Configure los nodos de la interconexión para especificar entradas y para crear salidas como parte de la interconexión.
Especificación del ámbito del espacio de trabajo
De forma predeterminada, el ámbito de un conducto es el proyecto que contiene el conducto. Puede especificar explícitamente un ámbito que no sea el predeterminado, para localizar un activo utilizado en el conducto. El ámbito es el proyecto, catálogo o espacio que contiene el activo. En la interfaz de usuario, puede buscar el ámbito.
Cambio de la modalidad de entrada
Al configurar un nodo, puede especificar cualquier recurso que incluya datos y cuadernos de varias maneras. Por ejemplo, especificar directamente un nombre o ID, examinar un activo o utilizar la salida de un nodo anterior en la interconexión para llenar un campo. Para ver qué opciones hay disponibles para un campo, pulse el icono de entrada del campo. Dependiendo del contexto, las opciones pueden incluir:
- Seleccionar un recurso: utilice el examinador de activos para buscar un activo, por ejemplo, un archivo de datos.
- Asignar parámetro de interconexión: asignar un valor utilizando una variable configurada con un parámetro de interconexión. Para obtener más información, consulte Configuración de objetos globales.
- Seleccionar otro nodo: utilice la salida de un nodo anterior en la interconexión como valor para este campo.
- Especifique la expresión: especifique el código para asignar valores o identificar recursos. Para obtener más información, consulte Elementos de codificación.
Nodos y parámetros de interconexión
Configure los siguientes tipos de nodos de interconexión:
Copia de nodos
Utilice los nodos Copiar para añadir activos a su conducto o para exportar activos de conducto.
Copiar activos seleccionados de un proyecto o espacio en un espacio no vacío. Puede copiar estos activos en un espacio:
Experimento de AutoAI
Trabajo de paquete de código
Conexión
Flujo de Data Refinery
Trabajo de Data Refinery
Activo de datos
Trabajo de despliegue
Entorno
Función
Trabajo
Modelo
Cuaderno
Trabajo de cuaderno
Trabajo de canalizaciones
Script
Trabajo de script
Trabajo de SPSS Modeler
Copiar activos
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Activos de origen | Examine o busque el activo de origen para añadirlo a la lista. También puede especificar un activo con un parámetro de interconexión, con la salida de otro nodo, o especificando el ID de activo |
| Destino | Examinar o buscar el espacio de destino |
| Modalidad de copia | Elija cómo manejar un caso en el que el flujo intenta copiar un activo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Activos de salida | Lista de activos copiados |
Exportar activos
Exporte los activos seleccionados del ámbito, por ejemplo, un proyecto o espacio de despliegue. La operación exporta todos los activos de forma predeterminada. Para limitar la selección de activos, cree una lista de recursos que desee exportar.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Activos | Elija Ámbito para exportar todos los elementos exportables o elija Lista para crear una lista de elementos específicos para exportar |
| Proyecto o espacio de origen | Nombre del proyecto o espacio que contiene los activos a exportar |
| Archivo exportado | Ubicación de archivo para almacenar el archivo de exportación |
| Modalidad de creación (opcional) | Elija cómo manejar un caso en el que el flujo intenta crear un activo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Archivo exportado | Vía de acceso al archivo exportado |
Notas:
- Si exporta activos de proyecto que contienen un cuaderno, la versión más reciente del cuaderno se incluye en el archivo de exportación. Si la interconexión con el nodo Ejecutar trabajo de cuaderno se ha configurado para utilizar una versión de cuaderno distinta de la versión más reciente, la interconexión exportada se vuelve a configurar automáticamente para utilizar la versión más reciente cuando se importa. Esto puede producir resultados inesperados o requerir alguna reconfiguración después de la importación.
- Si los activos están autocontenidos en el proyecto exportado, se conservan al importar un proyecto nuevo. De lo contrario, es posible que sea necesaria alguna configuración después de una importación de activos exportados.
Importar activos
Importar activos de un archivo ZIP que contiene activos exportados.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Vía de acceso para importar destino | Examinar o buscar los activos que se han de importar |
| Archivo de archivado que se ha de importar | Especificar la vía de acceso a un archivo ZIP o archivado |
Notas: Después de importar un archivo, se actualizan las vías de acceso y las referencias a los activos importados, siguiendo estas reglas:
- Las referencias a activos del proyecto o espacio exportado se actualizan en el nuevo proyecto o espacio después de la importación.
- Si los activos del proyecto exportado hacen referencia a activos externos (incluidos en un proyecto diferente), la referencia al activo externo persistirá después de la importación.
- Si el activo externo ya no existe, el parámetro se sustituye por un valor vacío y debe volver a configurar el campo para que apunte a un activo válido.
Crear nodos
Configure los nodos para crear activos en la interconexión.
