当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
クイック・スタート: SPSS Modeler を使用したモデルを作成する
最終更新: 2024年11月28日
SPSS Modelerを使用して、モデルを作成、トレーニング、およびデプロイできます。 SPSS Modelerについて読み、ビデオを見て、初心者向けのチュートリアルに従い、コーディングは必要ありません。
- 必須のサービス
- watsonx.aiStudio (SPSS Modelerを含む)
- watsonx.aiランタイム
基本的なワークフローには、以下のタスクが含まれます:
- サンドボックスプロジェクトを開く。 プロジェクトは、データを処理するために他のユーザーと共同作業できる場所です。
- SPSS Modeler フローをプロジェクトに追加します。
- キャンバス上のノードを構成し、フローを実行します。
- モデルの詳細を確認し、モデルを保存します。
- モデルをデプロイしてテストします。
SPSS Modeler について読む
SPSS Modeler フローを使用すると、ビジネスの専門知識を活用して予測モデルを迅速に開発し、それらをビジネス・オペレーションにデプロイして、意思決定を改善させることができます。 長年定評のある SPSS Modeler クライアントソフトウェアと、それが使用する業界標準の CRISP-DM モデルを中心に設計されたフローインターフェースは、データからより良いビジネス結果まで、データマイニングのプロセス全体を促進します。
SPSS Modeler には、マシン学習、人工知能、および統計に基づいたさまざまなモデル作成方法が用意されています。 ノード・パレットを利用して、データから新しい情報を引き出したり、予測モデルを作成することができます。 各手法によって、利点や適した問題の種類が異なります。
SPSS Modeler を使用したモデルの作成に関するビデオを見る
 このビデオを見て、 SPSS Modeler フローを作成して実行し、機械学習モデルをトレーニングする方法を確認してください。
このビデオを見て、 SPSS Modeler フローを作成して実行し、機械学習モデルをトレーニングする方法を確認してください。
このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
SPSS Modeler を使用してモデルを作成するチュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
