What's new
Check back each week to learn about new features and updates for Cloud Pak for Data as a Service and services such as watsonx.ai Studio (formerly Watson Studio), watsonx.ai Runtime (formerly Watson Machine Learning), DataStage, and IBM Knowledge Catalog.
Week ending 28 March 2025
Deprecation of data location and sovereignty rules for Data Privacy
25 March 2025
The data location and sovereignty rules were experimental features that provide attributes-based access control of data assets based on their location or sovereignty. These data location and sovereignty rules are now deprecated.
If you have questions or concerns that are related to the deprecation, you can open a support ticket.
Week ending 21 March 2025
Write analysis output to more databases (IBM Knowledge Catalog)
20 March 2025
You can now write the analysis output of advanced profiling or running data quality rules also to Amazon RDS for Oracle or Amazon RDS for PostgreSQL databases.
For more information, see Supported data sources for curation and data quality.
Enhancements to output tables for data quality rules (IBM Knowledge Catalog)
20 March 2025
You can now specify certain parameters to generate dynamic names for your rule output tables. Also, you can now select whether you want such tables to be added to your project. They are no longer automatically added.
For consistent setup of rule output tables, a project administrator can now configure default settings for a project. You can still overwrite these settings for individual rules.
For details, see Configuring output settings for data quality rules and Project settings for data quality.
New and enhanced features in Data Virtualization
17 March 2025
The most recent release requires you to assign extra permissions for the Service ID that interacts with Cloud Pak for Data as a Service. Complete this task before you request the Data Virtualization instance upgrade. See Assigning service ID permissions required for Data Virtualization upgrade.
The following new and enhanced features are available in Data Virtualization:
Securely connect to your on-premises data sources using Satellite Connectors
You can now use Satellite Connectors to securely connect to on-premises data sources such as Apache Hive, Apache Impala, Db2, and PostgreSQL. Satellite Connectors enable seamless integration between on-premises and cloud data sources while ensuring that all the data remains securely encrypted. For more information, see Accessing data sources by using IBM Cloud Satellite connectors.
Autocaching to improve query performance
You can now enable autocaching to automate the entire cache lifecycle from creation to deletion. Autocaching leverages the cache recommendation engine to analyze your query workloads and acts on the recommendations by creating the caches automatically. Autocaching also evicts caches that it had created earlier if they are no longer beneficial. As part of this feature, you can customize the name and refresh schedule of the caches, how often you want autocaching to run, the amount of storage space that autocaching can occupy and the type of queries in your workload that you want autocaching to analyze. Autocaching is disabled by default, and you can enable it from the Cache management page. For more information, see Autocaching in Data Virtualization.
Enhanced security with Kerberos authentication for Hive, Impala and Spark data sources
You can now set up Kerberos authentication on the Cloud for your Apache Hive, Apache Impala and Apache Spark data sources using a Satellite Connector with a remote agent. For more information, see Enabling Kerberos authentication.
Enforce data protection rules across Cloud Pak for Data as a Service
You can now use the new Cloud Pak for Data as a Service Data Data Source Definitions (DSD) to enforce IBM Knowledge Catalog data protection rules consistently across Cloud Pak for Data, regardless of whether you query the object through Data Virtualization or preview it in a catalog or project. A DSD is automatically created when you provision or upgrade your Data Virtualization instance. For more information, see Governing virtual data with data protection rules.
Query tables from previous Presto and Databricks catalogs with multiple catalog support
Virtual tables that you create from Presto and Databricks catalogs are now fully accessible. You can run queries on these tables regardless of any changes that you make to the catalog filters. This means that you do not need to switch back to previous Presto or Databricks catalogs to ensure the functionality of existing queries. For more information, see Supported data sources in Data Virtualization.
Control who can access and perform operations on individual data sources by using personal credentials
If you define personal credentials when you add a data source, the personal credentials are used for all operations, such as listing tables or listing schemas, on the data source. For more information, see Data source connection access restrictions.
Enhanced catalog visibility for Presto and Databricks
The Presto and Databricks web client now displays the name of the catalog that you selected in the breadcrumbs of the Explore view, and beside each schema name in the List view.
Updates to data sources
You can now connect to and query data in the following data sources:
- REST API
- Apache Spark
- Presto
- SAP HANA
For more information, see Supported data sources in Data Virtualization.
Troubleshoot queries that fail during the fetch phase
You can now use the information in fetch phase errors to determine why queries fail. When a problem, such as a connection error, occurs during the fetch phase, the query stops and the error is sent back to you. You can check the SQL state that is linked to the error to find out why your query stopped.
Fetch phase warnings alert you to a range of potential issues such as network disruptions, resource depletion problems (such as thread and memory constraints), SQL exceptions, and warnings that originate from the remote data source itself.
Use fetch phase errors in addition to fetch phase warnings to gain insight into problems or potential problems with your queries.
For more information, see Fetch phase warnings and errors.
Pushdown enhancements to improve query performance
Improve the performance of queries that use pushdown. Query pushdown is an optimization feature that reduces query times and memory use. Data Virtualization now includes following enhancements:
- Support OLAP functions when you connect to Oracle data sources. This support includes functions MIN, MAX, SUM, COUNT, COUNT_BIG, ROW NUMBER/ROWNUMBER, RANK, DENSERANK, DENSE_RANK, STDDEV_SAMP, PERCENTILE_CONT, PERCENTILE_DISC, and PERCENT_RANK when used in the query with the OLAP function specification. For more information, see OLAP specifications.
- Common subexpression pushdown to Oracle data sources.
- Use pushdown for various other string functions, including CASTs, TRIM, BITAND, and others.
- The Salesforce.com and Db2 for i data source connections have been optimized to take advantage of more data source capabilities to improve query performance on single-source tables.
- Query performance is improved in pushdown mode in the following situations:
- When you query string data on remote data sources with the IN predicate. For details about the IN predicate, see IN predicate in the Db2 documentation.
- When you query data where the total width of the columns in the Select list is greater than 32 thousand.
- When you use common sub-expressions (CSE) pushdown capabilities.
- When you reference numeric data type functions in the query. When you reference date and time type functions in the query.
Max Pushdown mode is automatically enabled to improve query performance
To improve the performance of your queries, Max Pushdown mode is enabled by default for new installations. A user with the Data Virtualization Manager role can change the query mode from Max Consistency to Max Pushdown. For more information, see Setting the query mode.
View the data protection rules that are applied to a user
You can now view details about the data protection rules that apply to a Data Virtualization object for a specific user by using the EXT_AUTHORIZER_EXPLAIN stored procedure. For more information, see EXT_AUTHORIZER_EXPLAIN.
Manage who can access and perform operations on individual data sources
With data source access restrictions, you can explicitly manage access to individual data source connections that use shared credentials. You can assign users, user groups, and roles as collaborators for a data source connection. Only those collaborators can access the data source connection. You assign specific privileges to the collaborators to manage the actions that they can perform on the data sources. This enables you to separate privileges from roles, so that some users who are assigned a role such as Manager can access and take action on different data source connections than other Manager users. For more information, see Data source connection access restrictions.
IBM Knowledge Catalog data protection rules are always enabled for Data Virtualization data
If IBM Knowledge Catalog and Data Virtualization are installed in the same instance of Cloud Pak for Data, IBM Knowledge Catalog is enabled and automatically applied to Data Virtualization data. For more information, see Governing virtual data with data protection rules.
Secure your ungoverned objects
With IBM Knowledge Catalog data protection rules in Data Virtualization, virtualized objects that are not published in a governed catalog will now follow the Default data access convention setting from your rule settings. For more information, see Allowing and denying access to data.
Improved error reporting of data protection rules
You can now access improved error reporting with enhanced and detailed information for errors that are linked to the enforcement of data protection rules. For more information, see SQL5105N error when you run a query.
