Un flux Data Refinery est un ensemble ordonné d'étapes de nettoyage, de mise en forme et d'amélioration des données. Lorsque vous affinez vos données en appliquant des opérations à un ensemble de données, vous générez dynamiquement un flux Data Refinery personnalisé que vous pouvez modifier en temps réel et sauvegarder pour une utilisation ultérieure.
Vous pouvez effectuer les actions suivantes lorsque vous affinez vos données:
Utilisation du flux Data Refinery
- Sauvegarde d'un flux Data Refinery
- Exécuter ou planifier un travail pour le flux de Data Refinery
- Changement de nom d'un flux Data Refinery
Etapes
- Annulation ou rétablissement d'une étape
- Editer, dupliquer, insérer ou supprimer une étape
- Affichez les étapes de flux Data Refinery dans une "vue instantanée"
- Exportation des données de flux Data Refinery dans un fichier CSV
Utilisation des fichiers
- Modification de la source d'un flux Data Refinery
- Modifier la taille de l'échantillon
- Editer les propriétés de la source
- Modifier la cible d'un flux de Data Refinery
- Editer les propriétés de la cible
- Modification du nom de la cible de flux Data Refinery
Actions sur la page du projet
- Réouverture d'un flux Data Refinery pour poursuivre l'utilisation
- Dupliquez un flux de Data Refinery
- Supprimez un flux de Data Refinery
- Promotion d'un flux Data Refinery vers un espace
- Exporter les données de flux de Data Refinery avec les actifs du projet
Utilisation du flux Data Refinery
Sauvegarde d'un flux Data Refinery
Sauvegardez un flux Data Refinery en cliquant sur l'icône Save Data Refinery flow ![]() dans la barre d'outils Data Refinery. Les flux de Data Refinery sont enregistrés dans le projet dans lequel vous travaillez. Sauvegardez un flux Data Refinery afin de pouvoir continuer à affiner un jeu de données ultérieurement.
dans la barre d'outils Data Refinery. Les flux de Data Refinery sont enregistrés dans le projet dans lequel vous travaillez. Sauvegardez un flux Data Refinery afin de pouvoir continuer à affiner un jeu de données ultérieurement.
La sortie par défaut du flux Data Refinery est sauvegardée en tant qu'actif de données source-file-name_shaped.csv. Par exemple, si le fichier source est mydata.csv, le nom et la sortie par défaut du flux de Data Refinery sont mydata_csv_shaped. Vous pouvez modifier le nom et ajouter une extension en modifiant de la cible d'un flux de Data Refinery.
Exécution ou planification d'un travail pour un flux Data Refinery
Data Refinery prend en charge les jeux de données volumineux, qui peuvent être chronophages et difficiles à affiner. Par conséquent, pour vous permettre de travailler rapidement et efficacement, Data Refinery agit sur un sous-ensemble (échantillon) de lignes du jeu de données. La taille de l'échantillon est de 1 Mo ou 10 000 lignes, selon la première éventualité. Lorsque vous exécutez un travail pour le flux Data Refinery, la totalité du jeu de données est traitée. Lorsque vous exécutez le travail, vous sélectionnez l'environnement d'exécution et vous pouvez ajouter une planification unique ou récurrente.
Dans Data Refinery, dans la barre d'outils Data Refinery, cliquez sur l'icône Jobs ![]() , puis sélectionnez Enregistrer et créer un job ou Enregistrer et visualiser les jobs.
, puis sélectionnez Enregistrer et créer un job ou Enregistrer et visualiser les jobs.
Après avoir sauvegardé un flux Data Refinery, vous pouvez également créer un travail pour celui-ci sur la page Projet. Allez dans l'onglet Assets, sélectionnez le flux Data Refinery, choisissez New job à partir de l'icône Overflow ![]() .
.
Vous devez avoir le rôle d'administrateur ou d'éditeur pour afficher les détails du travail ou pour modifier ou exécuter le travail. Avec le rôle d'afficheur pour le projet, vous ne pouvez afficher que les détails du travail.
Pour plus d'informations sur les travaux, voir Création de travaux dans Data Refinery.
Changement de nom d'un flux Data Refinery
Dans la barre d'outils Data Refinery, ouvrez le volet Info ![]() . Ou cliquez sur l'icône Paramètres de flux
. Ou cliquez sur l'icône Paramètres de flux ![]() et allez dans l'onglet Général.
et allez dans l'onglet Général.
Etapes
Annuler ou rétablir une étape
Cliquez sur l'icône Undo ![]() ou sur l'icône Redo
ou sur l'icône Redo ![]() dans la barre d'outils.
dans la barre d'outils.
