Data Virtualizationを使用して仮想テーブルを作成し、1 つまたは複数のテーブルからデータを分割または結合できます。 Data Virtualization は、複数のデータ・ソースを連結して、データ・ソースまたはデータベースの単一の自己平衡コレクションにします。 Data Virtualizationツールについて読んだ後、ビデオを見て、データの仮想化についてある程度の知識があり、コーディングを必要としないユーザーに適したチュートリアルを受けてください。
- 必要なサービス
- Data Virtualization
- オプションのサービス
- watsonx.aiスタジオ
- IBM Knowledge Catalog
基本的なワークフローには、以下のタスクが含まれます:
- サービスをプロビジョンし、サービス資格情報を作成します。
- 複数のデータ・ソースにデータベースを作成し、データベースの詳細と資格情報を収集します。
- データ・ソースに接続を追加します。
- すべてのデータ・ソースからのデータを結合して、仮想オブジェクトを作成します。
- 仮想オブジェクトへのアクセスを管理します。
- 仮想化されたデータをカタログおよびプロジェクトに追加します。
- IBM Db2 Data Management Consoleを使用してサービス・インスタンスをモニターします。
Data Virtualizationについて読む
Data Virtualizationサービスでは、複数のデータソースに接続し、仮想資産を作成して管理し、仮想化されたデータを利用することができます。
- 接続: まず、データ・ソースに接続します。 複数のデータ・ソースに接続することができます。 詳細については、「 Data Virtualizationでデータソースに接続する」および「 Data Virtualizationでサポートされるデータソース」を参照してください。
