CSV file format for importing governance artifacts
The CSV file for importing a single type of governance artifacts must conform to formatting rules.
General formatting rules
The CSV file must comply with the Common Format and MIME Type for comma-separated values (CSV) Files.
The CSV file consists of a header row that names the columns and multiple rows of values that are separated by commas.
Limitations
The maximum recommended size of the CSV import file is 50 MB.
Some IBM Knowledge Catalog plans have limits on the number of governance artifacts of a specific type you can create. The first imported draft is not counted separately but any further drafts that you import are counted. For example, if the published term A has one update draft, the published term and the draft are counted as one term. However, if the published term A has two draft updates, the published term and the drafts are counted as two terms. You can avoid double counting by publishing your imported artifacts before you reimport them.
Header row
The header row of the CSV file represents which properties are imported for the artifacts.
Follow these guidelines for the header row:
- The header row must be the first row in the file and must not be repeated.
- Separate column names with a comma. If you create the file in a spreadsheet editor, the commas are added automatically when you save the file in CSV format.
- The header row must include the mandatory columns for the artifact type.
- You can omit any optional columns.
- Use the exact column names in the header row, except for custom property and custom relationship columns. Some columns have alternative names. Column names are case-sensitive.
- Make sure the column names do not include extra white space characters. White space characters might be added by a spreadsheet or text editor, but not be visible. If you receive an import error that the column names are incorrect, even though your columns are spelled and capitalized correctly, check for white spaces. For more information, see Solving governance artifacts import problems.
Column delimiters
To delimit values for different columns, use a comma. If you create the file in a spreadsheet editor, the commas are added automatically when you save the file in CSV format.
To omit a value for a column, use a comma directly after the previous comma and without any other characters. For example, two consecutive commas indicate that the second column is empty.
To include a comma in a value, surround the value in double quotation marks. For example, to import a value of test,, use the following format:
"test,"
Category paths
You must specify the full category path for categories and relationships to artifacts. If you do not specify the category, the default category is [uncategorized].
To delimit the category path, use two greater-than (>>) symbols between each level of the category hierarchy and between the category path and the artifact name.
Format for the Category and Secondary Category fields
In the Category or Secondary Categories fields, list the category hierarchy from the top-level category name through the final category name, and separate each with the >> symbols. For example, to create a third level category, your Category field might look like this:
myCategory1 >> myCategory2 >> myCategory3
To specify the [uncategorized] category in the Category field, leave the field blank. You can't specify the [uncategorized] category as a secondary category and it can't have subcategories.
Artifact property values
The values for the governance artifact properties that you import are case-sensitive. For example, the tags numberNUMBER
Multiple values for a property
You can include only one value in each field. To include multiple values for a property, such as, tags, stewards, or related terms, add multiple rows for the same artifact and leave the other columns empty. For example,:
Name,Artifact Type,Category,Tags,Related Terms businessterm1,glossary_term,myCategory1,tag1,myCategory1 >> rel_term1 ,,,tag2,myCategory1 >> rel-term2 businessterm2,glossary_term,myCategory1,tag3,myCategory2 >> rel-term3 ,,,tag4,myCategory2 >> rel-term4
This file results in two business terms that each have two tags and two related terms, which include their full category paths.
Relationships between artifacts
When you define any kind of relationship between two artifacts, the related artifact must exist or the relationship is not created. The import process succeeds, and the defined artifacts are created, but relationships to nonexistent artifacts are skipped. Skipped relationships result in errors similar to this:
GIM00015E: Artifact Average balance in column Related Terms is not found in the specified hierarchy.
For more information, see Solving governance artifacts import problems.
However, if both artifacts are defined in the same CSV file, then the relationship is added.
If you plan to import multiple types of artifacts that have relationships between each other, first import all the artifacts, publish the imported artifacts, and then import the same CSV files again, with the Replace all values merge method. The second import processes add the relationships to the existing artifacts.
