Revenez chaque semaine pour découvrir les nouvelles fonctionnalités et les mises à jour de Cloud Pak for Data as a Service et des services tels que watsonx.ai Studio (anciennement Watson Studio, watsonx.ai Runtime (anciennement Watson Machine Learning), DataStage, et IBM Knowledge Catalog
Semaine se terminant le 7 février 2025
Dépréciation de l'onglet Actifs recommandés ( IBM Knowledge Catalog )
4 février 2025
L'onglet Recommandé, qui contient des actifs qui vous sont recommandés en fonction des propriétés communes aux actifs que vous avez consultés, créés et ajoutés à des projets sur la page Actifs, est obsolète et sera supprimé en mars 2025.
Si vous avez des questions ou des préoccupations liées à la dépréciation, vous pouvez ouvrir un ticket d'assistance.
L'inventaire par défaut remplace le catalogue des actifs de la plate-forme dans les watsonx.governance
3 février 2025
Un inventaire par défaut est désormais disponible pour stocker les artefacts watsonx.governance, y compris les cas d'utilisation de l'IA, les modèles tiers, les pièces jointes et les rapports. L'inventaire par défaut remplace toute dépendance antérieure à l'égard du catalogue d'accès à la plate-forme ou de IBM Knowledge Catalog pour le stockage des artefacts de gouvernance.
Semaine se terminant le 21 janvier 2025
Manta Data Lineage est désormais également disponible dans la région de Sydney
21 janvier 2025
Manta Data Lineage est désormais également disponible dans le centre de données de Sydney. Vous pouvez sélectionner Sydney comme région préférée lors de votre inscription.
Pour plus d'informations sur les caractéristiques des produits disponibles dans la région de Sydney, voir Disponibilité régionale des services et des caractéristiques.
Semaine se terminant le 17 janvier 2025
Déployer les modèles convertis de CatBoost et LightGBM au format ONNX
15 janvier 2024
Vous pouvez désormais déployer des modèles d'apprentissage automatique et d'IA générative qui sont convertis de CatBoost et LightGBM au format ONNX et utiliser le point final pour l'inférence. Ces modèles peuvent également être adaptés aux axes dynamiques. Pour plus d'informations, voir Déployer des modèles convertis au format ONNX.
Nouveau tutoriel et nouvelle vidéo sur Evaluation Studio
13 janvier 2025
Essayez le nouveau didacticiel et la nouvelle vidéo d'Evaluation Studio pour apprendre à évaluer et à comparer les performances de vos ressources d'IA générative.
| Tutoriel | Descriptif | Expertise pour le tutoriel |
|---|---|---|
| Comparer les performances rapides | Évaluez et comparez vos actifs d'IA générative à l'aide de mesures quantitatives et de critères personnalisables adaptés à vos cas d'utilisation. | Utilisez le studio d'évaluation pour évaluer la performance de plusieurs actifs simultanément. |
Suppression des règles relatives à la localisation des données et à la souveraineté en matière de Data Privacy
13 janvier 2025
Les règles de localisation et de souveraineté des données sont des fonctions expérimentales qui permettent de contrôler l'accès aux données en fonction de leur localisation ou de leur souveraineté. Ces fonctionnalités expérimentales sont obsolètes et pourraient être supprimées en mars 2025. Pour plus de détails, voir Règles de localisation des données (expérimental).
Si vous avez des questions ou des préoccupations liées à la dépréciation, vous pouvez ouvrir un ticket d'assistance.
Semaine se terminant le 20 décembre 2024
Déployer des modèles convertis au format ONNX
20 décembre 2024
Vous pouvez désormais déployer des modèles d'apprentissage automatique et d'IA générative convertis au format ONNX et utiliser le point final pour l'inférence. Ces modèles peuvent également être adaptés aux axes dynamiques. Pour plus d'informations, voir Déployer des modèles convertis au format ONNX.
Déployer des flux SPSS Modeler multi-sources
20 décembre 2024
Vous pouvez désormais créer des déploiements pour les flux de SPSS Modeler qui utilisent plusieurs flux d'entrée pour fournir des données au modèle. Pour plus d'informations, voir Déployer des flux SPSS Modeler multi-sources.
Semaine se terminant le 13 décembre 2024
Nouvelles sources de données pour l'importation de métadonnées de lignée
12 décembre 2024
Vous pouvez désormais importer des métadonnées de lignage à partir des sources de données suivantes. Une fois les données importées, vous pouvez les visualiser sur un graphique de lignée. Pour plus d'informations, voir Sources de données prises en charge pour la curation et la qualité des données.
Contrôle de la qualité des données et workflows de remédiation IBM Knowledge Catalog
12 décembre 2024
Pour concentrer les efforts d'amélioration de la qualité sur les données les plus importantes pour votre organisation, vous identifiez les éléments de données critiques, définissez les attentes en matière de qualité et veillez à remédier aux problèmes de qualité des données.
Vous pouvez désormais élaborer des règles de qualité des données pour les accords de niveau de service (SLA) :
- Contrôler la qualité des données critiques par rapport à des critères de qualité spécifiques dans le cadre de l'enrichissement des métadonnées.
- Déclencher des flux de travail de remédiation si la qualité ne répond pas aux attentes. Vous pouvez utiliser le flux de travail de remédiation par défaut ou créer des flux de travail personnalisés.
Vous pouvez consulter des informations sur la conformité ou les violations des règles SLA et l'état des tâches de remédiation sur la page Qualité des données d'une ressource de données surveillée.
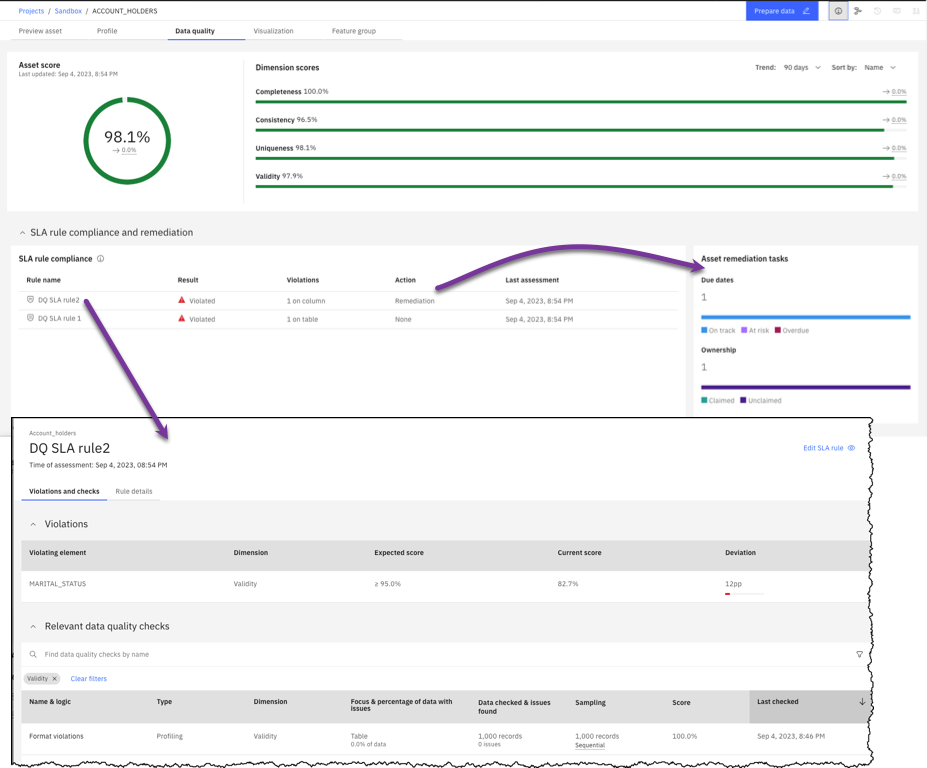
Pour plus d'informations, voir :
Supprimer les noms et descriptions suggérés des résultats de l'enrichissement des métadonnées IBM Knowledge Catalog
12 décembre 2024
Dans les résultats de l'enrichissement des métadonnées, vous pouvez désormais supprimer en bloc les noms d'affichage ou les descriptions suggérés lorsque l'enrichissement est exécuté avec l'option Étendre les métadonnées. Voir Modifications en bloc des résultats de l'enrichissement des métadonnées.
Utiliser les définitions des sources de données pour gérer et protéger les données auxquelles on accède à partir de connexions
12 décembre 2024
Les définitions de sources de données sont un nouveau type de ressources que vous définissez en fonction des points d'extrémité d'une connexion ou d'une ressource de données connectée. Lorsque vous créez une définition de source de données, vous pouvez contrôler l'endroit où vos données sont stockées dans plusieurs projets, catalogues ou sources de données multi-nœuds. Vous pouvez également appliquer la bonne solution de protection (moteur d'application) en fonction de la définition de la source de données. Pour plus d'informations, voir Protection des données avec les définitions de sources de données.
Ces nouvelles fonctionnalités de définition des sources de données sont désormais disponibles dans toutes les régions.
