Translation not up to date
Utwórz grupę elementów, aby zachować zestaw kolumn zasobu danych wraz z powiązanymi metadanymi w celu użycia z modelami Machine Learning . Opublikuj grupy składników w produkcie IBM Watson Knowledge Catalog , aby można go było używać jako składnicy składników. Grupy składników w programie Watson Knowledge Catalog mogą być przeszukiwane i wykorzystywane ponownie przez innych użytkowników bez konieczności uzyskiwania dostępu do projektu.
Wymagania i ograniczenia
Istnieje możliwość wyświetlenia grupy składników dla zasobów w następujących okolicznościach.
- Wymagana usługa
- Te usługi muszą być dostępne.
- Watson Studio (dla projektów)
- Watson Knowledge Catalog (dla katalogów)
- wymagane uprawnienia
- Aby wyświetlić tę stronę, użytkownik może mieć dowolną rolę w projekcie lub katalogu.
- Aby edytować lub zaktualizować informacje na tej stronie, użytkownik musi mieć przypisaną rolę Edytujący lub Administrator w projekcie lub katalogu.
- Miejsca pracy
- Grupę składników zasobów można wyświetlić w następujących obszarach roboczych:
- Projekty
- Katalogi
- Typy zasobów
- Te typy zasobów aplikacyjnych mogą mieć grupę składników:
- Tabelaryczne: CSV, TSV, Parkiet, xls, xslx, avro, text, pliki json
- Połączone typy danych , które są ustrukturyzowane i obsługiwane zarówno w produkcie Watson Studio , jak i w produkcie Watson Knowledge Catalog .
- Typy zasobów
- Te typy zasobów aplikacyjnych mogą mieć grupę składników:
- Tabelaryczne: CSV, TSV, Parkiet, xls, xslx, avro, text, pliki json
- Połączone typy danych , które są ustrukturyzowane i obsługiwane w programie Watson Studio.
- Wielkość danych
- Brak limitu
Grupy składników (beta)
Użyj opcji Watson Knowledge Catalog jako składnicy składników, w której można zapisywać i dodawać adnotacje do zasobów danych w celu ich użycia w organizacji. Utwórz grupę składników , aby zachować zestaw kolumn danego zasobu danych wraz z metadanymi używannymi dla Machine Learning. Jeśli na przykład istnieje zestaw funkcji dla modelu zatwierdzania uznania, można zachować funkcje używane do uczenia modelu, a także niektóre metadane, w tym kolumny, które są używane jako cel predykcji, i które kolumny są używane do wykrywania bias. Grupy składników ułatwiają zachowanie metadanych dla funkcji używanych do uczenia modelu uczenia maszynowego, tak aby inni naukowcy danych mogli korzystać z tych samych funkcji. Po wyświetleniu podglądu konkretnego zasobu można wyświetlić kartę grupy składników.
- Tworzenie grupy składników
- Edytowanie grupy składników
- Usuwanie składników lub grupy składników
- Współużytkowanie grupy składników z katalogiem
- Korzystanie z interfejsu API Python dla grup składników
Tworzenie grupy składników w projekcie
Zanim rozpoczniesz
Jeśli przed utworzeniem grupy składników zostanie utworzony profil dla zasobu danych, można wybrać metadane profilu w celu dodania wartości do składnika.
Tworzenie grupy składników
Istnieje możliwość wybrania konkretnych kolumn zasobów danych w celu utworzenia grupy składników.
Na karcie Zasoby projektu kliknij nazwę odpowiedniego zasobu, aby otworzyć podgląd, a następnie wybierz kartę Grupa składników . W tym miejscu można utworzyć grupę składników lub wyświetlić i edytować istniejącą. Zasób może mieć tylko jedną grupę składników. Kliknij opcję Nowa grupa składników.

Wybierz kolumny, które mają być używane w grupie składników. Zaznacz pole wyboru Nazwa , aby uwzględnić wszystkie kolumny jako składniki.

Istnieje również możliwość utworzenia grupy składników dla zasobów danych w Watson Knowledge Catalog. Więcej informacji na ten temat zawiera sekcja Zasoby katalogu .
Edytowanie grupy składników
Po wybraniu kolumn zasobu danych, które mają być używane w grupie składników, można wyświetlić każdą opcję i edytować ją w celu określenia roli, jaką będzie ona miała w modelach Machine Learning .

