デプロイメントスペースでモデルのデプロイメントを評価し、モデルのパフォーマンスに関する洞察を得ることができます。 評価を設定すると、評価結果やトランザクション記録のモデルをスペース内で直接分析できます。
- 必須のサービス
- watsonx.governance
- watsonx.ai
基本的なワークフローには、以下のタスクが含まれます:
- プロジェクトを開きます。 プロジェクトは、データを処理するために他のユーザーと共同作業できる場所です。
- 機械学習モデルを構築し、保存する。 モデルを構築するためのツールには、AutoAI実験、Jupyterノートブック、SPSS Modelerフロー、パイプラインなどさまざまなものがある。 データの分析とモデルの操作を参照してください。
- デプロイメントスペースでモデルをデプロイし、テストする。
- デプロイメントスペースで評価を構成する。
- モデルのパフォーマンスを評価する。
スペースにおける配備の評価方法について読む
watsonx.governanceは、パフォーマンスを測定し、モデルの予測を理解するために、モデルの展開を評価します。 モデル評価を構成すると、watsonx.governance は評価ごとにメトリックを生成し、確認できるさまざまな洞察を提供します。 watsonx.governance は、評価中に処理されたトランザクションのログも記録し、モデルの予測値がどのように決定されるかを理解するのに役立ちます。
スペースへの配備を評価する方法をビデオで見る
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオで紹介されているユーザー・インターフェースには若干の違いがあるかもしれません。 このビデオは、書面でのチュートリアルに付随するものです。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオで紹介されているユーザー・インターフェースには若干の違いがあるかもしれません。 このビデオは、書面でのチュートリアルに付随するものです。
スペースでの配備を評価するチュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
- タスク1:サンプルに基づいてプロジェクトを作成する
- タスク2:モデルのデプロイ
- タスク 3: デプロイメント空間での評価の構成
- タスク4:モデルの評価
- タスク5:モデルモニターの品質を観察する
- タスク6:公平性を保つためにモデルモニターを観察する
- タスク7:モデルモニターのドリフトを観察する
- タスク8:モデルのモニターを観察し、説明可能性を確認する
このチュートリアルを完了するためのヒント
このチュートリアルを成功させるためのヒントを紹介します。
ビデオのピクチャー・イン・ピクチャーを使う
次のアニメーション画像は、ビデオのピクチャー・イン・ピクチャーと目次機能の使い方を示しています:

地域の助けを借りる
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザのウィンドウを設定する
このチュートリアルを最適に完了するには、Cloud Pak for Data を 1 つのブラウザ ウィンドウで開き、このチュートリアルのページを別のブラウザ ウィンドウで開いておくと、2 つのアプリケーションを簡単に切り替えることができます。 2つのブラウザウィンドウを横に並べると、より見やすくなります。

タスク1:サンプルに基づいてプロジェクトを作成する
