DataStage フローを使用して、さまざまなデータ・ソースからのデータを簡単に統合、クレンジング、および分析できます。 DataStage ツールについて読み、ビデオを見て、データ変換に関する知識はあるがコーディングは必要ないユーザーに適したチュートリアルを学習します。
- 必須のサービス
- watsonx.aiスタジオ
- DataStage
基本的なワークフローには、以下のタスクが含まれます:
- プロジェクトを作成する プロジェクトは、データを処理するために他のユーザーと共同作業できる場所です。
- データをプロジェクトに追加します。 接続を介してリモート・データ・ソースからの CSV ファイルまたはデータを追加できます。
- DataStage フローを作成します。
- 操作を使用してデータを詳細化するステップを実行します。
- データを変換するジョブを作成して実行します。
DataStage について読む
DataStage は、プロジェクト内のデータを変換および統合するために使用できる抽出、変換、およびロード (ETL) ツールです。
DataStageは使いやすく設計されており、プラットフォームに完全に統合されている。 ISX ファイルを使用して既存のレガシー・パラレル・ジョブを DataStage にインポートし、 DataStage キャンバスを使用してフローを作成、編集、およびテストし、フローから生成されたジョブを実行することができます。
DataStage フローを使用してデータの変換に関するビデオをご覧ください
 このビデオを見て、単純な DataStage フローを作成する方法を確認してください。
このビデオを見て、単純な DataStage フローを作成する方法を確認してください。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
データ変換のチュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
- タスク 1: プロジェクトを開きます。
- タスク 2: データ・セットをプロジェクトに追加します。
- タスク 3: DataStage フローを作成します。
- タスク 4: ノードの編集
- タスク 5: DataStage フローを実行して、資産を表示します。
このチュートリアルを完了するための所要時間は約 20 分です。
このチュートリアルを完了するためのヒント
このチュートリアルを正常に完了するためのヒントを以下に示します。
ビデオ・ピクチャー・イン・ピクチャーの使用
以下のアニメーション・イメージは、ビデオ・ピクチャー・イン・ピクチャーおよび目次機能の使用方法を示しています。

コミュニティーでのヘルプの利用