- タスク1:プロジェクトを開く。
- タスク2:プロジェクトにデータセットを追加する
- Task 3: SPSS Modeler フローを作成する
- タスク 4: SPSS Modelerフローにノードを追加する
- タスク 5: SPSS Modeler フローを実行し、モデルの詳細を調査する
- タスク6:モデルの評価
- タスク7:新しいデータを使ったモデルのデプロイとテスト
このチュートリアルを完了するための所要時間は約 30 分です。
データの例
このチュートリアルで使用されるデータ・セットは、カリフォルニア大学アーバイン校のデータ・セットで、一定期間の入院患者を基にした大規模な研究の結果である。 このモデルは、慢性腎臓疾患の予測に役立つ 3 つの重要な要因を使用します。
このチュートリアルを完了するためのヒント
このチュートリアルを成功させるためのヒントを紹介します。
ビデオのピクチャー・イン・ピクチャーを使う
ヒント:ビデオを開始し、チュートリアルをスクロールすると、ビデオはピクチャ・イン・ピクチャ・モードに移行します。 ピクチャー・イン・ピクチャーで最高の体験をするために、ビデオの目次を閉じてください。 ピクチャ・イン・ピクチャ・モードを使用すると、このチュートリアルのタスクを完了しながらビデオを追うことができます。 各タスクのタイムスタンプをクリックしてください。
次のアニメーション画像は、ビデオのピクチャー・イン・ピクチャーと目次機能の使い方を示しています:

地域の助けを借りる
このチュートリアルで助けが必要な場合は、watsonxコミュニティーのディスカッション・フォーラムで質問したり、答えを見つけることができます。
ブラウザのウィンドウを設定する
このチュートリアルを最適に完了するには、Cloud Pak for Data を 1 つのブラウザ ウィンドウで開き、このチュートリアルのページを別のブラウザ ウィンドウで開いておくと、2 つのアプリケーションを簡単に切り替えることができます。 2つのブラウザウィンドウを横に並べると、より見やすくなります。

ヒント: このチュートリアルを完了する際に、ユーザーインターフェイスでガイドツアーが表示された場合は、後でをクリックしてください。
タスク 1:プロジェクトを開く
SPSS Modeler フローを格納するプロジェクトが必要です。 サンドボックス・プロジェクトを使うことも、プロジェクトを作成することもできる。