このタスクをプレビューするには、00:06から始まるビデオを見てください。
モデルを構築するためのアセットを保存するプロジェクトが必要です。 例えば、学習データ、AutoAI実験またはJupyterノートブック、保存されたモデルなどである。 以下の手順に従って、サンプルに基づいたプロジェクトを作成してください:
Resource hub のEvaluate an ML model sample projectにアクセスします。
プロジェクトを作成をクリックします。
プロジェクトを Cloud Object Storage インスタンスに関連付けるように求められたら、リストから Cloud Object Storage インスタンスを選択してください。
「作成」 をクリックします。
プロジェクトのインポートが完了するまで待ち、View new projectをクリックして、プロジェクトとアセットが正常に作成されたことを確認します。
アセットタブをクリックして、サンプルプロジェクトのアセットを表示します。
住宅ローン承認予測モデルをご覧ください。 このモデルは、信用履歴、負債総額、収入、融資額、職歴などいくつかの要素に基づいて、住宅ローン申請者が承認されるべきかどうかを予測する。
プロジェクトの 資産 タブに戻ります。
 進捗状況を確認する
進捗状況を確認する
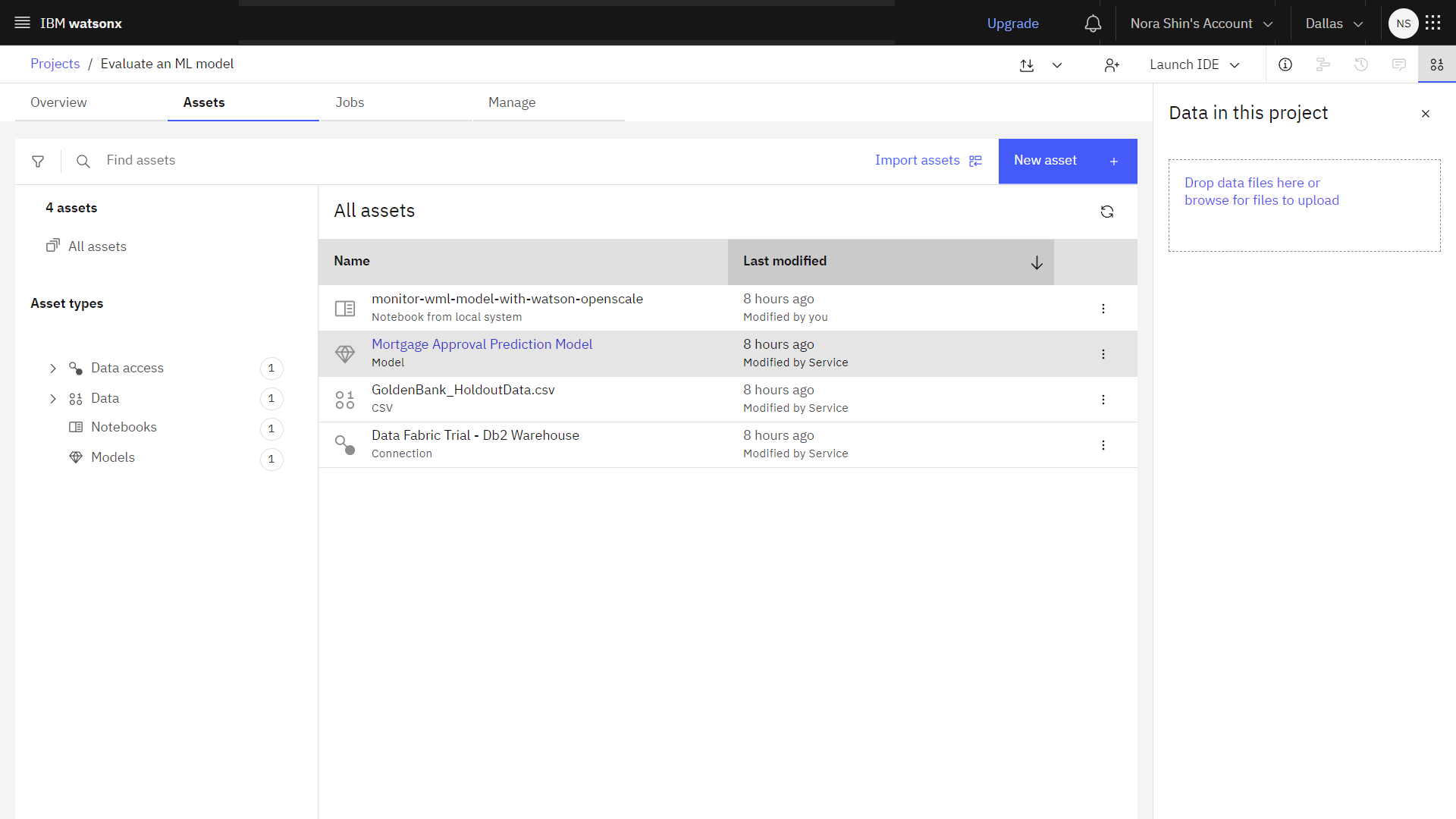
次の画像はサンプル・プロジェクトです。
これでチュートリアルを始める準備ができました
タスク2:モデルのデプロイ
モデルを配置する前に、モデルを新しい配置スペースにプロモートする必要があります。 デプロイメントスペースでは、入力データや環境などのサポートリソースを整理したり、モデルや関数をデプロイして予測やソリューションを生成したり、デプロイの詳細を表示または編集したりすることができます。 次のタスクは、評価データとモデルをデプロイメント空間に昇格させ、オンラインデプロイメントを作成することである。
タスク 2a: 評価データのダウンロード
このタスクをプレビューするには、00:34から始まるビデオをご覧ください。
モデルが要求通りに動作していることを検証するには、モデルのトレーニングから取り除かれたラベル付きデータセットが必要である。 サンプル・プロジェクトには評価データ(GoldenBank_HoldoutData.csv)が含まれており、後で配置スペースで評価を実行するためにアップロードできます。 以下の手順に従って、データセットをダウンロードしてください:
GoldenBank_HoldoutData.csvデータ資産のオーバーフローメニュー「
 クリックし、「ダウンロード」を選択します。
クリックし、「ダウンロード」を選択します。データ資産をコンピュータに保存します。
タスク 2b: 展開スペースにモデルをプロモートする
このタスクをプレビューするには、00:42から始まるビデオを見てください。
モデルを配置する前に、モデルを配置スペースにプロモートする必要があります。 以下の手順に従って、モデルを配置スペースにプロモートしてください:
Assetsタブで、Mortgage Approval Modelモデルのオーバーフローメニュー「
クリックし、Promote to space を選択する。既存のデプロイメント・スペースを選択してください。 もし配置スペースがなければ:
新しい配置スペースを作成をクリックします。
名前には
Golden Bank Preproduction Spaceストレージ・サービスを選択してください。
