このチュートリアルは、「高品質なデータを収集する」チュートリアルと「データを保護する」チュートリアルを終了した後に、高品質で保護されたデータを使用するために、データファブリックトライアルでデータガバナンスの使用事例を学びます。 目標は、データ・ファブリック内のデータを評価、共有、シェーピング、および分析することです。
このチュートリアルのストーリーは、ゴールデン・バンクには、高品質の顧客住宅ローン・データにアクセスする必要があるいくつかの部門があるということです。 データ・アナリストは、適切なデータを検索して見つけ、その内容を理解して信頼し、他のデータ・アナリストやデータ・サイエンティストが使用できるように準備する必要があります。
以下のアニメーション・イメージは、このチュートリアルの終わりまでに達成する内容のクイック・プレビューを提供します。ここでは、カタログ資産を表示し、資産を手動で拡充し、関係を作成し、データを視覚化し、データをフィルタリングして品質を向上させます。 イメージをクリックすると、より大きなイメージが表示されます。


チュートリアルをプレビューする
このチュートリアルでは、以下のタスクを実行します:
- 前提条件をセットアップします。
- タスク 1: データ資産の理解。
- タスク 2: 資産を強化し、関係を作成します。
- タスク 3: 強化されたデータをプロジェクトに追加する。
- 作業 4: データを視覚化する。
- 作業 5: 分析と AI 用にデータを準備する。
- クリーンアップ (オプション)
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある可能性があります。 このビデオは、作成されたチュートリアルのコンパニオンとなることを目的としています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある可能性があります。 このビデオは、作成されたチュートリアルのコンパニオンとなることを目的としています。
このビデオは、この資料の概念とタスクを学習するための視覚的な方法を提供します。
このチュートリアルを完了するためのヒント
このチュートリアルを正常に完了するためのヒントを以下に示します。
ビデオ・ピクチャー・イン・ピクチャーの使用
