このチュートリアルでは、金融業界での使用例を取り上げます。 ゴールデン銀行は、投資商品の販売促進を分析するプロセスを導入する必要があります。
- 必須のサービス
- watsonx.ai watsonx.ai ランタイムおよび スタジオを含む watsonx.ai
シナリオ:銀行のマーケティングプロモーションプロセス
この目標を達成するために、典型的なプロセスは以下のようになる:
- データエンジニアは、モデルのトレーニングに適した正しいフォーマットを検証するために、銀行のマーケティングデータを視覚化し、準備します。
- MLエンジニアは、プロモーションの効果を予測する機械学習モデルを構築した。
- MLエンジニアがモデルを展開し、テストします。
- データサイエンティストは、 Python コードを書き、銀行の競合他社の類似したプロモーションを見つけます。
- 迅速なエンジニア:
- 要約や質問応答のタスクを実行するためのテンプレートを迅速に作成します。
- 複数のプロンプトのパフォーマンスを比較し、再トレーニングが必要かどうかを判断します。
- foundation model を再トレーニングデータで調整し、最高のパフォーマンスと費用対効果を実現します。
- 再トレーニングプロセスを簡素化するパイプラインを作成します。
watsonx.aiを使った基本的なタスクのワークフロー
Watsonx.aiは、このプロセスの各段階を達成するのに役立ちます。 基本的なワークフローには、以下のタスクが含まれます:
- プロジェクトを開きます。 プロジェクトは、データを処理するために他のユーザーと共同作業できる場所です。
- データをプロジェクトに追加します。 接続を介してリモート・データ・ソースからの CSV ファイルまたはデータを追加できます。
- Data Refinery でトレーニングデータを準備します。
- 学習データを使ってモデルを訓練します。 モデルのトレーニングには、 AutoAI, SPSS Modeler、Jupyter notebook など、さまざまなツールを使用できます。
- プロジェクトまたはデプロイメントスペースでモデルを展開し、テストします。
- Jupyterノートブックでモデルに関連するデータを収集し、分析します。
- Prompt Lab に foundation model を追加する。
- 評価スタジオで迅速なパフォーマンスを比較してください。
- Tuning Studio の foundation model を調整します。
- Pipelines を使用して、モデルのライフサイクルを自動化します。
watsonx.aiについて読む
AIを活用したソリューションでビジネスプロセスを変革するには、機械学習とジェネレーティブAIの両方をオペレーションのフレームワークに統合する必要がある。 Watsonx.aiは、企業が機械学習モデルとジェネレーティブ AI ソリューションを開発および展開できるようにするプロセスとテクノロジーを提供します。
watsonx.aiについてのビデオを見る
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、書面でのチュートリアルに付随するものです。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、書面でのチュートリアルに付随するものです。
このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
watsonx.ai へのチュートリアルを試してみてください
このチュートリアルでは、以下のタスクを実行します:
- タスク1:サンプルプロジェクトの作成
- タスク2:データの可視化と準備
- タスク3:モデルのトレーニング
- タスク4:モデルのデプロイ
- タスク5:競合他社のマーケティングプログラムを収集する
- タスク6:プロンプトを表示する foundation model
このチュートリアルを完了するためのヒント
このチュートリアルを成功させるためのヒントを紹介します。
ビデオのピクチャー・イン・ピクチャーを使う
次のアニメーション画像は、ビデオのピクチャー・イン・ピクチャーと目次機能の使い方を示しています:

地域の助けを借りる
このチュートリアルについてお困りの場合は、 watsonx のコミュニティディスカッションフォーラムで質問を投稿したり、回答を検索することができます。
