You can create an end-to-end pipeline to deliver concise, pre-processed, and up-to-date data stored in an external data source. Read about Watson Pipelines, then watch a video and take a tutorial.
Your basic workflow includes these tasks:
- Open your sandbox project. Projects are where you can collaborate with others to work with data.
- Add connections and data to the project. You can add CSV files or data from a remote data source through a connection.
- Create a pipeline in the project.
- Add nodes to the pipeline to perform tasks.
- Run the pipeline and view the results.
Read about pipelines
The Watson Pipelines editor provides a graphical interface for orchestrating an end-to-end flow of assets from creation through deployment. Assemble and configure a pipeline to create, train, deploy, and update machine learning models and Python scripts. Putting a model into production is a multi-step process. Data must be loaded and processed, models must be trained and tuned before they are deployed and tested. Machine learning models require more observation, evaluation, and updating over time to avoid bias or drift.
Watch a video about pipelines
 Watch this video to preview the steps in this tutorial. You might notice slight differences in the user interface that is shown in the video.
The video is intended to be a companion to the written tutorial.
Watch this video to preview the steps in this tutorial. You might notice slight differences in the user interface that is shown in the video.
The video is intended to be a companion to the written tutorial.
This video provides a visual method to learn the concepts and tasks in this documentation.
Try a tutorial to create a model with Pipelines
This tutorial guides you through exploring and running an AI pipeline to build and deploy a model. The model predicts if a customer is likely subscribe to a term deposit based on a marketing campaign.
In this tutorial, you will complete these tasks:
- Task 1: Create a deployment space.