Data Virtualization connections in catalogs now reference the platform connection
When you publish objects to a catalog, the Data Virtualization connections that are created from that publication now reference the main Data Virtualization connection in Platform connections. This means that information such as personal credentials only needs to be defined or updated one time in the Data Virtualization platform connection. All referenced connections now automatically reflect changes that are made to the main Data Virtualization connection.
Enhanced security for the Manager role
For newly provisioned Data Virtualization service instances, the Manager role no longer has default access to all data. The DATAACCESS Db2 authority is removed from the Manager role. Manager users can still access data that they own or that they have been assigned to. For more information, see Revoking data access authority from the Manager role.
Mask multibyte characters for enhanced privacy of sensitive data
You can now perform partial redaction and basic obfuscation of multibyte characters such as symbols, characters from non-Latin alphabets like Chinese or Arabic, and special characters that are used in mathematical notation. The rest of the masking methods that involve multibyte characters are masked with the character “X”. For more information, see Masking virtual data.
Enhanced security for profiling results in Data Virtualization views
To prevent unexpected exposure to value distributions through the profiling results of a view, all users are denied access to profiling results in Data Virtualization views in all catalogs and projects.
Week ending 14 March 2025
Removed the Recommended assets tab (IBM Knowledge Catalog)
14 March 2025
The Recommended tab with assets recommended to you based on properties common to the assets that you viewed, created, and added to projects on the Asset page is no longer available.
Gen AI based metadata enrichment features are now available in all regions (IBM Knowledge Catalog)
14 March 2025
The options for semantic and AI-augmented data enrichment in IBM Knowledge Catalog are now also available in the Frankfurt, London, and Tokyo regions.
Run additional enrichment and data quality capabilities on more data sources (IBM Knowledge Catalog)
14 March 2025
You now have additional options when enriching or running data quality rules on the following data sources:
- Amazon RDS for Oracle
- Enrich metadata and create query-based data assets from Amazon RDS for Oracle databases.
- Amazon RDS for PostgreSQL
- Run data quality rules on assets and create query-based data assets from Amazon RDS for PostgreSQL databases.
- Snowflake
- Write analysis output to a Snowflake data storage.
For more information, see Supported data sources for curation and data quality.
Week ending 7 March 2025
New Google BigQuery data source for lineage metadata import
6 March 2025
You can now import lineage metadata from the Google BigQuery data source. After the data is imported, you can visualize it on a lineage graph.
For more information, see:
Code snippets are now available in Decision Optimization experiments
5 March 2025
When building Decision Optimization models in the experiment UI, you can now use code snippets for Python DOcplex or OPL models. Using code snippets can make model building faster, as you can add and edit code without having to enter all the lines of code from scratch.
For more information, see Code snippets for building models.
Week ending 28 February 2025
Removal of Runtime 23.1
27 February 2025
Support for IBM Runtime 23.1 in watsonx.ai Runtime and watsonx.ai Studio will be removed on 17 April 2025. To ensure a seamless experience and to leverage the latest features and improvements, switch to IBM Runtime 24.1.
- For information about changing environments, see Changing notebook environments.
- For details on deployment frameworks, see Managing frameworks and software specifications.
Deprecation of project-lib library
24 February 2025
The project-lib library is deprecated. Starting with Runtime 25.1, the library will not be included in any new runtime version. Although existing runtime versions through 24.1 will continue to include the deprecated library, consider rewriting your code to use the ibm-watson-studio-lib library.
For information on how to migrate your code, see:
Week ending 21 February 2025
Relationship explorer to visualize your metadata
21 February 2025
Relationship explorer is now available to help better understand your data. This new feature helps you to visualize, explore and govern your metadata. Discover how your governance artifacts and data assets relate with each other in a single view.
For more information, see Relationships.
Assign aliases for more complete lineage in Manta Data Lineage
21 February 2025
In complex data environments that connect multiple systems and technologies, lineage might appear incomplete due to missing system connections. You can now assign aliases to systems to bridge these gaps and generate a more complete and accurate cross-system lineage.
For more information, see Configuring alias assignments.
Week ending 14 February 2025
Deploy models converted from scikit-learn and XGBoost to ONNX format
13 February 2024
You can now deploy machine learning and generative AI models that are converted from scikit-learn and XGBoost to ONNX format and use the endpoint for inferencing. For more information, see Deploying models coverted to ONNX format.
IBM Knowledge Catalog and Manta Data Lineage are now also available in the Toronto region
14 February 2025
IBM Knowledge Catalog and Manta Data Lineage are now also available in the Toronto data center. You can select Toronto as your preferred region when you sign up.
For more information about product features that are available in the Toronto region, see Regional availability for services and features.
Deploy models converted from scikit-learn and XGBoost to ONNX format
13 February 2024
You can now deploy machine learning and generative AI models that are converted from scikit-learn and XGBoost to ONNX format and use the endpoint for inferencing. For more information, see Deploying models coverted to ONNX format.
Updated SPSS Modeler tutorial videos
11 February 2025
Watch and learn about SPSS Modeler by viewing the updated videos in the SPSS Modeler tutorials.
Week ending 7 February 2025
Deprecation of the Recommended assets tab (IBM Knowledge Catalog)
4 February 2025
The Recommended tab with assets recommended to you based on properties common to the assets that you viewed, created, and added to projects on the Asset page is deprecated and will be removed in March 2025.
If you have questions or concerns that are related to the deprecation, you can open a support ticket.
Default Inventory replaces Platform Asset Catalog in watsonx.governance
3 February 2025
A default inventory is now available to store watsonx.governance artifacts including AI use cases, third-party models, attachments, and reports. The default inventory replaces any previous dependency on Platform access catalog or IBM Knowledge Catalog for storing governance artifacts.
Week ending 21 January 2025
Manta Data Lineage is now also available in the Sydney region
21 January 2025
Manta Data Lineage is now also available in the Sydney data center. You can select Sydney as your preferred region when you sign up.
For more information about product features that are available in the Sydney region, see Regional availability for services and features.
Week ending 17 January 2025
Deploy models converted from CatBoost and LightGBM to ONNX format
15 January 2024
You can now deploy machine learning and generative AI models that are converted from CatBoost and LightGBM to ONNX format and use the endpoint for inferencing. These models can also be adapted to dynamic axes. For more information, see Deploying models coverted to ONNX format.
New Evaluation Studio tutorial and video
13 Jan 2025
Try the new Evaluation Studio tutorial and video to help you learn how to evaluate and compare the performance of your generative AI assets.
| Tutorial | Description | Expertise for tutorial |
|---|---|---|
| Compare prompt performance | Evaluate and compare your generative AI assets with quantitative metrics and customizable criteria that fit your use cases. | Use the Evaluation Studio to evaluate the performance of multiple assets simultaneously. |
Deprecation of data location and sovereignty rules for Data Privacy
13 January 2025
The data location and sovereignty rules are experimental features that provide attributes-based access control of data assets based on their location or sovereignty. These experimental features are deprecating and might be removed in March 2025. For details, see Data location rules (experimental).
If you have questions or concerns that are related to the deprecation, you can open a support ticket.
Week ending 20 December 2024
Deploy models converted to ONNX format
20 December 2024
You can now deploy machine learning and generative AI models that are converted to ONNX format and use the endpoint for inferencing. These models can also be adapted to dynamic axes. For more information, see Deploying models coverted to ONNX format.
Deploy multi-source SPSS Modeler flows
20 December 2024
You can now create deployments for SPSS Modeler flows that use multiple input streams to provide data to the model. For more information, see Deploying multi-source SPSS Modeler flows.
Week ending 13 December 2024
New data sources for lineage metadata import
12 December 2024
You can now import lineage metadata from the following data sources. After the data is imported, you can visualize it on a lineage graph. For more information, see Supported data sources for curation and data quality.
Data quality monitoring and remediation workflows (IBM Knowledge Catalog)
12 December 2024
To focus quality improvement efforts on the data that is most important for your organization, you identify critical data elements, define quality expectations, and ensure remediation of data quality issues.
You can now build data quality SLA rules to:
- Monitor the quality of critical data against specific quality criteria as part of metadata enrichment.
