With Evaluation Studio, you can evaluate and compare your generative AI assets with quantitative metrics and customizable criteria that fit your use cases. Evaluate the performance of multiple assets simultaneously and view comparative analyses of results to identify the best solutions.
You can use Evaluation Studio to streamline your generative AI development process by automating the process of evaluating multiple AI assets for various task types. Instead of individually reviewing each prompt template and manually comparing their performance, you can configure a single experiment to evaluate multiple prompt templates simultaneously, which can save time during development.
The following features are included in Evaluation Studio to help you evaluate and compare prompt templates to identify the best-performing assets for your needs:
-
Customizable experiment setup
- Choose from different task types to match your specific needs.
- Upload test data by selecting project assets.
- Select up to five prompt templates to evaluate and compare.
- Choose evaluation dimensions to configure task-specific metrics.
-
Flexible results analysis
- View results in table or chart formats to help gather insights.
- Select reference prompt templates to make easier comparisons
- Filter or sort results by specific metrics or values.
- Search across evaluation results with value ranges.
- Compare multiple prompt templates side-by-side with charts.
- Capture evaluation details automatically in AI Factsheets to track performance across AI use cases.
- Create custom rankings to prioritize the results that are most important for your use case.
- Add or remove prompt templates from experiments and rerun evaluations to make new comparisons.
Requirements
You can compare AI assets in Evaluation Studio if you meet the following requirements:
Required roles
You must be assigned the Service access: Reader role in watsonx.governance to use Evaluation Studio. You must also be assigned the Admin or Editor roles for your project and the Writer role for the Cloud Object Storage bucket that you use for your project.
Service plans
Evaluation Studio is restricted to certain service plans and data centers. For details, see watsonx.ai Studio service plans and Regional availability for services and features.
Prompt templates
The following restrictions currently apply when you evaluate and compare prompt templates in Evaluation Studio:
- Prompt template evaluations can be run only in projects.
- Prompt template evaluation results always display details of the latest evaluation that you run.
- You can't run a prompt template evaluation if an evaluation is still running for the same prompt template.
- You must evaluate at least two prompt templates.
- Detached prompt templates can't be evaluated.
- Prompt templates must be in the same project.
- Prompt templates must have the same number and name of variables.
- Prompt templates must be mapped to the same column name in test data.
- Prompt templates can't be imported or exported for any type of model.
- The same task type must be associated with each prompt template.
- The following task types are supported for prompt templates:
- Classification
- Summarization
- Generation
- Question answering
- Entity extraction
- Retrieval-augmented generation
Each prompt template can be associated with the same or different foundation models.
Test data
The test data that you upload must contain reference output and input columns for each prompt variable. Reference output columns are used to calculate reference-based metrics such as ROUGE and BLEU. For more information, see Managing data for model evaluations.
Resource usage
The resources that you need to use Evaluation Studio are calculated per experiment. Each evaluation that you run is calculated as one experiment. Higher numbers of prompt templates, evaluation records, and monitoring dimensions require more resources per experiment.
The following section describes how to evaluate and compare AI assets with Evaluation Studio:
Comparing and evaluating multiple AI assets
You can complete the following steps to evaluate and compare assets with Evaluation Studio:
- Select the evaluation task.
- On the Assets tab in your watsonx.governance project, select New asset.
- In the What do you want to do window, select the Evaluate and compare prompts task tile.
- Set up the evaluation. When the Evaluate and compare prompts wizard opens and displays the task types that are available for evaluations, specify an evaluation name and select the task type that is associated with the prompt templates that you want to evaluate.
- Select the prompt templates from your project that you want to evaluate and compare.
- Select metrics.
Watsonx.governance automatically selects the metrics that are available for the task type of the prompt templates and configures default settings for each metric. You can change the metric selections or select Configure to configure your evaluations with customized settings. - Select test data by selecting an asset from your project.
When you select test data, watsonx.governance automatically detects the columns that are mapped to your prompt variables. - Review and run the evaluation.
- Before you run your prompt template evaluation, you can review the selections for the task type, the uploaded test data, metrics, and the type of evaluation that runs.