Character encoding
The content type in the http request must be multipart/form-datatext/csv
Column formatting rules
The following table shows which columns are supported for each type of artifact when you import governance artifacts. The asterisk (*) indicates mandatory columns. Use the listed or alternative column names in the header row, except for custom property and custom relationship columns.
| Column name | Categories | Business terms | Classifications | Data classes | Reference data sets | Policies | Governance rules |
|---|---|---|---|---|---|---|---|
| Name* | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Artifact Type* | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Category* | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Description | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Secondary Categories | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Stewards | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Steward Groups | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Tags | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Classifications | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Business Start | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Business End | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Related Terms | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Custom property values | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Custom relationships | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Part of Terms | ✓ | ||||||
| Type of Terms | ✓ | ||||||
| Synonyms | ✓ | ||||||
| Data Classes | ✓ | ||||||
| Abbreviations | ✓ | ||||||
| Parent Classification | ✓ | ||||||
| Parent Data Class | ✓ | ||||||
| Enabled | ✓ | ||||||
| Reporting Authorized | ✓ | ||||||
| Definition | ✓ | ||||||
| Data Set Type* | ✓ | ||||||
| Parent Reference Data Sets | ✓ | ||||||
| Custom Columns | ✓ | ||||||
| Parent Policy | ✓ | ||||||
| Parent Policies | ✓ | ||||||
| Rules | ✓ | ✓ | |||||
| Reference Data Sets | ✓ |
Name (Mandatory)
- Alternative column name
- name
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The name of the artifact.
The name of a governance artifact is associated with its primary category, which you must include in the Category field. This is why the list of business terms, for example, might show business terms with identical names, but with different primary categories.
- Format
- The name of the artifact must be unique for the artifact type in its primary category. Names are case-sensitive. For example, the names "Confidential" and "confidential" are considered as different names.
The name must contain 1 - 255 characters. A name cannot include Unicode control characters, start or end with a white space, or any greater-than (>) symbols.
- Default value
- None. You must supply a value for the artifact name.
- Example
- To add a business term named Blue, specify:
Name,Artifact Type,Category Blue,glossary_term,Colors
Artifact Type (Mandatory)
- Alternative column name
- artifact_type
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The name of one type of governance artifact.
- Format
- You can import data for only one type of governance artifact at a time. Use the following values to specify the artifact type:
| Artifact type | Value |
|---|---|
| Business terms | glossary_term |
| Categories | category |
| Classifications | classification |
| Data classes | data_class |
| Governance rules | rule |
| Policies | policy |
| Reference data sets | reference_data |
- Default value
- None. You must supply an artifact type.
- Example
- To add a business term artifact, specify:
Name,Artifact Type,Category Blue,glossary_term,Colors
Category (Mandatory)
- Alternative column name
- category
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The primary category of the artifact or the category to create.
- Format
- Specify the full hierarchy path, starting with a top-level category, such as:
myCategory1 >> myCategory2 >> myCategory3
Unless you are importing categories, the specified categories must exist. If you are importing subcategories, the higher-level categories must exist, unless you define them in the same file.
- Default value
- Leave this field blank in the following situations:
- To import top-level categories.
- To add imported artifacts to the [uncategorized] category.
- Example
- To add a business term to the Colors top-level category, specify:
Name,Artifact Type,Category Blue,glossary_term,Colors
To import a new top-level category, named myCategory1, specify:
Name,Artifact Type,Category myCategory1,category,
To add a category, named myCategory2, as a subcategory to an existing category, named myCategory1, specify:
Name,Artifact Type,Category myCategory2,category,myCategory1
To add a category, named myCategory3, in an existing category hierarchy of myCategory1 >> myCategory2, specify:
Name,Artifact Type,Category myCategory3,category,myCategory1 >> myCategory2
Description
- Alternative column name
- description
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- A description for the artifact.
- Format
- A description can contain up to 15000 characters.
Secondary Categories
- Alternative column name
- secondary_categories
- Artifact types
- Business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- A secondary category for an artifact.
- Format
- The category must exist. You can't specify the [uncategorized] category as a secondary category. Specify the full hierarchy path, starting with a top-level category. See Category paths.
To import multiple secondary categories for an artifact, add multiple rows for that artifact, with a different secondary category value in each row.
