当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
クイック・スタート: Jupyter ノートブックでの機械学習モデルの作成とデプロイする
最終更新: 2025年2月21日
watsonx.aiランタイムを使えば、Jupyterノートブックで機械学習モデルの作成、学習、デプロイができる。 Jupyter ノートブックについて読み、ビデオを見て、中間ユーザーに適したコーディングが必要なチュートリアルを受けます。
- 必須のサービス
- watsonx.ai Studio
- watsonx.ai ランタイム
基本的なワークフローには、以下のタスクが含まれます:
- サンドボックスプロジェクトを開く。 プロジェクトは、データを処理するために他のユーザーと共同作業できる場所です。
- ノートブックをプロジェクトに追加します。 ブランクのノートブックを作成することも、ファイルまたは GitHub リポジトリーからノートブックをインポートすることもできます。
- コードを追加し、ノートブックを実行します。
- モデル・パイプラインを確認し、目的のパイプラインをモデルとして保存します。
- モデルをデプロイしてテストします。
Jupyter ノートブックについて読む
Jupyter ノートブックは、対話式計算処理のための Web ベースの環境です。 ノートブックで機械学習モデルを構築することを選択した場合、Jupyter ノートブックでのコーディングに慣れておく必要があります。 データを処理する小さなコード断片を実行して、計算結果を即時に表示することができます。 このツールを使えば、データを扱うために必要なすべてのビルディングブロックを組み立て、テストし、実行し、データをwatsonx.aiRuntimeに保存し、モデルをデプロイすることができます。
Jupyter ノートブックでのモデルの作成に関するビデオを見る
 このビデオを見て、Jupyter ノートブックで機械学習モデルをトレーニング、デプロイ、およびテストする方法を確認してください。
このビデオを見て、Jupyter ノートブックで機械学習モデルをトレーニング、デプロイ、およびテストする方法を確認してください。
このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