Définition d'une source de données avec une solution de protectionIBM Knowledge Catalog
09 décembre 2024
Une solution de protection est une méthode d'application des règles de protection des données, soit dans des catalogues régis, soit par une solution d'application en profondeur.
Pour configurer la plate-forme avec une solution d'application approfondie, vous pouvez créer une définition de source de données pour définir le type de source de données. Le type de source de données détermine les types de connexions auxquels la définition de la source de données peut être associée et les options de solution de protection disponibles. Pour plus de détails, voir Solutions de protection pour la définition des sources de données.
Ces nouvelles fonctionnalités de définition des sources de données sont désormais disponibles dans toutes les régions.
Dépréciation des fonctionnalités pour le flux de masquage
11 décembre 2024
Les fonctionnalités suivantes sont obsolètes et sont désormais supprimées :
- L'option de réversibilité est désormais supprimée pour l'obscurcissement des données, ce qui permet d'inverser ultérieurement le masquage pour récupérer les valeurs d'origine.
- Le chiffrement réversible n'est plus disponible pour créer des copies de données en créant des flux de masquage et la symbolisation par hachage à sens unique pour une conformité flexible.
- Décrypter des données masquées réversibles n'est plus disponible.
Mise à jour des didacticiels de SPSS Modeler
11 décembre 2024
Obtenez une expérience pratique avec SPSS Modeler en essayant les 15 tutoriels SPSS Modeler mis à jour.
IBM Knowledge Catalog est disponible dans la région de Sydney
09 décembre 2024
IBM Knowledge Catalog est désormais également disponible dans le centre de données de Sydney. Vous pouvez sélectionner Sydney comme région préférée lors de votre inscription.
Pour plus d'informations sur les caractéristiques des produits disponibles dans la région de Sydney, voir Disponibilité régionale des services et des caractéristiques.
IBM DataStage est disponible dans la région de Sydney
09 décembre 2024
DataStage est maintenant disponible dans le centre de données de Sydney. Vous pouvez sélectionner Sydney comme région préférée lors de l'inscription.
Pour plus d'informations sur les caractéristiques des produits disponibles dans la région de Sydney, voir Disponibilité régionale des services et des caractéristiques.
IBM watsonx.governance est disponible dans la région de Sydney
9 décembre 2024
IBM watsonx.governance est désormais disponible dans le centre de données de Sydney. Vous pouvez sélectionner Sydney comme région préférée lors de l'inscription.
Pour plus d'informations sur les caractéristiques des produits disponibles dans la région de Sydney, voir Disponibilité régionale des services et des caractéristiques.
Semaine se terminant le 6 décembre 2024
Nouvelles sources de données pour l'importation de métadonnées de lignée
06 décembre 2024
Vous pouvez désormais importer des métadonnées de lignage à partir des sources de données suivantes. Une fois les données importées, vous pouvez les visualiser sur un graphique de lignée. Pour plus d'informations, voir Sources de données prises en charge pour la curation et la qualité des données.
Déclassement du plan IBM Cloud Object Storage LiteIBM Knowledge Catalog
05 décembre 2024
Les plans Cloud Object Storage Lite à durée illimitée que vous avez provisionnés avant le 1er juillet 2024 sont obsolètes et pourraient être supprimés après le 15 décembre 2024. Pour conserver vos données et autres actifs, vous devez mettre à niveau votre service de Cloud Object Storage vers un plan standard avant le 15 décembre 2024. Si vous ne mettez pas à niveau votre plan de Cloud Object Storage vers Standard, vos espaces de travail pourraient devenir inaccessibles après le 15 décembre 2024, et vos données pourraient être définitivement supprimées. Pour plus d'informations, voir Lite plan (obsolète).
Les fichiers Microsoft Excel sont obsolètes pour les modèles OPL dans Decision Optimization
05 décembre 2024
Les fichiers Microsoft Excel (.xls et .xlsx) ne sont plus utilisés pour l'entrée et la sortie directes dans les modèles OPL de Decision Optimization. Pour se connecter à des fichiers Excel, utilisez plutôt un connecteur de données. Le connecteur de données transforme votre fichier Excel en fichier .csv. Pour plus d'informations, voir Données référencées.
Amélioration de la planification des tâches d'enrichissement des métadonnéesIBM Knowledge Catalog)
05 décembre 2024
Vous pouvez désormais configurer des fenêtres d'exécution pour vos travaux d'enrichissement des métadonnées afin d'équilibrer les charges de travail. Les travaux ne s'exécutent alors que dans les délais configurés. Pour plus d'informations, voir Gestion de la planification des travaux d'enrichissement.
Segmenter les données en fonction de la valeur des colonnes pour se concentrer sur les informations dont on a besoinIBM Knowledge Catalog
05 décembre 2024
Vous pouvez désormais diviser les ressources de données en plus petites ressources de données basées sur des valeurs de colonnes sélectionnées pour vous aider à accéder uniquement aux données qui vous intéressent. Pour plus d'informations, voir Création de ressources de données en segmentant les données des colonnes.
Nouveaux carnets d'exemples pour le déploiement de modèles convertis au format ONNX
03 décembre 2024
Vous pouvez désormais déployer des modèles d'apprentissage automatique et d'IA générative convertis au format ONNX et utiliser le point final pour l'inférence. Ces modèles peuvent également être adaptés aux axes dynamiques. Voir les exemples de carnets suivants :
- Convertir un réseau neuronal ONNX d'axes fixes en axes dynamiques
- Utiliser le modèle ONNX converti à partir de PyTorch
- Utiliser un modèle ONNX converti à partir de TensorFlow pour reconnaître des chiffres écrits à la main
Pour plus d'informations, voir les échantillons et les exemples de clients Python dewatsonx.ai Runtime.
Semaine se terminant le 29 novembre 2024
Amélioration de la documentation sur les options d'écriture pour Data Refinery
28 novembre 2024
Les options d'écriture et de tableau pour l'exportation des flux de données dépendent de votre connexion. Ces options sont maintenant expliquées afin que vous soyez mieux guidé dans le choix de vos options de table cible. Pour plus d'informations, voir Options de connexion cible pour Data Refinery.
Semaine du 25 novembre 2024
Changement de nom du service Watson Query
25 novembre 2024
Le service Watson Query a été renommé Data Virtualization ization Data Virtualizion.
Semaine se terminant le 22 novembre 2024
Changement de nom pour les services Watson Studio et Watson Machine Learning
21 novembre 2024
Les services suivants ont été renommés :
- Watson Machine Learning s'appelle désormais watsonx.ai Runtime.
- Watson Studio s'appelle désormais watsonx.ai Studio.
Certaines vidéos, certains carnets de notes et certains exemples de code peuvent continuer à faire référence à ces services sous leur ancien nom.
Cloud Pak for Data as a Service est disponible dans la région de Sydney
21 novembre 2024
Cloud Pak for Data as a Service est maintenant disponible dans le centre de données de Sydney avec les services watsonx.ai Runtime et watsonx.ai Studio. Lorsque vous vous inscrivez, vous pouvez sélectionner Sydney comme région préférée.
Tous les services ne sont pas encore disponibles dans la région de Sydney. Pour plus d'informations sur les caractéristiques des produits disponibles dans la région de Sydney, voir Disponibilité régionale des services et des caractéristiques.
Surveillance améliorée des travaux d'enrichissement des métadonnéesIBM Knowledge Catalog)
21 novembre 2024
Sur le nouveau tableau de bord des mesures d'exécution, vous pouvez suivre la progression des différentes tâches d'enrichissement pour un travail d'enrichissement des métadonnées actif. En outre, vous pouvez explorer les informations relatives aux exécutions de travaux terminés afin de déterminer si des problèmes sont survenus et où ils se sont produits. Pour plus d'informations, voir Suivi des exécutions de travaux d'enrichissement.
Promouvoir les flux de SPSS Modeler dans les espaces de déploiement
19 novembre 2024
Vous pouvez désormais promouvoir directement les flux SPSS Modeler des projets vers les espaces de déploiement sans avoir à exporter le projet et à l'importer ensuite dans l'espace de déploiement. Pour plus d'informations, voir Promouvoir les flux et les modèles SPSS Modeler.
Semaine se terminant le 15 novembre 2024
Les informations d'identification des tâches sont désormais requises pour déployer des ressources et exécuter des tâches à partir d'un espace de déploiement
11 novembre 2024
Pour améliorer la sécurité des tâches de déploiement en cours d'exécution, vous devez saisir vos informations d'identification pour déployer les ressources suivantes à partir d'un espace de déploiement :
- Modèles d'invite
- Services d’IA
- Modèles
- Fonctions Python
- Scripts
En outre, vous devez saisir vos informations d'identification pour créer les déploiements suivants à partir de votre espace de déploiement :
- En ligne
- Lot
Vous devez également utiliser vos identifiants de tâches pour créer et gérer des tâches de déploiement à partir de votre espace de déploiement.
Pour savoir comment configurer les informations d'identification de votre tâche et générer une clé API, voir Ajouter des informations d'identification de la tâche.