Stewards
- Alternative column name
- stewards
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
For categories, the steward is not displayed in the UI. To check the values, you can use the REST API call GET /v3/categories/{guid}
- Description
- The user ID for the person who is responsible for the artifact.
- Format
- An IBMid that consist of alphanumeric values. As an IBM Cloud account owner, you can view all users in your account. To find out a user's IBMid, go to Administration > Access (IAM) > Users. Open the entry for that user and click Details.
The format of the values of Stewards is not compatible between Cloud Pak for Data as a Service and Cloud Pak for Data 3.5 or 4.x.
Steward Groups
- Artifact types
- Categories, business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The steward user group responsible for the artifact.
span translate="no">Classifications
- Alternative column name
- classifications
- Artifact types
- Categories, business terms, data classes, reference data sets, policies, governance rules
For categories, the classification is not displayed in the UI. To check the values, you can use the REST API call GET /v3/categories/{guid}
- Description
- The classification that is assigned to the artifact.
- Format
- The classification must exist. Specify the classification with its full category hierarchy path. See Category paths.
To import multiple classifications for an artifact, add multiple rows for that artifact, with a different value for a classification in each row. Note that the Classifications column is supported in categories import, but it is not exported.
Example
Name,Artifact Type,Category,Classifications Account,glossary_term,Insurance >> Business Area >> All Accounts,Insurance >> concept
Business Start
- Alternative column name
- business_start
- Artifact types
- Business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The effective date for when the published artifact becomes active. You can import artifacts with a business start date that is in the past.
The effective start date is set as follows:
- Import of a new artifact with an effective start date in the past: when you publish the draft, the effective start date is set to the date and time of publishing.
- Import of a new artifact with an effective start date in the future: when you publish the draft, the effective start date that is specified in the import is used.
- Import of updates to an existing artifact that has an effective start date in the past: when you publish the draft, if you imported with the Replace empty values merge method, then the original start date is preserved. Otherwise, the start date is changed to the publish date.
- Import of updates to an existing artifact that has an effective start date in the future: when you publish the draft, the effective start date that is specified in the import is used unless that date is in the past. In this case, it is set to the date and time of publishing.
- Format
- Specify the start date, time, and the Coordinated Universal Time time offset, in the format
yyyy-mm-dd hh:mm±hh:mm2020-10-07 16:00+00:00
Business End
- Alternative column name
- business_end
- Artifact types
- Business terms, classifications, data classes, reference data sets, policies, governance rules
- Description
- The effective date for when the published artifact becomes inactive.
- Format
- Specify the start date, time, and the Coordinated Universal Time time offset in the format
yyyy-mm-dd hh:mm±hh:mm2021-10-07 17:00+00:00
Custom property values
- Column name
- custom_property-name
The column name for such a value is the name of the custom property that is prefixed with custom_.
- Artifact types
- Categories, business terms, data classes, policies, governance rules
- Description
- A value for any type of custom property except for custom property of type Relationship.
- Format
- The custom property must exist.
For the custom property of type USER_GROUP the supported format is:
- "user_id:user", for example "1000330999:user"
- "group_id:group", for example "10000:group"
Both users and user groups can be defined for one CP of type USER_GROUP (if it supports multi values).
Custom relationships
- Column name
- custom_directed_relationshipname
The column name for a relationship is the name of the custom relationship that is prefixed with custom_directed_. For example, custom_directed_Is Analyzed By.
- Artifact types
- Categories, business terms, data classes, classifications, policies, governance rules
- Description
- Custom properties of type Relationship.
- Format
- The custom relationship and the target artifact must exist. You must specify the directed relationship. The reversed relationship is created automatically. Specify the custom relationship with its full category hierarchy path. See Category paths.
Specify the information in the following format: contextPath:Type
Part of Terms
- Alternative column name
- part_of_terms
- Artifact types
- Business terms
- Description
- Adds a part relationship between two business terms:
- Is a part of: Specifies a relationship in which a term is a component of, a part of, an attribute of, or a member of another term.
- Has a part of: Specifies a relationship in which another term is a component of, a part of, an attribute of, or a member of the first term.