Jupyter ノートブックでモデルを作成するためのチュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
-
- モデルを作成してトレーニングします。
- パイプラインをモデルとして保存します。
- モデルをデプロイします。
- デプロイされたモデルをテストします。
このチュートリアルを完了するための所要時間は約 30 分です。
サンプル・データ
このチュートリアルで使用するサンプル・データは、 scikit-learn の一部であるデータからのものであり、0 から 9 までの手書きの数字の画像を認識するようにモデルをトレーニングするために使用されます。
このチュートリアルを完了するためのヒント
このチュートリアルを成功させるためのヒントを紹介します。
ビデオのピクチャー・イン・ピクチャーを使う
ヒント:ビデオを開始し、チュートリアルをスクロールすると、ビデオはピクチャ・イン・ピクチャ・モードに移行します。 ピクチャー・イン・ピクチャーで最高の体験をするために、ビデオの目次を閉じてください。 ピクチャ・イン・ピクチャ・モードを使用すると、このチュートリアルのタスクを完了しながらビデオを追うことができます。 各タスクのタイムスタンプをクリックしてください。
次のアニメーション画像は、ビデオのピクチャー・イン・ピクチャーと目次機能の使い方を示しています:

地域の助けを借りる
このチュートリアルに関してサポートが必要な場合は、 watsonxコミュニティ ディスカッション フォーラムで質問したり、回答を見つけたりすることができます。
ブラウザのウィンドウを設定する
このチュートリアルを最適に完了するには、Cloud Pak for Data を 1 つのブラウザ ウィンドウで開き、このチュートリアルのページを別のブラウザ ウィンドウで開いておくと、2 つのアプリケーションを簡単に切り替えることができます。 2つのブラウザウィンドウを横に並べると、より見やすくなります。

ヒント: このチュートリアルを完了する際に、ユーザーインターフェイスでガイドツアーに遭遇した場合は、後でをクリックしてください。
タスク 1:プロジェクトを開く
データとAutoAI実験を保存するプロジェクトが必要です。 サンドボックス・プロジェクトを使うことも、プロジェクトを作成することもできる。