- 結合、作成、および管理: 次に、仮想表を作成し、スキーマによって表をグループ化し、データをプロジェクトに関連付け、仮想資産を管理します。 詳細は「仮想化オブジェクトの作成」と「Data Virtualization仮想データを管理する 参照。
- コンシューム: 最後に、プロジェクト、データ・カタログ、およびその他のアプリケーションで仮想表をコンシュームします。 詳しくは、「 データの分析とモデルの作成」を参照してください。
Data Virtualizationについてのビデオを見る
 このビデオでは、Data Virtualizationサービスを使用してプロジェクトまたはカタログにデータを仮想化する方法を紹介します。
このビデオでは、Data Virtualizationサービスを使用してプロジェクトまたはカタログにデータを仮想化する方法を紹介します。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
データを仮想化するチュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
- タスク 1: プロジェクトを開きます。
- 作業 2: 必要なサービスをプロビジョンする。
- タスク 3: Db2 Warehouse データ・ソースへの接続を追加します。
- タスク 4: 仮想化データに表を追加します。
- タスク 5: 仮想化データをカタログまたはプロジェクトに公開する。
このチュートリアルを完了するための所要時間は約 30 分です。
このチュートリアルを完了するためのヒント
このチュートリアルを正常に完了するためのヒントを以下に示します。
ビデオ・ピクチャー・イン・ピクチャーの使用
以下のアニメーション・イメージは、ビデオ・ピクチャー・イン・ピクチャーおよび目次機能の使用方法を示しています。

コミュニティーでのヘルプの利用
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザー・ウィンドウのセットアップ