- Trigger remediation workflows if the quality doesn’t meet the expectations. You can work with the default remediation workflow or create custom workflows.
You can view information about SLA rule compliance or violations and the status of remediation tasks on a monitored data asset’s Data quality page.
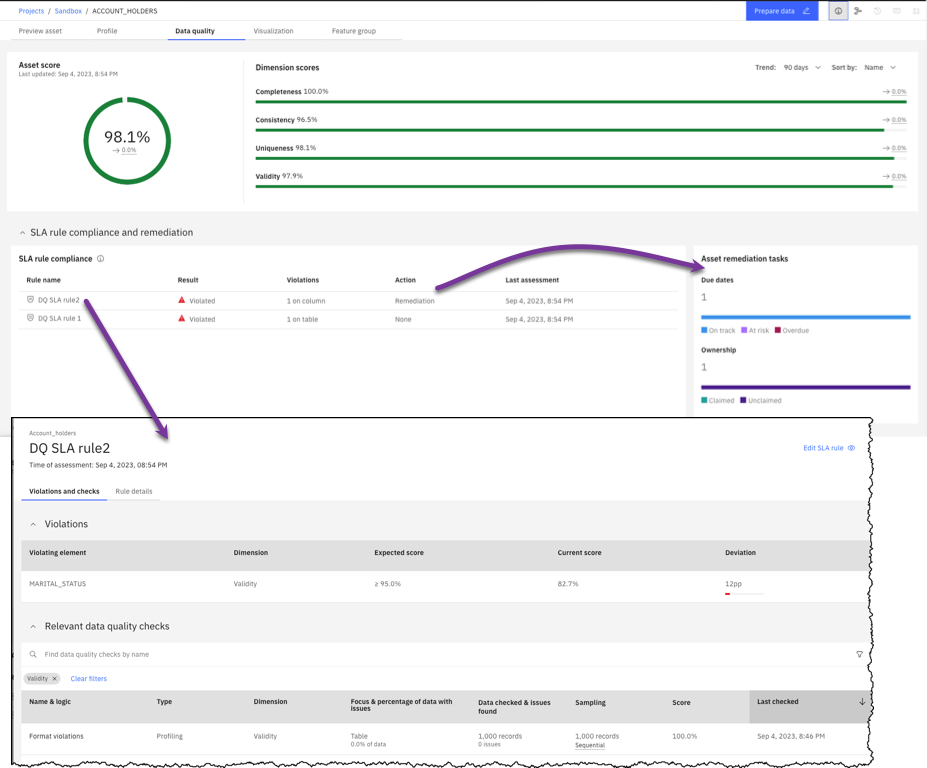
For more information, see:
Remove suggested names and descriptions from the metadata enrichment results (IBM Knowledge Catalog)
12 December 2024
In the metadata enrichment results, you can now remove suggested display names or descriptions in bulk that are suggested when the enrichment is run with the Expand metadata option. See Making bulk changes to metadata enrichment results.
Use data source definitions to manage and protect data that is accessed from connections
12 December 2024
Data source definitions are a new type of asset that you define based on a connection or connected data asset's endpoints. When you create a data source definition, you can monitor where your data is stored across multiple projects, catalogs, or multi-node data sources. You can also apply the correct protection solution (enforcement engine) based on the data source definition. For details, see Data protection with data source definitions.
These new data source definition features are now available in all regions.
Defining a data source definition with a protection solution (IBM Knowledge Catalog)
09 December 2024
A protection solution is a method of enforcing the data protection rules either in governed catalogs or by a deep enforcement solution.
To configure the platform with a deep enforcement solution, you can create a data source definition to set the data source type. The data source type determines which types of connections the data source definition can be associated with and your available protection solution options. For details, see Protection solutions for data source definition.
These new data source definition features are now available in all regions.
Deprecation of features for Masking flow
11 December 2024
The following features are deprecated and are now removed:
- Reversible option is now removed for obfuscating data, which you can later reverse the masking to recover the original values.
- Reversible encryption is no longer available for creating copies of data by creating masking flows and one-way hash tokenization for flexible compliance.
- Decrypt reversible masked data is no longer available.
Updated SPSS Modeler tutorials
11 December 2024
Get hands-on experience with SPSS Modeler by trying the 15 updated SPSS Modeler tutorials.
IBM Knowledge Catalog is available in the Sydney region
09 December 2024
IBM Knowledge Catalog is now also available in the Sydney data center. You can select Sydney as your preferred region when you sign up.
For more information about product features that are available in the Sydney region, see Regional availability for services and features.
IBM DataStage is available in the Sydney region
09 December 2024
DataStage is now generally available in the Sydney data center. You can select Sydney as your preferred region when signing-up.
For more information about the product features that are available in the Sydney region, see Regional availability for services and features.
IBM watsonx.governance is available in the Sydney region
9 December 2024
IBM watsonx.governance is now generally available in the Sydney data center. You can select Sydney as your preferred region when signing-up.
For more information about the product features that are available in the Sydney region, see Regional availability for services and features.
Week ending 06 December 2024
New data sources for lineage metadata import
06 December 2024
You can now import lineage metadata from the following data sources. After the data is imported, you can visualize it on a lineage graph. For more information, see Supported data sources for curation and data quality.
Deprecation of IBM Cloud Object Storage Lite plan (IBM Knowledge Catalog)
05 December 2024
The Cloud Object Storage Lite plans with unlimited duration that you provisioned prior to 1 July 2024 are deprecated and might be removed after 15 December 2024. To retain your data and other assets, you must upgrade your Cloud Object Storage service to a Standard plan before 15 December 2024. If you do not upgrade your Cloud Object Storage plan to Standard, your workspaces might become inaccessible after 15 December 2024, and your data might be permanently deleted. For more information, see Lite plan (deprecated).
Microsoft Excel files are deprecated for OPL models in Decision Optimization
05 December 2024
Microsoft Excel workbook (.xls and .xlsx) files are now deprecated for direct input and output in Decision Optimization OPL models. To connect to Excel files, use a data connector instead. The data connector transforms your Excel file into a .csv file. For more information, see Referenced data.
Enhanced scheduling of metadata enrichment jobs (IBM Knowledge Catalog)
05 December 2024
You can now configure execution windows for your metadata enrichment jobs to balance workloads. Jobs then run only within the configured time frames. For more information, see Managing scheduling of enrichment jobs.
Segment data assets by column values to focus on the information you need (IBM Knowledge Catalog)
05 December 2024
You can now chunk data assets into smaller data assets based on selected column values to help you access only the data that you’re interested in. For more information, see Creating data assets by segmenting column data.
New sample notebooks for deploying models converted to ONNX format
03 December 2024
You can now deploy machine learning and generative AI models that are converted to ONNX format and use the endpoint for inferencing. These models can also be adapted to dynamic axes. See the following sample notebooks:
- Convert ONNX neural network from fixed axes to dynamic axes
- Use ONNX model converted from PyTorch
- Use ONNX model converted from TensorFlow to recognize hand-written digits
For more information, see watsonx.ai Runtime Python client samples and examples.
Week ending 29 November 2024
Improved documentation on write options for Data Refinery
28 November 2024
The write options and table options for exporting data flows depends on your connection. These options are now explained so that you are better guided to select your target table options. For more information, see Target connection options for Data Refinery.
Week of 25 November 2024
Name change for Watson Query service
25 November 2024
The Watson Query service was renamed to Data Virtualization.
Week ending 22 November 2024
Name change for Watson Studio and Watson Machine Learning services
21 November 2024
The following services were renamed:
- Watson Machine Learning is now named watsonx.ai Runtime.
- Watson Studio is now named watsonx.ai Studio.
Some videos, notebooks, and code samples might continue to refer to these services by their former names.
Cloud Pak for Data as a Service is available in the Sydney region
21 November 2024
Cloud Pak for Data as a Service is now generally available in the Sydney data center with watsonx.ai Runtime and watsonx.ai Studio services. When you sign-up, you can select Sydney as the preferred region.