Crear experimento de AutoAI
Utilice este nodo para entrenar un experimento de regresión o clasificación deAutoAI y generar interconexiones candidatas a modelo.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Nombre del experimento de AutoAI | Nombre del nuevo experimento |
| Ámbito | Un proyecto o un espacio, donde se va a crear el experimento |
| Tipo de predicción | El tipo de modelo para los datos siguientes: binario, clasificación o regresión |
| Columna de predicción (etiqueta) | El nombre de columna de predicción |
| Clase positiva (opcional) | Especificar una clase positiva para un experimento de clasificación binaria |
| Proporción de división de datos de entrenamiento (opcional) | El porcentaje de datos que se retienen del entrenamiento y se utilizan para probar las interconexiones (flotante: 0.0 - 1.0) |
| Algoritmos a incluir (opcional) | Limitar la lista de estimadores que deben utilizarse (la lista depende del tipo de aprendizaje) |
| Algoritmos que se van a utilizar | Especifique la lista de estimadores que se van a utilizar (la lista depende del tipo de aprendizaje) |
| Métrica de optimización (opcional) | la métrica utilizada para la clasificación de modelos |
| Especificación de hardware (opcional) | Especifique una especificación de hardware para el experimento |
| Descripción del experimento de AutoAI | Descripción del experimento |
| Etiquetas de experimento de AutoAI (opcional) | Etiquetas para identificar el experimento |
| Modalidad de creación (opcional) | Elija cómo manejar un caso en el que la interconexión intenta crear un experimento y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Experimento de AutoAI | Vía de acceso al modelo guardado |
Crear experimento de serie temporal de AutoAI
Utilice este nodo para entrenar un experimento de serie temporal deAutoAI y generar interconexiones candidatas a modelo.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Nombre de experimento de serie temporal de AutoAI | Nombre del nuevo experimento |
| Ámbito | un proyecto o un espacio, donde se va a crear la interconexión |
| Columnas de predicción (etiqueta) | El nombre de una o más columnas de predicción |
| Columna de fecha/hora (opcional) | Nombre de la columna de fecha/hora |
| Aproveche los valores futuros de las características de soporte | Elija "True" para habilitar la consideración de las características de soporte (exógenas) para mejorar la predicción. Por ejemplo, incluya una característica de temperatura para predecir las ventas de helados. |
| Características de soporte (opcional) | Elija las características de soporte y añádalas a la lista |
| Método de imputación (opcional) | Elegir una técnica para imputar valores perdidos en un conjunto de datos |
| Umbral de imputación (opcional) | Especifique un umbral superior para el porcentaje de valores perdidos que deben proporcionarse con el método de imputación especificado. Si se supera el umbral, el experimento falla. Por ejemplo, si especifica que se puede imputar el 10% de los valores y al conjunto de datos le falta el 15% de los valores, el experimento falla. |
| Tipo de relleno | Especifique cómo el método de imputación especificado rellena los valores nulos. Elija proporcionar una media de todos los valores y una mediana de todos los valores, o especifique un valor de relleno. |
| Valor de relleno (opcional) | Si ha seleccionado especificar un valor para sustituir valores nulos, especifique el valor en este campo. |
| Conjunto de datos de entrenamiento final | Elija si desea entrenar las interconexiones finales sólo con los datos de entrenamiento o con los datos de entrenamiento y los datos reservados. Si elige datos de entrenamiento, el cuaderno generado incluye una celda para recuperar los datos reservados |
| Tamaño de reserva (opcional) | Si está dividiendo los datos de entrenamiento en datos de entrenamiento y reservados, especifique un porcentaje de los datos de entrenamiento para reservarlos como datos reservados para validar las interconexiones. Los datos reservados no superan un tercio de los datos. |
| Número de pruebas de retroceso (opcional) | Personalizar las pruebas de reserva para validar de forma cruzada el experimento de la serie temporal |
| Longitud de espacio (opcional) | Ajuste el número de puntos de tiempo entre el conjunto de datos de entrenamiento y el conjunto de datos de validación para cada prueba de fondo. Cuando el valor del parámetro es distinto de cero, los valores de serie temporal del espacio no se utilizan para entrenar el experimento o evaluar la prueba de retroceso actual. |
| Ventana de búsqueda (opcional) | Un parámetro que indica cuántos valores de series temporales anteriores se utilizan para pronosticar el punto temporal actual. |
| Ventana de previsión (opcional) | El rango que desea predecir basándose en los datos de la ventana de búsqueda. |
| Algoritmos a incluir (opcional) | Limitar la lista de estimadores que deben utilizarse (la lista depende del tipo de aprendizaje) |
| Interconexiones para completar | Opcionalmente, ajuste el número de interconexiones que desea crear. Más interconexiones aumentan el tiempo y los recursos de formación. |
| Especificación de hardware (opcional) | Especifique una especificación de hardware para el experimento |
| Descripción del experimento de serie temporal AutoAI (opcional) | Descripción del experimento |
| Etiquetas de experimento de AutoAI (opcional) | Etiquetas para identificar el experimento |
| Modalidad de creación (opcional) | Elija cómo manejar un caso en el que la interconexión intenta crear un experimento y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Experimento de serie temporal de AutoAI | Vía de acceso al modelo guardado |
Crear un despliegue por lotes
Utilice este nodo para crear un despliegue por lotes para un modelo de aprendizaje automático.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Activo ML | Nombre o ID del activo de aprendizaje automático que se va a desplegar |
| Nuevo nombre de despliegue (opcional) | Nombre del nuevo trabajo, con una descripción opcional y etiquetas |
| Modalidad de creación (opcional) | Cómo manejar un caso en el que la interconexión intenta crear un trabajo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
| Nueva descripción de despliegue (opcional) | Descripción del despliegue |
| Nuevas etiquetas de despliegue (opcional) | Etiquetas para identificar el despliegue |
| Especificación de hardware (opcional) | Especifique una especificación de hardware para el trabajo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Nuevo despliegue | Vía de acceso del despliegue que se acaba de crear |
Crear activo de datos
Utilice este nodo para crear un activo de datos.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Archivo | Vía de acceso al archivo en un almacenamiento de archivos |
