
当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
翻訳が最新ではありません
このページの翻訳は最新バージョンを表していません。 最新の更新については、資料の 英語版 を参照してください。
watsonx.data インテリジェンス・チュートリアル360度ビューの設定
最終更新: 2025年4月05日
このチュートリアルでは、顧客の360度ビューを構成し、データ・ファブリック・トライアルの watsonx.data インテリジェンス使用例でこれらの顧客を調査します。 このチュートリアルの目的は、顧客データとクレジット・スコア・データを組み合わせて、データ全体のエンティティーを解決し、顧客の統合 360 ビューを作成すること、およびキャンペーンでターゲットとする最も価値の高い顧客を特定し、それらを提供するための最適な率を決定することです。
技術プレビュー これは技術プレビューであり、実稼働環境での使用はまだサポートされていません。
クイック・スタート: このチュートリアルのサンプル・プロジェクトをまだ作成していない場合は、リソース・ハブで Master Data Management サンプル・プロジェクト にアクセスします。
このチュートリアルのストーリーは、ゴールデン・バンクが住宅ローン金利を下げるキャンペーンを実施したいとのものです。 データ・エンジニアは、 IBM Match 360 を使用して、顧客の 360 度ビューのためにデータをセットアップ、マップ、およびモデル化する必要があります。
以下のアニメーション・イメージは、このチュートリアルを終了するまでに実行する内容のクイック・プレビューを提供します。 資産をセットアップしてマスター・データに追加し、データ資産属性をマップし、データ・モデルを公開してマッチングを実行し、一致したデータをカタログに公開してから、一致したデータを探索して視覚化します。 イメージをクリックすると、より大きいイメージが表示されます。

チュートリアルをプレビューする
このチュートリアルでは、以下のタスクを実行できます:
- 前提条件の設定
- タスク1:マッチしたデータのカタログを作成する
- タスク2:マスターデータの設定と資産の追加
- タスク3:データ資産の属性をマッピングする
- タスク4:データモデルの発行とマッチングの実行
- タスク5:マッチしたデータをカタログに掲載する
- タスク6:マッチしたデータをプレビューする
- タスク 7: マッチング・アルゴリズムのチューニングとマッチングの実行
- タスク8:マッチング結果についての洞察を得る
- タスク9:エンティティの記録を可視化する
- クリーンアップ (オプション)
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある場合があります。 このビデオは、作成されたチュートリアルと一緒に使用することを目的としています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオに表示されるユーザー・インターフェースには若干の違いがある場合があります。 このビデオは、作成されたチュートリアルと一緒に使用することを目的としています。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
このチュートリアルを完了するためのヒント
このチュートリアルを正常に完了するためのヒントを以下に示します。
ビデオ・ピクチャー・イン・ピクチャーの使用
ヒント: ビデオを開始してから、チュートリアルをスクロールすると、ビデオはピクチャー・イン・ピクチャー・モードに移行します。 ピクチャー・イン・ピクチャーで最良のエクスペリエンスを得るには、ビデオの目次を閉じます。 ピクチャー・イン・ピクチャー・モードを使用して、このチュートリアルのタスクを完了する際にビデオをフォローすることができます。 後続の各タスクのタイム・スタンプをクリックします。
以下のアニメーション・イメージは、ビデオ・ピクチャー・イン・ピクチャーおよび目次機能の使用方法を示しています。

コミュニティーでのヘルプの利用
このチュートリアルでヘルプが必要な場合は、Cloud Pak for DataCommunityディスカッションフォーラムで質問したり、回答を見つけることができます。
ブラウザー・ウィンドウのセットアップ
このチュートリアルを最適に実行するには、1 つのブラウザー・ウィンドウで Cloud Pak for Data を開き、このチュートリアル・ページを別のブラウザー・ウィンドウで開いたままにして、2 つのアプリケーションを簡単に切り替えることができます。 2 つのブラウザー・ウィンドウを横並びに配置して、見やすくすることを検討してください。

ヒント: ユーザー・インターフェースでこのチュートリアルを実行しているときにガイド・ツアーが表示された場合は、 「後で行うこともあります」をクリックします。
