このチュートリアルでは、データ・サイエンスと MLOps のユース・ケースのために外部データ・ソースに保管された、簡潔で、前処理され、最新のデータを提供するエンドツーエンド・パイプラインを作成します。 目標は、オーケストレーション・パイプラインを使用してエンドツーエンドのワークフローを調整し、自動化された一貫性のある反復可能な結果を生成することです。 パイプラインはData RefineryそしてAutoAI,特徴エンジニアリングやハイパーパラメータの最適化など、モデル構築プロセスのさまざまな側面を自動化します。 AutoAI は、候補アルゴリズムをランク付けしてから、最適なモデルを選択します。
このチュートリアルのストーリーは、ゴールデン・バンクがオンライン・アプリケーション向けに特別低金利のモーゲージ更新を提供することでビジネスを拡大しようとしているというものです。 オンライン・アプリケーションは、銀行の顧客範囲を拡大し、銀行のアプリケーション処理コストを削減します。 意思決定を行う貸し手を支援するために、チームは Orchestration Pipelines を使用して、すべての住宅ローン申請者に関する最新データを提供するデータ・パイプラインを作成します。 データは Db2 Warehouseに保管されます。 データを準備する必要があるのは、データが不完全で古い可能性があり、データ・プライバシーおよび主権ポリシーにより難読化されているか、まったくアクセスできない可能性があるためです。 次に、チームは信頼できるデータから住宅ローン承認モデルを作成し、実動前環境でそのモデルをデプロイしてテストします。 最後に、チームはノートブックを使用して Watson OpenScale モニターを構成し、 Watson OpenScale でモニターを評価して監視し、モデルがすべての応募者を公平に扱っていることを確認します。
以下のアニメーション・イメージは、このチュートリアルの終わりまでに達成する内容のクイック・プレビューを提供します。 パイプラインを編集して実行し、機械学習モデルを作成してデプロイし、ノートブックを実行してモニターを構成し、モデルを検証します。 イメージをクリックすると、より大きいイメージが表示されます。


チュートリアルをプレビューする
このチュートリアルでは、以下のタスクを実行します:
- 前提条件をセットアップします。
- タスク 1: サンプル・プロジェクト内の資産を表示します。
- タスク 2: 既存のパイプラインを探索する。
- タスク 3: パイプラインにノードを追加する。
- タスク 4: パイプラインを実行します。
- タスク 5: 資産、デプロイ済みモデル、およびオンライン・デプロイメントを表示します。
Watson OpenScaleを使用してモデルをモニターする方法を引き続き確認する場合は、タスク 6 から 10 を実行します。
- タスク 6: ノートブックを実行して、 Watson OpenScale モニターを構成します。
- 作業 7: モデルを評価する。
- 作業 8: モデル・モニターの品質を監視する。
- 作業 9: 公平性についてモデル・モニターを監視する。
- 作業 10: 説明可能性についてモデル・モニターを監視する。
- クリーンアップ (オプション)
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある場合があります。 このビデオは、作成されたチュートリアルと一緒に使用することを目的としています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある場合があります。 このビデオは、作成されたチュートリアルと一緒に使用することを目的としています。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
このチュートリアルを完了するためのヒント
このチュートリアルを正常に完了するためのヒントを以下に示します。
ビデオ・ピクチャー・イン・ピクチャーの使用
以下のアニメーション・イメージは、ビデオ・ピクチャー・イン・ピクチャーおよび目次機能の使用方法を示しています。

コミュニティーでのヘルプの利用
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザー・ウィンドウのセットアップ
このチュートリアルを最適に実行するには、1 つのブラウザー・ウィンドウで Cloud Pak for Data を開き、このチュートリアル・ページを別のブラウザー・ウィンドウで開いたままにして、2 つのアプリケーションを簡単に切り替えることができます。 2 つのブラウザー・ウィンドウを横並びに配置して、見やすくすることを検討してください。

前提条件のセットアップ
Cloud Pak for Data as a Service への登録
Cloud Pak for Data as a Service に登録し、データ統合ユース・ケースに必要なサービスをプロビジョンする必要があります。
- 既存の Cloud Pak for Data as a Service アカウントがある場合は、このチュートリアルを開始できます。 ライト・プランのアカウントを持っている場合、このチュートリアルを実行できるのはアカウントごとに 1 人のユーザーのみです。