このチュートリアルを最適に実行するには、1 つのブラウザー・ウィンドウで Cloud Pak for Data を開き、このチュートリアル・ページを別のブラウザー・ウィンドウで開いたままにして、2 つのアプリケーションを簡単に切り替えることができます。 2 つのブラウザー・ウィンドウを横並びに配置して、見やすくすることを検討してください。

タスク 1: プロジェクトを開く
このタスクをプレビューするには、00:10から始まるビデオを見てください。
仮想化データを保管するためのプロジェクトが必要です。 以下のステップに従って、既存のプロジェクトを開くか、新規プロジェクトを作成します。
ナビゲーションメニュー「
 」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択する
」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択する既存のプロジェクトをを持っている場合は、それを開きます。
既存のプロジェクトがない場合は、 「新規プロジェクト」をクリックします。
「空のプロジェクトの作成」を選択します。
プロジェクトの名前と説明 (オプション) を入力します。
既存の オブジェクト・ストレージ・サービス・インスタンス を選択するか、または新規作成します。
「作成」 をクリックします。
詳細またはビデオについては、プロジェクトの作成をご覧ください。
 進捗状況を確認する
進捗状況を確認する
以下の画像は、新しい空のプロジェクトを示しています。
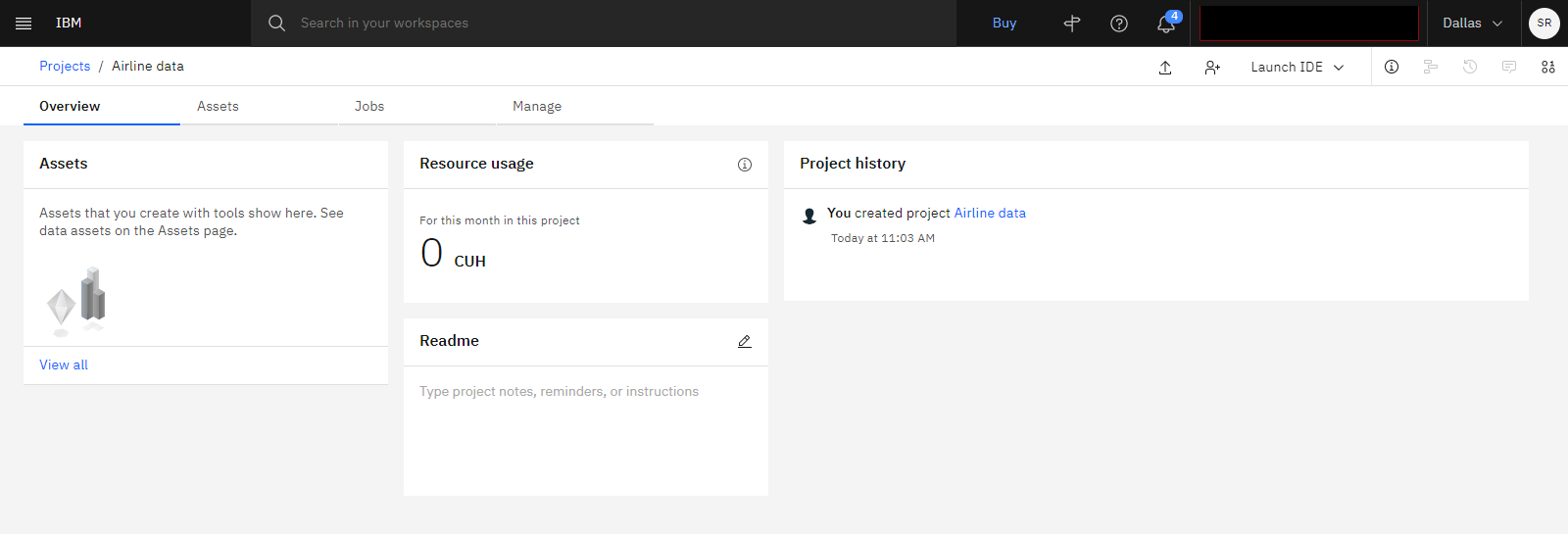
タスク 2: 必要なサービスのプロビジョン
このタスクをプレビューするには、00:32から始まるビデオを見てください。