機械学習サービスを選択してください。
デプロイメントステージでは、デベロップメントを選択します。
「作成」 をクリックします。
スペースの準備ができたら通知を閉じる。
プロモーション後、スペース内のモデルに移動するオプションを選択します。
プロモートをクリックします。
進捗状況を確認する
以下の画像は、デプロイメントスペースのモデルを示しています
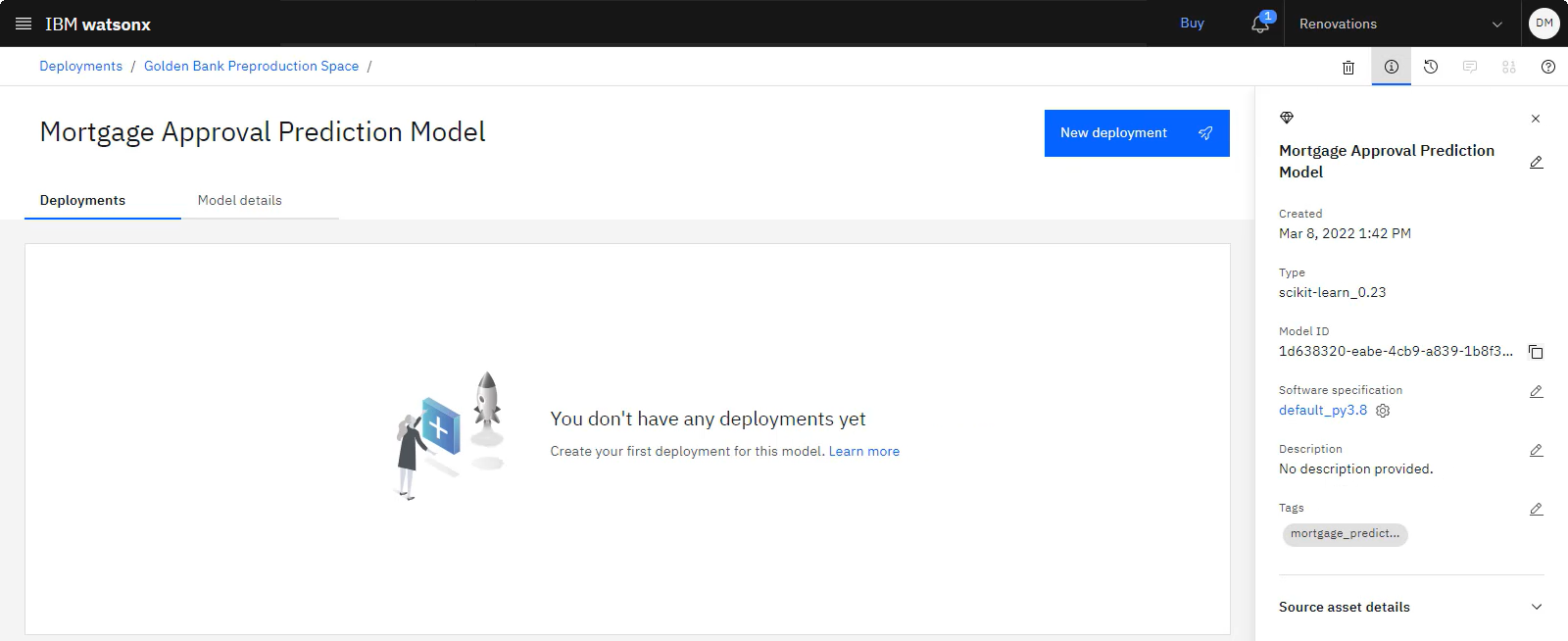
タスク 2c: モデルの配置を作成する
このタスクをプレビューするには、01:02から始まるビデオを見てください。
モデルが配置スペースに配置されたので、以下の手順に従ってモデルの配置を作成します:
モデルを開いた状態で、新規配置をクリックします。
デプロイメント・タイプとして オンライン を選択してください。
デプロイメント名には、次のように入力する:
Mortgage Approval Model Deploymentと入力します「作成」 をクリックします。
デプロイメントが完了したら、デプロイメント名をクリックして、デプロイメントの詳細ページを表示します。
あなたのアプリケーションでこのモデルにプログラム的にアクセスするために使用できる、スコアリング・エンドポイントを確認してください。
進捗状況を確認する
次の画像は、デプロイメントスペースでのモデルのデプロイメントを示しています。
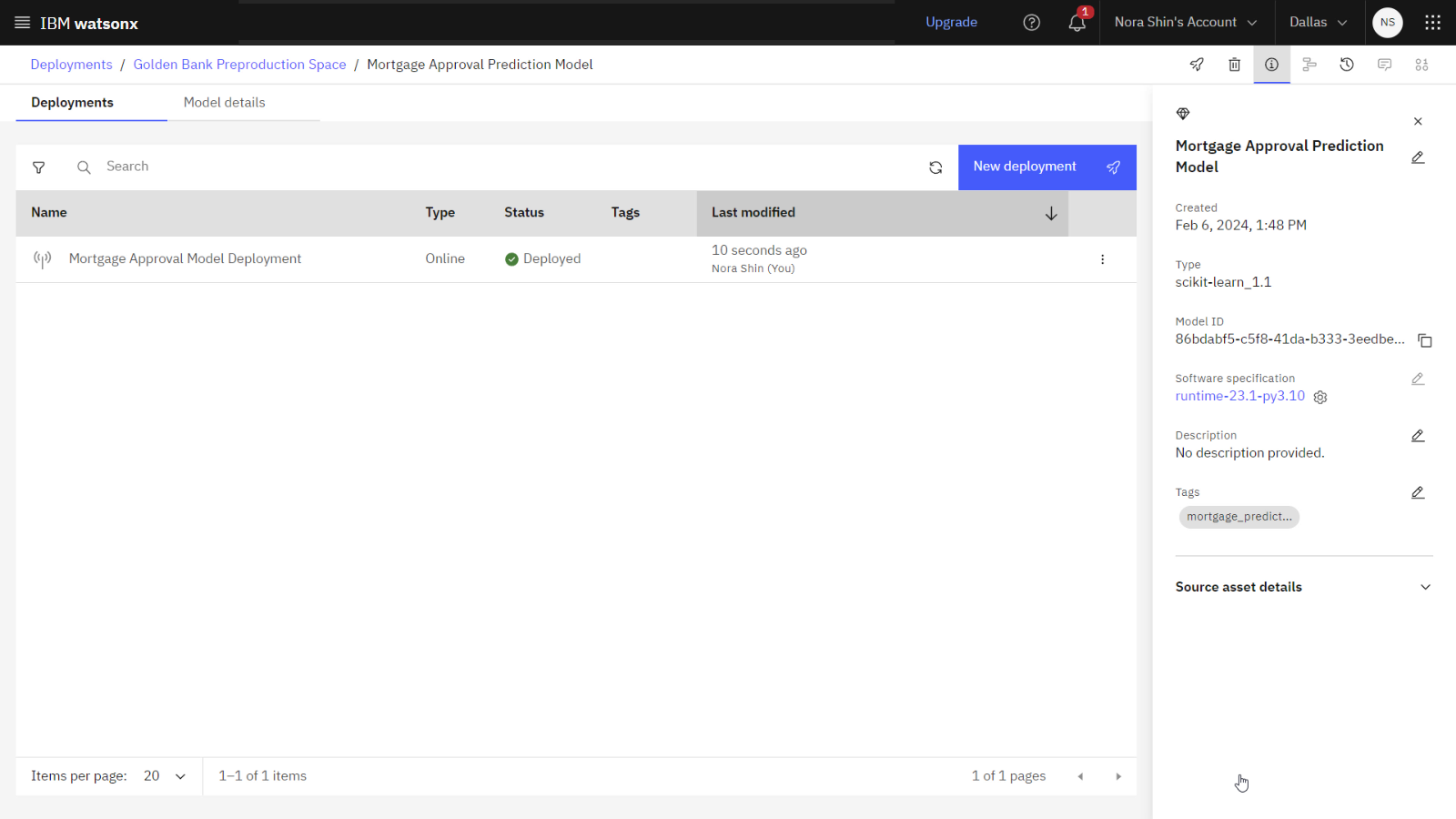
タスク 3: 展開スペースで評価を構成する
このタスクをプレビューするには、01:19から始まるビデオを見てください。
この配置スペースで評価を構成するには、次の手順に従います:
タスク 3a: モデルの詳細を設定する
してください。 モデルの詳細を設定するには、以下の手順に従ってください。
- 配置で、[評価]タブをクリックします。
- Configure OpenScale 評価設定をクリックします。
モデル入力データの指定
学習データには、2値分類モデルに適した数値データとカテゴリーデータが含まれる。
- ストレージの種類では、システム管理を選択します。
- データ・タイプでは、数値/カテゴリーを選択します。
- Algorithm typeでは、バイナリ分類を選択します。
- 概要を見るをクリックする。
- 概要を確認し、保存して続行をクリックします。
訓練データへの接続
学習データは、Db2 Warehouse on Cloud インスタンスに格納される。
- 設定方法では、手動設定を使用を選択します。
- 次へ をクリックします。
- トレーニングデータオプションでは、データベースまたはクラウドストレージを選択します。
- 場所はDb2を選択する。
- 接続情報を提供する:
- ホスト名または IP アドレス:
db2w-ruggyab.us-south.db2w.cloud.ibm.com - SSL ポート:
50001 - データベース:
BLUDB - ユーザー名:
CPDEMO - Password:
DataFabric@2022IBM
- ホスト名または IP アドレス:
- 「接続」 をクリックします。
- スキーマにはAI_MORTGAGEを選択します。
- テーブルにはMORTGAGE_APPROVAL_TABLEを選択します。
- 次へ をクリックします。
特徴とラベル列を選択する
MORTGAGE_APPROVAL列は、申請者が承認されたかどうかを示し、特徴列には承認決定に寄与する情報が含まれる。
- 以下の特徴的なコラムを確認する:
- GENDER
- Education
- EMPLOYMENT_STATUS
- MARITAL_STATUS
- INCOME
- APPLIEDONLINE
- RESIDENCE
- 現在の住所
- 現在の雇用主との勤続年数
- カード枚数
- クレジットカード
- LOANS
- ローン残高
- CREDIT_SCORE
- コマーシャル・クライアント
MORTGAGE_APPROVALを検索し、ラベル/ターゲットチェックボックスを選択します。- 次へ をクリックします。
モデル出力の詳細を指定
モデルの出力データから、配置されたモデルによって生成された予測列と、予測に対するモデルの信頼度を含む確率列を選択する必要があります。
- 予測と確率列の適切なチェックボックスを選択する。
- 概要を見るをクリックする。
- 「完了 (Finish)」 をクリックします。
進捗状況を確認する
次の画像は、完成したモデルの詳細である。 これで、説明可能性を設定する準備が整いました。
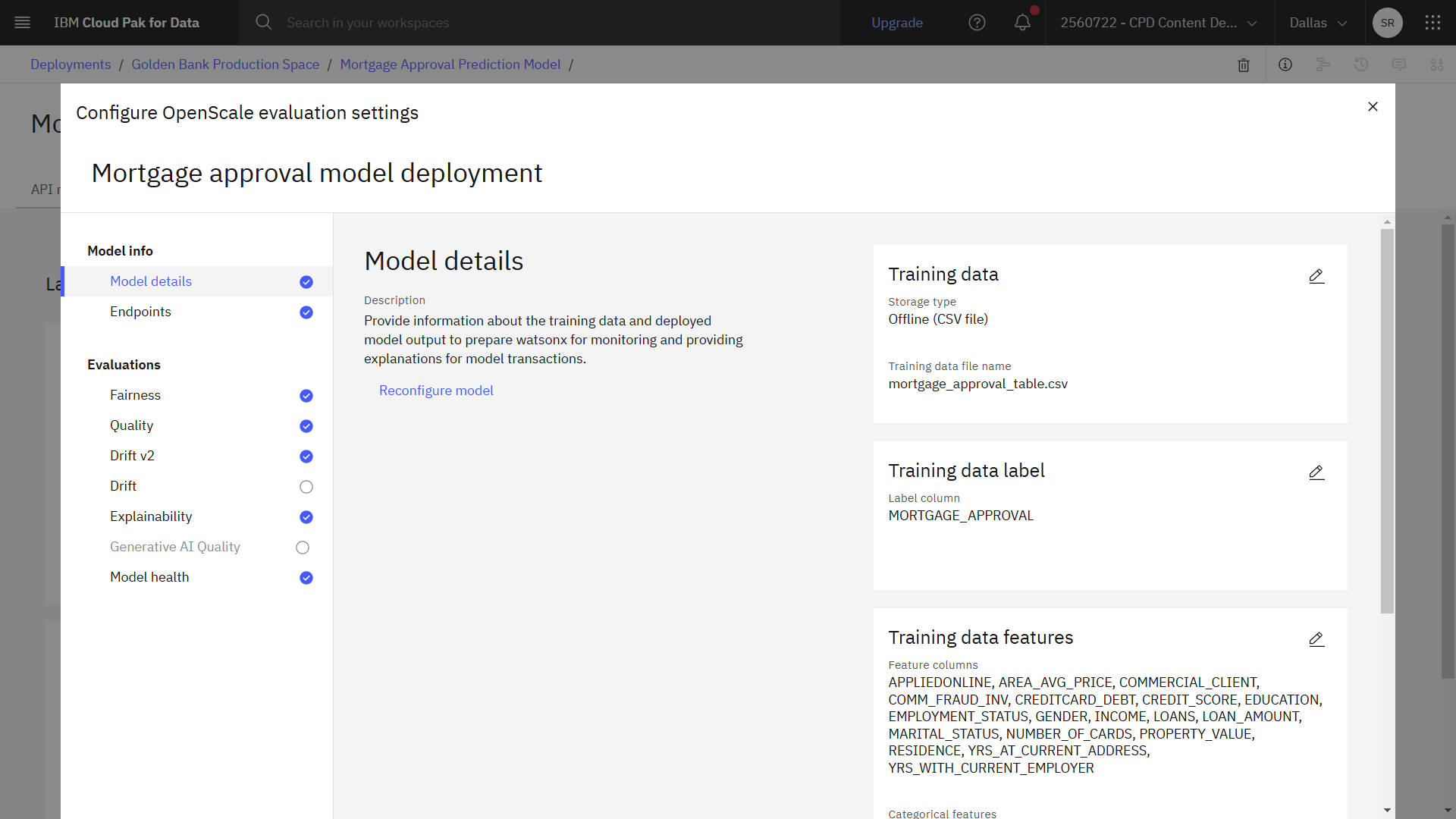
タスク 3b: 説明可能性の設定
このタスクをプレビューするには、 02:58から始まるビデオをご覧ください。
次に、以下の手順に従って、説明可能性を設定します。
説明方法の選択
SHAP(Shapley Additive Explanations)は、入力のすべての可能な組み合わせを使用して、各入力が予測を平均予測値または信頼度スコアに近づけたり遠ざけたりする方法を発見する。 局所的解釈可能モデル不可知論的説明(LIME)は、各特徴の重要性を発見するために疎な線形モデルを構築する。 SHAPはより徹底的で、LIMEはより速い。
- 一般設定をクリックします。
- 説明メソッドの横で、編集アイコン「
 」をクリックする。
」をクリックする。 - SHAPグローバル説明オプションをオンに切り替えます。
- Local explanatiion methodの場合は、LIME(enhanced)を選択する。
- 次へ をクリックします。
制御可能な機能を選択する
分析実行時に制御可能なフィーチャーを指定して、どのフィーチャーがモデルの結果を決定する上で最も重要であったかを示すことができます。
- 制御可能な機能のリストを確認し、Saveをクリックします。
グローバルな説明可能性の設定
SHAP は、各特徴量がモデルの結果に与える影響を定量化します。 SHAP は、グローバル説明に適した要約プロットを作成しますが、単一の予測説明を生成することもできます。
- 説明可能性の下で、シャップをクリックします。
- 共通設定の横にある編集アイコン「」をクリックする。
- 共通設定のデフォルトを受け入れる。
- 保存 をクリックします。
- グローバル説明の横にある編集アイコン「」をクリックする。
- グローバルな説明のためにデフォルトにアクセスする。
- 保存 をクリックします。
進捗状況を確認する
次の画像は、完成した説明可能性コンフィギュレーションを示している。 これでフェアネスを設定する準備ができた。
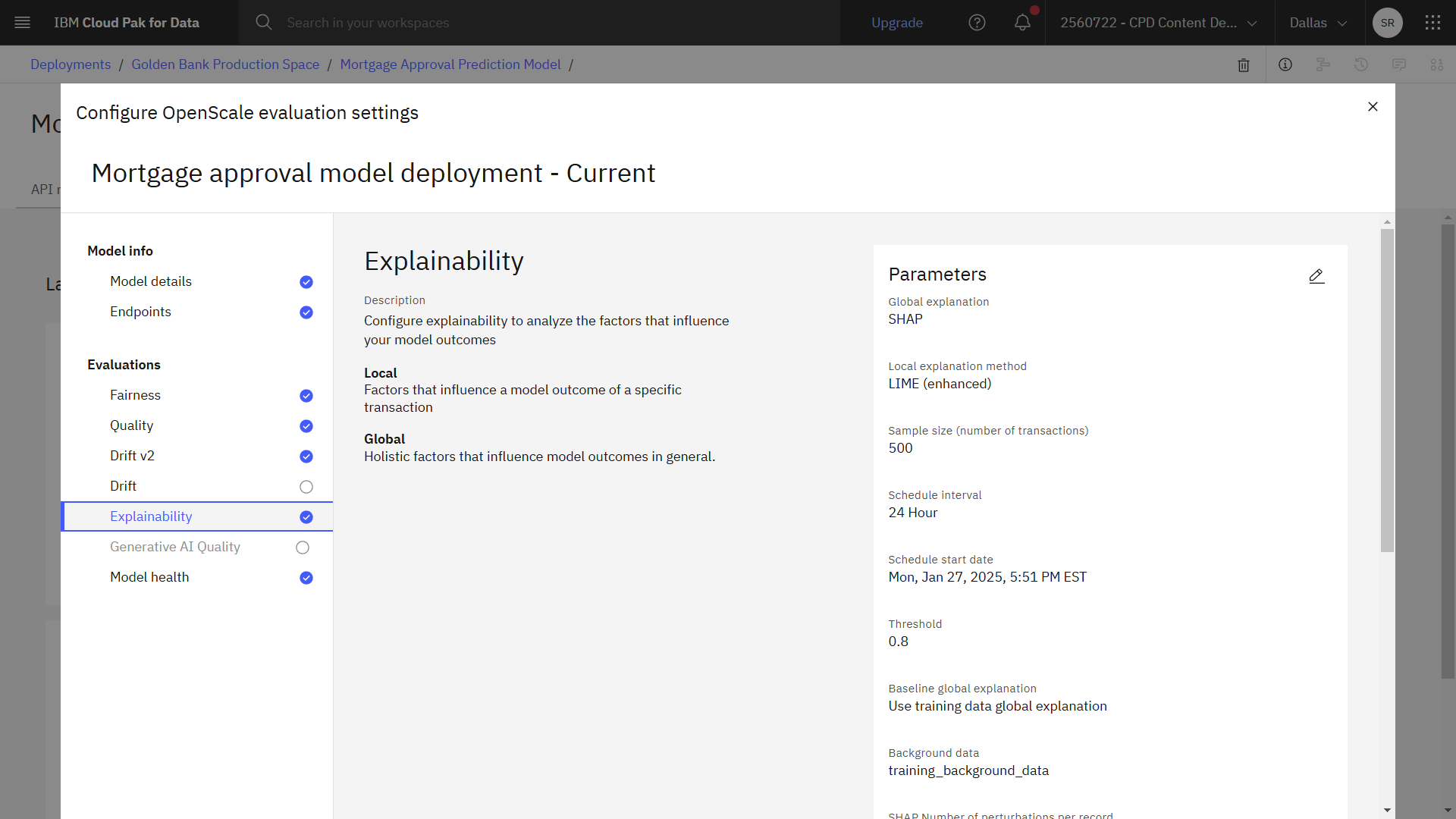
タスク 3c: フェアネスを設定する
このタスクをプレビューするには、 04:06から始まるビデオをご覧ください。
次に、以下の手順に従って公平性を設定する。
コンフィギュレーション・タイプを選択する
手動で公正さを設定するか、付属のJupyterノートブックを使って生成した設定ファイルをアップロードすることができる。