- Task 2: Create the sample pipeline.
- Task 3: Explore an existing pipeline.
- Task 4: Run the pipeline.
- Task 5: View the assets, deployed model, and online deployment.
This tutorial takes approximately 30 minutes to complete.
Sample data
The sample data that is used in the guided experience is UCI: Bank marketing data used to predict whether a customer enrolls in a marketing promotion.

Task 1: Create a deployment space
Deployment spaces help you to organize supporting resources such as input data and environments; deploy models or functions to generate predictions or solutions; and view or edit deployment details. Follow these steps to create a deployment space.
-
From the watsonx navigation menu
 , choose Deployments. If you have an existing deployment
space, you can skip to Task 2.
, choose Deployments. If you have an existing deployment
space, you can skip to Task 2. -
Click New deployment space.
-
Type a name for your deployment space.
-
Select a storage service from the list.
-
Select your provisioned machine learning service from the list.
-
Click Create.
 Check your progress
Check your progress
The following image shows the empty deployment space:
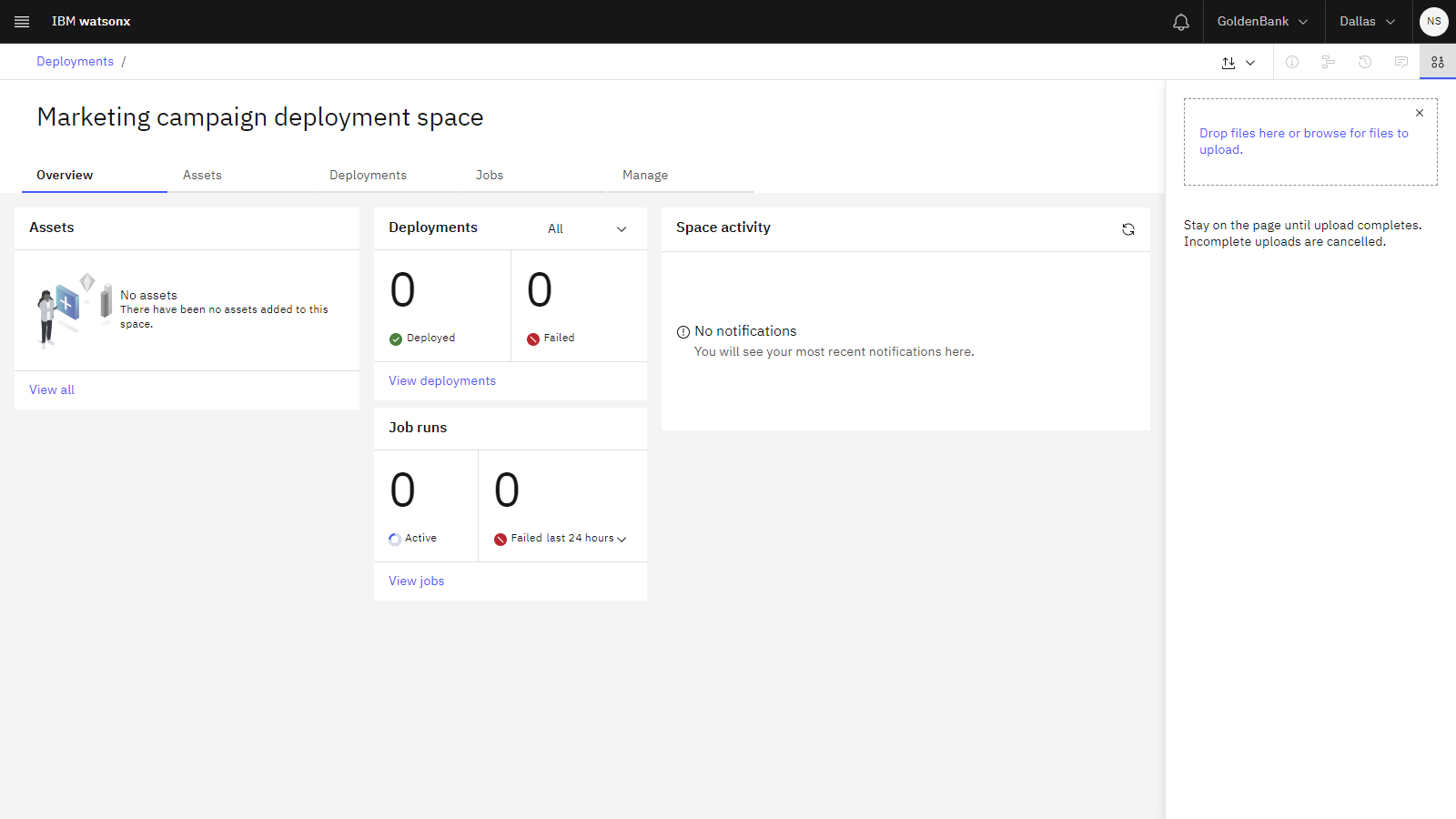
Task 2: Create the sample pipeline
To preview this task, watch the video beginning at 00:08.
You create and run pipelines in a project. Follow these steps to create a pipeline based on a sample in a project:
-
On the watsonx home page, select your sandbox or a different existing project from the drop down list.
-
Click Customize my journey, and then select View all tasks.
-
Select Automate model lifecycle.
-
Click Samples.
-
Select Orchestrate an AutoAI experiment, and click Next.
-
Optional: Change the name for the pipeline.
-
Click Create. The sample pipeline gets training data, trains a machine learning model by using the AutoAI tool, and selects the best pipeline to save as a model. The model is deployed to a space.
Check your progress
The following image shows the sample pipeline.