Not all of the services are available in the Sydney region yet. For more information about product features that are available in the Sydney region, see Regional availability for services and features.
Enhanced monitoring of metadata enrichment jobs (IBM Knowledge Catalog)
21 November 2024
On the new run metrics dashboard, you can monitor the progress of the individual enrichment tasks for an active metadata enrichment job run. In addition, you can explore run information for completed job runs to identify if and where issues occurred. For more information, see Monitoring runs of enrichment jobs.
Promote SPSS Modeler flows to deployment spaces
19 November 2024
You can now directly promote SPSS Modeler flows from projects to deployment spaces without having to export the project and then import it into the deployment space. For more information, see Promoting SPSS Modeler flows and models.
Week ending 15 November 2024
Task credentials are now required to deploy assets and run jobs from a deployment space
11 November 2024
To improve the security for running deployment jobs, you must enter your task credentials to deploy the following assets from a deployment space:
- Prompt templates
- AI services
- Models
- Python functions
- Scripts
Additionally, you must enter your task credentials to create the following deployments from your deployment space:
- Online
- Batch
You must also use your task credentials to create and manage deployment jobs from your deployment space.
To learn how to set up your task credentials and generate an API key, see Adding task credentials.
Editor mode for custom properties (IBM Knowledge Catalog)
14 November 2024
When viewing governance artifacts, you can now switch on the editor mode for custom properties. When the Edit values toggle is switched off in the Details section, you can only see those custom properties for which values were definded for the artifact. Switch the editor mode on, and you can see all available custom properties and edit their values. For more information, see Custom properties, relationships, and asset types.
Week ending 8 November 2024
Connect to new data sources with SPSS Modeler
7 November 2024
You can now connect SPSS Modeler to Databricks and Microsoft Azure Synapse Analytics, and SPSS Modeler has read and write access to both data sources. For more information, see Microsoft Azure Databricks connection and Microsoft Azure Synapse Analytics connection.
Week ending 1 November 2024
Deprecation of IBM Runtime 23.1
28 October 2024
IBM Runtime 23.1 is deprecated. Beginning November 21, 2024, you cannot create new notebooks or custom environments by using 23.1 runtimes. Also, you cannot create new deployments with software specifications that are based on the 23.1 runtime. To ensure a seamless experience and to leverage the latest features and improvements, switch to IBM Runtime 24.1.
- For information about changing environments, see Changing notebook environments.
- For details on deployment frameworks, see Managing frameworks and software specifications.
Week ending 25 October 2024
Compare tables in Decision Optimization experiments to see differences between scenarios
23 October 2024
You can now compare tables in a Decision Optimization experiment in either the Prepare data or Explore solution view. This comparison can be useful to see data value differences between scenarios displayed
next to each other.
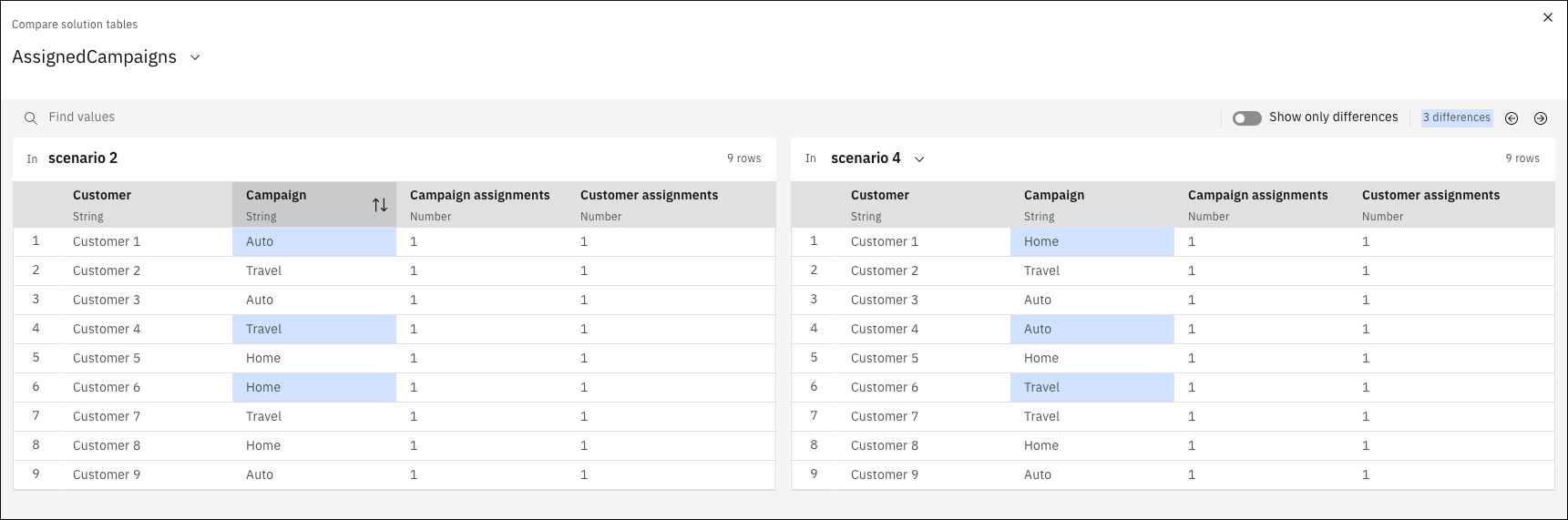
For more information, see Compare scenario tables.
Week ending 18 October 2024
Account resource scoping is enabled by default
17 October 2024
The Resource scopeONONOFF
When resource scoping is enabled, you can’t access projects that are not in your currently selected IBM Cloud account. If you belong to more than one IBM Cloud account, you might not see all your projects listed together. For example, you might not see all your projects on the All projects page. You must switch accounts to see the projects in the other accounts.
Week ending 11 October 2024
Analyze Japanese text data in SPSS Modeler with Text Analytics
9 October 2024
You can now use the Text Analytics nodes in in SPSS Modeler, such as the Text Link Analysis node and Text Mining node, to analyze text data written in Japanese.
Week ending 4 October 2024
Introducing IBM Manta Data Lineage: a new service that provides data lineage for your data
04 October 2024
IBM Manta Data Lineage is a data lineage service that increases data pipeline transparency so you can determine data accuracy throughout business models and systems. For information about data lineage, see Data lineage.
This service requires IBM Knowledge Catalog service and enabling data lineage on your IBM Cloud account. See, Enable data lineage. It is available only in the Dallas region.
You can access your imported lineages in the new workspace Data lineage or view lineage for a specific asset through Catalogs or Projects page.
You can import lineage metadata from the following sources:
- Microsoft Azure SQL Database connection
- Microsoft SQL Server connection
- Microsoft Power BI (Azure) connection
- Snowflake connection
- InfoSphere DataStage
- IBM DataStage for Cloud Pak for Data
For more information about metadata import, see Importing metadata.
Improved Draft tab for governance artifacts (IBM Knowledge Catalog)
3 October 2024
For each artifact type, you can now view all available drafts in the Draft tab. To view it, select the artifact type from the main menu and click Draft. The tab is visible only if you have the required permissions and if any drafts are available. When viewing all your drafts in the tab, you can select multiple drafts and use the bulk actions menu to edit or process them at once. Note that the All drafts page is no longer available from the main menu. For more information, see Managing governance artifacts.
Bulk actions on catalog assets (IBM Knowledge Catalog)
3 October 2024
You can now edit and remove classifications and custom properties for multiple assets in a catalog at the same time.
Automatically updated common properties of data assets (IBM Knowledge Catalog)
3 October 2024
With global asset identification, you can ensure that the common properties of data assets that have the same resource key and reference the same physical resource stay the same even if they're in different projects or catalogs. This way, you can manage such data assets properly and consistently. For more information, see Globla asset identification.
Assign user groups as asset members (IBM Knowledge Catalog)
3 October 2024
You can now assign user groups as asset members. Previously, you could add only individual catalog users as asset members.