ナビゲーションメニュー
 から、プロジェクト > すべてのプロジェクト表示をを選択します。
から、プロジェクト > すべてのプロジェクト表示をを選択します。サンドボックスプロジェクトを開く。 新しいプロジェクトを使いたい場合:
新規プロジェクトをクリックしてください。
「空のプロジェクトの作成」を選択します。
プロジェクトの名前と任意の説明を入力します。
既存の オブジェクト・ストレージ・サービス・インスタンス を選択するか、または新規作成します。
「作成」 をクリックします。
プロジェクトが開始したら、 管理 タブをクリックし、 サービスと統合 ページを選択してください。
このタスクをプレビューするには、ビデオの00:07からご覧ください。IBM servicesタブで、Associateサービスをクリックします。
watsonx.aiランタイムインスタンスを選択します。 watsonx.aiRuntime サービスインスタンスがまだプロビジョニングされていない場合は、以下の手順に従ってください:
新規サービスをクリックします。
watsonx.aiランタイムを選択します。
「作成」 をクリックします。
リストから新しいサービス・インスタンスを選択する。
サービスを関連付けるをクリックします。
必要に応じて、キャンセルをクリックし、サービス & 統合ページに戻ります。
詳細情報やビデオの視聴については、 「プロジェクトの作成」を参照してください。
関連サービスに関する詳細については、 「関連サービスの追加」を参照してください。
 進捗状況を確認する
進捗状況を確認する
以下の画像は新しいプロジェクトを示しています
タスク2:プロジェクトにノートブックを追加する
このタスクをプレビューするには、ビデオの00:18からご覧ください。
このチュートリアルでは、サンプルノートブックを使用します。 以下の手順に従って、サンプルノートブックをプロジェクトに追加してください:
リソース ハブの「sckit-learn を使用して手書きの数字を認識する」ノートブックにアクセスします。
プロジェクトに追加をクリックしてください。
リストからプロジェクトを選択し、 追加をクリックしてください。
ノートブックの名前と説明を確認します (オプション)。