ブラウザのウィンドウを設定する
このチュートリアルを最適に完了するには、Cloud Pak for Data を 1 つのブラウザ ウィンドウで開き、このチュートリアルのページを別のブラウザ ウィンドウで開いておくと、2 つのアプリケーションを簡単に切り替えることができます。 2つのブラウザウィンドウを横に並べると、より見やすくなります。

タスク 1:サンプルプロジェクトの作成
このタスクをプレビューするには、 00:51 から始まるビデオをご覧ください。
このチュートリアルでは、データセット、ノートブック、プロンプトテンプレートを含むサンプルプロジェクトを使用して分析を行います。 以下の手順に従って、サンプルに基づいたプロジェクトを作成してください:
ホーム画面から、 新規プロジェクト作成アイコン
 をクリックします。
をクリックします。サンプルを選択します。
Getting started with watsonx.aiを検索し、そのサンプルプロジェクトを選択して、 [次へ] をクリックします。既存の オブジェクト・ストレージ・サービス・インスタンス を選択するか、または新規作成します。
「作成」 をクリックします。
プロジェクトのインポートが完了するまで待ち、 [新しいプロジェクトを表示] をクリックします。
watsonx.ai のランタイムサービスをプロジェクトに関連付けます。 詳細については 、 watsonx.ai ランタイムを参照してください。
プロジェクトが開いたら、管理タブをクリックし、サービスと統合ページを選択します。
IBM サービスのタブで 、「サービスを関連付ける」 をクリックします。
watsonx.ai のランタイムインスタンスを選択します。 watsonx.ai ランタイムサービスインスタンスがまだプロビジョニングされていない場合は、以下の手順に従ってください
新規サービスをクリックします。
watsonx.ai のランタイムを選択します。
「作成」 をクリックします。
リストから新しいサービス・インスタンスを選択する。
サービスを関連付けるをクリックします。
必要に応じて、キャンセルをクリックし、サービス & 統合ページに戻ります。
プロジェクトのアセットタブをクリックすると、サンプルアセットが表示されます。
詳細情報または動画の視聴については 、「プロジェクトの作成」 を参照してください。
関連サービスの詳細については 、「関連サービスの追加 」を参照してください。
 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトの「資産」タブを示しています。 これでトレーニングデータを視覚化する準備が整いました。
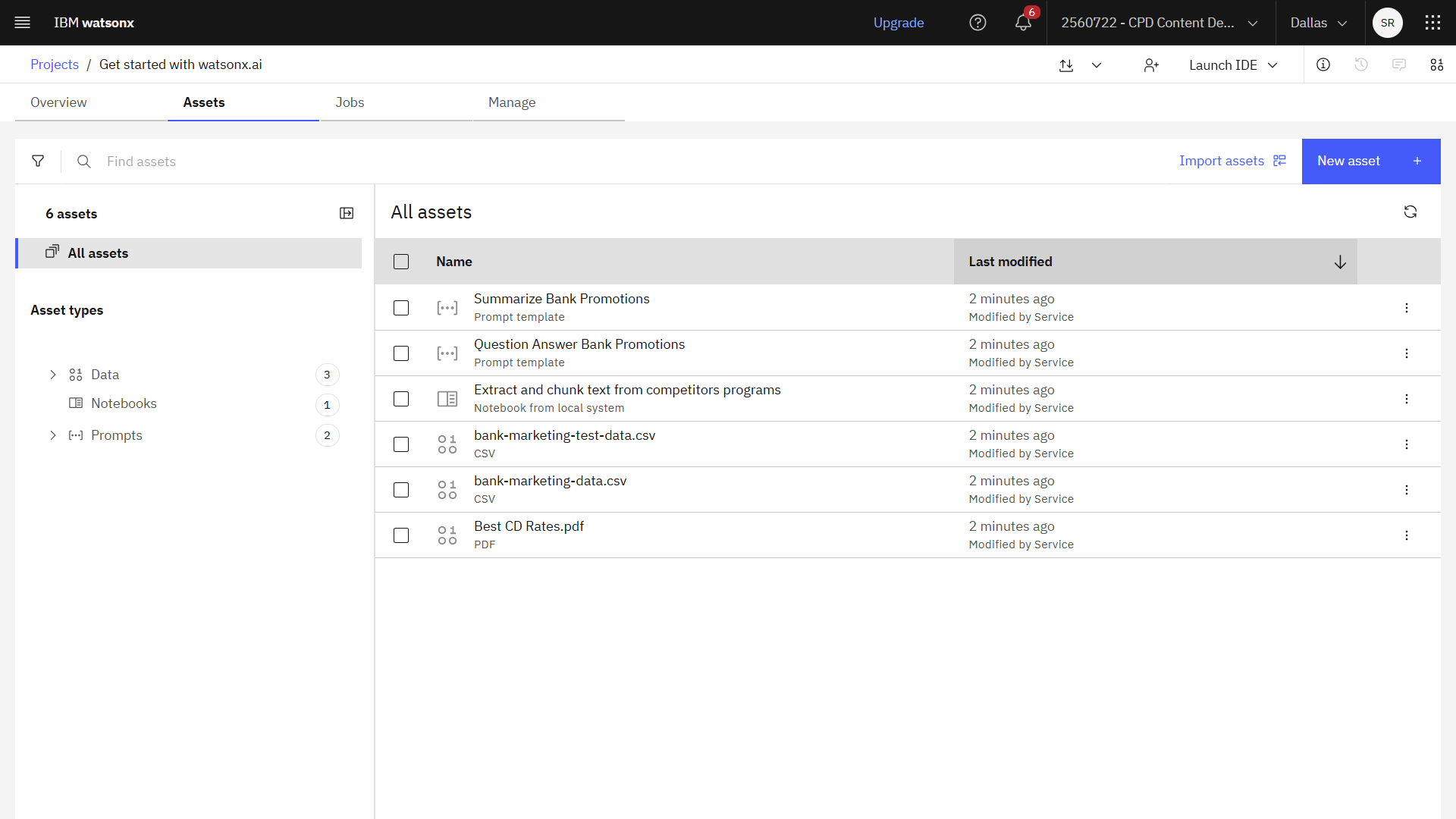
タスク2:データの可視化と準備
このデータは、ポルトガルの銀行機関のダイレクトマーケティングキャンペーン(電話)を表しています。 分類の目的は、顧客が定期預金に加入するかどうか(はい/いいえ)を予測することです(カラム current_outcome)。 このデータセットは、UCI Machine Learning リポジトリから取得したデータセットに基づいています。
タスク 2a: データの可視化
このタスクをプレビューするには、 1:24 から始まるビデオをご覧ください。
まず、データに明らかな異常がないかを確認するために可視化します。 データを可視化するには、以下の手順に従います
- データセットを開きます。 bank-marketing-data.csv データセットを開きます。 列には潜在的な顧客に関する情報が含まれています。
- 資産を表示 アイコン
 をクリックして、 資産について ウィンドウを閉じます。
をクリックして、 資産について ウィンドウを閉じます。 - ビジュアライゼーションタブをクリックします。
- current_outcome 列を可視化する列として選択します。 この列は、連絡した相手が現在のオファーを受け入れたかどうかを示します。この列は、モデルを構築する際のターゲット列となります。
- 「別の列を追加 」をクリックし、次に 「previous_outcome」列を選択します。 この欄には、連絡した相手が以前のオファーを受け入れたかどうかを示します。 青いドットが付いたチャートタイプが推奨チャートです。