| Ámbito de destino | Vía de acceso al espacio de destino o proyecto |
| Nombre (opcional) | Nombre del origen de datos con descripción opcional, país de origen y etiquetas |
| Descripción (opcional) | Descripción del activo |
| País de origen (opcional) | País de origen para la normativa de datos |
| Etiquetas (opcional) | Etiquetas para identificar activos |
| Modalidad de creación | Cómo manejar un caso en el que la interconexión intenta crear un trabajo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Activo de datos | El activo de datos recién creado |
Crear un espacio de despliegue
Utilice este nodo para crear y configurar un espacio que puede utilizar para organizar y crear despliegues.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Nombre del espacio nuevo | Nombre del nuevo espacio, con una descripción opcional y etiquetas |
| Nuevos códigos de espacio (opcional) | Etiquetas para identificar el espacio |
| CRN de la instancia COS del nuevo espacio | CRN de la instancia de servicio COS |
| Nuevo CRN de instancia de WML de espacio (opcional) | CRN de la instancia de servicio watsonx.ai Runtime |
| Modalidad de creación (opcional) | Cómo manejar un caso en el que la interconexión intenta crear un espacio y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
| Descripción de espacio (opcional) | Descripción del espacio |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Espacio | Vía de acceso del espacio recién creado |
Crear implementación en línea
Utilice este nodo para crear un despliegue en línea donde puede enviar datos de prueba directamente a un punto final de API REST de servicio web.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Activo ML | Nombre o ID del activo de aprendizaje automático que se va a desplegar |
| Nuevo nombre de despliegue (opcional) | Nombre del nuevo trabajo, con una descripción opcional y etiquetas |
| Modalidad de creación (opcional) | Cómo manejar un caso en el que la interconexión intenta crear un trabajo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
| Nueva descripción de despliegue (opcional) | Descripción del despliegue |
| Nuevas etiquetas de despliegue (opcional) | Etiquetas para identificar el despliegue |
| Especificación de hardware (opcional) | Especifique una especificación de hardware para el trabajo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Nuevo despliegue | Vía de acceso del despliegue que se acaba de crear |
Esperar
Utilice los nodos para poner en pausa una interconexión hasta que haya un activo disponible en la ubicación especificada en la vía de acceso.
Utilice este nodo para esperar hasta que todos los resultados de los nodos anteriores de la interconexión estén disponibles para que la interconexión pueda continuar.
Este nodo no recibe entradas ni produce salidas. Cuando los resultados estén todos disponibles, la interconexión continuará automáticamente.
Esperar todos los resultados
Utilice este nodo para esperar hasta que cualquier resultado de los nodos anteriores de la interconexión esté disponible para que la interconexión pueda continuar. Ejecute los nodos en sentido descendente tan pronto como se cumpla alguna de las condiciones en sentido ascendente.
Este nodo no recibe entradas ni produce salidas. Cuando hay resultados disponibles, la interconexión continúa automáticamente.
Esperar a cualquier resultado
Espere a que se cree o actualice un activo en la ubicación especificada en la vía de acceso desde un trabajo o proceso anterior en la interconexión. Especifique una duración de tiempo de espera para esperar a que se cumpla la condición. Si 00:00:00 es la longitud de tiempo de espera especificada, el flujo espera indefinidamente.
Esperar un archivo
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Ubicación del archivo | Especifique la ubicación en el navegador de activos donde reside el activo. Utilice el formato data_asset/filename donde la vía de acceso es relativa a la raíz. El archivo debe existir y estar en la ubicación que especifique o el nodo falla con un error. |
| Modalidad de espera | De forma predeterminada, la modalidad es que aparezca el archivo. Puede cambiar a esperar a que el archivo desaparezca |
| Longitud de tiempo de espera (opcional) | Especifique el periodo de tiempo que se debe esperar antes de continuar con la interconexión. Utilice el formato hh:mm:ss |
| Política de error (opcional) | Consulte Manejo de errores |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Valor de retorno | Valor de retorno del nodo |
| Estado de ejecución | Devuelve un valor de: Completado, Completado con avisos, Completado con errores, Anómalo o Cancelado |
| Mensaje de estado | Mensaje asociado con el estado |
Nodos de control
Controle la interconexión añadiendo el manejo de errores y la lógica.
Los bucles son un nodo de una interconexión que funciona como un bucle codificado.
Los dos tipos de bucles son paralelos y secuenciales.
Puede utilizar bucles cuando el número de iteraciones para una operación es dinámico. Por ejemplo, si no conoce el número de cuadernos a procesar, o si desea elegir el número de cuadernos en tiempo de ejecución, puede utilizar un bucle para iterar por la lista de cuadernos.
También puede utilizar un bucle para iterar por la salida de un nodo o por los elementos de una matriz de datos.
Bucles en paralelo
Añada una construcción de bucle paralelo a la interconexión. Un bucle paralelo ejecuta los nodos de iteración de forma independiente y posiblemente simultáneamente.
Por ejemplo, para entrenar un modelo de aprendizaje automático con un conjunto de hiperparámetros para encontrar el mejor rendimiento, puede utilizar un bucle para iterar sobre una lista de hiperparámetros para entrenar las variaciones del cuaderno en paralelo. Los resultados se pueden comparar más adelante en el flujo para encontrar el mejor cuaderno.
Parámetros de entrada al iterar tipos de lista
| Parámetro | Descripción |
|---|---|
| Entrada de lista | El parámetro Entrada de lista contiene dos campos, el tipo de datos de la lista y el contenido de la lista que el bucle itera o un enlace estándar a la entrada de interconexión o salida de interconexión. |
| Paralelismo | Número máximo de tareas que se deben ejecutar simultáneamente. Debe ser mayor que cero |
Parámetros de entrada al iterar tipos de serie
| Parámetro | Descripción |
|---|---|
| Entrada de texto | Datos de texto de los que lee el bucle |
| Separador | Un carácter utilizado para dividir el texto |
| Paralelismo (opcional) | Número máximo de tareas que se deben ejecutar simultáneamente. Debe ser mayor que cero |
Si el tipo de elemento de matriz de entrada es JSON o cualquier tipo que esté representado como tal, este campo puede descomponerlo como diccionario. Las claves son las claves del elemento original y los valores son los alias de los nombres de salida.