Kliknij nazwę składnika i kliknij opcję Edytuj tę funkcję. Zostanie otwarte okno, w którym wyświetlane są następujące karty:
Szczegóły -podaj następujące informacje na temat składnika. Wybierz opcję Rola , która ma zostać przypisana do składnika:
Input: składnik może być używany jako dane wejściowe do uczenia modelu Machine Learning .Target: funkcja, która ma być używana jako cel predykcji, gdy dane są używane do uczenia modelu Machine Learning .Identifier: klucz podstawowy, taki jak identyfikator klienta, używany do identyfikowania danych wejściowych.
Wprowadź wartość w polu Opis, Przepis (dowolna metoda lub formuła używana do tworzenia wartości dla składnika) i dowolny Znaczniki.
Opisy wartości Opisy wartości umożliwiają wyjaśnienie znaczenia konkretnych wartości. Na przykład, należy rozważyć kolumnę "ocena kredytowa" z wartościami -1, 0 i 1. Opisy wartości mogą być używane w celu zapewnienia znaczenia dla tych wartości. Na przykład wartość -1 może oznaczać, że "wartościowanie zostało odrzucone". Można wprowadzić opisy dla konkretnych wartości. W przypadku wartości liczbowych można również określić zakres. Aby określić zakres wartości liczbowych, wprowadź następujący tekst [ n, m] , gdzie n to początek, a m to koniec zakresu, otoczony nawiasami kwadratowymi, a następnie kliknij przycisk Dodaj. Na przykład, aby opisać wszystkie wartości wieku od 18 do 24 jako "łagodne", należy wprowadzić [ 18,24] jako wartość i milleniały jako opis. Jeśli użytkownik ma zdefiniowany profil , wartości profilu są wyświetlane na liście opisów wartości. W tym miejscu można wybrać jedną wartość lub wiele wartości.
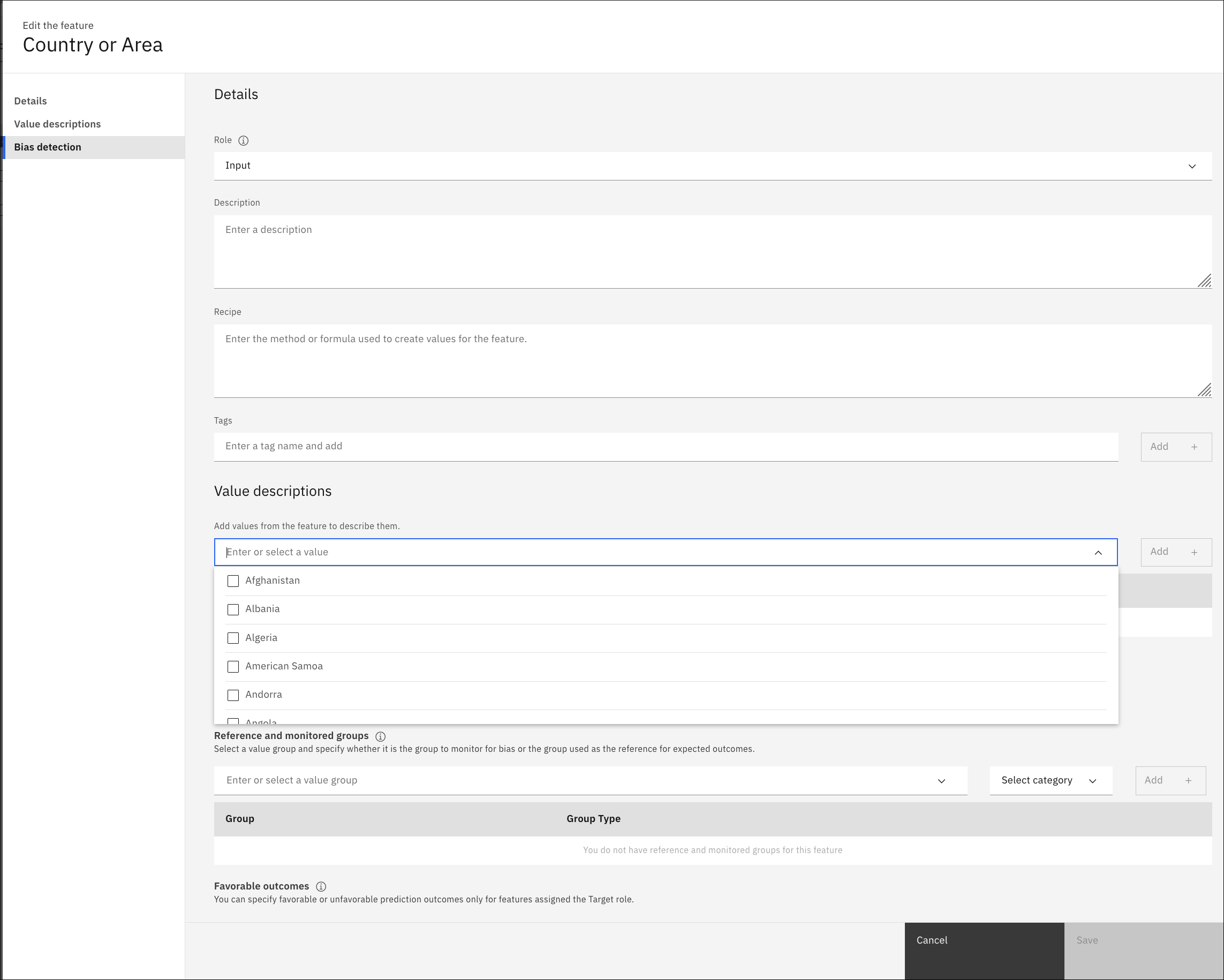
Informacje o Fairness Można zdefiniować grupy wartości
MonitorlubReferencedla monitorowania danych dwukierunkowe. Wartości, które są bardziej narażone na ryzyko związane z tendencyjnymi wynikami, mogą być umieszczane w grupie monitorowania. Wartości te są następnie porównywane z wartościami w grupie odwołań. Aby określić zakres wartości liczbowych, należy wprowadzić następujący tekst: [ n, m] , gdzie n to początek, a m to koniec zakresu, w