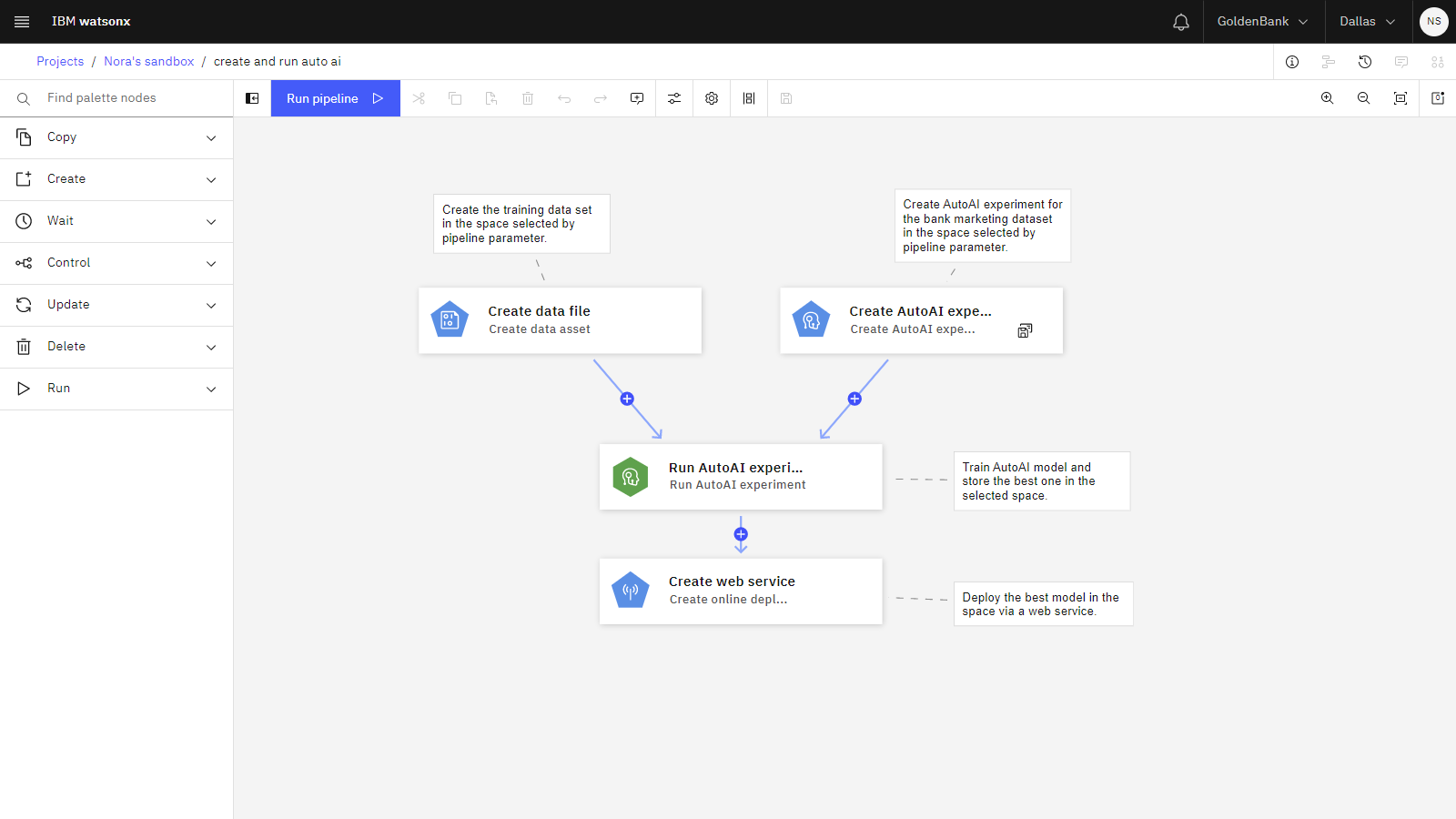
Task 3: Explore the existing pipeline
To preview this task, watch the video beginning at 00:30.
The sample pipeline includes several nodes to create assets and use those assets to build a model. Follow these steps to view the nodes:
-
Click the Global objects
 icon to view the pipeline parameters. Expand the deployment_space parameter. This pipeline includes a parameter to specify a deployment space where the best model from the AutoAI experiment is stored and deployed. Click the X to close the window.
icon to view the pipeline parameters. Expand the deployment_space parameter. This pipeline includes a parameter to specify a deployment space where the best model from the AutoAI experiment is stored and deployed. Click the X to close the window. -
Double-click the Create data file node to see that it is configured to access the data set for the experiment. Click Cancel to close the properties pane.