- Cloud Pak for Data as a Service アカウントをまだお持ちでない場合は、 登録してください。
必要なプロビジョン済みサービスの確認
このタスクをプレビューするには、 00:50から始まるビデオをご覧ください。
必要なサービスを検証またはプロビジョンするには、以下の手順を実行します。
ナビゲーションメニュー「
 」から、「サービス」>「サービスインスタンス」を選択する。
」から、「サービス」>「サービスインスタンス」を選択する。Productドロップダウンリストを使用して、既存のwatsonx.aiStudio サービスインスタンスが存在するかどうかを判断します。
watsonx.aiStudio サービスのインスタンスを作成する必要がある場合は、Add service をクリックします。
watsonx.aiStudioを選択します。
「ライト」 プランを選択します。
「作成」 をクリックします。
watsonx.aiStudio サービスがプロビジョニングされるまでお待ちください。
これらのステップを繰り返して、以下の追加サービスを確認またはプロビジョニングします:
- watsonx.aiランタイム
- Cloud Object Storage
- watsonx.governance -デプロイされたモデルをモニターする場合
 進捗状況を確認する
進捗状況を確認する
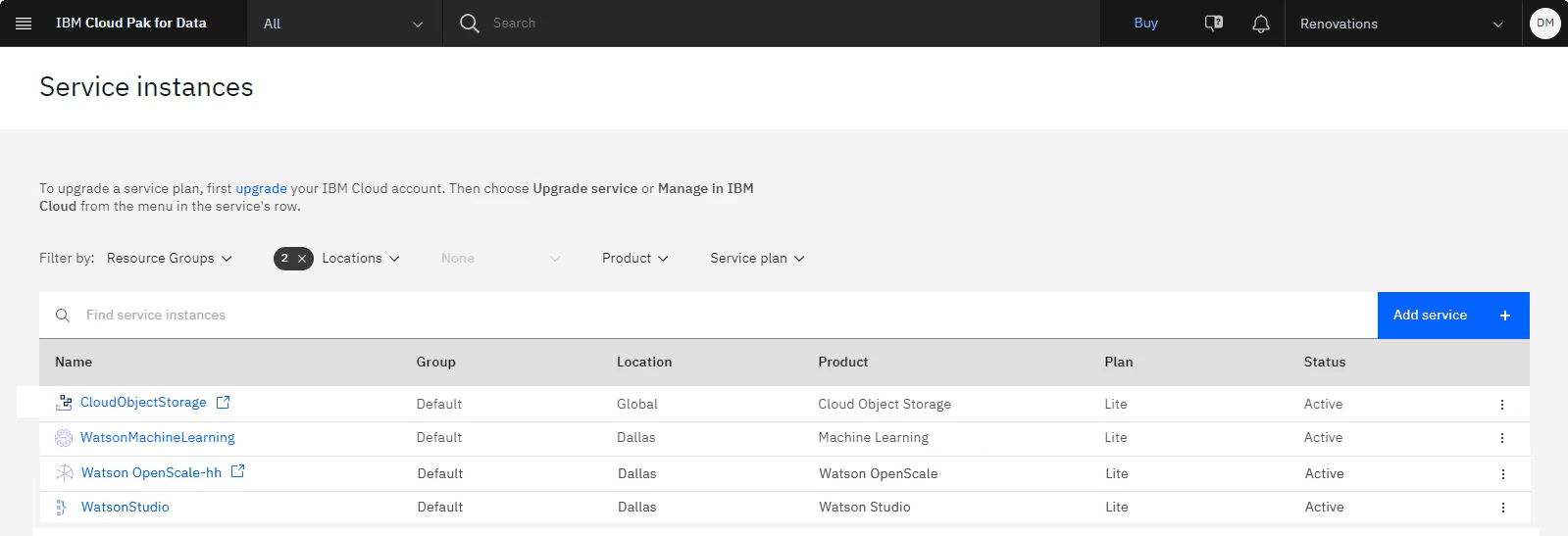
次のイメージは、プロビジョンされたサービス・インスタンスを示しています。
サンプル・プロジェクトを作成する
このタスクをプレビューするには、01:27から始まるビデオを見てください。
このチュートリアルのサンプル・プロジェクトが既にある場合は、このタスクをスキップしてください。 そうでない場合は、以下のステップに従ってください。
リソース・ハブからデータ・サイエンスとMLOpsのサンプル・プロジェクトにアクセスします。
「プロジェクトの作成」をクリックします。
プロジェクトを Cloud Object Storage インスタンスに関連付けるように求められたら、リストから Cloud Object Storage インスタンスを選択してください。
「作成」 をクリックします。
プロジェクトのインポートが完了するまで待ってから、 「新規プロジェクトの表示」 をクリックして、プロジェクトと資産が正常に作成されたことを確認します。
「アセット」 タブをクリックして、このチュートリアルのアセットを表示します。
進捗状況を確認する
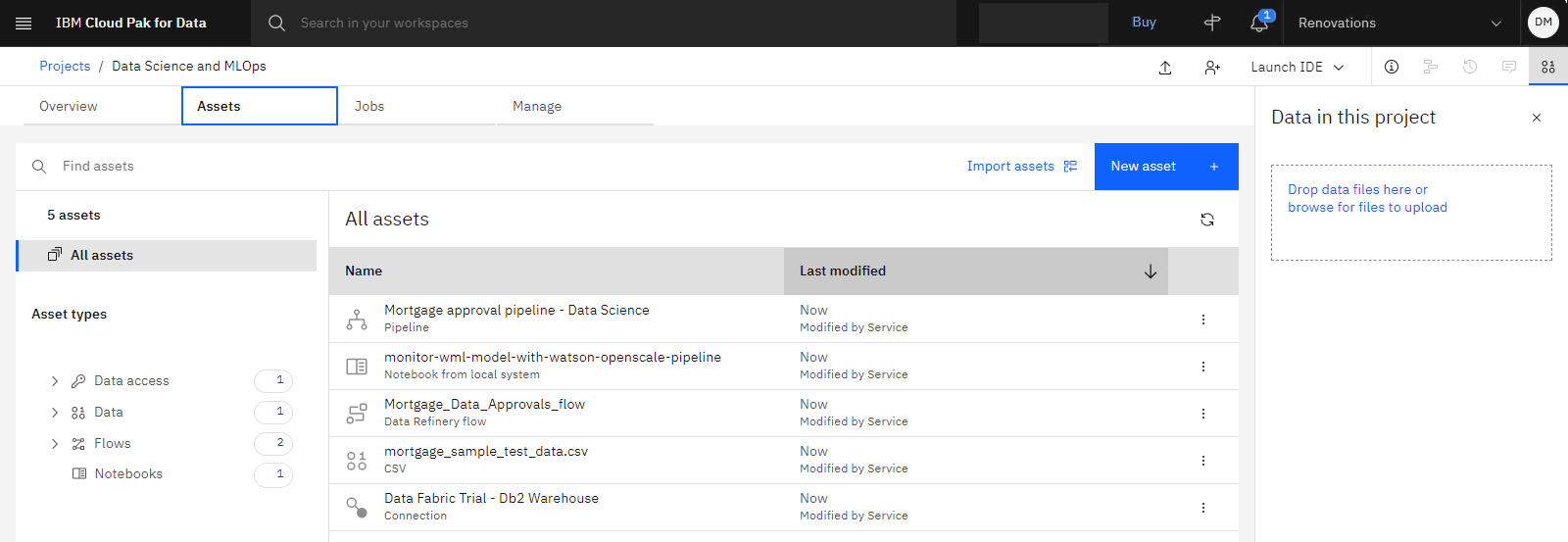
以下の画像は、サンプル・プロジェクトの「資産」タブを示しています。 これで、チュートリアルを開始する準備ができました。
watsonx.aiRuntime サービスをサンプルプロジェクトに関連付けます
このタスクをプレビューするには、02:17から始まるビデオをご覧ください。
モデルの作成とデプロイにはwatsonx.aiRuntime を使用するので、以下の手順に従ってwatsonx.aiRuntime サービスインスタンスをサンプルプロジェクトに関連付けます。
「データ・サイエンスおよび MLOps」 プロジェクトで、 「管理」 タブをクリックします。
「サービス」&「統合」 ページをクリックします。
「サービスの関連付け」をクリックします。
watsonx.aiRuntimeサービスインスタンスの横にあるボックスにチェックを入れます。
「関連付け」をクリックします。
「キャンセル」 をクリックして、 「サービス」&「統合」 ページに戻ります。
進捗状況を確認する
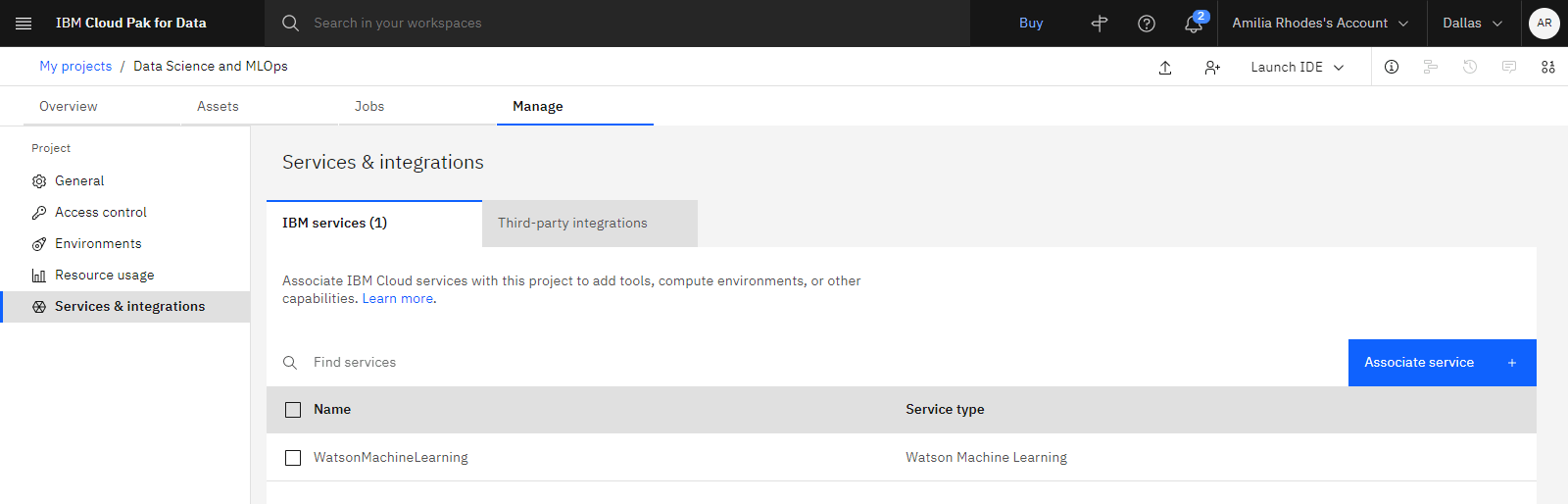
次の画像は、watsonx.aiRuntime サービスが表示されている「Services and Integrations」ページです。 これで、サンプル・プロジェクトを作成する準備ができました。
タスク 1: サンプル・プロジェクト内の資産の表示
このタスクをプレビューするには、02:37から始まるビデオをご覧ください。
サンプル・プロジェクトには、接続、データ定義、1 つの Data Refinery フロー、およびパイプラインを含む複数の資産が含まれています。 これらの資産を表示するには、以下の手順に従います。
「データ・サイエンスと MLOps (Data Science and MLOps)」 プロジェクトの 「資産 (Assets)」 タブをクリックし、 「すべての資産 (All assets)」を表示します。
Data Refinery フローおよびパイプラインで使用されるデータ資産のリストを表示します。 これらの資産は、 AI_MORTGAGE スキーマの Data Fabric Trial- Db2 Warehouse 接続に保管されます。 「資産のインポート」をクリックしてから、 Data Fabric Trial- Db2 Warehouse > AI_MORTGAGEにナビゲートします。 以下のイメージは、その接続からの資産を示しています。

