Istnieje możliwość wyświetlenia wykresu wizualizacji dla oceny fairness, który przedstawia punkty danych dla monitorowanego elementu w wybranej godzinie.
Na panelu kontrolnym insights wybierz wdrożony model, aby wyświetlić szczegółowe informacje o skonfigurowanych monitorach.
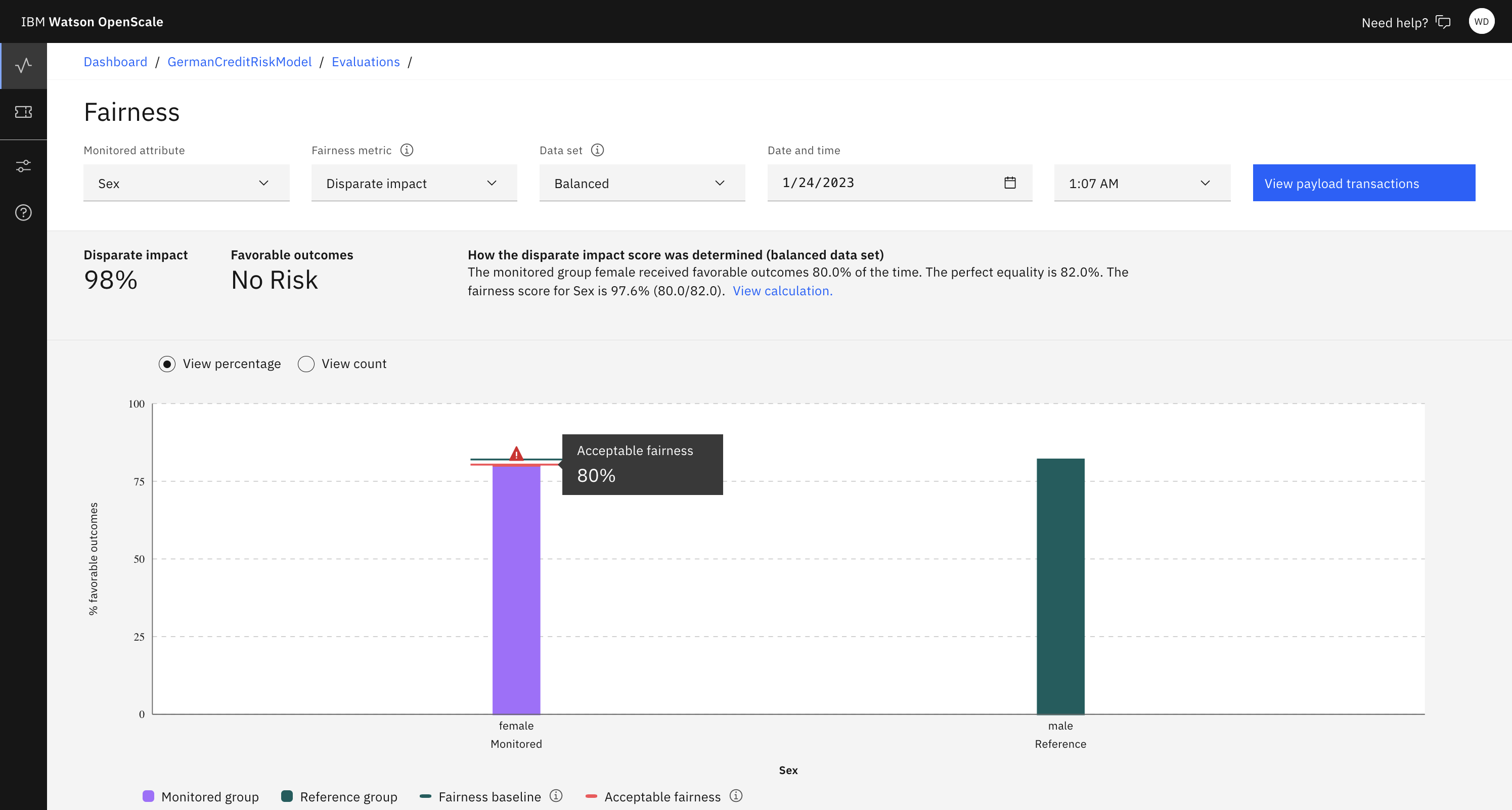
Aby wyświetlić szczegóły dotyczące konkretnej statystyki fairness, wybierz opcję Fairness (Fairness), a następnie wybierz konkretny czas z wykresu fairness (wykres fairness). Aby wybrać inną funkcję lub czas, aby przejrzeć szczegóły, można użyć filtrów, takich jak Monitorowany atrybut, Datai Czas.
Interpretowanie wykresu
Wykres udostępnia reprezentację wizualną dla następujących informacji:
Można obserwować populację, która doświadcza bias (na przykład, klienci z zakresu 18-23 lat). Wykres przedstawia również procent oczekiwanego wyniku dla tej populacji.
Wykres przedstawia wartość procentową oczekiwanego wyniku dla populacji referencyjnej, która jest średnią oczekiwanego wyniku we wszystkich populacjach referencyjnych.
Wykres wskazuje na obecność bias. Współczynnik procentowy oczekiwanych wyników dla populacji w zakresie do wartości procentowej oczekiwanych wyników dla populacji referencyjnej oraz od tego, czy przekracza próg.
Wykres przedstawia również rozkład wartości referencyjnych i monitorowanych dla każdej odrębnej wartości atrybutu w danych z tabeli ładunku, która została przeanalizowana w celu identyfikacji bias. Rozkład danych ładunku jest wyświetlany dla każdej odrębnej wartości atrybutu fairness (parzyste wartości odniesienia są wyświetlane). Te informacje mogą być używane do korelowania bias z ilością danych, które są odbierane przez model.
Dodatkowo wykres przedstawia procent populacji z oczekiwanymi wynikami. Źródłem danych bias są dane w tej grupie, które skośne wyniki i doprowadziły do zwiększenia odsetka oczekiwanych wyników dla klasy referencyjnej. Te informacje mogą być używane do identyfikowania części danych, które mogą być następnie objęte próbą podczas ponownego uczenia modelu.
Inną ważną rzeczą, jaką pokazuje wykres jest nazwa tabeli zawierającej dane, które zostały zidentyfikowane do ręcznego tworzenia etykiet. Za każdym razem, gdy algorytm wykryje bias w modelu. Identyfikuje on również punkty danych, które mogą być wysyłane w celu ręcznego etykietowania przez ludzi. Te ręcznie oznaczone dane mogą być następnie używane wraz z oryginalnymi danymi uczonymi w celu przekwalifikowania modelu. Ten przeszkolony model prawdopodobnie nie będzie miał bias. Tabela etykiet ręcznych znajduje się w bazie danych powiązanej z instancją Watson OpenScale .
Dalsze kroki
Wyświetlanie wyników poprawności dla dwukierunków pośrednich
Temat nadrzędny: Pobieranie spostrzeżeń za pomocą narzędzia Watson OpenScale