Upload and update assets in bulk (IBM Knowledge Catalog)
3 October 2024
To upload and update multiple assets in bulk, you can now import and export CSV files with either asset metadata details or asset relationship details, or both. For more information, see Adding and updating assets and asset metadata from CSV files to catalogs).
Availability of watsonx.governance plan in Frankfurt region and deprecation of OpenScale legacy plan
3 October 2024
The watsonx.governance legacy plan to provision Watson OpenScale in the Frankfurt region is deprecated. IBM Watson OpenScale will no longer be available for new subscription or to provision new instances. For OpenScale capabilities, subscribe to the watsonx.governance Essentials plan, which is now available in Frankfurt as well as Dallas.
- To view plan details, see watsonx.governance plans.
- To get started, see Provisioning and launching watsonx.governance.
Notes:
- Existing legacy plan instances will continue to operate and will be supported until the End of Support date which remains to be determined.
- Existing customers on IBM Watson OpenScale can continue to open support tickets using IBM Watson OpenScale.
Updated environments and software specifications
3 October 2024
The Tensorflow and Keras libraries that are included in IBM Runtime 23.1 are now updated to their newer versions. This might have an impact on how code is executed in your notebooks. For details, see Library packages included in watsonx.ai Studio (formerly Watson Studo) runtimes.
Runtime 23.1 will be discontinued in favor of IBM Runtime 24.1 later this year. To avoid repeated disruption we recommend that you switch to IBM Runtime 24.1 now and use related software specifications for deployments.
- For information about changing environments, see Changing notebook environments.
- For details on deployment frameworks, see Managing frameworks and software specifications.
Use data source definitions to manage and protect data that is accessed from connections
04 October 2024
Data source definitions are a new type of asset that you define based on a connection or connected data asset's endpoints. When you create a data source definition, you can monitor where your data is stored across multiple projects, catalogs, or multi-node data sources. You can also apply the correct protection solution (enforcement engine) based on the data source definition. For details, see Data protection with data source definitions.
These new data source definition features are available only in the Dallas region.
Defining a data source definition with a protection solution (IBM Knowledge Catalog)
04 October 2024
A protection solution is a method of enforcing the data protection rules either in governed catalogs or by a deep enforcement solution.
To configure the platform with a deep enforcement solution, you can create a data source definition to set the data source type. The data source type determines which types of connections the data source definition can be associated with and your available protection solution options. For details, see Protection solutions for data source definition.
These new data source definition features are available only in the Dallas region.
Review and manage data class and term assignments in a spreadsheet (IBM Knowledge Catalog)
04 October 2024
If you prefer to work in a familiar spreadsheet program when you review and update metadata enrichment results, you can now install the Review metadata add-in for Microsoft Excel. Use the spreadsheet template provided with the product in combination with the add-in:
- To download enriched data assets from a specific project and metadata enrichment.
- To review and update suggested and assigned data classes and terms for these data assets.
- To upload the updated data assets to the project.
For more information, see Reviewing and updating enrichment results in an external program.
Week ending 27 September 2024
Removal of Spark 3.3 runtime
23 September 2024
Support for Spark 3.3 runtime in IBM Analytics Engine will be removed by October 29, 2024 and the default version will be changed to Spark 3.4 runtime. To ensure a seamless experience and to leverage the latest features and improvements, switch to Spark 3.4.
Beginning October 29, 2024, you cannot create or run notebooks or custom environments by using Spark 3.3 runtimes. Also, you cannot create or run deployments with software specifications that are based on the Spark 3.3 runtime.
- To upgrade your instance to Spark 3.4, see Replace Instance Default Runtime.
- For details on available notebook environments, see Changing the environment of a notebook.
- For details on deployment frameworks, see Managing frameworks and software specifications.
Week ending 20 September 2024
Group data quality rules (IBM Knowledge Catalog)
20 September 2024
You can now group certain types of data quality rules into a single DataStage flow and run them together. For more information, see Grouping rules.
Week ending 13 September 2024
Create batch jobs for SPSS Modeler flows in deployment spaces
10 September 2024
You can now create batch jobs for SPSS Modeler flows in deployment spaces. Flows give you the flexibility to decide which terminal nodes to run each time that you create a batch job from a flow. When you schedule batch jobs for flows, the batch job uses the data sources and output targets that you specified in your flow. The mapping for these data sources and outputs is automatic if the data sources and targets are also in your deployment space. For more information about creating batch jobs from flows, see Creating deployment jobs for SPSS Modeler flows.
For more information about flows and models in deployment spaces, see Deploying SPSS Modeler flows and models.
Week ending 30 August 2024
Change pipeline node shape
30 August 2024
You can now change pipeline nodes' appearance to turn them from uniform card style into more compact sized shapes which reflect the type of node. For more information, see Pipelines settings.
Create global parameter sets
30 August 2024
You can now add PROJDEF parameters to your pipeline parameter sets. The parameters can be referenced from both DataStage and Orchestration Pipelines flows at the same project level. For more information, see Configuring global objects for Orchestration Pipelines.
Week ending 23 August 2024
Add user groups as collaborators in projects and spaces
22 August 2024
You can now add user groups as collaborators in projects and spaces if your IBM Cloud account contains IAM access groups. Your IBM Cloud account administrator can create access groups, which are then available as user groups in projects. While creating a project, you must leave the Restrict who can be a collaborator option enabled to add user groups as collaborators. For more information, see Working with IAM access groups.
Support ending for anomaly prediction feature for AutoAI time-series experiments
19 August 2024
The feature to predict anomalies (outliers) in AutoAI time-series model predictions, currently in beta, is deprecated and will be removed on Sep 23, 2024. Standard AutoAI time-series experiments are still fully supported. For details, see Building a time series experiment.
Assign classifications in metadata enrichment (IBM Knowledge Catalog)
22 August 2024
You can now assign classifications to data assets and columns in metadata enrichment, either automatically based on term or data-class assignment or manually in the enrichment results. See Designing metadata enrichment: Assign terms and classifications.
Week ending 16 August 2024
Archive and unarchive projects and spaces
16 August 2024
Projects and spaces are now archived after 90 days of inactivity to preserve resources. To work with such projects or spaces again, unarchive them by opening them directly on the project or space page. Depending on the size of the project or space, unarchiving might take a varied amount of time.
Configure asset removal
16 August 2024
Now, when you create a new catalog, you can also decide how you want to configure the removal of assets. You can either select to purge the assets automatically either immediately after the removal or 30 days after the removal. For previously created catalogs, you can change asset removal settings on the catalog Settings page.
For more information, see:
Task credentials are now required to run jobs in a deployment space
15 August 2024
To improve the security for running deployment jobs, you must enter your task credentials to run job in a deployment space. For more information, see Creating jobs in deployment spaces.
To learn how to set up your task credentials and generate an API key, see Adding task credentials.
Week ending 26 July 2024
Pausing metadata enrichment (IBM Knowledge Catalog)
25 July 2024
You can now pause and resume metadata enrichment job runs. For details, see Pausing and resuming enrichment job runs.
Announcing support for Python 3.11 and R4.3 frameworks and software specifications on runtime 24.1
25 July 2024
You can now use IBM Runtime 24.1, which includes the latest data science frameworks based on Python 3.11 and R 4.3, to run Jupyter notebooks and R scripts, and train models. Starting on July 29, you can also run deployments. Update your assets and deployments to use IBM Runtime 24.1 frameworks and software specifications.
- For information on the IBM Runtime 24.1 release and the included environments for Python 3.10 and R 4.2, see Notebook environments.
- For details on deployment frameworks, see Managing frameworks and software specifications.
Enhanced version of Jupyter Notebook editor is now available
25 July 2024
If you're running your notebook in environments that are based on Runtime 24.1, you can use these enhancements to work with your code:
- Automatically debug your code
- Automatically generate a table of contents for your notebook
- Toggle line numbers next to your code
- Collapse cell contents and use side-by-side view for code and output, for enhanced productivity
For more information, see Jupyter notebook editor.
