Take this tutorial to learn how to generate synthetic tabular data in IBM watsonx.ai. The benefit to synthetic data is that you can procure the data on-demand, then customize to fit your use case, and produce it in large quantities. This tutorial helps you learn how to use the graphical flow editor tool, Synthetic Data Generator, to generate synthetic tabular data based on production data or a custom data schema using visual flows and modeling algorithms.
- Required services
- watsonx.ai Studio
Your basic workflow includes these tasks:
- Open a project. Projects are where you can collaborate with others to work with data.
- Add your data to the project. You can add CSV files or data from a remote data source through a connection.
- Create and run a synthetic data flow to the project. You use the graphical flow editor tool Synthetic Data Generator to generate synthetic tabular data based on production data or a custom data schema using visual flows and modeling algorithms.
- Review the synthetic data flow and output.
Read about synthetic data
Synthetic data is information that has been generated on a computer to augment or replace real data to improve AI models, protect sensitive data, and mitigate bias. Synthetic data helps to mitigate many of the logistical, ethical, and privacy issues that come with training machine learning models on real-world examples.
Watch a video about generating synthetic tabular data
 Watch this video to preview the steps in this tutorial. There might be slight differences in the user interface shown in the video. The
video is intended to be a companion to the written tutorial.
Watch this video to preview the steps in this tutorial. There might be slight differences in the user interface shown in the video. The
video is intended to be a companion to the written tutorial.
This video provides a visual method to learn the concepts and tasks in this documentation.
Try a tutorial to generate synthetic tabular data
In this tutorial, you will complete these tasks:
- Task 1: Open a project
- Task 2: Add data to your project
- Task 3: Create a synthetic data flow
- Task 4: Review the data flow and output
Tips for completing this tutorial
Here are some tips for successfully completing this tutorial.
Use the video picture-in-picture
The following animated image shows how to use the video picture-in-picture and table of contents features:

Get help in the community
If you need help with this tutorial, you can ask a question or find an answer in the watsonx Community discussion forum.
Set up your browser windows
For the optimal experience completing this tutorial, open Cloud Pak for Data in one browser window, and keep this tutorial page open in another browser window to switch easily between the two applications. Consider arranging the two browser windows side-by-side to make it easier to follow along.

Task 1: Open a project
You need a project to to store the assets.
Watch a video to see how to create a sandbox project and associate a service. Then follow the steps to verify that you have an existing project or create a sandbox project.
This video provides a visual method to learn the concepts and tasks in this documentation.
-
From the watsonx home screen, scroll to the Projects section. If you see any projects listed, then skip to Task 2. If you don't see any projects, then follow these steps to create a project.
-
Click Create a sandbox project. When the project is created, you will see the sandbox project in the Projects section.
For more information or to watch a video, see Creating a project.
 Check your progress
Check your progress
The following image shows the home screen with the sandbox listed in the Projects section. You are now ready to open the Prompt Lab.
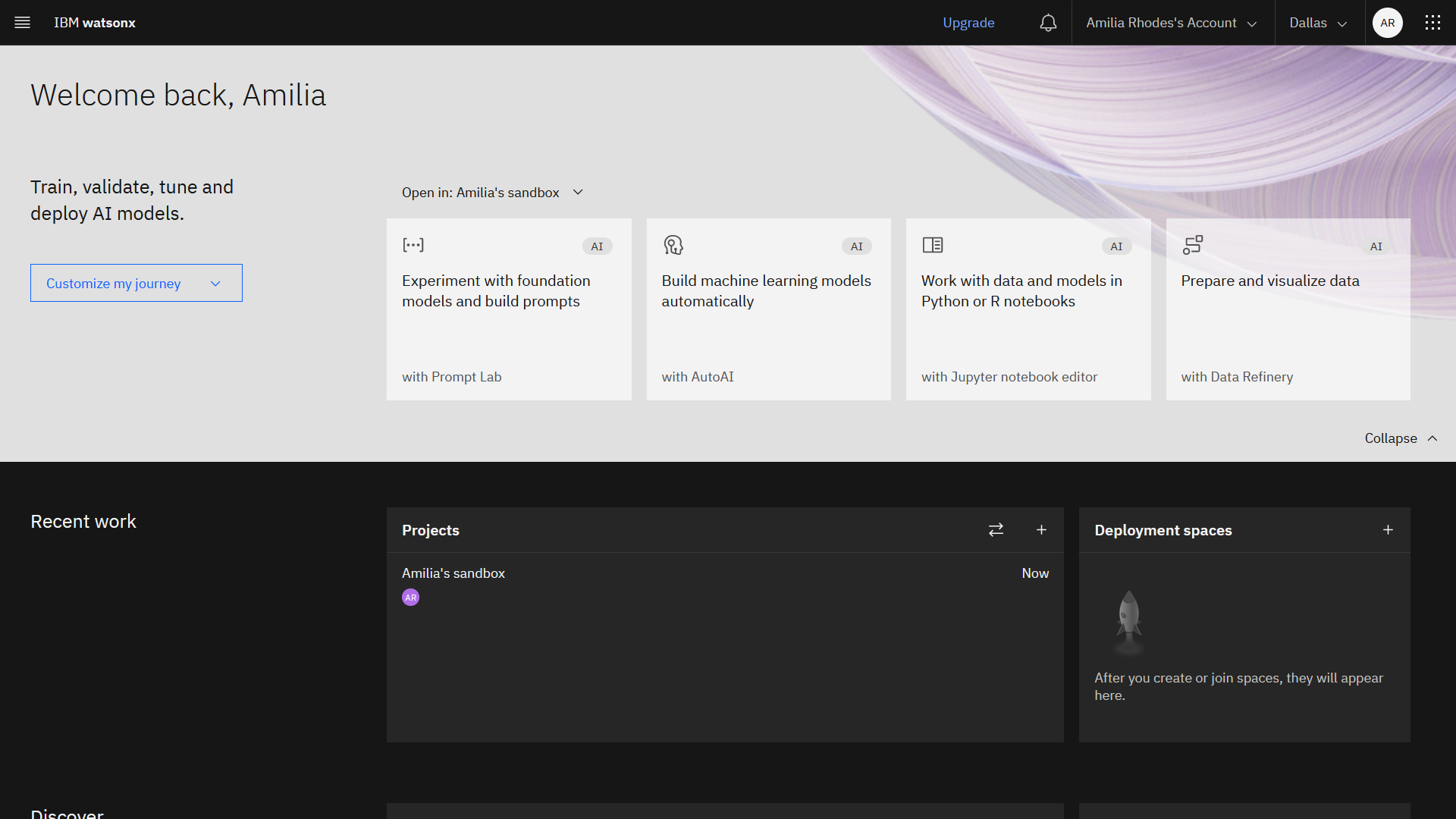
Task 2: Add data to your project
To preview this task, watch the video beginning at 00:24.
The data set used in this tutorial contains typical information that a company gathers about their customers, and is available in the Resource hub. Follow these steps to find the data set in the Resource hub and add it to your project:
-
Access the Customers data set in the Resource hub.
-
Click Add to project.
-
Select your project from the list, and click Add.
-
After the data set is added, click View Project.
For more information on adding data assets from the Resource hub to your project, see Loading and accessing data in a notebook.
Check your progress
The following image shows the Assets tab in the project. Now you are ready to create the synthetic data flow.
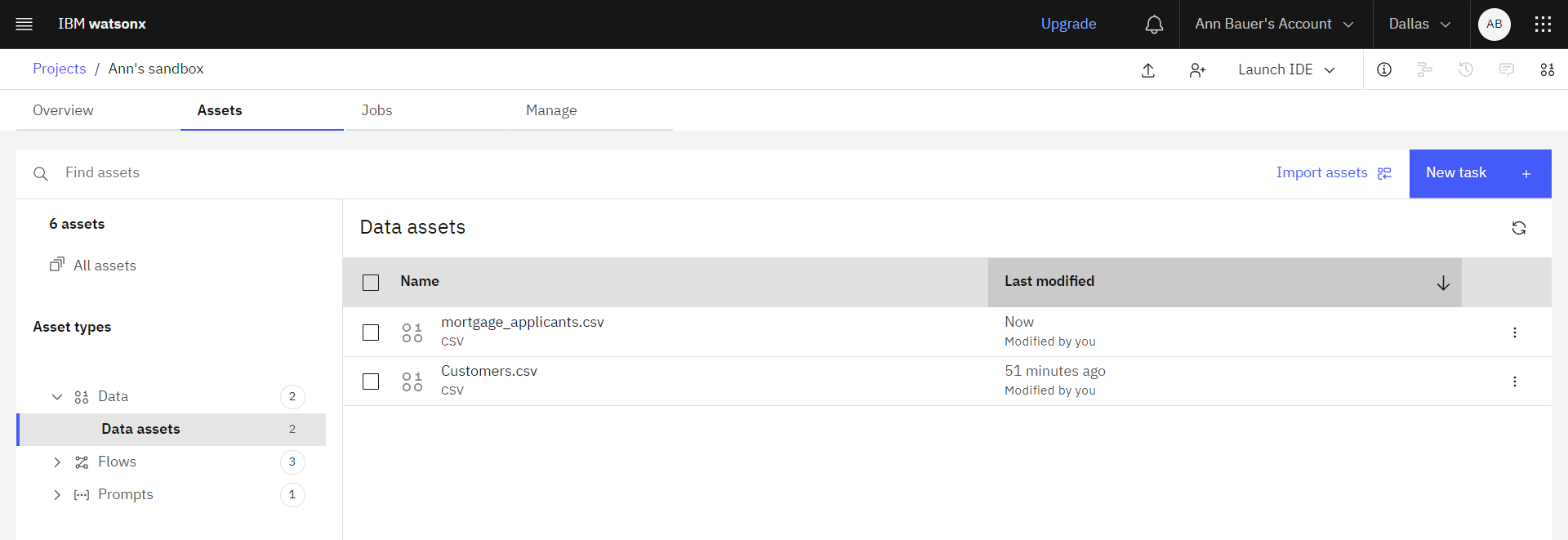
Task 3: Create a synthetic data flow
To preview this task, watch the video beginning at 00:43.
