está pasando?
Se ha superado el límite de velocidad para el plan actual.
Cómo solucionarlo
Para solucionar este problema, adquiera otro plan con un límite de tasa superior
Parámetro de consulta no válido {{paramName}} valor: {{value}}
¿Qué está pasando?
Se ha producido un error de validación porque se ha pasado un valor de parámetro de consulta incorrecto.
¿Por qué está pasando?
Error al obtener el resultado de la consulta.
Cómo solucionarlo
Corrija el valor del parámetro de consulta. Los detalles se pueden encontrar en la documentación.
Tipo de señal no válido: {{type}}
¿Qué está pasando?
Error relacionado con el tipo de señal.
¿Por qué está pasando?
Error en la autorización.
Cómo solucionarlo
La señal debe iniciarse con el prefijo Bearer .
El formato de token no es válido. Debe utilizar el formato de señal portadora.
¿Qué está pasando?
Error relacionado con el formato de señal.
¿Por qué está pasando?
Error en la autorización.
Cómo solucionarlo
La señal debe ser una señal portadora y debe empezar con el prefijo Bearer .
Falta el archivo JSON de entrada o no es válido: 400
¿Qué está pasando?
El siguiente mensaje aparece cuando se intenta puntuar en línea: Falta el archivo JSON de entrada o no es válido.
¿Por qué está pasando?
Este mensaje se muestra cuando la carga útil de entrada de puntuación no coincide con el tipo de entrada previsto que se necesita para puntar el modelo. En concreto, se pueden aplicar las razones siguientes:
- La carga útil de entrada está vacía.
- El esquema de carga útil de entrada no es válido.
- Los tipos de datos de entrada no coinciden con los tipos de datos esperados.
Cómo solucionarlo
Corrija la carga útil de entrada. Asegúrese de que la carga útil tenga la sintaxis correcta, un esquema válido y tipos de datos adecuados. Una vez aplicadas las correcciones, intente puntuar en línea de nuevo. Para problemas con la sintaxis, verifique el archivo JSON utilizando el mandato jsonlint.
Identificación de despliegue desconocida: 404
¿Qué está pasando?
El siguiente mensaje aparece cuando se intenta puntar en línea una identificación de despliegue desconocida.
¿Por qué está pasando?
Este mensaje se muestra cuando el ID de despliegue que se utiliza para la puntuación no existe.
Cómo solucionarlo
Asegúrese de haber proporcionado el ID de despliegue correcto. De lo contrario, despliegue el modelo con el ID de despliegue e intente puntar de nuevo.
Error de servidor interno: 500
¿Qué está pasando?
El mensaje siguiente se muestra cuando intenta puntuar en línea: Error de servidor interno
¿Por qué está pasando?
Este mensaje aparece cuando falla el flujo de datos en sentido descendente del que depende la puntuación en línea.
Cómo solucionarlo
Espere algún tiempo y vuelva a intentar puntuar en línea. Si vuelve a fallar, póngase en contacto con el soporte de IBM .
Tipo no válido para ml_artifact: Interconexión
¿Qué está pasando?
El siguiente mensaje se muestra cuando intenta publicar un modelo Spark utilizando la biblioteca de cliente de API común en la estación de trabajo.
¿Por qué está pasando?
Este mensaje se muestra si tiene un pyspark no válido configurado en el sistema operativo.
Cómo solucionarlo
Configure las vías de acceso del entorno del sistema de acuerdo con la instrucción:
SPARK_HOME={installed_spark_path}
JAVA_HOME={installed_java_path}
PYTHONPATH=$SPARK_HOME/python/
ValueError: El nombre de Training_data_ref y la conexión no pueden ser Ninguna, si no se proporciona el artefacto de interconexión.
¿Qué está pasando?
Falta el conjunto de datos de entrenamiento o no se hace referencia a él correctamente.
¿Por qué está pasando?
El artefacto de interconexión es un conjunto de datos de entrenamiento en esta instancia.
Cómo solucionarlo
Debe proporcionar un conjunto de datos de entrenamiento cuando persista un PipelineModelde Spark. Si no lo hace, el cliente dice que no admite PipelineModels, en lugar de decir que un PipelineModel debe ir acompañado del conjunto de entrenamiento.