前提条件のセットアップ
Cloud Pak for Data as a Service への登録
Cloud Pak for Data as a Service にサインアップし、 watsonx.data インテリジェンスのユースケースに必要なサービスをプロビジョニングする必要がある。
- 既存の Cloud Pak for Data as a Service アカウントがある場合は、このチュートリアルを開始できます。 ライト・プランのアカウントを持っている場合、このチュートリアルを実行できるのはアカウントごとに 1 人のユーザーのみです。
- Cloud Pak for Data as a Service のアカウントをお持ちでない場合は、 トライアルにサインアップしてください。
![]() Cloud Pak for Dataのデータ・ファブリックについては、以下のビデオをご覧ください。
Cloud Pak for Dataのデータ・ファブリックについては、以下のビデオをご覧ください。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
必要なプロビジョン済みサービスの確認
このタスクをプレビューするには、 00:50から始まるビデオをご覧ください。
重要: Match 360 サービスは、ダラス・リージョンでのみ使用可能です。 必要に応じて、続行する前にダラス地域に切り替えてください。
以下のステップに従って、必要なサービスを検証またはプロビジョンします。
Cloud Pak for Dataで、ダラス・リージョンにいることを確認します。 そうでない場合は、地域ドロップダウンをクリックし、 「ダラス」を選択します。

ナビゲーションメニュー「
 」から、「サービス」>「サービスインスタンス」を選択する。
」から、「サービス」>「サービスインスタンス」を選択する。製品 ドロップダウン・ボックスを使用して、 IBM Match 360 with Watson サービス・インスタンスが存在するかどうかを判別します。
IBM Match 360 サービス・インスタンスを作成する必要がある場合は、 サービスの追加をクリックしてください。
IBM Match 360 with Watsonを選択してください’。
地域として 「ダラス」を選択します。
「ライト」 プランを選択します。
オプション: IBM Match 360 with Watson サービス・インスタンスの名前を入力します。
「作成」 をクリックします。
これらのステップを繰り返して、以下のサービスを検証またはプロビジョンします:
- IBM Knowledge Catalog
- Cloud Object Storage
 進捗状況を確認する
進捗状況を確認する
次のイメージは、プロビジョンされたサービス・インスタンスを示しています。
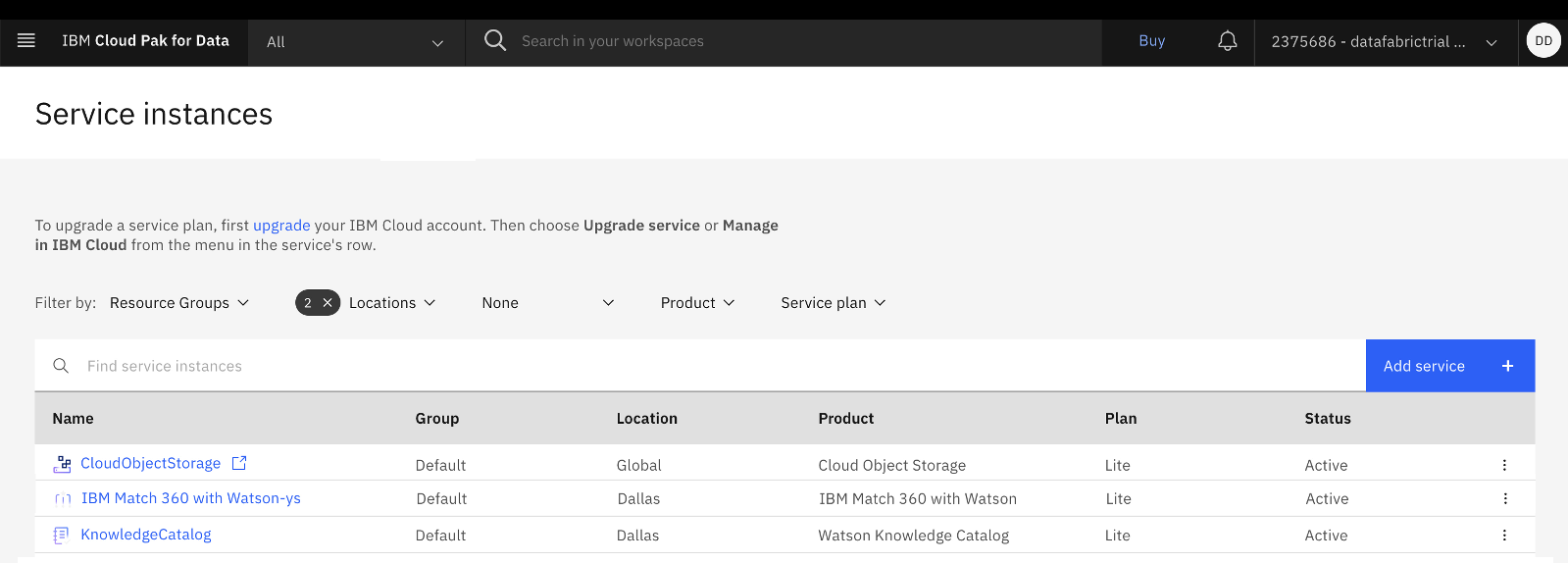
サンプル・プロジェクトを作成する
このタスクをプレビューするには、01:29から始まるビデオをご覧ください。
このチュートリアルのサンプル・プロジェクトを作成するには、以下の手順を実行します。
リソース・ハブからMaster Data Managementサンプル・プロジェクトにアクセスします。
「プロジェクトの作成」をクリックします。
プロジェクトを Cloud Object Storage インスタンスに関連付けるように求められたら、リストから Cloud Object Storage インスタンスを選択してください。
「作成」 をクリックします。
プロジェクトのインポートが完了するまで待ってから、 「新規プロジェクトの表示」 をクリックして、プロジェクトと資産が正常に作成されたことを確認します。
注: 今回初めてプロジェクトにアクセスする場合は、プロジェクトのツアーが必要かどうかを尋ねるガイド・ツアーが表示されます。 ここでは、 後で実行をクリックしてください。「アセット」 タブをクリックして、プロジェクトのアセットを表示します。
注: このユース・ケースに含まれているチュートリアルを示すガイド・ツアーが表示される場合があります。 ガイド・ツアーのリンクから、これらのチュートリアルの説明が開きます。
進捗状況を確認する
以下の画像は、サンプル・プロジェクトを示しています。 これで、チュートリアルを開始する準備ができました。
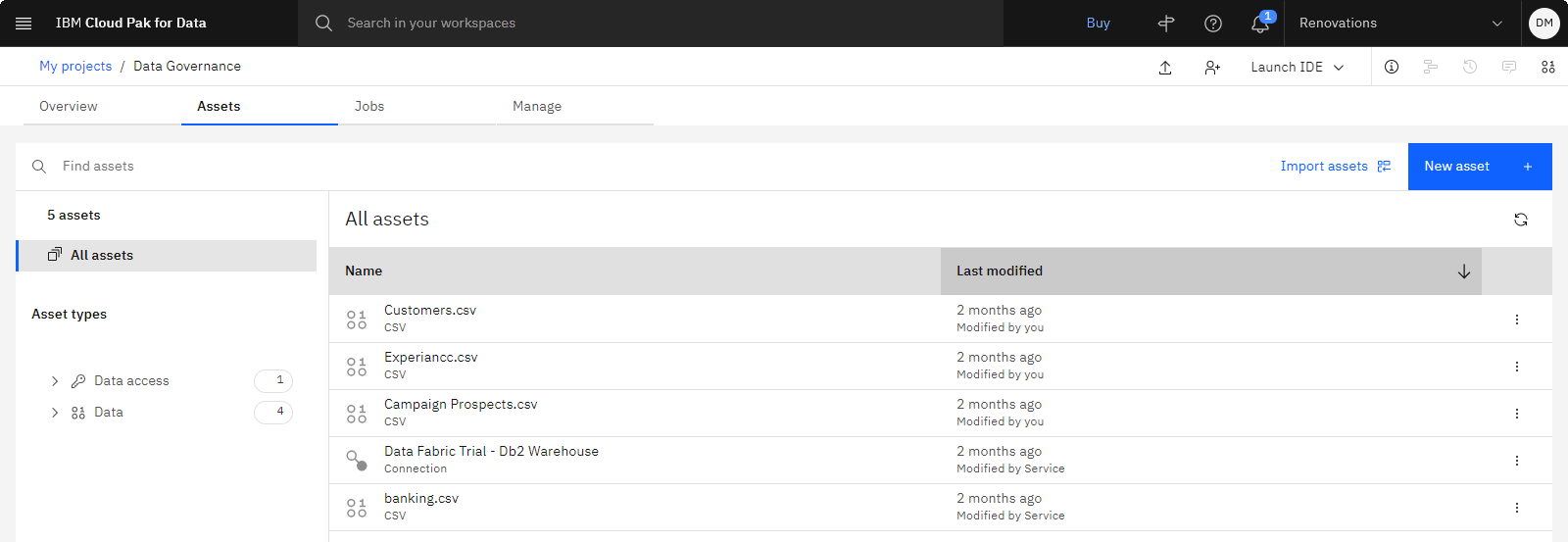
タスク 1: 一致したデータのカタログの作成
このタスクをプレビューするには、 02:08から始まるビデオをご覧ください。
マスター・データおよび一致したデータにアクセスするには、カタログが必要です。 IBM Knowledge Catalog ライト・プランでは、2 つのカタログを作成できます。 既に 2 つのカタログがある場合は、既存のカタログのいずれかを使用して、使用したいカタログの編集者であることを確認できます。