- 公平をクリックします。
- Configuration(設定)」の横にある「Edit(編集)」アイコンの「」をクリックする。
- 設定の種類で手動で設定を選択します。
- 次へ をクリックします。
好ましい結果の選択
このモデル展開では、有利な結果とは申請者が住宅ローンの承認を受けることであり、不利な結果とは申請者が承認を受けないことである。
- この表では、Favorableを選択し、1の値は、申請者が住宅ローンを承認されたことを表します。
- この表では、0の値に対して好ましくないを選択する。
- 次へ をクリックします。
サンプル・サイズ
モデルの評価に使用するデータセットに基づいて、サンプル・サイズを調整します。
- 最小サンプルサイズを
100に変更してください。 - 次へ をクリックします。
メトリック
公平性モニタリングは、複数の公平性指標を追跡します。 格差の影響とは、監視対象グループにとっての好ましい結果の割合と、参照グループにとっての好ましい結果の割合の比率である。
- すべてのデータから生成された監視対象メトリクスを監視対象フィーチャに適用し、フィードバック・データから生成されたメトリクスを監視対象フィーチャに適用します。
- デフォルトの測定基準を受け入れ、Nextをクリックします。
- 下限しきい値と上限しきい値のデフォルト値を受け入れ、Nextをクリックします。
モニタリング対象のフィールドを選択
配備されたモデルが、あるグループに対して他のグループよりも有利な結果をもたらす傾向を監視したい。 この場合、性別の偏りについてモデルを監視したい。
- GENDERフィールドを選択します。
- 次へ をクリックします。
- 値が表に記載されている場合:
- 女性をチェックモニター
- 男性をチェック参考
- 値が表に記載されていない場合:
- カスタム値の追加フィールドに、
Femaleと入力する。 - 値を追加をクリックします。
- 表の男性の隣にある監視を選択する。
- カスタム値の追加フィールドに、
Femaleと入力する。 - 値を追加をクリックします。
- 表の男性の隣にある参照を選択する。
- カスタム値の追加フィールドに、
- 次へ をクリックします。
- 監視対象グループのデフォルトの閾値を受け入れ、Saveをクリックします。
進捗状況を確認する
次の画像は、完成した公平性のコンフィギュレーションを示している。 これで品質を設定する準備ができた。
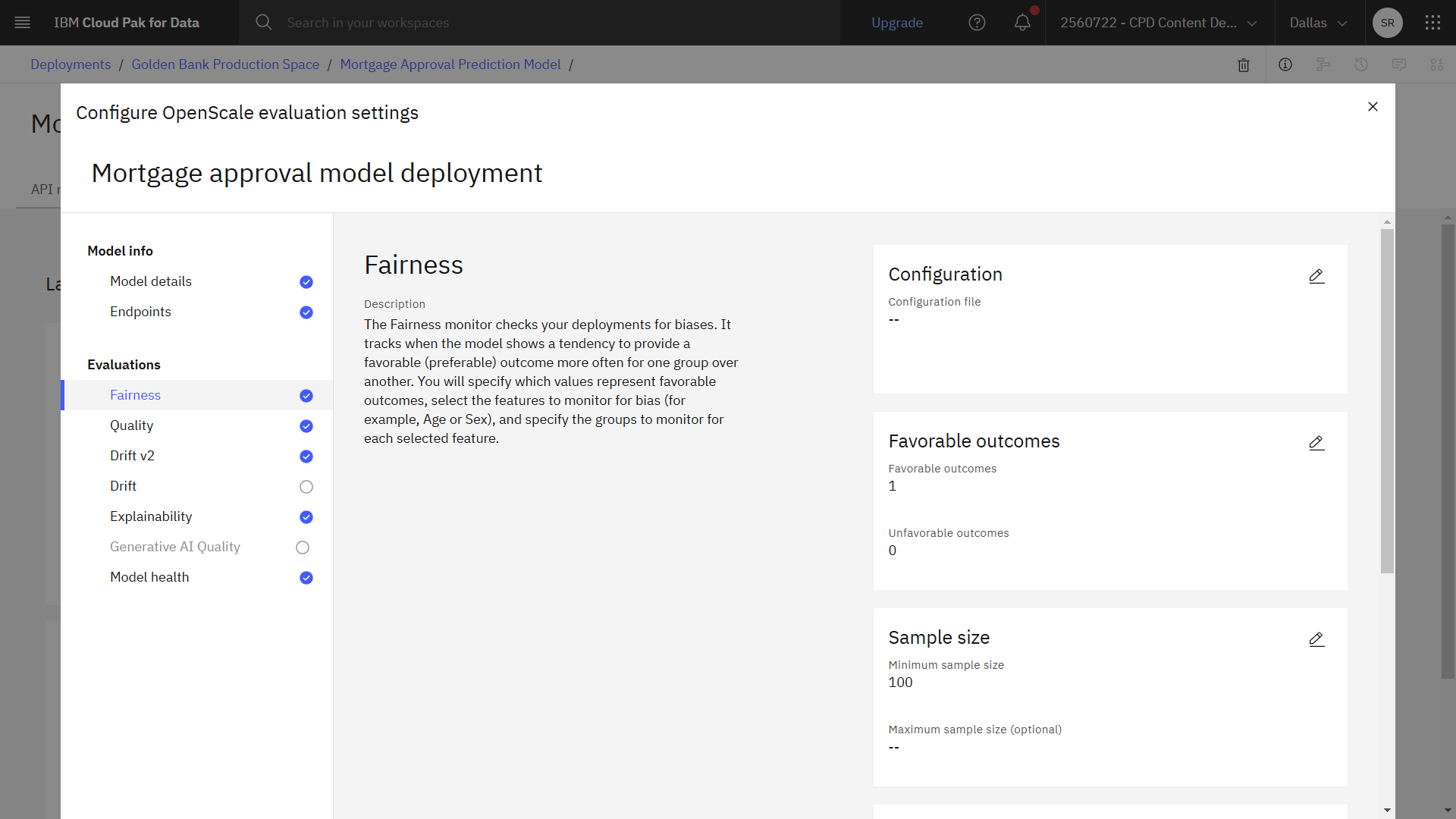
タスク 3d: クオリティの設定
このタスクをプレビューするには、05:17から始まるビデオをご覧ください。
次に、以下の手順に従って品質を設定する。 モデル性能モニタリングは、どの程度モデルが正確な結果を予測するかを評価します。
- 品質をクリックします。
- 品質しきい値(Quality thresholds)」の横にある「編集(Edit)」アイコンの「」をクリックする。
- Area under ROCの値を
0.7に変更する。 - 次へ をクリックします。
- 最小サンプルサイズを
100に変更します。 - 保存 をクリックします。
進捗状況を確認する
次の図は、完成した品質コンフィギュレーションを示している。 これでドリフトを設定する準備ができた。
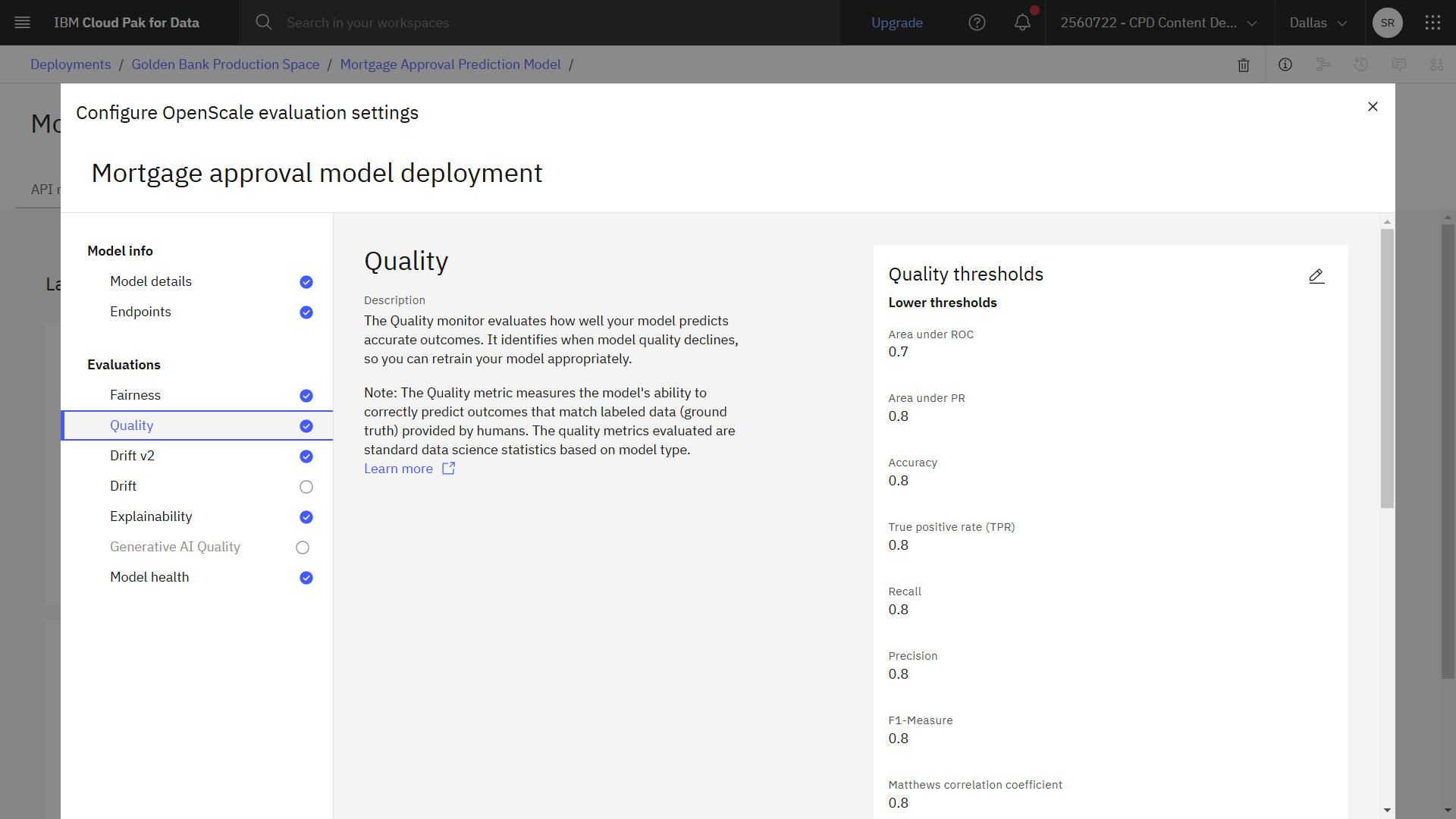
タスク 3e: ドリフトを設定する
このタスクをプレビューするには、05:42から始まるビデオをご覧ください。