Mode éditeur pour les propriétés personnaliséesIBM Knowledge Catalog
14 novembre 2024
Lors de l'affichage des artefacts de gouvernance, vous pouvez désormais activer le mode éditeur pour les propriétés personnalisées. Lorsque l'option Modifier les valeurs est désactivée dans la section Détails, vous ne pouvez voir que les propriétés personnalisées pour lesquelles des valeurs ont été définies pour l'artefact. Activez le mode éditeur et vous pourrez voir toutes les propriétés personnalisées disponibles et modifier leurs valeurs. Pour plus d'informations, voir Propriétés, relations et types d'actifs personnalisés.
Semaine se terminant le 8 novembre 2024
Se connecter à de nouvelles sources de données avec SPSS Modeler
7 novembre 2024
Vous pouvez désormais connecter SPSS Modeler à Databricks et à Microsoft Azure Synapse Analytics, et SPSS Modeler dispose d'un accès en lecture et en écriture aux deux sources de données. Pour plus d'informations, voir Connexion àMicrosoft Azure Databricks et Connexion àMicrosoft Azure Synapse Analytics.
Semaine se terminant le 1er novembre 2024
Déclassement d'IBM Runtime 23.1
28 octobre 2024
IBM Runtime 23.1 est obsolète. À partir du 21 novembre 2024, vous ne pourrez plus créer de nouveaux carnets ou environnements personnalisés en utilisant les runtimes 23.1 Vous ne pouvez pas non plus créer de nouveaux déploiements avec des spécifications logicielles basées sur le runtime 23.1 Pour garantir une expérience transparente et tirer parti des dernières fonctionnalités et améliorations, passez à IBM Runtime 24.1
- Pour plus d'informations sur la modification des environnements, voir Modification des environnements des ordinateurs portables.
- Pour plus d'informations sur les structures de déploiement, voir Gestion des cadres et des spécifications logicielles.
Semaine se terminant le 25 octobre 2024
Comparer les tableaux dans les expériences d'Decision Optimization pour voir les différences entre les scénarios
23 octobre 2024
Vous pouvez désormais comparer les tableaux d'une expérience d'Decision Optimization dans la vue Préparer les données ou Explorer la solution. Cette comparaison peut être utile pour voir les différences de valeur des données entre les scénarios affichés l'un à côté de l'autre. 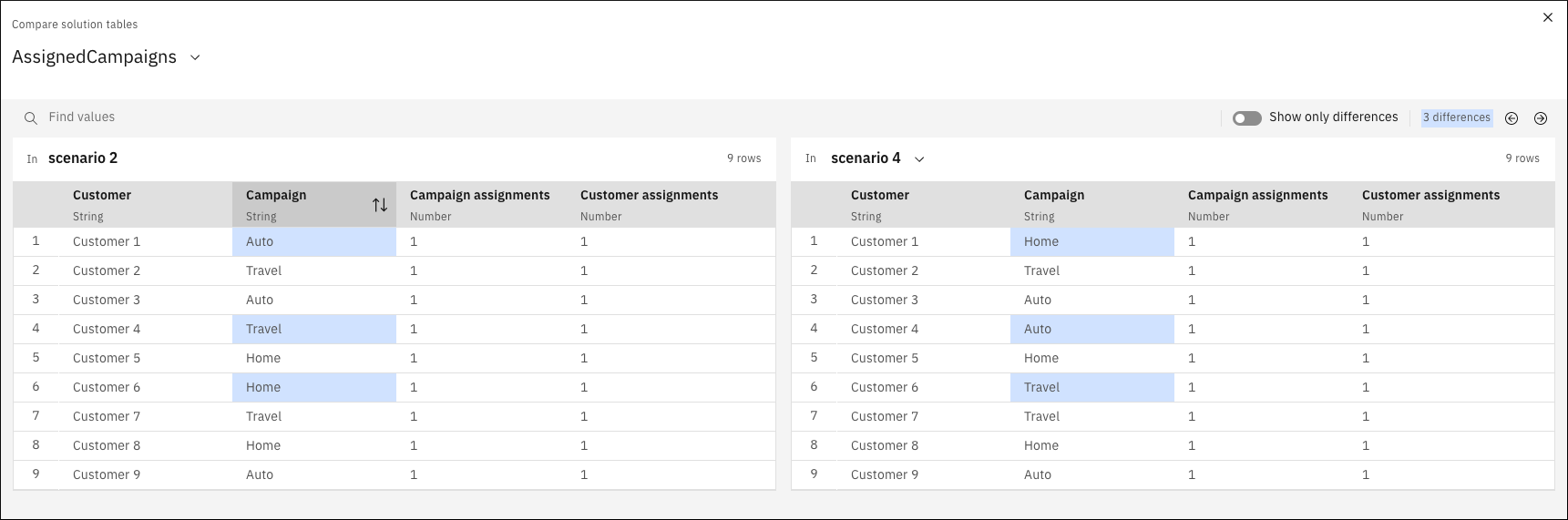
Pour plus d'informations, voir Comparer les tables de scénarios.
Semaine se terminant le 18 octobre 2024
La délimitation des ressources du compte est activée par défaut
17 octobre 2024
Le paramètre " Resource scope de votre compte est désormais défini par défaut sur " ON Toutefois, si vous avez précédemment défini la valeur du paramètre d'étendue des ressources sur " ON ou " OFF, le paramètre actuel n'est pas modifié.
Lorsque la délimitation des ressources est activée, vous ne pouvez pas accéder aux projets qui ne font pas partie de votre compte IBM Cloud actuellement sélectionné. Si vous appartenez à plusieurs comptes IBM Cloud, il se peut que vous ne voyiez pas tous vos projets listés ensemble. Par exemple, il se peut que vous ne voyiez pas tous vos projets sur la page Tous les projets. Vous devez changer de compte pour voir les projets dans les autres comptes.
Semaine se terminant le 11 octobre 2024
Analysez les données textuelles japonaises dans SPSS Modeler avec Text Analytics
9 octobre 2024
Vous pouvez désormais utiliser les nœuds d'analyse de texte dans SPSS Modeler, tels que le nœud d'analyse des liens de texte et le nœud d'exploration de texte, pour analyser les données textuelles écrites en japonais.
Semaine se terminant le 4 octobre 2024
Présentation d'IBM Manta Data Lineage: un nouveau service qui fournit un data lineage pour vos données
04 octobre 2024
IBM Manta Data Lineage est un service de lignage de données qui augmente la transparence du pipeline de données afin que vous puissiez déterminer l'exactitude des données dans l'ensemble des modèles et systèmes d'entreprise. Pour plus d'informations sur le lignage des données, voir Lignage des données.
Ce service nécessite le service IBM Knowledge Catalog et l'activation du lignage des données sur votre compte IBM Cloud. Voir, Enable data lineage. Il n'est disponible que dans la région de Dallas.
Vous pouvez accéder à vos lignages importés dans le nouvel espace de travail Lignage de données ou visualiser le lignage d'un actif spécifique dans la page Catalogues ou Projets.
Vous pouvez importer des métadonnées de lignage à partir des sources suivantes :
- Connexion Microsoft Azure SQL Database
- Connexion Microsoft SQL Server
- Connexion àMicrosoft Power BI (Azure)
- Connexion Snowflake
- InfoSphere DataStage
- IBM DataStage for Cloud Pak for Data
Pour plus d'informations sur l'importation de métadonnées, voir Importation de métadonnées.
Amélioration de l'onglet " Draft" pour les artefacts de gouvernanceIBM Knowledge Catalog
3 octobre 2024
Pour chaque type d'artefact, vous pouvez désormais visualiser tous les brouillons disponibles dans l'onglet Brouillon. Pour l'afficher, sélectionnez le type d'artefact dans le menu principal et cliquez sur Brouillon. L'onglet n'est visible que si vous disposez des autorisations nécessaires et si des brouillons sont disponibles. Lorsque vous affichez tous vos brouillons dans l'onglet, vous pouvez sélectionner plusieurs brouillons et utiliser le menu d'actions groupées pour les modifier ou les traiter en une seule fois. Notez que la page Tous les brouillons n'est plus disponible à partir du menu principal. Pour plus d'informations, voir Gestion des artefacts de gouvernance.
Actions en bloc sur les ressources du catalogueIBM Knowledge Catalog
3 octobre 2024
Vous pouvez désormais modifier et supprimer les classifications et les propriétés personnalisées de plusieurs actifs d'un catalogue en même temps.
Mise à jour automatique des propriétés communes des donnéesIBM Knowledge Catalog
3 octobre 2024
Grâce à l'identification globale des actifs, vous pouvez vous assurer que les propriétés communes des actifs de données ayant la même clé de ressource et référençant la même ressource physique restent les mêmes, même s'ils se trouvent dans des projets ou des catalogues différents. Vous pouvez ainsi gérer ces données de manière appropriée et cohérente. Pour plus d'informations, voir l'identification des biens de Globla.