nawiasach kwadratowych. Na przykład, aby monitorować wszystkie wartości wieku w zakresie od 18 do 35, należy wprowadzić wartość [ 18,35]. Następnie wybierz opcję Monitor lub Reference, a następnie kliknij przycisk Dodaj. Można również określić Ulubione wyniki. Więcej informacji na temat fairness zawiera sekcja Fairness in AutoAI experiments .
Po zmodyfikowaniu składnika kliknij przycisk Zapisz. Teraz można wyświetlić zmiany w oknie Szczegóły funkcji . Zamknij to okno, aby powrócić do grupy składników.
Usuwanie składników z grupy
Aby usunąć składnik z grupy:
Wyświetl podgląd zasobu aplikacyjnego w projekcie i wybierz kartę Grupa składników .
W wyświetlonym tabeli Funkcje wybierz składnik (lub składniki), który ma zostać usunięty.
Na pasku narzędzi, który zostanie wyświetlony, wybierz opcję Usuń z grupy.

Opcja lub grupa składników, jeśli wybrano wszystkie składniki, zostanie usunięta.
Wyszukiwanie grupy składników
Możliwe jest wyszukiwanie zasobów lub kolumn we wszystkich katalogach i projektach. Aby odfiltrować wyniki wyszukiwania w celu znalezienia zasobów z grupą składników, należy wybrać opcję Dane , aby wyświetlić opcje filtru, a następnie wybrać opcję Grupa składników. Zasoby zawierające grupę składników zostaną następnie wyświetlone w wynikach wyszukiwania.
Korzystanie z interfejsu API Python do tworzenia i używania grup składników
Do tworzenia i edytowania grup składników można również użyć biblioteki assetframe-lib Python w podręcznikach. Ta biblioteka umożliwia również korzystanie z metadanych składnika, takich jak informacje o godziwości podczas tworzenia modeli uczenia maszynowego.
Więcej inform.
Przykłady tworzenia i używania grup składników w notatnikach:
- Przykładowy projekt Tworzenie i korzystanie z danych składnicy składników w galerii
Patrz także:
- Wyszukiwanie zasobów w produkcie Watson Knowledge Catalog
- Wyszukiwanie zasobów aplikacyjnych we wszystkich katalogach i projektach
- Wyświetlanie zasobów w katalogach
- Edytowanie zasobów w katalogach
- Publikowanie zasobów aplikacyjnych projektu w katalogu
Temat nadrzędny: Przygotowywanie danych