-
Double-click the Create AutoAI experiment node. View the experiment name, the scope, which is where the experiment is stored, the prediction type (binary classification, multiclass classification, or regression), the prediction column, and positive class. The rest of the parameters are all optional. Click Cancel to close the properties pane.
-
Double-click the Run AutoAI experiment node. This node runs the AutoAI experiment onboarding-bank-marketing-prediction, trains the pipelines, then saves the best model. The first two parameters are required. The first parameter takes the output from the Create AutoAI experiment node as the input to run the experiment. The second parameter takes the output from the Create data file node as the training data input for the experiment. The rest of the parameters are all optional. Click Cancel to close the properties pane.
-
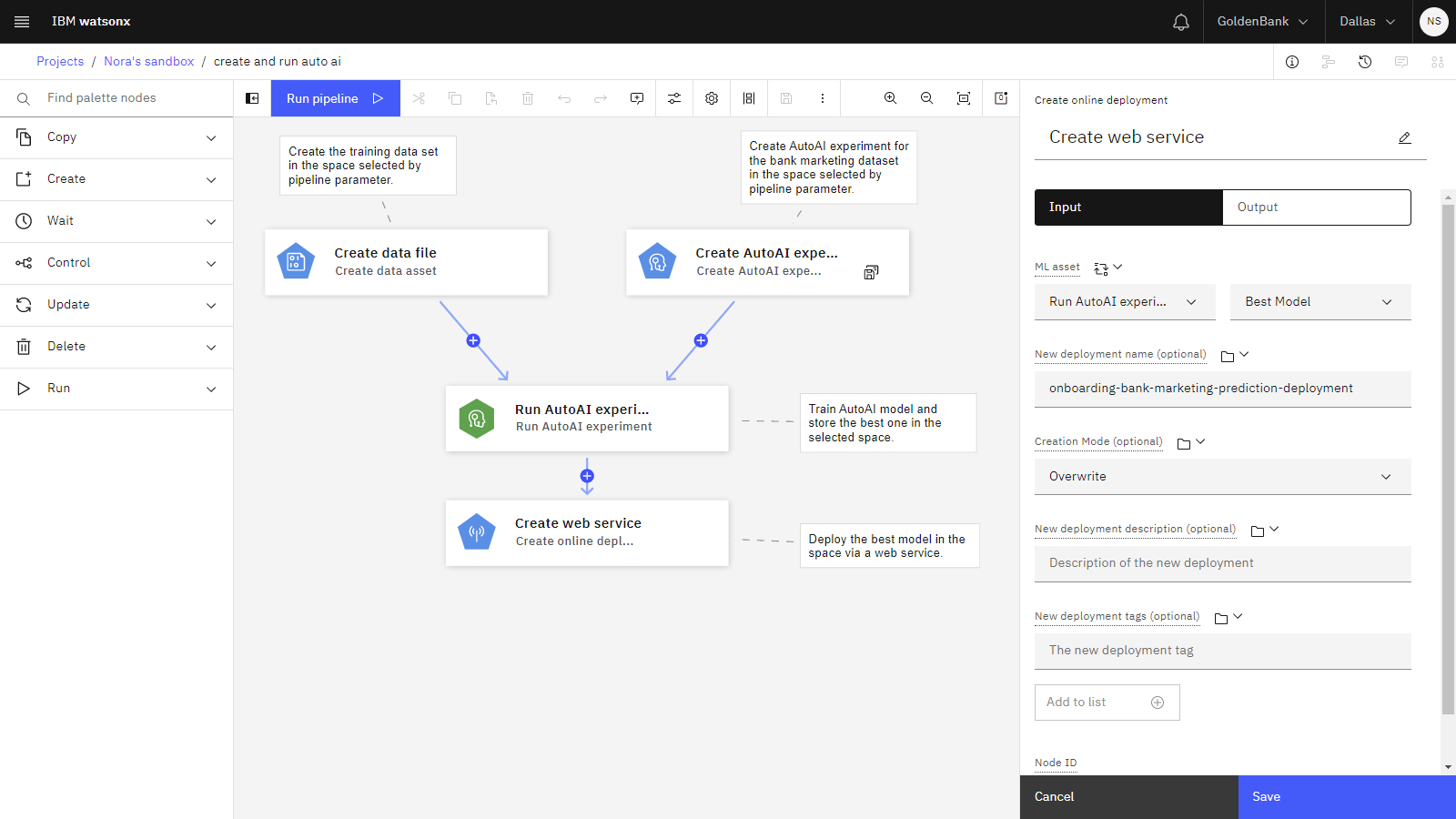
Double-click the Create Web service node. This node creates a deployment with the name
onboarding-bank-marketing-prediction-deployment. The first parameter takes the best model output from the Run AutoAI experiment node as the input to create the deployment with the specified name. The rest of the parameters are all optional. Click Cancel to close the properties pane.