Mortgage Age_Data_Approvals_flow Data Refinery フローは、各住宅ローン申請者に関するデータを統合します。 統合されたデータには、アプリケーションの詳細、クレジット・スコア、商用バイヤーとしてのステータス、最終的には各応募者が選択した自宅の価格などの個人情報が含まれます。 次に、フローは、結合されたデータを含むプロジェクト内に
Mortgage_Data_with_Approvals_DS.csvという名前の順次ファイルを作成します。 次の図は、 Mortgage Age_Data_Approvals_flow Data Refinery フローを示しています。
進捗状況を確認する
以下のイメージは、サンプル・プロジェクト内のすべての資産を示しています。 これで、サンプル・プロジェクトでパイプラインを探索する準備ができました。
タスク 2: 既存のパイプラインの探索
このタスクをプレビューするには、03:25から始まるビデオをご覧ください。
サンプル・プロジェクトには、以下のタスクを自動化するオーケストレーション・パイプラインが含まれています。
既存の Data Refinery ジョブを実行します。
AutoAI エクスペリメントを作成します。
AutoAI エクスペリメントを実行し、 Data Refinery ジョブからの結果出力ファイルをトレーニング・データとして使用する最適なパフォーマンス・モデルを保存します。
デプロイメント・スペースを作成します。
保存したモデルをデプロイメント・スペースにプロモートします。
パイプラインを探索するには、以下の手順を実行します。
「データ・サイエンスと MLOps」 プロジェクトの 「資産」 タブで、 「すべての資産」を表示します。
「住宅ローン承認パイプライン-データ・サイエンス」 をクリックして、パイプラインを開きます。
「住宅ローン承認データの統合 (Integrate Mortgage Approval Data)」 Data Refinery ジョブをダブルクリックします。このジョブは、 Db2 Warehouse on Cloud 接続のさまざまな表を結合して、 AutoAI エクスペリメントのトレーニング・データとして使用される統合ラベル付きデータ・セットにします。 パイプラインに戻るには、 「キャンセル」 をクリックします。
「状況の確認」 条件をクリックし、 「編集」を選択します。 この条件は、 「完了」 または 「警告ありで完了」のいずれかの値を持つ Data Refinery ジョブの完了を確認するための、パイプライン内の決定点です。 パイプラインに戻るには、 「キャンセル」 をクリックします。
「 AutoAI エクスペリメントの作成」 ノードをダブルクリックして、設定を確認します。 このノードは、設定を使用して AutoAI エクスペリメントを作成します。
以下の設定の値を確認します。
AutoAI エクスペリメント名
有効範囲 (Scope)
予測タイプ
予測列
ポジティブ・クラス
データ分割率のトレーニング
含めるアルゴリズム
使用するアルゴリズム
メトリックの最適化
設定を閉じるには、 「キャンセル」 をクリックします。
「 AutoAI エクスペリメントの実行」 ノードをダブルクリックして、設定を確認します。 このノードは、 「住宅ローン承認の統合」 Data Refinery ジョブからの出力をトレーニング・データとして使用する 「 AutoAI エクスペリメントの作成」 ノードによって作成された AutoAI エクスペリメントを実行します。
以下の設定の値を確認します。
AutoAI エクスペリメント
トレーニング・データ資産
モデル名接頭部
設定を閉じるには、 「キャンセル」 をクリックします。
「 AutoAI エクスペリメントの実行」 ノードと 「デプロイメント・スペースの作成」 ノードの間で、 「モデルをデプロイしますか?」 をクリックします。 「編集」を選択します。 この条件の値 True は、デプロイメント・スペースの作成を続行するためのパイプライン内の決定点です。 パイプラインに戻るには、 「キャンセル」 をクリックします。
「デプロイメント・スペースの作成」 ノードをダブルクリックして、設定を更新します。 このノードでは、指定した名前の新しいデプロイメントスペースが作成され、Cloud Object Storageとwatsonx.aiRuntime サービスの入力が必要になります。
「新規スペース名」 設定の値を確認します。
「新規スペース COS インスタンス CRN (New space COS Instance CRN)」 フィールドで、リストから Cloud Object Storage インスタンスを選択します。
New space WML Instance CRN] フィールドで、リストからwatsonx.aiRuntime インスタンスを選択します。
保存 をクリックします。
「モデルをデプロイメント・スペースにプロモート」 ノードをダブルクリックして設定を表示します。 このノードは、 「 AutoAI エクスペリメントの実行」 ノードから、 「デプロイメント・スペースの作成」 ノードから作成されたデプロイメント・スペースに最適なモデルをプロモートします。
以下の設定の値を確認します。
ソース資産
ターゲット
設定を閉じるには、 「キャンセル」 をクリックします。
進捗状況を確認する
