About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Last updated: Nov 28, 2024
You can use watsonx.governance generative AI quality evaluations to measure how well your foundation model performs tasks.
When you evaluate prompt templates, you can review a summary of generative AI quality evaluation results for the following task types:
- Text summarization
- Content generation
- Entity extraction
- Question answering
- Retrieval Augmented Generation (RAG)
The summary displays scores and violations for metrics that are calculated with default settings.
To configure generative AI quality evaluations with your own settings, you can set a minimum sample size and set threshold values for each metric as shown in the following example:
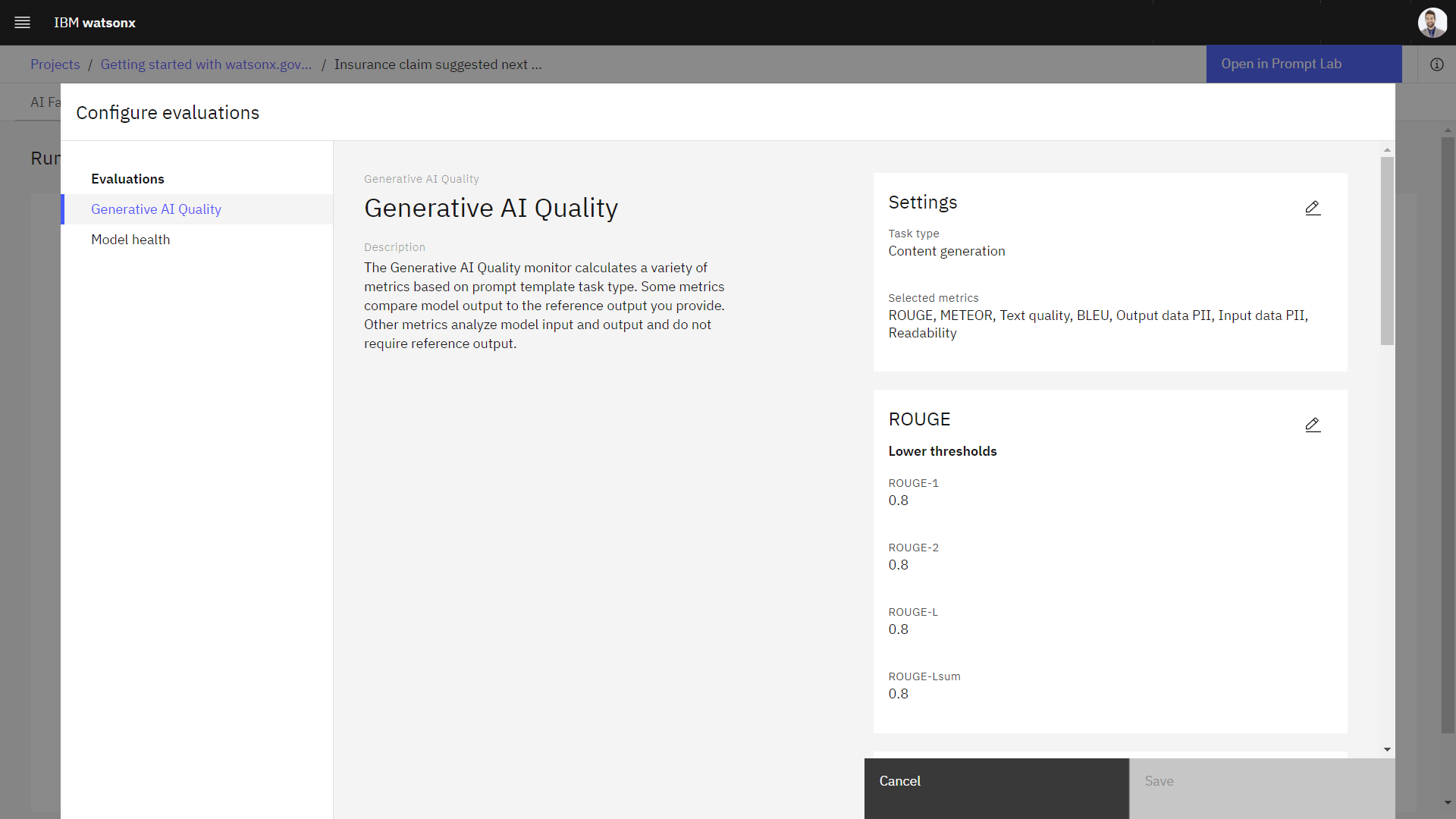
The minimum sample size indicates the minimum number of model transaction records that you want to evaluate and the threshold values create alerts when your metric scores violate your thresholds. The metric scores must be higher than the lower threshold values to avoid violations. Higher metric values indicate better scores.