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザー・ウィンドウのセットアップ
このチュートリアルを最適に実行するには、1 つのブラウザー・ウィンドウで Cloud Pak for Data を開き、このチュートリアル・ページを別のブラウザー・ウィンドウで開いたままにして、2 つのアプリケーションを簡単に切り替えることができます。 2 つのブラウザー・ウィンドウを横並びに配置して、見やすくすることを検討してください。

タスク 1: プロジェクトを開く
データ・セットと DataStage フローを保管するためのプロジェクトが必要であり、 DataStage サービスをプロビジョンする必要があります。 既存のプロジェクトを開くか、新規プロジェクトを作成してサービスをプロビジョンするには、以下の手順を実行します。
ナビゲーションメニュー「
 」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択する
」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択する既存のプロジェクトをを持っている場合は、それを開きます。
既存のプロジェクトがない場合は、 「新規プロジェクト」をクリックします。
「空のプロジェクトの作成」を選択します。
プロジェクトの名前と説明 (オプション) を入力します。
「作成」 をクリックします。
ナビゲーションメニュー「
」から、「サービス」>「サービスインスタンス」をクリックする。サービスの追加 をクリックし、 DataStageを選択してください。
「作成」 をクリックします。 プロビジョンされたサービスが サービス・インスタンス ページに表示されます。
詳細またはビデオについては、プロジェクトの作成をご覧ください。
 進捗状況を確認する
進捗状況を確認する
以下のイメージは、プロビジョンされたサービスを示しています。
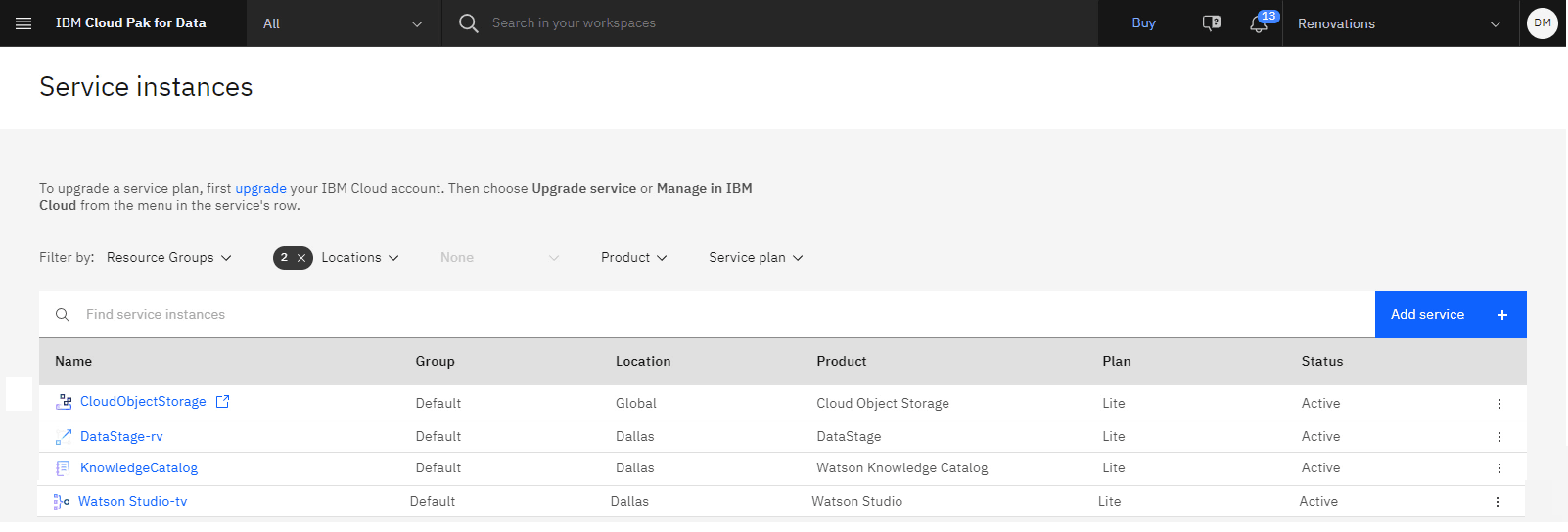
タスク 2: プロジェクトへのデータ・セットの追加
このチュートリアルで使用するデータ・セットは、リソース・ハブで使用できます。 リソース・ハブでデータ・セットを見つけてプロジェクトに追加するには、以下の手順を実行します。
Resource ハブのCustomers データセットにアクセスします。
プロジェクトに追加をクリックしてください。
リストからプロジェクトを選択し、 追加をクリックしてください。
データ・セットが追加されたら、 プロジェクトの表示をクリックしてください。
リソース・ハブからプロジェクトへのデータ資産の追加について詳しくは、 ノートブックでのデータのロードおよびアクセスを参照してください。