最後に、以下の手順に従ってドリフトを設定する。 ドリフト・モニターは、デプロイメントが最新で一貫して動作しているかどうかを検査します。
- ドリフトv2をクリックします。
- ドリフト・アーカイブを計算する」の横にある「編集」アイコンの「」をクリックする。
- Compute option では、Compute in Watson OpenScale を選択します。 このオプションは、Watson OpenScale に、学習データの分析を行い、特徴量のデータ分布を決定するように指示します。
- 次へ をクリックします。
- 上限しきい値のデフォルト値を受け入れ、Nextをクリックします。
- サンプル・サイズのデフォルト値を受け入れ、保存をクリックします。
- X をクリックしてウィンドウを閉じ、Watson OpenScale がモニターを取得するのを待ちます。
進捗状況を確認する
次の図は、デプロイメントスペースに完成した設定を示しています。 これで、モデルのデプロイメントをモニターする準備ができた。
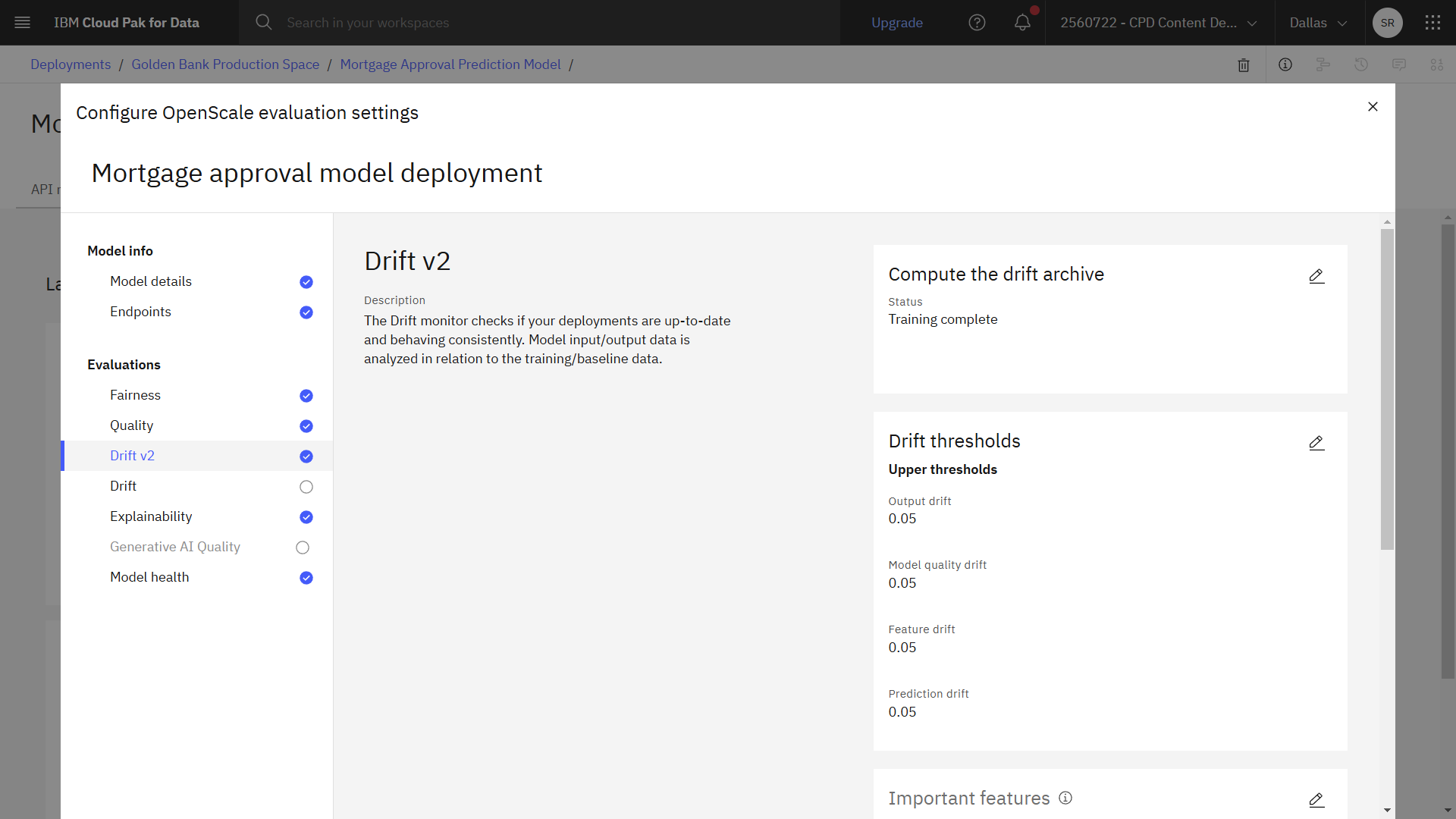
タスク4:モデルの評価
このタスクをプレビューするには、06:22から始まるビデオをご覧ください。
以下の手順に従って、ホールドアウトデータを使用してモデルを評価する:
アクション メニューから、 今すぐ評価を選択してください。
インポート・オプションのリストから、 CSV ファイルからを選択してください。
プロジェクトからダウンロードした Golden Bank_HoldoutData.csv データ・ファイルをサイド・パネルにドラッグします。
アップロードして評価するをクリックし、評価が完了するまで待ちます。
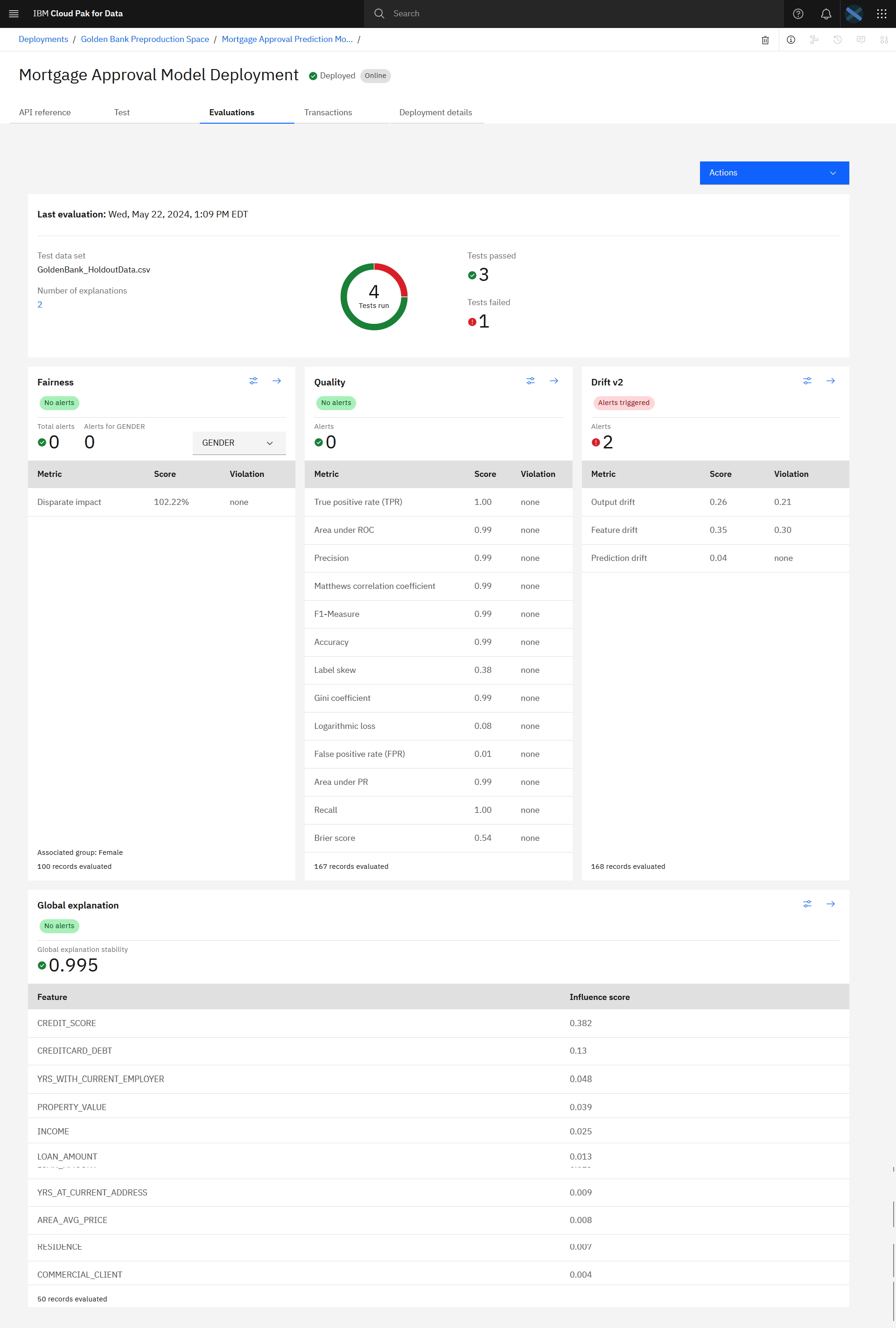
評価が完了すると、実行されたテストの数、合格したテスト、失敗したテストが表示されます。 スクロールすると、公平さ、質、漂流、グローバルな説明の結果を見ることができる。
進捗状況を確認する
以下の画像は、導入モデルの評価結果である。 モデルを評価したところで、モデルの品質を観察する準備ができました。
タスク5:モデルモニターの品質を観察する
このタスクをプレビューするには、06:36から始まるビデオをご覧ください。
Watson OpenScale 品質モニターは、モデルの品質を評価するための一連のメトリクスを生成します。 これらの品質メトリックを使用して、モデルの予測結果の精度を判別できます。 ホールドアウトデータを使用した評価が完了したら、以下の手順に従ってモデルの品質または精度を観察する:
品質セクションで、設定アイコン「
 」をクリックする。 ここでは、このモニターに設定されている品質しきい値は70%であり、ROC曲線下の面積が品質測定に使用されていることがわかる。
」をクリックする。 ここでは、このモニターに設定されている品質しきい値は70%であり、ROC曲線下の面積が品質測定に使用されていることがわかる。Xをクリックしてウィンドウを閉じ、モデルの評価画面に戻ります。
品質セクションで、詳細アイコン「
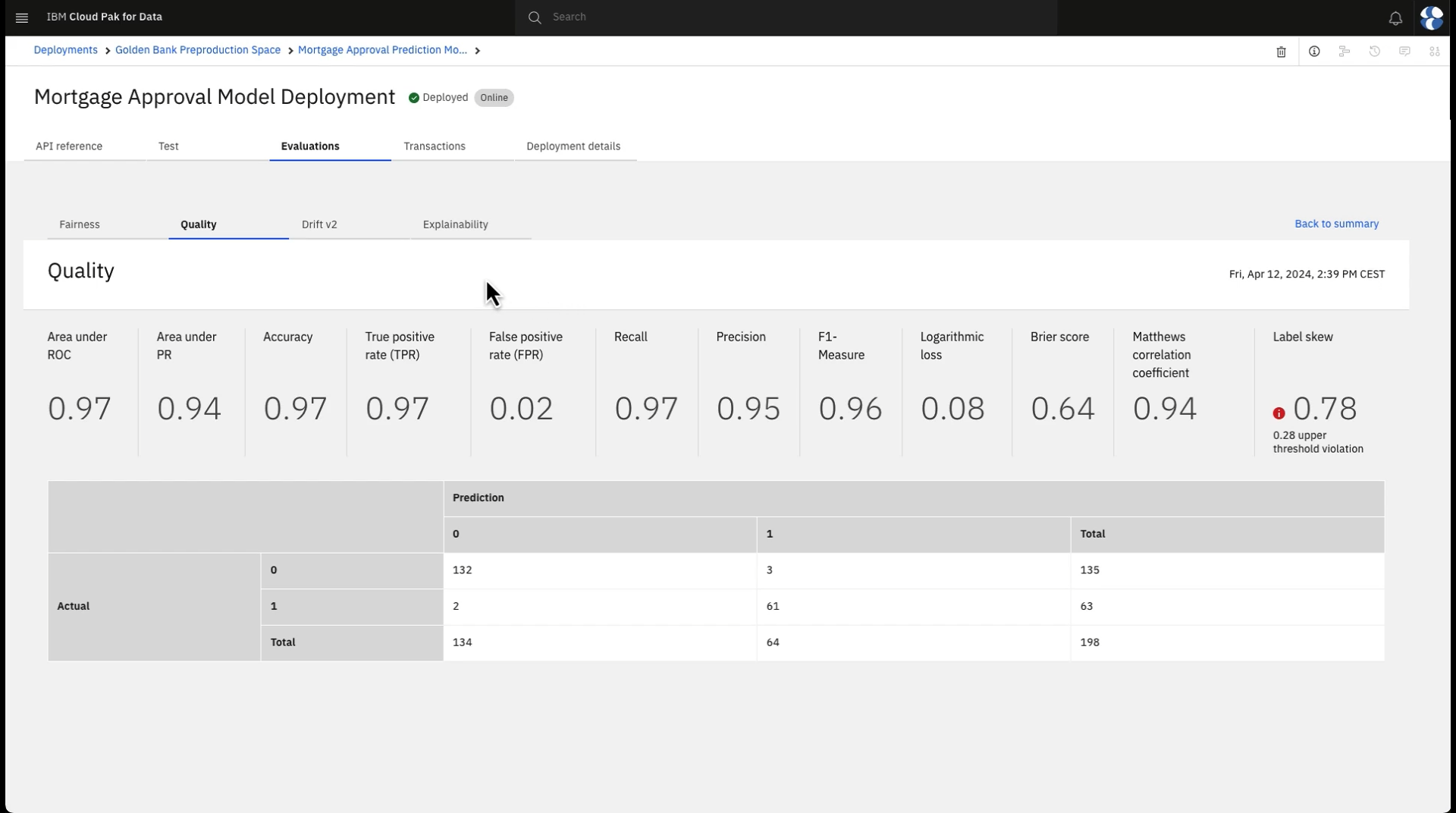
 」をクリックすると、モデル品質の詳細結果が表示されます。 ここでは、多くの品質指標の計算と、正しいモデルの判断と偽陽性・偽陰性を示す混同行列を見ることができる。 計算されたROC曲線下面積は0.9以上であり、0.7のしきい値を超えているので、モデルは品質要件を満たしている。
