Translation not up to date
Podczas projektowania reguły ochrony danych należy określić kryteria wymuszania reguły i odpowiedniego działania wymuszania. Kryteria mogą obejmować użytkowników, którzy mają wpływ na dane, klasyfikacji zasobu danych lub innych metadanych przypisanych do zasobu danych. Działaniem wymuszania może być albo zablokowanie dostępu do wszystkich danych w zasobie, maskowanie części danych lub filtrowanie wierszy z danych.
wymagane uprawnienia
Użytkownik musi mieć następujące uprawnienia użytkownika:
- Aby utworzyć reguły ochrony danych, użytkownik musi mieć uprawnienie Zarządzanie regułami ochrony danych .
- Aby uwzględnić artefakty zarządzania w regułach, użytkownik musi mieć uprawnienie Artefakty zarządzania dostępem , a użytkownik musi być współpracownikiem w kategoriach artefaktów zarządzania, które mają być używane w regule.
Jeśli nie masz uprawnień, poproś administratora platformy o nadanie im uprawnień.
Właściwości zasad ochrony danych
Właściwości i zachowanie reguł ochrony danych różnią się znacząco od innych artefaktów zarządzania.
| Właściwość lub zachowanie | Czy obsługuje? | Objaśnienie |
|---|---|---|
| Czy muszą mieć unikalne nazwy? | Tak | Każda reguła ochrony danych musi mieć unikalną nazwę. |
| Opis? | Tak | Opisz to, co reguła robi w języku naturalnym, tak aby łatwo było zrozumieć. Dołącz standardowe słowa i terminy, aby ułatwić wyszukiwanie tej reguły. |
| Czy dodać relacje do innych reguł? | Nie | Zasady ochrony danych nie mają ze sobą związków. |
| Czy dodać relacje do innych artefaktów zarządzania? | Tak | Istnieje możliwość dodawania artefaktów zarządzania w definicjach reguł ochrony danych. Reguła ochrony danych zostanie wyświetlona na karcie Treść pokrewna w artefaktach zarządzania, które są uwzględnione w definicji. Można również dodać reguły ochrony danych do strategii. Reguły ochrony danych są jednak wymuszane niezależnie od tego, czy są one uwzględniane w opublikowanych strategiach. |
| Czy dodać relację do zasobu aplikacyjnego? | Tak | Patrz sekcja Relacje zasobów w katalogach. |
| Czy dodać właściwości niestandardowe? | Nie | Reguły ochrony danych nie obsługują właściwości niestandardowych. |
| Czy dodać relacje niestandardowe? | Nie | Reguły ochrony danych nie obsługują relacji niestandardowych. |
| Organizuj w kategoriach? | Nie | Reguły ochrony danych nie są kontrolowane przez kategorie. Są one wymuszane we wszystkich katalogach zarządzanych na platformie i widoczne dla wszystkich użytkowników. |
| Czy zaimportować z pliku? | Nie | Każdą regułę ochrony danych należy utworzyć osobno. |
| Czy wyeksportować do pliku? | Nie | Nie można wyeksportować reguły ochrony danych. |
| Zarządzane przez przepływy pracy? | Nie | Reguły ochrony danych są publikowane i aktywne po utworzeniu. |
| Czy określić daty rozpoczęcia i zakończenia? | Nie | Reguły ochrony danych są aktywne po utworzeniu i dopóki nie zostaną usunięte. |
| Przypisać Steward? | Nie | Zasady ochrony danych nie mają steków. |
| Czy dodać znaczniki? | Tak | Mimo że nie można dodawać znaczników jako właściwości do reguł ochrony danych, można uwzględnić znaczniki w definicjach reguł ochrony danych. |
| Przypisać do zasobu? | Tak | Mimo że nie można ręcznie przypisać reguł ochrony danych do zasobów, reguły są wymuszane dla zasobów, gdy zasoby są zgodne z kryteriami reguły. |
| Przypisać do kolumny w zasobie danych? | Tak | Mimo że nie można ręcznie przypisać reguły ochrony danych do kolumny w zasobie, reguły ochrony danych mogą maskować wartości kolumny, gdy kolumna jest zgodna z dyrektywami bloku reguł i bloku działania reguły. |
| Zautomatyzowane przypisanie podczas profilowania lub wzbogacania? | Nie | Reguły ochrony danych są wymuszane, gdy użytkownik próbuje uzyskać dostęp do zasobu danych. |
| Predefiniowane artefakty w kategorii [ uncategorized] ? | Nie | Należy utworzyć wszystkie reguły ochrony danych. |
Zasady ochrony danych składają się z dwóch komponentów:
Kryteria
Kryteria określają warunki wymuszania reguły ochrony danych. Kryteria składają się z jednego lub więcej warunków. Każdy warunek składa się z predykatu, operatora porównania i jednej lub większej liczby wartości wejściowych.