Affecter des groupes d'utilisateurs en tant que membres d'actifsIBM Knowledge Catalog
3 octobre 2024
Vous pouvez maintenant assigner des groupes d'utilisateurs comme membres de l'actif. Auparavant, vous ne pouviez ajouter que des utilisateurs de catalogues individuels en tant que membres d'actifs.
Téléchargement et mise à jour des actifs en masseIBM Knowledge Catalog
3 octobre 2024
Pour télécharger et mettre à jour plusieurs biens en masse, vous pouvez désormais importer et exporter des fichiers CSV contenant soit les détails des métadonnées des biens, soit les détails des relations entre les biens, soit les deux. Pour plus d'informations, voir Ajouter et mettre à jour des actifs et des métadonnées d'actifs à partir de fichiers CSV vers des catalogues).
Disponibilité du plan watsonx.governance dans la région de Francfort et suppression du plan OpenScale legacy
3 octobre 2024
L'ancien plan watsonx.governance pour provisionner Watson OpenScale dans la région de Francfort est obsolète. IBM Watson OpenScale ne sera plus disponible pour un nouvel abonnement ou pour provisionner de nouvelles instances. Pour les capacités OpenScale, souscrivez au plan Essentials de watsonx.governance, qui est désormais disponible à Francfort et à Dallas.
- Pour afficher les détails d'un plan, voir les plans watsonx.governance .
- Pour commencer, voir Mise à disposition et lancement de watsonx.governance.
Remarques :
- Les instances de plan existantes continueront à fonctionner et seront prises en charge jusqu'à la date de fin de prise en charge, qui reste à déterminer.
- Les clients existants sur IBM Watson OpenScale peuvent continuer à ouvrir des tickets de support en utilisant IBM Watson OpenScale.
Mise à jour des environnements et des spécifications logicielles
3 octobre 2024
Les bibliothèques Tensorflow et Keras incluses dans IBM Runtime 23.1 sont désormais mises à jour vers leurs nouvelles versions. Cela peut avoir un impact sur la façon dont le code est exécuté dans vos carnets. Pour plus de détails, voir Paquets de bibliothèques inclus dans les exécutions 'watsonx.ai Studio (anciennement 'Watson Studo).
Le Runtime 23.1 sera abandonné au profit du Runtime 24.1 d'IBM dans le courant de l'année. Pour éviter des perturbations répétées, nous vous recommandons de passer dès maintenant à IBM Runtime 24.1 et d'utiliser les spécifications logicielles correspondantes pour les déploiements.
- Pour plus d'informations sur la modification des environnements, voir Modification des environnements des ordinateurs portables.
- Pour plus d'informations sur les structures de déploiement, voir Gestion des cadres et des spécifications logicielles.
Utiliser les définitions des sources de données pour gérer et protéger les données auxquelles on accède à partir de connexions
04 octobre 2024
Les définitions de sources de données sont un nouveau type de ressources que vous définissez en fonction des points d'extrémité d'une connexion ou d'une ressource de données connectée. Lorsque vous créez une définition de source de données, vous pouvez contrôler l'endroit où vos données sont stockées dans plusieurs projets, catalogues ou sources de données multi-nœuds. Vous pouvez également appliquer la bonne solution de protection (moteur d'application) en fonction de la définition de la source de données. Pour plus d'informations, voir Protection des données avec les définitions de sources de données.
Ces nouvelles caractéristiques de définition des sources de données ne sont disponibles que dans la région de Dallas.
Définition d'une source de données avec une solution de protectionIBM Knowledge Catalog
04 octobre 2024
Une solution de protection est une méthode d'application des règles de protection des données, soit dans des catalogues régis, soit par une solution d'application en profondeur.
Pour configurer la plate-forme avec une solution d'application approfondie, vous pouvez créer une définition de source de données pour définir le type de source de données. Le type de source de données détermine les types de connexions auxquels la définition de la source de données peut être associée et les options de solution de protection disponibles. Pour plus de détails, voir Solutions de protection pour la définition des sources de données.
Ces nouvelles caractéristiques de définition des sources de données ne sont disponibles que dans la région de Dallas.
Examiner et gérer les affectations de classes et de périodes de données dans une feuille de calculIBM Knowledge Catalog
04 octobre 2024
Si vous préférez travailler dans un tableur familier lorsque vous examinez et mettez à jour les résultats de l'enrichissement des métadonnées, vous pouvez désormais installer le module complémentaire Review metadata pour Microsoft Excel. Utilisez le modèle de feuille de calcul fourni avec le produit en combinaison avec le module complémentaire :
- Pour télécharger les données enrichies d'un projet spécifique et l'enrichissement des métadonnées.
- Examiner et mettre à jour les classes de données et les termes suggérés et attribués pour ces actifs de données.
- Pour télécharger les données mises à jour dans le projet.
Pour plus d'informations, voir Révision et mise à jour des résultats d'enrichissement dans un programme externe.
Semaine se terminant le 27 septembre 2024
Suppression de la durée d'exécution de Spark 3.3
23 septembre 2024
La prise en charge du runtime Spark 3.3 dans IBM Analytics Engine sera supprimée d'ici le 29 octobre 2024 et la version par défaut sera remplacée par le runtime Spark 3.4. Pour garantir une expérience transparente et tirer parti des dernières fonctionnalités et améliorations, passez à Spark 3.4.
À partir du 29 octobre 2024, vous ne pourrez plus créer ou exécuter des notebooks ou des environnements personnalisés en utilisant des runtimes Spark 3.3. De plus, vous ne pouvez pas créer ou exécuter des déploiements avec des spécifications logicielles basées sur le runtime Spark 3.3.
- Pour mettre à jour votre instance vers Spark 3.4, voir Remplacer le Runtime par défaut de l'instance.
- Pour plus de détails sur les environnements disponibles pour les ordinateurs portables, voir Changer l'environnement d'un ordinateur portable.
- Pour plus d'informations sur les structures de déploiement, voir Gestion des cadres et des spécifications logicielles.
Semaine se terminant le 20 septembre 2024
Règles de qualité des données du groupeIBM Knowledge Catalog
20 septembre 2024
Vous pouvez désormais regrouper certains types de règles de qualité des données dans un seul flux DataStage et les exécuter ensemble. Pour plus d'informations, voir Règles de regroupement.
Semaine se terminant le 13 septembre 2024
Créer des jobs batch pour les flux SPSS Modeler dans les espaces de déploiement
10 septembre 2024
Vous pouvez désormais créer des travaux par lots pour les flux SPSS Modeler dans les espaces de déploiement. Les flux vous permettent de décider des nœuds terminaux à exécuter chaque fois que vous créez un travail par lots à partir d'un flux. Lorsque vous planifiez des travaux par lots pour des flux, le travail par lots utilise les sources de données et les cibles de sortie que vous avez spécifiées dans votre flux. Le mappage de ces sources de données et de ces sorties est automatique si les sources de données et les cibles se trouvent également dans votre espace de déploiement. Pour plus d'informations sur la création de travaux par lots à partir de flux, voir Création de travaux de déploiement pour les flux SPSS Modeler.
Pour plus d'informations sur les flux et les modèles dans les espaces de déploiement, voir Déploiement des flux et des modèles SPSS Modeler.
Semaine se terminant le 30 août 2024
Modifier la forme du nœud du pipeline
30 août 2024
Vous pouvez désormais modifier l'apparence des nœuds de pipeline afin de les transformer d'un style de carte uniforme en des formes plus compactes qui reflètent le type de nœud. Pour plus d'informations, voir Paramètres des pipelines.
Créer des jeux de paramètres globaux
30 août 2024
Vous pouvez désormais ajouter des paramètres PROJDEF aux jeux de paramètres de votre pipeline. Les paramètres peuvent être référencés à la fois dans les flux DataStage et Orchestration Pipelines au même niveau de projet. Pour plus d'informations, voir Configuration des objets globaux pour Orchestration Pipelines.
Semaine se terminant le 23 août 2024
Ajouter des groupes d'utilisateurs comme collaborateurs dans les projets et les espaces
22 août 2024
Vous pouvez désormais ajouter des groupes d'utilisateurs en tant que collaborateurs dans les projets et les espaces si votre compte IBM Cloud contient des groupes d'accès IAM. Votre IBM Cloud peut créer des groupes d'accès, qui sont ensuite disponibles en tant que groupes d'utilisateurs dans les projets. Lors de la création d'un projet, vous devez laisser l'option Restreindre qui peut être collaborateur activée pour ajouter des groupes d'utilisateurs en tant que collaborateurs. Pour plus d'informations, voir Travail avec les groupes d'accès IAM.
Fin de support pour la fonction de prédiction d'anomalie pour les expériences de séries temporelles AutoAI
19 août 2024
La fonction de prédiction des anomalies (outliers) dans les prédictions des modèles de séries temporelles de AutoAI, actuellement en version bêta, est obsolète et sera supprimée le 23 septembre 2024. Les expériences de séries temporelles standard AutoAI sont toujours entièrement prises en charge. Pour plus de détails, voir Construction d'une expérience de série temporelle.