オプション 1: デフォルト・カタログの使用
以下のステップに従って、デフォルト・カタログを使用するための適切なアクセス権限があることを確認します。
ナビゲーションメニュー「
」から、「カタログ」>「すべてのカタログを見る」を選択するこのチュートリアルで使用したいカタログを開きます。
「アクセス制御」 タブをクリックします。
アカウントに 編集者 役割があることを確認します。 アクセス権限が 「ビューアー」の場合は、管理者に連絡して 「編集者」 アクセス権限を要求してください。
オプション 2: 新規カタログの作成
そうでない場合は、以下のステップに従ってカタログを作成します。
「カタログ」 ページで、 「カタログの作成」をクリックします。
「名前」に、表示されているとおりにカタログ名をコピー・アンド・ペーストします。先頭または末尾にスペースは使用しません。
Mortgage Approval Catalog「データ保護ルールの適用 (Enforce data protection rules)」を選択し、選択内容を確認して、他のフィールドのデフォルトを受け入れます。
デフォルト設定を使用するには、 作成 をクリックしてください。 新規カタログが開きます。
進捗状況を確認する
以下のイメージは、カタログを示しています。 カタログが作成されたので、マスター・データをセットアップし、データ資産を追加することができます。
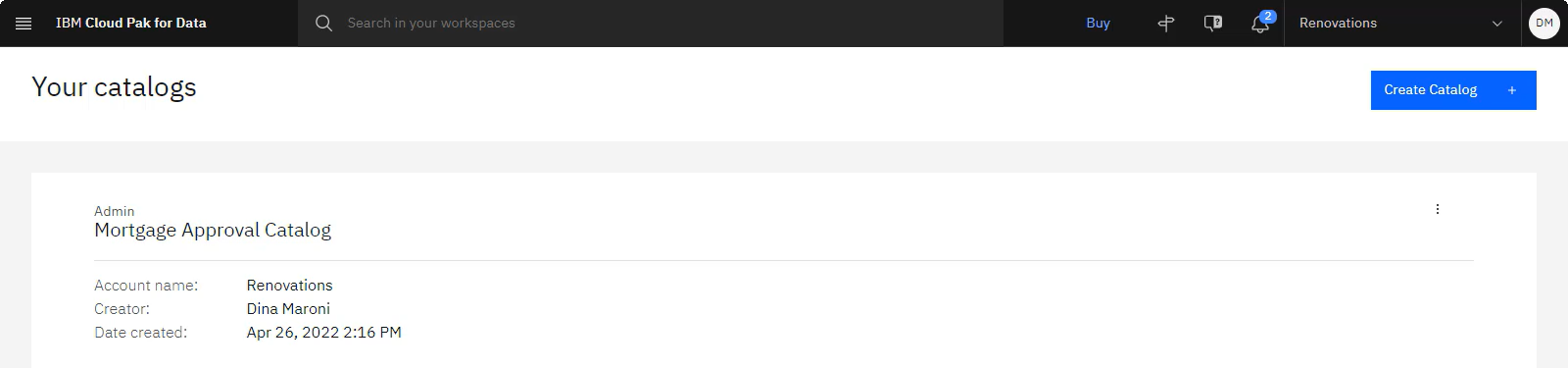
タスク 2: 資産をセットアップしてマスター・データに追加する
このタスクをプレビューするには、02:48から始まるビデオをご覧ください。
統合するすべてのデータ資産をマスター・データに追加する必要があります。 データのソースは、コンピューターのハード・ディスクを含むソースからのものでも、プロジェクトまたはカタログからのデータ資産からのものでもかまいません。
ナビゲーションメニュー「
」から、「データ」>「マスターデータ」を選択する。マスター・データをセットアップする必要がある場合は、 「マスター・データのセットアップ」 をクリックし、必要なプロジェクトおよびサービスをマスター・データに関連付けるための手順に従います。 それ以外の場合は、 構成に移動 をクリックして、次のステップに進みます。
Cloud Object Storage サービスを選択し、 次へをクリックしてください。
Master Data Management プロジェクトを選択し、構成資産のデフォルト名を受け入れて、 「次へ」をクリックします。
既存のカタログを選択し、 「データ保護ルールの適用 (Enfoce data protection rules)」 オプションにチェック・マークを付けてから、 「次へ」をクリックします。
デフォルトのワークフロー構成名を受け入れて、 「終了」をクリックします。
構成を続行 をクリックして、セットアップを完了します。
データ資産から開始をクリックしてください。
「データの追加」をクリックします。
以下の 3 つのデータ資産をすべてプロジェクトに挿入します。
プロジェクト タブを選択します。
3つのcsvファイル(CampaignProspects.csv、Customers.csv、Experiancc.csv)をすべて選択し、「データの挿入」アイコン(
 )をクリックします。
)をクリックします。「データの追加」をクリックします。
担当者レコード・タイプをデータ資産に割り当てます。 レコード・タイプは、資産に含まれるデータのタイプに関する情報を提供します。 各資産にはレコード・タイプが割り当てられている必要があります。これにより、 IBM Match 360 は、データに最適なモデルの部分を見つけることができます。
3 つの資産 ( Campaign Prospects.csv、 Customers.csv、および Experiancc.csv) のチェック・ボックスを選択し、 「資産プロパティーの設定」をクリックします。
データ資産の種類を選択]ドロップダウン リストで、個人データ資産の種類を選択します。
保存 をクリックします。
進捗状況を確認する
以下のイメージは、マスター・データに追加された資産を示しています。 これで、マスター・データがセットアップされ、3 つのデータ資産が追加されたので、データ資産属性のマッピングを開始する準備ができました。
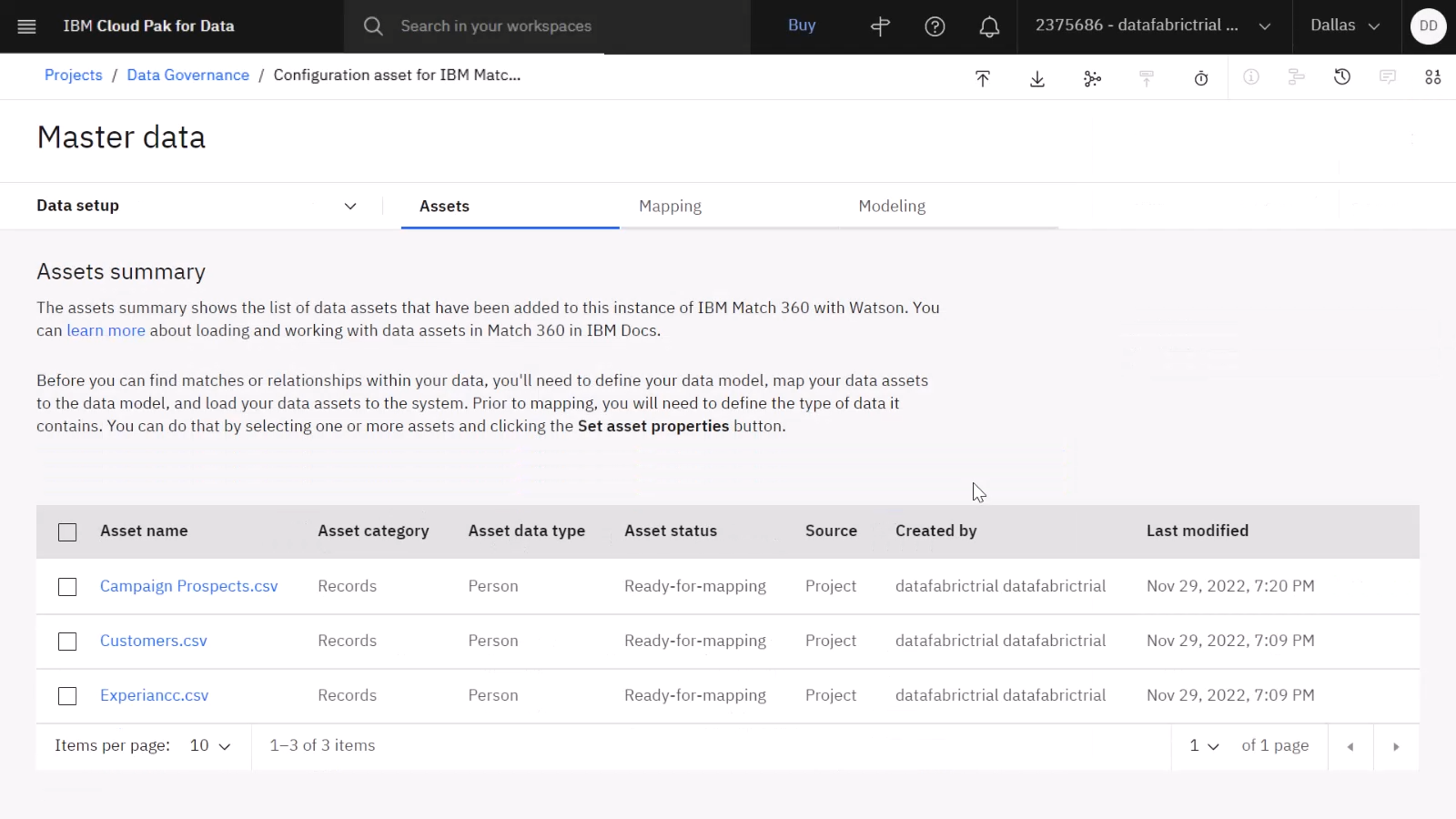
タスク 3: データ資産属性のマップ
このタスクをプレビューするには、03:22から始まるビデオをご覧ください。
IBM Match 360 がすべてのデータと一致するようにするには、各データ・セットのどの列が、 IBM Match 360 によって認識される特定の属性にマップされるかを指定する必要があります。 データ資産属性をマップするには、以下のステップを実行します。