Natural Language Processor transformer embedding models supported with Runtime 24.1
25 July 2024
In the new Runtime 24.1 environment, you can now use natural language processing (NLP) transformer embedding models to create text embeddings that capture the meaning of a sentence or passage to help with retrieval-augmented generation tasks. For more information, see Embeddings.
New specialized NLP models are available in Runtime 24.1
25 July 2024
The following new, specialized NLP models are now included in the Runtime 24.1 environment:
- A model that is able to detect and identify hateful, abusive, or profane content (HAP) in textual content. For more information, see HAP detection.
- Three pre-trained models that are able to address topics related to finance, cybersecurity, and biomedicine. For more information, see Classifying text with a custom classification model.
Extract detailed insights from large collections of texts by using Key Point Summarization
25 July 2024
You can now use Key Point Summarization in notebooks to extract detailed and actionable insights from large collections of texts that represent people’s opinions (such as product reviews, survey answers, or comments on social media). The result is delivered in an organized, hierarchical way that is easy to process. For more information, see Key Point Summarization
RStudio version update
25 July 2024
To provide a consistent user experience across private and public clouds, the RStudio IDE for the Cloud Pak for Data as a Service will be updated to RStudio Server 2024.04.1 and R 4.3.1 on July 29, 2024. The new version of RStudio provides a number of enhancements and security fixes. See the RStudio Server 2024.04.1 release notes for more information. While no major compatibility issues are anticipate, users should be aware of the version changes for some packages described in the following table below.
When launching the RStudio IDE from a project after the upgrade, reset the RStudio workspace to ensure that the library path for R 4.3.1 packages is picked up by the RStudio Server.
Week ending 12 July 2024
Tracking data protection rule enforcement decisions
9 July 2024
You can now track enforcement decisions as audit events when the Send policy evaluations to audit logs checkbox is selected from the Managing rule settings page.
Week ending 5 July 2024
Connectors grouped by data source type
05 July 2024
When you create a connection, the connectors are now grouped by data source type so that the connectors are easier to find and select. For example, the MongoDB data source type includes the IBM Cloud Databases for MongoDB and the MongoDB connectors.
In addition, a new Recents category shows the six latest connectors that you used to create a connection.
For instructions, see Adding connections to data sources in a project or Adding connections to data sources in a catalog.
Bulk edits for governance artifact properties
05 July 2024
You can now change the primary or secondary category for multiple governance artifacts at once. Bulk edits are also available when updating relationships. For more information, see Managing governance artifacts.
Setting an assignment threshold for results of relationship analyses (IBM Knowledge Catalog)
05 July 2024
You now also set a threshold for when results of a relationship analysis should be assigned automatically. You can set a project default but overwrite the setting for each analysis run. For details, see Identifying relationships.
Changes to Cloud Object Storage Lite plans
01 July 2024
Starting on 1 July 2024, the Cloud Object Storage Lite plan that is automatically provisioned when you sign up for a 30 day trial of Cloud Pak for Data as a Service expires after the trial ends. You can upgrade your Cloud Object Storage Lite instance to the Standard plan with the Free Tier option at any time during the 30 day trial.
Existing Cloud Object Storage service instances with Lite plans that you provisioned prior to 1 July 2024 will be retained until 15 December 2024. You must upgrade your Cloud Object Storage service to a Standard plan before 15 December 2024.
Week ending 21 June 2024
Adding catalog assets to projects
20 June 2024
Added a Add catalog assets to projects user permission. Now, to add assets to projects, you must have the Add catalog assets to projects, the Admin, Editor or Viewer role in the catalog, and be the asset owner or editor. Users that don't have an existing role with the Manage catalogs or Access catalogs permission must be explicitly granted the Add catalog assets to projects permission.
Cognos Dashboard removal postponed
20 June 2024
Any existing dashboards that you created with the Cognos Dashboards Embedded service will now continue working until 30 September 2024. You can no longer provision an instance of the Cognos Dashboards Embedded service. You can use Cognos Analytics on Cloud On-Demand as a replacement for Cognos Dashboards Embedded. For more information, see IBM Cognos Analytics Pricing Plans.
Task credentials will be required for deployment job requests
19 Jun 2024
To improve security for running deployment jobs, the user requesting the job will be required to provide task credentials in the form of an API key. The requirement will be enforced starting August 15, 2024. See Adding task credentials for details on generating the API key.
Enhanced data enrichment in IBM Knowledge Catalog
20 Jun 2024
In addition to the existing capabilities, metadata enrichment now provides options for semantic and AI-augmented data enrichment:
- Recommend descriptive names for tables and columns based on the collected metadata and a predefined glossary.
- Suggest and assign semantic descriptions for the contents of tables and columns based on the surrounding columns and the context of the tables.
- Complete semantic term assignment for tables and columns.
For details, see Designing metadata enrichments.
These new gen AI based metadata enrichment features are available only in the Dallas region.
IBM Federated Learning Python client change
20 Jun 2024
Federated Learning's Python client library has been merged with the watsonx.ai library. Your code samples must be updated with the newest Python client. See Connecting to the aggregator.
Connect to a new data source in DataStage: IBM Planning Analytics
14 Jun 2024
You can now include data from an IBM Planning Analytics data source in your DataStage flows.
For the full list of DataStage connectors, see Supported data sources in DataStage.
Week ending 7 June 2024
Bulk edits for governance artifacts
7 Jun 2024
You can now make changes to multiple governance artifacts at once when you want to edit tags or stewards. For more information, see Managing governance artifacts.
Changing parent category for individual artifacts
7 Jun 2024
When viewing artifact details, you can now change the parent category by selecting Move to from the three-dot action menu.
Data protection rules no longer enforced in projects
7 June 2024
Data protection rules are now only enforced either in governed catalogs or by a deep enforcement solution. A deep enforcement solution is a protection solution to enforce rules on data that is outside of Cloud Pak for Data when the data source is integrated with one of these services:
- IBM Data Virtualization
- IBM watsonx.data
Assets that are added into projects from a governed catalog no longer have preview, download or profiling restricted by data protection rules unless you have configured a deep enforcement solution.
You will be reminded of the revised data protection rule enforcement protocols when you:
- Creating a data protection rule.
- Copying an asset from a governed catalog into a project
For details, see Accept revised protocol for enforcing data protection rules.
Managing reports settings
6 June 2024
IBM Cloud account owners or administrators can now manage the reports settings on the Account page. For more information, see Managing your account settings.
Week ending 31 May 2024
IBM Watson Pipelines is now IBM Orchestration Pipelines
30 May 2024
The new service name reflects the capabilities for orchestrating parts of the AI lifecycle into repeatable flows.
Tag projects for easy retrieval
31 May 2024
You can now assign tags to projects to make them easier to group or retrieve. Assign tags when you create a new project or from the list of all projects. Filter the list of projects by tag to retrieve a related set of projects. For more information, see Creating a project.
Connect to a new data source: Milvus
31 May 2024
Use the Milvus connection to store and confirm the accuracy of your credentials and connection details to access a Milvus vector store. For information, see Milvus connection.
Week ending 24 May 2024
Asset user and role
24 May 2024
Updated the asset membership roles for catalogs. Now, users can hold the asset owner, asset editor, or asset viewer role. The asset editor role replaced the asset member role. Now, to complete any asset-related actions, you must be an asset owner or asset editor.
Also, assets might have more than one owner now.
You can change asset user roles on the Access control page of an asset by selecting a role from the Role dropdown menu.
Bulk actions on catalog assets
24 May 2024
You can now edit and remove the business terms, owners or tags on up to 20 catalog assets at a time.
Week ending 10 May 2024
New filters for enrichment results (IBM Knowledge Catalog)
10 May 2024
You can now apply additional filters to your enrichment results:
- Assigned, suggested, or no business terms
- Assigned, suggested, or no data class
Name changes for DataStage connections and connectors
10 May 2024
The following DataStage connections and connectors have new names:
- "Apache Cassandra (optimized)" is now "Apache Cassandra for DataStage".