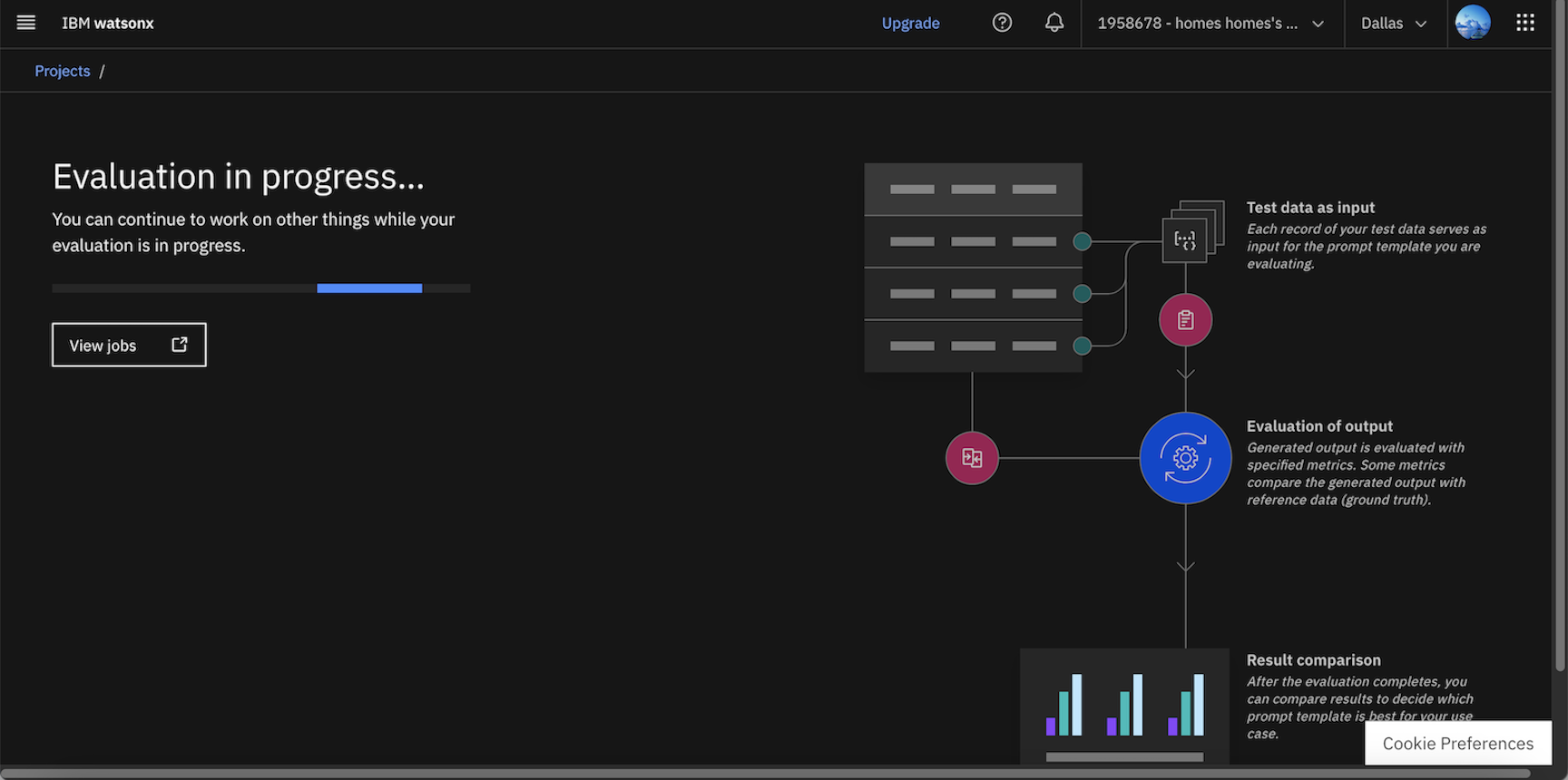
- After your run your evaluation, you can select View jobs to view a list that shows the status of the evaluation while it is in progress and previous evaluations that you have completed.
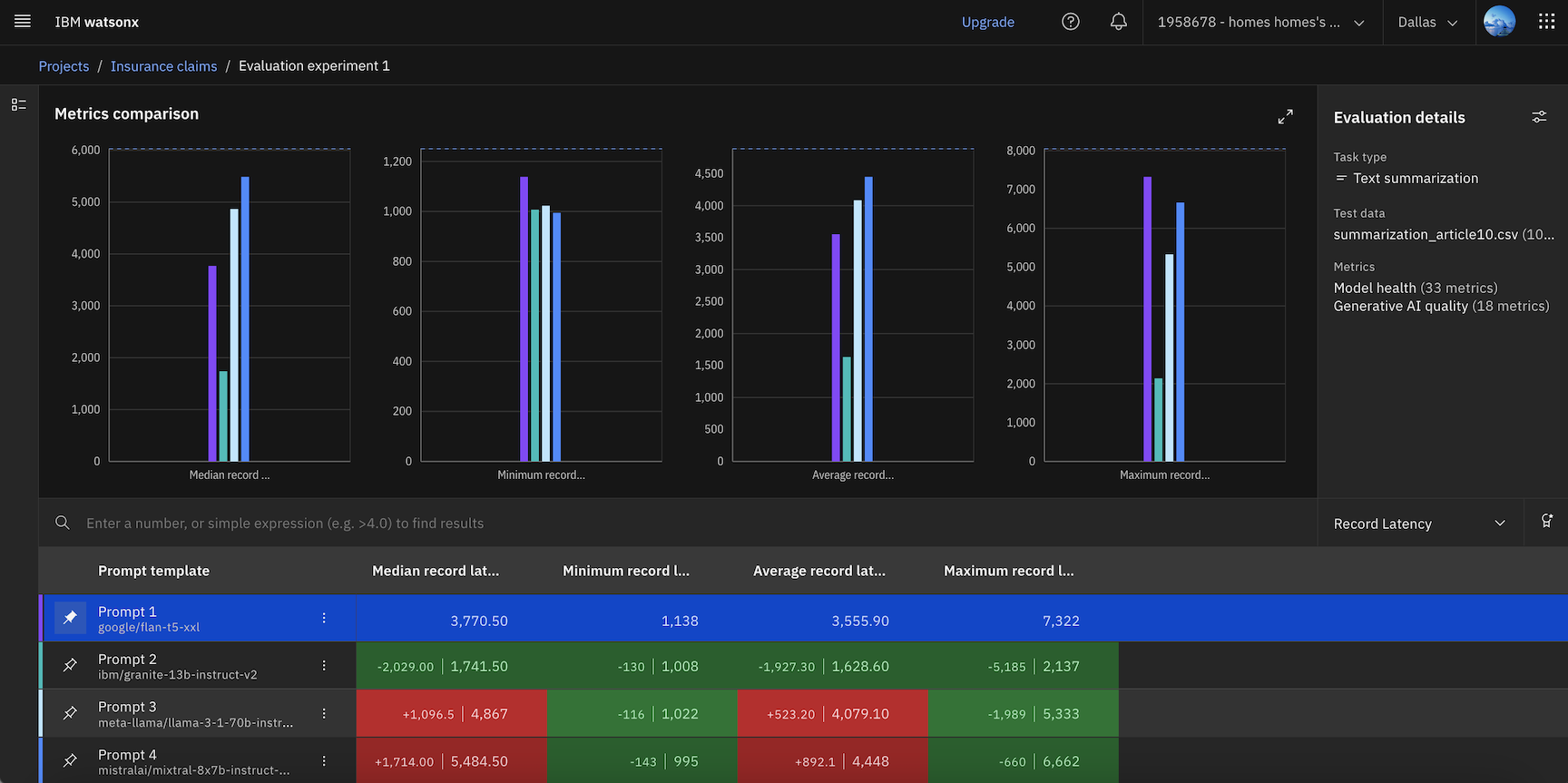
- Review the metrics comparison.
- When your evaluation completes, you can view data visualizations that compare results for each prompt template that you selected. The visualizations display whether scores violate the thresholds for each metric. Results are also displayed in a table that you can use to analyze results by selecting, filtering, or ranking the metrics that you want to view for your assets.
- To make comparisons, select a reference asset to highlight columns in the table to show whether other assets are performing better or worse than the asset that you select.
