About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Last updated: Oct 23, 2024
You must provide details about how your your model is set up to enable model evaluations.
You can use different methods to provide model details for evaluations. The method that you use depends on how you want to configure evaluations and the type of deployments that you want to evaluate.
Providing model details
When you add deployments, all of the required model details can be detected automatically. If detect all of the required model details are not detected, you must manually provide model details.
The following sections describe how you can provide model details for model evaluations:
Select a configuration method
For structured data models, you must provide model details by following guided steps or running a notebook to generate a configuration package that you can upload. If the deployment that you selected does not have a scoring endpoint, you must upload a configuration package.
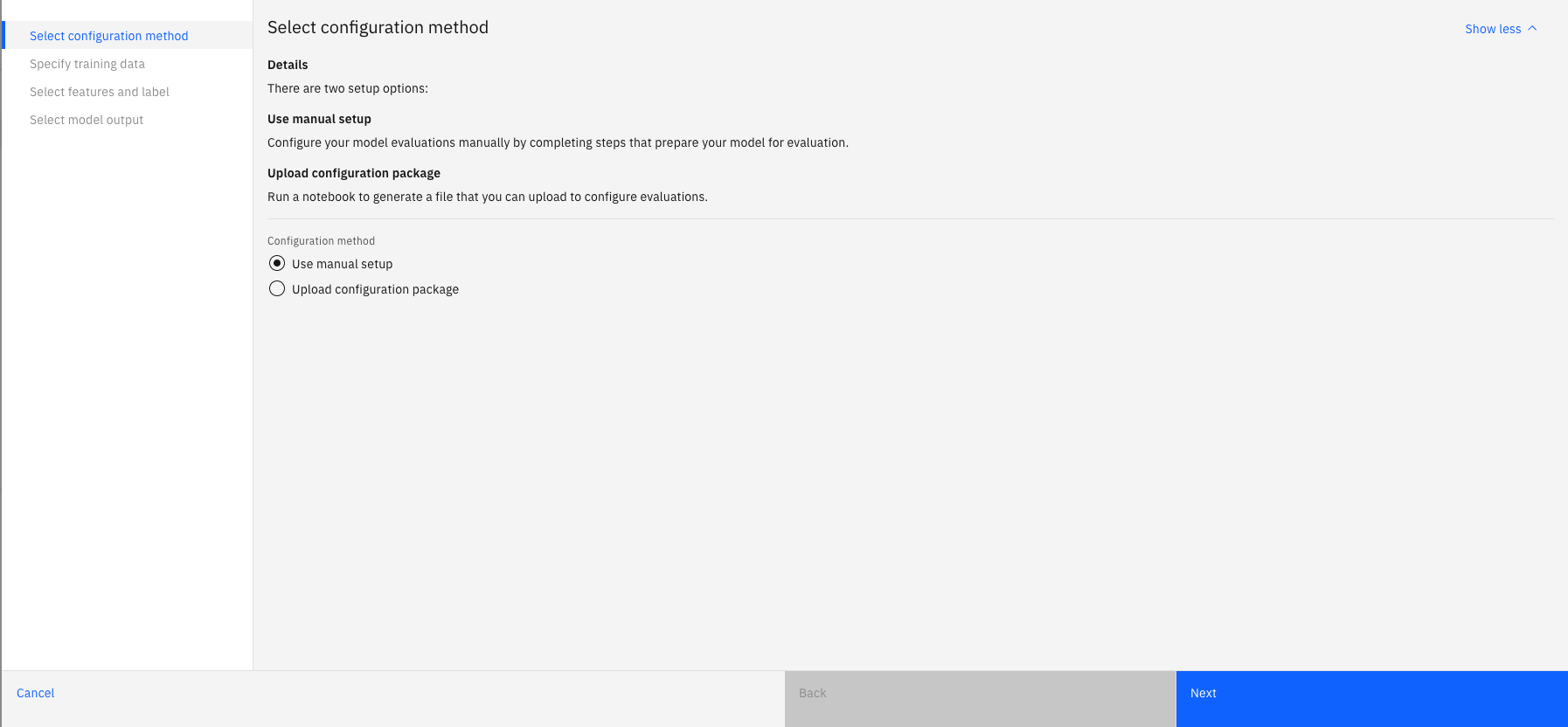
Provide a sample transaction
For image and unstructured text models, training data is not required and you must manually provide a sample transaction to specify your model output and input.