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Control Break Nodo ID | Contiene el ID del nodo terminador en el que terminó el nodo, vacío en caso contrario |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del trabajo |
Bucles en secuencia
Añada una construcción de bucle secuencial a la interconexión. Los bucles pueden iterar sobre un rango numérico, una lista o texto con un delimitador.
Un caso de uso para bucles secuenciales es si desea intentar una operación 3 veces antes de determinar si una operación ha fallado.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Entrada de lista | El parámetro Entrada de lista contiene dos campos, el tipo de datos de la lista y el contenido de la lista que el bucle itera o un enlace estándar a la entrada de interconexión o salida de interconexión. |
| Entrada de texto | Datos de texto de los que lee el bucle. Especifique un carácter para dividir el texto. |
| Rango | Especifique el paso inicial, final y opcional para un rango sobre el que iterar. El paso predeterminado es 1. |
Después de configurar el rango iterativo de bucle, defina un flujo de subinterconexión dentro del bucle para que se ejecute hasta que se complete el bucle. Por ejemplo, puede invocar cuaderno, script u otro flujo por iteración.
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Control Break Nodo ID | Contiene el ID del nodo terminador en el que terminó el nodo, vacío en caso contrario |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del trabajo |
Terminar bucle
En un flujo de proceso de bucle paralelo o secuencial, puede añadir un nodo Terminar interconexión para finalizar el proceso de bucle en cualquier momento. Debes personalizar tus propias condiciones de rescisión. En los nodos, puedes cambiar el estado del bucle cuando termina como Completo o Fallo. Esto garantiza que pueda completar el bucle y seguir cumpliendo las condiciones del nodo de bucle que falla y elegir continuar con la canalización o realizar otras acciones.
Establecer variables de usuario
Configure una variable de usuario con un par de clave/valor y, a continuación, añada la lista de variables dinámicas para este nodo.
Para obtener más información sobre cómo crear una variable de usuario, consulte Configuración de objetos globales.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Nombre | Escriba el nombre o la clave para la variable |
| Tipo de entrada | Elija el parámetro Expresión o Interconexión como tipo de entrada. |
- Para expresiones, utilice el Generador de expresiones incorporado para crear una variable que resulte de una expresión personalizada.
- Para los parámetros de interconexión, asigne un parámetro de interconexión y utilice el valor de parámetro como entrada para la variable de usuario.
Finalizar interconexión
Puede iniciar y controlar la terminación de un conducto con un nodo Terminar conducto desde la categoría Control. Cuando se ejecuta el flujo de errores, puede especificar opcionalmente cómo manejar los trabajos de cuaderno o de entrenamiento iniciados por nodos en la interconexión. Debe especificar si desea esperar a que finalicen los trabajos, cancelar los trabajos y, a continuación, detener la interconexión o detenerlo todo sin cancelar. Especifique las opciones para el nodo de interconexión Terminar.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Modalidad de terminador (opcional) | Seleccione el comportamiento del flujo de errores |
La modalidad de terminador puede ser:
- Terminar ejecución de interconexión y todos los trabajos en ejecución detiene todos los trabajos y detiene la interconexión.
- Cancelar todos los trabajos en ejecución y luego terminar la interconexión cancela los trabajos en ejecución antes de detener la interconexión.
- Terminar la ejecución de interconexión después de que finalicen los trabajos en ejecución espera a que finalicen los trabajos en ejecución y, a continuación, detiene la interconexión.
- Terminar interconexión que se ejecuta sin detener trabajos detiene la interconexión pero permite que continúen los trabajos en ejecución.
Actualizar nodos
Utilice los nodos de actualización para sustituir o actualizar activos para mejorar el rendimiento. Por ejemplo, si desea estandarizar las etiquetas, puede actualizarse para sustituir una etiqueta por otra.
Actualice los detalles de entrenamiento para un experimento de AutoAI.
Actualizar experimento de AutoAI
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Experimento de AutoAI | Vía de acceso a un proyecto o espacio donde reside el experimento |
| Nombre de experimento de AutoAI (opcional) | Nombre del experimento que se va a actualizar, con etiquetas y una descripción opcional |
| Descripción del experimento AutoAI (opcional) | Descripción del experimento |
| Etiquetas de experimento de AutoAI (opcional) | Etiquetas para identificar el experimento |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Experimento de AutoAI | Vía de acceso del experimento actualizado |
Actualizar un despliegue por lotes
Utilice estos parámetros para actualizar un despliegue por lotes.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| virtual | Vía de acceso al despliegue que se va a actualizar |
| Nuevo nombre para el despliegue (opcional) | Nombre o ID del despliegue que se actualizará |
| Nueva descripción para el despliegue (opcional) | Descripción del despliegue |
| Nuevas etiquetas para el despliegue (opcional) | Etiquetas para identificar el despliegue |
| Activo ML | Nombre o ID del activo de aprendizaje automático que se va a desplegar |
| Especificaciones de hardware | Actualizar la especificación de hardware para el trabajo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| virtual | Vía de acceso del despliegue actualizado |
Actualizar un espacio de despliegue
Actualice los detalles de un espacio.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Espacio | Vía de acceso del espacio existente |
| Nombre de espacio (opcional) | Actualizar el nombre de espacio |
| Descripción de espacio (opcional) | Descripción del espacio |
| Códigos de espacio (opcional) | Etiquetas para identificar el espacio |
| Instancia de WML (opcional) | Especifique una nueva instancia de Machine Learning |
| Instancia de WML | Especifique una nueva instancia de aprendizaje automático. Nota: Aunque asigne un nombre distinto para una instancia en la interfaz de usuario, el nombre del sistema es Instancia de aprendizaje automático. Diferenciar entre distintas instancias utilizando el CRN de instancia |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Espacio | Vía de acceso del espacio actualizado |
Actualizar implementación en línea
Utilice estos parámetros para actualizar un despliegue en línea (servicio web).