Attribuer des classifications dans l'enrichissement des métadonnéesIBM Knowledge Catalog)
22 août 2024
Vous pouvez désormais attribuer des classifications aux ressources de données et aux colonnes dans l'enrichissement des métadonnées, soit automatiquement sur la base de l'attribution de termes ou de classes de données, soit manuellement dans les résultats de l'enrichissement. Voir Conception de l'enrichissement des métadonnées : Attribuer des termes et des classifications.
Semaine se terminant le 16 août 2024
Archiver et désarchiver des projets et des espaces
16 août 2024
Les projets et les espaces sont désormais archivés après 90 jours d'inactivité afin de préserver les ressources. Pour travailler à nouveau avec ces projets ou espaces, désarchivez-les en les ouvrant directement sur la page du projet ou de l'espace. En fonction de la taille du projet ou de l'espace, le désarchivage peut prendre plus ou moins de temps.
Configurer le retrait des actifs
16 août 2024
Désormais, lorsque vous créez un nouveau catalogue, vous pouvez également décider de la manière dont vous souhaitez configurer la suppression des actifs. Vous pouvez choisir de purger les actifs automatiquement, soit immédiatement après la suppression, soit 30 jours après la suppression. Pour les catalogues créés précédemment, vous pouvez modifier les paramètres de suppression des actifs sur la page Paramètres du catalogue.
Pour plus d'informations, voir :
Les informations d'identification des tâches sont désormais requises pour exécuter des travaux dans un espace de déploiement
15 août 2024
Pour améliorer la sécurité de l'exécution des tâches de déploiement, vous devez saisir vos informations d'identification pour exécuter une tâche dans un espace de déploiement. Pour plus d'informations, voir Créer des emplois dans des espaces de déploiement.
Pour savoir comment configurer les informations d'identification de votre tâche et générer une clé API, voir Ajouter des informations d'identification de la tâche.
Semaine se terminant le 26 juillet 2024
Mise en pause de l'enrichissement des métadonnéesIBM Knowledge Catalog)
25 juillet 2024
Vous pouvez désormais suspendre et reprendre les exécutions des tâches d'enrichissement des métadonnées. Pour plus de détails, voir Suspendre et reprendre les exécutions de tâches d'enrichissement.
Annonce du soutien à Python 3.11 et R4.3 frameworks et spécifications logicielles sur le runtime 24.1
25 juillet 2024
Vous pouvez désormais utiliser IBM Runtime 24.1, qui inclut les derniers cadres de science des données basés sur Python 3.11 et R 4.3, pour exécuter des carnets Jupyter et des scripts R, et former des modèles. À partir du 29 juillet, vous pourrez également effectuer des déploiements. Mettez à jour vos ressources et vos déploiements pour utiliser les frameworks et les spécifications logicielles IBM Runtime 24.1
- Pour des informations sur le IBM Durée 24.1 version et les environnements inclus pour Python 3.10 et R 4.2, voir Environnements de bloc-notes.
- Pour plus d'informations sur les structures de déploiement, voir Gestion des cadres et des spécifications logicielles.
Version améliorée de Jupyter Notebook l'éditeur est maintenant disponible
25 juillet 2024
Si vous exécutez votre ordinateur portable dans des environnements basés sur Runtime 24.1, vous pouvez utiliser ces améliorations pour travailler avec votre code :
- Déboguer automatiquement votre code
- Générez automatiquement une table des matières pour votre bloc-notes
- Basculer les numéros de ligne à côté de votre code
- Réduisez le contenu des cellules et utilisez la vue côte à côte pour le code et la sortie, pour une productivité améliorée
Pour plus d'informations, voir Jupyter notebook editor.
Modèles d'intégration de transformateur de processeur de langage naturel pris en charge avec Runtime 24.1
25 juillet 2024
Dans le nouveau Runtime 24.1 environnement, vous pouvez désormais utiliser des modèles d'intégration de transformateur de traitement du langage naturel (NLP) pour créer des intégrations de texte qui capturent le sens d'une phrase ou d'un passage afin de faciliter les tâches de génération augmentée par récupération. Pour plus d'informations, voir Intégrations.
De nouveaux modèles PNL spécialisés sont disponibles dans Runtime 24.1
25 juillet 2024
Les nouveaux modèles PNL spécialisés suivants sont désormais inclus dans le Runtime 24.1 environnement:
- Un modèle capable de détecter et d'identifier le contenu haineux, abusif ou grossier (HAP) dans le contenu textuel. Pour plus d'informations, voir Détection des PAD.
- Trois modèles pré-entraînés capables d'aborder des sujets liés à la finance, à la cybersécurité et à la biomédecine. Pour plus d'informations, voir Classer du texte avec un modèle de classification personnalisé.
Extrayez des informations détaillées à partir de grandes collections de textes à l'aide de la synthèse des points clés
25 juillet 2024
Vous pouvez désormais utiliser la synthèse de points clés dans les carnets de notes pour extraire des informations détaillées et exploitables à partir de vastes collections de textes représentant les opinions des personnes (telles que des évaluations de produits, des réponses à des enquêtes ou des commentaires sur les médias sociaux). Le résultat est livré de manière organisée, hiérarchique et facile à traiter. Pour plus d'informations, voir Résumé des points clés
Mise à jour de la version de RStudio
25 juillet 2024
Afin d'offrir une expérience utilisateur cohérente dans les nuages privés et publics, l'IDE RStudio pour le Cloud Pak for Data as a Service sera mis à jour vers RStudio Server 2024.04.1 et R 4.3.1 le 29 juillet 2024. La nouvelle version de RStudio apporte un certain nombre d'améliorations et de correctifs de sécurité. Voir les notes de mise à jour de RStudio Server 2024.04.1 pour plus d'informations. Bien qu'aucun problème de compatibilité majeur ne soit prévu, les utilisateurs doivent être conscients des changements de version de certains packages décrits dans le tableau ci-dessous.
Lorsque vous lancez l'IDE RStudio à partir d'un projet après la mise à jour, réinitialisez l'espace de travail RStudio pour vous assurer que le chemin de la bibliothèque pour les paquets R 4.3.1 est pris en compte par le serveur RStudio.
Semaine se terminant le 12 juillet 2024
Suivi des décisions d’application des règles de protection des données
9 juillet 2024
Vous pouvez désormais suivre les décisions d'application en tant qu'événements d'audit lorsque le Envoyer les évaluations des stratégies aux journaux d'audit est cochée dans la liste Gestion des paramètres de règles page.
Semaine se terminant le 5 juillet 2024
Connecteurs regroupés par type de source de données
05 juillet 2024
Lorsque vous créez une connexion, les connecteurs sont désormais regroupés par type de source de données afin de faciliter leur recherche et leur sélection. Par exemple, le type de source de données MongoDB inclut les connecteurs IBM Cloud Databases for MongoDB et MongoDB.
De plus, un nouveau Récents La catégorie affiche les six derniers connecteurs que vous avez utilisés pour créer une connexion.
Pour les instructions, voir Ajout de connexions aux sources de données dans un projet ou Ajout de connexions à des sources de données dans un catalogue .
Modifications groupées des propriétés des artefacts de gouvernance
05 juillet 2024
Vous pouvez désormais modifier la catégorie principale ou secondaire de plusieurs artefacts de gouvernance à la fois. Des modifications groupées sont également disponibles lors de la mise à jour des relations. Pour plus d'informations, voir Gestion des artefacts de gouvernance.
Définition d'un seuil d'affectation pour les résultats des analyses de relationsIBM Knowledge Catalog
05 juillet 2024
Vous définissez désormais également un seuil pour lequel les résultats d’une analyse de relation doivent être attribués automatiquement. Vous pouvez définir une valeur par défaut pour le projet, mais écraser le paramètre pour chaque exécution d'analyse. Pour plus de détails, voir Identifier les relations .
Modifications àCloud Object Storage Forfaits allégés
01 juillet 2024
À compter du 1er juillet 2024, leCloud Object Storage Plan Lite qui est automatiquement provisionné lorsque vous vous inscrivez pour un essai de 30 jours deCloud Pak for Data as a Service expire après la fin de l’essai. Vous pouvez mettre à niveau votreCloud Object Storage Lite au forfait Standard avec l'option Free Tier à tout moment pendant la période d'essai de 30 jours.
ExistantCloud Object Storage les instances de service avec des forfaits Lite que vous avez provisionnés avant le 1er juillet 2024 seront conservées jusqu'au 15 décembre 2024. Vous devez mettre à niveau votreCloud Object Storage service à un forfait Standard avant le 15 décembre 2024.
Semaine se terminant le 21 juin 2024
Ajout d'actifs de catalogue à des projets
20 juin 2024
Ajout d'un droit d'utilisateur Ajouter des actifs de catalogue à des projets. Désormais, pour ajouter des actifs à des projets, vous devez disposer du rôle Ajouter des actifs de catalogue à des projets, du rôle Administrateur, Editeur ou Afficheur dans le catalogue et être le propriétaire ou l'éditeur de l'actif. Les utilisateurs qui ne disposent pas d'un rôle existant avec le droit Gérer les catalogues ou Accéder aux catalogues doivent disposer explicitement du droit Ajouter des actifs de catalogue aux projets.