このノートブックのランタイム環境を選択してください。
「作成」 をクリックします。 ノートブック・エディターがロードされるまで待ちます。
メニューからKernel > Restart & Clear Outputをクリックし、Restart and Clear All Outputsをクリックして確認すると、最後に保存した実行の出力がクリアされます。
進捗状況を確認する
以下の画像は新しいノートブックです
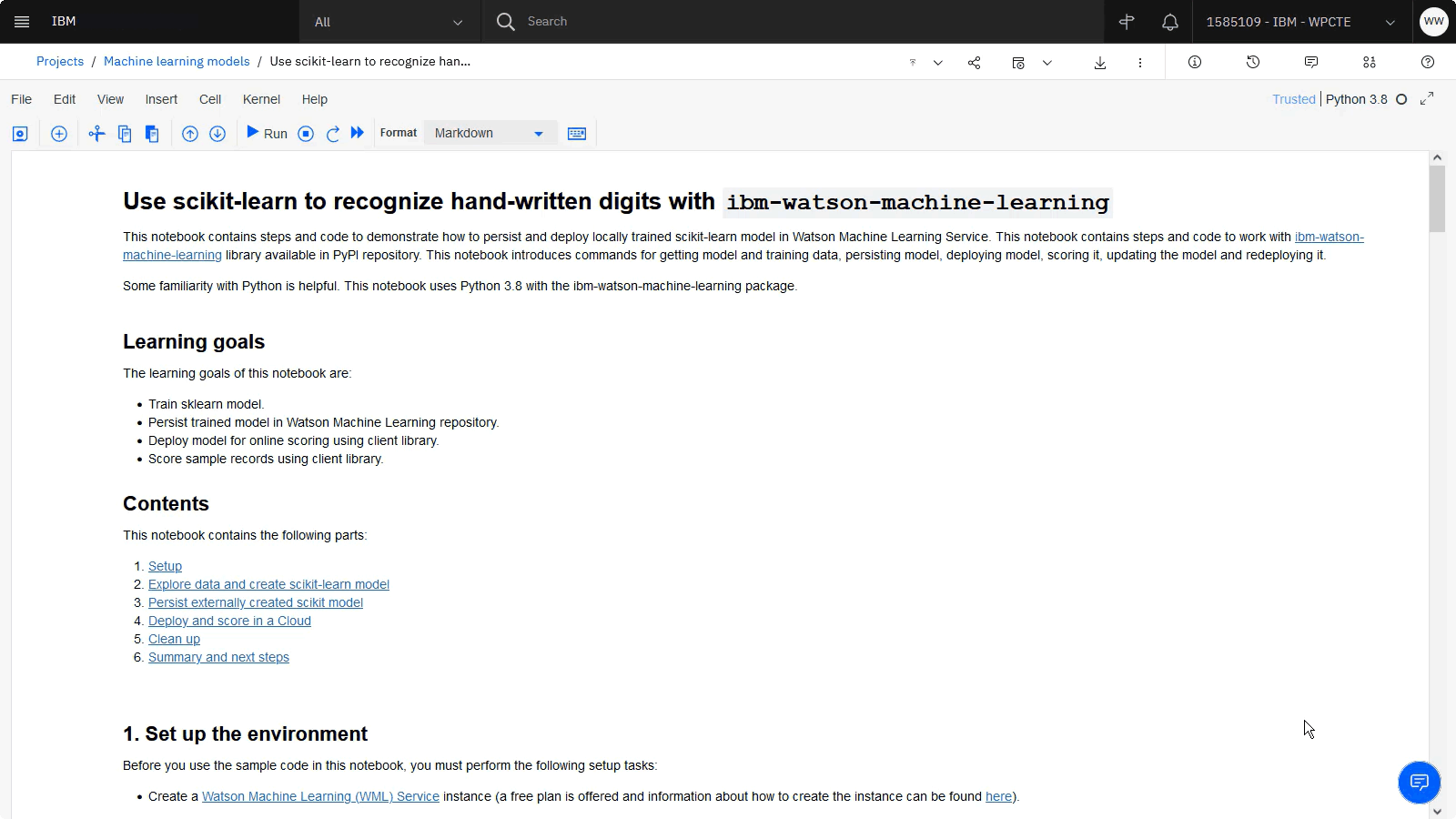
タスク3:環境のセットアップ
このタスクをプレビューするには、 00:44から始まるビデオをご覧ください。
ノートブックの最初のセクションでは、IBM Cloudの認証情報とwatsonx.aiRuntime サービスインスタンスの場所を指定して環境をセットアップします。 以下の手順に従って、ノートブックの環境をセットアップしてください:
環境のセットアップ セクションまでスクロールします。
API キーとロケーションを取得する方法を選択してください。
コマンド・プロンプトからノートブックの IBM Cloud CLI コマンドを実行します。
IBM Cloud コンソールを使用してください。
IBM Cloudリソース リストにアクセスし、 watsonx.aiランタイム サービス インスタンスを表示して、場所をメモします。
正しいエンドポイントについては、 watsonx.ai のランタイムAPIドキュメントを参照してください。 URL。 例えば、ダラスはアメリカ南部にある。
API キーと場所をセル 1 に貼り付けます。
実行アイコン
 をクリックして、セル 1 と 2 のコードを実行します。
をクリックして、セル 1 と 2 のコードを実行します。セル3を実行して
ibm-watson-machine-learningセル4を実行してAPIクライアントをインポートし、認証情報を使用してAPIクライアントのインスタンスを作成する。
client.spaces.list(limit=10)watsonx 配置で別のタブを開きます。
ナビゲーション メニュー
から、 「デプロイメント」をクリックします。新規デプロイメント・スペースをクリックしてください。
デプロイメントの名前と説明 (オプション) を追加します。