」をクリックすると、モデル品質の詳細結果が表示されます。 ここでは、多くの品質指標の計算と、正しいモデルの判断と偽陽性・偽陰性を示す混同行列を見ることができる。 計算されたROC曲線下面積は0.9以上であり、0.7のしきい値を超えているので、モデルは品質要件を満たしている。Back to summaryをクリックすると、モデルの詳細画面に戻ります。
進捗状況を確認する
次の画像は、Watson OpenScale での品質の詳細を示しています。 さて、モデルの品質を観察したところで、モデルの公平性を観察してみましょう。
です
タスク6:公平性を保つためにモデルモニターを観察する
このタスクをプレビューするには、07:20から始まるビデオをご覧ください。
Watson OpenScale フェアネス・モニターは、モデルのフェアネスを評価するための一連のメトリクスを生成します。 公平性メトリックを使用して、モデルがバイアスのある結果を生成するかどうかを判別できます。 以下の手順に従って、モデルの公平性を観察してください:
公平性セクションで、設定アイコン「
」をクリックする。 ここでは、性別に関係なく応募者が公平に扱われていることを確認するために、モデルがレビューされていることがわかります。 女性は、公平性が測定されているモニター対象グループとして識別され、公平性のしきい値は少なくとも 80% になります。 公平性モニターは、公平性を判別するために異なる影響方式を使用します。 差別的影響は、モニター対象グループの好ましい結果の割合を、参照グループの好ましい結果の割合と比較します。Xをクリックしてウィンドウを閉じ、モデルの評価画面に戻ります。
公平性セクションで、詳細アイコン「
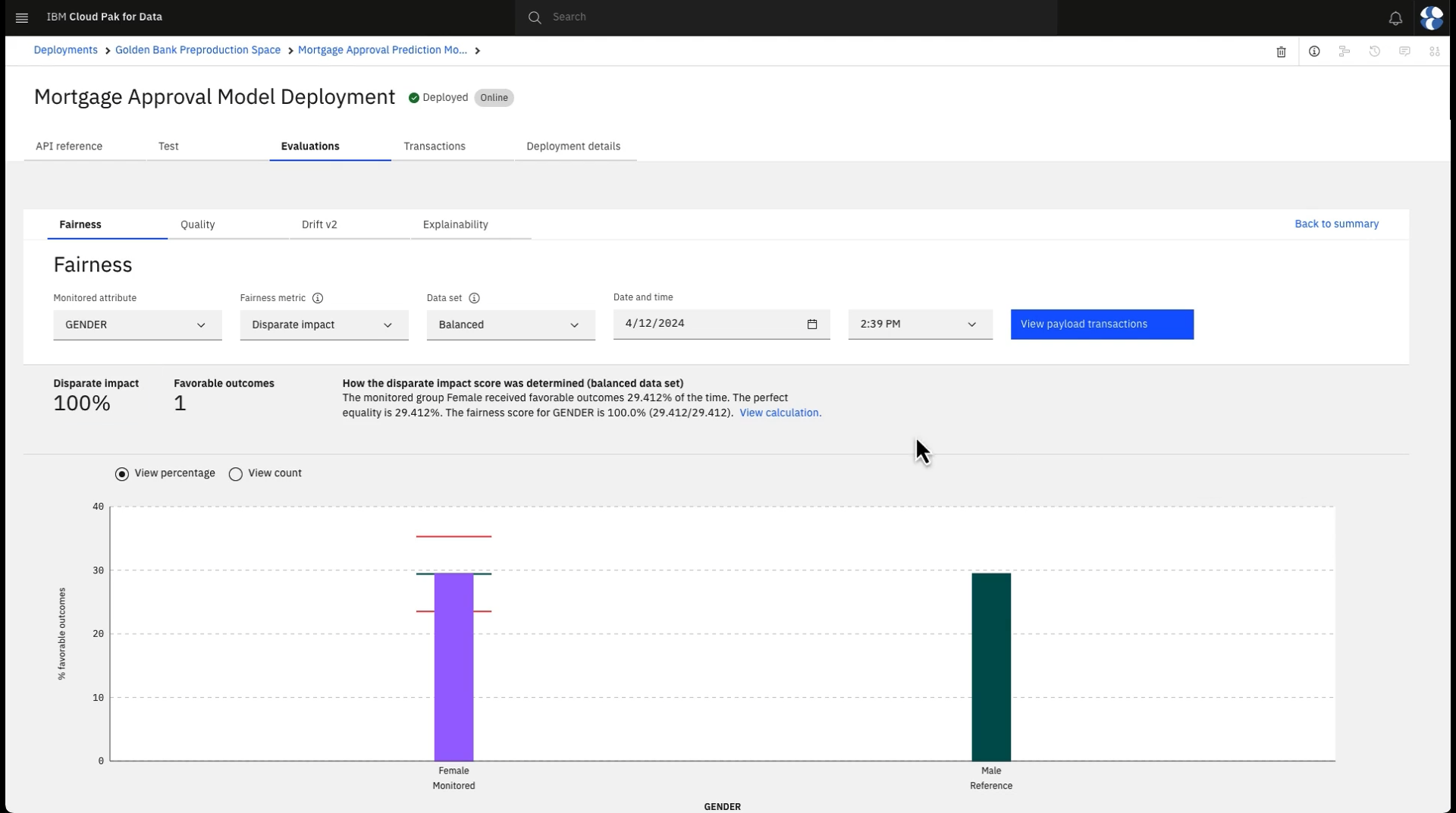
」をクリックすると、モデルの公平性の詳細結果が表示される。 ここでは、自動的に承認される男女の申請者の割合と、100%を超える公平性スコアが示されている。特定されたデータセットに注意。 公平性の測定基準が最も正確であることを保証するために、Watson OpenScale は摂動を使用し、保護された属性と関連するモデル入力のみが変更され、他の機能は変更されない結果を決定します。 摂動により、特徴量の値が参照グループからモニター対象グループに (またはその逆に) 変更されます。 これらの追加のガードレールは、「平衡型」データ・セットが使用されている場合に公平性を計算するために使用されますが、ペイロードまたはモデルのトレーニング・データのみを使用して公平性の結果を表示することもできます。 モデルは公正に動作しているため、このメトリックの詳細を追加する必要はありません。

Back to summaryをクリックすると、モデルの詳細画面に戻ります。
進捗状況を確認する
次の画像は、Watson OpenScale のフェアネス詳細を示しています。 モデルの公正さを観察できたので、モデルの説明可能性を観察できる。
タスク7:モデルモニターのドリフトを観察する
このタスクをプレビューするには、08:25から始まるビデオをご覧ください。
Watson OpenScale ドリフトモニターは、データの経時変化を測定し、モデルの一貫した結果を保証します。 ドリフト評価を使用して、モデルの出力、予測の精度、入力データの分布の変化を確認します。 以下の手順に従って、モデルのドリフトを観察してください:
ドリフトセクションで、設定アイコン「