このチュートリアルでは、Data Virtualizationサービスと、オプションのサービスwatsonx.aiStudio およびIBM Knowledge Catalog が必要です。 以下の手順に従って、これらのサービスを作成します。
ナビゲーションメニュー「
」から、「サービス」>「サービスインスタンス」をクリックする。Data Virtualizationサービスがリストアップされていれば、別のインスタンスをプロビジョニングする必要はない。 そうでない場合は、以下のステップに従ってください。
「サービスの追加」をクリックします。
Data Virtualizationを選択します。
Data Virtualization化のライトプランを選択する。
「作成」 をクリックします。
サービス・インスタンス ページでサービスがプロビジョンされていることを確認します。
詳細は、 Cloud Pak for Data as a ServiceにおけるData Virtualization化を参照。
進捗状況を確認する
以下のイメージは、プロビジョンされたサービスを示しています。
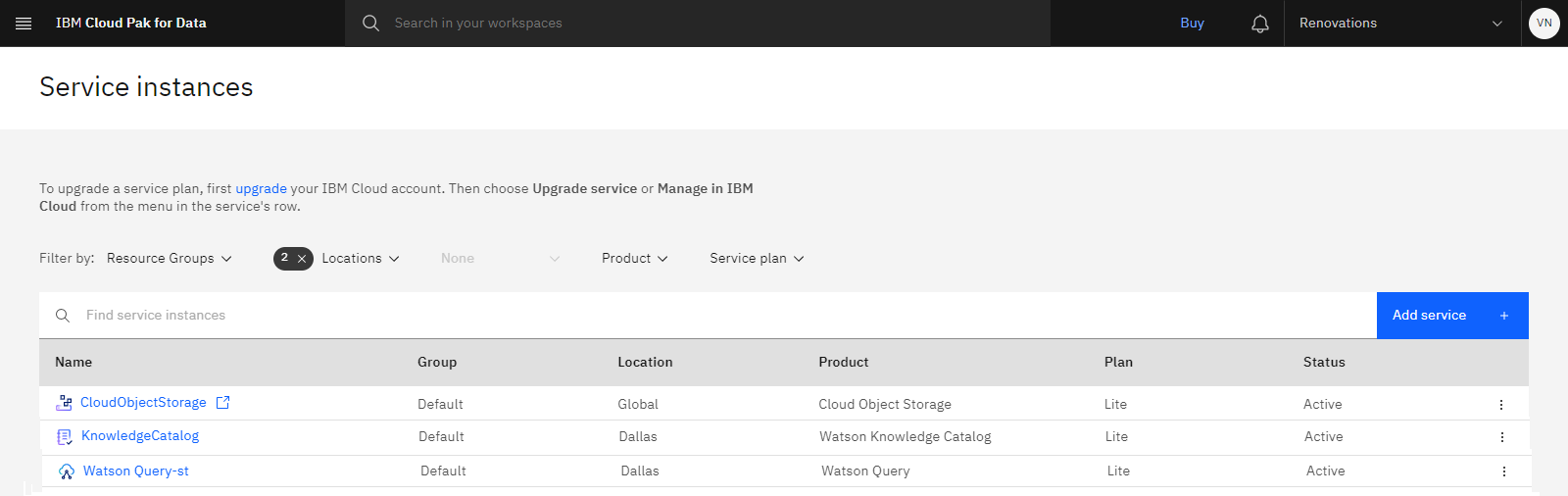
タスク 3: Db2 Warehouse データ・ソースへの接続の追加
このタスクをプレビューするには、00:58から始まるビデオを見てください。
データを仮想化する前に、データ・ソースへの接続を作成する必要があります。 Data Virtualizationで接続を作成するには、以下の手順を実行します。
ナビゲーションメニュー「
」から、「データ」>「Data virtualization」を選択する。 構成された データ・ソース のリストが表示されます。接続の追加 > 新規接続をクリックしてください。
Db2 Warehouse on Cloudを選択し、 「選択」をクリックします。
以下の情報を使用して、接続の詳細を入力します。
- 名前:
Db2 Warehouse - データベース:
BLUDB - ホスト名または IP アドレス:
db2w-ruggyab.us-south.db2w.cloud.ibm.com - ポート:
50001 - ユーザー名:
CPDEMO - Password:
DataFabric@2022IBM - 「ポートは SSL 対応 (Port is SSL-enabled)」 チェック・ボックスを選択します。
- 名前:
「テスト」をクリックします。
「作成」 をクリックします。
詳細については、 Data Virtualization化のデータソースへの接続を参照してください。
進捗状況を確認する
以下の画像は、「データ・ソース」ページを示しています。
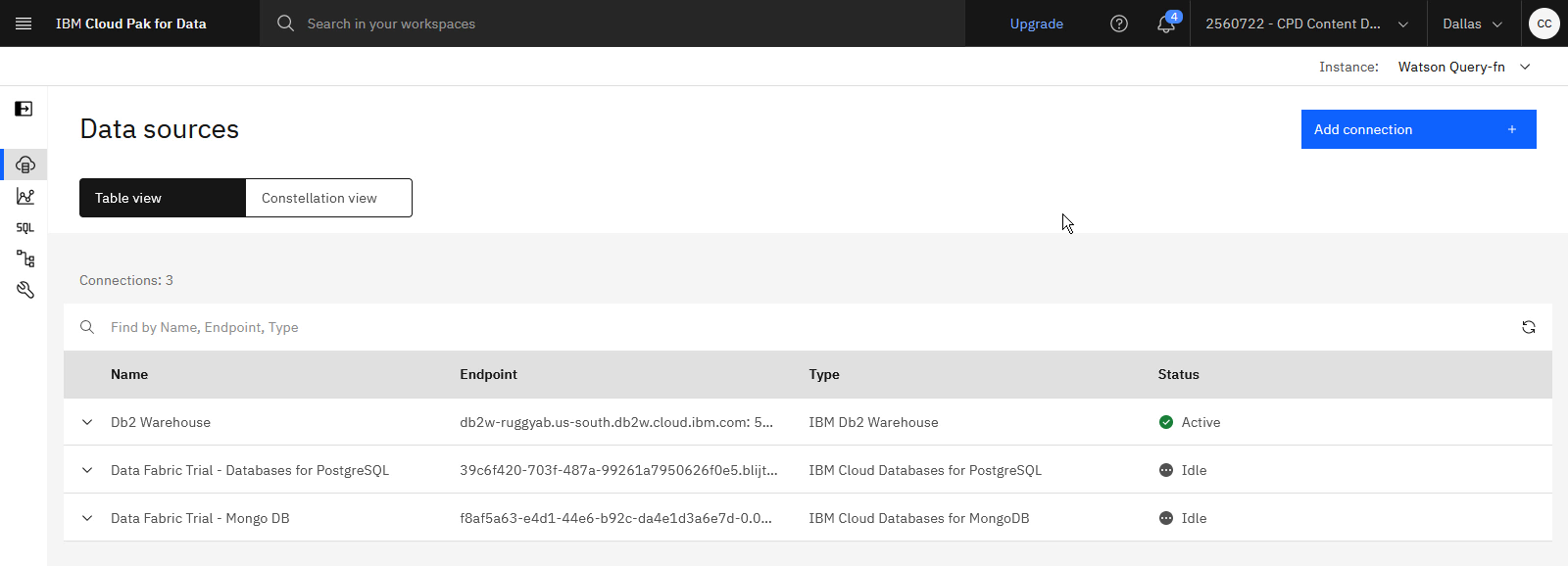
タスク 4: 仮想化データへの表の追加
このタスクをプレビューするには、01:45から始まるビデオを見てください。
接続を定義すると、そのデータ・ソースからのデータを仮想化できます。 以下のステップに従って、仮想化データに表を追加します。
Data Virtualization メニューから、 「仮想化」>「仮想化」を選択し、使用可能な表がロードされるのを待ちます。
リストから 顧客 表と 営業 表を見つけて選択し、 カートに追加をクリックしてください。
カートの表示をクリックしてください。
「プロジェクトに割り当て」 フィールドをクリアします。 これにより、2 つの表が仮想化データのリストに追加されますが、プロジェクトには追加されません。 後で、仮想化データをプロジェクトに追加します。
仮想化をクリックしてください。
「確認 (Confirm)」をクリックします。
「仮想化データに移動」をクリックします。
詳細については、 Data Virtualization化の仮想オブジェクトの作成を参照してください。
進捗状況を確認する
以下の画像は、「マイ仮想化データ」ページを示しています。
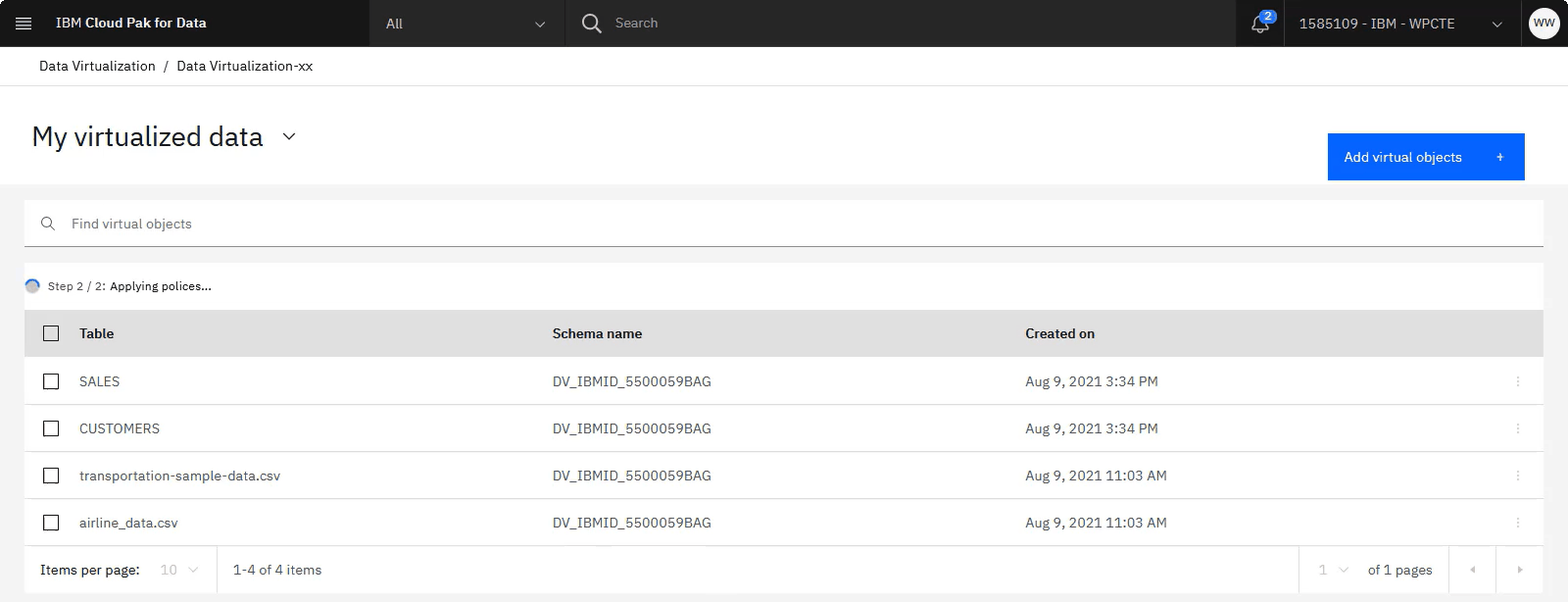