Suppression du Cognos Dashboard différée
20 juin 2024
Tous les tableaux de bord existants que vous avez créés avec le service Cognos Dashboards Embedded continueront de fonctionner jusqu'au 30 septembre 2024. Vous ne pouvez plus mettre à disposition une instance du service Cognos Dashboards Embedded. Vous pouvez utiliser Cognos Analytics on Cloud On-Demand pour remplacer Cognos Dashboards Embedded. Pour plus d'informations, voir IBM Cognos Analytics -Plans de tarification.
Les données d'identification de tâche seront requises pour les demandes de travail de déploiement
19 juin 2024
Pour améliorer la sécurité de l'exécution des travaux de déploiement, l'utilisateur qui demande le travail doit fournir des données d'identification de tâche sous la forme d'une clé d'API. L'exigence sera appliquée à compter du 15 août 2024. Voir Ajout de données d'identification de tâche pour plus de détails sur la génération de la clé d'API.
Enrichissement de données amélioré dans IBM Knowledge Catalog
20 juin 2024
Outre les fonctions existantes, l'enrichissement des métadonnées fournit désormais des options pour l'enrichissement des données sémantiques et étendues à l'intelligence artificielle:
- Recommander des noms descriptifs pour les tables et les colonnes en fonction des métadonnées collectées et d'un glossaire prédéfini.
- Suggérez et affectez des descriptions sémantiques pour le contenu des tables et des colonnes en fonction des colonnes environnantes et du contexte des tables.
- Terminez l'affectation de termes sémantiques pour les tables et les colonnes.
Pour plus de détails, voir Conception d'enrichissements de métadonnées.
Ces nouvelles fonctions d'enrichissement des métadonnées basées sur l'intelligence artificielle de génération sont disponibles uniquement dans la région de Dallas.
Modification du client IBM Federated Learning Python
20 juin 2024
La bibliothèque client Python de Federated Learning a été fusionnée avec la bibliothèque watsonx.ai . Vos exemples de code doivent être mis à jour avec le client Python le plus récent. Voir Connexion à l'agrégateur.
Connectez-vous à une nouvelle source de données dansDataStage:IBMPlanning Analytics
14 juin 2024
Vous pouvez désormais inclure des données provenant d'une source de données IBM Planning Analytics dans vos flux DataStage .
Pour la liste complète des connecteurs DataStage , voir Sources de données prises en charge dans DataStage.
Semaine se terminant le 7 juin 2024
Modifications en bloc pour les artefacts de gouvernance
7 juin 2024
Vous pouvez désormais apporter des modifications à plusieurs artefacts de gouvernance à la fois lorsque vous souhaitez éditer des étiquettes ou des intendants. Pour plus d'informations, voir Gestion des artefacts de gouvernance.
Modification de la catégorie parent pour des artefacts individuels
7 juin 2024
Lorsque vous affichez les détails de l'artefact, vous pouvez désormais modifier la catégorie parent en sélectionnant Déplacer vers dans le menu d'action à trois points.
Les règles de protection des données ne sont plus appliquées dans les projets
7 juin 2024
Les règles de protection des données ne sont désormais appliquées que dans les catalogues gouvernés ou par une solution d'application approfondie. Une solution d'application approfondie est une solution de protection permettant d'appliquer des règles sur les données qui se trouvent en dehors de Cloud Pak for Data lorsque la source de données est intégrée à l'un de ces services:
- IBM Data Virtualization
- IBM watsonx.data
Les actifs ajoutés aux projets à partir d'un catalogue gouverné ne sont plus soumis à des restrictions d'aperçu, de téléchargement ou de profilage par les règles de protection des données, sauf si vous avez configuré une solution d'application approfondie.
Il vous sera rappelé les protocoles révisés d'application des règles de protection des données lorsque vous:
- Création d'une règle de protection des données.
- Copie d'un actif d'un catalogue gouverné dans un projet
Pour plus de détails, voir Accepter le protocole révisé pour l'application des règles de protection des données.
Gestion des paramètres des rapports
6 juin 2024
Les propriétaires ou les administrateurs de compte IBM Cloud peuvent désormais gérer les paramètres des rapports sur la page Compte . Pour plus d'informations, voir Gestion des paramètres de compte.
Semaine se terminant le 31 mai 2024
IBM Watson Pipelines est désormais IBM Orchestration Pipelines
30 mai 2024
Le nouveau nom de service reflète les capacités d'orchestration de parties du cycle de vie de l'intelligence artificielle en flux reproductibles.
Etiquetez les projets pour les extraire facilement
31 mai 2024
Vous pouvez désormais affecter des étiquettes à des projets afin de faciliter leur regroupement ou leur extraction. Affectez des balises lorsque vous créez un nouveau projet ou à partir de la liste de tous les projets. Filtrez la liste des projets par étiquette pour extraire un ensemble de projets associé. Pour plus d'informations, voir Création d'un projet.
Se connecter à une nouvelle source de données : Milvus
31 mai 2024
Utilisez la connexion Milvus pour stocker et confirmer l'exactitude de vos identifiants et détails de connexion pour accéder à un magasin de vecteurs Milvus. Pour plus d'informations, voir la connexion Milvus.
Semaine se terminant le 24 mai 2024
Utilisateur et rôle de l'actif
24 mai 2024
Mise à jour des rôles d'appartenance d'actif pour les catalogues. Désormais, les utilisateurs peuvent détenir le rôle de propriétaire d'actif, d'éditeur d'actif ou d'afficheur d'actif. Le rôle d'éditeur d'actif a remplacé le rôle de membre d'actif. Maintenant, pour effectuer des actions liées à un actif, vous devez être un propriétaire d'actif ou un éditeur d'actif.
En outre, les actifs peuvent avoir plusieurs propriétaires maintenant.
Vous pouvez modifier les rôles utilisateur d'un actif dans la page de contrôle Accès d'un actif en sélectionnant un rôle dans le menu déroulant Rôle .
Actions en bloc sur les actifs de catalogue
24 mai 2024
Vous pouvez désormais modifier et supprimer les termes commerciaux, les propriétaires ou les étiquettes pour un maximum de 20 actifs de catalogue à la fois.
Semaine se terminant le 10 mai 2024
Nouveaux filtres pour les résultats d'enrichissementIBM Knowledge Catalog)
10 mai 2024
Vous pouvez maintenant appliquer des filtres supplémentaires à vos résultats d'enrichissement:
- Affecté, suggéré ou aucun terme métier
- Affecté, suggéré ou aucune classe de données
Modifications de nom pour les connexions et les connecteurs DataStage
10 mai 2024
Les connexions et connecteurs DataStage suivants portent de nouveaux noms:
- "Apache Cassandra (optimisé)" est maintenant "Apache Cassandra pourDataStage" .
- "IBMDb2 (optimisé") est maintenant "IBMDb2 pourDataStage" .
- "IBMNetezza Performance Server (optimisé)" est maintenant "IBMNetezza Performance Server pourDataStage" .
- "Oracle (optimisé)" est maintenant "Oracle Database pourDataStage" .
- "Salesforce.com (optimisé)" est maintenant "Salesforce API pourDataStage" .
- "Teradata (optimisé)" est maintenant "Teradata base de données pourDataStage" .
Vos paramètres précédents pour les connexions, les connecteurs et les travaux associés restent les mêmes. Seuls les noms de connexion et de connecteur ont été modifiés.
Semaine se terminant le 26 avril 2024
Changement de nom pour la connexion IBM Watson Query
26 avril 2024
La connexion "IBM Watson Query" a été renommée en "IBM Data Virtualization". Vos paramètres précédents pour la connexion sont conservés. Seul le nom de la connexion a été modifié.
Changement de nom pour le connecteur DataStage IBM Watson Query
26 avril 2024
Le nom de connecteur DataStage "IBM Watson Query" a été remplacé par "IBM Data Virtualization". Ce changement coïncide avec le changement de nom de connexion. Vos paramètres précédents pour la connexion, le connecteur et les travaux associés restent les mêmes. Seuls le nom de la connexion et du connecteur ont été modifiés.
Masquagewatsonx.data dansIBM Knowledge Catalog
26 avril 2024
Vous pouvez protéger les données sensibles danswatsonx.data en utilisant les capacités de masquage deIBM Knowledge Catalog . Pour plus d'informations, voir Masquagewatsonx.data actifs enIBM Knowledge Catalog .
Semaine se terminant le 19 avril 2024
Vue de liste de projets améliorée dans les catalogues
18 avril 2024
A présent, lorsque vous ajoutez des actifs d'un catalogue à un projet, vous pouvez afficher plus de 100 projets dans votre page de liste de projets et ajouter jusqu'à 50 actifs à la fois à votre projet. Pour plus d'informations, voir Ajout d'actifs à partir du catalogue.