以下のアニメーション・イメージは、ビデオ・ピクチャー・イン・ピクチャーおよび目次機能の使用方法を示しています。

コミュニティーでのヘルプの利用
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザー・ウィンドウのセットアップ
このチュートリアルを最適に実行するには、1 つのブラウザー・ウィンドウで Cloud Pak for Data を開き、このチュートリアル・ページを別のブラウザー・ウィンドウで開いたままにして、2 つのアプリケーションを簡単に切り替えることができます。 2 つのブラウザー・ウィンドウを横並びに配置して、見やすくすることを検討してください。

前提条件のセットアップ
前提条件のチュートリアルの完了
このタスクをプレビューするには、00:39から始まるビデオを見てください。
高品質データのキュレート および データの保護 のチュートリアルを完了します。
- 高品質データのキュレート ・チュートリアルでは、データ資産をインポートしてエンリッチし、それらをカタログに公開します。
- Protect your data チュートリアルはデータ保護ルールとマスキング・フローを作成してデータを保護します。
ベース・ プレミアム・ スタンダード特に断りのない限り、この情報はIBM Knowledge Catalog のすべてのエディションに適用されます。
タスク 1: データ資産の理解
このタスクをプレビューするには、01:12から始まるビデオを見てください。
カタログ内のデータ資産は、データへのポインター以上のものです。 これらには、データの形式と意味、およびデータ値に関する統計に関する情報が含まれています。 データ資産の価値を理解するには、以下のステップを実行します。
ナビゲーションメニュー「
 」から、「カタログ」>「すべてのカタログを見る」を選択します。
」から、「カタログ」>「すべてのカタログを見る」を選択します。Mortgage Approval Catalogを開きます。
「おすすめの資産」セクションには、 「最近追加された」 資産、過去の使用状況と人気に基づいて AI および機械学習から推奨された資産である 「推奨」 資産、およびカタログ・コラボレーターが評価およびレビューした 「高評価」 資産が表示されます。
主なアセットの非表示 をクリックして、そのセクションを閉じます。