タスク 5: カタログおよびプロジェクトへの仮想化データの公開
このタスクをプレビューするには、 02:43から始まるビデオをご覧ください。
次に、以下の手順に従って 2 つの表を結合し、仮想化資産を作成してカタログとプロジェクトに公開します。
仮想化データ 画面で、リストから 顧客 表と 営業 表を選択し、 参加をクリックしてください。
表ごとに、
salesrepを検索します。2 つの表の SALESREP_ID 列に接続します。
次へ をクリックします。
結合された表を確認し、 次へをクリックしてください。
ビュー名の場合、
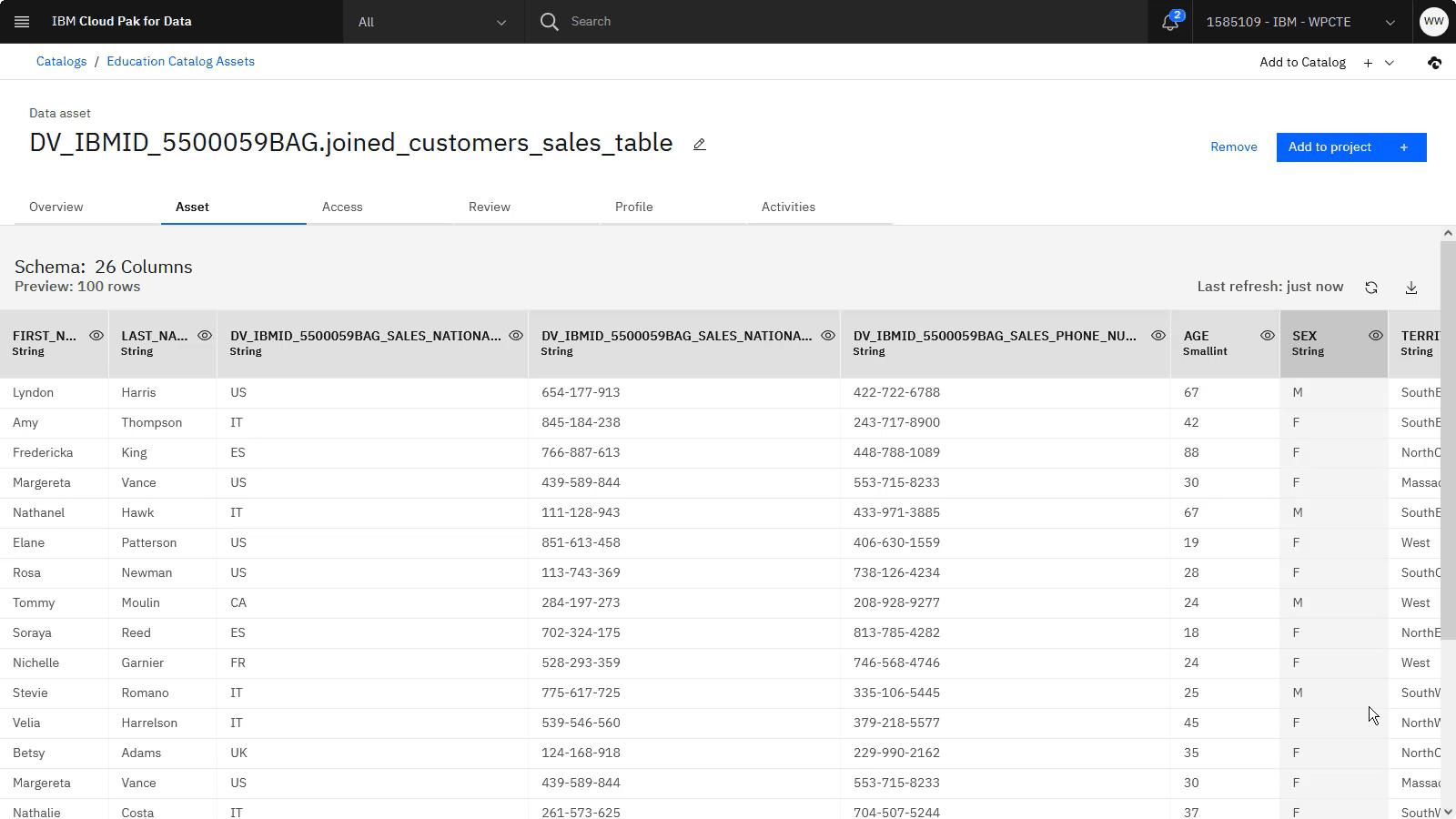
joined_customers_sales_tableと入力します。リストからプロジェクトを選択します。
カタログに公開 オプションにチェックして、カタログを選択します。
「ビューの作成」をクリックします。
プロセスが完了したら、プロジェクトまたはカタログを閲覧して、仮想化データをプレビューできます。 プロジェクトまたはカタログ内のデータを表示するには、 IBM Cloud API キーが必要です。 IBM CloudAPI キーの作成」を参照してください。
詳細については、 Data Virtualizationにおける仮想データの管理を参照してください。
進捗状況を確認する
以下の図は、カタログ内の仮想化データ資産を示しています。
次のステップ
これで、仮想データを使用する準備ができました。 例えば、以下のいずれかのタスクを実行できます:
その他のリソース
詳しくは、 ビデオを参照してください。
Resource hubでサンプルデータセットを検索できます。
この追加チュートリアルを試して、'Data Virtualization: 'Data Virtualizationを'IBM Cloud Pak for Dataに '
 .
.
親トピック: クイック・スタート・チュートリアル