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| virtual | Vía de acceso del despliegue existente |
| Nombre de despliegue (opcional) | Actualizar el nombre de despliegue |
| Descripción de despliegue (opcional) | Descripción del despliegue |
| Etiquetas de despliegue (opcional) | Etiquetas para identificar el despliegue |
| Activo (opcional) | Activo de aprendizaje automático (o versión) que se va a desplegar de nuevo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| virtual | Vía de acceso del despliegue actualizado |
Suprimir nodos
Configure los parámetros para las operaciones de supresión.
Suprimir
Puede suprimir:
- Experimento de AutoAI
- Despliegue por lotes
- Espacio de despliegue
- Despliegue en línea
Para cada artículo, elija el activo que desea suprimir.
Nodos de ejecución
Utilice estos nodos para entrenar un experimento, ejecutar un script o ejecutar un flujo de datos.
Ejecutar experimento AutoAI
Entrena y almacena interconexiones y modelos de experimento deAutoAI .
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Experimento de AutoAI | Busque el activo Interconexión ML u obtenga el experimento de un parámetro de interconexión o la salida de un nodo anterior. |
| Activo de datos de entrenamiento | Examine o busque los datos para entrenar el experimento. Tenga en cuenta que puede proporcionar datos en tiempo de ejecución utilizando un parámetro de interconexión |
| Activo de datos reservados (opcional) | Opcionalmente, elija un archivo separado para utilizar para los datos reservados para el rendimiento de testingmodel |
| Recuento de modelos (opcional) | Especifique cuántos modelos se deben guardar de las interconexiones con mejor rendimiento. El límite es de 3 modelos |
| Nombre de ejecución (opcional) | Nombre del experimento, una descripción opcional y etiquetas |
| Prefijo de nombre de modelo (opcional) | Prefijo utilizado para nombrar modelos entrenados. El valor predeterminado es < (nombre de experimento) > |
| Descripción de ejecución (opcional) | Descripción de la nueva ejecución de entrenamiento |
| Ejecutar etiquetas (opcional) | Etiquetas para la nueva ejecución de entrenamiento |
| Modalidad de creación (opcional) | Elija cómo manejar un caso en el que el flujo de interconexión intenta crear un activo y existe uno con el mismo nombre. Una de los siguientes opciones: ignore, fail, overwrite |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Modelos de | Lista de vías de acceso del modelo más alto N entrenado y persistente (ordenado por métrica de evaluación seleccionada) |
| Mejor modelo | vía de acceso del modelo ganador (basado en la métrica de evaluación seleccionada) |
| Métricas de modelo | una lista de métricas de modelos entrenados (cada elemento es un objeto anidado con métricas como: holdout_accuracy, holdout_average_precision, ...) |
| Métrica del modelo ganador | métrica de evaluación elegida del modelo ganador |
| Métrica optimizada | Métrica utilizada para ajustar el modelo |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del trabajo |
Ejecutar script Bash
Ejecute un script de Bash en línea para automatizar una función o proceso para la interconexión. Puede especificar el código de script Bash manualmente, o puede importar el script bash desde un recurso, un parámetro de interconexión o la salida de otro nodo.
También puede utilizar un script Bash para procesar archivos de salida de gran tamaño. Por ejemplo, puede generar una lista grande separada por comas sobre la que luego puede iterar utilizando un bucle.
En el ejemplo siguiente, el usuario ha especificado el código de script en línea manualmente. El script utiliza la herramienta cpdctl para buscar todos los cuadernos con una etiqueta de variable establecida y agrega los resultados en una lista JSON. A continuación, la lista se puede utilizar en otro nodo, por ejemplo, ejecutando los cuadernos devueltos de la búsqueda.