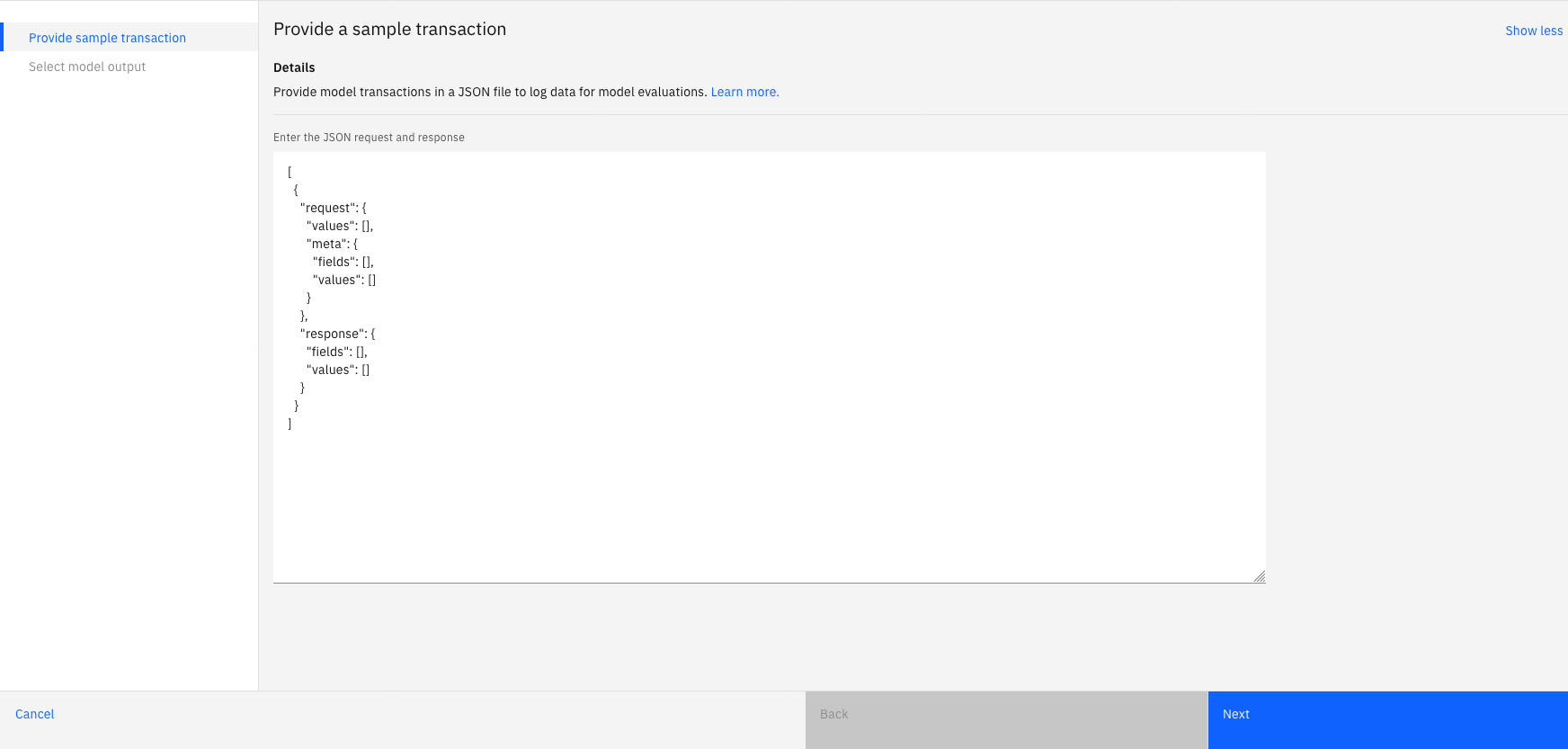
Specify training data
If your training data details are not detected when you add a deployment, you can upload a CSV file to specify training data or connect to training data that is stored in a database or cloud storage. To connect to training data, you must select the location and specify connection details. If your training data details are detected when you add a deployment, the Database or cloud storage option is preselected and the location and connection details are specified for you.