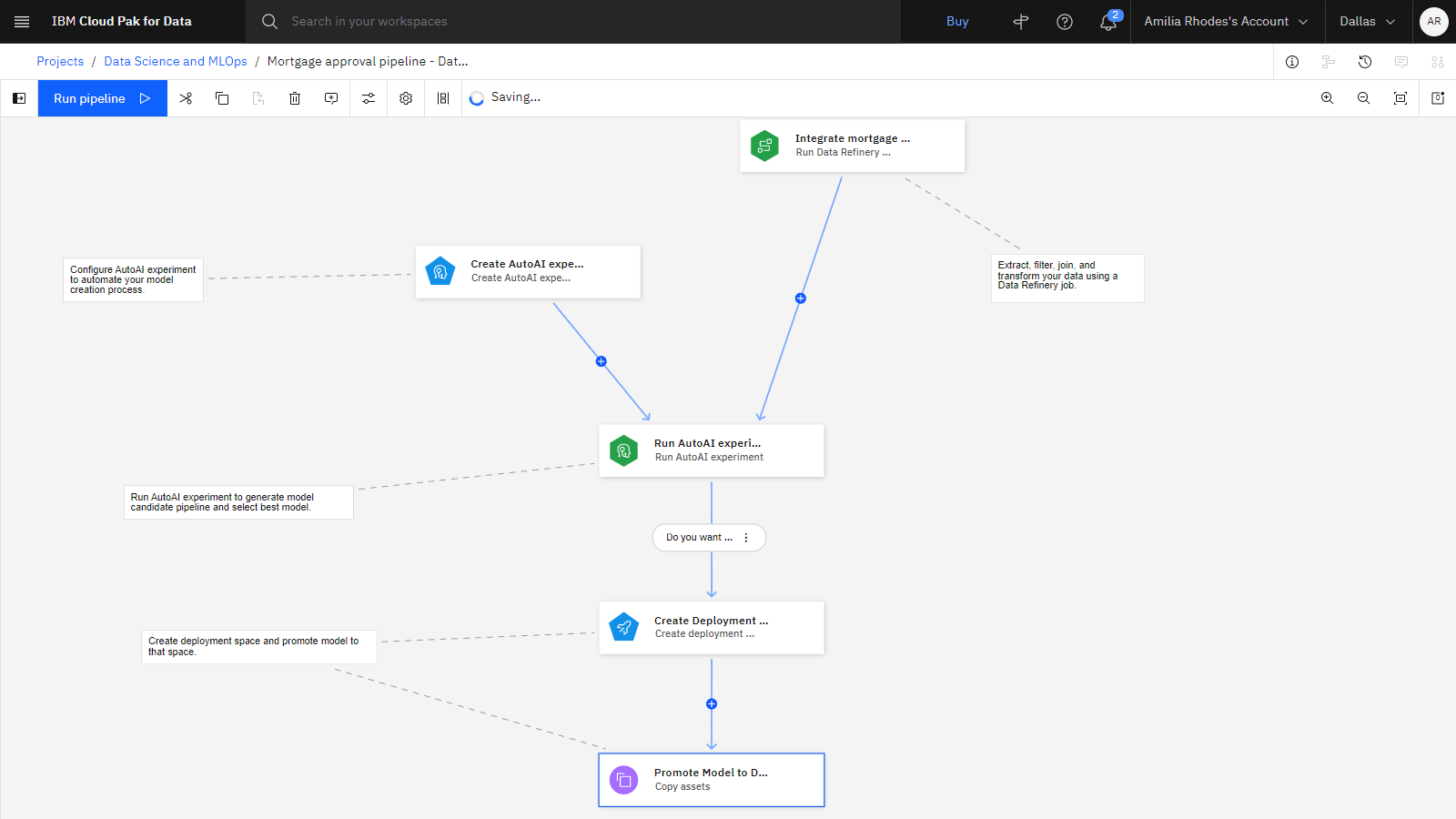
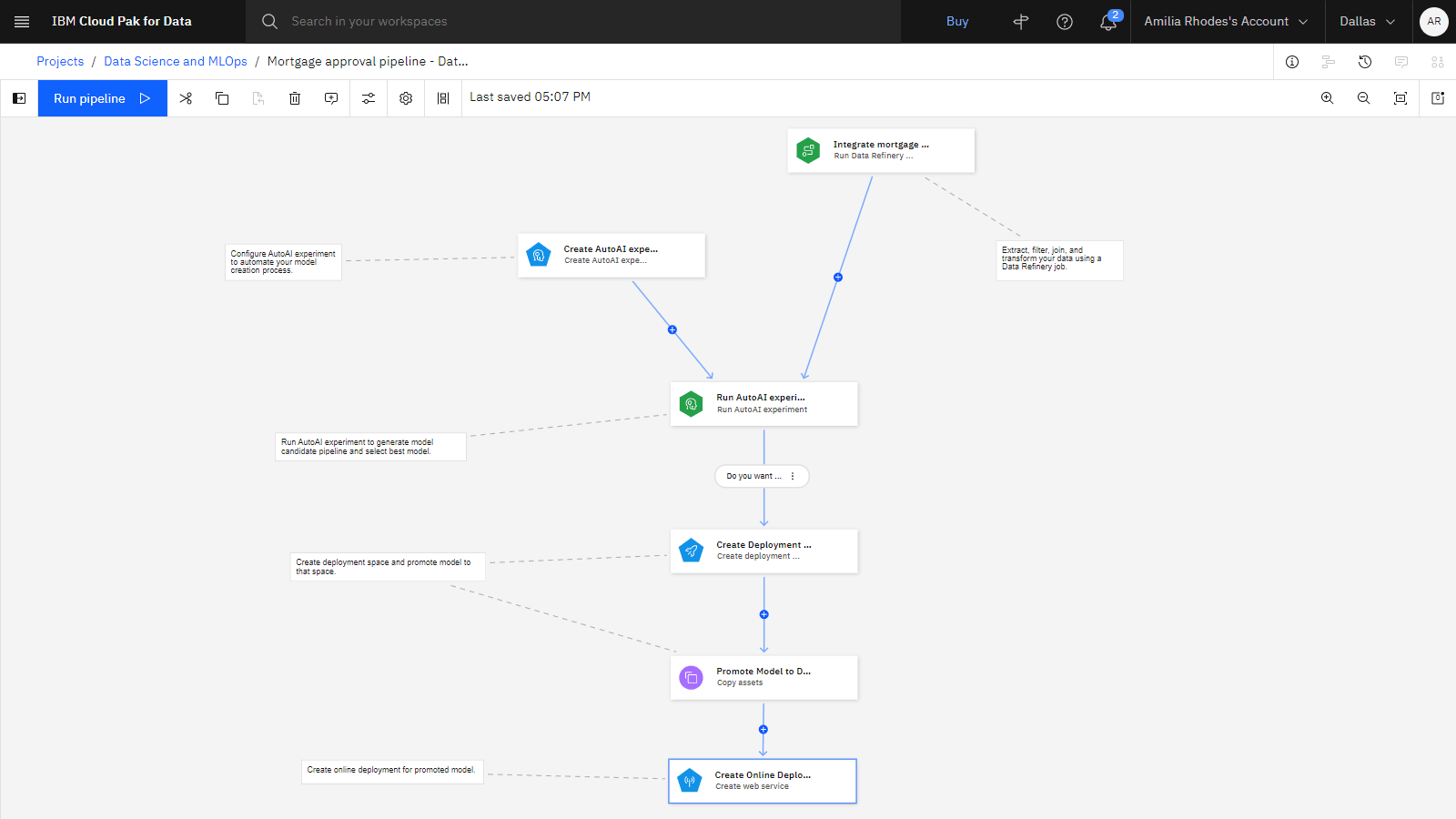
以下のイメージは、初期パイプラインを示しています。 これで、パイプラインを編集してノードを追加する準備ができました。
タスク 3: パイプラインへのノードの追加
このタスクをプレビューするには、05:41から始まるビデオをご覧ください。
パイプラインによってモデルが作成され、デプロイメント・スペースが作成されてから、デプロイメント・スペースにプロモートされます。 オンライン・デプロイメントを作成するには、ノードを追加する必要があります。 オンライン・デプロイメントの作成を自動化するためにパイプラインを編集するには、以下の手順を実行します。
「オンライン・デプロイメントの作成」 ノードをキャンバスに追加します。
ノード・パレットで 「作成」 セクションを展開します。
「オンライン・デプロイメントの作成 (Create online deployment)」 ノードをキャンバスにドラッグし、そのノードを 「モデルをデプロイメント・スペースにプロモート (Promote Model to Deployment Space)」 ノードの後にドロップします。
「モデルをデプロイメント・スペースにプロモート」 ノードの上にカーソルを移動すると、矢印が表示されます。 矢印を 「オンライン・デプロイメントの作成 (Create online deployment)」 ノードに接続します。
注: パイプライン内のノード名は、以下のアニメーション化されたイメージとは異なる場合があります。
コメント・ボックス上の円をノードに接続して、 「プロモートされたモデルのオンライン・デプロイメントの作成」 コメントを 「オンライン・デプロイメントの作成」 ノードに接続します。
注: パイプライン内のノード名は、以下のアニメーション化されたイメージとは異なる場合があります。
「オンライン・デプロイメントの作成」 ノードをダブルクリックして、設定を表示します。
ノード名を
Create Online Deploymentに変更します。「ML 資産」の横にあるメニューから 「別のノードから選択」 をクリックします。

リストから 「モデルをデプロイメント・スペースにプロモート」 ノードを選択します。 ノード ID winning_model が選択されています。
「新規デプロイメント名」に
Mortgage approval model deployment - Data Scienceと入力します。「作成モード」で、 「上書き」を選択します。
「保存」 をクリックして、 「オンライン・デプロイメントの作成」 ノードの設定を保存します。
進捗状況を確認する
以下のイメージは、完了したパイプラインを示しています。 これで、パイプラインを実行する準備ができました。
タスク 4: パイプラインの実行
このタスクをプレビューするには、06:57から始まるビデオをご覧ください。
パイプラインが完了したら、以下のステップに従ってパイプラインを実行します。
ツールバーから、 「パイプラインの実行」>「トライアル実行」をクリックします。
「パイプライン・パラメーターの定義」 ページで、デプロイメントの 「True」 を選択します。
Trueに設定すると、パイプラインはデプロイされたモデルを検証し、そのモデルをスコアリングします。
Falseに設定すると、パイプラインは、 AutoAI エクスペリメントによってプロジェクト内にモデルが作成されたことを検証し、モデル情報とトレーニング・メトリックを確認します。
今回初めてパイプラインを実行する場合は、API キーを指定します。 パイプライン資産は、個人用の IBM Cloud API キーを使用して、中断することなく安全に操作を実行します。
既存の API キーがある場合は、 「既存の API キーを使用 (Use existing API key)」をクリックし、API キーを貼り付け、 「保存」をクリックします。
既存の API キーがない場合は、 「新規 API キーの生成」をクリックし、名前を指定して、 「保存」をクリックします。 API キーをコピーして、後で使用するために保存します。 完了したら、 「閉じる」をクリックします。
「実行」 をクリックして、パイプラインの実行を開始します。
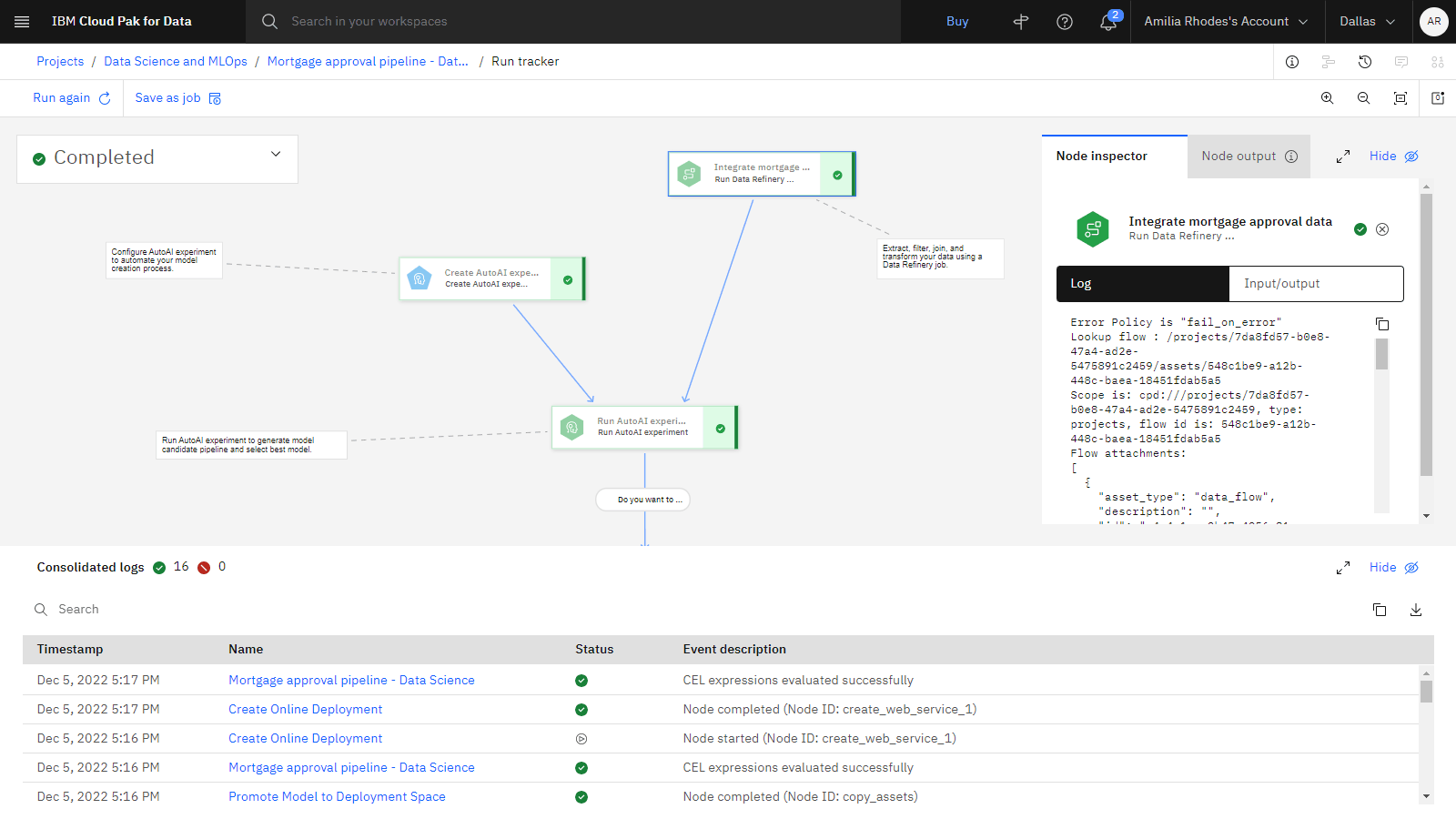
パイプラインの進行状況をモニターします。
パイプラインの実行中に統合ログをスクロールします。 試用版の実行が完了するまでに最大 10 分かかる場合があります。
各操作が完了したら、キャンバス上でその操作のノードを選択します。
「ノード・インスペクター」 タブで、操作の詳細を表示します。
「ノード出力」 タブをクリックして、各ノード操作の出力の要約を表示します。
進捗状況を確認する
以下のイメージは、試用版の実行が完了した後のパイプラインを示しています。 これで、パイプラインによって作成された資産を確認する準備ができました。
タスク 5: 資産、デプロイ済みモデル、およびオンライン・デプロイメントの表示
このタスクをプレビューするには、08:58から始まるビデオをご覧ください。
パイプラインによって複数の資産が作成されました。 資産を表示するには、以下の手順を実行します。