- Format
- The target business term must exist or must be defined in the same CSV file. In the row for the business term that has an Is a part of relationship, list the target business term. The Has a part of half of the relationship is added automatically.
Specify a part relationship with its full category hierarchy path`. See Category paths. A part relationship must always be defined as an Is a part of relationship.
To import multiple relationships for a term, add multiple rows for that term.
- Example
- For example, Fixed Rate, Hybrid Rate, and Variable Rate are attributes of the term Interest Rate, which in turn is an attribute of the term Home Loan. In this case, each of the terms Fixed Rate, Hybrid Rate, and Variable Rate has the Is a part of relationship to the term Interest Rate. The term Interest Rate has the Has a part of relationship to those terms but also the Is a part of relationship to the term Home Loan.
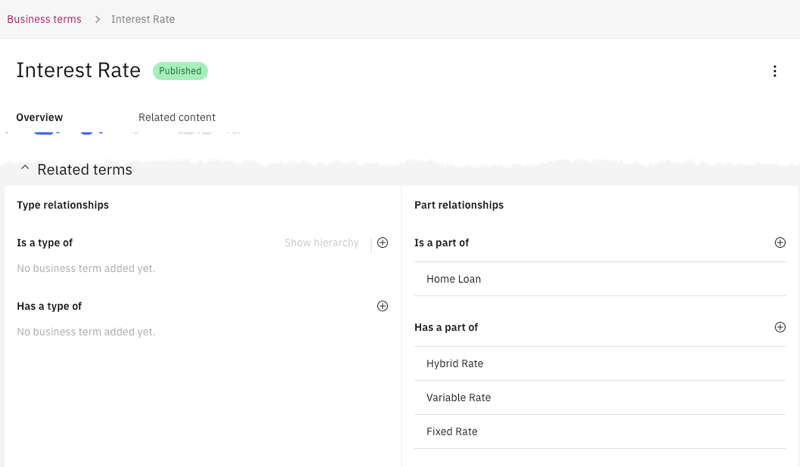
The rows for these terms look similar to this sample:
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Related Terms,Part of Terms,Abbreviations Interest Rate,glossary_term,myCategory1,,,,,,myCategory1 >> Home Loan,, Fixed Rate,glossary_term,myCategory1,,,,,myCategory1 >> Interest Rate,, Hybrid Rate,glossary_term,myCategory1,,,,,myCategory1 >> Interest Rate,, Variable Rate,glossary_term,myCategory1,,,,,myCategory1 >> Interest Rate,,
Type of Terms
- Alternative column name
- type_of_terms
- Artifact types
- Business terms
- Description
- Shows type relationships:
- Is a type of: Specifies a relationship in which a term is an instance of the concept that is expressed by another term typically broader in scope.
- Has a type of: Specifies a relationship in which the concept that is expressed by a term has one or more subtypes that are expressed by other terms. For example, the term Loan might be specified as having the Has a type relationship to the terms Home Loan, Car Loan, and Student Loan.
- Format
- The target business term must exist or must be defined in the same CSV file. In the row for the business term that has an Is a type of relationship, list the target business term. The Has a type of half of the relationship is added automatically.
Specify a type relationship with its full category hierarchy path. See Category paths. A type relationship must always be defined as an Is a type of relationship.
To import multiple relationships for a term, add multiple rows for that term.
- Example
- For example, Home Loan, Car Loan, and Student Loan are different types of loan. In this case, each of the terms Home Loan, Car Loan, and Student Loan has the Is a type of relationship to the term Loan. The term Loan has the Has a type relationship to those terms.
The rows for these terms look similar to this sample:
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Related Terms,Part of Terms,Type of Terms Home Loan,glossary_term,myCategory1,,,,,,,myCategory1 >> Loan, Car Loan,glossary_term,myCategory1,,,,,,,myCategory1 >> Loan, Student Loan,glossary_term,myCategory1,,,,,,,myCategory1 >> Loan,
Synonyms
- Alternative column name
- synonyms
- Artifact types
- Business terms
- Description
- A relationship to another business term that has the same meaning.