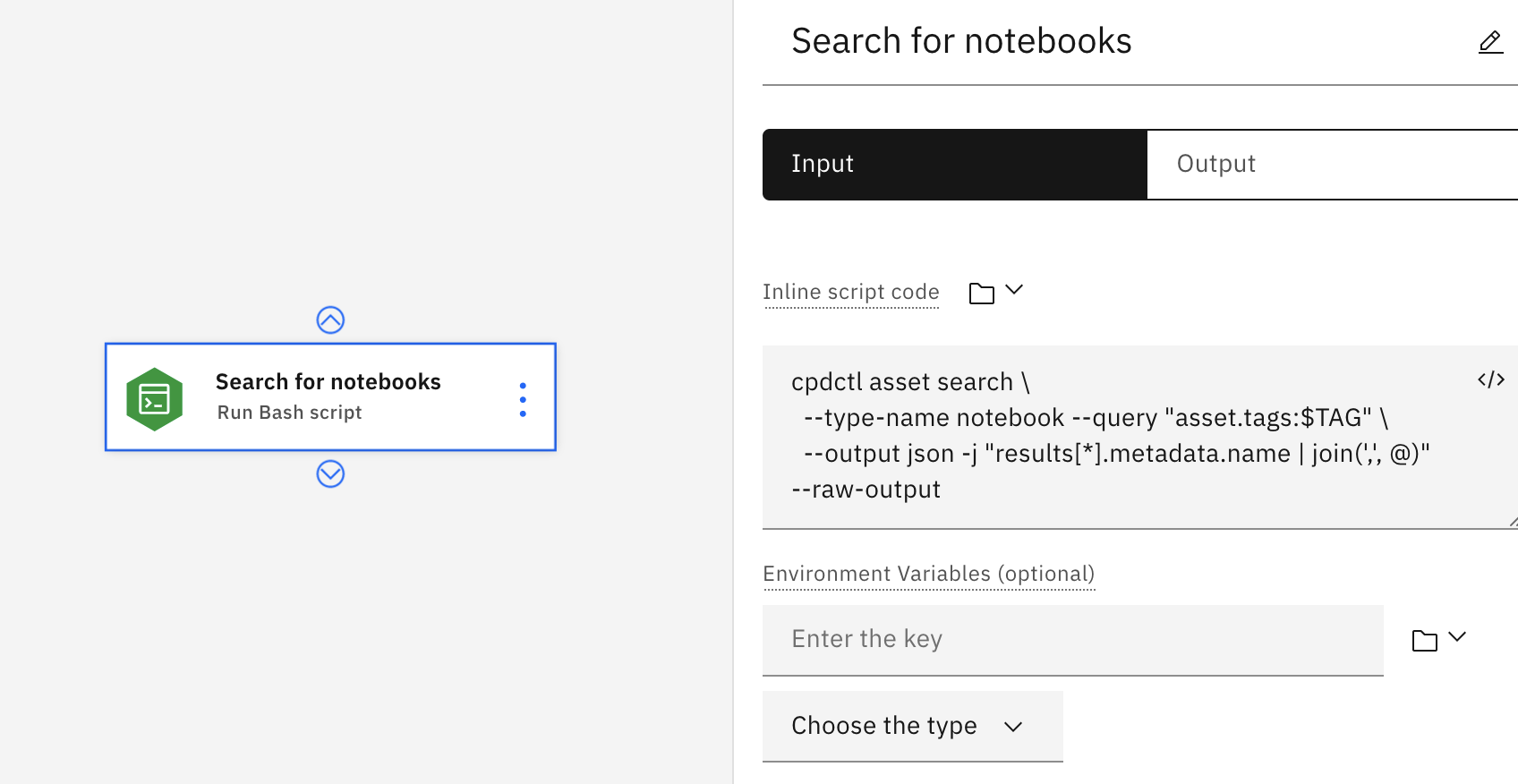
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Código de script en línea | Especifique un script de Bash en el editor de código en línea. Opcional: De forma alternativa, puede seleccionar un recurso, asignar un parámetro de interconexión o seleccionar desde otro nodo. |
| Variables de entorno (opcional) | Especifique un nombre de variable (la clave) y un tipo de datos y añádalos a la lista de variables que se deben utilizar en el script. |
| Tipo de tiempo de ejecución (opcional) | Seleccione utilizar tiempo de ejecución autónomo (valor predeterminado) o un tiempo de ejecución compartido. Utilice un tiempo de ejecución compartido para las tareas que requieren la ejecución en pods compartidos. |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Variables de salida | Configure un par de clave/valor para cada variable personalizada y, a continuación, pulse el botón Añadir para rellenar la lista de variables dinámicas para el nodo |
| Valor de retorno | Valor de retorno del nodo |
| Salida estándar | Salida estándar del script |
| Error estándar | Mensaje de error estándar del script |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Mensaje asociado con el estado |
Reglas para la salida del script Bash
La salida de un script Bash suele ser el resultado de una expresión calculada y puede ser grande. Cuando está revisando las propiedades de un script con una salida grande válida, puede obtener una vista previa o descargar la salida en un visor.
Estas reglas rigen qué tipo de salida grande es válida.
- La salida de un
list_expressiones una expresión calculada, por lo que es válida una salida grande. - La salida de serie se trata como un valor literal en lugar de una expresión calculada, por lo que debe seguir los límites de tamaño que rigen las expresiones en línea. Por ejemplo, se le avisa cuando un valor literal excede 1 KB y los valores de 2 KB y superiores dan como resultado un error.
- Puede incluir mensajes de error estándar en la salida estándar (
standard_output) y verlos, por ejemplo con la funciónGetCommandOutput.
Cómo hacer referencia a una variable en un script Bash
La forma en que se hace referencia a una variable en un script depende de si la variable se ha creado como una variable de entrada o como una variable de salida. Las variables de salida se crean como un archivo y requieren una vía de acceso de archivo en la referencia. En concreto:
- Las variables de entrada están disponibles utilizando el nombre asignado
- Los nombres de variables de salida requieren que
_PATHse añada al nombre de la variable para indicar que los valores deben escribirse en el archivo de salida apuntado por la variable{output_name}_PATH.
Ejecutar despliegue por lotes
Configure este nodo para ejecutar los trabajos de despliegue seleccionados.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| virtual | Examinar o buscar el trabajo de despliegue |
| Activos de datos de entrada | Especificar los datos utilizados para el trabajo por lotes |
| Activo de salida | Nombre del archivo de salida de los resultados del trabajo por lotes. Puede seleccionar Nombre de archivo y especificar un nombre de archivo personalizado, o Activo de datos y seleccionar un activo existente en un espacio. |
| Especificación de hardware (opcional) | Buscar una especificación de hardware para solicitar el trabajo |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso al archivo con resultados del trabajo de despliegue |
| Ejecución de trabajo | ID del trabajo |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del trabajo |
IBM DataStage es una herramienta de integración de datos para diseñar, desarrollar y ejecutar trabajos que mueven y transforman datos. Ejecute un trabajo de DataStage y utilice la salida en un nodo posterior.