Proces konfigurowania kryteriów polega na wybraniu typu predykatu w celu zdefiniowania zasobu lub atrybutu użytkownika, operatora porównania oraz konkretnych wartości predykatu, z którym ma zostać porównany. Następnie można łączyć predykaty i warunki z operatorami boolowskim AND lub OR w celu utworzenia zagnieżdżonych struktur logicznych o dokładnych kryteriach.
Typy predykatów
| Predykat | Opis | Wartości wejściowe |
|---|---|---|
| Alokacja | Globalnie unikalny identyfikator (GUID) zasobu, na przykład 4899251b-6073-4f25-9601-fc70fca1f9a9. |
Wprowadź jeden lub większą liczbę identyfikatorów zasobów, rozdzielając je przecinkami za pomocą interfejsu API danychWatson. |
| Nazwa zasobu | Nazwa zasobu, na przykład SALES_LEADS. |
Wprowadź jedną lub więcej nazw zasobów, rozdzielając je przecinkami. |
| Właściciel zasobu | Adres e-mail użytkownika, który jest właścicielem zasobu w katalogu, na przykład [email protected]. |
Wyszukaj, a następnie wybierz jeden lub kilka adresów e-mail. |
| Schemat zasobu | Schemat połączonego zasobu, na przykład db2_conn1. |
Wprowadź jeden lub większą liczbę schematów zasobów, rozdzielając je przecinkami. |
| Termin biznesowy | Termin biznesowy przypisany do zasobu lub do kolumny, na przykład work phone number. |
Wyszukaj, a następnie wybierz opublikowany termin biznesowy. |
| Katalog | Globalnie unikalny identyfikator (GUID) katalogu zawierającego zasób aplikacyjny, na przykład 46a19524-bfbf-4810-a1f0-b131f12bc773. |
Wprowadź jeden lub więcej identyfikatorów katalogów, rozdzielając je przecinkami za pomocą interfejsu API danychWatson. |
| Danych | Typ informacji poufnych w zasobie aplikacyjnym, na przykład Confidential lub Personally Indentifiable Information. |
Wyszukaj, a następnie wybierz jedną lub więcej klasyfikacji. |
| Nazwa kolumny | Nazwa kolumny w zasobie aplikowym, na przykład FNAME, LNAME, CLAIM_ID. |
Wprowadź jedną lub więcej nazw kolumn, oddzielając je przecinkami. |
| klasa danych | Klasa danych, która jest przypisana do kolumny, która klasyfikuje treść danych, na przykład Customer Number, Date of Birthlub City. |
Wyszukaj, a następnie wybierz opublikowaną klasę danych. |
| Znacznik | Znacznik, który jest przypisany do zasobu lub kolumny, na przykład Marketing, Client Informationlub Claim. |
Wprowadź jeden lub więcej znaczników, rozdzielając je przecinkami. |
| Nazwa użytkownika | Nazwa lub adres e-mail użytkownika, na przykład [email protected]. |
Wyszukaj, a następnie wybierz jeden lub kilka adresów e-mail. |