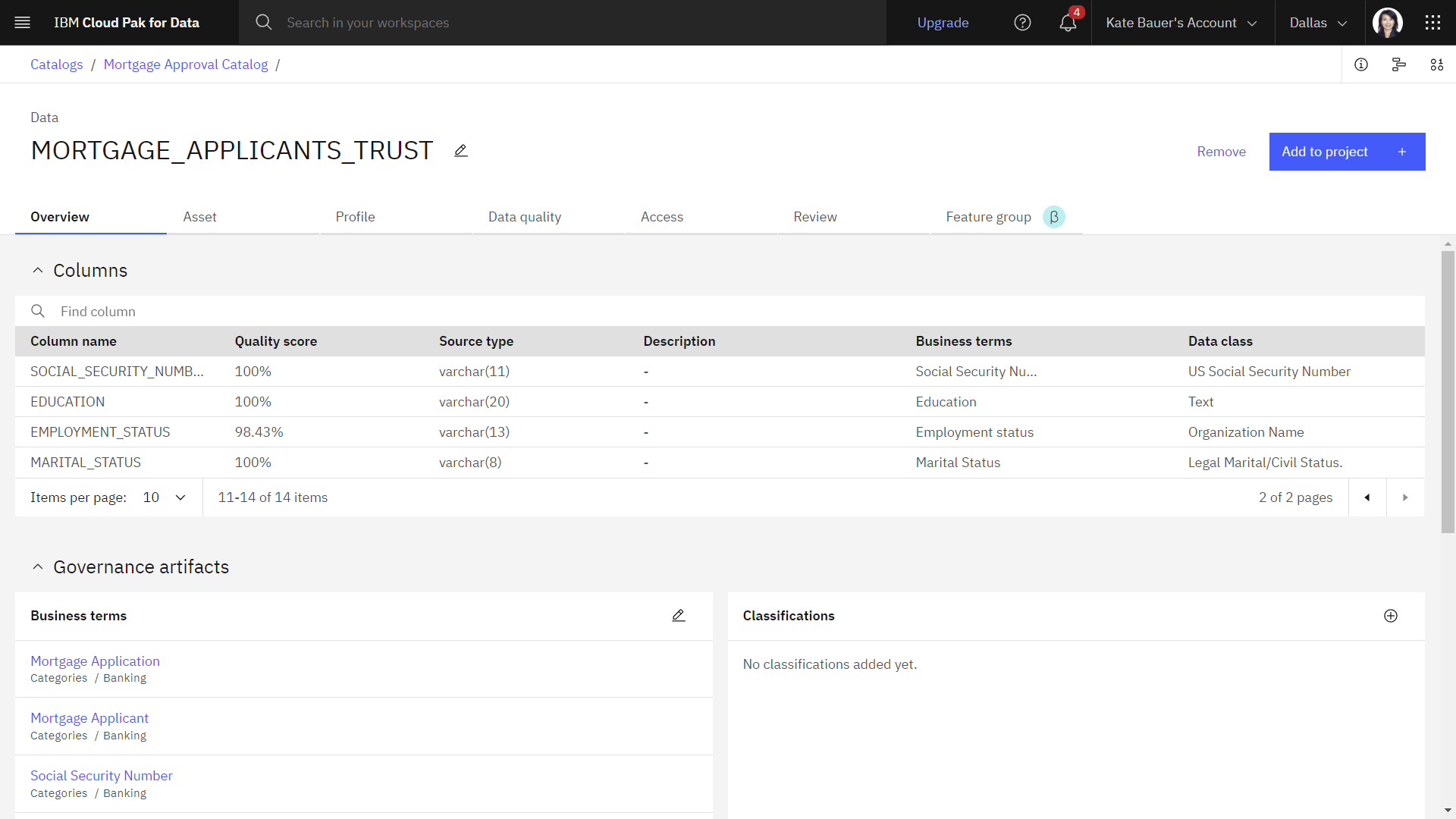
mortgageを検索します。そのカタログ資産を表示するには、 「MORTGAGE_APPLICANTS_TRUST」 をクリックします。 「概要」 タブおよびサイド・パネルには、資産に関する基本情報 (説明、評価、タグ、資産が配置されている場所、ビジネス用語、データ・クラス、および関連項目など) が表示されます。
プロファイル タブをクリックしてください。 プロファイル情報は、データの内容、品質、およびユーザビリティーを理解するのに役立ちます。
右にスクロールして、 ZIP_CODE 列を見つけます。
「ZIP_CODE」 列に自動的に割り当てられたデータ・クラスは、 Commercial and Government Entityです。 自動的に割り当てられるデータ・クラスは異なる場合があることに注意してください。 値は郵便番号であるため、この列は簡単に再分類できます。 ドロップダウン・リストをクリックすると、その他の可能なデータ・クラスとその信頼性レベルが表示されます。 US Zip Codeを選択します。
Asset タブをクリックして、データのプレビューを表示します。
列に関するメタデータをさらに表示するには、 「概要」 タブに戻ります。 列のリストで、 職業状況 列を検索して、割り当てられたビジネス用語を含むメタデータを確認します。
 進捗状況を確認する
進捗状況を確認する
次の図は、カタログ内の MORTGAGE_APPLICANTS_TRUST 資産を示しています。 メタデータ・エンリッチメント中に IBM Knowledge Catalog がデータ資産に自動的に追加する情報のタイプを探索しました。 次のタスクでは、このデータ資産を手動でエンリッチします。
タスク 2: 資産のエンリッチと関係の作成
このタスクをプレビューするには、02:49から始まるビデオをご覧ください。
資産に情報を追加することで、資産の価値を高めることができます。 例えば、アセットに関する意見を追加したり、アセット・プロパティーを更新したり、アセットをリンクする関係を作成したりすることができます。 資産を強化し、関係を作成するには、以下の手順を実行します。