Por ejemplo, el flujo siguiente muestra un nodo Ejecutar DataStage que recupera datos de un repositorio Git . Si el trabajo se completa correctamente, la interconexión ejecuta el siguiente nodo y crea un espacio de despliegue. Si el trabajo falla, se desencadena un correo electrónico de notificación y se termina el bucle.
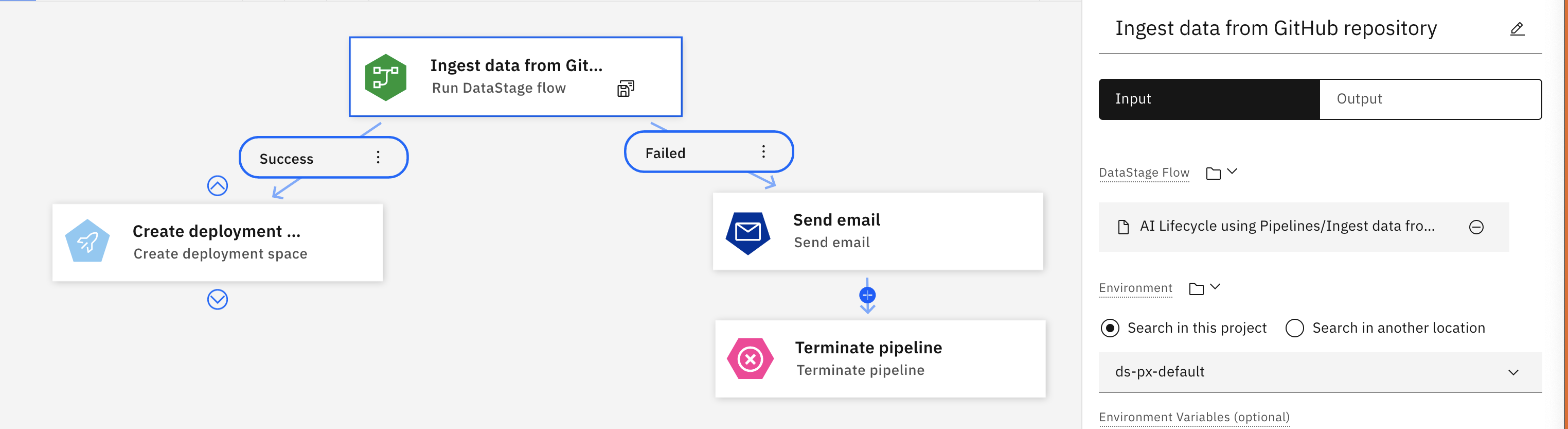
| Parámetro | Descripción |
|---|---|
| Trabajo de DataStage | Vía de acceso al trabajo de DataStage |
| Valores para parámetros locales (opcional) | Edite los parámetros de trabajo predeterminados. Esta opción sólo está disponible si tiene parámetros locales en el trabajo. |
| Valores de conjuntos de parámetros (opcional) | Edite los conjuntos de parámetros utilizados por este trabajo. Puede elegir utilizar los parámetros tal como se definen de forma predeterminada, o utilizar conjuntos de valores de otros parámetros de interconexiones. |
| Entorno | Busque y seleccione el entorno que se utiliza para ejecutar el trabajo DataStage . Atención: deje el campo de entornos tal cual para utilizar el tiempo de ejecución predeterminado de DataStage XS. Si opta por alterar temporalmente, especifique un entorno alternativo para ejecutar el trabajo. Asegúrese de que cualquier entorno que especifique sea compatible con la configuración de hardware para evitar un error de tiempo de ejecución.
|
| Variables de entorno (opcional) | Especifique un nombre de variable (la clave) y un tipo de datos y añádalo a la lista de variables a utilizar en el trabajo |
| Parámetros de trabajo (opcional) | Parámetro adicional para pasar al trabajo cuando se ejecuta. Especifique un par de clave/valor y añádalo a la lista. Nota: Si se utiliza el parámetro local
DSJobInvocationId , ese valor se pasa como nombre de trabajo en el panel de instrumentos de detalles de trabajo. |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso a los resultados del trabajo de DataStage |
| Ejecución de trabajo | Información sobre la ejecución del trabajo |
| Nombre de trabajo | Nombre del trabajo |
| Estado de ejecución | Información sobre el estado del trabajo: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del trabajo |
Ejecutar trabajo de Data Refinery
Este nodo ejecuta un trabajo de Data Refinery especificado.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Trabajo de Data Refinery | Vía de acceso al trabajo de Data Refinery . |
| Entorno | Vía de acceso del entorno utilizado para ejecutar el trabajo Atención: deje el campo de entornos tal como está para utilizar el tiempo de ejecución predeterminado. Si opta por alterar temporalmente, especifique un entorno alternativo para ejecutar el trabajo. Asegúrese de que cualquier entorno que especifique sea compatible con el idioma del componente y la configuración de hardware para evitar un error de tiempo de ejecución.
|
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso a los resultados del trabajo de Data Refinery |
| Ejecución de trabajo | Información sobre la ejecución del trabajo |
| Nombre de trabajo | Nombre del trabajo |
| Estado de ejecución | Información sobre el estado del flujo: pendiente, iniciando, ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado del flujo |
Ejecutar trabajo de cuaderno
Utilice estas opciones de configuración para especificar cómo ejecutar un Jupyter Notebook en un conducto.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Trabajo de cuaderno | Vía de acceso al trabajo del cuaderno. |
| Entorno | Vía de acceso del entorno utilizado para ejecutar el cuaderno. Atención: deje el campo de entornos tal como está para utilizar el entorno predeterminado. Si opta por alterar temporalmente, especifique un entorno alternativo para ejecutar el trabajo. Asegúrese de que cualquier entorno que especifique sea compatible con el idioma del cuaderno y la configuración de hardware para evitar un error de tiempo de ejecución.
|
| Variables de entorno (opcional) | Lista de variables de entorno utilizadas para ejecutar el trabajo del cuaderno |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Notas:
- Las variables de entorno que defina en un conducto no se pueden utilizar para trabajos de cuaderno que ejecute fuera de las interconexiones de orquestación.