- ツリーチャートの種類を選択します。 このグラフは、以前のオファーを受諾した人々と、それらの同じ人々が現在のオファーを受諾したかどうかを比較したものです。
- ルートノードにカーソルを合わせると、データセット内のレコードの総数を確認できます。
- 同様に 、「いいえ」 と「はい」のノードにカーソルを合わせると、それらの合計が表示されます。
- ラベルのないノードにカーソルを合わせると、 current_outcomeフィールドがnullであるデータセット内のレコードの総数を確認できます。
進捗状況を確認する
次の画像は、 bank-marketing-data.csv ファイルの視覚化を示しています。 これで、トレーニングデータの準備が整いました。
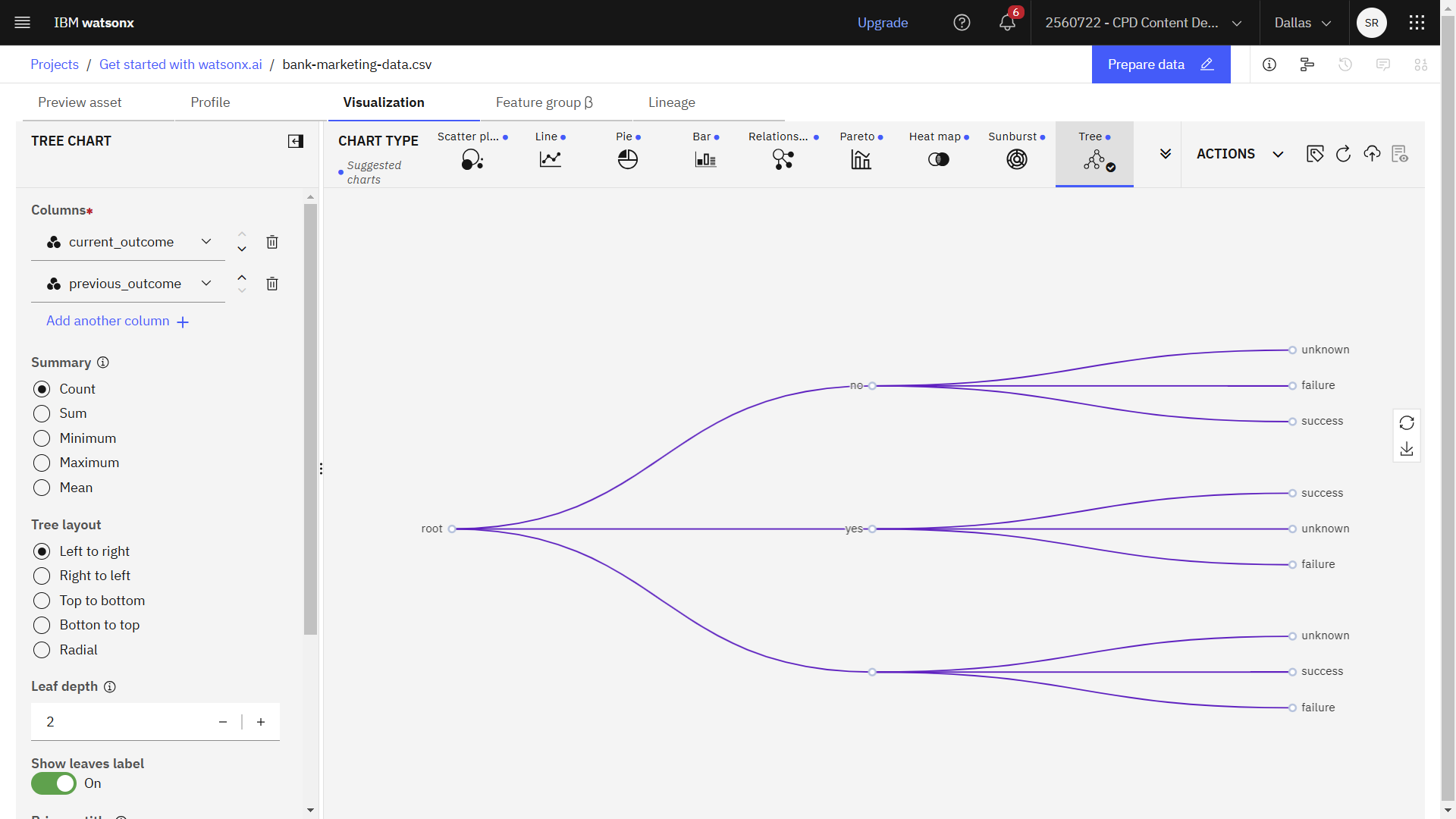
タスク 2b: データの準備
このタスクのプレビューを見るには、 2分40秒から始まるビデオをご覧ください。
current_outcome が対象の列であるため、null値の行を削除するデータセットを用意する必要があります。 データセットを準備するには、以下の手順に従います
- 「データの準備 」をクリックすると、 Data Refinery が開きます。
- 資産について のウィンドウを閉じます。
- current_outcome 列を選択します。
- [新しいステップ] > [空の行を削除] をクリックします。
- 「適用」をクリックします。
- [プロファイル] タブをクリックして、アクションを確認します。
- current_outcomeの列までスクロールすると、すべての値が「はい」または「いいえ」のいずれかであることがわかります。
進捗状況を確認する
次の画像は、[プロファイル] タブの [現在の結果] 列を示しています。
これで、このトレーニングデータを使ってモデルを構築する準備ができた
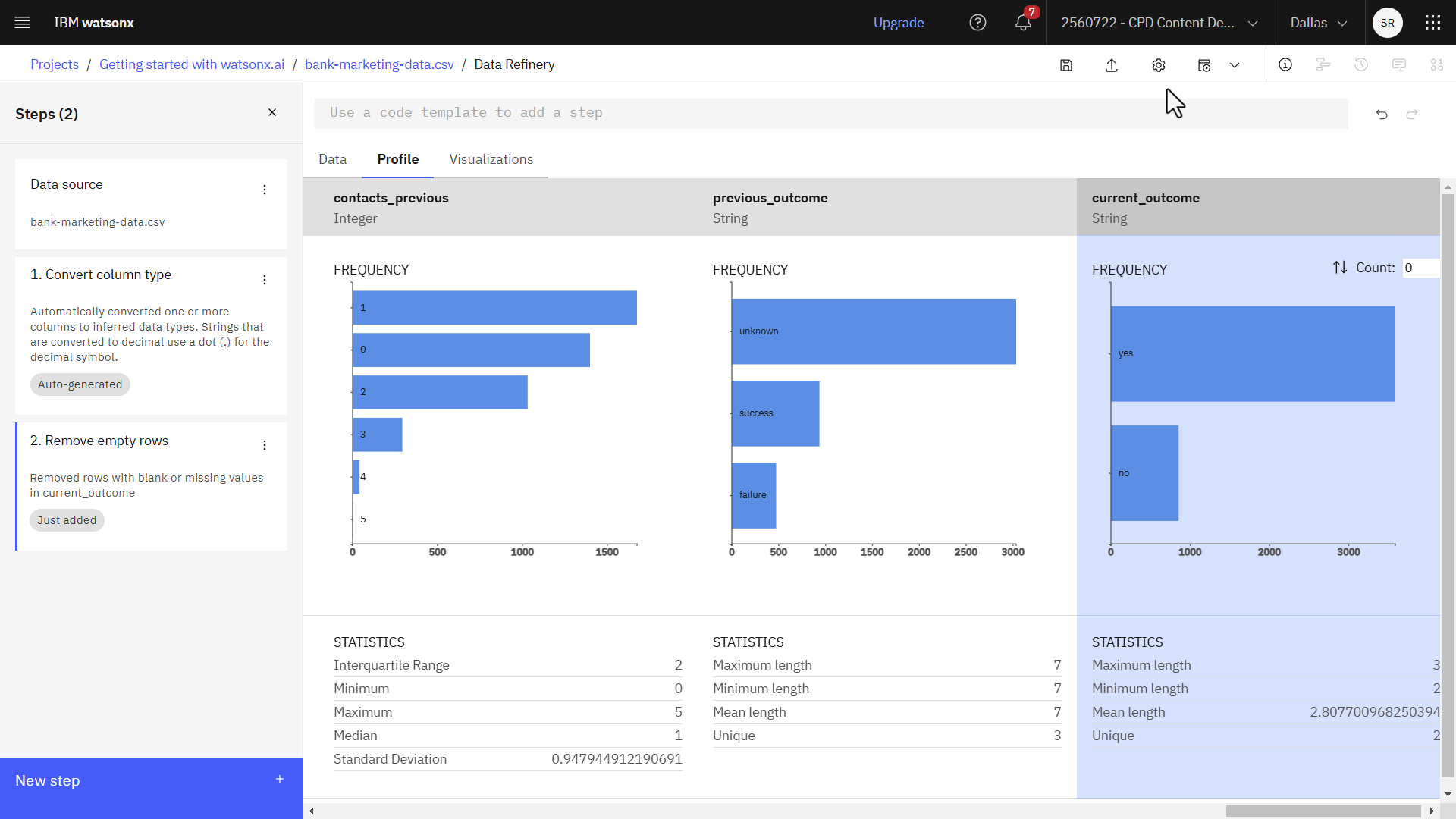
タスク 2c: 精製されたデータを保存する
このタスクをプレビューするには、 3分8秒から始まるビデオをご覧ください。
精製したデータを保存するには、ターゲットデータセットのファイル名を指定し、ジョブを作成して実行します。 以下の手順に従って、精製したデータを保存してください
ファイル名を指定してください:
- 設定アイコン
 をクリックします。
をクリックします。 - ターゲットデータセットページをクリックします。
- プロパティの編集をクリックします。
- データ資産*を
bank-marketing-data-prepared.csvに変更してください。 - 保存 をクリックします。
- 「適用」をクリックします。
- 設定アイコン
ジョブを作成して実行します
ツールバーから 「ジョブ」アイコンをクリックし 、「保存してジョブを作成」 を選択します。

次の名前を入力し、
Bank marketing dataをクリックして次へをクリックします。「Configure(設定)」ページで、実行環境を選択し 、「Next(次へ)」 をクリックします。
スケジュールページで、デフォルト値を受け入れ 、「次へ」 をクリックします。
通知ページで、このジョブの通知をオフにしたままにし 、「次へ」 をクリックします。
詳細を確認し、 作成して実行 をクリックしてジョブを即時に実行してください。
ジョブが作成されたら、通知内の ジョブの詳細 リンクをクリックして、プロジェクト内のジョブを表示します。 あるいは、プロジェクトの ジョブ タブにナビゲートし、ジョブ名をクリックして開くこともできます。
ジョブの 状態 が 完了 の場合、プロジェクト内の 資産 タブに戻るには、プロジェクトのナビゲーション履歴を使用します。
データ > データ資産 のセクションをクリックすると、 Data Refinery フローの出力が表示されます。 bank-marketing-data-prepared.csv を開いて値を確認します。
進捗状況を確認する
次の画像は、 bank-marketing-data-prepared.csv ファイルを示しています。
これで、このトレーニングデータを使ってモデルを構築する準備ができた
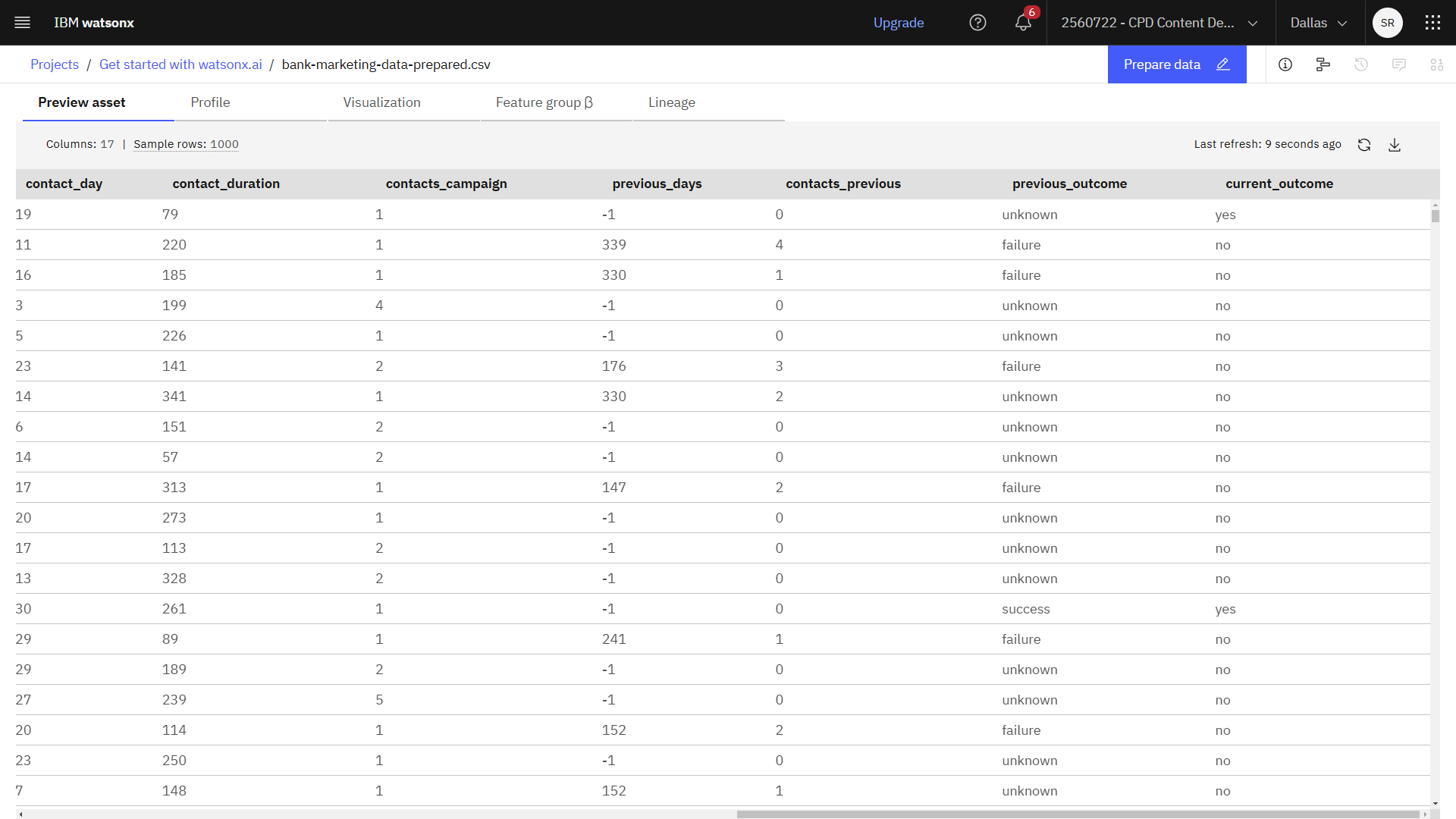