- Format
- The target business term must exist or be defined in the same CSV file. Specify the synonym with its full category hierarchy path. See Category paths.
To import multiple synonyms for a term, add multiple rows for that term, with a different synonym in each row.
Data Classes
- Alternative column name
- data_classes
- Artifact types
- Business terms
- Description
- Any data classes that are assigned to a term.
- Format
- The data class must exist. Specify the data class with its full category hierarchy path. See Category paths.
To import multiple data classes for a term, add multiple rows for that term, with a different data class in each row.
Abbreviations
- Alternative column name
- abbreviations
- Artifact types
- Business terms
- Description
- An abbreviated form of the business term name.
- Format
- The abbreviation for a term.
To import multiple abbreviations for a term, add multiple rows for that term, with a different value for an abbreviation in each row.
Parent Classification
- Alternative column name
- parent_classification
- Artifact types
- Classifications
- Description
- The main classification to which this classification belongs.
- Format
- The parent classification must exist or be defined in the same CSV file. Specify the parent classification with its full category hierarchy path. See Category paths.
Example :
Name,Artifact Type,Category,Parent Classification,Related Terms financial,classification,Insurance >> Business Area >> Claim,Insurance >> property
Parent Data Class
- Alternative column name
- parent_data_class
- Artifact types
- Data classes
- Description
- Specifies the relationship within a hierarchy of data classes.
- Format
- The parent data class must exist or must be defined in the same CSV file. Each data class can have only one parent data class. The parent and child data classes must be in the same category. Specify the parent data class with its full category hierarchy path. See Category paths.
Example :
Name,Artifact Type,Category,Description,Classifications,Related Terms,Parent Data Class Georgia State Driver's License,data_class,Driver's License >> US License,A string representing a driver license of US state Georgia.,,,Driver's License >> US License >> Southeastern Driver's License
Enabled
- Alternative column name
- enabled
- Artifact types
- Data classes
- Description
- Indicates whether a data class is enabled for data matching.
- Format
- Possible values are TRUE or FALSE. This column is optional but if you add it, it must contain a value for each data class in the CSV file.
Reporting Authorized
- Alternative column name
- reporting
Definition
- Alternative column name
- definition
- Artifact types
- Data classes
- Description
- The data class definition.
- Format
- XML code surrounded by double quotation marks. Create this XML code by exporting an existing data class.
This column is optional but if you add it, it must contain a value for each data class in the CSV file.
Example :
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><DataClasses xmlns="http://www.ibm.com/infosphere/ia/classification/DataclassesDefinition"><DataClass id="AddressLine1" name="Address Line 1" description="Address Line 1 of a multi-line address." priority="12" active="true" provider="IBM"><JavaClassifier scope="column" className="com.ibm.infosphere.classification.impl.AddressLineClassifier"/><DataTypeFilter><LogicalDataType>string</LogicalDataType></DataTypeFilter><DataLengthFilter minLength="4" maxLength="100"/><ColumnNameFilter><ColumnNameRegularExpression>addr.{0,15}(1|one)$</ColumnNameRegularExpression></ColumnNameFilter></DataClass></DataClasses>
Data Set Type (Mandatory for reference data sets)
- Alternative column name
- type
- Artifact types
- Reference data sets
- Description
- The data type of the reference data set. This property is mandatory if you import a reference data set.
- Format
- Supported values are text, date, number.
Parent Reference Data Sets
- Alternative column name
- parent_rds
- Artifact types
- Reference data sets
- Description
- Specifies the relationship within a hierarchy of reference data sets.
- Format
- The parent reference data set must exist or must be defined in the same CSV file. A reference data set can have any number of parent reference data sets. Specify the parent reference data set with its full category hierarchy path. See Category paths.
To import multiple parent reference data sets, add a separate row for each one.