MORTGAGE_APPLICANTS_TRUST カタログ資産の場合は、 「レビュー」 タブをクリックします。 このアセットを評価してコメントすることで、他のユーザーがアセットを簡単に見つけられるようにします。
レーティングに 星 5 個 を選択してください。
レビューのために、以下のテキストをコピーして貼り付けます。
This contains high quality customer data from the mortgage system.「実行依頼」をクリックします。
「概要」 タブをクリックします。
アセット名の横にある編集アイコン「
 」をクリックして、アセット名を編集します。
」をクリックして、アセット名を編集します。名前を次のように変更します。
MORTGAGE_APPLICANTS_TRUST_PROTECT「適用」をクリックします。
右サイドパネルの説明セクションで、追加アイコン「
 」をクリックする。注:
」をクリックする。注:このアセットに既存の説明がある場合、[追加]アイコンの代わりに [編集]アイコン '
が表示されます。以下の説明をコピーして貼り付けます。
Mortgage applicants from the Mortgage System「適用」をクリックします。
この資産は住宅ローンに関するものであるため、「Business terms」の隣にある「Add」アイコンの「
または「Edit」アイコンの「」をクリックする。「検索」 フィールドに
loanと入力します。注: 検索語を入力した後に Enter キーを押す必要はありません。 検索語を入力すると、すぐに結果のリストが表示されます。「ローン」を選択します。
保存 をクリックします。
この資産には個人情報が含まれているため、「分類」の横にある「追加」アイコン「
 または「編集」アイコン「」をクリックします。
または「編集」アイコン「」をクリックします。Personally Identifiable Informationを選択します。
保存 をクリックします。
この資産は他の住宅ローン資産に関連しているため、 「関連項目」の横にある 「関連項目の追加」>「関連資産の追加」をクリックします。
Is related to を選択し、 Nextをクリックします。
CREDIT_SCORE 資産と MORTGAGE_APPLICATION 資産を選択し、 Addをクリックします。
MORTGAGE_APPLICATION をクリックして、その関連資産を表示します。