Use the Synthetic Data Generator to create a data flow that generates synthetic tabular data based on production data or a custom data schema using visual flows and modeling algorithms. Follow these steps to create a synthetic data flow asset in your project:
- From the Assets tab in your project, click New asset > Generate synthetic tabular data.
- For the name, type
Bank customers. - Click Create.
- On the Welcome to Synthetic Data Generator screen, click First time user, and click Continue. This option provides a guided experience for you to build the data flow.
- Review the two use cases:
- Leverage your existing data: Generate a structured synthetic data set based on your production data. You can connect to a database, import or upload a file, mask, and generate your output before exporting.
- Create from custom data: Generate a structured synthetic data set based on meta data. You can define the data within each table column, their distributions, and any correlations.
- Select the Leverage your existing data use case, and click Next to import existing data.
- Click Select data from project to use the customers data asset that you added from the Resource hub.
- Select Data asset > customers.csv.
- Click Select.
- Click Next.
- In the list of columns, search for
creditcard_number.- In the Anonymize column for
CREDITCARD_NUMBER, select Yes to mask customers' credit card numbers. - Click Next.
- In the Anonymize column for
- On the Mimic options page, change the Number of rows to
1000. Accept the default settings for the rest of the options. These options generate synthetic data, based on your production data, using a set of candidate statistical distributions to modify each column in your data. Click Next. - On the Evaluate screen, toggle the Enable evaluate metrics option. Here, you can specify settings to compare the generated synthetic data with your baseline input. You can choose which metrics to assess.
- Select the following metrics:
- Fidelity score
- Data distinguishability
- Leakage prevention score
- Proximity score
- Click Next.
- Select the following metrics:
- On the Export data page, type
bank_customers.csvfor the File name, and click Next. - Review the settings, and click Save flow. The Synthetic Data Generator tool displays with the data flow.
- When prompted, click Run flow, and wait for the run to complete.
Check your progress
The following image shows the data flow open in the Synthetic Data Generator. Now you can explore the data flow and view the output.