タスク3:モデルのトレーニング
このタスクをプレビューするには、 3:58 から始まるビデオをご覧ください。
モデルのトレーニングには、 AutoAI, SPSS Modeler、Jupyter notebook など、さまざまなツールを使用できます。 このチュートリアルでは、 AutoAI を使用して予測二値分類モデルをトレーニングします。 以下の手順に従って、AutoAI実験を作成する:
プロジェクトの 資産 タブに戻り、 新規資産 > 機械学習モデルの構築または検索拡張生成の自動取得 をクリックします。
機械学習モデルの構築または検索拡張生成の自動取得 ページで、名前を入力します。
Bank marketing experiment「作成」 をクリックします。
この実験のタスクとして 、機械学習モデルの構築を選択します。
データソースの追加ページで、トレーニングデータを追加します:
プロジェクトから選択をクリックします。
Data asset > bank-marketing-data-prepared.csv を選択し、 選択資産 をクリックします。
時系列分析を作成するには ? 番号を選択
予測の列には、 現在の結果を選択します。
「エクスペリメントの実行 (Run experiment)」をクリックします。 模型が動くと、パイプラインの構築プロセスを示すインフォグラフィックが表示されます。

AutoAI, で各機械学習手法で利用可能なアルゴリズム、または推定器の一覧については、 AutoAI の実装の詳細を参照してください。
実験の実行が完了したら、ランキング付きのパイプラインをリーダーボードで確認します。

パイプライン比較をクリックすると、両者の違いを確認できます。

パイプラインのリーダーボードで、最も高い順位のパイプラインをクリックすると、パイプラインの詳細が表示されます。
モデル評価ページで、 ROC曲線チャートとモデル評価指標表でモデルのパフォーマンスを確認します。
モデルを保存します。
名前を付けて保存をクリックします。
モデルを選択します。
モデル名を入力します。
Bank marketing prediction model「作成」 をクリックします。 これにより、パイプラインがモデルとしてプロジェクトに保存されます。
モデルが保存されたら、通知内の プロジェクトで表示 リンクをクリックして、プロジェクト内のモデルを表示します。 あるいは、プロジェクトの資産タブに移動し、モデルセクションでモデル名をクリックすることもできます。
進捗状況を確認する
以下の画像はモデルを示している
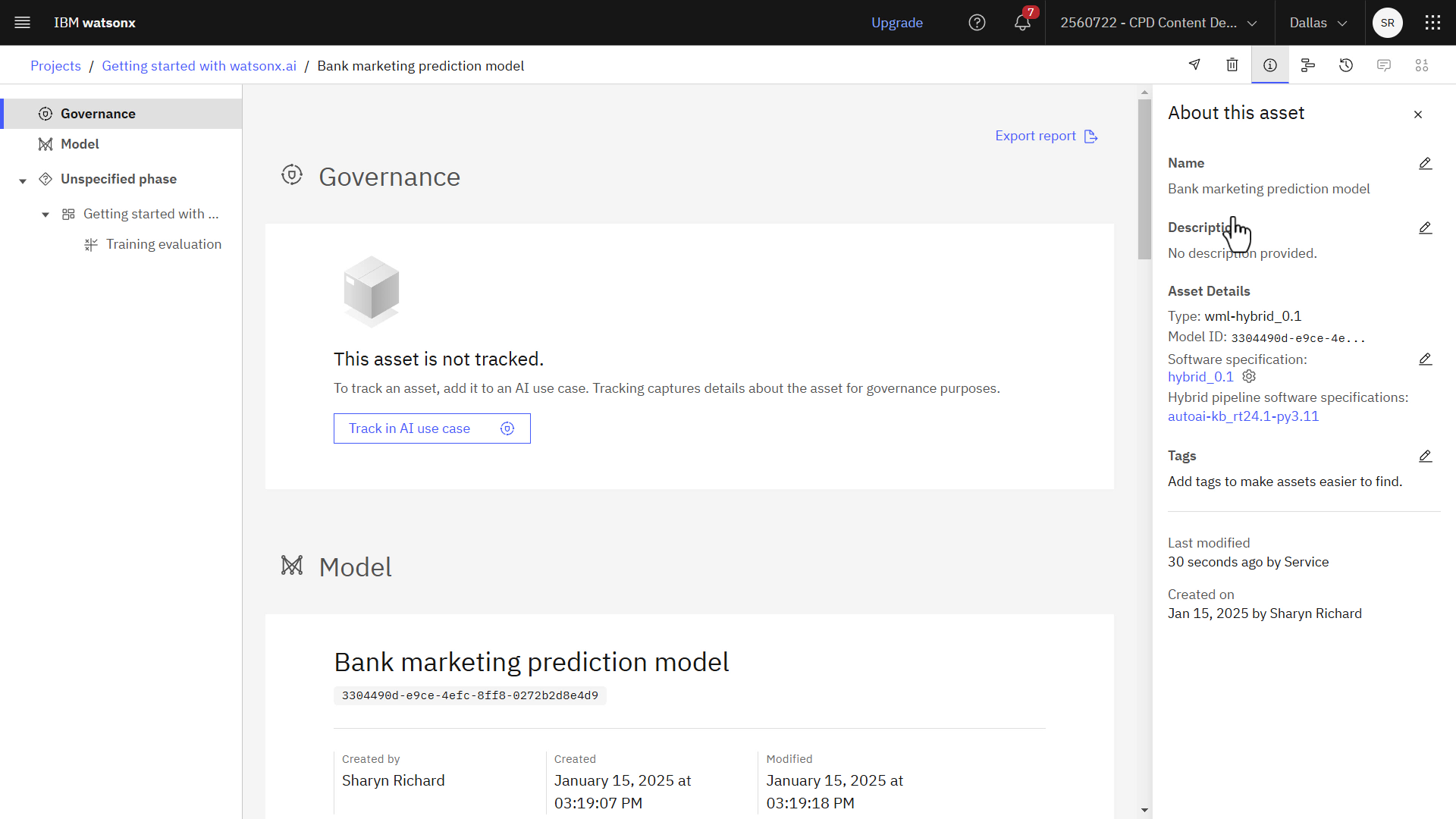
タスク4:モデルのデプロイ
次の作業は、モデルデプロイメントスペースにプロモートし、 デプロイメントを作成することです。
Task 4a: Promote the test data to a deployment space
このタスクをプレビューするには、 5分34秒から始まるビデオをご覧ください。
サンプルプロジェクトにはテストデータが含まれています。 そのテストデータをデプロイメントスペースに昇格させ、デプロイされたモデルをテストするためにテストデータを使用できるようにします。 テスト データを配置スペースに昇格させるには、次の手順に従います:
プロジェクトの 資産 タブに戻ります。
Click the 溢れる menu
 for the bank-marketing-test-data.csv data asset, and choose スペースへのプロモートへ.
for the bank-marketing-test-data.csv data asset, and choose スペースへのプロモートへ.既存のデプロイメント・スペースを選択してください。 もし配置スペースがなければ:
新しい配置スペースを作成をクリックします。
名前を入力し、タイプします。
Bank marketing promotion spaceストレージ・サービスを選択してください。
機械学習サービスを選択してください。
「作成」 をクリックします。
スペースの準備ができたら通知を閉じる。
リストから新しい配置スペースを選択します。
プロモートをクリックします。
閉じる をクリックすると、プロジェクトの 資産 タブに戻ります。
進捗状況を確認する
次の図は、スペースに昇格 page.