進捗状況を確認する
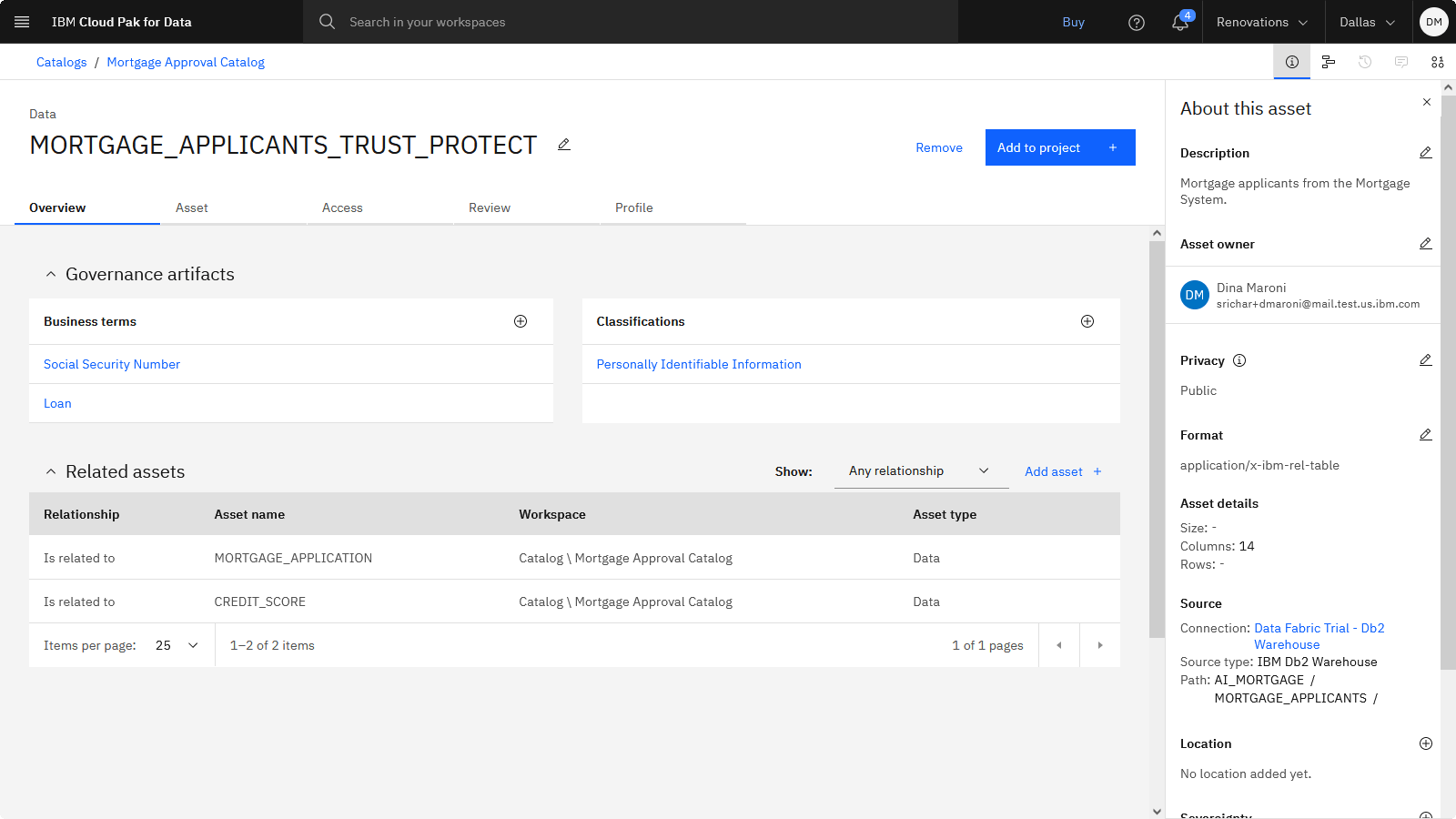
以下のイメージは、カタログ内の MORTGAGE_APPLICANTS_TRUST_PROTECT 資産の「概要」タブを示しています。 プロパティーの確認、更新、およびアセットへの関係の追加を行うことで、これらのアセットの価値を高めました。 次のタスクでは、エンリッチされた資産をプロジェクトに追加します。
タスク 3: 強化されたデータをプロジェクトに追加する
このタスクをプレビューするには、04:09から始まるビデオをご覧ください。
データ・アナリスト・チームは、モデルのトレーニング・データとして詳細化、視覚化、分析、および使用するために、住宅ローン分析プロジェクトで住宅ローン申請者データを必要とします。 以下の手順に従って、エンリッチされたデータをプロジェクトに追加します。
ナビゲーション・トレイルで「住宅ローン承認カタログ」をクリックする。
'
MORTGAGE_APPLICANTS_TRUST_PROTECTカタログ資産行の最後で、オーバーフローメニュー「
 」をクリックし、「プロジェクトに追加」を選択します。
」をクリックし、「プロジェクトに追加」を選択します。「ターゲット」 ドロップダウン・リストで、 「データ・ガバナンス」 プロジェクトを選択します。
追加 をクリックします。
通知が表示されたら、 Go to projectをクリックします。 通知を見落としたら、以下のようにします:
ナビゲーションメニュー「
クリックし、「Projects」 > 「View all projects」を選択します。「データ・ガバナンス」 プロジェクトをクリックします。
プロジェクトで 「資産」 タブをクリックして、 MORTGAGE age_applicants_trust_protect データ資産を表示します。
進捗状況を確認する
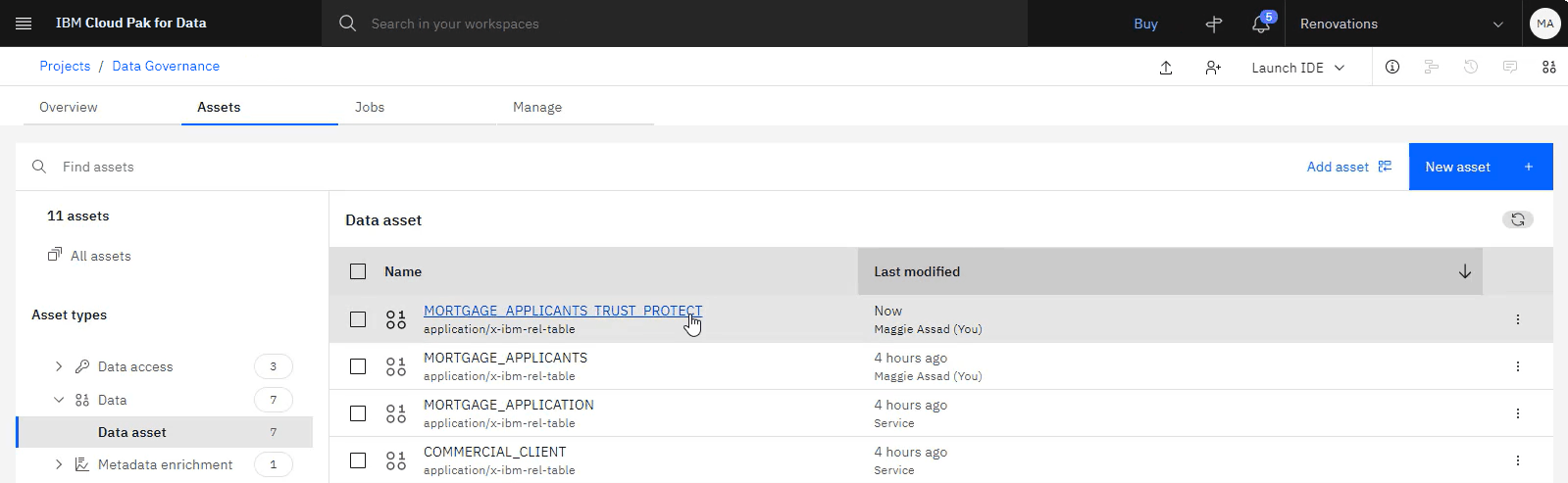
以下の図は、プロジェクト内の MORTGAGE_APPLICANTS_TRUST_PROTECT 資産を示しています。 これで、データを視覚化する準備ができました。
タスク 4: データの視覚化
このタスクをプレビューするには、04:39から始まるビデオをご覧ください。