」をクリックする。 ここにドリフトのしきい値がある。 出力ドリフトは、モデルの信頼度分布の変化を測定する。 モデルの品質ドリフトは、推定された実行時精度とトレーニング精度を比較することで、精度の低下を測定する。 特徴ドリフトは、重要な特徴の値分布の変化を測定する。 設定には、選択された機能の数と最も重要な機能も表示されます。Xをクリックしてウィンドウを閉じ、モデルの評価画面に戻ります。
ドリフトセクションで、詳細アイコン「
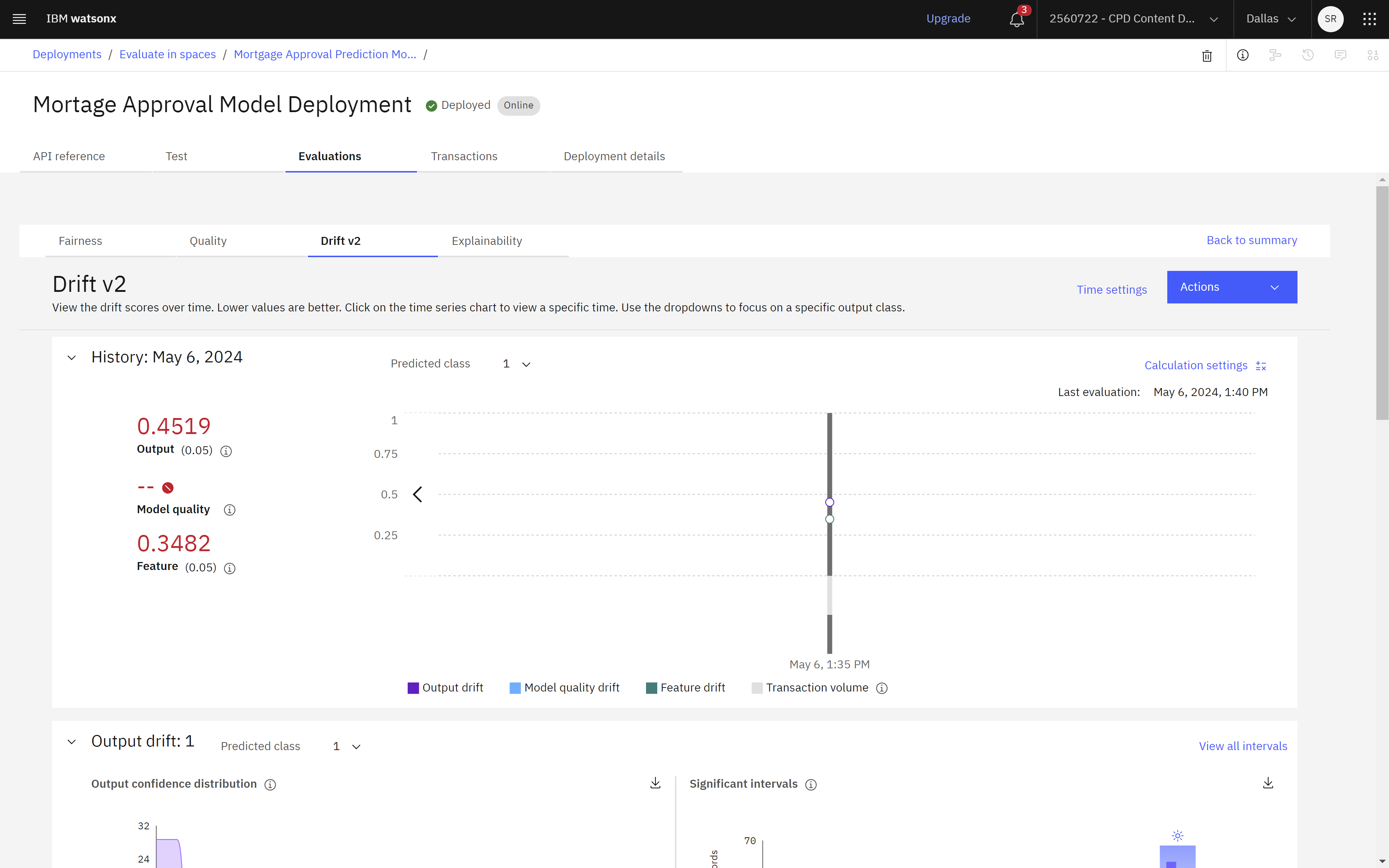
」をクリックすると、モデルのドリフト詳細結果が表示されます。 時系列チャートで、各メトリックスコアの経年変化の履歴を見ることができます。 数値は低い方が良いので、この場合、結果はコンフィギュレーションで設定されている上限しきい値を超えている。 次に、スコア出力と特徴ドリフトの計算方法の詳細を表示します。 また、各機能の詳細を表示して、Watson OpenScale が生成するスコアにどのように貢献しているかを理解することもできます。Back to summaryをクリックすると、モデルの詳細画面に戻ります。
進捗状況を確認する
次の図は、Watson OpenScale でのドリフトの詳細を示しています。 モデル・ドリフトを観察したので、モデルの説明可能性を観察することができます。
タスク8:モデルのモニターを観察し、説明可能性を確認する
このタスクをプレビューするには、09:10から始まるビデオをご覧ください。
また、モデルがどのようにしてその決定に至ったかを理解することも重要である。 この理解は、ローン承認に関わる人々に決定を説明するためにも、モデル・オーナーに決定が有効であることを保証するためにも必要である。 これらの決定を理解するために、以下の手順に従ってモデルの説明可能性を観察する:
取引タブをクリックします。
グラフ上で時間枠を選択すると、その期間の取引リストが表示される。
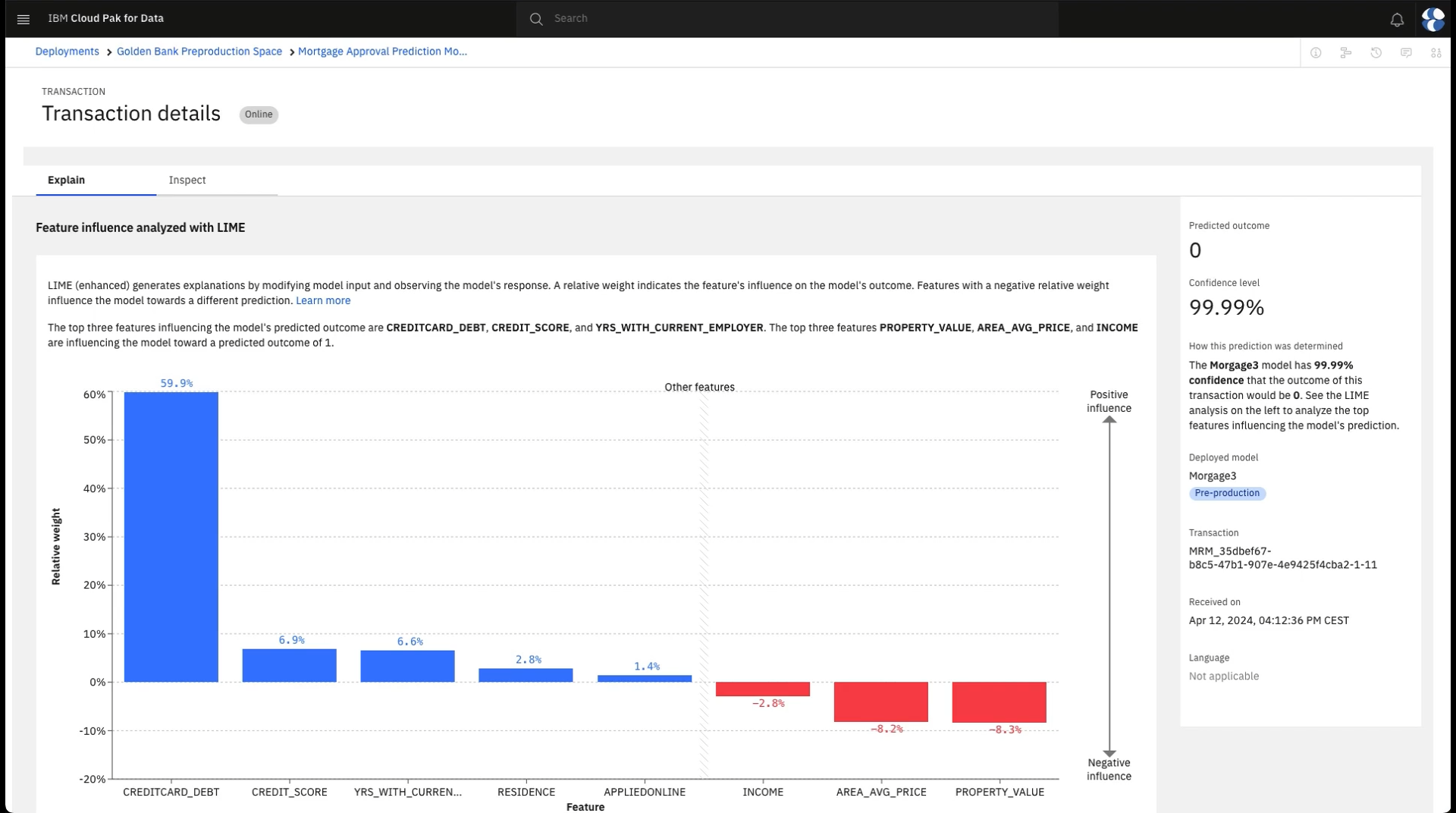
任意のトランザクションについて、 アクション 列の下の 説明 をクリックしてください。 ここに、この決定の詳細な説明が表示されます。 モデルへの最も重要な入力と、最終結果に対する各入力の重要度が表示されます。 青い棒はモデルの決定を支持する傾向のあるインプットを表し、赤い棒は別の決定につながったかもしれないインプットを表す。 たとえば、ある申込者は十分な収入があって審査に通るかもしれないが、クレジットヒストリーが乏しく、負債が多いために審査に通らないというケースだ。 この説明を検討して、モデルの決定の基礎について満足するようにしてください。
オプション:モデルがどのように決定したかをさらに掘り下げたい場合は、Inspectタブをクリックします。 インスペクト 機能を使用して決定を分析し、いくつかの入力を少し変更しただけで異なる決定になるような感度の領域を見つけます。 分析を実行するをクリックすると、Watson OpenScale が異なる結果を得るために必要な最小限の変更を明らかにします。 Analyze features onlyを選択すると、制御可能な機能のみに変更を限定することができます。
進捗状況を確認する
次の図は、Watson OpenScale におけるトランザクションの説明可能性を示しています。 あなたは、このモデルが正確であり、すべての応募者を公平に扱っていると判断した。 Now, you can advance the model to the next phase in its lifecycle.
次のステップ
チュートリアルの追加をお試しください:
その他のリソース
親トピック: クイック・スタート・チュートリアル