Musíte připojit svá data školení k systému Watson OpenScale , aby bylo možné pochopit způsob zpracování vašeho modelu. Produkt Watson OpenScale používá schéma dat pro školení, které poskytujete ve své implementaci, aby bylo zajištěno, že informace, které poskytnete k identifikaci dat, jsou přesné a odpovídají způsobu, jakým model rozumí. Následující příklad ukazuje, jak musí být schéma dat školení formátováno:
"training_data_references": [
{
"connection": {
"endpoint_url": "",
"access_key_id": "",
"secret_access_key": ""
},
"location": {
"bucket": "",
"path": ""
},
"type": "fs",
"schema": {
"id": "4cdb0a0a-1c69-43a0-a8c0-3918afc7d45f",
"fields": [
{
"metadata": {},
"name": "CheckingStatus",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanDuration",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "CreditHistory",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanPurpose",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanAmount",
"nullable": true,
"type": "integer"
},
{
"metadata": {
"modeling_role": "target",
"values": [
"No Risk",
"Risk"
]
},
"name": "Risk",
"nullable": true,
"type": "string"
}
],
"type": "struct"
}
}
]
Generování artefaktů ze vzdělávacích dat
K datům školení se přistupuje z následujících důvodů:
- Pro sestavení modelu detekce unášených detekcí za účelem zjištění poklesu přesnosti, která je posunem modelu.
- Chcete-li zjistit omezení dat pro zjištění poklesu konzistence dat, což je posun dat.
- Chcete-li generovat statistiku dat školení, která se používá k doporučení konfigurace spravedlnosti, jako jsou atributy spravedlnosti, odkazy a monitorované skupiny pro tyto atributy,
- Výcviková data se také používají ke generování korelací mezi citlivými atributy (například: gender, race, atd.) proti funkcím, které se používají k vycvičování modelu. Tyto korelace se dále používají k vyhledání nepřímého zkreslení v implementaci modelu.
- Statistika výukových dat se používá ke generování poruch transakcí, které se používají pro generování vysvětlení transakce.
Předcházející artefakty lze generovat prostřednictvím produktu Watson OpenScalenebo prostřednictvím Jupyter Notebook.
Udržení soukromí vašich dat školení
Při přístupu k datům školení prostřednictvím Jupyter Notebook, buď ze samostatného produktu Jupyter nebo Python , nebo z produktu Watson Studio, se dříve vypsané artefakty vygenerují a odešlou do Watson OpenScale.
V tomto přístupu produkt Watson OpenScale nevyžaduje přístup ke školením za běhu programu, protože jsou vypočteny ceny spravedlnosti, vysvětlení, posunu a kvality.
Posun modelu
V produkčních prostředích produkt Watson OpenScale vytváří model detekce unášení tím, že se dívá na data, která byla použita k procvičení a testování modelu. Například, pokud má model přesnost 90% na testovacích datech, znamená to, že poskytuje nesprávné předpovědi na 10% testové dat. Produkt Watson OpenScale sestavuje binární model klasifikace, který přijímá datový bod a předpovídá, zda tento datový bod je podobný přesně (90%) nebo nepřesně předpovězených (10%) dat.
Poté, co produkt Watson OpenScale vytvoří model detekce unášení, za běhu se tento model zobrazí s použitím všech dat, která přijímá model klienta. Pokud například model klienta obdržel v posledních třech hodinách 1000 záznamů, produkt Watson OpenScale spustí model detekce unášení na těchto 1000 datových bodech. vypočítá, kolik záznamů se bude podobat 10% záznamů, na kterých došlo k chybě při školení. Je-li 200 z těchto záznamů podobné 10%, znamená to, že přesnost modelu bude pravděpodobně 80%. Vzhledem k tomu, že přesnost modelu v době školení činila 90%, znamená to, že v modelu je v modelu přesnost 10%.
Posun dat
Výpočet a zpracování unášených dat vyžaduje statistiky sloupců, jako jsou průměrné a percentily a omezení nebo pravidla ve vzdělávacích datech, která mohou přesahovat jeden sloupec nebo dva sloupce. V případě online odběrů se zpracování provádí prostřednictvím knihoven python, jako jsou pandas, numpynebo scipy. U dávkových odběrů se zpracování provádí prostřednictvím knihovny produktu pyspark .