進捗状況を確認する
以下の画像は、プロジェクトの「資産」タブを示しています。
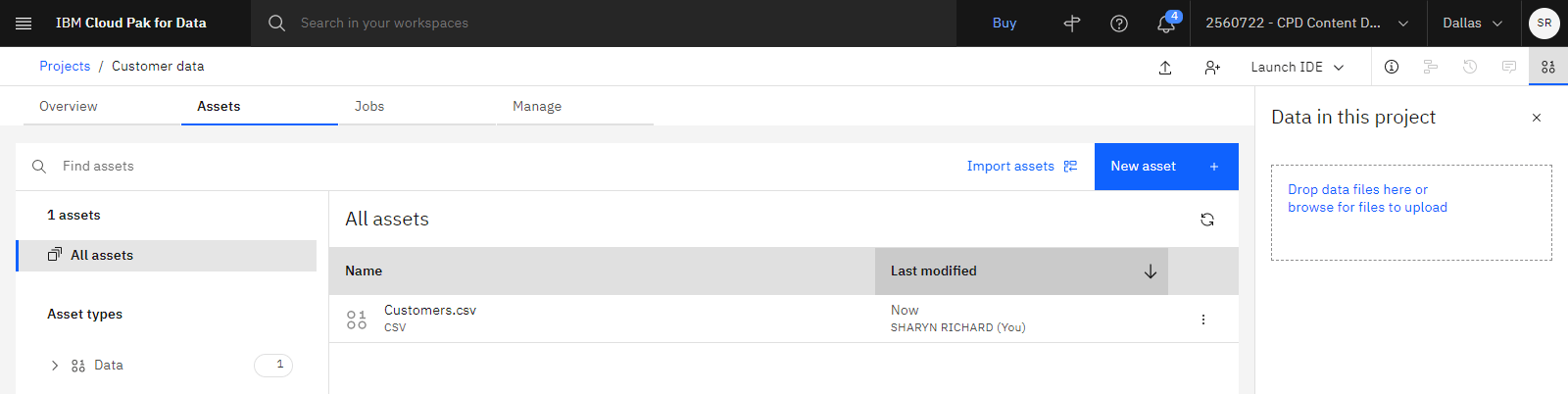
タスク 3: DataStage フローの作成
このタスクをプレビューするには、00:26から始まるビデオを見てください。
DataStage フローには、元のデータ資産、フィルター・ノード、ソート・ノード、および変換されたデータ資産の 4 つのノードが含まれます。 DataStage フローを作成するには、以下の手順を実行します。
クリック新しい資産 > データの変換と統合。
名前と説明を提供し、 作成をクリックしてください。
コネクター をクリックし、 アセット・ブラウザー ノードをキャンバスにドラッグ・アンド・ドロップします。
データ資産 > customers.csvを選択し、 追加をクリックしてください。
ノード・パレットで、 段階 セクションを展開し、 フィルター ノードをキャンバスにドラッグします。
ノードをリンクするには、 Customers.csv ノードの青い矢印をクリックして 「フィルター」 ノードにドラッグします。
段階 セクションで、 ソート ノードをキャンバスにドラッグします。
フィルター ノードを ソート ノードに接続します。
コネクター セクションを展開し、 アセット・ブラウザー ノードをキャンバスにドラッグします。
データ資産 > customers.csvを選択し、 追加をクリックしてください。 後でファイル名を変更して、customer.csv ファイルを上書きしないようにします。
「ソート」 ノードをこの最後の Customers.csv ノードに接続します。
進捗状況を確認する
次の画像は、最初のフローを示している。
'
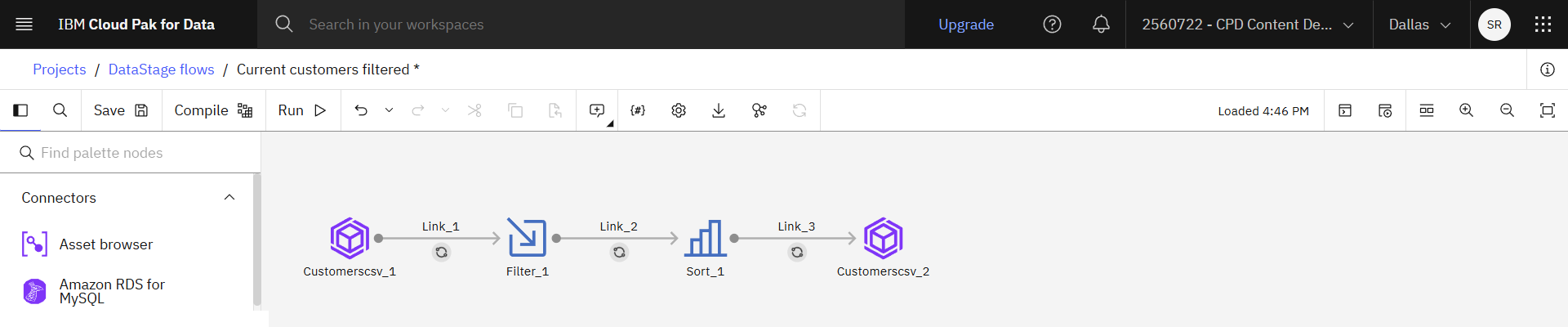
タスク 4: ノードの編集
このタスクをプレビューするには、03:27から始まるビデオをご覧ください。
キャンバス上の各ノードのプロパティーを編集するには、以下の手順を実行します。
ノード 1: 最初の資産ブラウザー・ノードの編集
最初の Customer.csv ノードをダブルクリックします。
右側の 「プロパティー」 パネルで、ノードの名前を
CustomerTableに変更して、資産ノードの名前を変更します。「出力」 タブをクリックします。
カラム セクションを展開し、 編集をクリックしてください。
YTD_ SALES列のデータ型を変更するには、Data typeで DECIMALを選択します。
適用して戻る をクリックして、「プロパティー」パネルに戻ります。
保存 をクリックして、 顧客テーブル ノードに対する変更を保存します。