を示している
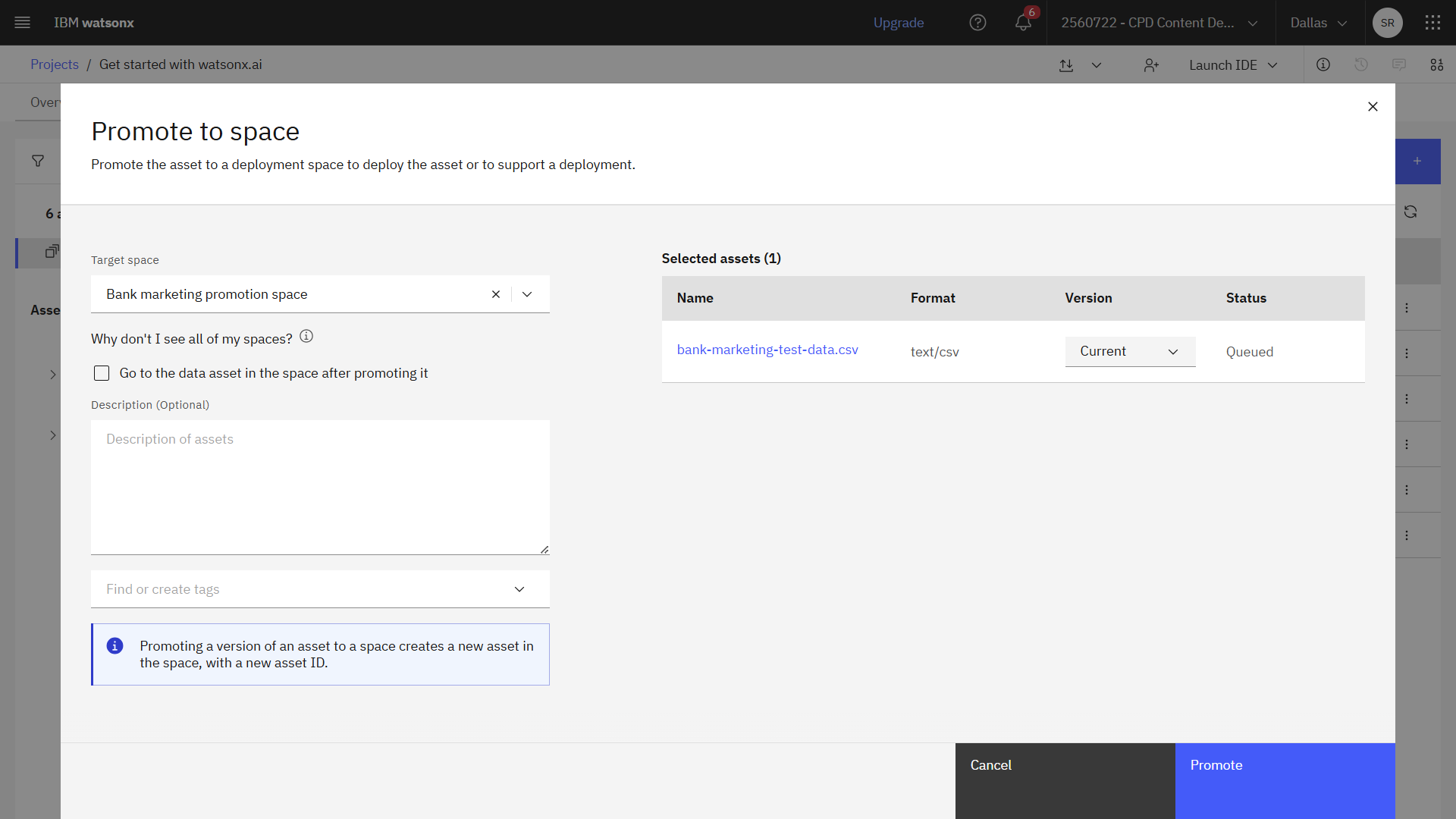
タスク 4b: 展開スペースにモデルをプロモートする
このタスクのプレビューを見るには、 6:11 から始まるビデオをご覧ください。
モデルを配置する前に、モデルを配置スペースにプロモートする必要があります。 以下の手順に従って、モデルを配置スペースにプロモートしてください:
Click the 溢れる menu
for the 銀行マーケティング予測モデル data asset, and choose スペースへのプロモートへ.リストから同じ配置スペースを選択します。
プロモートをクリックします。
プロモーション後、スペース内のモデルに移動するオプションを選択します。
プロモートをクリックします。
進捗状況を確認する
以下の画像は、デプロイメントスペースのモデルを示しています
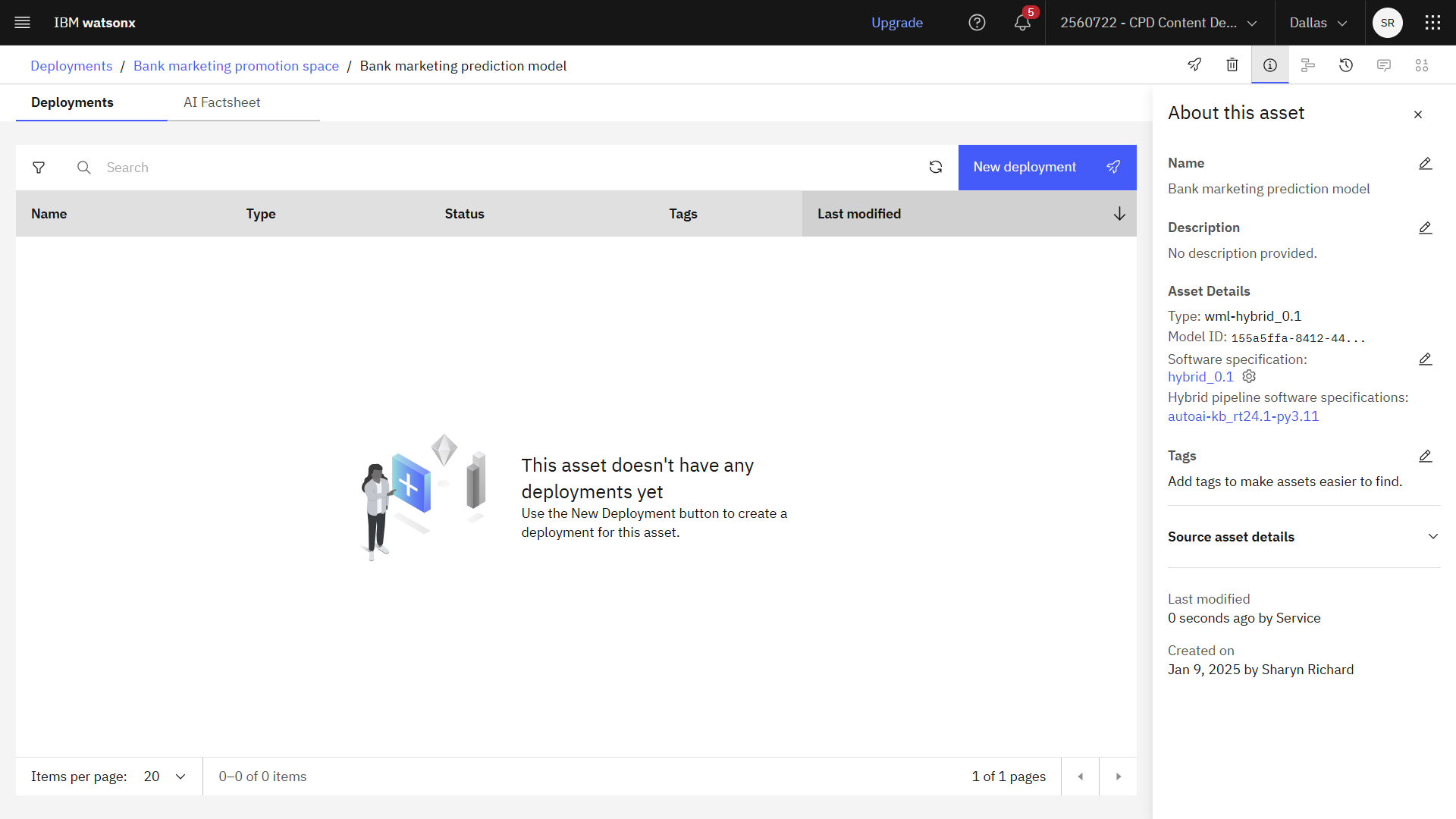
タスク 4c: モデルのデプロイメントを作成し、テストする
このタスクをプレビューするには、 6分21秒から始まるビデオをご覧ください。
モデルが配置スペースに配置されたので、以下の手順に従ってモデルの配置を作成します:
モデルを開いた状態で、新規配置をクリックします。
デプロイメント・タイプとして オンライン を選択してください。
For the deployment name, type:
Bank marketing model deployment「作成」 をクリックします。
デプロイメントが完了したら、デプロイメント名をクリックして、デプロイメントの詳細ページを表示します。
API リファレンスのタブで、アプリケーションでこのモデルにプログラムでアクセスするために使用できる、スコアリングエンドポイントを確認します。
モデルをテストします。
テストタブをクリックします。 デプロイされたモデルは、デプロイメントの詳細ページから 2 つの方法でテストできます:1 つはフォームを使用してテストし、もう 1 つは JSON コードを使用してテストします。 この場合、サンプルプロジェクトからデプロイメントスペースにプロモートしたCSVファイルを選択します。
テストデータを探すには、スペースで検索をクリックします。
Data asset > bank-marketing-test-data.csv を選択します。
「確認 (Confirm)」をクリックします。
[予測] をクリックし、テストデータの60件のレコードの予測を確認します。 モデルは、銀行顧客が定期預金に加入すると予測したすべての顧客に対して「はい」を返します。
進捗状況を確認する
以下の画像は、デプロイされたモデルのテスト結果です
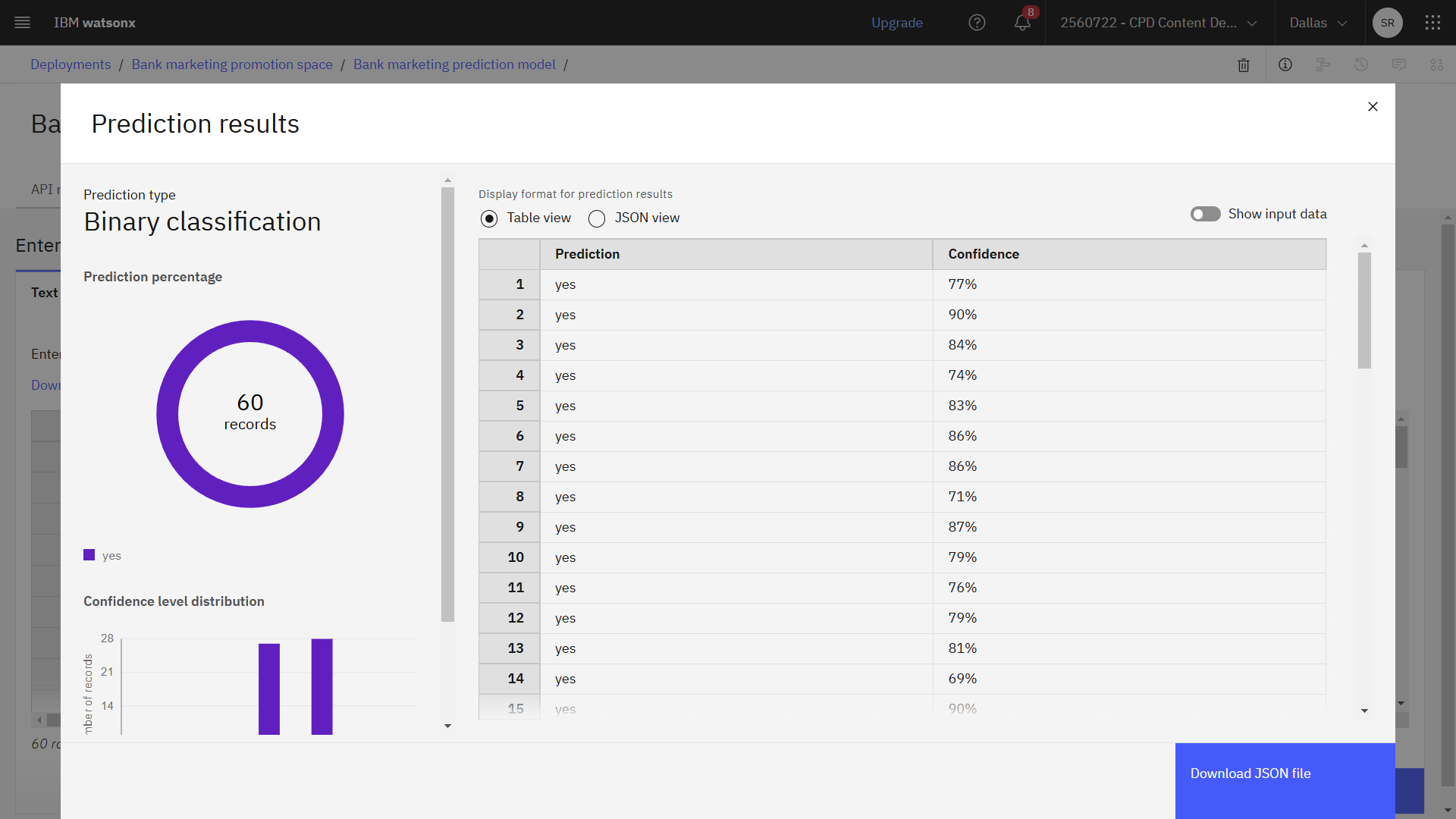
タスク5:競合他社のマーケティングプログラムを収集する
このタスクをプレビューするには、 7:01 から始まるビデオをご覧ください。
Prompt Lab は構造化および非構造化テキストに対応していますが、モデルが処理できる正しいデータを入力することが重要です。 Jupyter notebookで Python のコードを使用すれば、これを行うことができます。
基盤モデルでは、1回のプロンプト(コンテキストウィンドウとして知られている)で処理できるトークンの数に制限があるため、この制限内に収まるようにデータを分割または要約する必要がある場合があります。 このステップでは、入力データが、 foundation model が本質的な情報を失うことなく効果的に処理できる形式であることを確認します。
ノートブックを実行するには、以下の手順に従ってください:
- ナビゲーションメニューの
 から、 [プロジェクト] > [すべてのプロジェクトを表示 ] を選択します。
から、 [プロジェクト] > [すべてのプロジェクトを表示 ] を選択します。 - watsonx.ai プロジェクトの開始を開きます。
