Translation not up to date
Reguły położenia danych udostępniają opartą na atrybutach kontrolę dostępu do zasobów danych w oparciu o ich lokalizację. Reguły zapewniają, że w przypadku przenoszenia danych z jednej fizycznej lub suwerennej lokalizacji do innej reguły są wymuszane w zakresie ochrony danych i przepisów dotyczących lokalizacji.
Experimental Jest to wersja eksperymentalna i nie jest jeszcze obsługiwana w środowiskach produkcyjnych. Aby wypróbować tę funkcję eksperymentalną, należy odpowiedzieć na ten post (przykładowy kurs) oraz dodatkowe informacje na temat interfejsu API.
Istnieje możliwość tworzenia reguł położenia danych w celu ochrony poufnych danych w oparciu o lokalizację lub suwerenność danych lub użytkowników, którzy uzyskują dostęp do danych.
Reguła położenia danych składa się z opcjonalnego kierunku danych, kryteriów i bloku działania.
Domyślnie reguła położenia danych jest stosowana do danych zarówno w momencie wprowadzania danych, jak i w przypadku, gdy dane opuszczają miejsce fizyczne lub suwerenne. Istnieje możliwość ograniczenia reguły do pojedynczego kierunku danych. W przypadku określenia kierunku danych reguły jako danych przychodzących, dane wprowadzane do lokalizacji są ograniczone. Jeśli kierunek danych zostanie określony jako wychodzący, dane opuszczające jego położenie są ograniczone.
Na przykład Anya jest kierownikiem ds. prawnych i compliance w banku w Niemczech. Dane osobowe w Niemczech są regulowane przez ogólne rozporządzenie o ochronie danych osobowych. Anya musi zapewnić, że nazwy klientów i adresy, którymi zarządza, jest maskowane, zanim opuści Niemcy i dostęp do nich w innych krajach. Gdy Anya projektuje regułę położenia danych, wybierana przez nią kierunek danych jest wychodząca. Dane pochodzą z Niemiec, a nazwy i adresy klientów są zamaskowane, gdy dostęp do nich jest uzyskiwany w innych krajach.
Kryteria określają, jakie dane mają być sterowane i które mogą obejmować, kto żąda dostępu do danych i właściwości zasobu danych. Kryteria mogą składać się z wielu predykatów, które są łączone w wyrażeniu boolowskim. Predykaty mogą obejmować atrybuty użytkownika i atrybuty zasobów, takie jak klasyfikacje, znaczniki i warunki biznesowe.
Blok działania określa sposób sterowania danymi. Blok działań może składać się z działań binarnych, takich jak negowanie lub zezwalanie na dostęp do danych, a także działania transformujące dane, takie jak maskowanie wartości danych w kolumnie.
Przykład reguły położenia danych
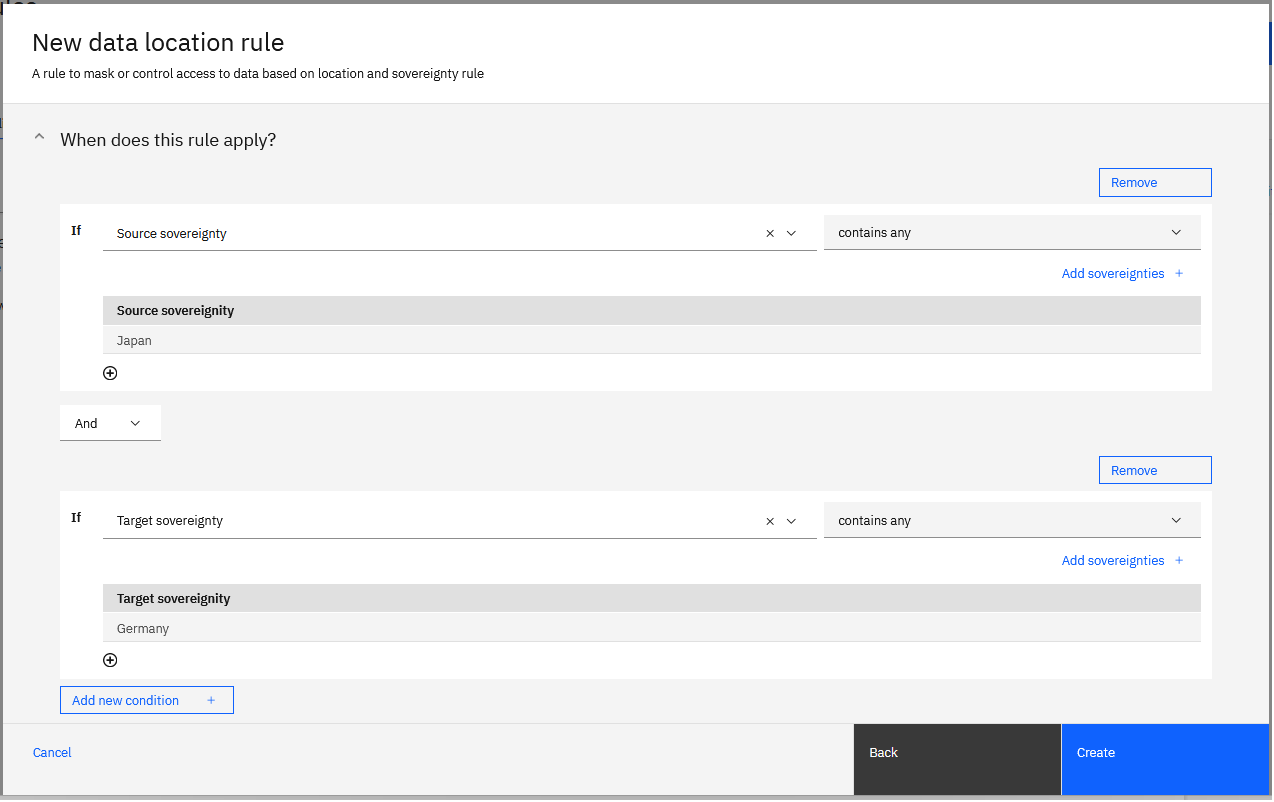
Istnieje możliwość utworzenia reguły położenia danych, która wskazuje, że kierunek danych jest przychodzący. Maskuje nazwy kolumn Nazwa i Adres, używając zaciemnienia, jeśli dane pochodzą z Japonii i wkraczają do Niemiec. Definicja tej reguły składa się z kierunku danych, kryteriów z dwoma warunkami i z działaniem.
