カスタム機械学習フレームワークを使用して、ペイロードのロギング、フィードバックのロギング、パフォーマンス精度の測定、実行時のバイアス検出、説明可能性、ドリフト検出、モデル評価のための自動デビアス機能を完了することができます。 カスタム機械学習フレームワークは、IBM watsonx.aiRuntimeと同等でなければならない。
以下のカスタム機械学習フレームワークは、モデルの評価をサポートする:
| フレームワーク | 問題のタイプ | データ・タイプ |
|---|---|---|
| IBM watsonx.aiランタイムと同等 | 機密区分 | 構造化 |
| IBM watsonx.aiランタイムと同等 | 回帰 | 構造化 |
IBM watsonx.aiRuntime と同等でないモデルの場合、必要な REST API エンドポイントを公開するカスタムモデルのラッパーを作成する必要があります。 また、 Watson OpenScale と実際のカスタム機械学習エンジンの間で入出力をブリッジする必要があります。
カスタム機械学習エンジンが最善の選択肢になる状況
カスタム機械学習エンジンは、以下の状況が当てはまるときに最善の選択肢になります。
- すぐに使用可能な製品を使用せずに機械学習モデルにサービスを提供します。 あなたはモデルにサービスを提供するシステムを持っているが、モデル評価のためにその機能を直接サポートするものは存在しない。
- 3rd-partyから使用しているサービングエンジンは、モデル評価にまだ対応していません。 この場合は、元のデプロイメントまたはネイティブ・デプロイメントに対するラッパーとして、カスタム機械学習エンジンを開発することを検討してください。
仕組み
以下の画像は、カスタム環境のサポートを示しています。
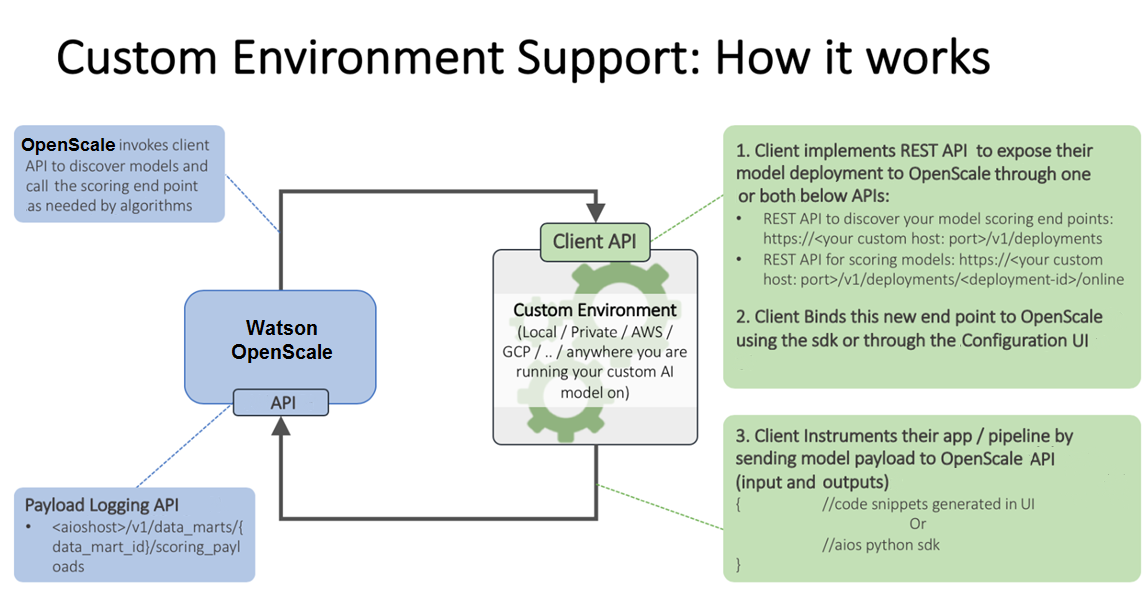
以下のリンクも参照できます。
Watson OpenScale ペイロード・ロギング API
モニターをサポートするためのモデルの入力基準
以下の例では、モデルは、基本的に名前付きフィールドとその値の集合であるフィーチャー・ベクトルを入力として取ります。
{ "fields": [ "name", "age", "position" ], "values": [ [ "john", 33, "engineer" ], [ "mike", 23, "student" ] ]“age”フィールドは公平性によって評価されることができます。入力がテンソルや行列で、入力特徴空間から変換されている場合、そのモデルは評価できない。 そのため、テキスト入力またはイメージ入力を使用するディープ・ラーニング・モデルを、バイアスの検出と緩和のために処理することもできません。
さらに、説明性をサポートするためにトレーニング・データをロードする必要があります。
テキストの説明性を確保するには、いずれかの特徴量がフルテキストでなければなりません。 カスタム・モデルのイメージに関する説明性は、現行リリースではサポートされていません。
モニターをサポートするためのモデルの出力基準
モデルは、そのモデル内のさまざまなクラスの予測確率とともに、入力特徴量ベクトルを出力します。
{ "fields": [ "name", "age", "position", "prediction", "probability" ], "labels": [ "personal", "camping" ], "values": [ [ "john", 33, "engineer", "personal", [ 0.6744664422398081, 0.3255335577601919 ] ], [ "mike", 23, "student" "camping", [ 0.2794765664946941, 0.7205234335053059 ] ] ] }この例では、
"personal”と“camping”が可能なクラスであり、各スコアリング出力のスコアが両方のクラスに割り当てられます。 予測確率が欠落している場合、バイアス検出は機能しますが、自動バイアス緩和は機能しません。モデル評価用のREST APIで呼び出すことができるライブスコアリングエンドポイントからスコアリング出力にアクセスすることができます。 CUSTOMML、AmazonSageMaker, IBM watsonx.aiRuntimeについては、Watson OpenScaleはネイティブのスコアリング・エンドポイントに直接接続する。
カスタム機械学習エンジン
カスタム機械学習エンジンは、機械学習モデルと Web アプリケーションのインフラストラクチャーとホスティング機能を提供します。 モデル評価のためにサポートされるカスタム機械学習エンジンは、以下の要件に適合していなければならない:
次の 2 つのタイプの REST API エンドポイントを公開します。
- ディスカバリー・エンドポイント (デプロイメントと詳細の GET リスト)
- 評価エンドポイント (オンラインかつリアルタイムの評価)
すべてのエンドポイントは、サポートされる swagger の仕様に準拠している必要があります。
入力ペイロードと、デプロイメントへの出力およびデプロイメントからの出力は、仕様で説明された JSON ファイル形式に準拠している必要があります。
REST API エンドポイントの仕様については、REST API を参照してください。
カスタム機械学習エンジンの追加
カスタム機械学習プロバイダーで動作するようにモデル評価を構成するには、以下のいずれかの方法を使用します:
- コンフィギュレーション・インターフェースを使用して、最初のカスタム機械学習プロバイダーを追加することができる。 詳しくは、カスタム機械学習インスタンスの指定を参照してください。