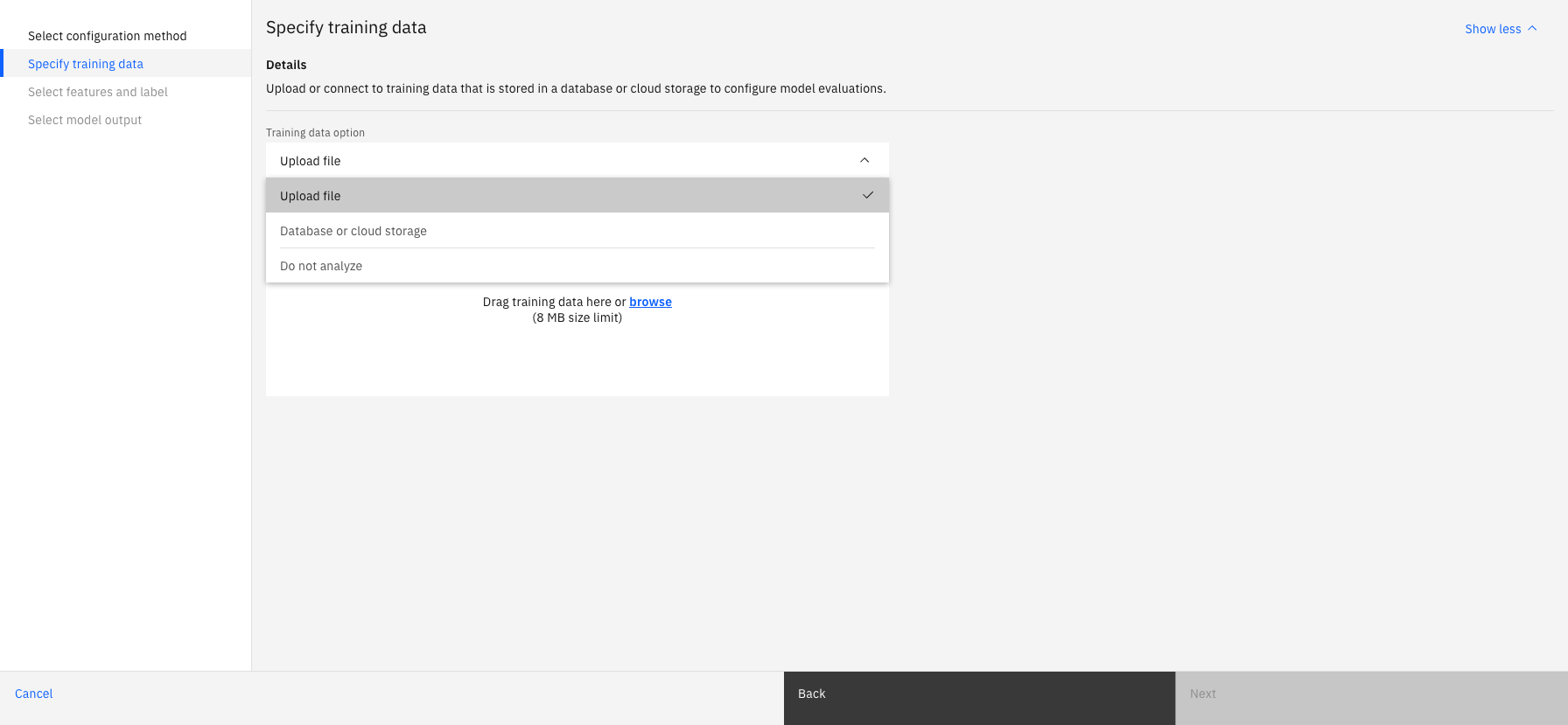
Select the feature and label columns
When the list of columns that are available in your training data are displayed, you must select the features that you used to train the model and specify a column as the Label/Target column that contains the expected or accurate class label for each record. After you select the feature and label columns, your training data is used to automatically senda a scoring request to your deployment to validate your model output and your deployment status.