ナビゲーションメニュー「
 」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択する
」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択するサンドボックスプロジェクトを開く。 新しいプロジェクトを使いたい場合:
新規プロジェクトをクリックしてください。
「空のプロジェクトの作成」を選択します。
プロジェクトの名前と任意の説明を入力します。
既存の オブジェクト・ストレージ・サービス・インスタンス を選択するか、または新規作成します。
「作成」 をクリックします。
詳細またはビデオについては、プロジェクトの作成をご覧ください。
 進捗状況を確認する
進捗状況を確認する
以下の画像は新しいプロジェクトを示している

タスク 2: データセットをプロジェクトに追加する
このタスクをプレビューするには、00:13から始まるビデオを見てください。
このチュートリアルでは、サンプルデータセットを使用します。 以下の手順に従って、サンプル・データ・セットをプロジェクトに追加してください:
リソースハブ「UCI MLリポジトリ:慢性腎臓病データセット」にアクセスする。
「プレビュー」をクリックします。 この分析の一環として利用できる慢性腎臓疾患の予測に役立つ重要な要因として、被験者の年齢、血清クレアチニン検査結果、糖尿病検査結果の 3 つがあります。 クラス値は、患者が以前に腎臓病の診断を受けたことがあるかどうかを示します。
プロジェクトに追加をクリックしてください。
リストからプロジェクトを選択し、 追加をクリックしてください。
プロジェクトの表示をクリックしてください。
プロジェクトの 資産 ページで、 UCI ML Repository Chronic Kidney Disease Data Set.csv ファイルを見つけます。
進捗状況を確認する
次の画像は、プロジェクトの資産タブを示しています。

タスク 3: SPSS Modeler フローの作成
このタスクをプレビューするには、01:11から始まるビデオを見てください。
以下の手順に従って、プロジェクトに SPSS Modeler フローを作成してください:
New asset > Build models as visual flow をクリックします。
フローの名前と説明を入力してください。
ランタイム定義の場合は、 デフォルト SPSS Modeler S 定義を受け入れます。