| Grupa użytkowników | Nazwa grupy użytkowników, która jest współpracownikiem katalogu, na przykład people managers lub finance group. |
Wyszukaj, a następnie wybierz jedną lub kilka grup użytkowników. |
| Predykaty niestandardowe | Predykat zdefiniowany przez użytkownika, który jest odwzorowyany na atrybut użytkownika niestandardowego lub atrybut niestandardowego zasobu danych. | Utwórz predykaty zdefiniowane przez użytkownika za pomocą Interfejs API danych produktu Watson. |
porównania, operatory
| Operator | Opis | Wartości wejściowe |
|---|---|---|
| jest równe | Dokładne porównanie zgodności, zwykle używane dla identyfikatorów atrybutów, takich jak identyfikatory katalogów lub identyfikatory zasobów. Na przykład: "Zatwierdzanie pożyczek" i "Finansowanie". | Wyszukaj, a następnie wprowadź identyfikatory jednej lub większej liczby wartości rozdzielanych przecinkami, używając interfejsu API danych Watson dla identyfikatorów zasobów lub identyfikatorów katalogu. |
| zawiera dowolny | Filtruje typ predykatu dla zasobów, które zawierają którekolwiek z wymienionych wartości dla tego atrybutu. Na przykład zasoby, które zawierają dowolny znacznik "poufny", "wrażliwy" lub "finansowy". | Wyszukaj, a następnie wprowadź jedną lub więcej wartości rozdzielonych przecinkami. |
| nie zawiera żadnego | Filtruje typ predykatu dla zasobów, które nie zawierają żadnej z wymienionych wartości dla tego atrybutu. Na przykład: zasoby, które nie zawierają żadnego znacznika "poufne", "wrażliwe" lub "finansowe". | Wyszukaj, a następnie wprowadź jedną lub więcej wartości rozdzielonych przecinkami. |
| zgodne | Filtruje wartość predykatu dla wzorca określonego jako wyrażenie regularne, na przykład "FINANCE. *". lub "(USER | CUSTOMER). +" | Wprowadź wyrażenia regularne rozdzielone przecinkami. |
Na przykład zagnieżdżanie w różnych metodach w kryteriach może generować różne wyniki z tymi samymi predykatami.
Następujące kryteria tworzą regułę, która maskuje dane, które mają konkretną klasyfikację oraz określoną klasę danych lub konkretną kadencję biznesową.
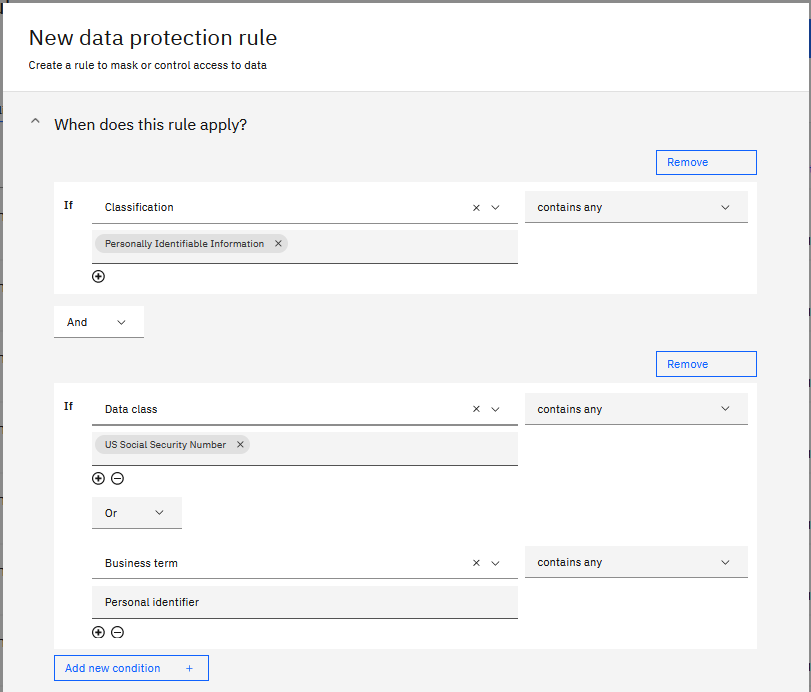
Następujące kryteria tworzą regułę, która maskuje dane, które mają określoną klasyfikację oraz konkretną klasę danych lub która ma określony termin biznesowy:
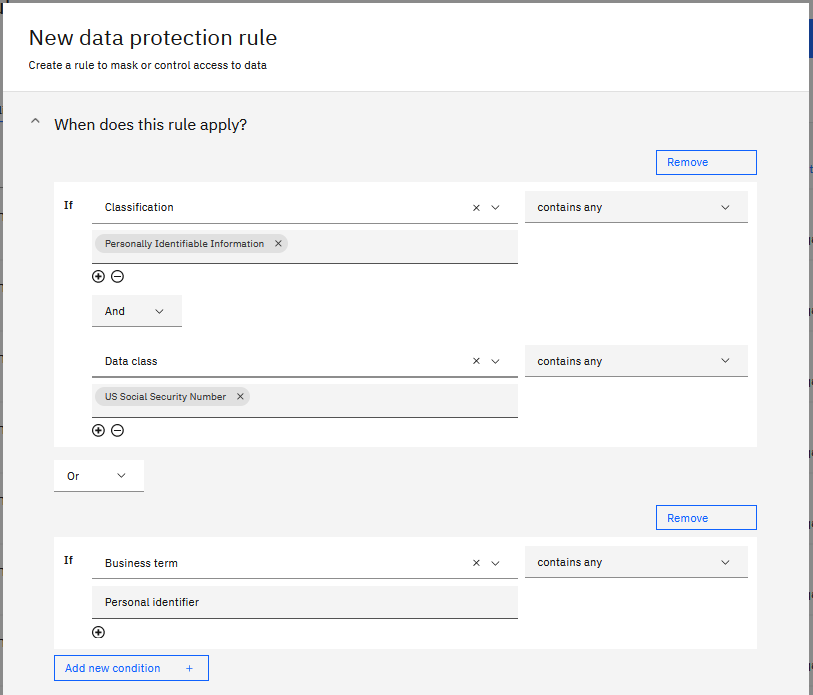
Działania
Działanie reguły ochrony danych definiuje efekt wymuszenia reguły. Działanie uniemożliwi członkom katalogu uzyskanie dostępu do oryginalnych danych lub wyświetlanie ich, zgodnie z warunkami. Właściciel zasobu nie ma wpływu na reguły ochrony danych.
Użytkownik wybiera spośród następujących typów działań.