You can also configure settings to calculate metrics with LLM-as-a-judge models. LLM-as-a-judge models are LLM models that you can use to evaluate the performance of other models.
To calculate metrics with LLM-as-a-judge models, you must select Manage to add a generative_ai_evaluator
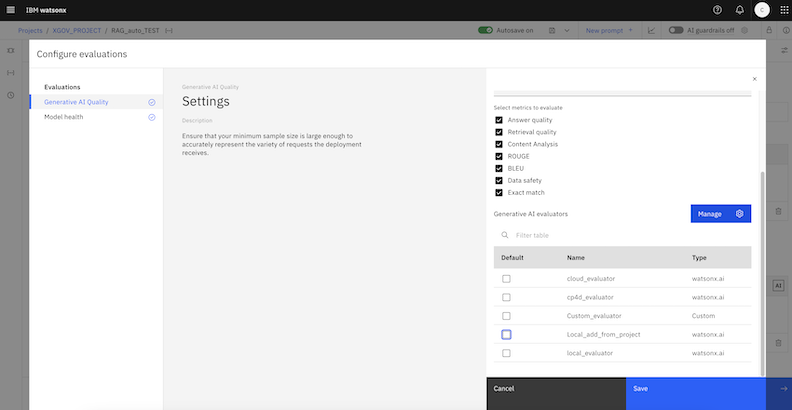
You can select an evaluator to calculate answer quality and retrieval quality metrics.
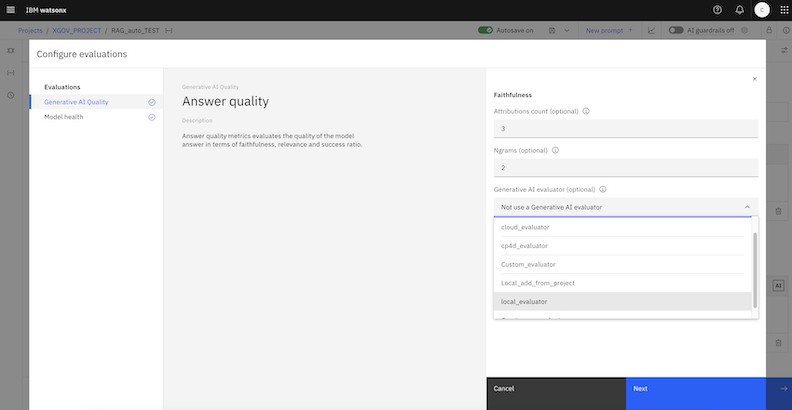
You can also use a notebook to create an evaluator when you set up your prompt templates and review evaluation results for the RAG task in watsonx.governance.
Supported generative AI quality metrics
The following generative AI quality metrics are supported by watsonx.governance:
ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics measure how well generated summaries or translations compare to reference outputs. The generative AI quality evaluation calculates the rouge1, rouge2, and rougeLSum metrics.
-
Task types:
- Text summarization
- Content generation
- Question answering
- Entity extraction
- Retrieval Augmented Generation (RAG)
-
Parameters:
- Use stemmer: If true, users Porter stemmer to strip word suffixes. Defaults to false.
-
Thresholds:
- Lower bound: 0.8
- Upper bound: 1.0
-
How it works: Higher scores indicate higher similarity between the summary and the reference.
SARI
SARI (system output against references and against the input sentence) compares the predicted sentence output against the reference sentence output to measure the quality of words that the model uses to generate sentences.
-
Task types:
- Text summarization
-
Thresholds:
- Lower bound: 0
- Upper bound: 100
-
How it works: Higher scores indicate a higher quality of words are used to generate sentences.
METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) measures how well the text that is generated with machine translations match the structure of the text from reference translations. It is calculated with the harmonic mean of precision and recall.
-
Task types:
- Text summarization
- Content generation
-
Parameters:
- Alpha: Controls relative weights of precision and recall
- Beta: Controls shape of penalty as a function of fragmentation.
- Gamma: The relative weight assigned to fragmentation penalty.
-
Thresholds:
- Lower bound: 0
- Upper bound: 1
-
How it works: Higher scores indicate that machine translations match more closely with references.
Text quality
Text quality evaluates the output of a model against SuperGLUE datasets by measuring the F1 score, precision, and recall against the model predictions and its ground truth data. It is calculated by normalizing the input strings and identifying the number of similar tokens that exist between the predictions and references.