住宅ローン申請者のデータをクレンジングして改善し、分析ツールやモデルに対応できるようにする必要があります。 どのように形成する必要があるかを判断するための迅速かつ簡単な方法は、 Data Refineryでデータを視覚化することです。 視覚化は、データの最初の 5,000 行に基づいています。 データを視覚化するには、以下の手順を実行します。
MORTGAGE_APPLICANTS_TRUST_PROTECT データ資産をクリックして、データをプレビューします。
「データの準備 (Prepare Data)」 をクリックして Data Refineryでデータ資産を開き、データが読み取られて処理されるのを待ちます。
「このアセットについて」 パネルで、 「X」 をクリックしてパネルを閉じます。
「ステップ」 パネルで、 「X」 をクリックしてパネルを閉じます。
視覚化 タブをクリックしてください。
「視覚化する列 (Column to visualize)」で、 「STREMENT_STATUS」を選択します。
データの視覚化(Visualize data)をクリックします。 このツールは、この列に最適なグラフ・タイプとして円グラフを選択します。このグラフには、採用状況ごとの応募者の分布が表示されます。 推奨されるグラフ・タイプは、バー、ワード・クラウド、およびサンバーストの横に青い点で示されています。
「グラフ・タイプ」で、 「バブル」 グラフ・タイプを選択します。 バブル・チャートは、特定のデータ・セット内の値の分布を素早く視覚化するための 1 つの簡単な方法です。
「グラフ・タイプ」 ドロップダウンから、 「関係」 グラフ・タイプを選択します。
このグラフ・タイプには 2 つの列が必要です。 以下の列を選択します:
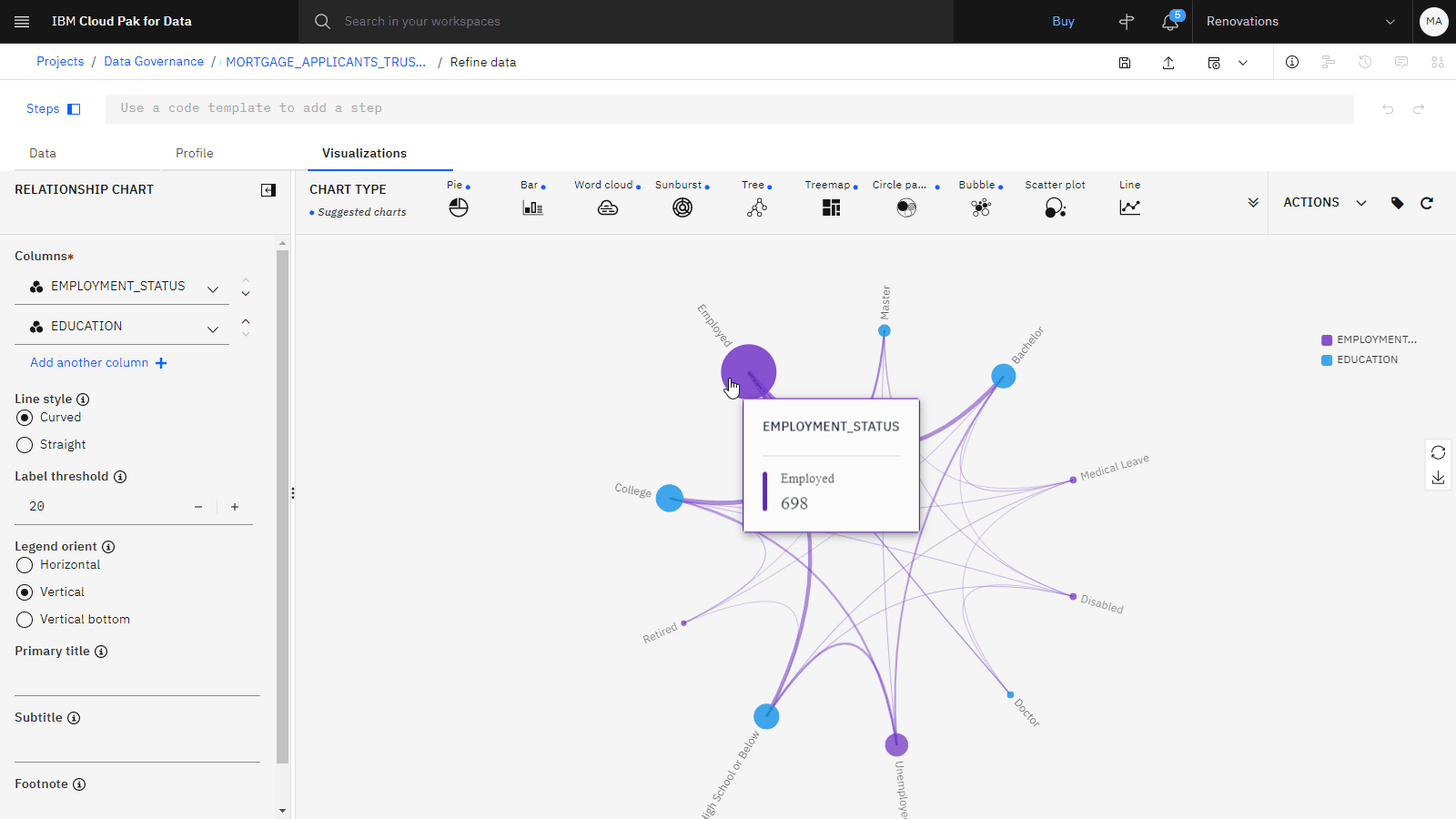
最初の列では、 雇用状況を選択します。
「別の列の追加」をクリックします。
2 番目の 「列」で、 「EDUCATION」を選択します。
「関係」 グラフでは、エンドポイントを選択して関係を表示できます。 例えば、学歴ごとに応募者の雇用状況を表示できます。
進捗状況を確認する
以下のイメージは、 Data Refineryで視覚化された MORTGAGE_APPLICANTS_TRUST_PROTECT 資産を示しています。 これで、データをクレンジングする準備ができました。