- "IBM Db2 (optimized") is now "IBM Db2 for DataStage".
- "IBM Netezza Performance Server (optimized)" is now "IBM Netezza Performance Server for DataStage".
- "Oracle (optimized)" is now "Oracle Database for DataStage".
- "Salesforce.com (optimized)" is now "Salesforce API for DataStage".
- "Teradata (optimized)" is now "Teradata database for DataStage".
Your previous settings for the connections, connectors, and their associated jobs remain the same. Only the connection and connector names have changed.
Week ending 26 April 2024
Name change for the IBM Watson Query connection
26 Apr 2024
The "IBM Watson Query" connection has been renamed to "IBM Data Virtualization". Your previous settings for the connection remain the same. Only the connection name has changed.
Name change for the DataStage IBM Watson Query connector
26 Apr 2024
The DataStage "IBM Watson Query" connector name has changed to "IBM Data Virtualization". This change coincides with the connection name change. Your previous settings for the connection, connector, and the associated jobs remain the same. Only the connection and connector name have changed.
Masking watsonx.data in IBM Knowledge Catalog
26 Apr 2024
You can protect sensitive data in watsonx.data by using masking capabilities of IBM Knowledge Catalog. For more information, see Masking watsonx.data assets in IBM Knowledge Catalog.
Week ending 19 April 2024
Enhanced project list view in catalogs
18 Apr 2024
Now, when you are adding assets from a catalog to a project, you can view more than 100 projects in your project list page and add up to 50 assets at a time to your project. For more information, see Add assets from within the catalog.
Evaluate machine learning deployments in spaces
18 Apr 2024
Configure watsonx.governance evaluations in your deployment spaces to gain insights about your machine learning model performance. For example, evaluate a deployment for bias or monitor a deployment for drift. When you configure evaluations, you can analyze evaluation results and model transaction records directly in your spaces.
For more information, see Evaluating deployments in spaces.
19 Apr 2024
Factsheets available from AI use cases on main navigation menu
Factsheets that track lifecycle details for machine learning models are now stored in AI uses cases rather than model use cases. AI use cases and external models are displayed on the main navigation menu for easy access.
Week ending 12 April 2024
Revised data protection rule enforcement protocol across Cloud Pak for Data
12 Apr 2024
A revised version of the data protection rule enforcement protocol is now in place across Cloud Pak for Data. When you're inside of a governed catalog and click Add to project
Cognos Dashboards Embedded service is deprecated
11 Apr 2024
You can no longer provision an instance of the Cognos Dashboards Embedded service. However, any existing dashboards that you created with the Cognos Dashboards Embedded service will continue working until 20 June 2024. You can use Cognos Analytics on Cloud On-Demand as a replacement for Cognos Dashboards Embedded. For more information, see IBM Cognos Analytics Pricing Plans.
Week ending 5 April 2024
Use pivot tables to display data aggregated in Decision Optimization experiments
5 Apr 2024
You can now use pivot tables to display both input and output data aggregated in the Visualization view in Decision Optimization experiments. For more information, see Visualization widgets in Decision Optimization experiments.
Access the list of connection API properties from the user interface
05 Apr 2024
Previously the only way to view the connection properties was to open a new web page at https://dataplatform.cloud.ibm.com/connections/docs. Now you can access the same information from Data > Connectivity. Expand Connection resources, and select Connection properties.
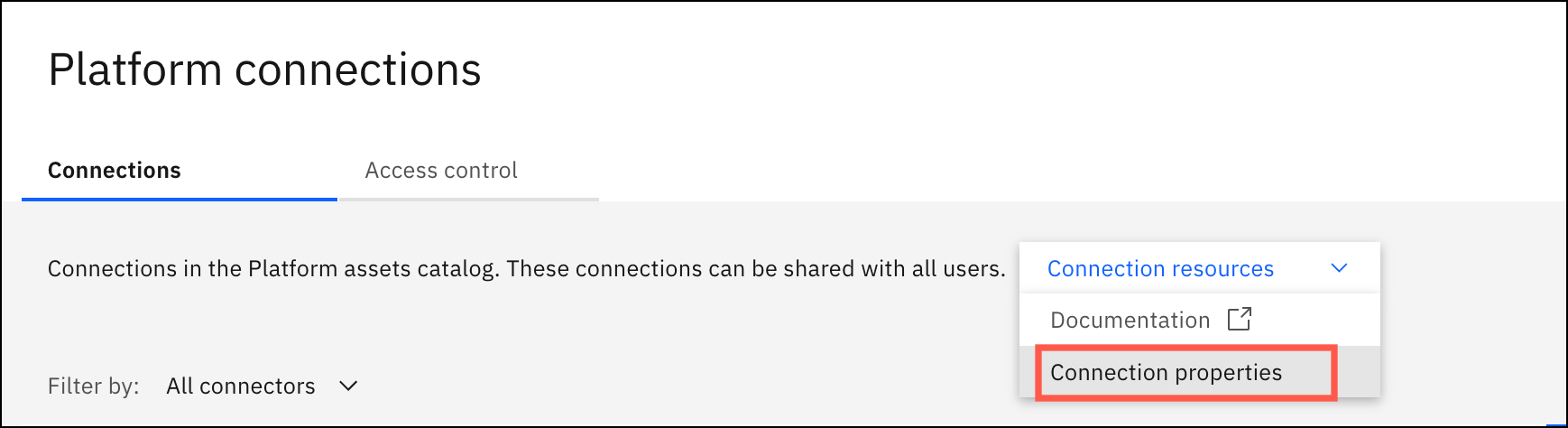
You can use these properties to create connections with the connections in the Watson Data API. For example, if you create a connection in a notebook programmatically, you can use this information to identify the properties that you need.
Week ending 22 March 2024
Create dynamic views of connected data (IBM Knowledge Catalog)
21 March 2024
A new type of connected data asset provides filtered access to data from data sources that support SQL queries so you can access only relevant data. In a project, provide an SQL query to create a view of specific columns or rows from one or more tables. You can use these data assets in metadata enrichment and data quality analysis just like any other connected data asset.
For more information, see Adding a dynamic view of connected data to a project.
Use Delta Lake or Apache Iceberg table formats in the Amazon S3 and the Apache HDFS connectors
22 March 2024
The Amazon S3 and the Apache HDFS connectors now include properties for the Delta Lake and Apache Iceberg table formats. These table formats are integral to data lakes, which provide a centralized repository for managing large data volumes. Data lakes serve as a foundation for collecting and analyzing structured, semi-structured, and unstructured data in its original format for long-term storage and to drive insights and predictions.
The table format property is included in the interaction properties for the supported tools. For example, in the connector Stage properties in DataStage.
Week ending 23 February 2024
New Watson OpenScale tutorial and video
23 Feb 2024
Try the new Watson OpenScale tutorial to help you learn how to evaluate a machine learning model for fairness, accuracy, drift, and explainability.
| Tutorial | Description | Expertise for tutorial |
|---|---|---|
| Evaluate a machine learning model | Deploy a model, configure monitors for the deployed model, and evaluate the model. | Run a notebook to configure the models and use Watson OpenScale to evaluate. |
Access data from DataStax Enterprise
23 Feb 2024
You can now work with data from DataStax Enterprise.
Week ending 16 February 2024
Case-sensitive codes in reference data sets in IBM Knowledge Catalog
16 Feb 2024
Reference data values consist of at least two columns: code and value. For all new reference data sets the code column is now case-sensitive. When you add values to a new reference data set, the code is saved exactly as you type it. Note that any reference data sets that were created before this change was introduced remain case-insensitive, and any new values added there will be saved in upper case. These reference data sets are marked with a Case-insensitive tag in the UI. For details, see Case-sensitive code.