マッピング]タブをクリックし、[ゴット]をクリックして、データ資産の列を適切な属性にマッピングし始めます。
資産リスト パネルで、 Campaign Prospects.csvを選択してください。
サイドパネルでProfile dataをクリックする。 データの列をIBM Match 360データ・モデルの属性に自動的にマッピングするには、データのプロファイリングが前提条件となります。 プロファイル作成には 2 分から 5 分かかります。 データ・プロファイリングが終了すると、Profiling completeと表示される。
プロファイリングが完了したら、Automap assetをクリックしてデータの列を自動的にマッピングします。
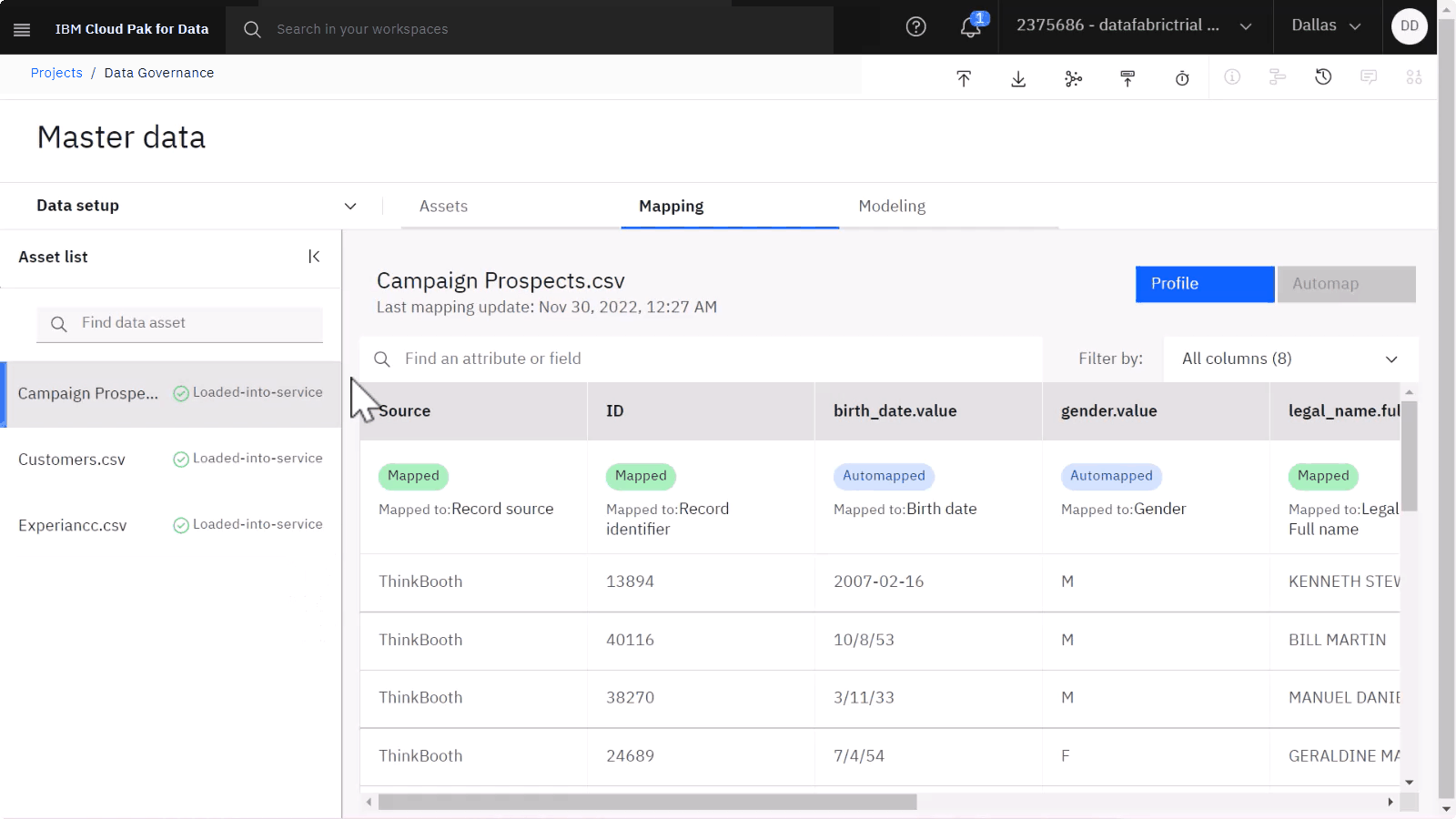
表1: CampaignProspects.csvのマッピングを参照して、ステータスがNot mappedまたは表に従って正しくマッピングされていないすべての列を手動でマッピングします。 カラムを属性にマップするには、「既存の属性をマップする」の例に従ってください。 カラムを除外するには、次の例に従ってください:マッピングからカラムを除外する。
アセット内のすべての列のステータスが[マップ済み]、[自動マップ済み]、または[除外済み]のいずれかになると、次のデータ アセットをマップするオプションが表示されます。
Customers.csvおよびExperiancc.csvアセットについて、ステップ3~5を繰り返します。 それぞれのテーブルを使用して、表 2:Customers.csvのマッピング案、および表 3:Experiancc.csvのマッピング案に従って、これらのデータ資産の列をIBM Match 360データモデルにマッピングします。 個々の属性を手動でマップする方法を説明する例を参照してください。 カラムを既存の属性にマッピングすることも、カラムをマッピングから除外することもできます。
例 1: 既存の属性のマップ
このタスクをプレビューするには、04:07から始まるビデオをご覧ください。
この例では、 Campaign Prospects.csv データ資産の legal_name.full_name 列を既存の属性 legal_name.full_name -Legal name-Full nameにマップする方法について説明します。 IBM Match 360 には、データ・セット内の列のマップ先として選択できる、一般的に顧客レコードに関連付けられるいくつかの属性が提供されています。
列 legal_name.full_nameをクリックします。
「マッピング・ターゲット」 パネルで、検索フィールドに
と入力します。リストからLegal name - Full nameを選択します。 この列は、 「マップ済み」 および 「マップ先: 正式名称-氏名」として表示されます。
これらのステップを繰り返して、データ資産の他の列を、以前に作成した既存の属性、または IBM Match 360 によって提供された既存の属性にマップできます。
例 2: マッピングからの列の除外
このタスクをプレビューするには、05:15から始まるビデオをご覧ください。
この例では、データ資産マッピングから列を除外する方法について説明します。 列がマッチング・プロセス中に IBM Match 360 にとって有用でない場合、または列をマッチング・データ出力に含めない場合は、列をマッピングから除外することができます。
「ソース」という名前の列をクリックします。
チェックボックスExclude columnをトグルする。 この列は 除外と表示されます。
これらのステップを繰り返して、データ資産の他の列を除外することができます。
表 1. Campaign Prospects.csv suggested mapping
| 列 | ターゲット | 方法 |
|---|---|---|
| ソース | マッピングからこの列を除外 | マッピングから列を除外する |
| ID | マッピングからこの列を除外 | マッピングから列を除外する |
| birth_date.value | 生年月日 | 既存の属性をマップする |
| gender.value | 性別 | 既存の属性をマップする |
| legal_name.full_name | 正式名称 - 氏名 | 既存の属性をマップする |
| mobile_telephone.phone_number | 携帯電話 - 電話番号 | 既存の属性をマップする |
| personal_email.email_id | 個人メール - メール・アドレス | 既存の属性をマップする |
| リードの品質 | マッピングからこの列を除外 | マッピングから列を除外する |
表 2. Customers.csv suggested mapping