ノード 2: フィルター・ノードの編集
フィルター ノードをダブルクリックしてください。
プロパティー パネルで、テキスト
Filter_1をFilterYTDSalesに名前変更して、フィルター・ノードの名前を変更します。プロパティー セクションを展開します。 述部の下で、 編集をクリックしてください。
「Where 文節」 列で、
YTD_SALES > 1000と入力します。「適用して戻る」をクリックします。
「出力」 タブをクリックします。
カラム セクションを展開し、 編集をクリックしてください。
すべての列を選択し、このチュートリアルで使用する以下の列の選択を解除する。
- CUST_ID
- CUSTNAME
- COUNTRY_CODE
- EMAIL_ADDRESS
- PHONE_NUMBER
- YTD_SALES
- SALESREP_ID
選択した行の削除アイコン「
 」をクリックして、残りの選択した列を削除する。
」をクリックして、残りの選択した列を削除する。CUSTNAME 列の名前を
CUSTOMERNAMEに変更します。 この変更は、 フィルター ノードの後に続くノードに伝搬されます。適用して戻る をクリックして、「プロパティー」パネルに戻ります。
保存 をクリックして、 フィルター ノードに対する変更を保存します。
ノード 3: ソート・ノードの編集
ソート ノードをダブルクリックしてください。
プロパティー パネルで、テキスト
Sort_1をSortYTDSalesに名前変更して、ソート・ノードの名前を変更します。プロパティー セクションを展開します。
Sorting Keys」の下にある「Add key」をクリックする。
「鍵の追加」をクリックします。
キー ドロップダウンから、 YTD_SALESを選択してください。
ソート順の場合は、 降順を選択してください。
適用 をクリックして、ソート・キー・リストに戻ります。
適用して戻る をクリックして、「プロパティー」パネルに戻ります。
「入力」 タブをクリックし、 「列」 セクションを展開して、 CUSTOMERNAME 列名の変更が 「フィルター」 ノードから伝搬されていることを確認します。
「出力」 タブをクリックし、 「列」 セクションを展開して、 CUSTOMERNAME 列名の変更が 「フィルター」 ノードから伝搬されていることを確認します。
保存 をクリックして、 ソート ノードに対する変更を保存します。
ノード 4: 最後の資産ブラウザー・ノードの編集
最後の Customers.csv ノードをダブルクリックします。
「プロパティー」 パネルで、ノードの名前を