Check your progress
The following image shows the properties for the Create web service node. You are now ready to run the sample pipeline.
Task 4: Run the pipeline
To preview this task, watch the video beginning at 03:43.
Now that the pipeline is complete, follow these steps to run the pipeline:
-
From the toolbar, click Run pipeline > Trial run.
-
In the Values for pipeline parameters section, select your deployment space:
-
Click Select Space.
-
Click Spaces.
-
Select your deployment space from Task 1.
-
Click Choose.
-
-
Provide an API key if this occasion is your first time running a pipeline. Pipeline assets use your personal IBM Cloud API key to run operations securely without disruption.
-
If you have an existing API key, click Use existing API key, paste the API key, and click Save.
-
If you don't have an existing API key, click Generate new API key, provide a name, and click Save. Copy the API key, and then save the API key for future use. When you're done, click Close.
-
-
Click Run to start running the pipeline.
-
Monitor the pipeline progress.
-
Scroll through consolidated logs while the pipeline is running. The trial run might take up to 10 minutes to complete.
-
As each operation completes, select the node for that operation on the canvas.
-
On the Node Inspector tab, view the details of the operation.
-
Click the Node output tab to see a summary of the output for each node operation.
-
Check your progress
The following image shows the pipeline after it completed the trial run. You are now ready to review the assets that the pipeline created.
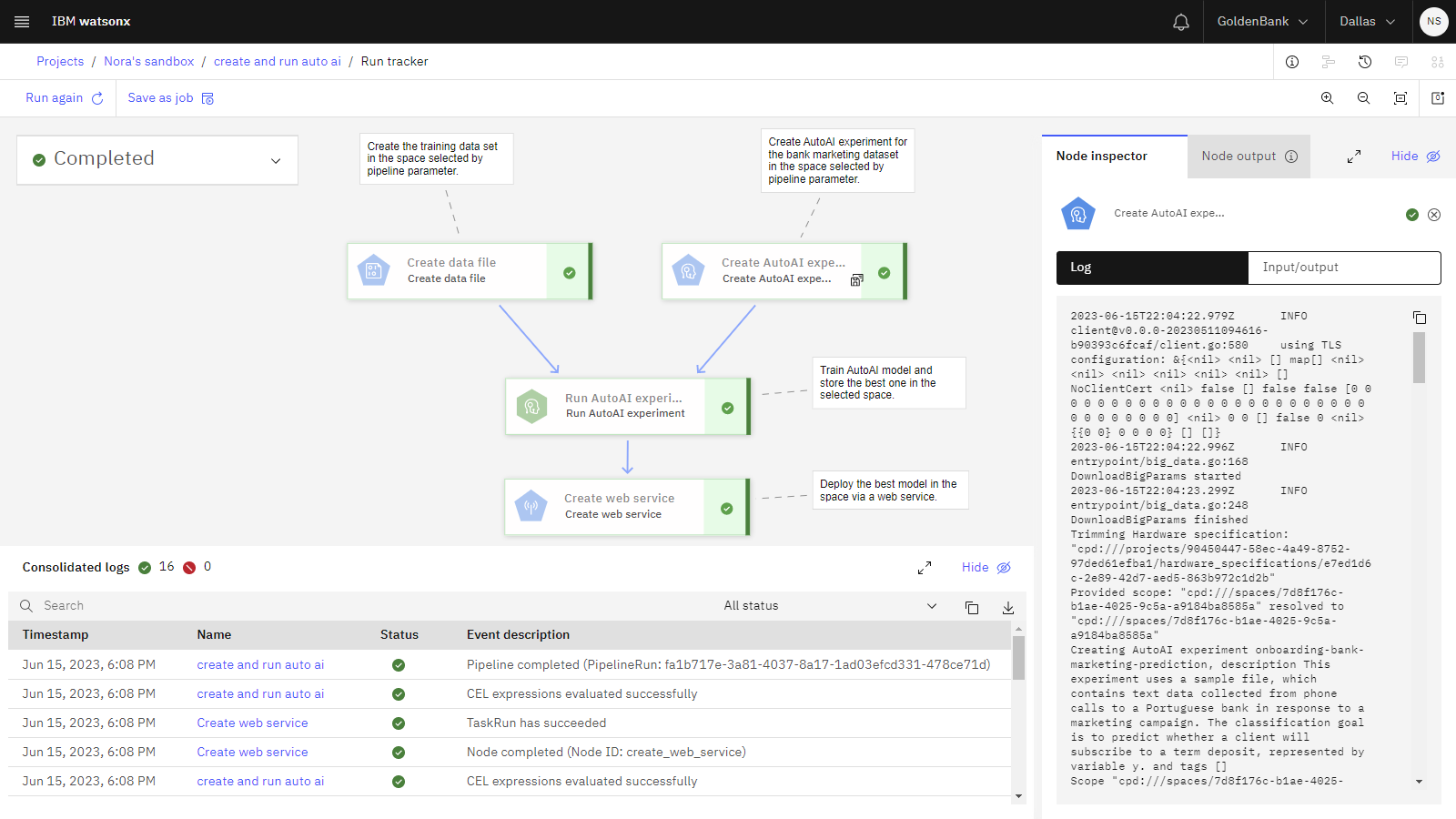
Task 5: View the assets, deployed model, and online deployment
To preview this task, watch the video beginning at 04:27.
The pipeline created several assets in the deployment space. Follow these steps to view the assets:
-
From the watsonx navigation menu
, choose Deployments. -
Click the name for your deployment space.
-
On the Assets tab, view All assets.
-
Click the bank-marketing-data.csv data asset. The Create data file node created this asset.
-
Click the model beginning with the name onboarding-bank-marketing-prediction. The Run AutoAI experiment node generated several model candidates, and chose this as the best model.
-
Click the Model details tab, and scroll through the model and training information.
-
Click the Deployments tab, and open the onboarding-bank-marketing-prediction-deployment.
-
Click the Test tab.
-
Click the JSON input tab, and replace the sample text with the following JSON text.