| 列 | ターゲット | 方法 |
|---|---|---|
| 顧客番号 (Customer Number) | マッピングからこの列を除外 | マッピングから列を除外する |
| 名前 | 正式名称 - 氏名 | 既存の属性をマップする |
| 国 | マッピングからこの列を除外 | マッピングから列を除外する |
| STREET_ADDRESS | 主要住居 - 住所行 1 | 既存の属性をマップする |
| CITY | 主要住居 - 市区町村 | 既存の属性をマップする |
| STATE | 主な居住地 - 州/県値 | 既存の属性をマップする |
| ZIP_CODE | 主要住居 - 郵便番号 | 既存の属性をマップする |
| EMAIL_ADDRESS | 個人メール - メール・アドレス | 既存の属性をマップする |
| PHONE_NUMBER | 自宅電話 - 電話番号 | 既存の属性をマップする |
| GENDER | 性別 | 既存の属性をマップする |
| CREDITCARD_NUMBER | マッピングからこの列を除外 | マッピングから列を除外する |
表 3. Experiancc.csv suggested mapping
| 列 | ターゲット | 方法 |
|---|---|---|
| ソース | マッピングからこの列を除外 | マッピングから列を除外する |
| Experian_ID | マッピングからこの列を除外 | マッピングからこの列を除外 |
| birth_date.value | 生年月日 | 既存の属性をマップする |
| gender.value | 性別 | 既存の属性をマップする |
| home_telephone.phone_number | 自宅電話 - 電話番号 | 既存の属性をマップする |
| legal_name.given_name | 正式名称 - 名前 | 既存の属性をマップする |
| legal_name.last_name | 正式名称 - 姓 | 既存の属性をマップする |
| mobile_telephone.phone_number | 携帯電話 - 電話番号 | 既存の属性をマップする |
| personal_email.email_id | 個人メール - メール・アドレス | 既存の属性をマップする |
| primary_residence.address_line1 | 主要住居 - 住所行 1 | 既存の属性をマップする |
| primary_residence.address_line2 | 主要住居 - 住所行 2 | 既存の属性をマップする |
| primary_residence.city | 主要住居 - 市区町村 | 既存の属性をマップする |
| primary_residence.province_state | マッピングからこの列を除外 | マッピングから列を除外する |
| primary_residence.zip_postal_code | 主要住居 - 郵便番号 | 既存の属性をマップする |
| クレジット・スコア | マッピングからこの列を除外 | マッピングから列を除外する |
| CREDITCARD_NUMBER | マッピングからこの列を除外 | マッピングから列を除外する |
進捗状況を確認する
以下のイメージは、マップされたすべてのデータ資産を示しています。 これで、3 つすべてのデータ資産の属性をマップしたので、データ・モデルを公開してマッチングを実行することができます。

タスク 4: データ・モデルの公開とマッチングの実行
タスク4a:データモデルと全データの公開
このタスクをプレビューするには、05:51から始まるビデオをご覧ください。
データ・モデルは、データ資産のすべての列を属性にマップした後に作成されます。 公開されたデータ・モデルは、すべてのデータ・ソースからの単一エンティティーを解決するために IBM Match 360 によって使用されます。 データ・モデルを公開するには、以下の手順に従ってください。
最後のデータセットの最後の列をマップすると、オプションが表示されます。 モデルの公開をクリックしてください。 あるいは、モデルの発行アイコン '
 を使って、後でモデルを発行することもできます。 このオプションは、3 つのデータ資産のすべての列のマッピングが完了した後に表示されます。 モデルの公開には最大 1 分かかります。 データ・モデルが正常に公開されると、通知を受け取ります。
を使って、後でモデルを発行することもできます。 このオプションは、3 つのデータ資産のすべての列のマッピングが完了した後に表示されます。 モデルの公開には最大 1 分かかります。 データ・モデルが正常に公開されると、通知を受け取ります。データの発行」アイコン「