-
Task types:
- Text summarization
- Content generation
-
Thresholds:
- Lower bound: 0.8
- Upper bound: 1
-
How it works: Higher scores indicate higher similarity between the predictions and references.
BLEU
BLEU (Bilingual Evaluation Understudy) compares translated sentences from machine translations to sentences from reference translations to measure the similarity between reference texts and predictions.
-
Task types:
- Text summarization
- Content generation
- Question answering
- Retrieval Augmented Generation (RAG)
-
Parameters:
- Max order: Maximum n-gram order to use when completing BLEU score
- Smooth: Whether or not to apply a smoothing function to remove noise from data
-
Thresholds:
- Lower bound: 0.8
- Upper bound: 1
-
How it works: Higher scores indicate more similarity between reference texts and predictions.
Sentence similarity
Sentence similarity captures semantic information from sentence embeddings to measure the similarity between texts. It measures Jaccard similarity and Cosine similarity.
-
Task types: Text summarization
-
Thresholds:
- Lower limit: 0.8
- Upper limit: 1
-
How it works: Higher scores indicate that the texts are more similar.
Data safety
You can use the following data safety metrics to identify whether your model's input or output contains harmful or sensitive information:
- PII
- PII measures if your model input or output data contains any personally identifiable information by using the Watson Natural Language Processing entity extraction model.
- Task types:
- Text summarization
- Content generation
- Question answering
- Retrieval Augmented Generation (RAG)
- Thresholds:
- Upper limit: 0
- How it works: Higher scores indicate that a higher percentage of personally identifiable information exists in the input or output data.
- Task types:
- HAP
- HAP measures if there is any toxic content that contains hate, abuse, or profanity in the model input or output data.
- Task types:
- Text summarization
- Content generation
- Question answering
- Retrieval Augmented Generation (RAG)
- Thesholds
- Upper limit: 0
- How it works: Higher scores indicate that a higher percentage of toxic content exists in the model input or output.
- Task types:
Readability
Readability determines how difficult the model's output is to read by measuring characteristics such as sentence length and word complexity.
-
Task types:
- Text summarization
- Content generation
-
Thresholds:
- Lower limit: 60
-
How it works: Higher scores indicate that the model's output is easier to read.
Exact match
Exact match compares model prediction strings to reference strings to measure how often the strings match.
-
Task types:
- Question answering
- Entity extraction
- Retrieval Augmented Generation (RAG)
-
Parameters:
- Regexes to ignore: Regex expressions of characters to ignore when calculating the exact matches.
- Ignore case: If True, turns everything to lowercase so that capitalization differences are ignored.
- Ignore punctuation: If True, removes punctuation before comparing strings.
- Ignore numbers: If True, removes all digits before comparing strings.
-
Thresholds:
- Lower limit: 0.8
- Upper limit: 1
-
How it works: Higher scores indicate that model prediction strings match reference strings more often.
Multi-label/class metrics
Multi-label/class metrics measure model performance for multi-label/multi-class predictions.
- Metrics:
- Micro F1 score
- Macro F1 score
- Micro precision
- Macro precision
- Micro recall
- Macro recall
- Task types: Entity extraction
- Thresholds:
- Lower limit: 0.8
- Upper limit: 1
- How it works: Higher scores indicate that predictions are more accurate.
Answer quality
You can use answer quality metrics to evaluate the quality of model answers. Answer quality metrics are calculated with LLM-as-a-judge models.
You can calculate the following answer quality metrics:
- Faithfulness
-
Faithfulness measures how grounded the model output is in the model context and provides attributions from the context to show the most important sentences that contribute to the model output. The attributions are provided when the metric is calculated with fine-tuned models only.
- Task types: Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: Higher scores indicate that the output is more grounded and less hallucinated.
- Answer relevance
-
Answer relevance measures how relevant the answer in the model output is to the question in the model input.
- Task types: Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: Higher scores indicate that the model provides relevant answers to the question.
- Answer similiarity
-
Answer similarity measures how similar the answer or generated text is to the ground truth or reference answer to determine the quality of your model performance. The answer similarity metric is supported for configuration with LLM-as-a-judge models only.
- Task types: Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: Higher scores indicate that the answer is more similar to the reference output.
- Unsuccessful requests
-
Unsuccessful requests measures the ratio of questions that are answered unsuccessfully out of the total number of questions. Watsonx.governance does not calculate the unsuccessful requests metric with fine-tuned models.