「作成」 をクリックします。 これにより、フローの作成に使用するフロー・エディターが開きます。
進捗状況を確認する
以下の画像はフローエディターを示しています

タスク 4: SPSS Modeler フローにノードを追加する
このタスクをプレビューするには、01:31から始まるビデオを見てください。
データをロードしたら、データを変換しなければならない。 トランスフォーマーとエスティメーターをキャンバス上にドラッグし、データソースに接続してシンプルなフローを作成します。 パレットから以下のノードを使用します:
データ資産: プロジェクトから CSV ファイルをロードします
データ区分: データを学習セグメントとテスト・セグメントに分割します
タイプ: データ・タイプを設定します。 これを使用して、
classtargetC5.0: 分類アルゴリズム
分析: モデルを表示し、その正確度を確認します
表: 予測を使用したデータのプレビュー
以下の手順でフローを作成する:
データ資産ノードを追加します:
インポート セクションから、 データ資産 ノードをキャンバスにドラッグします。
データ資産 ノードをダブルクリックして、データ・セットを選択してください。
Data asset > UCI ML Repository Chronic Kidney Disease Data Set.csv を選択します。
「選択」をクリックします。
データ資産のプロパティーを表示します。
保存 をクリックします。
パーティション・ノードを追加します:
フィールド操作 セクションから、 パーティション ノードをキャンバスにドラッグします。
データ資産 ノードを パーティション ノードに接続します。
パーティション ノードをダブルクリックして、そのプロパティーを表示します。 デフォルトのデータ区分では、データの半分をトレーニング用に、残りの半分をテスト用に分割しています。
保存 をクリックします。
Typeノードを追加する:
フィールド操作 セクションから、 タイプ ノードをキャンバスにドラッグします。
パーティション ノードを タイプ ノードに接続します。
タイプ ノードをダブルクリックして、そのプロパティーを表示します。 データ型ノードは、各フィールドの測定のレベルを指定します。 このソース・データ・ファイルでは、4 つの異なる測定レベル (連続型、カテゴリー型、名義型、順序型、フラグ型) を使用しています。
classclass保存 をクリックします。
C5.0分類アルゴリズム・ノードを追加します:
モデリング セクションから、 C5.0 ノードをキャンバスにドラッグします。
タイプ ノードを C5.0 ノードに接続します。
C5.0 ノードをダブルクリックして、そのプロパティーを表示します。 デフォルトでは、 C5.0 アルゴリズムはデシジョン・ツリーが作成します。 C5.0 モデルは、最大の情報ゲインを提供するフィールドに基づいてサンプルを分割することによって作業します。 最初の分割によって定義された各サブサンプルは、通常は別のフィールドに基づいて再度分割され、サブサンプルがそれ以上分割できなくなるまでプロセスが繰り返されます。 最後に、最下位レベルの分割が再検討され、モデルの価値に大きく寄与しない分割が削除されます。
このノードで定義された設定を使用するに切り替えます。
対象の場合は、 クラスを選択してください。
入力 セクションで、 列の追加をクリックしてください。
フィールド名の横のチェックボックスをオフにします。
年齢、 sc、 dmを選択してください。
「OK」をクリックします。
保存 をクリックします。
進捗状況を確認する
以下の画像は完成したフローを示している

タスク 5: SPSS Modeler フローを実行し、モデルの詳細を調べる
このタスクをプレビューするには、04:20から始まるビデオをご覧ください。
フローが設計できたので、以下の手順に従ってフローを実行し、ツリー図を調べて決定点を確認する:
C5.0 ノードを右クリックし、 実行を選択してください。 フローを実行すると、キャンバス上に新しいモデル・ナゲットが生成されます。
モデル・ナゲットを右クリックし、 モデルの表示 を選択してモデルの詳細を表示します。
モデルの要約を提供する モデル情報 を表示します。
上位の決定ルールをクリックしてください。 テーブルには、さまざまな入力フィールドの値に基づいて個々のレコードを下位ノードに割り当てるために使用された一連のルールが表示されます。
特徴量の重要度をクリックしてください。 グラフには、モデルを推定する際の各予測値の相対的な重要度が表示されます。 このことから、血清クレアチニンが最も重要な因子であり、糖尿病が次に重要な因子であることがわかります。
ツリー図をクリックしてください。 同じモデルがツリーの形式で表示され、各デシジョン・ポイントにノードが表示されます。
一番上のノードにカーソルを合わせると、データセット内の全レコードのサマリーが表示されます。 データセットのほぼ40%の症例は腎臓病と診断されていない。 ツリーは、原因となる可能性がある要因に関する追加のヒントを提供できます。