- Python SDK を使用して、機械学習プロバイダーを追加することもできます。 複数のプロバイダーが必要な場合は、この方法を使用する必要があります。 詳しくは、 カスタム機械学習エンジンの追加を参照してください。
詳細はこちら
カスタム機械学習モニターを使って、他のサービスと相互作用する方法を作ることができる。
カスタム ML サービス・インスタンスの指定
モデル評価を設定する最初のステップは、サービスインスタンスを指定することです。 サービス・インスタンスは、AI モデルとデプロイメントの格納場所となります。
カスタム・サービス・インスタンスの接続
AIモデルと配置は、モデル評価のためのサービスインスタンスで接続されている。 カスタム・サービスを接続できます。 サービスを接続するには、「Configure' タブで機械学習プロバイダーを追加し、「Edit'
タブで機械学習プロバイダーを追加し、「Edit'![]() アイコンをクリックする。 名前、説明、および 実動前 または 生産 環境タイプの指定に加えて、このタイプのサービス・インスタンスに固有の以下の情報を提供する必要があります:
アイコンをクリックする。 名前、説明、および 実動前 または 生産 環境タイプの指定に加えて、このタイプのサービス・インスタンスに固有の以下の情報を提供する必要があります:
- ユーザー名
- パスワード
https://host:port形式を使用する API エンドポイント (https://custom-serve-engine.example.net:8443など)
デプロイメントへの接続を、リストを要求することで行うか、評価エンドポイントを個々に入力することで行うかを選択します。
デプロイメントのリストの要求
「デプロイメントのリストの要求」タイルを選択した場合は、資格情報と API エンドポイントを入力してから構成を保存します。
個々の評価エンドポイントの指定
「個々の評価エンドポイントの入力」タイルを選択した場合は、API エンドポイントの資格情報を入力してから構成を保存します。
これで、デプロイされたモデルを選択し、モニターを構成する準備ができました。 ダッシュボードに追加]をクリックすると、デプロイされたモデルがInsightsダッシュボードに表示されます。 モニターするデプロイメントを選択し、 構成をクリックしてください。
詳しくは、モニタリングの構成を参照してください。
カスタム機械学習エンジンの例
以下のアイデアを使用して、独自のカスタム機械学習エンジンをセットアップします。
Python と Flask
Python および flask を使用して、scikit-learn モデルを提供することができます。
ドリフト検出モデルを生成するには、ノートブックで scikit-learn バージョン 0.20.2 を使用する必要があります。
アプリは、テスト目的でローカルにデプロイすることも、 IBM Cloud上のアプリケーションとしてデプロイすることもできます。
Node.js
ここのNode.jsで書き込まれたカスタム機械学習エンジンの例を見つけることもできます。
エンドツーエンドのコード・パターン
カスタムエンジンのデプロイとモデル評価との統合のend2endの例を示すコードパターン。
カスタム機械学習エンジンのペイロード・ロギング
IBM以外のwatsonx.aiRuntime またはカスタム機械学習エンジンにペイロードロギングを設定するには、ML エンジンをカスタムとしてバインドする必要があります。
カスタム機械学習エンジンの追加
non-watsonx.aiRuntime エンジンは、メタデータを使用してカスタムとして追加され、IBMIBMwatsonx.aiRuntime サービスとの直接的な統合は存在しない。 wos_client.service_providers.addメソッドを使えば、モデル評価のために複数の機械学習エンジンを追加することができる。
CUSTOM_ENGINE_CREDENTIALS = {
"url": "***",
"username": "***",
"password": "***",
}
wos_client.service_providers.add(
name=SERVICE_PROVIDER_NAME,
description=SERVICE_PROVIDER_DESCRIPTION,
service_type=ServiceTypes.CUSTOM_MACHINE_LEARNING,
credentials=CustomCredentials(
url= CUSTOM_ENGINE_CREDENTIALS['url'],
username= CUSTOM_ENGINE_CREDENTIALS['username'],
password= CUSTOM_ENGINE_CREDENTIALS['password'],
),
background_mode=False
).result
以下のコマンドを使用してサービス・プロバイダーを表示できます。
client.service_providers.get(service_provider_id).result.to_dict()

API キーを使用してセキュリティーを構成する
カスタム機械学習エンジンのセキュリティを設定するには、IBM CloudとIBM Cloud Pak for Dataをモデル評価の認証プロバイダーとして使用します。 https://iam.cloud.ibm.com/identity/token URL を使用して IBM Cloud の IAM トークンを生成し、 https://<$hostname>/icp4d-api/v1/authorize URL を使用して Cloud Pak for Dataのトークンを生成できます。