Evaluer les déploiements d'apprentissage automatique dans les espaces
18 avril 2024
Configurez les évaluations watsonx.governance dans vos espaces de déploiement pour obtenir des informations sur les performances de votre modèle d'apprentissage automatique. Par exemple, évaluez un déploiement pour le biais ou surveillez un déploiement pour la dérive. Lorsque vous configurez des évaluations, vous pouvez analyser les résultats d'évaluation et modéliser les enregistrements de transaction directement dans vos espaces.
Pour plus d'informations, voir Evaluation des déploiements dans les espaces.
19 avril 2024
Fiches d'information disponibles à partir des cas d'utilisation de l'IA dans le menu de navigation principal
Les fiches d'information qui suivent les détails du cycle de vie des modèles d'apprentissage automatique sont désormais stockées dans des cas d'utilisation de l'IA plutôt que dans des cas d'utilisation de modèle. Les cas d'utilisation de l'intelligence artificielle et les modèles externes sont affichés dans le menu de navigation principal pour faciliter l'accès.
Semaine se terminant le 12 avril 2024
Révision du protocole d'application des règles de protection des données dans Cloud Pak for Data
12 avril 2024
Une version révisée du protocole d'application des règles de protection des données est désormais en place dans Cloud Pak for Data. Lorsque vous vous trouvez dans un catalogue gouverné et que vous cliquez sur Add to project, des informations sur le nouveau protocole d'application des règles de protection des données s'affichent. Vous devez le reconnaître pour continuer.
Cognos Dashboards Le service Embedded est obsolète
11 avril 2024
Vous ne pouvez plus mettre à disposition une instance du service Cognos Dashboards Embedded. Toutefois, tous les tableaux de bord existants que vous avez créés avec le service Cognos Dashboards Embedded continueront de fonctionner jusqu'au 20 juin 2024. Vous pouvez utiliser Cognos Analytics on Cloud On-Demand pour remplacer Cognos Dashboards Embedded. Pour plus d'informations, voir IBM Cognos Analytics -Plans de tarification.
Semaine se terminant le 5 avril 2024
Utiliser des tableaux croisés dynamiques pour afficher les données agrégées dans les expérimentations Decision Optimization
5 avril 2024
Vous pouvez désormais utiliser des tableaux croisés dynamiques pour afficher à la fois les données d'entrée et de sortie agrégées dans la vue Visualisation des expérimentations Decision Optimization . Pour plus d'informations, voir Widgets de visualisation dans les expérimentations Decision Optimization.
Accès à la liste des propriétés d'API de connexion à partir de l'interface utilisateur
5 avril 2024
Auparavant, le seul moyen d'afficher les propriétés de la connexion était d'ouvrir une nouvelle page web à l'https://dataplatform.cloud.ibm.com/connections/docs. Vous pouvez désormais accéder aux mêmes informations à partir de Données > Connectivité. Développez Ressources de connexionet sélectionnez Propriétés de connexion.
Vous pouvez utiliser ces propriétés pour créer des connexions avec les connexions dans l'API Watson Data. Par exemple, si vous créez une connexion dans un bloc-notes à l'aide d'un programme, vous pouvez utiliser ces informations pour identifier les propriétés dont vous avez besoin.
Semaine se terminant le 22 mars 2024
Créer des vues dynamiques des données connectéesIBM Knowledge Catalog
21 mars 2024
Un nouveau type d'actif de données connecté fournit un accès filtré aux données des sources de données qui prennent en charge les requêtes SQL afin que vous puissiez accéder uniquement aux données pertinentes. Dans un projet, fournissez une requête SQL pour créer une vue de colonnes ou de lignes spécifiques à partir d'une ou de plusieurs tables. Vous pouvez utiliser ces actifs de données dans l'enrichissement des métadonnées et l'analyse de la qualité des données comme n'importe quel autre actif de données connecté.
Pour plus d'informations, voir Ajout d'une vue dynamique des données connectées à un projet.
Utiliser les formats de table Delta Lake ou Apache Iceberg dans les connecteurs Amazon S3 et Apache HDFS
22 mars 2024
Les connecteurs Amazon S3 et Apache HDFS incluent désormais des propriétés pour les formats de table Delta Lake et Apache Iceberg. Ces formats de table font partie intégrante des lacs de données, qui fournissent un référentiel centralisé pour la gestion de grands volumes de données. Les lacs de données servent de base à la collecte et à l'analyse de données structurées, semi-structurées et non structurées dans leur format d'origine pour le stockage à long terme et pour générer des connaissances et des prévisions.
La propriété de format de tableau est incluse dans les propriétés d'interaction pour les outils pris en charge. Par exemple, dans le connecteur Propriétés d'étape dans DataStage.
Semaine se terminant le 23 février 2024
Nouveau tutoriel et nouvelle vidéo Watson OpenScale
23 février 2024
Essayez le nouveau tutoriel Watson OpenScale pour apprendre à évaluer un modèle d'apprentissage automatique en termes d'équité, de précision, de dérive et d'explicabilité.
| Tutoriel | Descriptif | Expertise pour le tutoriel |
|---|---|---|
| Évaluer un modèle d'apprentissage automatique | Déployer un modèle, configurer des moniteurs pour le modèle déployé et évaluer le modèle. | Exécuter un notebook pour configurer les modèles et utiliser Watson OpenScale pour les évaluer. |
Accès aux données à partir de DataStax Enterprise
23 février 2024
Vous pouvez désormais utiliser les données d' DataStax Enterprise.
Semaine se terminant le 16 février 2024
Codes sensibles à la casse dans les jeux de données de référence dans IBM Knowledge Catalog
16 février 2024
Les valeurs de données de référence se composent d'au moins deux colonnes: code et valeur. Pour tous les nouveaux jeux de données de référence, la colonne de code est désormais sensible à la casse. Lorsque vous ajoutez des valeurs à un nouveau jeu de données de référence, le code est sauvegardé exactement comme vous l'avez saisi. Notez que tous les jeux de données de référence qui ont été créés avant l'introduction de cette modification restent insensibles à la casse et que les nouvelles valeurs qui y ont été ajoutées seront sauvegardées en majuscules. Ces jeux de données de référence sont marqués avec une balise insensible à la casse dans l'interface utilisateur. Pour plus de détails, voir Code sensible à la casse.
Amélioration des options de recherche, de filtrage et de tri pour les jeux de données de référence dans IBM Knowledge Catalog
16 février 2024
Lorsque vous affichez une liste de valeurs de données de référence, vous pouvez utiliser les méthodes suivantes pour trouver plus rapidement les valeurs requises:
- Utilisez une barre de recherche pour entrer une requête pour un code, une valeur ou une valeur de colonne personnalisée.
- Utilisez l'une des 6 options de filtre avancées.
- Utilisez la fonction de tri.
Les options de recherche, de filtrage et de tri peuvent être combinées. Pour plus de détails, voir Affichage des jeux de données de référence.
Semaine se terminant le 09 février 2024
Nouvel environnement Spark 3.4 pour l'exécution de travaux de flux Data Refinery
09 fév 2024
Lorsque vous sélectionnez un environnement pour un travail de flux Data Refinery , vous pouvez maintenant sélectionner Default Spark 3.4 & R 4.2, qui inclut des améliorations de Spark.
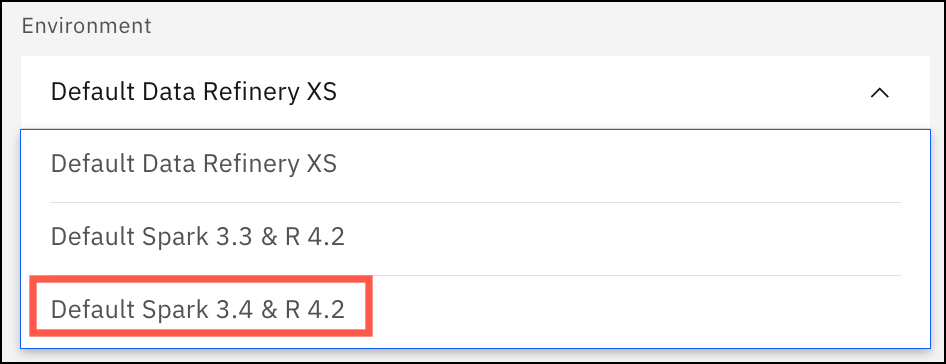
L'environnement Default Spark 3.3 & R 4.2 est obsolète et sera supprimé lors d'une mise à jour ultérieure.
Mettez à jour vos travaux de flux Data Refinery pour utiliser le nouvel environnement Default Spark 3.4 & R 4.2 . Pour plus de détails, voir Options de ressource de calcul pour Data Refinery dans les projets.
Documentation Decision Optimization plus centrée sur les tâches
09 fév 2024
Vous pouvez désormais trouver plus facilement les informations appropriées pour créer et configurer des expérimentations Decision Optimization . Voir ExpériencesDecision Optimization et ses sous-sections.
Fonction de vue de pagination pour la publication d'actifs dans un catalogue
08 fév 2024
Lorsque vous publiez des actifs de projet dans un catalogue, vous pouvez désormais afficher 20 catalogues et actifs sur chaque page avec la vue de pagination. Auparavant, vous pouvez afficher vos actifs dans une liste. Voir Publication d'actifs dans un catalogue.