- Puede ejecutar un cuaderno desde un paquete de código en un paquete normal.
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso a los resultados del trabajo de cuaderno |
| Ejecución de trabajo | Información sobre la ejecución del trabajo |
| Nombre de trabajo | Nombre del trabajo |
| Variables de salida | Configure un par de clave/valor para cada variable personalizada y, a continuación, pulse Añadir para rellenar la lista de variables dinámicas para el nodo |
| Estado de ejecución | Información sobre el estado de la ejecución: pendiente, iniciando, en ejecución, completado, cancelado o ha fallado con errores |
| Mensaje de estado | Información sobre el estado de la ejecución del cuaderno |
Ejecutar componente de interconexiones
Ejecute un componente de interconexión reutilizable que se crea utilizando un script Python . Para obtener más información, consulte Creación de un componente personalizado.
- Si un componente de interconexión está disponible, la configuración del nodo presenta una lista de componentes disponibles.
- El componente que elija especifica la entrada y salida para el nodo.
- Una vez que asigna un componente a un nodo, no puede suprimir o cambiar el componente. Debe suprimir el nodo y crear uno nuevo.
Ejecutar trabajo de canalizaciones
Añada un conducto para ejecutar un trabajo de conducto anidado como parte de un conducto contenedor. Esta es una forma de añadir procesos reutilizables a varias interconexiones. Puede utilizar la salida de una interconexión anidada que se ejecuta como entrada para un nodo en la interconexión contenedora.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Trabajo de canalizaciones | Seleccione o especifique una vía de acceso a un trabajo de interconexiones existente. |
| Entorno (opcional) | Seleccione el entorno en el que ejecutar el trabajo de interconexiones y asigne recursos de entorno. Atención: deje el campo de entornos tal como está para utilizar el tiempo de ejecución predeterminado. Si opta por alterar temporalmente, especifique un entorno alternativo para ejecutar el trabajo. Asegúrese de que cualquier entorno que especifique sea compatible con el idioma del componente y la configuración de hardware para evitar un error de tiempo de ejecución.
|
| Nombre de ejecución de trabajo (opcional) | Se utiliza un nombre de ejecución de trabajo predeterminado a menos que lo altere temporalmente especificando un nombre de ejecución de trabajo personalizado. Puede ver el nombre de ejecución del trabajo en el panel de control Detalles del trabajo . |
| Valores para parámetros locales (opcional) | Edite los parámetros de trabajo predeterminados. Esta opción sólo está disponible si tiene parámetros locales en el trabajo. |
| Valores de conjuntos de parámetros (opcional) | Edite los conjuntos de parámetros utilizados por este trabajo. Puede elegir utilizar los parámetros tal como se definen de forma predeterminada, o utilizar conjuntos de valores de otros parámetros de interconexiones. |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso a los resultados del trabajo de interconexión |
| Ejecución de trabajo | Información sobre la ejecución del trabajo |
| Nombre de trabajo | Nombre del trabajo |
| Estado de ejecución | Devuelve un valor de: Completado, Completado con avisos, Completado con errores, Anómalo o Cancelado |
| Mensaje de estado | Mensaje asociado con el estado |
Notas para ejecutar trabajos de interconexión anidados
Si crea un conducto con conductos anidados y ejecuta un trabajo de conducto desde el nivel superior, los conductos se denominan y se guardan como activos de proyecto que utilizan este convenio:
- El trabajo de interconexión de nivel superior se denomina "Trabajo de prueba- guid de interconexión".
- Todos los trabajos posteriores se denominan "pipeline_ pipeline guid".
Ejecute el trabajo SPSS Modeler
Utilice estas opciones de configuración para especificar cómo ejecutar un SPSS Modeler en un conducto.
Parámetros de entrada
| Parámetro | Descripción |
|---|---|
| Trabajo de SPSS Modeler | Seleccione o especifique una vía de acceso a un trabajo existente de SPSS Modeler . |
| Entorno (opcional) | Seleccione el entorno en el que ejecutar el trabajo SPSS Modeler y asigne recursos de entorno. Atención: deje el campo de entornos tal como está para utilizar el tiempo de ejecución predeterminado de SPSS Modeler . Si opta por alterar temporalmente, especifique un entorno alternativo para ejecutar el trabajo. Asegúrese de que cualquier entorno que especifique sea compatible con la configuración de hardware para evitar un error de tiempo de ejecución.
|
| Valores para parámetros locales | Edite los parámetros de trabajo predeterminados. Esta opción sólo está disponible si tiene parámetros locales en el trabajo. |
| Política de error (opcional) | Opcionalmente, altere temporalmente la política de error predeterminada para el nodo |
Parámetros de salida
| Parámetro | Descripción |
|---|---|
| Trabajo | Vía de acceso a los resultados del trabajo de interconexión |
| Ejecución de trabajo | Información sobre la ejecución del trabajo |
| Nombre de trabajo | Nombre del trabajo |
| Estado de ejecución | Devuelve un valor de: Completado, Completado con avisos, Completado con errores, Anómalo o Cancelado |
| Mensaje de estado | Mensaje asociado con el estado |
Más información
Tema padre: Creación de un conducto