作成をクリックしてから、 新規スペースの表示をクリックしてください。
「管理」 タブをクリックします。
Space GUID をコピーしてタブを閉じると、この値が
space_id
適切な配置スペースIDをコピーして、コード
space_id = 'PASTE YOUR SPACE ID HERE'client.set.default_space(space_id)
進捗状況を確認する
以下の画像は、すべての環境変数が設定されたノートブックです
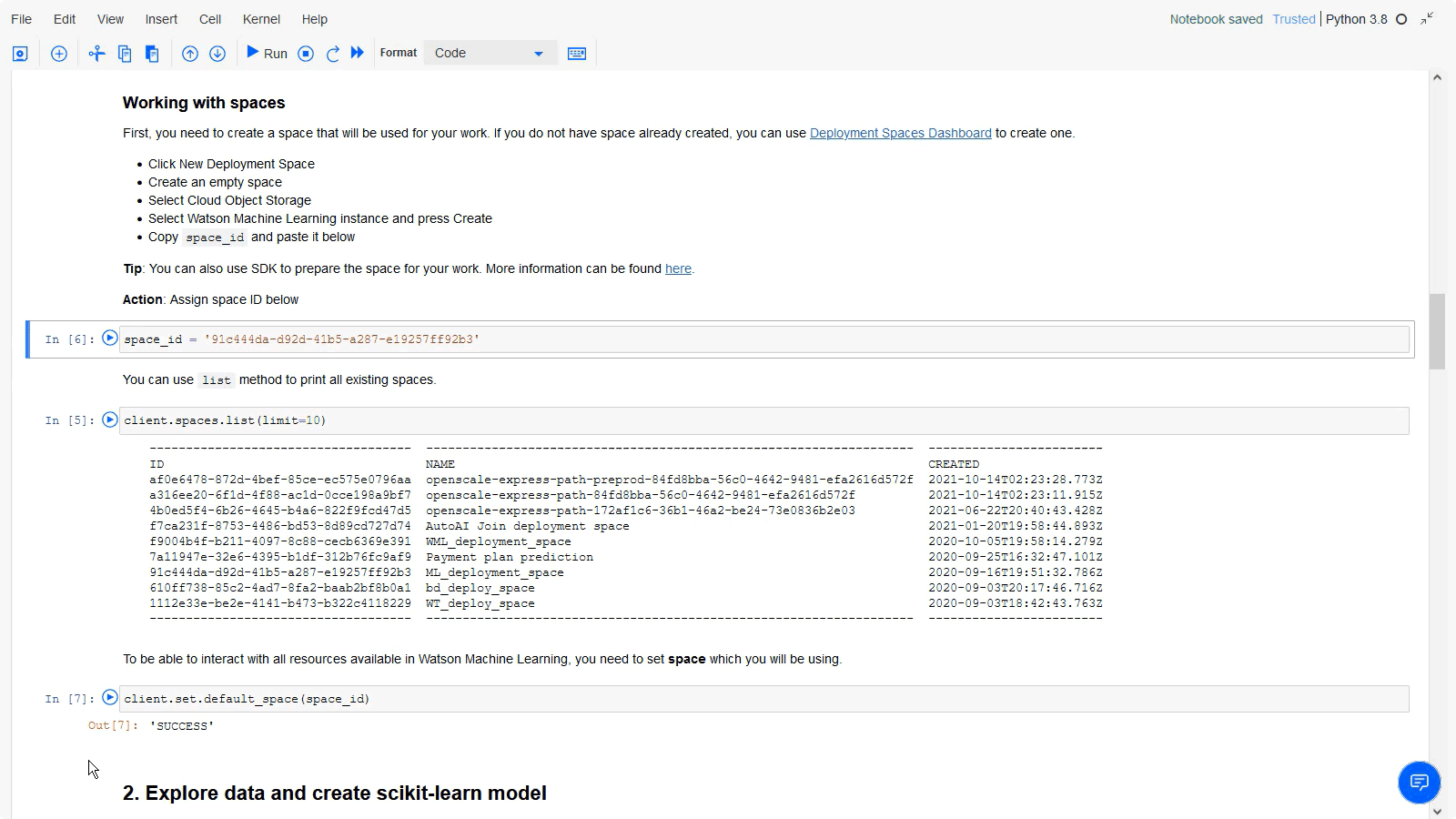
タスク4:ノートブックの実行
このタスクをプレビューするには、ビデオの02:14からご覧ください。
これですべての環境変数がセットアップされたので、ノートブックの残りのセルを実行できる。 以下の手順に従って、コメントを読み、セルを実行し、出力を確認する:
データを調べるセクションのセルを実行します。
Create a scikit-learn model セクションのセルを実行してください。
データを 3 つのデータ・セット (トレーニング、テスト、およびスコア) に分割して準備します。
パイプラインを作成します。
モデルをトレーニングします。
テスト・データを使用してモデルを評価します。
Persist locally created scikit-learn model セクションのセルを実行して、モデルを公開し、モデルの詳細を取得し、すべてのモデルを取得します。
注:Python 3.11 でランタイム 24.1 を使っている場合は、
software_spec_uidruntime-24.1-py3.11scikit-learn-1.3Deploy and score セクションのセルを実行して、オンラインデプロイメントを作成し、デプロイメントの詳細を取得し、デプロイされたモデルにスコアリング要求を送信して予測を確認します。
ファイル > 保存をクリックします。
進捗状況を確認する
以下の画像は、予想が書かれたノートブックである
タスク 5: デプロイメントスペースでデプロイされたモデルを表示し、テストする
このタスクをプレビューするには、ビデオの04:07からご覧ください。
また、配置スペースからモデルの配置を直接表示することもできます。 以下の手順に従って、スペースに配備されたモデルをテストしてください。