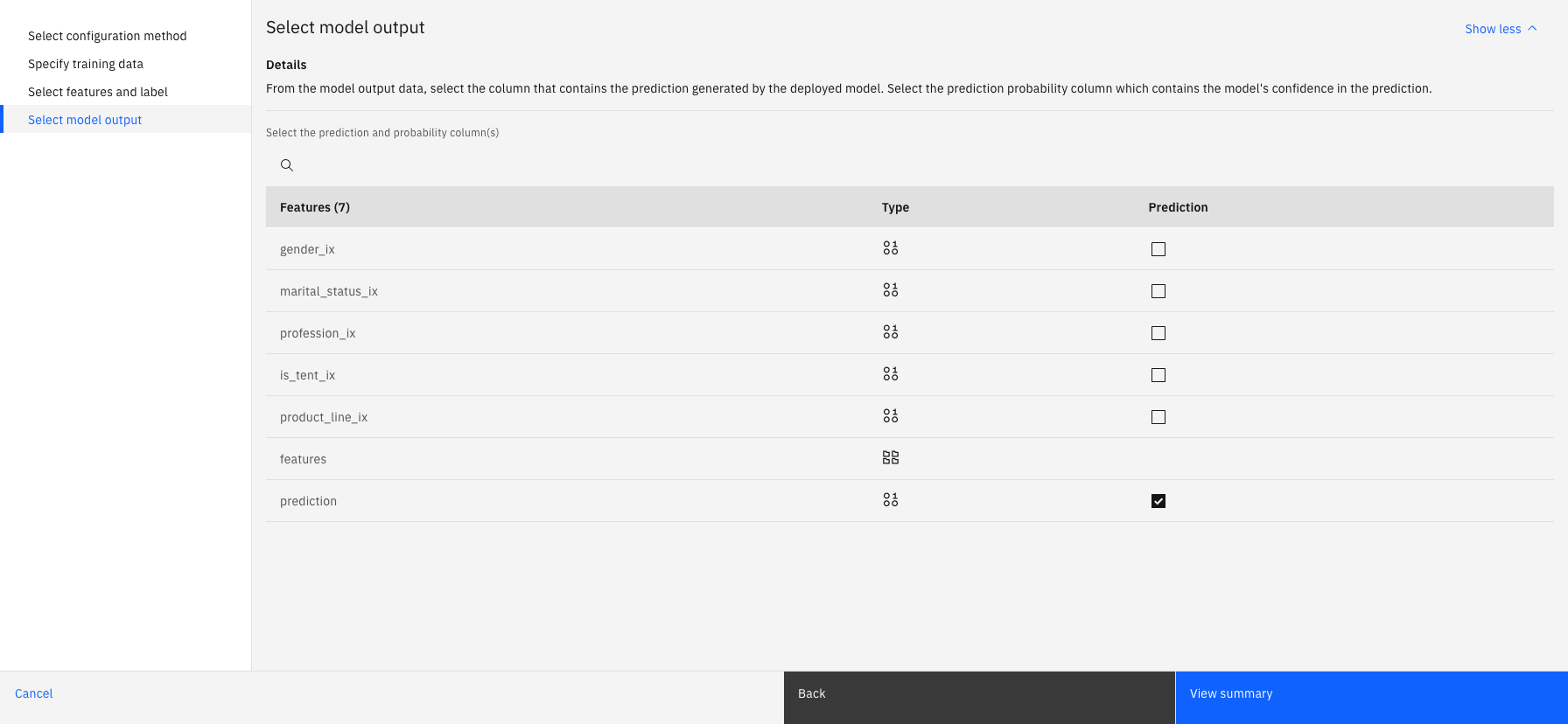
Select model output
Select a prediction column and a prediction probability column. The prediction column contains the prediction that your deployment generates and the prediction probability column contains the model's confidence in the prediction. Expected columns might get preselected based on the metadata that it identifies from your model deployment. You can choose to change these selections. The data type of the prediction column must match the data type of the label column. If the data types don't match, your model evaluations might not work properly.
Parent topic: Preparing to evaluate a model