ナビゲーション・トレールで 「データ・サイエンスと MLOps (Data Science and MLOps)」 プロジェクト名をクリックして、プロジェクトに戻ります。

「アセット」 タブで、 「すべてのアセット」を表示します。
データ資産を表示します。
Mortgage_Data_with_Approvals_DS.csv データ資産をクリックします。 Data Refinery ジョブがこの資産を作成しました。
ナビゲーション・トレールで 「データ・サイエンスおよび MLOps (Data Science and MLOps)」 プロジェクト名をクリックして、 「資産」 タブに戻ります。
モデルを表示します。
ds_mortgage age_approval_best_modelで始まる機械学習モデル資産をクリックします。 AutoAI エクスペリメントでは、いくつかのモデル候補が生成され、これが最良のモデルとして選択されました。 このモデル名をテキスト・ファイルに保存します。 次のタスクで Watson OpenScale モニターを構成するには、モデル名が必要です。
モデル情報をスクロールします。
ナビゲーション・トレールで 「データ・サイエンスおよび MLOps (Data Science and MLOps)」 プロジェクト名をクリックして、 「資産」 タブに戻ります。
プロジェクトの 「ジョブ」 タブをクリックして、 Data Refinery ジョブおよびパイプライン・ジョブに関する情報を表示します。
パイプラインで作成したデプロイメント・スペースを開きます。
ナビゲーションメニュー「
」から「Deployments」を選択する。「スペース」 タブをクリックします。
「Mortgage approval-Data Science and MLOps」 デプロイメント・スペースをクリックします。
「資産」 タブをクリックし、 ds_mortgage age_approval_best_modelで始まるデプロイ済みモデルを確認します。
デプロイメント タブをクリックしてください。
「住宅ローン承認モデルのデプロイメント-データ・サイエンス」 をクリックして、デプロイメントを表示します。
「API リファレンス」 タブで、API エンドポイントとコード・スニペットを表示します。
「テスト」 タブをクリックします。
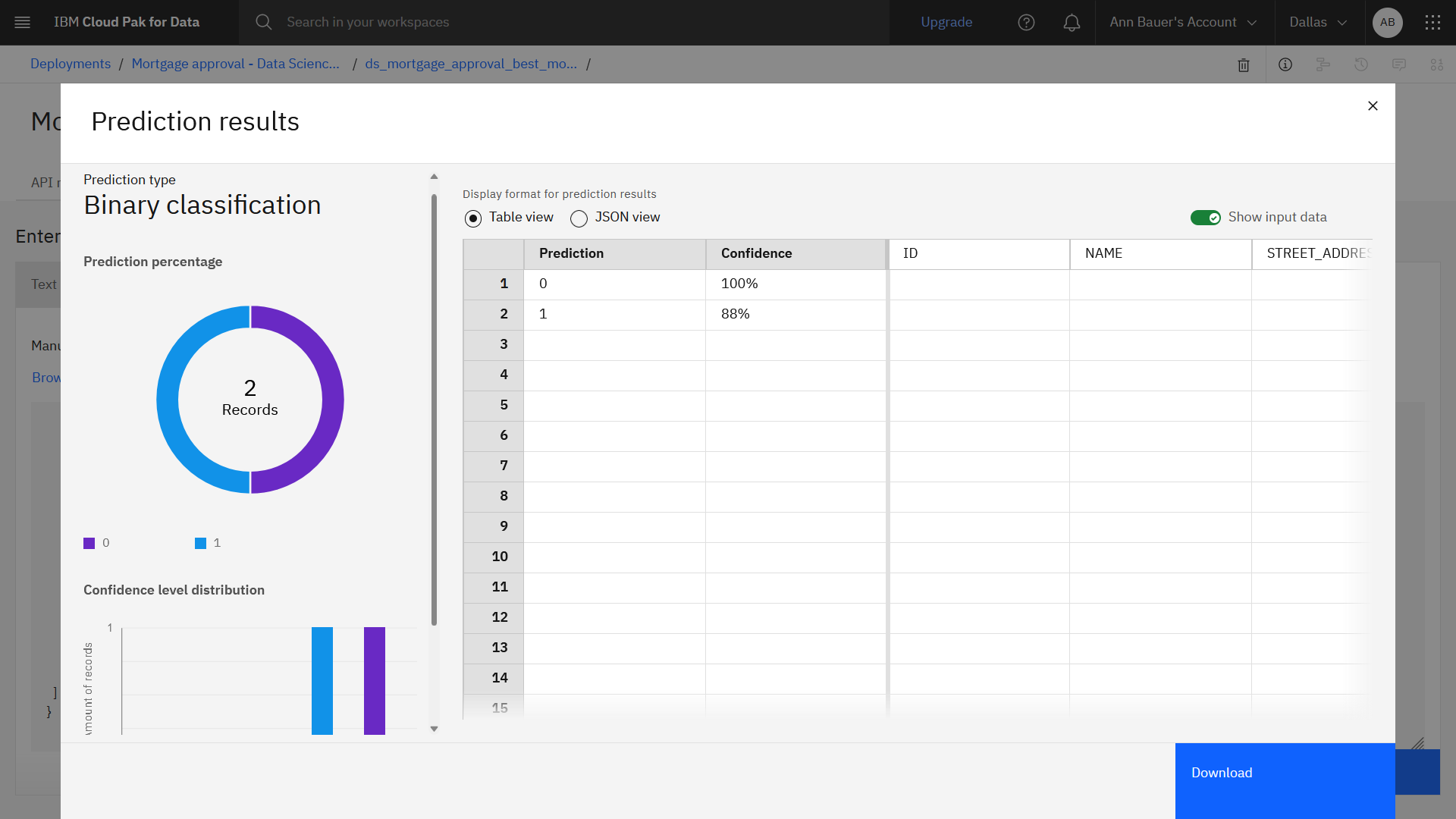
「JSON 入力」 タブをクリックし、サンプル・テキストを以下の JSON テキストに置き換えます。
{ "input_data": [ { "fields": [ "ID", "NAME", "STREET_ADDRESS", "CITY", "STATE", "STATE_CODE", "ZIP_CODE", "EMAIL_ADDRESS", "PHONE_NUMBER", "GENDER", "SOCIAL_SECURITY_NUMBER", "EDUCATION", "EMPLOYMENT_STATUS", "MARITAL_STATUS", "INCOME", "APPLIEDONLINE", "RESIDENCE", "YRS_AT_CURRENT_ADDRESS", "YRS_WITH_CURRENT_EMPLOYER", "NUMBER_OF_CARDS", "CREDITCARD_DEBT", "LOANS", "LOAN_AMOUNT", "CREDIT_SCORE", "CRM_ID", "COMMERCIAL_CLIENT", "COMM_FRAUD_INV", "FORM_ID", "PROPERTY_CITY", "PROPERTY_STATE", "PROPERTY_VALUE", "AVG_PRICE" ], "values": [ [ null, null, null, null, null, null, null, null, null, null, null, "Bachelor", "Employed", null, 144306, null, "Owner Occupier", 15, 19, 2, 7995, 1, 1483220, 437, null, false, false, null, null, null, 111563, null ], [ null, null, null, null, null, null, null, null, null, null, null, "High School", "Employed", null, 45283, null, "Private Renting", 11, 13, 1, 1232, 1, 7638, 706, null, false, false, null, null, null, 54262, null ] ] } ] }予測をクリックしてください。 結果は、最初の応募者が承認されず、2 番目の応募者が承認されることを示しています。
進捗状況を確認する
以下の画像は、テストの結果を示しています。 テストの信頼度スコアは、画像に表示されているスコアとは異なる場合があります。
タスク 6: ノートブックを実行して Watson OpenScale モニターを構成する
このタスクをプレビューするには、 10:40から始まるビデオをご覧ください。