CustomerFilteredTableに変更して、資産ノードの名前を変更します。プロパティー セクションを展開し、チェック・ボックス データ資産の作成を選択してください。
データ資産名フィールドに「
Customers filtered入力する。「入力」 タブをクリックし、 「列」 セクションを展開して、 CUSTOMERNAME 列名の変更が 「フィルター」 ノードから伝搬されていることを確認します。
「保存」 をクリックして、 「顧客フィルター・テーブル」 ノードに対する変更を保存します。
進捗状況を確認する
次の画像は、最終的なフローを示している。
'
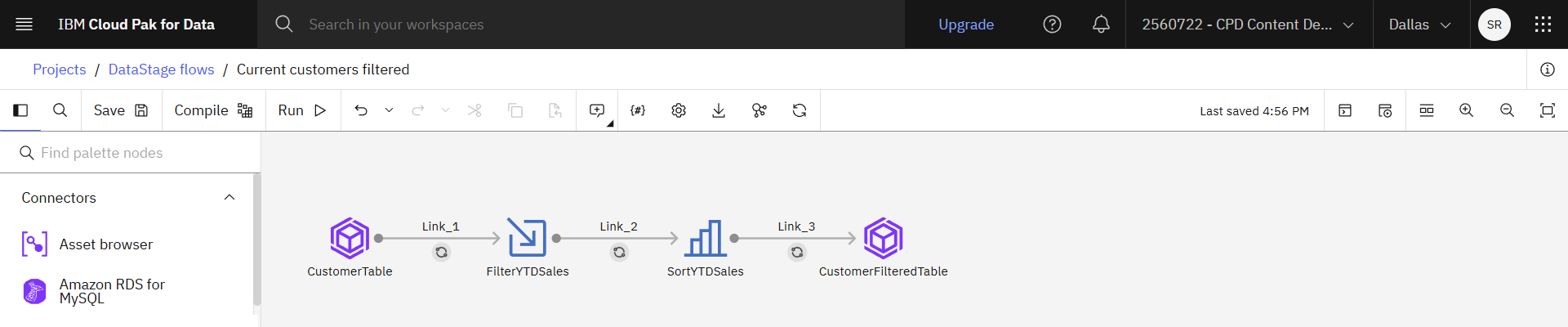
タスク 5: DataStage フローを実行して資産を表示する
このタスクをプレビューするには、06:36から始まるビデオをご覧ください。
これで、フローを実行する準備ができました。 以下のステップに従って、フローを実行し、プロジェクト内の変換された資産を表示します。
保存 をクリックします。
コンパイルをクリックしてください。
「実行 (Run)」 をクリックします。
(オプション) ログ リンクをクリックして、実行の詳細を表示します。
最後の 「顧客フィルター・テーブル」 ノードをダブルクリックします。
プロパティー セクションを展開します。
スクロールダウンして、 データのプレビューをクリックしてください。 データが正しくフィルタリングされ、ソートされていることが分かります。
「グラフ」 パネルをクリックします。
「視覚化する列」で、 「YTD_SALES」を選択します。
「グラフ・タイプ」で、 「Q-Q プロット」をクリックします。
「閉じる」をクリックします。
プロジェクトにデータ資産を作成するようにフローをセットアップしたため、ナビゲーション・トレールでプロジェクト名をクリックして、プロジェクトに戻ります。
「資産」 タブで、 「顧客フィルター」 資産を開きます。
進捗状況を確認する
以下の画像は、フィルタリングされた顧客のデータ資産を示しています。

次のステップ
では、データを使用する準備ができました。 例えば、ユーザーまたは他のユーザーは、以下のいずれかのタスクを実行できます:
その他のリソース
詳しくは、 ビデオを参照してください。
Resource hubでデータの変換を実際に体験できるサンプルデータセットをご覧ください。
サンプルのDataStageプロジェクトから始めましょう:COVID-19 IBM DataStageによるトラッキング。
この追加チュートリアルを試して、'DataStageフローをより実際に体験してください: 新しい'IBM'DataStageサービスを使い始める'
 .
.
親トピック: クイック・スタート・チュートリアル