W poniższym przykładzie przedstawiono kierunek danych i kryteria dla dwóch warunków, które są zdefiniowane dla reguły:
W poniższym przykładzie przedstawiono działanie Obfuscation, które jest zdefiniowane dla reguły:
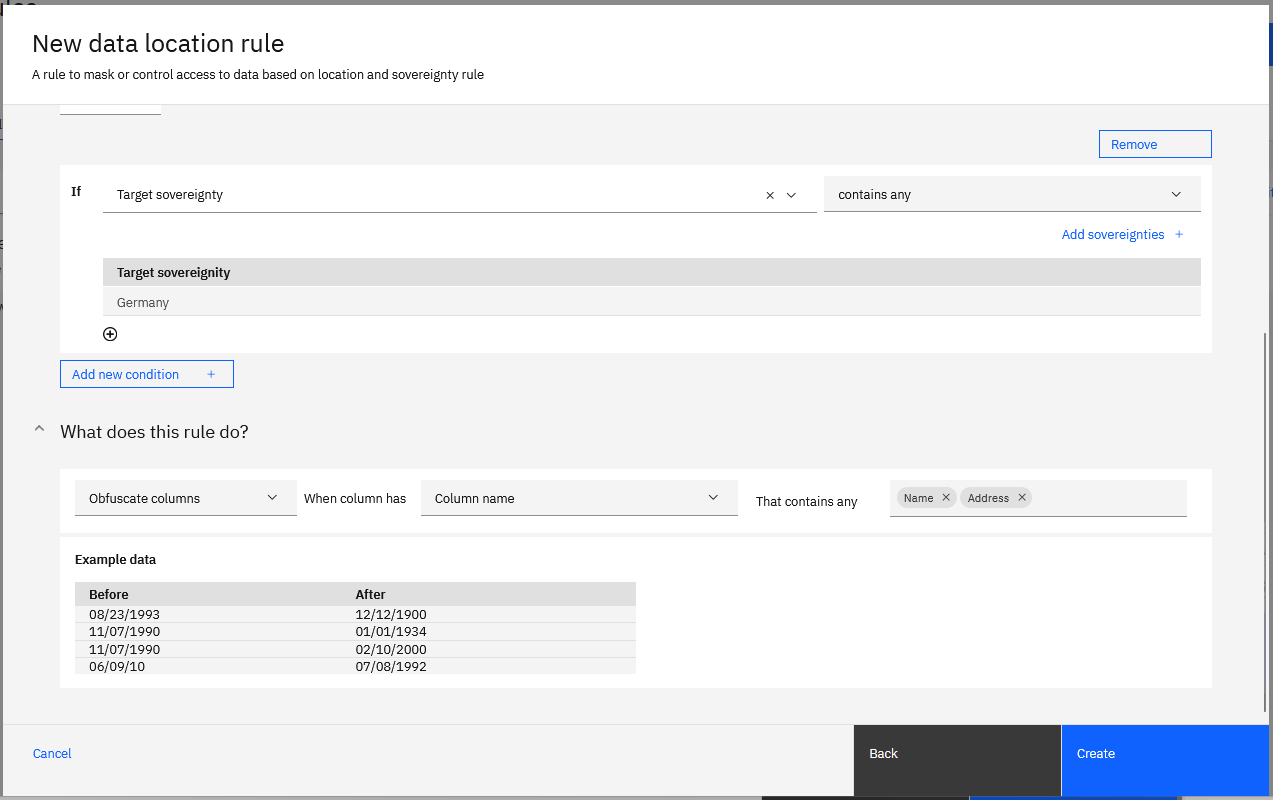
Definicja reguły została ponownie zapisana jako zdanie: If the data direction is incoming, the source sovereignty is Japan, and the target sovereignty is Germany, mask the Name and Address columns using obfuscation transformation.
Dowiedz się więcej
- Projektowanie reguł położenia danych
- Wymuszanie reguł położenia danych
- Zarządzanie regułami położenia danych
Temat nadrzędny: Artefakty zarządzania