Editer, dupliquer, insérer ou supprimer une étape
Dans le volet Étapes, cliquez sur l'icône Débordement ![]() de l'étape correspondant à l'opération que vous souhaitez modifier. Sélectionnez l'action (Editer, Dupliquer, Insérer une étape avant, Insérer une étape aprèsou Supprimer).
de l'étape correspondant à l'opération que vous souhaitez modifier. Sélectionnez l'action (Editer, Dupliquer, Insérer une étape avant, Insérer une étape aprèsou Supprimer).
Si vous sélectionnez Editer, Data Refinery passe en mode édition et affiche l'opération à éditer sur la ligne de commande ou dans le panneau Opération. Appliquez l'opération modifiée.
Si vous sélectionnez Dupliquer, l'étape dupliquée est insérée après l'étape sélectionnée.
L'action Dupliquer n'est pas disponible pour les opérations Joindre ou Union .
Data Refinery met à jour le flux Data Refinery pour refléter les modifications et réexécute toutes les opérations.
Afficher les étapes de flux Data Refinery dans une "vue instantanée"
Pour voir comment se présentaient vos données à un moment donné, cliquez sur une étape précédente pour faire passer Data Refinery en vue d'instantané. Par exemple, si vous cliquez sur Source de données, vous voyez à quoi ressemblent vos données avant de commencer à les affiner. Cliquez sur l'étape d'une opération pour voir comment se présentaient vos données après l'application de l'opération. Pour quitter la vue instantanée, cliquez sur Affichage de l'étape x de y ou cliquez sur l'étape que vous avez sélectionnée pour accéder à la vue instantanée.
Exportez les données de flux Data Refinery dans un fichier CSV
Cliquez sur l'icône Export ![]() de la barre d'outils pour exporter les données de l'étape actuelle de votre flux Data Refinery vers un fichier CSV sans enregistrer ou exécuter une tâche de flux Data Refinery. Utilisez cette option, par exemple, si vous souhaitez une sortie rapide d'un flux Data Refinery qui est en cours. Lorsque vous exportez les données, un fichier CSV est créé et téléchargé dans le dossier Downloads de votre ordinateur (ou dans l'emplacement de téléchargement spécifié par l'utilisateur) à l'étape en cours du flux Data Refinery . Si vous vous trouvez dans la vue instantanée, la sortie du fichier CSV se trouve à l'étape sur laquelle vous avez cliqué. Si vous visualisez un échantillon (sous-ensemble) des données, seules les données d'échantillon seront affichées dans la sortie.
de la barre d'outils pour exporter les données de l'étape actuelle de votre flux Data Refinery vers un fichier CSV sans enregistrer ou exécuter une tâche de flux Data Refinery. Utilisez cette option, par exemple, si vous souhaitez une sortie rapide d'un flux Data Refinery qui est en cours. Lorsque vous exportez les données, un fichier CSV est créé et téléchargé dans le dossier Downloads de votre ordinateur (ou dans l'emplacement de téléchargement spécifié par l'utilisateur) à l'étape en cours du flux Data Refinery . Si vous vous trouvez dans la vue instantanée, la sortie du fichier CSV se trouve à l'étape sur laquelle vous avez cliqué. Si vous visualisez un échantillon (sous-ensemble) des données, seules les données d'échantillon seront affichées dans la sortie.
Si votre fichier CSV contient une charge utile malveillante (des formules par exemple) dans un champ de saisie, ces éléments peuvent être exécutés.
Vous pouvez également exporter un flux Data Refinery en exportant les actifs du projet. Pour plus d'informations, voir Exporter des ressources de projet.
Utilisation des ensembles de données
Modification de la source d'un flux Data Refinery
Modifiez la source d'un flux Data Refinery . Exécutez le même flux Data Refinery mais avec un jeu de données source différent. Vous pouvez modifier la source de deux manières:
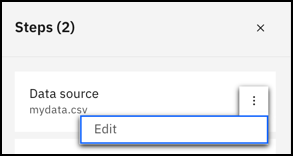
Dans le volet Étapes: Cliquez sur l'icône de débordement '
 à côté de Data source, sélectionnez Edit, puis choisissez un autre ensemble de données source.
à côté de Data source, sélectionnez Edit, puis choisissez un autre ensemble de données source.
'
Dans les paramètres de flux: vous pouvez utiliser cette méthode si vous souhaitez modifier plusieurs sources de données au même endroit. Par exemple, pour une opération Join ou Union. Dans la barre d'outils, cliquez sur l'icône des paramètres de flux "
 . Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow ' à côté de la source de données. Sélectionnez Remplacer la source de données, puis choisissez un autre jeu de données source.
. Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow ' à côté de la source de données. Sélectionnez Remplacer la source de données, puis choisissez un autre jeu de données source.
Pour obtenir de meilleurs résultats, le nouveau jeu de données doit posséder un schéma compatible avec le jeu de données d'origine (par exemple, les noms de colonne, le nombre de colonnes et les types de données). Si le nouveau fichier possède un schéma différent, les opérations qui ne fonctionnent pas avec le schéma affichent des erreurs. Vous pouvez éditer ou supprimer les opérations, ou remplacer la source par une autre qui possède un schéma plus compatible.
Si vous choisissez une connexion pour une cible, vous ne pouvez utiliser qu'une connexion figurant dans la liste des sources de données prises en charge par Data Refinery.
Editer la taille de l'échantillon
Lorsque vous exécutez le travail pour le flux Data Refinery , les opérations sont effectuées sur le jeu de données complet. Toutefois, lorsque vous appliquez les opérations de manière interactive dans Data Refinery, en fonction de la taille de l'ensemble de données, vous affichez uniquement un échantillon des données.
Augmentez la taille de l'échantillon pour voir les résultats qui seront plus proches des résultats du travail de flux Data Refinery , mais sachez que l'affichage des résultats dans Data Refinerypeut prendre plus de temps. La valeur maximale est un nombre de premières lignes de 10 000 lignes ou de 1 Mo, selon celle qui vient en premier. Réduisez la taille de l'échantillon pour afficher les résultats plus rapidement. En fonction de la taille des données et du nombre et de la complexité des opérations, vous pouvez tester la taille de l'échantillon pour voir ce qui fonctionne le mieux pour le jeu de données.
Dans la barre d'outils, cliquez sur l'icône des paramètres de flux " ![]() . Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow '
. Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow '![]() à côté de la source de données, puis sélectionnez Edit sample.
à côté de la source de données, puis sélectionnez Edit sample.
Editer les propriétés de la source
Les propriétés disponibles dépendent de la source de données. Différentes propriétés sont disponibles pour les actifs de données et pour les données provenant de différents types de connexion. Modifiez le format de fichier uniquement si le format de fichier induit est incorrect. Si vous modifiez le format de fichier, la source est lue avec le nouveau format, mais le fichier source reste inchangé. La modification des propriétés de la source de format peut être un processus itératif. Examinez vos données après avoir appliqué une option.
Dans la barre d'outils, cliquez sur l'icône des paramètres de flux " ![]() . Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow '
. Allez dans l'onglet Source data sets et cliquez sur l'icône Overflow '![]() à côté de la source de données, puis sélectionnez Edit format.
à côté de la source de données, puis sélectionnez Edit format.
Modifier la cible d'un flux de Data Refinery
Par défaut, la cible de Data Refinery est sauvegardée en tant qu'actif de données dans le projet dans lequel vous travaillez.
Pour modifier le " emplacement de la cible, cliquez sur l'icône " Réglages du débit ou " ![]() dans la barre d'outils. Accédez à l'onglet Fichier cible , cliquez sur Sélectionner une cibleet sélectionnez un autre emplacement cible.
dans la barre d'outils. Accédez à l'onglet Fichier cible , cliquez sur Sélectionner une cibleet sélectionnez un autre emplacement cible.
Si vous choisissez une connexion pour une cible, vous ne pouvez utiliser qu'une connexion figurant dans la liste des sources de données prises en charge par Data Refinery. Certaines de ces connexions ne peuvent être utilisées que comme source pour un flux Data Refinery.
Editer les propriétés de la cible
Les propriétés disponibles dépendent de la source de données. Différentes propriétés sont disponibles pour les actifs de données et pour les données provenant de différents types de connexion.
Pour modifier les propriétés de l'ensemble de données cible, cliquez sur l'icône Flow settings " ![]() dans la barre d'outils. Accédez à l'onglet Fichier cible et cliquez sur Editer les propriétés.
dans la barre d'outils. Accédez à l'onglet Fichier cible et cliquez sur Editer les propriétés.
Modification du nom de la cible de flux Data Refinery
Le nom de l'ensemble de données cible est inclus dans les zones que vous pouvez modifier lorsque vous éditez les propriétés de la cible.
Par défaut, la cible de Data Refinery est sauvegardée en tant qu'actif de données source-file-name_shaped.csv dans le projet. Par exemple, si la source est mydata.csv, le nom et la sortie par défaut du flux Data Refinery sont l'actif de données mydata_csv_shaped.
Différentes propriétés et conventions de dénomination s'appliquent à un jeu de données cible à partir d'une connexion. Par exemple, si le fichier se trouve dans Cloud Object Storage, il est identifié dans les zones Compartiment et Nom de fichier . Si le jeu de données se trouve dans une base de données Db2 , il est identifié dans les zones Nom de schéma et Nom de table .