 クリックし、「データの発行」をクリックして、マッピングに基づいてマッピングされたデータ資産をIBM Match 360データモデルにロードします。 資産の状況が、 「データの公開」 から 「一致準備完了」に変わります。 データがサービスにロードされるまでに 5 分から 10 分かかります。
クリックし、「データの発行」をクリックして、マッピングに基づいてマッピングされたデータ資産をIBM Match 360データモデルにロードします。 資産の状況が、 「データの公開」 から 「一致準備完了」に変わります。 データがサービスにロードされるまでに 5 分から 10 分かかります。
進捗状況を確認する
以下の図は、データ・モデルが正常に公開されたことを示す、サービスにロードされたものとしてリストされたデータ資産を示しています。 次に、マッチングを実行できます。
タスク4b:マッチングのセットアップを完了し、マッチングを実行する
このタスクをプレビューするには、06:23から始まるビデオをご覧ください。
IBM Match 360 は、公開されたデータ・モデルを使用して、データ・ソースのすべてのレコードを単一のエンティティーに統合し、より完全なレコードを持つデータ資産を作成します。 マッチングを実行するには、以下の手順を実行します。
マスターデータ・メニューの「
 」から、マッチング・セットアップの「
」から、マッチング・セットアップの「 」を選択する。
」を選択する。Person エンティティタイプを選択して、レコードの照合方法をカスタマイズします。
マッチング設定タブをクリックし、属性選択画面で「ゴット」をクリックする。 属性の選択、レコードの選択、アルゴリズムの調整、および属性の構成ページの設定を確認します。 このチュートリアルでは、既に選択されているデフォルト属性を受け入れることができます。 ここでは、マッチング・アルゴリズムを支援するために、生年月日、E メール・アドレス、電話番号などのレコードを相互に区別するのに役立つ属性を選択できます。
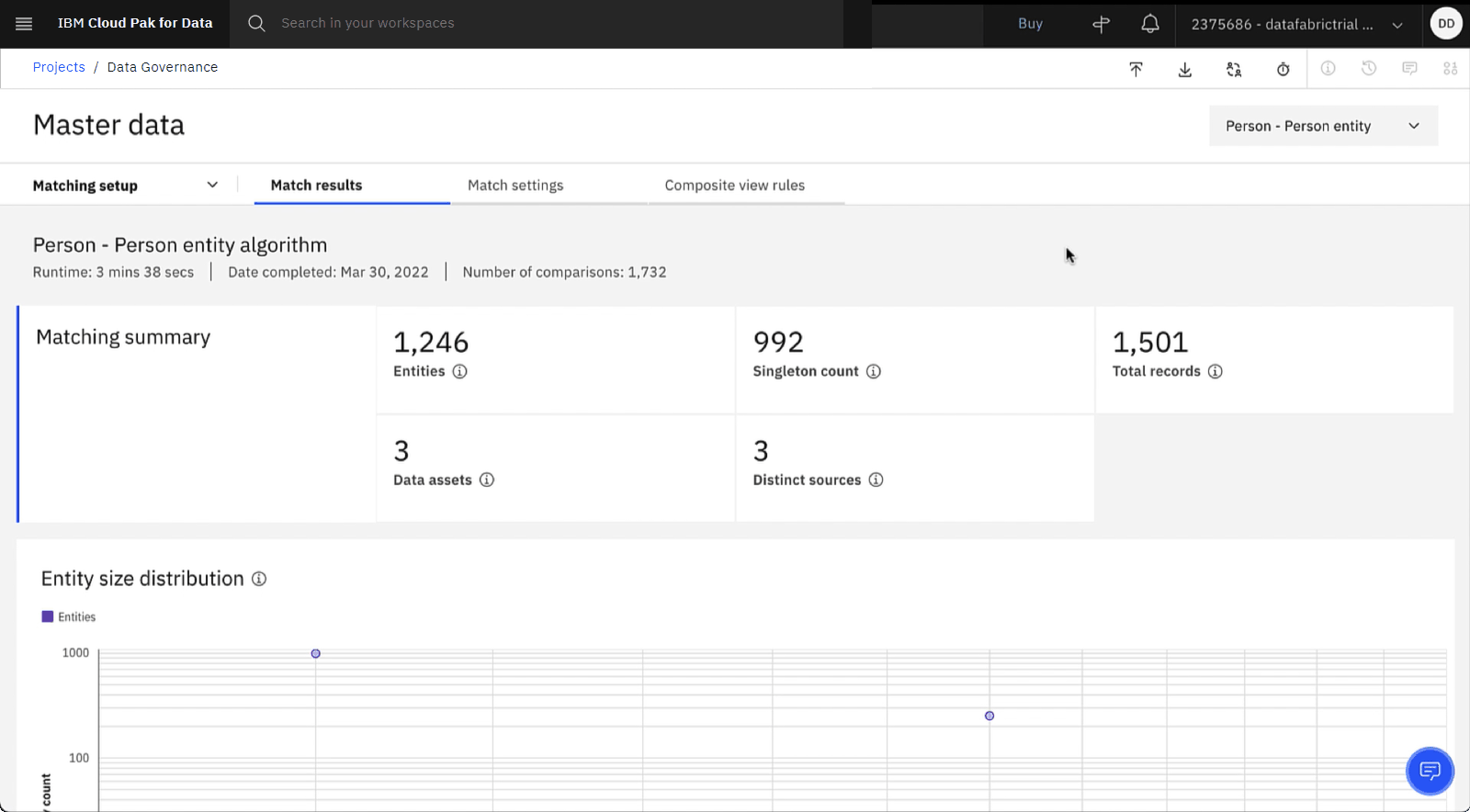
マッチ結果]タブをクリックし、[マッチングの実行]をクリックします。 マッチング・プロセスが完了し、マッチング結果が表示されると、通知を受け取ります。
進捗状況を確認する
以下のイメージは、マッチングを実行した後の結果を示しています。 これで、データ・モデルが公開され、マッチングが実行されたので、一致したデータをカタログに公開する準備ができました。
タスク 5: 一致したデータをカタログに公開する
このタスクをプレビューするには、06:54から始まるビデオをご覧ください。
タスク5a: IBM Match 360用の接続アセットの作成
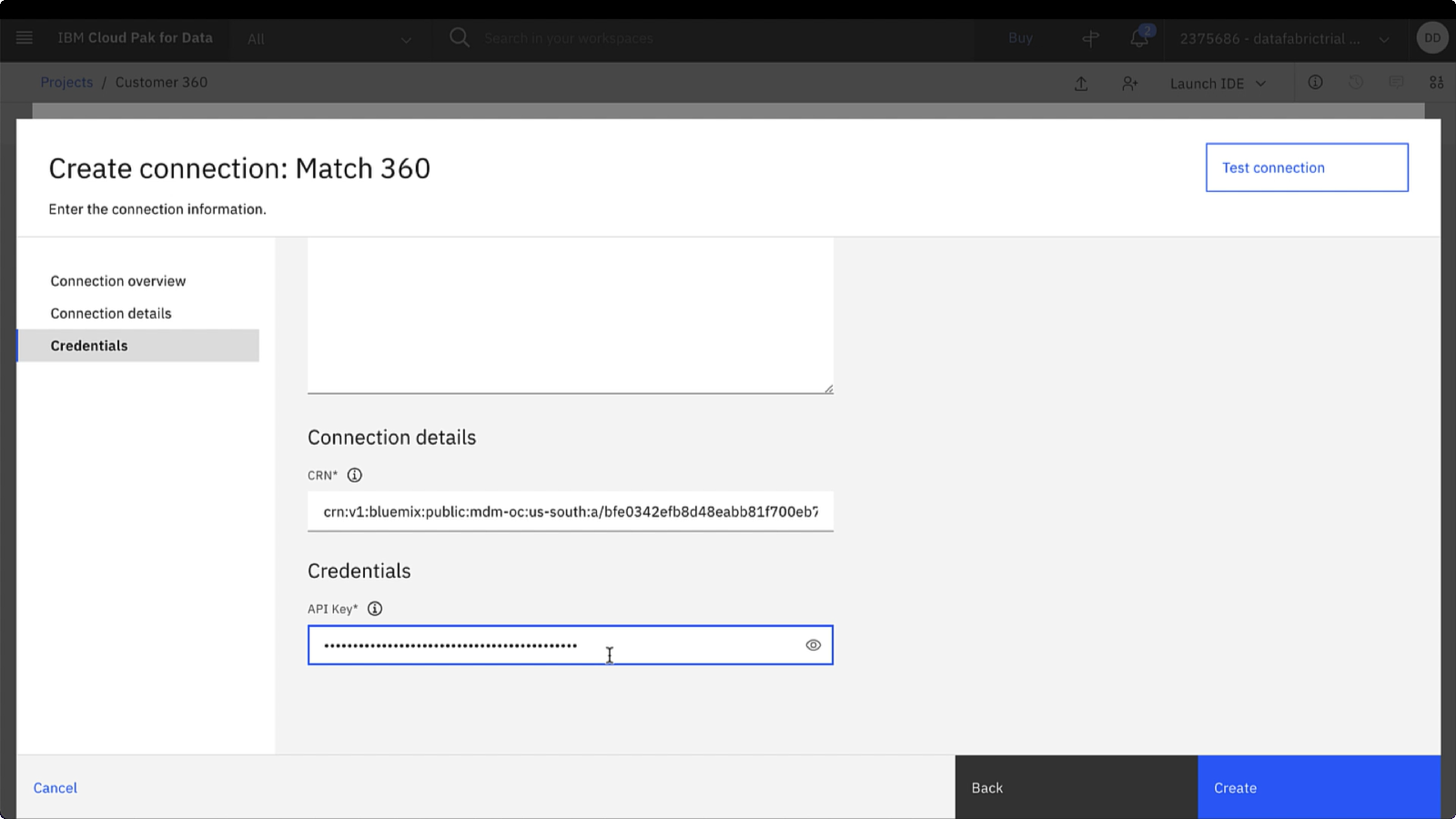
プロジェクト内の一致したデータにアクセスするには、 IBM Match 360への接続資産を作成する必要があります。 IBM Match 360 接続資産は、 IBM Match 360 サービスと一致したデータを、接続されたデータ資産に接続します。 接続資産を作成するには、以下の手順を実行します。
ナビゲーションメニュー「
」から、「プロジェクト」 > 「すべてのプロジェクトを表示」を選択するMaster Data Management サンプル・プロジェクトを選択します。
上の資産タブをクリックして新しいアセット > データソースへの接続。
を選択IBMMatch 360コネクタをクリックし、次。
接続資産名
を入力します。IBM Match 360 with Watson サービス・インスタンスの CRN を取得します:
IBM Cloudコンソールのリソース・リスト・ページから、Analyticsをクリックしてサービス・インスタンスのリストを展開します。
製品 列で、 IBM Match 360 with Watson をクリックしてください。
開いた詳細パネルで、選択した IBM Match 360 with Watson サービスの CRN の クリップボードにコピー アイコンをクリックしてください。
「接続の詳細」に、 IBM Match 360 with Watson サービス・インスタンスに対応する CRN を貼り付けます。
IBM Match 360 API キーを作成します:
IBM Cloud コンソールから、 「管理」> 「アクセス (IAM)」をクリックしてください。
API キー ページをクリックしてください。
「IBM Cloud API キーの作成」をクリックします。 既存の API キーがある場合は、このボタンに 「作成」というラベルを付けることができます。
名前および説明を入力します。
「作成」 をクリックします。
API キーをコピーします 。
将来使用するために API キーをダウンロードします。
「API キー」 フィールドに、作成した API キーを入力します。
「作成」 をクリックします。