Improved search, filter and sort options for reference data sets in IBM Knowledge Catalog
16 Feb 2024
When you view a list of reference data values, you can use the following methods to find the required values faster:
- Use a search bar to type a query for a code, value or a custom column value.
- Use one of the 6 advanced filter options.
- Use the sorting feature.
The search, filter, and sort options can be combined. For details, see Viewing reference data sets.
Week ending 09 February 2024
New Spark 3.4 environment for running Data Refinery flow jobs
09 Feb 2024
When you select an environment for a Data Refinery flow job, you can now select Default Spark 3.4 & R 4.2, which includes enhancements from Spark.
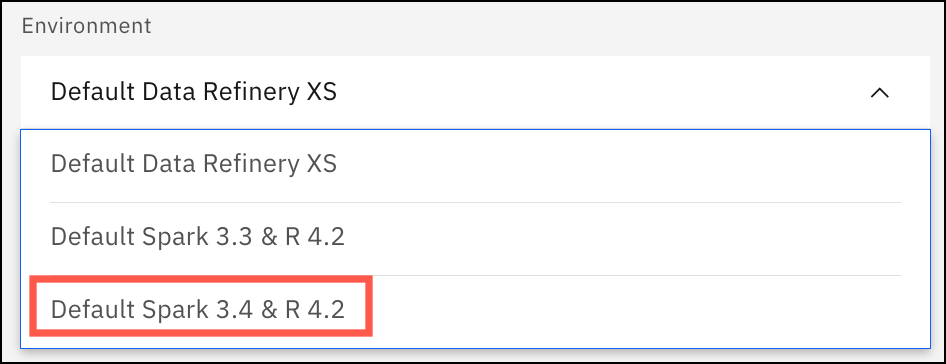
The Default Spark 3.3 & R 4.2 environment is deprecated and will be removed in a future update.
Update your Data Refinery flow jobs to use the new Default Spark 3.4 & R 4.2 environment. For details, see Compute resource options for Data Refinery in projects.
More task-oriented Decision Optimization documentation
09 Feb 2024
You can now more easily find the right information for creating and configuring Decision Optimization experiments. See Decision Optimization experiments and its subsections.
Pagination view feature to publish assets to a catalog
08 Feb 2024
When you are publishing project assets to a catalog, you can now view 20 catalogs and assets on each page with the pagination view. Previously, you can view your assets on a list. See Publishing assets to a catalog.
Advanced analysis types in metadata enrichment are available in the Frankfurt region (IBM Knowledge Catalog)
09 Feb 2024
Advanced primary key and relationship analysis and advanced profiling are now also available in the Frankfurt region, in addition to the Dallas region.
IBM Cloud Data Engine connection is deprecated
08 Feb 2024
The IBM Cloud Data Engine connection is deprecated and will be discontinued in a future release. See Deprecation of Data Engine for important dates and details.
Week ending 02 February 2024
Save your searches for catalog assets
02 Feb 2024
Each user can now save up to 25 searches within each of their catalogs. The user who saves a search in a catalog is the only user who can view, run, edit, and remove the search. For more information, see Saving searches for catalog assets.
Gallery renamed to Resource hub
02 Feb 2024
The Gallery is renamed to Resource hub. The Resource hub contains sample projects, data sets, and notebooks. See Resource hub.
IBM Cloud Databases for DataStax connection is discontinued
02 Feb 2024
The IBM Cloud Databases for DataStax connection has been removed from Cloud Pak for Data as a Service.
Dremio connection requires updates
02 Feb 2024
Previously the Dremio connection used a JDBC driver. Now the connection uses a driver based on Arrow Flight.
Important: Update the connection properties. Different changes apply to a connection for a Dremio Software (on-prem) instance or a Dremio Cloud instance.
Dremio Software: Update the port number.
The new default port number that is used by Flight is 32010
Additionally, Dremio no longer supports connections with IBM Cloud Satellite.
Dremio Cloud: Update the authentication method and hostname.
- Log into Dremio and generate a personal access token. For instructions see Personal Access Tokens.
- In Cloud Pak for Data as a Service in the Create connection: Dremio form, change the authentication type to Personal Access Token and add the token information. (The Username and password authentication can no longer be used to connect to a Dremio Cloud instance.)
- Select Port is SSL-enabled.
If you use the default hostname for a Dremio Cloud instance, you need to change it:
- Change
sql.dremio.clouddata.dremio.cloud - Change
sql.eu.dremio.clouddata.eu.dremio.cloud
Additional analysis types in metadata enrichment (IBM Knowledge Catalog)
31 Jan 2024
Metadata enrichment now provides these additional analysis options:
-
Primary key analysis to detect primary keys in your data that uniquely identify each record in a data asset.
Shallow analysis is automatically included when you select the Profile data enrichment option. Advanced analysis can be run on selected assets from the enrichment results.
-
Relationship analysis to identify relationships between data asset or to find overlapping and redundant data in columns.
Shallow key relationship analysis is run when you select the new Set relationships enrichment option. Advanced analysis can be run on selected assets from the enrichment results.
-
Advanced profiling to get more exact results for certain metrics, such as frequency distribution and uniqueness of values within a column.
Advanced profiling can be run on selected assets from the enrichment results.
Advanced primary key and relationship analysis and advanced profiling require the DataStage service in addition to the IBM Knowledge Catalog service and are available only in the Dallas region.
For more information, see Creating a metadata enrichment asset, Identifying primary keys, Identifying relationships, and Advanced data profiles.
Week ending 26 January 2024
AutoAI supports ordered data for all experiments
25 Jan 2024
You can now specify ordered data for all AutoAI experiments rather than just time series experiments. Specify if your training data is ordered sequentially, according to a row index. When input data is sequential, model performance is evaluated on newest records instead of a random sampling, and holdout data uses the last n records of the set rather than n random records. Sequential data is required for time series experiments but optional for classification and regression experiments.
Set to dark theme
25 Jan 2024
You can now set your Cloud Pak for Data as a Service user interface to dark theme. Click your avatar and select Profile and settings to open your account profile. Then, set the Dark theme switch to on. Dark theme is not supported in RStudio and Jupyter notebooks. For information on managing your profile, see Managing your settings.
Week ending 19 January 2024
View native type information in the details panel for asset columns
19 Jan 2024
Now, you can view both standardized and native data types directly in the column details panel. To view the native type information, click an asset column name from the Overview page of an asset.
New option for rule action precedence (IBM Knowledge Catalog)
18 Jan 2024
Rule action precedence enables you to specify how rules are applied when there are multiple rules with different actions on a data set. You can use the new Hierarchical enforcement option to configure a two-layer evaluation of data protection rules.
- The first layer evaluates the rules for an
AllowDeny - The second layer evaluates the rules for a
Transform
You can set this option from the user interface or from the access_decision_precedence
For more information, see Managing rule settings.
Store the results of data quality analysis (IBM Knowledge Catalog)
18 Jan 2024
You now have the option to write the output of the predefined data quality checks that are run as part of metadata enrichment to a database. For example, you might want to store this data so that you can use the tables for tracking quality issues and as input to remediation processes. For more information, see Creating a metadata enrichment.
Connect to a new data source in DataStage: Tableau
18 Jan 2024
You can now include data from a Tableau data source in your DataStage flows.
For the full list of DataStage connectors, see Supported data sources in DataStage.
Week ending 12 January 2024
Support for IBM Runtime 22.2 deprecated in watsonx.ai Runtime (formerly Watson Machine Learning)
11 Jan 2024
IBM Runtime 22.2 is deprecated and will be removed on 11 April 2024. Beginning 7 March 2024, you cannot create notebooks or custom environments by using the 22.2 runtimes. Also, you cannot train new models with software specifications that are based on the 22.2 runtime. Update your assets and deployments to use IBM Runtime 23.1 before 7 March 2024.
- To learn more about migrating an asset to a supported framework and software specification, see Managing outdated software specifications or frameworks.
- To learn more about the notebook environment, see Compute resource options for the notebook editor in projects.
- To learn more about changing your environment, see Changing the environment of a notebook.