タスク 5: 分析と AI のためのデータの準備
このタスクをプレビューするには、05:59から始まるビデオをご覧ください。
社会保障番号のない応募者は処理できないため、データを確認して、社会保障番号のない応募者を削除する必要があります。 MORTGAGE_APPLICANTS_TRUST_PROTECT データを準備するために、以下を行います。
- Social_Security_Number 列の値の頻度を表示します。
- 「ソーシャル・セキュリティー番号 (Social_Security_Number)」列の値が欠落している応募者をフィルタリングします。
データを準備するには、以下の手順を実行します。
Data Refineryで、 「プロファイル」 タブをクリックします。
右にスクロールして、 Social_Security_Number 列を見つけます。 いくつかの欠損値に注意してください。
「データ」 タブをクリックして、これらのレコードをフィルターで除外します。 画面下部のステータス・バーにある Data Refinery は、 「FULL DATA SET」 が 1101 行であることを示します。
「ステップ」 パネルが表示されない場合は、 「ステップ」 をクリックしてパネルを開きます。
「新規ステップ」をクリックします。
「クリーンアップ」 セクションで、 「フィルター」を選択します。
「列」 フィールドで、 「Social_Security_Number」 列を選択します。
「演算子」 フィールドで、 「空ではない」を選択します。
「適用」をクリックします。 画面下部のステータス・バーにある Data Refinery に、 「FULL DATA SET」 が 1000 行であることが示されるようになりました。これは、ソーシャル・セキュリティー番号が欠落している行がフィルターで除外されるためです。 「ステップ」 パネルに、 「フィルター」 操作を示す新しいステップが表示されることに注意してください。
プロファイル タブをクリックしてください。
右にスクロールして、 Social_Security_Number 列を見つけます。 欠落値がなくなっていることに注意してください。
ツールバーから保存アイコン「
 」をクリックします。