ロケーションと主権を設定せずに接続を作成するかどうかの確認を求められたら、 「作成」をクリックします。
あなたの進行状況を確認
以下の画像は、 Match 360 接続資産を示しています。 これで、この接続から接続済みデータ資産を作成できるようになりました。
タスク5b:接続データ資産のインポート
このタスクをプレビューするには、ビデオを視聴してください。 8:32 。
次に、 IBM Match 360 接続を使用して、 IBM Match 360の統合データの新しい接続データ資産を作成します。 接続済みデータ資産を作成するには、以下の手順を実行します。
「アセットのインポート」をクリックします。
「アセットのインポート」 ページで、 「接続済みデータ」を選択します。
Match 360 接続>「records」>「person」>「person_entity」を選択します。
インポート をクリックします。
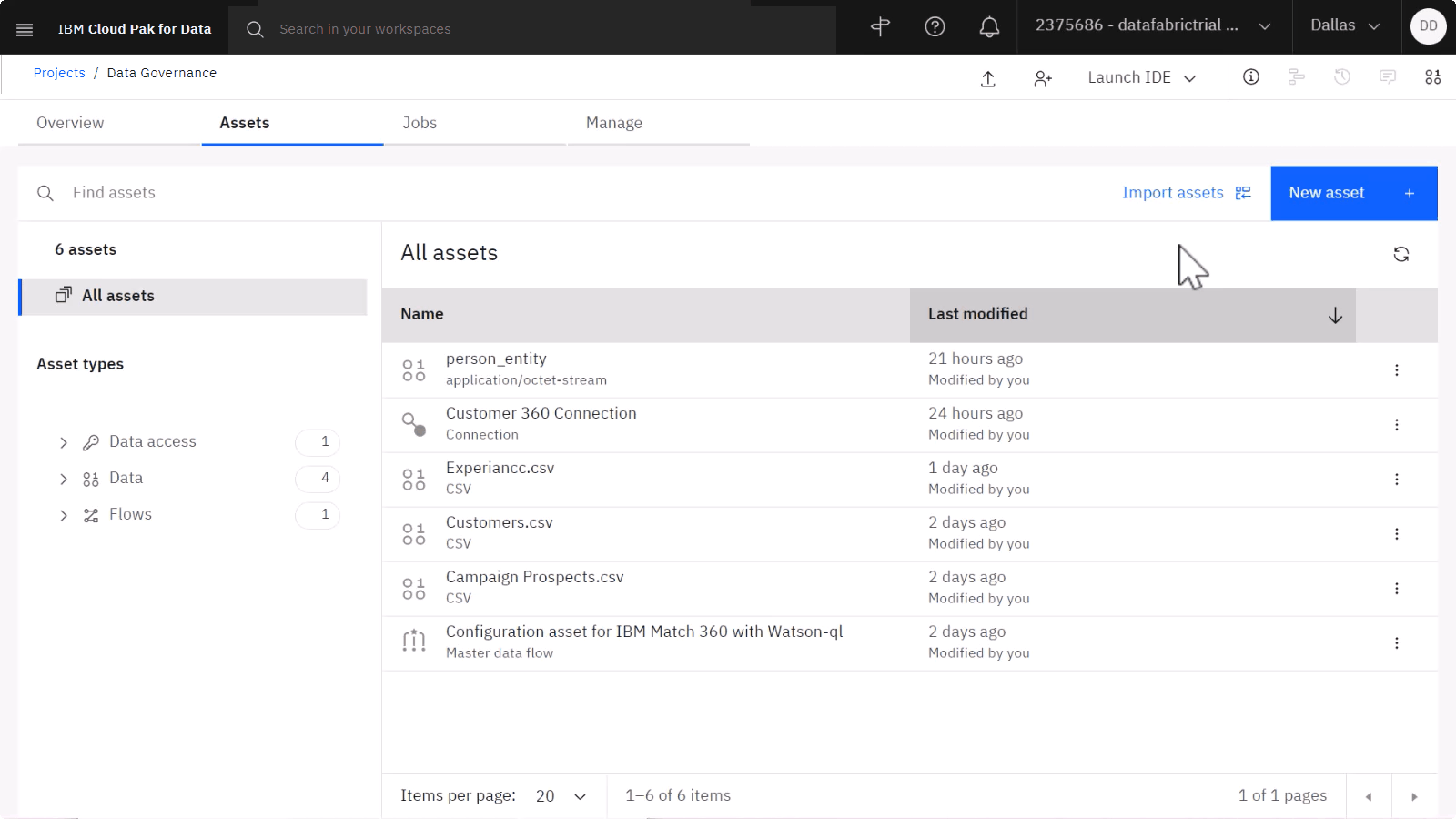
あなたの進行状況を確認
以下の画像は、接続されたデータ資産を示しています。 これで、統合された一致データ用の接続済みデータ資産が作成されたので、その資産をカタログに公開できます。
タスク5c:接続したデータ資産をカタログに公開する
このタスクをプレビューするには、ビデオを視聴してください。 8:55 。
以下のステップに従って、統合された一致データをそのカタログに公開します。
Master Data Management プロジェクトで、 「資産」 タブが表示されていることを確認します。
クリックオーバーフローメニュー
 接続されたデータ資産人物エンティティを選択し、カタログに公開。
接続されたデータ資産人物エンティティを選択し、カタログに公開。リストから 「住宅ローン承認カタログ」 (またはカタログ名) を選択し、 「次へ」をクリックします。
オプションで、 「公開後にカタログに移動」のオプションを選択し、 「次へ」をクリックします。
アセットを確認し、 「公開」をクリックします。
カタログ内の資産を表示および更新します。
カタログに載っていない場合は、ナビゲーションメニュー「
」から「カタログ」>「すべてのカタログを見る」を選択する、 接続したデータ資産を公開したカタログをクリックします。person_entity に接続されたデータ資産をクリックします。
編集名アイコン「
 」をクリックする。 接続するデータ資産の名前「
」をクリックする。 接続するデータ資産の名前「」を入力し、「Apply」をクリックします。資産 タブをクリックして、データをプレビューします。
あなたの進行状況を確認
以下の画像は、カタログ内のデータ資産を示しています。
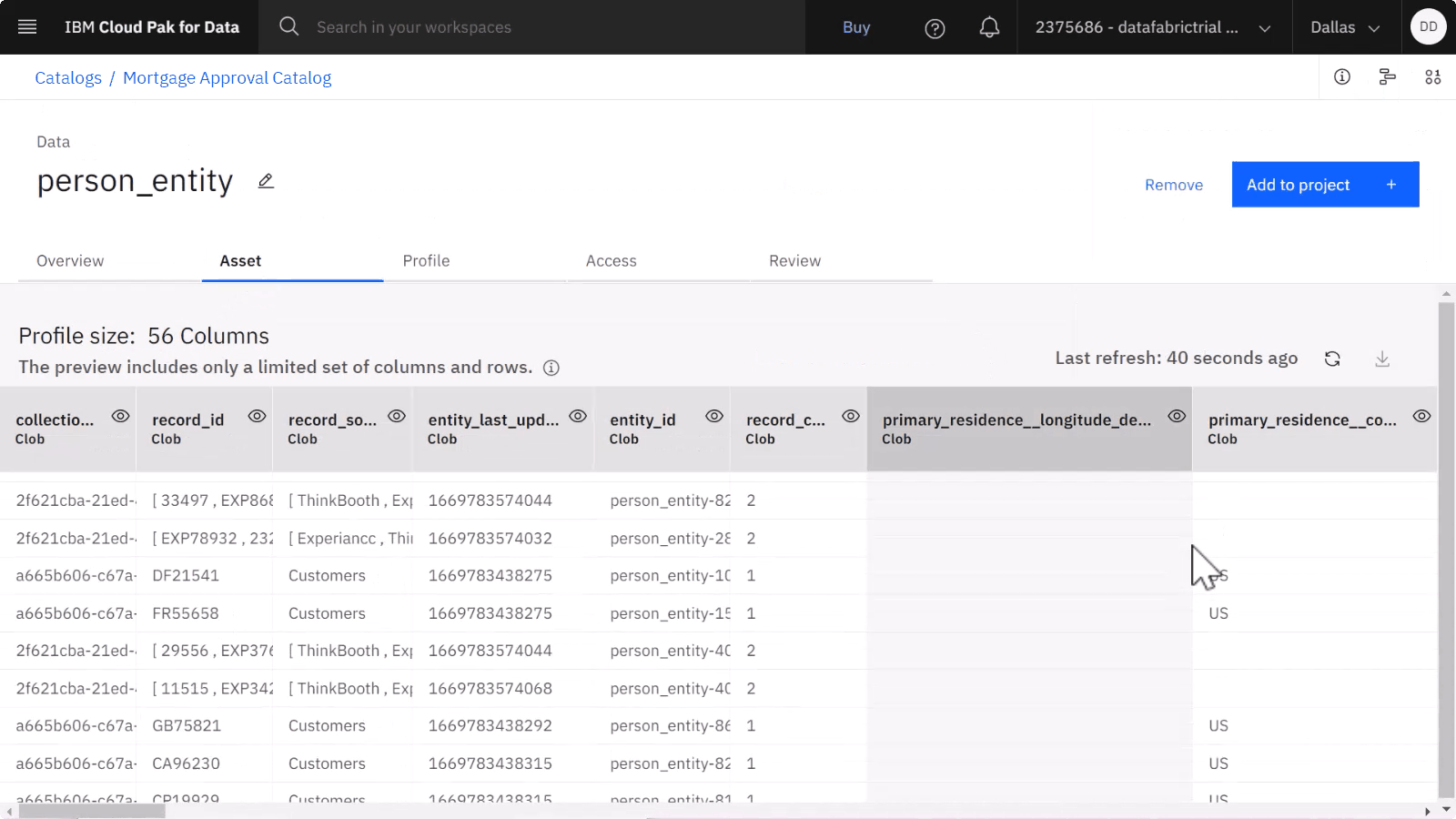
ゴールデン・バンクのデータ・エンジニアは、 IBM Match 360 を使用して、お客様の 360 度の視点でデータをセットアップ、マップ、およびモデル化することに成功しました。 その後、組織内の他のユーザーがアクセスできるように、一致したデータの完全な 360 度ビューをカタログに公開しました。
タスク 6: 一致したデータのプレビュー
このタスクをプレビューするには、ビデオを視聴してください。 09:28 。
これで、モデルまたはデータの変更が IBM Match 360に公開され、マッチング・パラメーターが設定され、マッチングが実行されたので、マスター・データ・エクスプローラーを使用してマッチング・データを照会できます。 マスター・データ・エクスプローラーを使用すると、一致する結果を検索、表示、比較、および編集できます。 現在は、ゴールデン・バンクのデータ・アナリストとして、 IBM Match 360 の結果を分析、検討、および検証して、フォーム・マーケティング・キャンペーンのオファーをターゲットにする最適な顧客を特定して選択する必要があります。 以下のステップに従って、一致するデータを探索および調整します。
ナビゲーションメニュー
から、データ > マスターータをデ選択します。マスターデータメニューの「
」から「search' 選択する。
選択する。検索バーに
を入力し、「Enter」 キーを押して、検索条件として ブランデン・バンクス を追加します。 この検索照会では、Branden Banks に対して 2 つのエンティティーが表示されます。 最初の列の数値 2 は、このエンティティーを構成する 2 つのソース・レコードを示し、最初の列の数値 1 は、一方のソース・レコードが他方のエンティティーを構成することを意味します。両方の事業体を拡大する。 Branden Banks のこれらの別個のエンティティーは 1 人の可能性が高いことが分かります。 これらのエンティティーを単一のエンティティーに結合するために、マッチング・アルゴリズムを調整できます。
進捗状況を確認する