- Task types:
- Retrieval Augmented Generation (RAG)
- Question answering
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: Higher scores indicate that the model can not provide answers to the question.
- Task types:
Content analysis
You can use the following content analysis metrics to evaluate your model output against your model input or context:
- Coverage
-
Coverage measures the extent that the foundation model output is generated from the model input by calculating the percentage of output text that is also in the input.
- Task types:
- Text summarization
- Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower bound: 0
- Upper bound: 1
- How it works: Higher scores indicate that a higher percentage of output words are within the input text.
- Task types:
- Density
-
Density measures how extractive the summary in the foundation model output is from the model input by calculating the average of extractive fragments that closely resemble verbatim extractions from the original text.
- Task types:
- Text summarization
- Retrieval Augmented Generation (RAG)
- Thresholds: Lower bound: 0
- How it works: Lower scores indicate that the model output is more abstractive and on average the extractive fragments do not closely resemble verbatim extractions from the original text.
- Task types:
- Compression
-
Compression measures how much shorter the summary is when compared to the input text. It calculates the ratio between the number of words in the original text and the number of words in the foundation model output.
- Task types: Text summarization
- Thresholds: Lower bound: 0
- How it works: Higher scores indicate that the summary is more concise when compared to the original text.
- Repetitiveness
-
Repetitiveness measures the percentage of n-grams that repeat in the foundation model output by calculating the number of repeated n-grams and the total number of n-grams in the model output.
- Task types: Text summarization
- Thresholds: Lower bound: 0
- Abstractness
-
Abstractness measures the ratio of n-grams in the generated text output that do not appear in the source content of the foundation model.
- Task types:
- Text summarization
- Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower bound: 0
- Upper bound: 1
- How it works: Higher scores indicate high abstractness in the generated text output.
- Task types:
Retrieval quality
You can use the retrieval quality metrics to measure the quality of how the retrieval system ranks relevant contexts. Retrieval quality metrics are calculated with LLM-as-a-judge models.
You can calculate the following retrieval quality metrics:
- Context relevance
-
Context relevance measures how relevant the context that your your model retrieves is with the question that is specified in the prompt. When multiple context variables exist, the context relevance scores are generated when the metric is calculated with fine-tuned models only.
- Task types: Retrieval Augmented Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: Higher scores indicate that the context is more relevant to the question in the prompt.
- Retrieval precision
-
Retrieval precision measures the quanity of relevant contexts from the total of contexts that are retrieved.
- Task types: Retrieval Augment Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: A value of 1 indicates that all of the retrieved contexts are relevant. A value of 0 indicates that none of the retrieved contexts are relevant. If the score is trending upwards, the retrieved contexts are relevant to the question. If the score is trending downwards, the retrieved contexts are not relevant to the question.
- Average precision
-
Average precision evaluates whether all of the relevant contexts are ranked higher or not by calculating the mean of the precision scores of relevant contexts.
- Task types: Retrieval Augment Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: A value of 1 indicates that all the relevant contexts are ranked higher. A value of 0 indicates that none of the retrieved contexts are relevant. If the score is trending upwards, the relevant contexts are ranked higher. If the score is trending downwards, the relevant contexts are not ranked lower.
- Reciprocal rank
-
Reciprocal rank is the reciprocal rank of the first relevant context.
- Task types: Retrieval Augment Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: A value of 1 indicates that the first relevant context is at the first position. A value of 0 indicates that none of the relevant contexts are retrieved. If the score is trending upwards, the first relevant context is ranked higher. If the score is trending downwards, the first relevant context is ranked lower.
- Hit rate
-
Hit rate measures whether there is at least one relevant context among the retrieved contexts.
- Task types: Retrieval Augment Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: A value of 1 indicates that there is at least one relevant context. A value of 0 indicates that no relevant context is in the retrieved contexts. If the score is trending upwards, at least one relevant context is in the retrieved context. If the score is trending downwards, no relevant contexts are retrieved.
- Normalized Discounted Cumulative Gain
-
Normalized Discounted Cumulative Gain (NDCG) measures the ranking quality of the retrieved contexts.
- Task types: Retrieval Augment Generation (RAG)
- Thresholds:
- Lower limit: 0
- Upper limit: 1
- How it works: A value of 1 indicates that the retrieved contexts are ranked in the correct order. If the score is trending upwards, the ranking of the retrieved contexts is correct. If the score is trending downwards, the ranking of the retrieved contexts is incorrect.
Parent topic: Configuring model evaluations