」をクリックします。ツールバーから「エクスポート」アイコンをクリックし、「現在のデータをCSVにエクスポート」を選択します。
'
MORTGAGE_APPLICANTS_TRUST_PROTECT_shaped.csv をローカル・フォルダーに保存します。
そのフォルダーにナビゲートし、CSV ファイルを開きます。このファイルには 1000 行が含まれていますが、社会保障番号が欠落している応募者はいません。
Cloud Pak for Data に戻り、ナビゲーショントレイルでData governanceproject をクリックします。
'
「すべての資産」をクリックし、 MORTGAGE_APPLICANTS_TRUST_PROTECT_flowという名前の新しい Data Refinery フロー資産を見つけます。
進捗状況を確認する
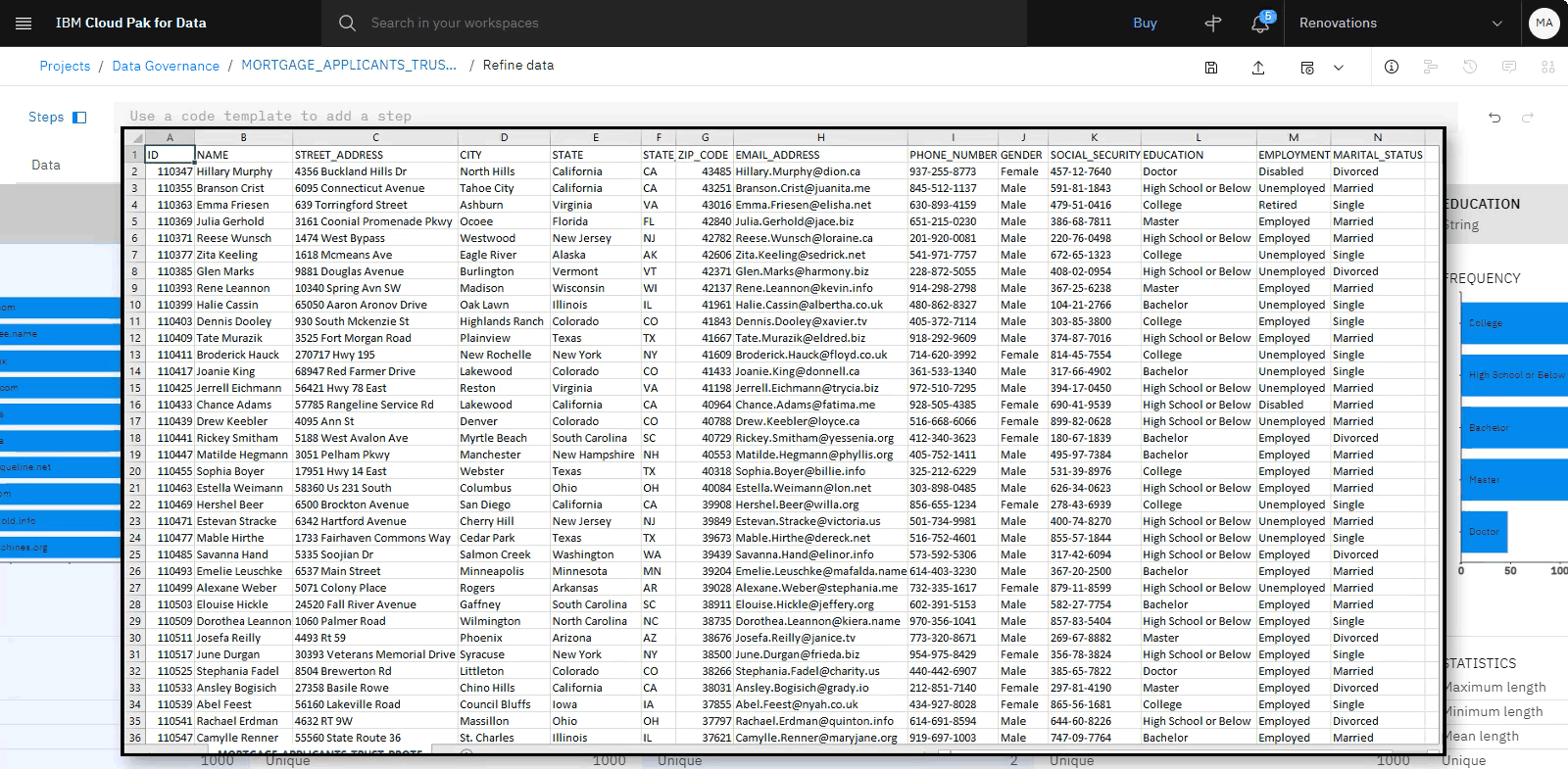
以下のイメージは、 Data Refineryで精製した MORTGAGE_APPLICANTS_TRUST_PROTECT_shaped.csv ファイルを示しています。 このデータ・セットには、社会保障番号を提供した住宅ローン申請者に関する情報が含まれています。
ゴールデン・バンクのデータ・アナリストは、適切なデータを検索して見つけ、そのコンテンツを理解して信頼し、他のデータ・アナリストやデータ・サイエンティストが使用できるように準備する方法を学習しました。
クリーンアップ (オプション)
データ・ガバナンスのユース・ケースでチュートリアルを再利用する場合は、以下の成果物を削除します。
| 成果物 | 削除方法 |
|---|---|
| インポートされたビジネス用語 | ガバナンス・アーティファクトの削除 |
| 銀行カテゴリー | カテゴリーを削除します |
| データ保護ルール: 機密情報と Redact 社会保障番号 | データ保護ルールの削除 |
| 住宅ローン承認カタログ | カタログの削除 |
| データ・ガバナンス・サンプル・プロジェクト | プロジェクトの削除 |
次のステップ
仮想化データの管理チュートリアルをお試しください。
360 度ビューの構成チュートリアルをお試しください。
別の データ・ファブリックのユース・ケースに登録します。
もっと見る
親トピック: ユース・ケースのチュートリアル