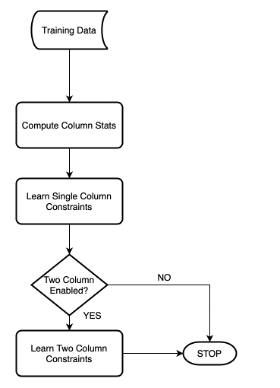
Pro každý numerický sloupec jsou zpracovány následující statistiky:
- střední hodnota ve sloupci
- minimální hodnota ve sloupci
- maximální hodnota ve sloupci
- směrodatná odchylka ve sloupci
- kvartily
- skutečný počet dat po zrušení outliers [ pouze v online odběrech]
- přibližný počet pro počet odlišených hodnot [ pouze v dávkových odběrech]
Čestnost
Výcviková data pro spravedlnost se používají ke generování statistických údajů pro odbornou přípravu. Tyto statistiky pak doporučují konfiguraci spravedlnosti (například: atributy spravedlnosti, reference a monitorované skupiny) a výpočet spravedlnosti (nesourodý dopad) na údaje o školení pro danou konfiguraci spravedlivosti.
Statistika výukových dat obsahuje rozdělení sloupců atributu spravedlnosti přes hodnoty ve sloupci predikce. Například ukázkový německý model úvěrového rizika (German Credit Risk), který obsahuje statistické údaje o školení pro funkce Sex a Age , by vypadal takto:
{
"fields": [
"feature",
"feature_value",
"label",
"count",
"is_favourable",
"group"
],
"values": [
[
"Sex",
"male",
"No Risk",
1995,
true,
"reference"
],
[
"Age",
[
26,
75
],
"No Risk",
2431,
true,
"reference"
]
]
}
Tyto statistické údaje o školeních jsou uloženy v instanci monitoru spravedlnosti. Dojde-li ke změně v konfiguraci spravedlivosti, musí být tato statistika znovu vygenerována. Je-li umístění dat pro školení přiděleno produktu Watson OpenScale jako součást odběru, produkt Watson OpenScale by tyto statistiky automaticky znovu vygeneroval, dojde-li ke změně konfigurace spravedlnosti. Pokud tomu tak není, musí to být provedeno uživatelem prostřednictvím zápisníku pro statistiky školení.
Výcviková data se používají také ke generování korelací mezi funkcemi, které byly použity k vycvičování modelu a metafunkcí, které jsou citlivé, jako např. pohlaví nebo rasa. Tyto korelace jsou dále použity k určení korelované referenční a monitorované skupiny pro zjištění nepřímého zkreslení v implementaci modelu.
Tyto statistiky nejsou použity k hlášení nebo odebrání předpojatosti z implementace modelu.
Znázornění
Pro vysvětlitelnost jsou z údajů o výcviku vypočteny tyto statistické údaje:
- Pro sloupec kategoriálních funkcí počet kategoriálních hodnot ve vzdělávacích datech
Pro sloupec číselné funkce jsou vypočteny následující hodnoty:
- Minimum, Maximum, Medián a směrodatné odchylky hodnot pro sloupec.
- Vytvořte přihrádky (4 nebo 10) pro číselný sloupec a minimální, maximální, střední, směrodatnou odchylku pro každou přihrádku. Také počty hodnot v každém zásobníku.
Pro sloupec popisku je uveden seznam hodnot sloupce popisků.
Jak se tato statistika používá ve vysvětleních? Ve vysvětlení generování se statistika používá ke generování hodnot perturbation ve stejné distribuci jako statistiky. Jsou také použity k zajištění, že jsou perturbations generovány s hranicí hodnot funkcí.
Ukázkové schéma údajů o školení
Následující výstup ukazuje ukázkové schéma dat školení z německého modelu Credit Risk:
"training_data_references": [
{
"connection": {
"endpoint_url": "",
"access_key_id": "",
"secret_access_key": ""
},
"location": {
"bucket": "",
"path": ""
},
"type": "fs",
"schema": {
"id": "4cdb0a0a-1c69-43a0-a8c0-3918afc7d45f",
"fields": [
{
"metadata": {},
"name": "CheckingStatus",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanDuration",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "CreditHistory",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanPurpose",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "LoanAmount",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "ExistingSavings",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "EmploymentDuration",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "InstallmentPercent",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "Sex",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "OthersOnLoan",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "CurrentResidenceDuration",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "OwnsProperty",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "Age",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "InstallmentPlans",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "Housing",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "ExistingCreditsCount",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "Job",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "Dependents",
"nullable": true,
"type": "integer"
},
{
"metadata": {},
"name": "Telephone",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "ForeignWorker",
"nullable": true,
"type": "string"
},
{
"metadata": {
"modeling_role": "target",
"values": [
"No Risk",
"Risk"
]
},
"name": "Risk",
"nullable": true,
"type": "string"
}
],
"type": "struct"
}
}
]
Další kroky
Nadřízené téma: Konfigurace produktu Watson OpenScale