- 「資産」タブをクリックします。
- 「オーバーフロー」メニュー の をクリックし 、「競合他社のプログラムからテキストを抽出および分割 」ノートブックを選択して 、「編集」 を選択します。
- セットアップセクションを完了します。
- 最初のセルでライブラリをインポートするには、 実行アイコン
 をクリックします。
をクリックします。 - 必要なAPIキーを取得する:
- TheNewsAPIのリンクからアカウントとAPIキーを作成してください。
- API キーを
thenewsapi_key変数に貼り付けます。 - ArticlExtractor でアカウントとAPIキーを作成するリンクに従ってください。
- API キーを
extract_key変数に貼り付けます。
- セルを実行して2つのAPIキー変数を設定する。
- 最初のセルでライブラリをインポートするには、 実行アイコン
- ニュース記事のURLを取得する関数を定義するセクションでセルを実行する。
- このセクションの最初のセルでは、 TheNewsAPI's トップ記事からデータを取得する関数を定義し、関連ニュースを取得できるようにパラメータを設定します。
- このセクションの2番目のセルでは、応答に基づいてURLのリストを取得する関数を定義します。
- ニューステキストを抽出する関数を定義するセクションでセルを実行する。
- 最初のセルでは、 ArticlExtractor API を使用して特定のニュース URL からニュースのテキストを抽出する関数を定義します。
- 2番目のセルは、TheNewsAPIから取得したすべての記事URLからニューステキストを結合する関数を定義している。
- ニューステキストをチャンクする関数を定義するセクションでセルを実行する。
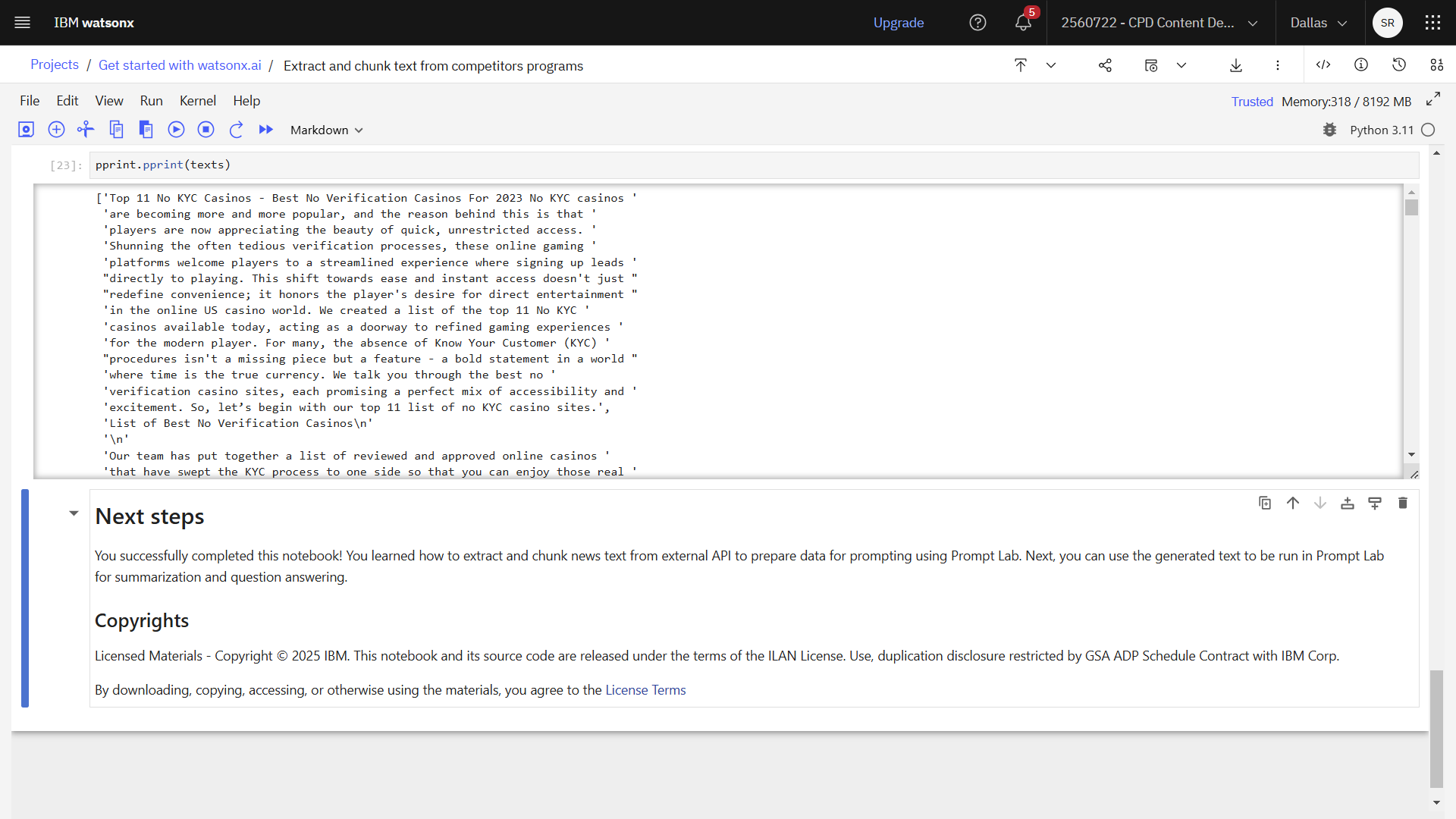
- このセクションの最初のセルでは、ニューステキストのコンテクストを考慮して文字テキストを分割するために、 LangChain を使用する関数を定義しています。 foundation model がテキストから情報を取得できるようにするには、トークンがコンテキストトークンウィンドウの制限を超えないようにする必要があります。
- このセクションの2番目のセルには、応答が表示されています。 データの最終出力は、 Prompt Lab に送られる準備ができていることがわかります。 LangChain’sテキストスプリッタは、長いテキストを意味的に意味のある塊(センテンス)に分割し、それらを再び全体のテキストとして結合して処理します。 チャンクの最大サイズを調整できる。
進捗状況を確認する
次の画像は完成したノートブックです。 foundation model を促すために使用するチャンク化されたテキストが用意できました。
タスク6:プロンプトを表示する foundation model
関連するニュース記事を適切に分割したので、 Prompt Lab で独自のプロンプトテンプレートを作成するか、サンプルプロジェクトのサンプルプロンプトテンプレートを使用することができます。 このサンプルプロジェクトには、要約や質問に答えるタスクのためのサンプルプロンプトテンプレートが含まれています。 Prompt Lab で foundation model を表示するには、以下の手順に従ってください
タスク 6a: 要約タスク
このタスクのプレビューを見るには、 9分32秒から始まるビデオをご覧ください。
まず、要約プロンプトテンプレートをお試しください。
プロジェクトの 資産 タブに戻ります。
銀行プロモーションの要約プロンプトテンプレートをクリックします。 これにより、 Prompt Lab でプロンプトテンプレートが開きます。
Editをクリックすると、プロンプトテンプレートが編集モードで開きます。