これで、サンプル・プロジェクトに含まれているノートブックを実行する準備ができました。 ノートブックには、以下のためのコードが含まれています。
- モデルとデプロイメントを取り出します。
- Watson OpenScaleを構成します。
- 機械学習サービスのサービス・プロバイダーとサブスクリプションを作成します。
- 品質モニターを構成します。
- 公平性モニターを構成します。
- 説明性を構成します。
サンプル・プロジェクトに含まれているノートブックを実行するには、以下のステップを実行します。 しばらく時間をかけて、各セルのコードを説明するノートブックのコメントを読みます。
ナビゲーションメニュー「
」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択します。「Data Science and MLOps」 プロジェクト名をクリックします。
Assets」タブをクリックし、「Notebooks」に移動します。
'
monitor-wml-model-with-watson-openscale-pipeline ノートブックを開きます。
編集アイコン「
 」をクリックして、ノートブックを編集モードにする。
」をクリックして、ノートブックを編集モードにする。リソース・ハブからプロジェクトをインポートすると、ノートブックの最初のセルにプロジェクト・アクセス・トークンが含まれます。 このノートブックにプロジェクト・アクセス・トークンを持つ最初のセルが含まれていない場合は、トークンを生成する必要があります。 その他 メニューから、 プロジェクト・トークンの挿入を選択してください。 このアクションにより、プロジェクト・トークンを含むノートブックの最初のセルとして新しいセルが挿入されます。
「 IBM Cloud API キーの指定」 セクションで API キーを指定します。 API キーを使って、watsonx.aiRuntime API に認証情報を渡す必要があります。 保存された API キーがまだない場合は、以下の手順に従って API キーを作成します。
このタスクをプレビューするには、04:55から始まるビデオをご覧ください。IBM Cloudコンソールの API キーのページにアクセスします。
「IBM Cloud API キーの作成」をクリックします。 既存の API キーがある場合は、このボタンに 「作成」というラベルを付けることができます。
名前および説明を入力します。
「作成」 をクリックします。
API キーをコピーします 。
将来使用するために API キーをダウンロードします。
ノートブックに戻り、 ibmcloud_api_key フィールドに API 鍵を貼り付けます。
セクション 3. モデルおよびデプロイメントでは、 model_name 変数に、前のタスクでテキスト・ファイルに保存したモデル名を貼り付けます。 パイプラインで指定された名前を使用して、 space_name および deployment_name が自動的に入力されます。
ノートブックのすべてのセルを実行するには、 「セル」>「すべて実行」 をクリックします。 あるいは、実行アイコン「
 クリックしてノートブックをセルごとに実行し、各セルとその出力を調べることもできます。
クリックしてノートブックをセルごとに実行し、各セルとその出力を調べることもできます。セルごとに進行状況セルをモニターし、アスタリスク「In [
*]」が数値 (例えば、「In [1]」) に変更されていることを確認します。 ノートブックの完了には 1 分から 3 分かかります。ノートブックの実行中にエラーが発生した場合は、以下のヒントを試してください。
- 「カーネル」>「再始動」&「出力のクリア」 をクリックしてカーネルを再始動してから、ノートブックを再実行します。
- デプロイメント名を正確にコピーして貼り付け、先頭または末尾にスペースがないことを確認します。
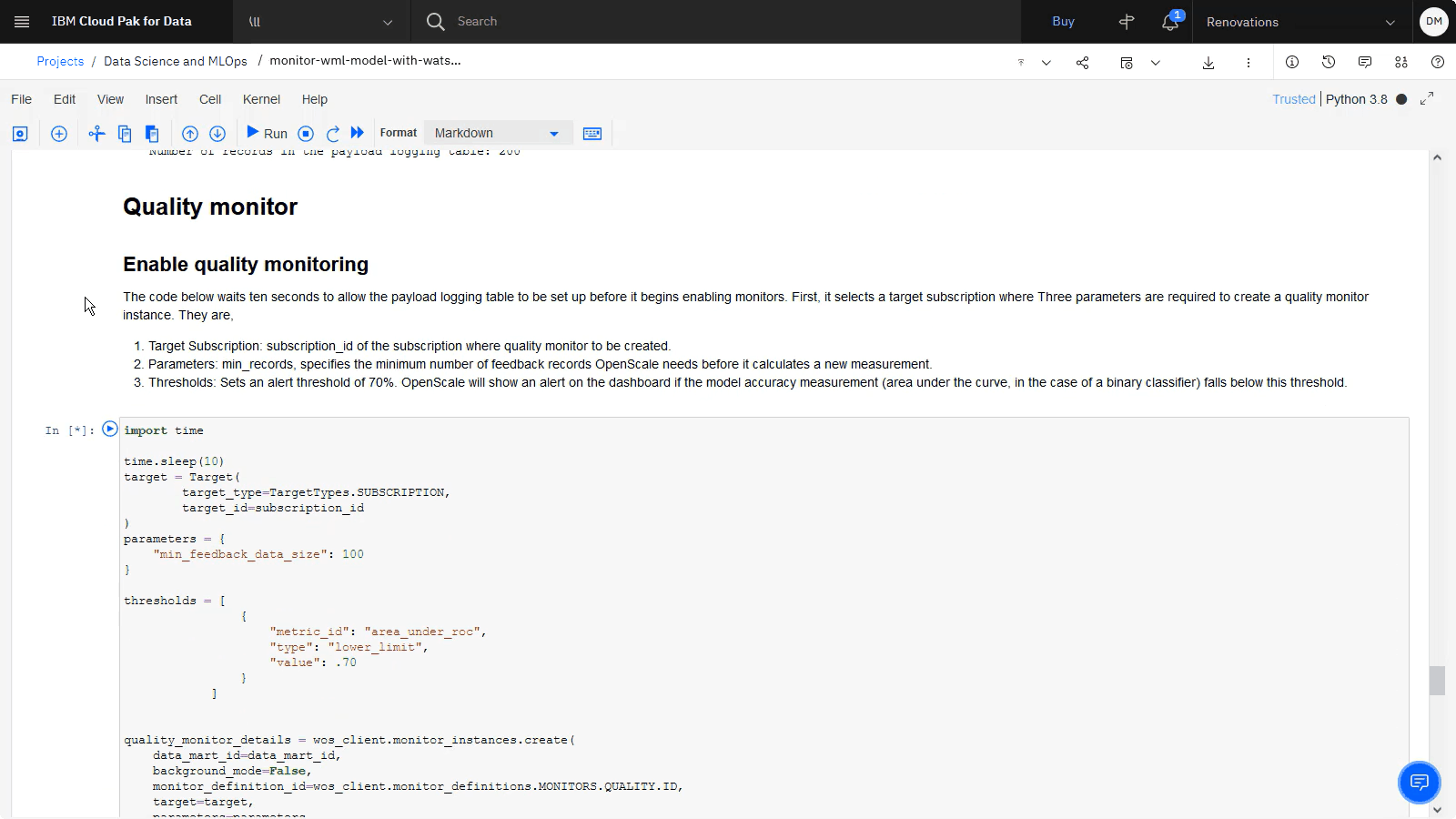
進捗状況を確認する
以下のイメージは、実行が完了したときのノートブックを示しています。 ノートブックがモデルをプロジェクトに保存したため、モデルを評価する準備ができました。
タスク 7: モデルの評価
このタスクをプレビューするには、13:35から始まるビデオをご覧ください。
Watson OpenScaleでモデルを評価するには、以下の手順を実行します。
ナビゲーション・トレイルでデータサイエンスとMLOpsプロジェクトをクリックする。
'「アセット」 タブで、 「データ」 アセット・タイプを展開し、 「データ・アセット」をクリックします。
mortgage_sample_test_data.csvデータ資産のオーバーフローメニュー「
 クリックし、「ダウンロード」を選択します。 モデルが必要に応じて機能していることを検証するには、モデルのトレーニングから除外された一連のラベル付きデータが必要です。 この CSV ファイルには、そのホールドアウト・データが含まれています。
クリックし、「ダウンロード」を選択します。 モデルが必要に応じて機能していることを検証するには、モデルのトレーニングから除外された一連のラベル付きデータが必要です。 この CSV ファイルには、そのホールドアウト・データが含まれています。Watson OpenScale を起動します。