{ "input_data": [ { "fields": [ "age", "job", "marital", "education", "default", "balance", "housing", "loan", "contact", "day", "month", "duration", "campaign", "pdays", "previous", "poutcome" ], "values": [ [ 35, "management", "married", "tertiary", "no", 0, "yes", "no", "cellular", 1, "jun", 850, 10, -1, 4, "unknown" ] ] } ] } -
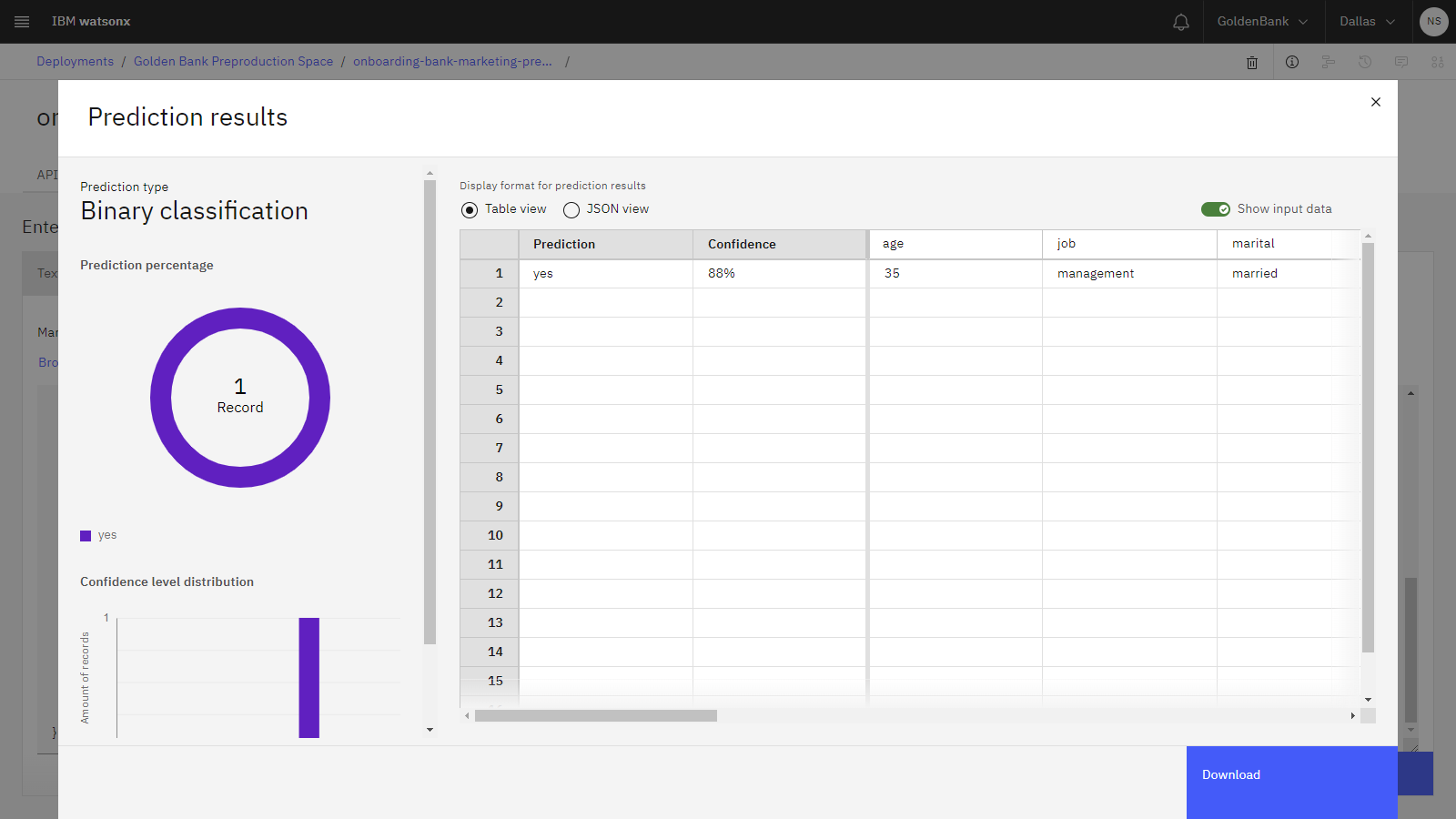
Click Predict. The results show that the prediction is to approve the applicant.
-
Check your progress
The following image shows the results of the test. The confidence scores for your test might be different from the scores that are shown in the image.
Next steps
-
Try these other methods to build models:
Learn more
Parent topic: Quick start tutorials