要約作業では、チャンク化されたニュース記事のテキストを入力例として使用し、マーケティング担当者が通常、販促オファーを説明する内容を手動で作成することを出力例として示します。 これは、マーケティングチームが自ら書くであろう内容に近いアウトプットを確保するためです。
このプロンプトで使用されている foundation model は XX であることに注意してください。
Generateをクリックすると、要約結果が表示されます。
ノートブックのチャンクされたニュース記事から、さまざまな入力と出力のテキストを試す。
タスク 6b: 質問応答タスク
このタスクのプレビューを見るには、 10:15 から始まるビデオをご覧ください。
次に、質問応答プロンプトテンプレートをお試しください。
保存したプロンプトをクリックすると、
 プロジェクトから保存したプロンプトを確認できます。
プロジェクトから保存したプロンプトを確認できます。保存したプロンプトのリストから 「Question Answer Bank Promotions」 のプロンプトテンプレートをクリックします。
Editをクリックすると、プロンプトテンプレートが編集モードで開きます。
質問と回答のタスクでは、入力例として質問を使い、出力例として要求される詳細レベルと望ましい形式の回答を使います。
このプロンプトで使用されている foundation model は flan-t5-xxl-11b であることに注意してください。
Generateをクリックすると、要約結果が表示されます。
入力と出力のテキストを変えて実験する。
タスク 6c: モデルパラメータを調整する
このタスクをプレビューするには、 10:37 から始まるビデオをご覧ください。
Prompt Lab では、特定のタスクに合わせてモデルの出力を最適化するために、デコード設定を調整することができます
- デコード
- 貪欲:常に最も確率の高い単語を選択する
- サンプリング:単語選択のばらつきをカスタマイズする
- 反復ペナルティ:どの程度の反復が許されるか
- 停止基準:生成された場合にテキスト生成を停止させる1つ以上の文字列
この柔軟性により高度なカスタマイズが可能となり、モデルがタスクの要件と制約に最適なパラメータで動作するようにすることができます。
Prompt Lab では、タスクがモデルの運用範囲内に収まるようにトークン制限を設定することができます。 この設定により、モデルの技術的限界と応答の包括性のバランスが取れ、タスクの効率的かつ効果的な処理が可能になります。
タスク 6d: ドキュメントとのチャット
このタスクのプレビューを見るには、 10:45 から始まるビデオをご覧ください。
また、 チャット モードを使用して、事実を記載したサンプルPDF文書を使用して foundation model を促すこともできます。 1つまたは複数のドキュメントを追加すると、 foundation model が質問に回答するために使用するインメモリベクトルインデックスが作成されます。
- 「新規」 をクリックします。
- チャットをクリックします。
- オプション:モデルを選択します。例えば、 llama-3-1-8b-instruct。
- 「アップロード」 アイコン
 をクリックし 、「ドキュメントを追加」 を選択します。
をクリックし 、「ドキュメントを追加」 を選択します。 - プロジェクトから選択をクリックします。
- Bank CD Rates.pdf を選択します。
- 「選択」をクリックします。
- Back on the Ground gen AI with vectorized documents ページに戻り、名前を確認して 、Create をクリックします。
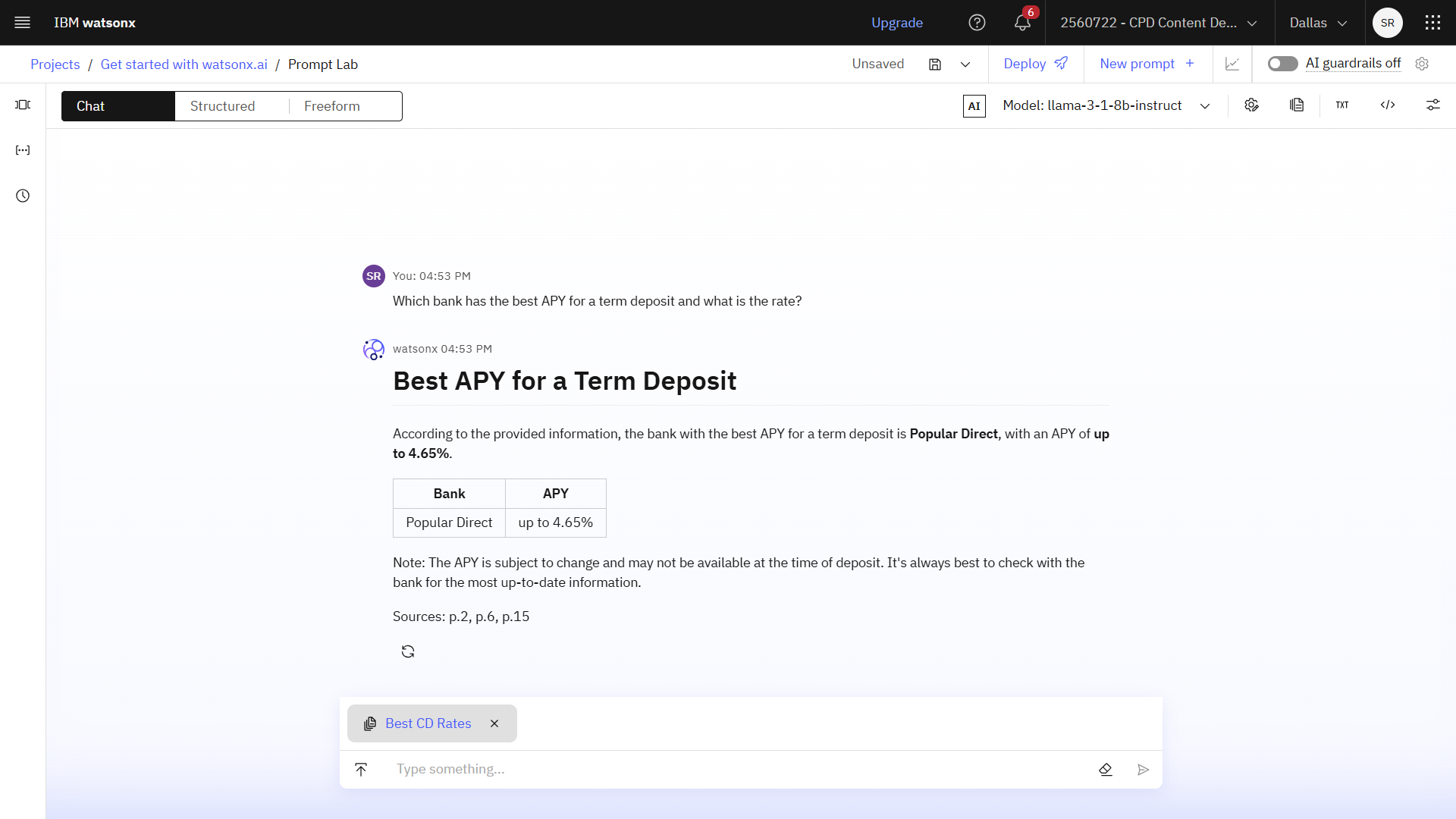
- 「何かを入力」の欄に