Pour plus d'informations, voir Options de connexion à la cible.
Actions sur la page du projet
Réouverture d'un flux Data Refinery pour poursuivre l'utilisation
Pour rouvrir un flux Data Refinery et continuer à affiner vos données, accédez à l'onglet Actifs du projet. Sous Types d'actif, développez Flux, puis cliquez sur FluxData Refinery. Cliquez sur le nom du flux de Data Refinery.
Dupliquer un flux de Data Refinery
Pour créer une copie d'un flux Data Refinery , accédez à l'onglet Actifs du projet, développez Flux, puis cliquez sur Data Refinery. Sélectionnez le flux Data Refinery, puis sélectionnez Duplicate dans l'icône Overflow '![]() . Le flux de Data Refinery est ajouté à la liste des flux de Data Refinery sous la forme "Nom-origine copie 1".
. Le flux de Data Refinery est ajouté à la liste des flux de Data Refinery sous la forme "Nom-origine copie 1".
Suppression d'un flux de Data Refinery
Pour supprimer un flux Data Refinery , accédez à l'onglet Actifs du projet, développez Flux, puis cliquez sur Data Refinery. Sélectionnez le flux Data Refinery, puis sélectionnez Delete dans l'icône Overflow '![]() .
.
Promotion d'un flux Data Refinery vers un espace
Les espaces de déploiement sont utilisés pour gérer un ensemble d'actifs associés dans un environnement distinct de vos projets. Vous utilisez un espace pour préparer les données d'une tâche de déploiement pour watsonx.ai Runtime. Vous pouvez promouvoir des flux Data Refinery depuis plusieurs projets vers un espace. Procédez comme indiqué ci-après dans le flux Data Refinery avant de le promouvoir car il n'est pas modifiable dans un espace.
Pour promouvoir un flux Data Refinery dans un espace, accédez à l'onglet Actifs du projet, développez Flux, puis cliquez sur Data Refinery. Sélectionnez le flux Data Refinery . Cliquez sur l'icône de débordement " ![]() pour le flux Data Refinery, puis sélectionnez Promote. Le fichier source pour le flux Data Refinery et les autres données dépendantes seront également promus.
pour le flux Data Refinery, puis sélectionnez Promote. Le fichier source pour le flux Data Refinery et les autres données dépendantes seront également promus.
Pour créer ou exécuter un travail pour le flux Data Refinery dans un espace, allez dans l'onglet Assets de l'espace, descendez jusqu'au flux Data Refinery et cliquez sur l'icône Nouveau travail " ![]() à partir de l'icône Débordement "
à partir de l'icône Débordement " ![]() . Si vous avez déjà créé le travail, accédez à l'onglet Travaux pour modifier le travail ou afficher les détails de l'exécution du travail. La sortie en forme du travail de flux de Data Refinery sera disponible dans l'onglet Actifs de l'espace. Vous devez avoir le rôle d'administrateur ou d'éditeur pour afficher les détails du travail ou pour modifier ou exécuter le travail. Avec le rôle Afficheur pour le projet, vous pouvez uniquement afficher les détails du travail. Vous pouvez utiliser la sortie façonnée comme données d'entrée pour un travail dans watsonx.ai Runtime.
. Si vous avez déjà créé le travail, accédez à l'onglet Travaux pour modifier le travail ou afficher les détails de l'exécution du travail. La sortie en forme du travail de flux de Data Refinery sera disponible dans l'onglet Actifs de l'espace. Vous devez avoir le rôle d'administrateur ou d'éditeur pour afficher les détails du travail ou pour modifier ou exécuter le travail. Avec le rôle Afficheur pour le projet, vous pouvez uniquement afficher les détails du travail. Vous pouvez utiliser la sortie façonnée comme données d'entrée pour un travail dans watsonx.ai Runtime.
Lorsque vous effectuez la promotion d'un flux Data Refinery depuis un projet vers un espace et que la cible du flux Data Refinery est un actif de données connecté, vous devez promouvoir manuellement l'actif de données connecté. Cette action garantit que les données de l'actif de données connecté sont mises à jour lorsque vous exécutez le travail de flux de Data Refinery dans l'espace. Sinon, une exécution réussie du travail de flux Data Refinery créera un nouvel actif de données dans l'espace.
Pour plus d'informations sur les espaces, voir Espaces de déploiement.
Exporter les données de flux de Data Refinery avec les actifs du projet
Vous pouvez également exporter un flux Data Refinery en exportant les actifs du projet. Pour plus d'informations, voir Exporter des ressources de projet.
Rubrique parent : Affinage des données