ナビゲーションメニュー「
」から、「サービス」>「サービスインスタンス」を選択する。Watson OpenScale インスタンス名をクリックします。 プロンプトが出されたら、 Cloud Pak for Dataの登録に使用したのと同じ資格情報を使用してログインします。
Watson OpenScale サービス・インスタンス・ページで、 アプリケーションの起動をクリックしてください。
「洞察ダッシュボード (Insights dashboard)」で、 「住宅ローン承認モデルのデプロイメント-データ・サイエンス (Mortgage approval model deployment-Data Science)」 タイルをクリックします。
アクション メニューから、 今すぐ評価を選択してください。
インポート・オプションのリストから、 CSV ファイルからを選択してください。
プロジェクトからダウンロードした mortgage_sample_test_data.csv データ・ファイルをサイド・パネルにドラッグします。
アップロードして評価をクリックしてください。 評価が完了するまでに数分かかる場合があります。
進捗状況を確認する
以下の図は、 Watson OpenScaleでのデプロイされたモデルの評価結果を示しています。 これで、モデルを評価したので、モデルの品質を監視する準備ができました。
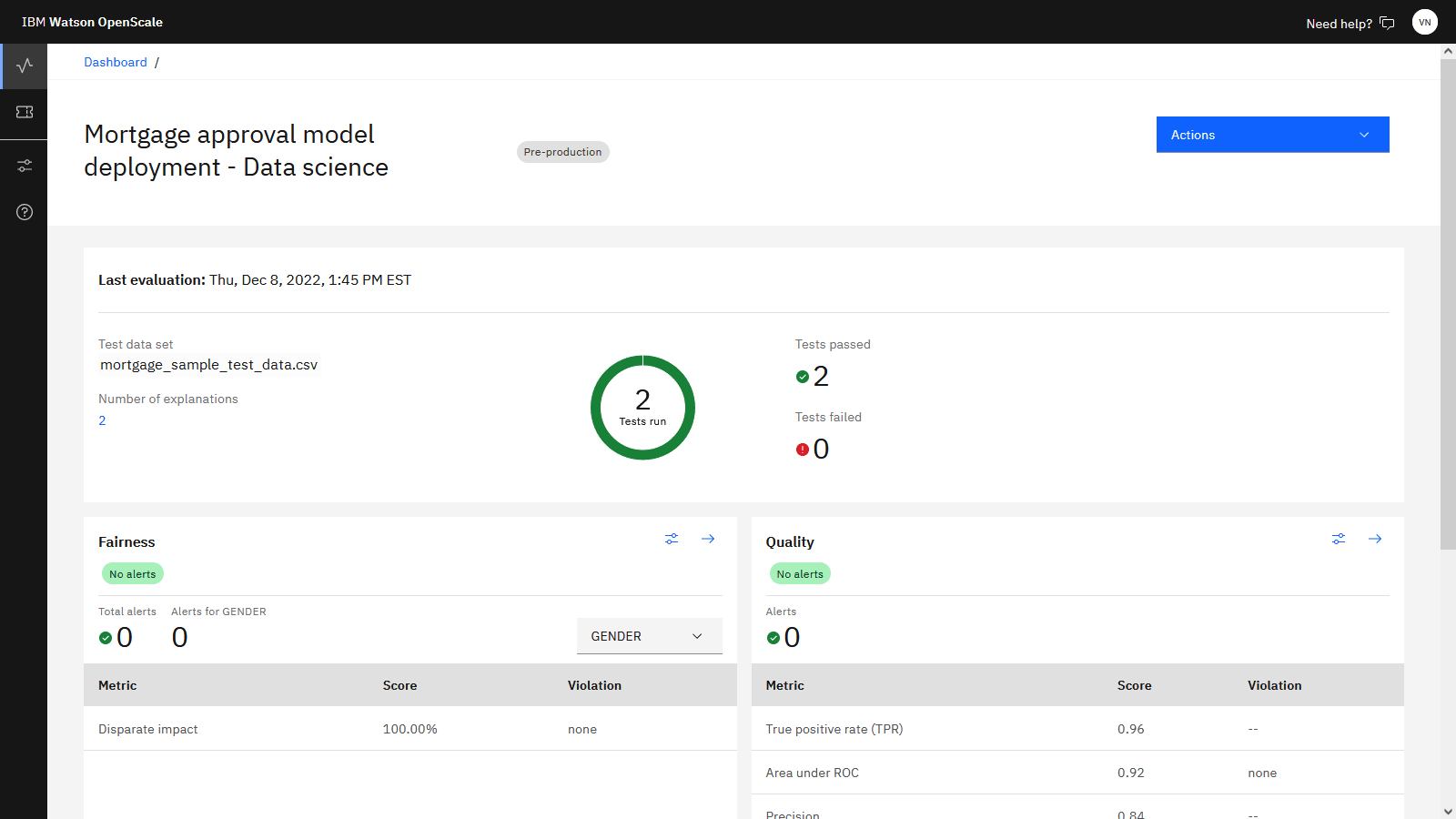
タスク 8: モデル・モニターの品質の監視
このタスクをプレビューするには、14:44から始まるビデオをご覧ください。
Watson OpenScale 品質モニターは、モデルの品質を評価するための一連のメトリックを生成します。 これらの品質メトリックを使用して、モデルの予測結果の精度を判別できます。 ホールドアウト・データを使用する評価が完了したら、以下の手順に従ってモデルの品質または正確度を確認します。
左のナビゲーションパネルで、インサイトダッシュボードのアイコン「
 」をクリックする。
」をクリックする。「Mortgage approval model deployment-Data Science」 タイルを見つけます。 デプロイメントには問題がなく、 「品質」 テストと 「公平性」 テストの両方でエラーが生成されなかったこと、つまりモデルが必要なしきい値を満たしていることに注意してください。
注: 評価後に更新を表示するには、ダッシュボードの最新表示が必要な場合があります。「Mortgage approval model deployment-Data Science」 タイルをクリックすると、詳細が表示されます。
品質セクションで、設定アイコン「
 」をクリックする。 ここでは、このモニターに対して構成されている品質しきい値が 70% であること、および使用されている品質の測定値が ROC 曲線の下の領域であることが分かります。
」をクリックする。 ここでは、このモニターに対して構成されている品質しきい値が 70% であること、および使用されている品質の測定値が ROC 曲線の下の領域であることが分かります。「モデル要約に移動」 をクリックして、モデルの詳細画面に戻ります。
品質セクションで、詳細アイコン「
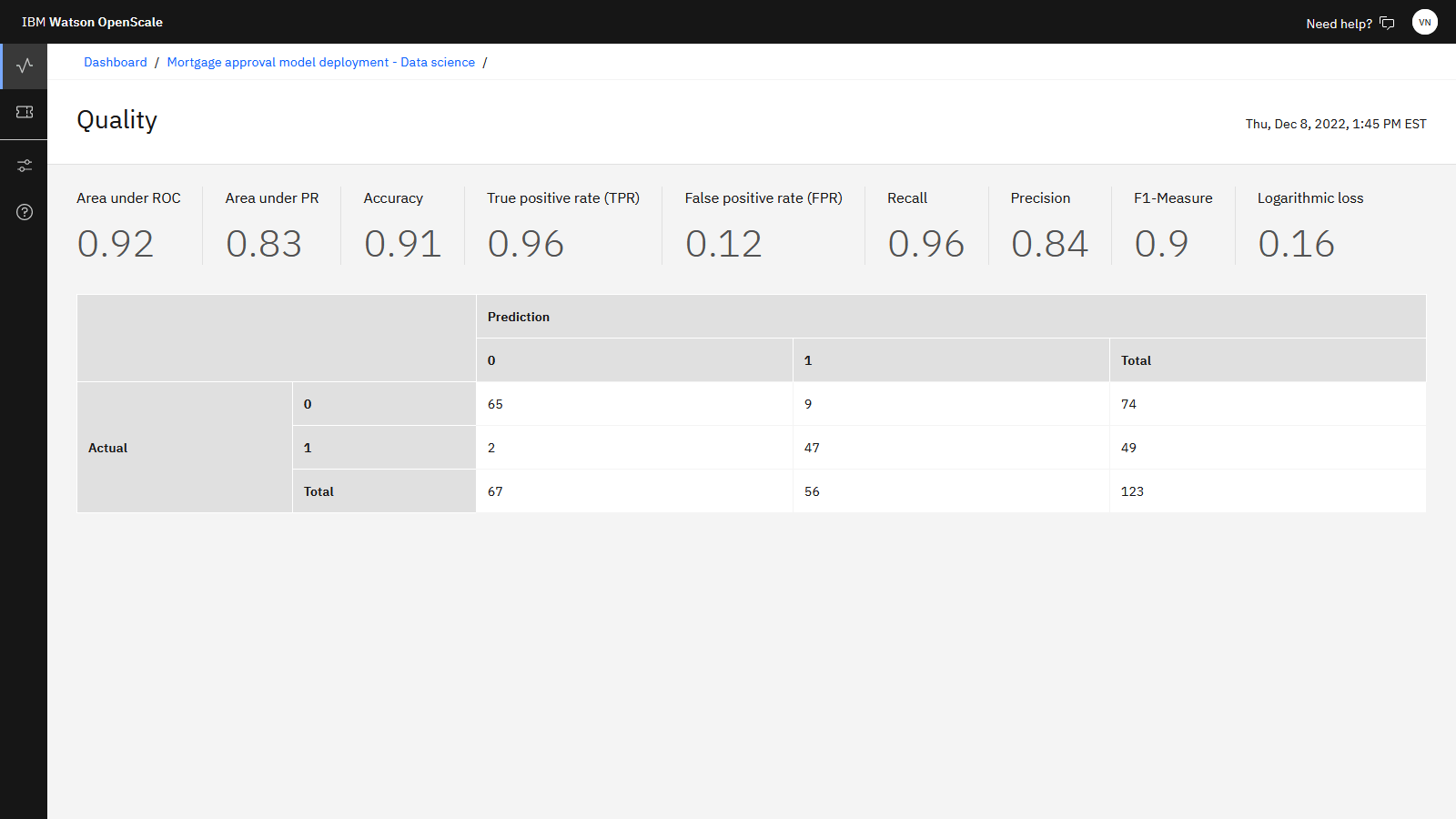
 」をクリックすると、モデル品質の詳細結果が表示されます。 ここには、いくつかの品質メトリック計算と、正しいモデル決定と誤検出および検出漏れを示す混同行列が表示されます。 ROC 曲線の下の計算領域は 0.9 以上であり、これは 0.7 しきい値を超えているため、モデルは品質要件を満たしています。
」をクリックすると、モデル品質の詳細結果が表示されます。 ここには、いくつかの品質メトリック計算と、正しいモデル決定と誤検出および検出漏れを示す混同行列が表示されます。 ROC 曲線の下の計算領域は 0.9 以上であり、これは 0.7 しきい値を超えているため、モデルは品質要件を満たしています。ナビゲーション・トレールで 「住宅ローン承認モデルのデプロイメント-データ・サイエンス」 をクリックして、モデルの詳細画面に戻ります。
進捗状況を確認する
以下の画像は、 Watson OpenScaleの品質の詳細を示しています。 品質スコアは異なる可能性があります。 モデルの品質を確認したので、モデルの公平性を確認できます。
タスク 9: 公平性についてのモデル・モニターの監視
このタスクをプレビューするには、15:59から始まるビデオをご覧ください。
Watson OpenScale 公平性モニターは、モデルの公平性を評価するための一連の指標を生成します。 公平性メトリックを使用して、モデルがバイアスのある結果を生成するかどうかを判別できます。 モデルの公平性を確認するには、以下の手順を実行します。
公平性セクションで、設定アイコン「
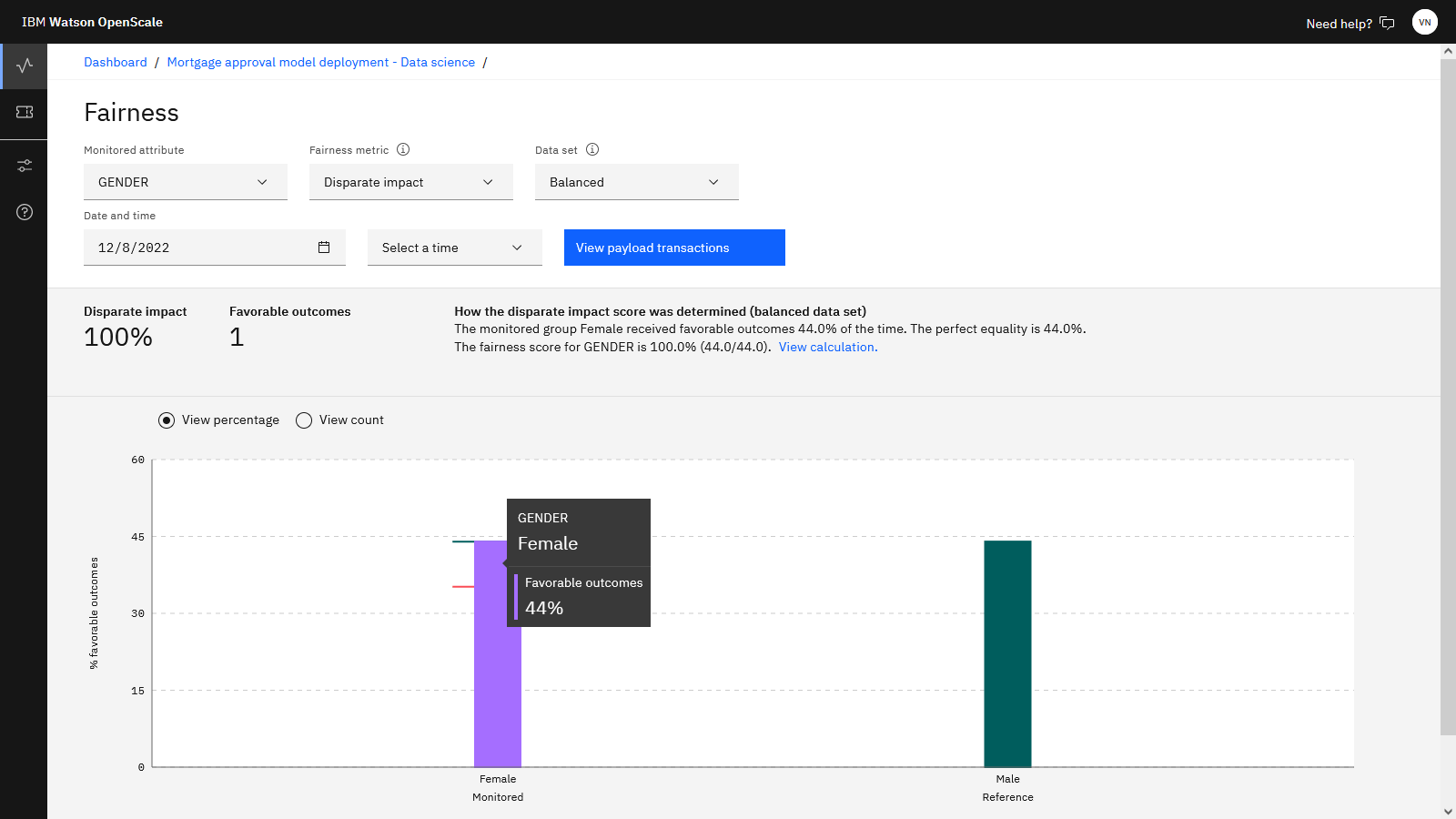