Which bank has the best APY for a term deposit and what is the rate?と入力し 、「送信」アイコン をクリックすると、回答が表示されます。
をクリックすると、回答が表示されます。
進捗状況を確認する
次の画像は Prompt Lab を示しています。
今後のステップ
プロンプト・ノートを使ってみる
Prompt Lab から、ノートブック形式で作業内容を保存できます
- 保存したプロンプトテンプレートをロードする。
- Save work > Save asをクリックします。
- 標準のノートパソコンを選択します。 また、AIサービスとしてデプロイできるデプロイメントとして作業内容を保存することもできます。
- 名前を入力します。
- 保存をクリックし、プロンプトノートブックを検索します。
- もう一方のプロンプトテンプレートについても、この手順を繰り返します。
調整する foundation model
foundation model を調整して、プロンプトエンジニアリングのみの場合と比較してモデルのパフォーマンスを向上させたり、より大きなモデルと同等のパフォーマンスを発揮するより小さなモデルを展開してコストを削減したりすることができます。 調整する foundation model のチュートリアルをご覧ください。
迅速なパフォーマンスを比較する
複数のプロンプトを比較するには、Evaluation Studio を使用するとよいでしょう。 Evaluation Studio を使用すると、生成型 AI 資産を、ユースケースに適した定量的な指標とカスタマイズ可能な基準で評価および比較できます。 複数の資産のパフォーマンスを同時に評価し、結果の比較分析を表示して、最適なソリューションを特定します。 プロンプトのパフォーマンスを比較するチュートリアルをご覧ください。
Pipelines を使用してモデルのライフサイクルを自動化する
外部データソースに保存された簡潔で事前処理済みの最新データを配信するためのエンドツーエンドのパイプラインを作成できます。 オーケストレーションパイプラインエディタは、作成からデプロイメントまでの 資産のエンドツーエンドのフローをオーケストレーションするためのグラフィカルインターフェースを提供します。 機械学習モデルおよび Python スクリプトを作成、トレーニング、デプロイ、および更新するためのパイプラインをアセンブルおよび構成します。 パイプラインを使用してモデルのライフサイクルを自動化するチュートリアルを参照してください。
その他のリソース
watsonx.ai:でより実践的な経験を積むために、以下の追加チュートリアルを試してみてください
もっとビデオを見る.
リソースハブでサンプルデータセット、プロジェクト、モデル、プロンプト、ノートブックを見つけ、実践的な経験を積んでください
 プロジェクトに追加して、データの分析とモデルの構築を開始できるノートブック。
プロジェクトに追加して、データの分析とモデルの構築を開始できるノートブック。 プロジェクト that you can import containing notebooks, data sets, prompts, and other assets.
プロジェクト that you can import containing notebooks, data sets, prompts, and other assets. プロジェクトに追加して、モデルの改良、分析、構築を行うことができるデータセット。
プロジェクトに追加して、モデルの改良、分析、構築を行うことができるデータセット。 プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。
プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。プロンプト・ラボで使用できる
 基盤モデル 。
基盤モデル 。
親トピック: クイック・スタート・チュートリアル