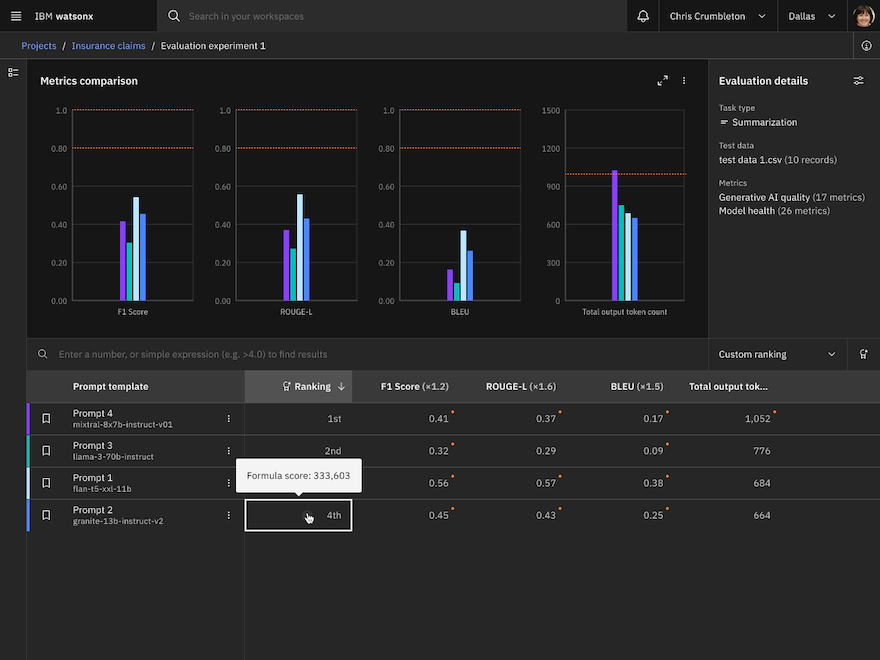
- To analyze results, you can also create a custom ranking of metrics across different groups by specifying weight factors and a ranking formula to determine which prompt templates have the best performance.
- If you want to run the evaluations again, click Adjust settings
 in the Evaluation details pane to update test data or reconfigure metrics.
in the Evaluation details pane to update test data or reconfigure metrics. - If you want to edit the experiment, click Edit Assets
 to remove or add assets to your evaluation to change your comparison.
to remove or add assets to your evaluation to change your comparison.
Next steps
You have now created a new AI evaluation asset in your project. You can reopen the asset in your project to edit or run new experiments.
Learn more
Parent topic: Evaluating AI models.