Example :
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Related Terms,Business Start,Business End,Data Set Type,Parent Reference Data Sets,Secondary Categories,Custom Columns RDS1,reference_data,cat1,Test RDS,tag1,Confidential,1000330999,cat1 >> term1,6/15/2021 13:08,7/31/2021 21:59,TEXT,cat1 >> RDS2,Information Governance,TEXT||CUSTOM COLUMN1||test ,,,,,,,,,,,,Business Information,NUMBER||CUSTOM COLUMN2||test2 RDS2,reference_data,cat1,,,,,,6/15/2021 13:13,,TEXT,,,
In a spreadsheet program, the definition would look like this:

Custom Columns
- Alternative column name
- custom_columns
- Artifact types
- Reference data sets
- Description
- Map columns in a reference data set to existing custom columns. When importing new reference data sets, you can define new custom columns. See Custom columns.
- Format
- Specify the information in the following format:
type (TEXT/NUMBER/DATE)||name||description (optional)||composite-key/normal-column (optional, default: normal-column)||mandatory/optional (optional, default: optional)||max characters number (optional, default: 2000 for normal-column, 200 for CK column)||validator as path>>name (optional)
- If the column is defined as composite key, then it must be mandatory.
- Only a published referece data set of type TEXT can be a validator.
- Only custom columns of type TEXT can have a validator.
- Maximum number of composite key columns per a set is 5.
Examples :
NUMBER||Digit Count||Number of digits of the prime TEXT||Additional information
Parent Policy
- Alternative column name
- parent_policy
- Artifact types
- Policies
- Description
- Specifies the parent policy of a policy.
- Format
- The parent policy must exist. Specify the parent policy with its full category hierarchy path. See Category paths.
A policy can have only one parent policy.
Examples :
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Secondary Categories,Rules,Parent Policy policy7,policy,PolicyDef,test policy7,Tag1,,,,,PolicyDef >> policy1
Parent Policies
- Alternative column name
- parent_policies
- Artifact types
- Governance rules
- Description
- Specifies the parent policy of a governance rule.
- Format
- The parent policy must exist. Specify the parent policy with its full category hierarchy path. See Category paths.
Examples :
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Related Terms,Business Start,Business End,Type,Secondary Categories,Rules,Reference Data Sets,Parent Policies,custom_Rule_text_0 rule2,rule,cat1,,,,,,6/15/2021 13:17,,Governance,,cat1 >> rule1,,cat1 >> pol1, rule1,rule,cat1,test description,tag1,Confidential,1000330999,cat1 >> term1,6/15/2021 13:16,8/31/2021 21:59,Governance,Business Information,cat1 >> rule3,cat1 >> RDS2,cat1 >> pol2,example CA value ,,,,,,,,,,,,cat1 >> rule2,cat1 >> RDS1,cat1 >> pol1, rule3,rule,cat1,,,,,,6/15/2021 13:20,,Governance,,cat1 >> rule1,,cat1 >> pol1,
Rules
- Alternative column name
- rules
- Artifact types
- Policies, governance rules
- Description
- For a policy, a governance rule that is governed by this policy.
For a rule, the governance rules that are related in some way to this rule. The relationship is symmetrical. If you specify that rule A is related to rule B, then rule B is related to rule A.
- Format
- The governance rule must exist. Specify the governance rule with its full category hierarchy path. See Category paths.
To import relationships with multiple rules, add a separate row for each one.
Example :
Name,Artifact Type,Category,Description,Tags,Classifications,Stewards,Related Terms,Business Start,Business End,Secondary Categories,Rules,Parent Policy,custom_policy_text_0 pol3,policy,cat1,,,,,,6/15/2021 13:16,,,,, pol2,policy,cat1,,,,,,6/15/2021 13:14,,,cat1 >> rule1,cat1 >> pol1, pol1,policy,cat1,test descritpion,tag1,Confidential,1000330999,cat1 >> term1,6/15/2021 13:11,7/31/2021 21:59,Information Governance,cat1 >> rule3,cat1 >> pol3,example CA value ,,,,,,,,,,,cat1 >> rule1,, ,,,,,,,,,,,cat1 >> rule2,,
Reference Data Sets
- Alternative column name
- rds
- Artifact types
- Governance rules
- Description
- A reference data set that is related to the governance rule.
- Format
- The reference data set must exist. Specify the reference data set with its full category hierarchy path. See Category paths.
Learn more
Parent topic: Import methods for governance artifacts