これは血清クレアチニンによる分岐を示している。
血清クレアチニンが1.25より大きい記録を示すブランチを見直してください。 この場合、100% の患者が腎臓病の診断で陽性となる。
血清クレアチニンが1.25以下である記録を示すブランチを確認してください。 これらの患者の約 80% は腎臓疾患の陽性診断を受けていないが、血清クレアチニンが低い患者の約 20% は依然として腎臓疾患と診断されている。
sc<=1.250に由来する枝が、糖尿病によって分割されていることに注目してほしい。
血清クレアチニンが低く(sc<=1.250)、糖尿病と診断された(dm=yes)患者を示す枝を見直す。 これらの患者の100%が腎臓病と診断された。
血清クレアチニンが低く(sc<=1.250)、糖尿病がない(dm=no)患者を示す枝を見直すと、85%は腎臓病と診断されなかったが、15%はやはり腎臓病と診断された。
dm=noに由来する枝に注目。これは、最後の重要な要素である年齢によって分割されている。
14歳以下(age <= 14)の患者を示す枝を見直す。 この枝によると、血清クレアチニンが低く、糖尿病のない若い患者の75%が腎臓病になる危険性があった。
14歳以上(age > 14)の患者を示す枝を見直す。 この枝によると、血清クレアチニンが低く、糖尿病のない14歳以上の患者のうち、腎臓病になる危険性があったのはわずか12%であった。
モデルの詳細を閉じます。
進捗状況を確認する
ツリー図を以下に示す

タスク6:モデルの評価
このタスクをプレビューするには、07:24から始まるビデオをご覧ください。
分析ノードと表ノードを使用してモデルを評価するには、以下の手順に従います:
出力 セクションから、 分析 ノードをキャンバスにドラッグします。
モデル ナゲットを 分析 ノードに接続します。
分析 ノードを右クリックし、 実行を選択してください。
Outputsパネルから、Analysisを開くと、モデルがほぼ95%の確率で腎臓病の診断を正しく予測したことがわかります。 分析を閉じます。
分析 ノードを右クリックし、 ブランチをモデルとして保存を選択してください。
モデル名の場合は、
と入力します。保存 をクリックします。
閉じるをクリックします。
出力 セクションから、 表 ノードをキャンバスにドラッグします。
モデル ナゲットを 表 ノードに接続します。
テーブルノードを右クリックし、データのプレビューを選択します。