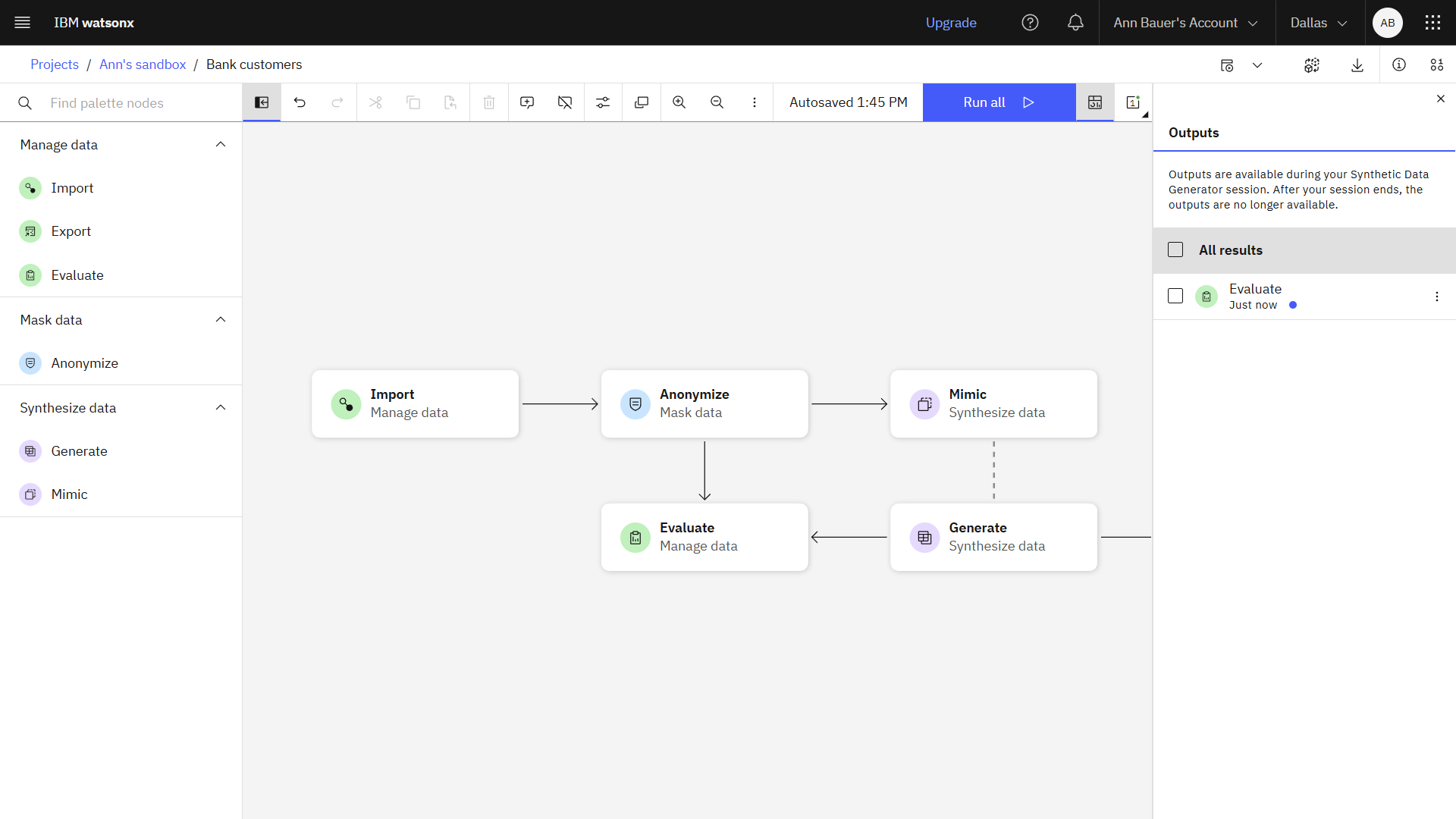
Task 4: Review the data flow and output
To preview this task, watch the video beginning at 01:48.
When the run completes, you can explore the data flow. Follow these steps to review the synthetic data flow and the results:
-
Click the Palette icon
 to close the node panel.
to close the node panel. -
Double-click the Import node to see the settings.
- Review the Data properties. The tool read the data set from the project and filled in the appropriate data properties.
- Expand the Types section. The tool read the values and columns in the data set.
- Click Cancel.
-
Double-click the Anonymize node to see the settings.
- Verify that the CREDITCARD_NUMBER column is set to be anonymized.
- Expand the Anonymize values section. Here you can customize how the values are anonymized.
- Click Cancel.
-
Double-click the Mimic node to see the settings.
- Review the default settings to mimic the data in the source customers data set.
- Click Cancel.
-
Double-click the Evaluate node to see the settings.
- Review the following settings:
- The Baseline input is set to Import. The flow shows that the Evaluate node has two inputs, the output from the Anonymize and Generate nodes.
- The Quality metrics, Privacy metrics, Utility metrics, and Assessment level. Hover over the Information icon
 to see a description for each setting.
to see a description for each setting.
- Click Cancel.
- Review the following settings:
-
Double-click the Generate node to see the settings.
- Review the list of Synthesized columns.
- Optional: Review the Correlations and Advanced Options.
- Click Cancel.
-
Double-click the Export node to see the settings.
- Optional: By default the exported data is stored in the project. Click Change path to store the exported data in a connection, such as Db2 Warehouse.
- Click Cancel.
-
In the Outputs pane, click the results with the name Evaluate. If you don't see the Outputs pane, click the Outputs icon
 .
. -
Click the View details icon
 for each of the metrics to see the visualizations for that metric.
for each of the metrics to see the visualizations for that metric. -
On the Chart metrics tab, you can see the same scores. When you are done, close the window.
-
Click your project name to return to the Assets tab.

-
Click bank_customers.csv to see a preview of the generated synthetic tabular data.
Check your progress
The following image shows the exported, generated synthetic tabular data set.