」をクリックする。 ここでは、性別に関係なく応募者が公平に扱われていることを確認するために、モデルがレビューされていることがわかります。 女性は公平性が測定されている監視対象グループとして識別され、公平性のしきい値は少なくとも 80% になります。 公平性モニターは、公平性を判別するために異なる影響方式を使用します。 差別的影響は、モニター対象グループの好ましい結果の割合を、参照グループの好ましい結果の割合と比較します。「モデルの要約に移動」 をクリックして、モデルの詳細画面に戻ります。
公平性セクションで、詳細アイコン「
」をクリックすると、モデルの公平性の詳細結果が表示される。 ここには、自動的に承認される男性と女性の応募者の割合と、約 100% の公平性スコアが表示されます。そのため、モデルのパフォーマンスは、必要とされる 80% の公平性しきい値をはるかに超えています。「 Data set (データ・セット) 」リストに示されているデータ・セットに注意してください。 公平性指標が最も正確であることを確実にするために、 Watson OpenScale は摂動を使用して、保護された属性と関連するモデル入力のみが変更され、他の特徴量は変更されていない結果を判別します。摂動により、特徴量の値が参照グループからモニター対象グループに (またはその逆に) 変更されます。 これらの追加のガードレールは、「平衡型」データ・セットが使用されている場合に公平性を計算するために使用されますが、ペイロードまたはモデル・トレーニング・データのみを使用して公平性の結果を表示することもできます。 モデルは公平に動作しているため、この指標についてさらに詳しく説明する必要はない。
'
「Mortgage approval model deployment-Data Science」 ナビゲーション・トレールをクリックして、モデルの詳細画面に戻ります。
進捗状況を確認する
以下の画像は、 Watson OpenScaleでの公平性の詳細を示しています。 これで、モデルの公平性が確認されたので、モデルの説明可能性を確認できます。
タスク 10: 説明可能性についてのモデル・モニターの監視
このタスクをプレビューするには、17:42から始まるビデオをご覧ください。
モデルがどのように決定されたかを理解する必要があります。 この理解は、ローン承認に関係する人に意思決定を説明し、その意思決定が有効であることをモデル所有者に保証するために必要です。 これらの決定を理解するには、以下のステップに従って、モデルの説明可能性を確認します。
左のナビゲーション・パネルで、'Explain a transaction' アイコン '
 をクリックする。
をクリックする。トランザクションのリストを表示するには、 「住宅ローン承認モデルのデプロイメント-データ・サイエンス」 を選択します。
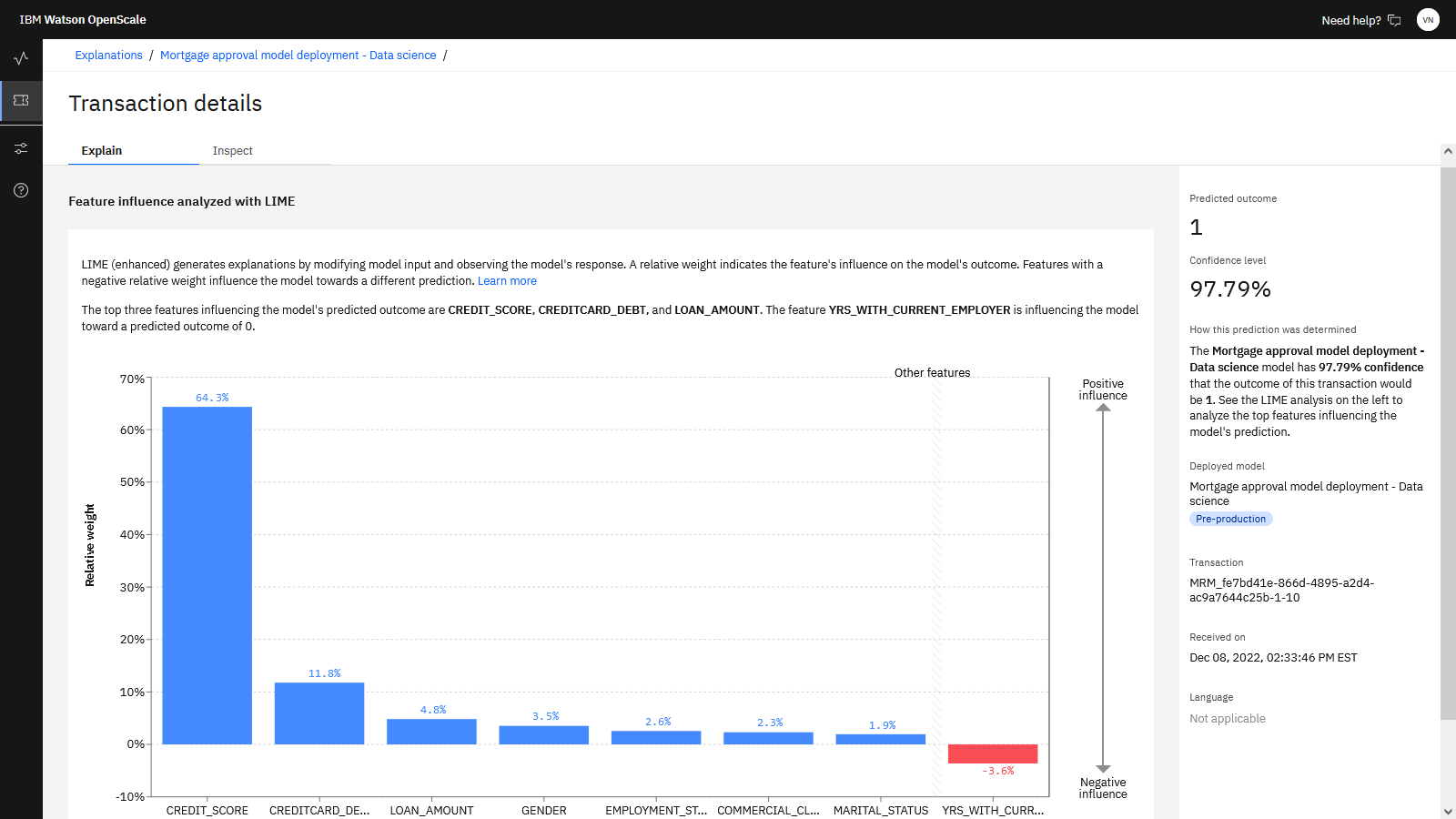
任意のトランザクションについて、 アクション 列の下の 説明 をクリックしてください。 ここに、この決定の詳細な説明が表示されます。モデルへの最も重要な入力と、最終結果に対する各入力の重要度が表示されます。 青い棒はモデルの決定をサポートする傾向のある入力を表し、赤い棒は別の決定につながった可能性のある入力を示します。 例えば、申請者が承認されるのに十分な収入を持っているが、それらの申請者の信用履歴と高い負債が一緒になって、申請を拒否するモデルが作成されているとします。この説明を検討して、モデルの決定の基礎について満足するようにしてください。
オプション: モデルの決定方法をさらに詳しく調べる場合は、 「検査」 タブをクリックします。 「検査」 機能を使用して意思決定を分析し、少数の入力に対する小さな変更によって異なる意思決定が行われる可能性がある感度の領域を検出します。 実際の入力のいくつかを代替でオーバーライドして結果に影響を与えるかどうかを確認することにより、自分で感度をテストすることができます。
進捗状況を確認する
以下の画像は、 Watson OpenScaleでのトランザクションの説明性を示しています。 モデルが正確であり、すべての応募者を公平に扱うと判断しました。 これで、モデルをそのライフサイクルの次のフェーズに進めることができます。
ゴールデン・バンクのチームは、Orchestration Pipelines を使用して、すべての住宅ローン申請者に関する最新データと、貸し手が意思決定に使用できる機械学習モデルを提供するデータ・パイプラインを作成しました。 次に、チームは Watson OpenScale を使用して、モデルがすべての応募者を公平に扱っていることを確認しました。
クリーンアップ (オプション)
このチュートリアルをやり直す場合は、以下の成果物を削除してください。
| 成果物 | 削除方法 |
|---|---|
| Mortgage approval-Data Science and MLOps デプロイメント・スペース内の 「住宅ローン承認モデルのデプロイメント-データ・サイエンス」 | デプロイメントの削除 |
| Mortgage approval-Data Science and MLOps デプロイメント・スペース | デプロイメント・スペースの削除 |
| データ・サイエンスと MLOps のサンプル・プロジェクト | プロジェクトの削除 |
次のステップ
以下のチュートリアルをお試しください。
別の ユース・ケースに登録します。
もっと見る
親トピック: ユース・ケースのチュートリアル