以下のイメージは、マスター・データ・エクスプローラーでの検索結果を示しています。 次に、マッチング・アルゴリズムを調整し、再度マッチングを実行することができます。

タスク 7: マッチング・アルゴリズムのチューニングとマッチングの実行
このタスクをプレビューするには、10:09から始まるビデオをご覧ください。
一致したデータを探索した後、より良い結果を得るために、マッチング・アルゴリズムを微調整して再度マッチングを実行することが必要になる場合があります。
マスターデータのメニュー「
」から、マッチング設定「」を選択する。Person エンティティタイプを選択して、レコードの照合方法をカスタマイズします。
マッチング設定タブをクリックし、属性選択画面で「ゴット」をクリックする。
アルゴリズムチューニングページをクリックする。
マッチ結果]タブをクリックし、[マッチングの実行]をクリックします。 マッチング・プロセスが完了し、マッチング結果が表示されると、通知を受け取ります。
「マスター・データ・エクスプローラー (Master data explorer)」 ドロップダウンをクリックし、メニューから 「マッチング・セットアップ (Matching setup)」 を選択します。
「マッチング設定」 タブをクリックし、 「アルゴリズムのチューニング」 ページを選択します。
Clerical range is enabledフィールドを切り替える。
事務審査基準値フィールドに「
入力する。 このしきい値以下の得点では、試合にはならない。オートリンク閾値フィールドに「
入力する。 しきい値を 20 に減らすと、ソース全体のレコード間の全体的な一致が多くなります。 事務的スコアとオートリンクの閾値の間のスコアは、事務的レビュータスクを生成する。調整されたアルゴリズムでマッチングを実行するには、 「しきい値の適用」>「次へ」>「マッチングの実行」 をクリックします。
「一致結果」 タブをクリックします。 マッチングが終了すると、結果が表示されます。
進捗状況を確認する
以下のイメージは、マッチング・セットアップの結果を示しています。 次に、一致したデータを再度表示して、微調整によって結果がどのように変化したかを確認できます。
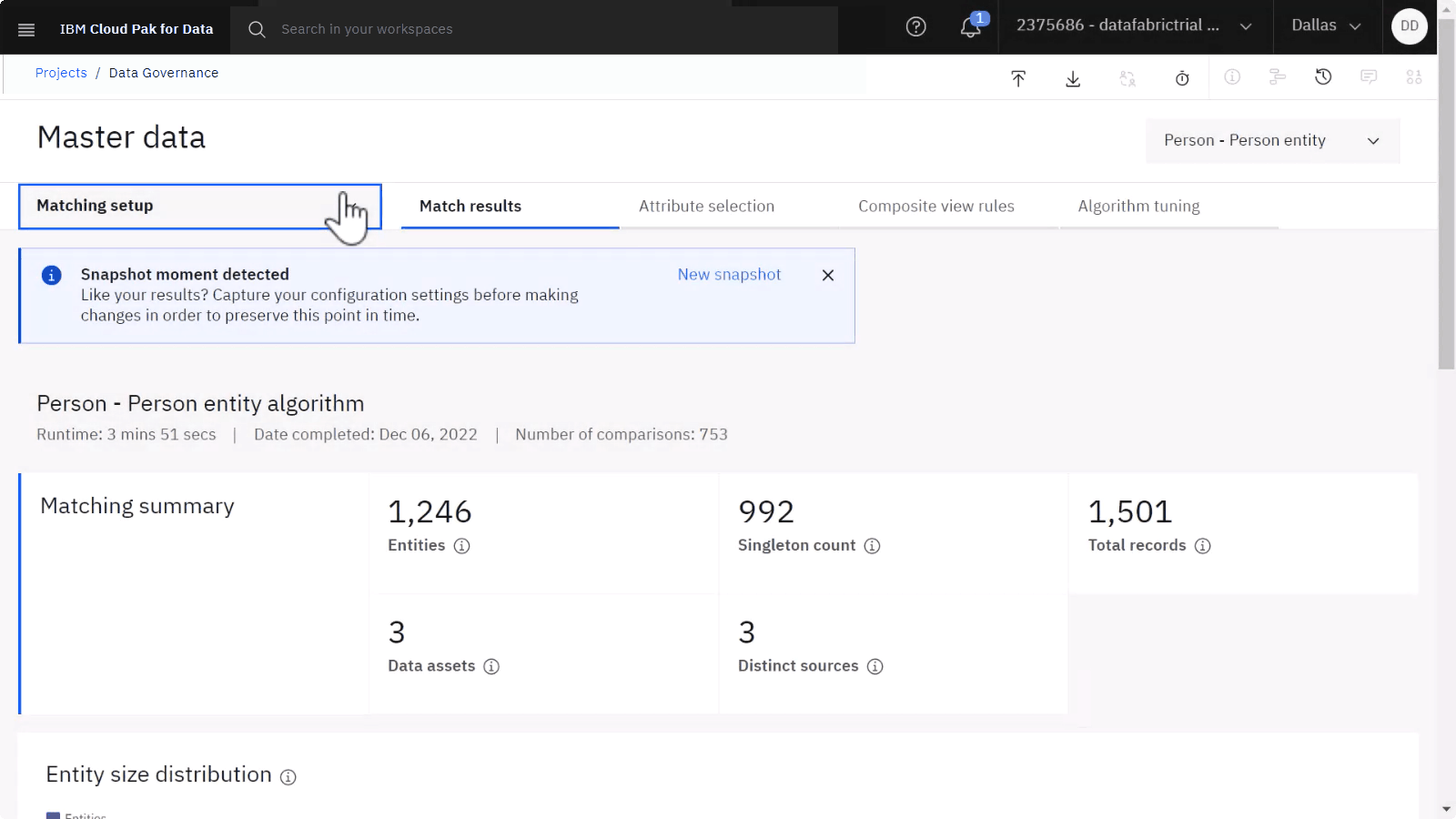
タスク 8: 一致する結果に関する洞察の取得
このタスクをプレビューするには、10:45から始まるビデオを見てください。
マスター・データ・エクスプローラーに戻って、アルゴリズムのチューニングによって一致結果がどのように変更されたかを確認できます。
マスターデータメニューの「
」から「search'選択する。検索バーに
を入力し、「Enter」 キーを押して、検索条件として ブランデン・バンクス を追加します。 表示されているエンティティーに関連付けられている番号 3 は、3 つのレコードがエンティティー Branden バンクスを構成していることを意味します。これらのレコードは、別個のエンティティーに分割される前に複数のエンティティーに分割されています。エンティティーの最初の列の行を展開して、レコードを表示します。 このエンティティーに一致した 3 つのレコードがあると分かります。
進捗状況を確認する
以下のイメージは、マスター・データ・エクスプローラーでの検索結果を示しています。 次に、一致する結果を視覚化することで、洞察を得ることができます。

タスク 9: エンティティーのレコードの視覚化
このタスクをプレビューするには、11:11から始まるビデオを見てください。
また、チューニングしたマッチング結果をノードとして視覚化して、洞察を得ることもできます。
Show graph をクリックして、照会されたエンティティーに貢献しているレコードを確認します。
個人エンティティーに接続されているいずれかのノードをクリックすると、そのエンティティーに関連付けられている詳細が表示されます。 ここから、どのレコードが照会のどのエンティティーに関連付けられているかを視覚化して手動で変更し、必要に応じて修正することができます。
進捗状況を確認する
以下の画像は、検索結果をグラフとして示しています。

データ・アナリストとして、 IBM Match 360 の結果を分析、探索、および検証して、マーケティング・キャンペーン・オファーのターゲットにする最適な顧客を特定し、選択しました。
クリーンアップ (オプション)
このユースケースのチュートリアルを再度受講したい場合は、以下の成果物を削除してください。
| 成果物 | 削除方法 |
|---|---|
| 住宅ローン承認カタログ | カタログの削除 |
| Master Data Management サンプル・プロジェクト | プロジェクトの削除 |
次のステップ
以下のチュートリアルをお試しください。
別のデータファブリックの使用例を表示します。
もっと見る
親トピック: ユース・ケースのチュートリアル
トピックは役に立ちましたか?
0/1000