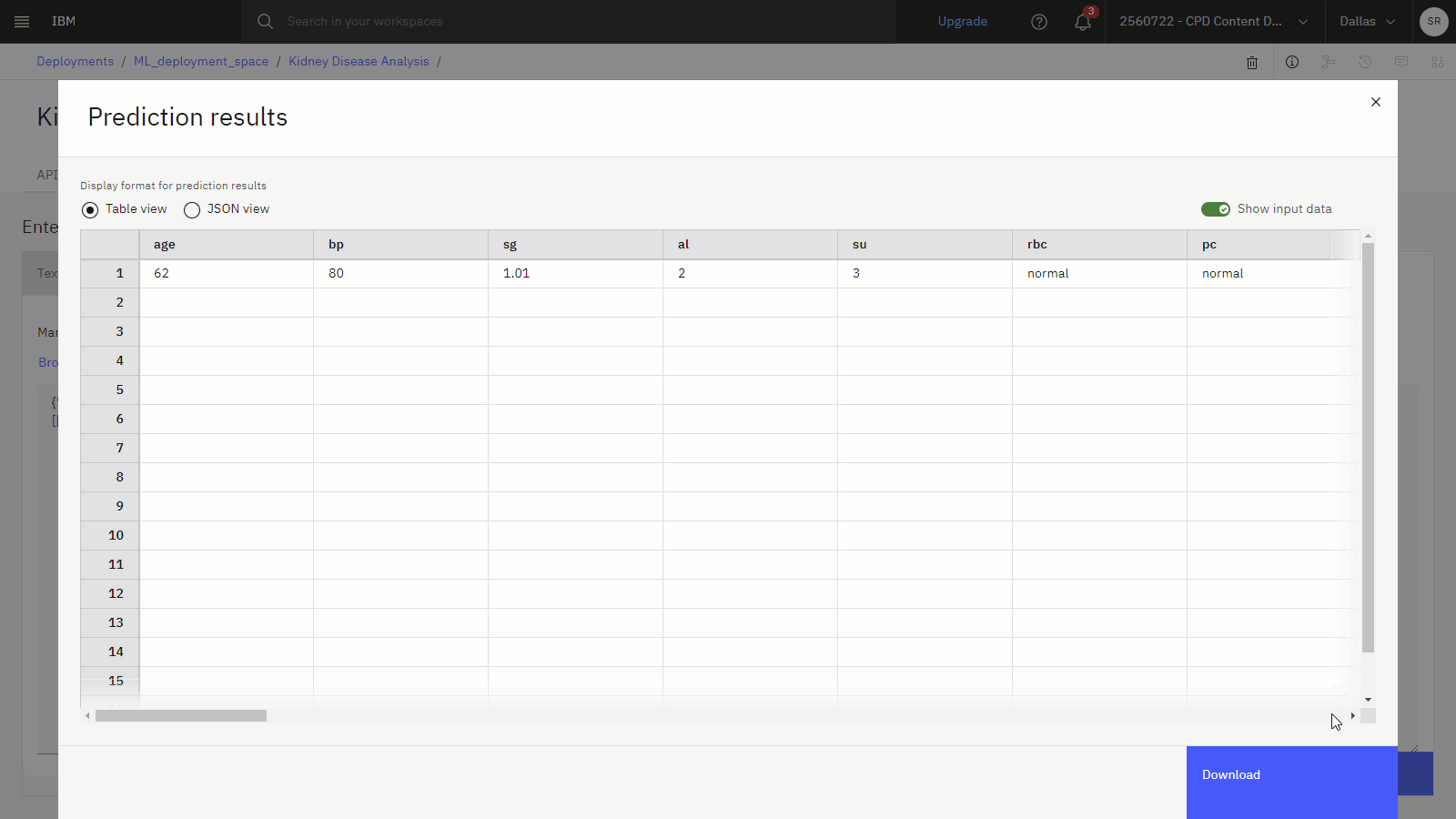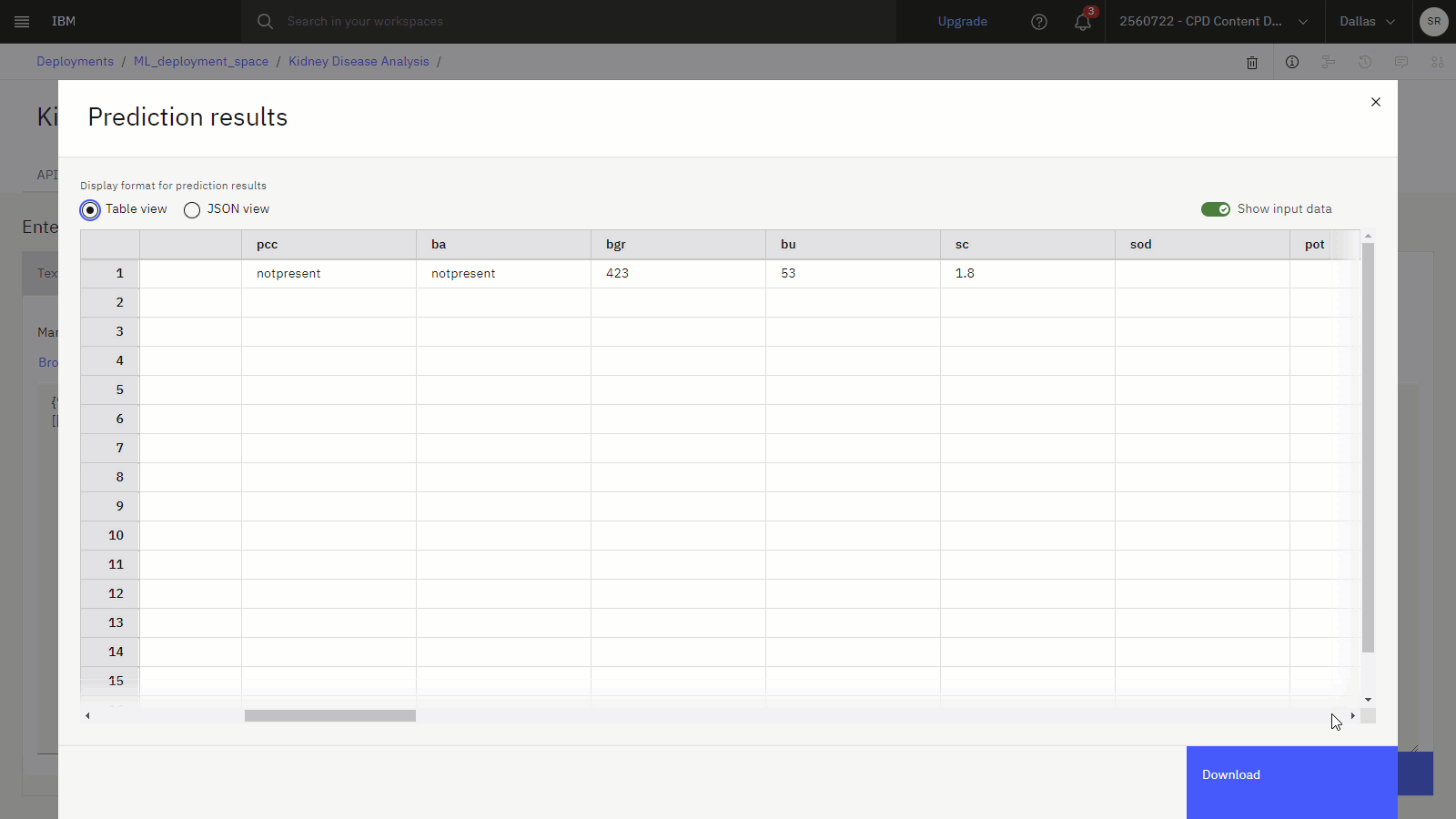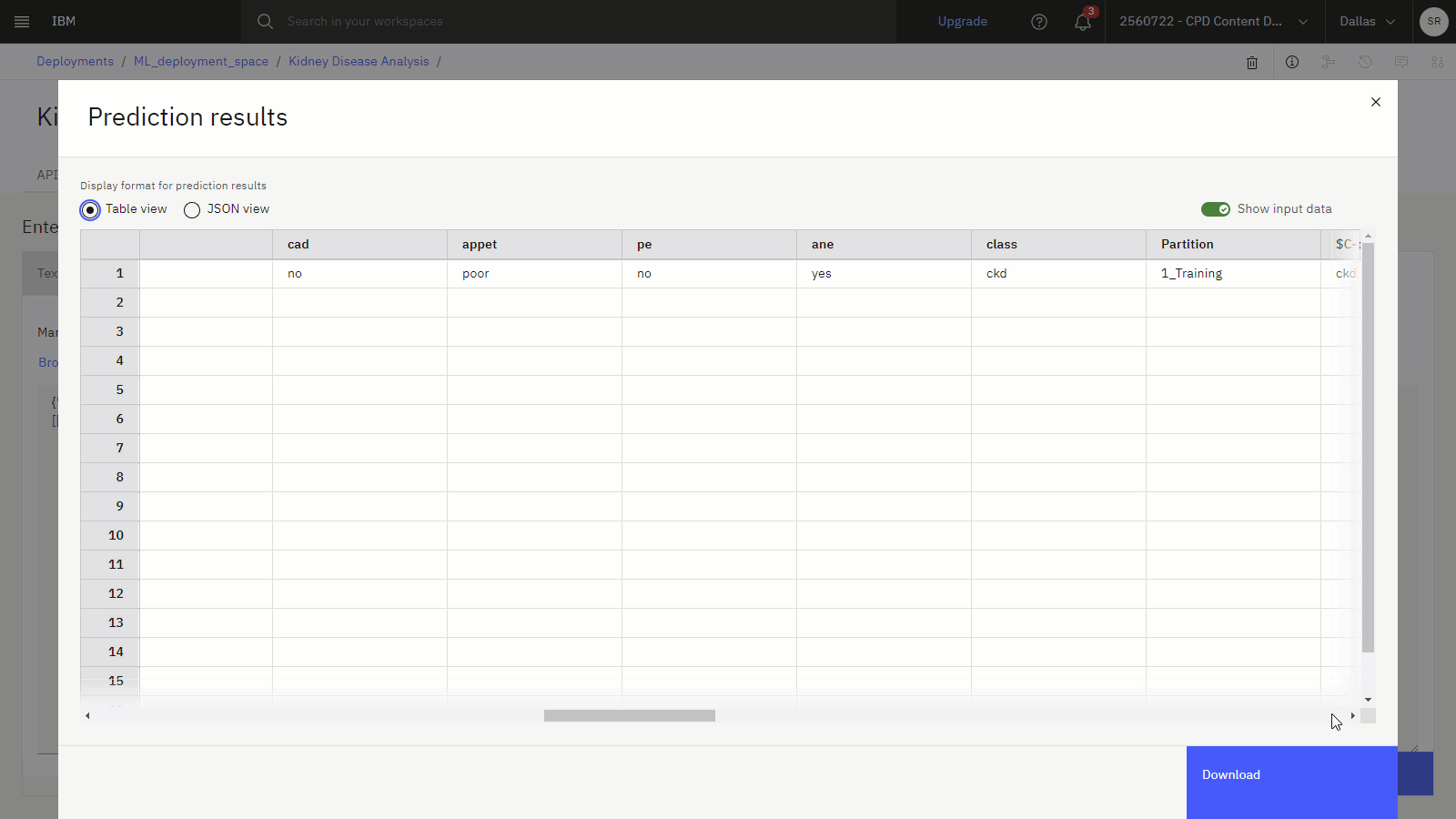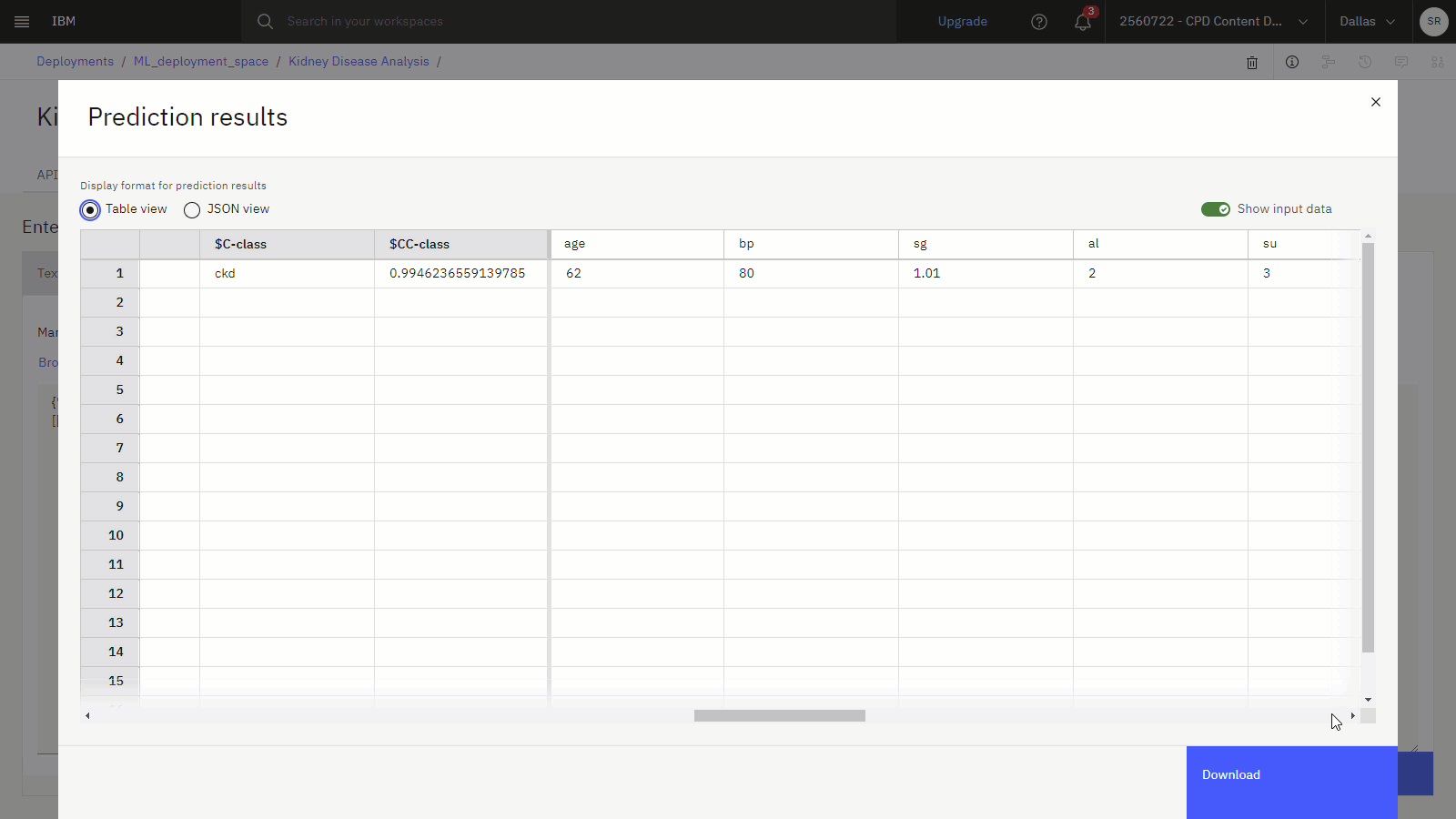
プレビューが表示されたら、最後の 2 列までスクロールします。 $C-Class 列には腎臓病の予測が含まれ、また $CC-Class 列にはその予測の信頼性スコアが示されます。
プレビューを閉じます。
進捗状況を確認する
以下の画像は、プレビューテーブルの予測です

タスク7:新しいデータを使ったモデルの展開とテスト
このタスクをプレビューするには、09:10から始まるビデオをご覧ください。
最後に、このモデルを展開し、新しいデータで結果を予測するために、以下の手順に従ってください。
プロジェクトの 資産 タブに戻ります。
モデルセクションをクリックし、腎臓病分析モデルを開きます。
配備促進スペースアイコン「
 」をクリックする。
」をクリックする。既存のデプロイメント・スペースを選択してください。 デプロイメント・スペースを持っていない場合は、新しいデプロイメント・スペースを作成できます:
スペース名を指定してください。
ストレージ・サービスを選択してください。
機械学習サービスを選択してください。
「作成」 をクリックします。
閉じるをクリックします。
プロモート後にスペース内のモデルに移動を選択してください。
プロモートをクリックします。
モデルがデプロイメント・スペース内に表示されたら、 新規デプロイメントをクリックしてください。
デプロイメント・タイプとして オンライン を選択してください。
デプロイメントの名前を指定します。
「作成」 をクリックします。
デプロイメントが完了したら、デプロイメント名をクリックして、デプロイメントの詳細ページを表示します。
テスト タブに移動します。 デプロイされたモデルは、デプロイメントの詳細ページから 2 つの方法でテストできます:1 つはフォームを使用してテストし、もう 1 つは JSON コードを使用してテストします。
JSON入力をクリックし、以下のテストデータをコピーして、既存のJSONテキストを置き換えるように貼り付けます:
{ "input_data": [ { "fields": [ "age", "bp", "sg", "al", "su", "rbc", "pc", "pcc", "ba", "bgr", "bu", "sc", "sod", "pot", "hemo", "pcv", "wbcc", "rbcc", "htn", "dm", "cad", "appet", "pe", "ane", "class" ], "values": [ [ "62", "80", "1.01", "2", "3", "normal", "normal", "notpresent", "notpresent", "423", "53", "1.8", "", "", "9.6", "31", "7500", "", "no", "yes", "no", "poor", "no", "yes", "ckd" ] ] } ] }予測 をクリックして、62 歳の人が糖尿病と血清クレアチニン比 1.8 が腎臓病と診断される可能性が高いかどうかを予測します。 結果の予測は、この患者が腎臓病の診断を受ける可能性が高いことを示しています。
進捗状況を確認する
以下の画像は、予測付きのモデルデプロイメントのテストタブを示しています
今後のステップ
これで、このデータ・セットをさらに分析するために使用できます。 例えば、以下のようなタスクを実行できます:
その他のリソース
SPSS Modeler のチュートリアルをもっと見る
模型を作る他の方法を試してみよう:
詳しくは、 ビデオを参照してください。
サンプルデータセット、プロジェクト、モデル、プロンプト、ノートブックをリソースハブで見つけて、実践的な経験を積むことができます:
 ノートブックをプロジェクトに追加することで、データの分析やモデルの構築を始めることができます。
ノートブックをプロジェクトに追加することで、データの分析やモデルの構築を始めることができます。 ノートブック、データセット、プロンプト、その他のアセットを含むインポート可能なプロジェクト。
ノートブック、データセット、プロンプト、その他のアセットを含むインポート可能なプロジェクト。 プロジェクトを改良、分析、モデル構築するために追加できるデータセット。
プロジェクトを改良、分析、モデル構築するために追加できるデータセット。 プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。
プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。プロンプト・ラボで使用できる
 基盤モデル 。
基盤モデル 。SPSS Modelerコミュニティに貢献する
親トピック: クイック・スタート・チュートリアル
トピックは役に立ちましたか?
0/1000