ナビゲーション メニュー
から、 「デプロイメント」をクリックします。スペースタブをクリックします。
リストから適切なデプロイメント・スペースを選択してください。
Scikitモデルをクリックします。
scikitモデルの展開をクリックします。
エンドポイント および コード・スニペットを確認してください。
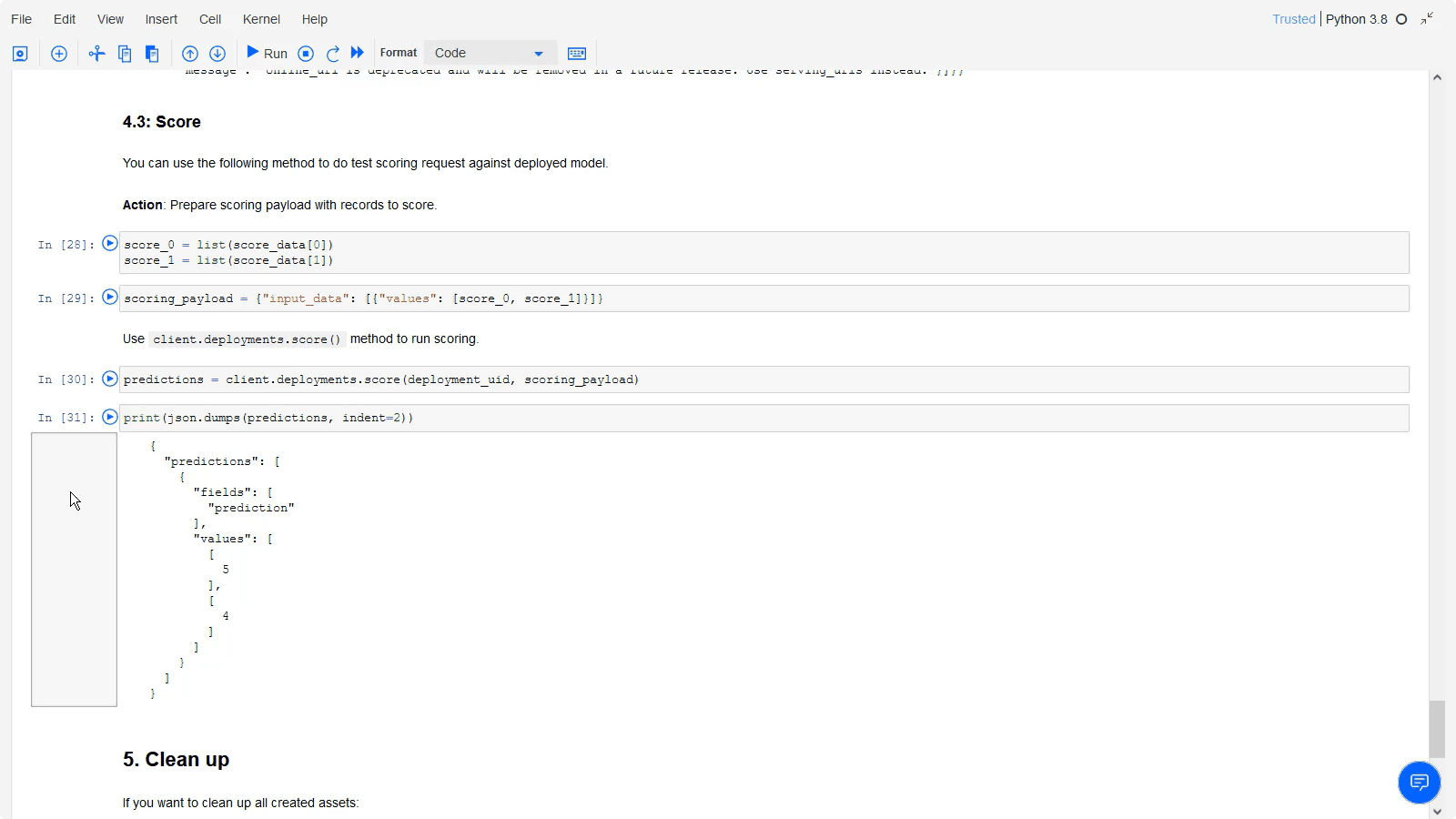
テストタブをクリックします。 以下の JSON コードを貼り付けることで、デプロイされたモデルをテストできます:
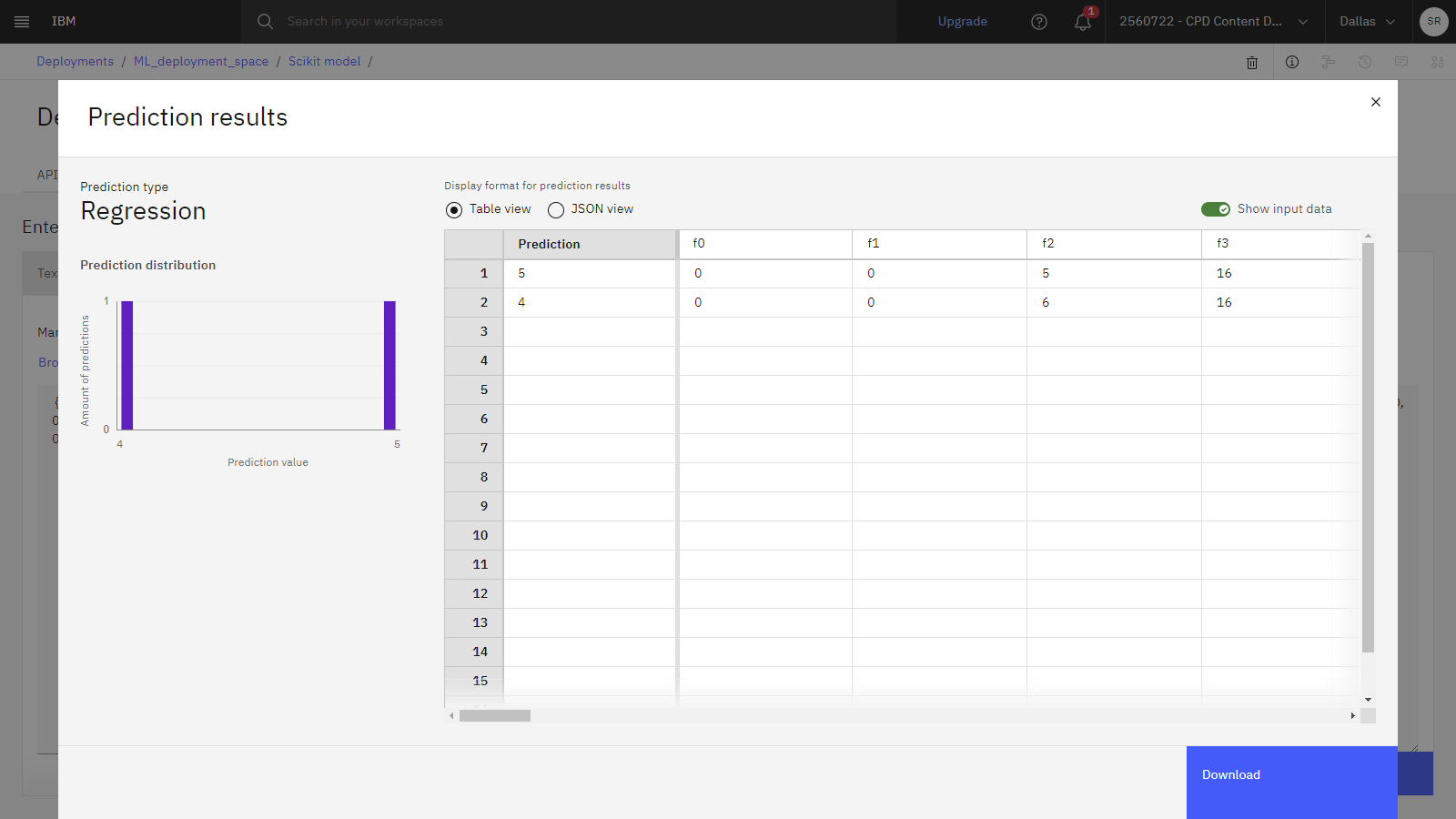
{"input_data": [{"values": [[0.0, 0.0, 5.0, 16.0, 16.0, 3.0, 0.0, 0.0, 0.0, 0.0, 9.0, 16.0, 7.0, 0.0, 0.0, 0.0, 0.0, 0.0, 12.0, 15.0, 2.0, 0.0, 0.0, 0.0, 0.0, 1.0, 15.0, 16.0, 15.0, 4.0, 0.0, 0.0, 0.0, 0.0, 9.0, 13.0, 16.0, 9.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 14.0, 12.0, 0.0, 0.0, 0.0, 0.0, 5.0, 12.0, 16.0, 8.0, 0.0, 0.0, 0.0, 0.0, 3.0, 15.0, 15.0, 1.0, 0.0, 0.0], [0.0, 0.0, 6.0, 16.0, 12.0, 1.0, 0.0, 0.0, 0.0, 0.0, 5.0, 16.0, 13.0, 10.0, 0.0, 0.0, 0.0, 0.0, 0.0, 5.0, 5.0, 15.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 8.0, 15.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 13.0, 13.0, 0.0, 0.0, 0.0, 0.0, 0.0, 6.0, 16.0, 9.0, 4.0, 1.0, 0.0, 0.0, 3.0, 16.0, 16.0, 16.0, 16.0, 10.0, 0.0, 0.0, 5.0, 16.0, 11.0, 9.0, 6.0, 2.0]]}]}予測をクリックしてください。 結果の予測は、手書きの数字が 5 と 4 であることを示しています。