POST /v1/deployments/{deployment_id}/online 要求を使用して、以下の形式でスコアリング API を実装できます:
要求
{
"input_data": [{
"fields": [
"name",
"age",
"position"
],
"values": [
[
"john",
33,
"engineer"
],
[
"mike",
23,
"student"
]
]
}]
}
応答
{
"predictions": [{
"fields": [
"name",
"age",
"position",
"prediction",
"probability"
],
"labels": [
"personal",
"camping"
],
"values": [
[
"john",
33,
"engineer",
"personal",
[
0.6744664422398081,
0.32553355776019194
]
],
[
"mike",
23,
"student",
"camping",
[
0.2794765664946941,
0.7205234335053059
]
]
]
}]
}
カスタム・サブスクリプションの追加
カスタム・サブスクリプションを追加するには、次のコマンドを実行します。
custom_asset = Asset(
asset_id=asset['entity']['asset']['asset_id'],
name=asset['entity']['asset']['name'],
url = "dummy_url",
asset_type=asset['entity']['asset']['asset_type'] if 'asset_type' in asset['entity']['asset'] else 'model',
problem_type=ProblemType.MULTICLASS_CLASSIFICATION,
input_data_type=InputDataType.STRUCTURED,
)
deployment = AssetDeploymentRequest(
deployment_id=asset['metadata']['guid'],
url=asset['metadata']['url'],
name=asset['entity']['name'],
deployment_type=asset['entity']['type'],
scoring_endpoint = scoring_endpoint
)
asset_properties = AssetPropertiesRequest(
prediction_field='predicted_label',
probability_fields = ["probability"],
training_data_reference=None,
training_data_schema=None,
input_data_schema=None,
output_data_schema=output_schema,
)
result = ai_client.subscriptions.add(
data_mart_id=cls.datamart_id,
service_provider_id=cls.service_provider_id,
asset=custom_asset,
deployment=deployment,
asset_properties=asset_properties,
background_mode=False
).result
サブスクリプション・リストを取得するには、以下のコマンドを実行します。
subscription_id = subscription_details.metadata.id
subscription_id
details: wos_client.subscriptions.get(subscription_id).result.to_dict()
ペイロード・ロギングの有効化
サブスクリプションでペイロード・ロギングを有効にするには、次のコマンドを実行します。
request_data = {'fields': feature_columns,
'values': [[payload_values]]}
ロギングの詳細を取得するには、次のコマンドを実行します。
response_data = {'fields': list(result['predictions'][0]),
'values': [list(x.values()) for x in result['predictions']]}
評価とペイロード・ロギング
モデルを評価します。
ペイロード・ロギング・テーブルに要求と応答を格納します
records_list = [PayloadRecord(request=request_data, response=response_data, response_time=response_time), PayloadRecord(request=request_data, response=response_data, response_time=response_time)] subscription.payload_logging.store(records=records_list)
Python 以外の言語の場合は、REST API を使用してペイロードをログに記録することもできます。