È possibile visualizzare un grafico di visualizzazione per la valutazione della correttezza, che mostra i punti di dati per una funzione monitorata in un'ora selezionata.
Dal dashboard delle informazioni approfondite, selezionare il modello distribuito per visualizzare i dettagli sui monitor configurati.
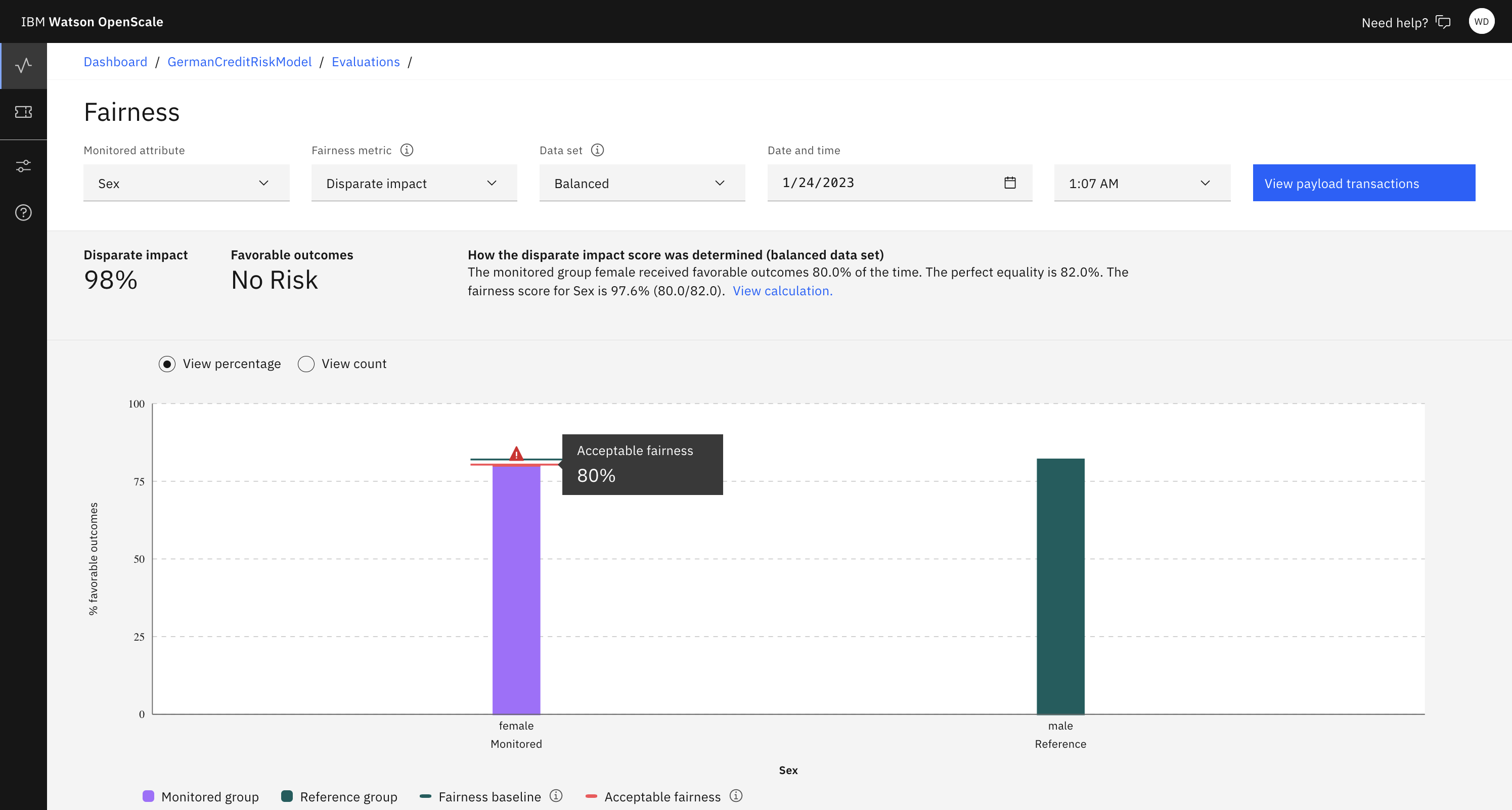
Per visualizzare i dettagli dietro una particolare statistica di correttezza, selezionare Correttezza e quindi è possibile scegliere un orario specifico dal grafico di correttezza. Per selezionare una funzione o un'ora diversa per esaminare i dettagli, è possibile utilizzare i filtri, come ad esempio Attributo monitorato, Datae Ora.
Interpretazione del grafico
Il grafico fornisce una rappresentazione visiva per le seguenti informazioni:
È possibile osservare la popolazione che sperimenta la distorsione (ad esempio, i clienti nell'intervallo 18-23 anni). Il grafico mostra anche la percentuale di risultati previsti per questa popolazione.
Il grafico mostra la percentuale di risultati previsti per la popolazione di riferimento, che è la media di risultati previsti in tutte le popolazioni di riferimenti.
Il grafico indica la presenza di distorsione. Il rapporto tra la percentuale di risultati previsti per le popolazioni nell'intervallo e la percentuale di risultati previsti per la popolazione di riferimento e se supera la soglia.
Il grafico mostra anche la distribuzione del riferimento e dei valori monitorati per ogni valore distinto dell'attributo nei dati dalla tabella payload che è stata analizzata per identificare la distorsione. La distribuzione dei dati di payload viene visualizzata per ogni valore distinto dell'attributo di correttezza (sono visualizzati anche i valori di riferimento). Queste informazioni possono essere utilizzate per correlare la distorsione con la quantità di dati ricevuti dal modello.
Inoltre, il grafico mostra la percentuale di popolazione con i risultati previsti. L'origine della distorsione sono i dati in questo gruppo, che hanno distorto i risultati e hanno portato ad un aumento della percentuale di risultati previsti per la classe di riferimento. Queste informazioni possono essere utilizzate per identificare parti dei dati che possono essere sottoposte a sottocampionamento quando si riaddestra il modello.
Un'altra cosa importante che il diagramma mostra è il nome della tabella che contiene i dati identificati per l'etichettatura manuale. Ogni volta che l'algoritmo rileva la distorsione in un modello. Identifica anche i punti di dati che possono essere inviati per l'etichettatura manuale da parte degli umani. Questi dati etichettati manualmente possono quindi essere utilizzati insieme ai dati di addestramento originali per riaddestrare il modello. Questo modello risottoposto a training è probabile che non abbia la distorsione. La tabella di etichettatura manuale è presente nel database associato all'istanza Watson OpenScale .
Passi successivi
Visualizzazione dei risultati di correttezza per la distorsione indiretta
Argomento principale: Introduzione a Watson OpenScale