Des types d'analyse avancés dans l'enrichissement des métadonnées sont disponibles dans la région de FrancfortIBM Knowledge Catalog
09 fév 2024
La clé primaire avancée et l'analyse des relations et le profilage avancé sont désormais également disponibles dans la région de Francfort, en plus de la région de Dallas.
IBM Cloud Data Engine la connexion est obsolète
08 fév 2024
La connexion IBM Cloud Data Engine est obsolète et sera supprimée dans une prochaine version. Pour connaître les dates importantes et les détails, consultez la rubrique " Déclassement du moteur de données".
Semaine se terminant le 02 février 2024
Sauvegardez vos recherches d'actifs de catalogue
02 fév 2024
Chaque utilisateur peut désormais enregistrer jusqu'à 25 recherches dans chacun de ses catalogues. L'utilisateur qui sauvegarde une recherche dans un catalogue est le seul utilisateur qui peut afficher, exécuter, éditer et supprimer la recherche. Pour plus d'informations, voir Sauvegarde des recherches d'actifs de catalogue.
Galerie renommée en concentrateur de ressources
02 fév 2024
La galerie est renommée en concentrateur de ressources. Le concentrateur de ressources contient des exemples de projets, de fichiers et de blocs-notes. Voir concentrateur de ressources.
IBM Cloud Databases for DataStax connexion interrompue
02 fév 2024
La connexion IBM Cloud Databases for DataStax a été supprimée de Cloud Pak for Data as a Service.
La connexion Dremio requiert des mises à jour
02 fév 2024
Auparavant, la connexion Dremio utilisait un pilote JDBC . La connexion utilise désormais un pilote basé sur Arrow Flight.
Important: mettez à jour les propriétés de connexion. Différentes modifications s'appliquent à une connexion pour une instance Dremio Software (sur site) ou une instance Dremio Cloud.
Logiciel Dremio : mettez à jour le numéro de port.
Le nouveau numéro de port par défaut utilisé par Flight est 32010. Vous pouvez confirmer le numéro de port dans le fichier dremio.conf . Voir Configuration via dremio.conf pour plus d'informations.
En outre, Dremio ne prend plus en charge les connexions avec IBM Cloud Satellite.
Dremio Cloud: mettez à jour la méthode d'authentification et le nom d'hôte.
- Connectez-vous à Dremio et générez un jeton d'accès personnel. Pour plus d'informations, voir les jetons d'accès personnels.
- Dans Cloud Pak for Data as a Service dans le formulaire Create connection: Dremio , remplacez le type d'authentification par Personal Access Token et ajoutez les informations relatives au jeton. (L'authentification Nom d'utilisateur et mot de passe ne peut plus être utilisée pour se connecter à une instance cloud Dremio .)
- Sélectionnez Le port est activé pour SSL.
Si vous utilisez le nom d'hôte par défaut pour une instance Dremio Cloud, vous devez le modifier:
- Remplacez
sql.dremio.cloudpardata.dremio.cloud - Remplacez
sql.eu.dremio.cloudpardata.eu.dremio.cloud
Types d'analyse supplémentaires dans l'enrichissement de métadonnées (IBM Knowledge Catalog)
31 janvier 2024
L'enrichissement des métadonnées fournit désormais les options d'analyse supplémentaires suivantes:
Analyse de clé primaire pour détecter les clés primaires dans vos données qui identifient de manière unique chaque enregistrement dans un actif de données.
L'analyse superficielle est automatiquement incluse lorsque vous sélectionnez l'option d'enrichissement Données de profil . L'analyse avancée peut être exécutée sur des actifs sélectionnés à partir des résultats d'enrichissement.
Analyse des relations pour identifier les relations entre les actifs de données ou pour trouver des données redondantes et redondantes dans les colonnes.
L'analyse des relations de clé superficielle est exécutée lorsque vous sélectionnez la nouvelle option d'enrichissement Définir les relations . L'analyse avancée peut être exécutée sur des actifs sélectionnés à partir des résultats d'enrichissement.
Profilage avancé pour obtenir des résultats plus précis pour certains indicateurs, tels que la distribution de fréquence et l'unicité des valeurs dans une colonne.
Le profilage avancé peut être exécuté sur des actifs sélectionnés à partir des résultats d'enrichissement.
L'analyse avancée des clés primaires et des relations et le profilage avancé nécessitent le service DataStage en plus du service IBM Knowledge Catalog et ne sont disponibles que dans la région de Dallas.
Pour plus d'informations, voir Création d'un actif d'enrichissement de métadonnées, Identification des clés primaires, Identification des relationset Profils de données avancés.
Semaine se terminant le 26 janvier 2024
AutoAI prend en charge les données ordonnées pour toutes les expérimentations
25 janvier 2024
Vous pouvez désormais spécifier des données ordonnées pour toutes les expérimentations AutoAI plutôt que des expérimentations de séries temporelles. Indiquez si vos données d'apprentissage sont classées de manière séquentielle, en fonction d'un index de ligne. Lorsque les données d'entrée sont séquentielles, les performances du modèle sont évaluées sur les enregistrements les plus récents au lieu d'un échantillonnage aléatoire, et les données restantes utilisent les n derniers enregistrements de l'ensemble au lieu de n enregistrements aléatoires. Des données séquentielles sont requises pour les expériences de séries temporelles, mais facultatives pour les expériences de classification et de régression.
Définir sur le thème foncé
25 janvier 2024
Vous pouvez désormais définir votre interface utilisateur Cloud Pak for Data as a Service sur le thème foncé. Cliquez sur votre avatar et sélectionnez Profil et paramètres pour ouvrir votre profil de compte. Ensuite, définissez le bouton de thème foncé sur on. Le thème sombre n'est pas pris en charge dans RStudio et les carnets Jupyter. Pour plus d'informations sur la gestion de votre profil, voir Gestion de vos paramètres.
Semaine se terminant le 19 janvier 2024
Afficher les informations de type natif dans le panneau des détails des colonnes d'actif
19 janvier 2024
Vous pouvez maintenant afficher les types de données standardisés et natifs directement dans le panneau des détails de la colonne. Pour afficher les informations de type natif, cliquez sur le nom d'une colonne d'actif dans la page Présentation d'un actif.
Nouvelle option pour la priorité des actions de règle (IBM Knowledge Catalog)
18 janvier 2024
La priorité des actions de règle vous permet de spécifier comment les règles sont appliquées lorsqu'il existe plusieurs règles avec des actions différentes sur un ensemble de données. Vous pouvez utiliser la nouvelle option Application hiérarchique pour configurer une évaluation à deux couches des règles de protection des données.
- La première couche évalue les règles pour une action
AllowouDenysans prendre en compte les actions de masquage. La décision de cette première couche doit être de permettre l'accès à la deuxième couche. - La deuxième couche évalue les règles d'une action
Transform.
Vous pouvez définir cette option à partir de l'interface utilisateur ou de l' APIaccess_decision_precedence.
Pour plus d'informations, voir Gestion des paramètres de règle.
Stockez les résultats de l'analyse de la qualité des données (IBM Knowledge Catalog)
18 janvier 2024
Vous avez maintenant la possibilité d'écrire la sortie des contrôles de qualité de données prédéfinis qui sont exécutés dans le cadre de l'enrichissement des métadonnées dans une base de données. Par exemple, vous pouvez stocker ces données afin de pouvoir utiliser les tables pour le suivi des problèmes de qualité et en tant qu'entrée pour les processus de résolution. Pour plus d'informations, voir Création d'un enrichissement de métadonnées.
Connectez-vous à une nouvelle source de données dansDataStage:Tableau
18 janvier 2024
Vous pouvez désormais inclure des données provenant d'une source de données Tableau dans vos flux DataStage .
Pour la liste complète des connecteurs DataStage , voir Sources de données prises en charge dans DataStage.
Semaine se terminant le 12 janvier 2024
La prise en charge du Runtime IBM 22.2 est obsolète dans le Runtime watsonx.ai (anciennement Watson Machine Learning)
11 janvier 2024
IBM Runtime 22.2 est obsolète et sera supprimé le 11 avril 2024. A partir du 7 mars 2024, vous ne pouvez pas créer de blocs-notes ou d'environnements personnalisés à l'aide des environnements d'exécution 22.2 . En outre, vous ne pouvez pas entraîner de nouveaux modèles avec des spécifications logicielles basées sur l'environnement d'exécution 22.2 . Mettez à jour vos actifs et vos déploiements pour utiliser IBM Runtime 23.1 avant le 7 mars 2024.
- Pour en savoir plus sur la migration d'un actif vers une infrastructure et une spécification logicielle prises en charge, voir Gestion des spécifications ou des infrastructures logicielles obsolètes.
- Pour en savoir plus sur l'environnement de bloc-notes, voir Options de ressource de calcul pour l'éditeur de bloc-notes dans les projets.
- Pour en savoir plus sur la modification de votre environnement, voir Modification de l'environnement d'un bloc-notes.