| Działanie | Zakres | Wynik |
|---|---|---|
| Odmowa dostępu | Wszystkie wartości danych we wszystkich kolumnach zasobu danych | Poszkodowane użytkownicy mogą wyświetlać metadane zasobu, ale nie mogą wyświetlać podglądu dowolnych wartości danych, używać danych lub wykonywać działania na zasobie. Użytkownicy nie mogą również pobierać zasobów ani dodawać ich do projektu. |
| Kolumny Redact | Wartości w kolumnie, które są zgodne z kryteriami maskowania | Użytkownicy, których to dotyczy, widzą wartości zastępowane łańcuchem o powtarzającym się znaku. Patrz Mask data with data protection rules. Maskowanie może rozszerzać się na projekty. Patrz sekcja Maskowanie w projektach. |
| Zaciemnij kolumny | Wartości w kolumnie, które są zgodne z kryteriami maskowania | Poszkodowane użytkownicy widzą zastępowane dane o podobnych wartościach i w tym samym formacie. Patrz Mask data with data protection rules. Maskowanie może rozszerzać się na projekty. Patrz sekcja Maskowanie w projektach. |
| Zastępowanie kolumn | Wartości w kolumnie, które są zgodne z kryteriami maskowania | Poszkodowane użytkownicy widzą zastępowane dane o wartości mieszanej. Patrz Mask data with data protection rules. Maskowanie może rozszerzać się na projekty. Patrz sekcja Maskowanie w projektach. |
| Filtruj wiersze | Wszystkie wiersze, które spełniają określone kryteria | Poszkodowane użytkownicy mogą albo wyświetlać, albo są blokowani od wyświetlania, wszystkie wartości w konkretnych wierszach w zależności od ich ról w katalogu i typu wybranego filtrowania. Filtrowanie wierszy jest albo włączeń/wykluczeniem, w zależności od wymagań zasobu danych. Patrz sekcja Filtrowanie wierszy. |
Predykaty niestandardowe
Istnieje możliwość użycia predykatów dostosowywania, gdy standardowe predykaty, takie jak właściwości zasobów danych lub identyfikujące użytkowników, są niewystarczające lub nie spełniają potrzeb biznesowych.
Tworzone predykaty są odwzorowywane na właściwości zasobów danych.
Aby utworzyć lub usunąć predykaty niestandardowe, należy użyć Interfejs API danych produktu Watson . Jeśli później zostanie podjęta decyzja o aktualizacji predykatu niestandardowego, należy najpierw usunąć wszystkie istniejące reguły, używając predykatu niestandardowego, a następnie ponownie utworzyć nowe reguły przy użyciu zaktualizowanego predykatu niestandardowego.
Więcej inform.
- Maskowanie danych
- Filtrowanie wierszy
- Ocena reguł ochrony danych
- Zarządzanie regułami ochrony danych
- Interfejs API danychWatson
Temat nadrzędny: Reguły ochrony danych