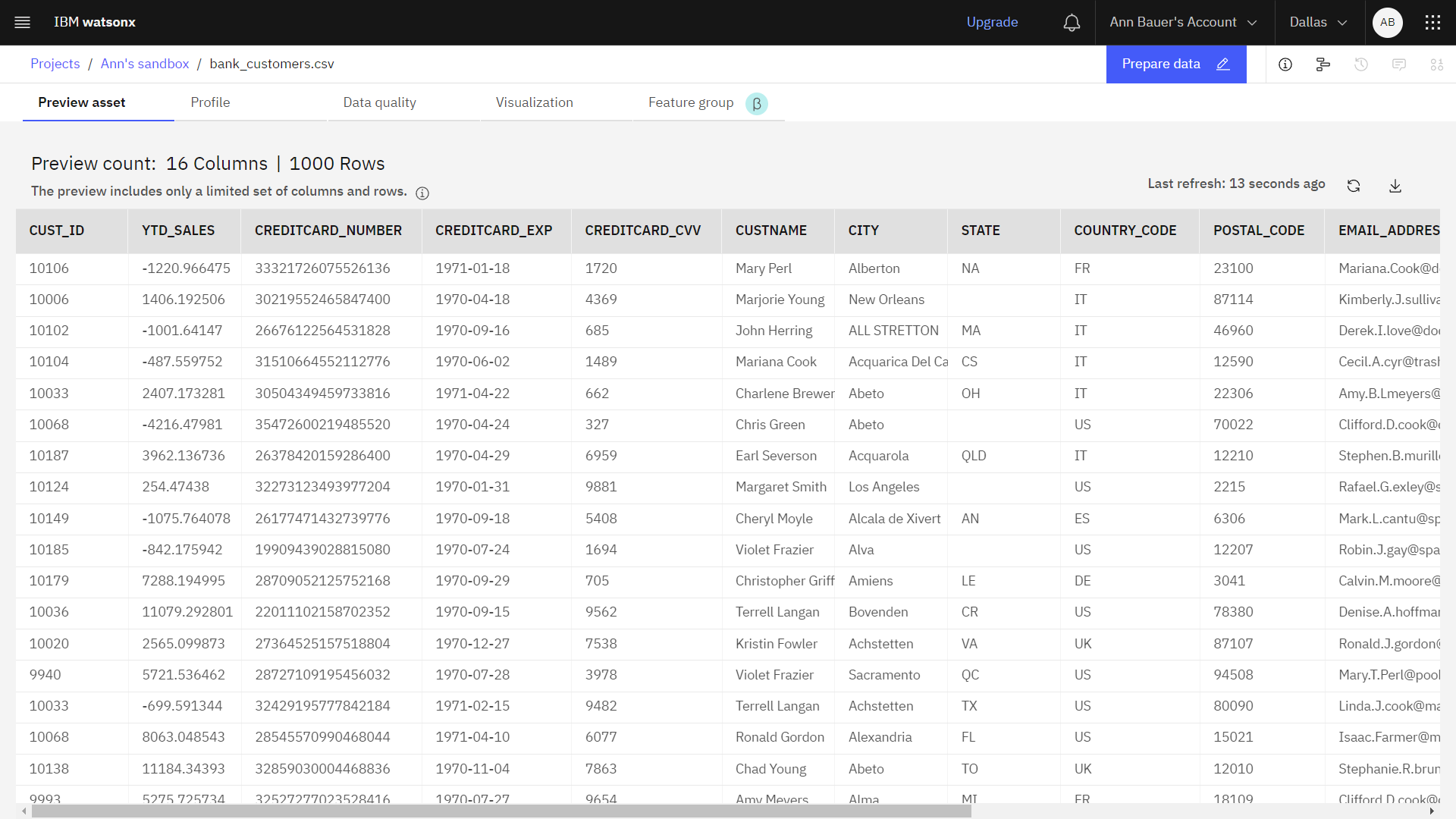
Next steps
Try these additional tutorials to get more hands-on experience with watsonx.ai:
Additional resources
-
View more videos.
-
Find sample data sets, projects, models, prompts, and notebooks in the Resource hub to gain hands-on experience:
 Notebooks that you can add to your project to get started analyzing data and building models.
Notebooks that you can add to your project to get started analyzing data and building models. Projects that you can import containing notebooks, data sets, prompts, and other assets.
Projects that you can import containing notebooks, data sets, prompts, and other assets. Data sets that you can add to your project to refine, analyze, and build models.
Data sets that you can add to your project to refine, analyze, and build models. Prompts that you can use in the Prompt Lab
to prompt a foundation model.
Prompts that you can use in the Prompt Lab
to prompt a foundation model. Foundation models that you can use in the Prompt Lab.
Foundation models that you can use in the Prompt Lab.
Parent topic: Quick start tutorials