進捗状況を確認する
以下の画像は、テストタブと予測結果を示しています
(オプション)タスク6:クリーンアップ
ノートブックによって作成されたすべてのアセットを削除する場合は、Machine Learningアーティファクト管理ノートブックに基づいて新しいノートブックを作成します。 このノートブックへのリンクは、このチュートリアルで使用したUse scikit-learn to recognize hand-written digits notebookのクリーンアップセクションにもあります。
次のステップ
これで、このデータ・セットをさらに分析するために使用できます。 例えば、ユーザーまたは他のユーザーは、以下のいずれかのタスクを実行できます:
その他のリソース
模型を作る他の方法を試してみよう:
詳しくは、 ビデオを参照してください。
サンプルデータセット、プロジェクト、モデル、プロンプト、ノートブックをリソースハブで見つけて、実践的な経験を積むことができます:
 データの分析とモデルの構築を開始するためにプロジェクトに追加できるノートブック。
データの分析とモデルの構築を開始するためにプロジェクトに追加できるノートブック。 ノートブック、データ セット、プロンプト、その他のアセットを含む、インポートできるプロジェクト。
ノートブック、データ セット、プロンプト、その他のアセットを含む、インポートできるプロジェクト。 プロジェクトに追加して、モデルを改良、分析、構築できるデータ セット。
プロジェクトに追加して、モデルを改良、分析、構築できるデータ セット。 プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。
プロンプト 。プロンプト・ラボで基盤モデルのプロンプトを出すために使用できます。プロンプト・ラボで使用できる
 基盤モデル 。
基盤モデル 。詳しくは、 Python クライアントのサンプルと例を参照してください。
親トピック: クイック・スタート・チュートリアル
トピックは役に立ちましたか?
0/1000