Translation not up to date
Skonfiguruj węzły potoku, aby określić wejścia i utworzyć wyjścia jako część potoku.
Określanie zasięgu obszaru roboczego
Domyślnie zasięgiem potoku jest projekt zawierający potok. W celu zlokalizowania zasobu używanego w potoku można jawnie określić zasięg inny niż domyślny. Zasięg to projekt, katalog lub obszar zawierający zasób aplikacyjny. W interfejsie użytkownika można przeglądać zasięg.
Zmiana trybu wprowadzania
Podczas konfigurowania węzła można określić dowolne zasoby, w tym dane i notatniki, na różne sposoby, takie jak bezpośrednie wprowadzenie nazwy lub identyfikatora, przeglądanie w poszukiwaniu zasobu lub użycie wyników z wcześniejszego węzła w potoku w celu zapełnienia pola. Aby zobaczyć, jakie opcje są dostępne dla pola, kliknij ikonę wprowadzania dla pola. W zależności od kontekstu opcje mogą obejmować:
- Wybierz zasób: użyj przeglądarki zasobów, aby znaleźć zasób, taki jak plik danych.
- Przypisz parametr potoku: przypisz wartość przy użyciu zmiennej skonfigurowanej z parametrem potoku. Więcej informacji na ten temat zawiera sekcja Konfigurowanie obiektów globalnych.
- Wybierz z innego węzła: użyj wyniku z węzła wcześniej w potoku jako wartości dla tej zmiennej.
- Wprowadź wyrażenie: wprowadź kod, aby przypisać wartości lub zidentyfikować zasoby. Szczegółowe informacje na ten temat zawiera sekcja Kodowanie elementów.
Węzły i parametry potoku
Skonfiguruj następujące typy węzłów potoku:
Kopiuj węzły
Węzły Kopiuj służą do dodawania zasobów do potoku lub do eksportowania zasobów potoku.
Skopiuj wybrane zasoby aplikacyjne z projektu lub obszaru do niepustego obszaru. Zasoby te można skopiować do obszaru:
- Zasób danych
- operacyjny
- Potok ML
- Funkcja
- Połączenie
- Specyfikacja oprogramowania
- Przepływ Data Refinery
- Środowisko
- Skrypt
Parametry wejściowe
Parametr Opis Zasoby źródłowe Przeglądaj lub wyszukaj zasób źródłowy, który ma zostać dodany do listy. Można również określić zasób z parametrem potoku, z wynikiem innego węzła lub wprowadzając identyfikator zasobu Docelowa Przeglądaj lub wyszukaj obszar docelowy Tryb kopiowania Wybierz sposób obsługi przypadku, w którym przepływ próbuje skopiować zasób aplikacyjny i istnieje jeden o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteParametry wyjściowe
Parametr Opis Zasoby wyjściowe Lista skopiowanych zasobów
Eksportuj wybrane zasoby aplikacyjne z zasięgu, na przykład projekt lub obszar wdrażania. Operacja domyślnie eksportuje wszystkie zasoby aplikacyjne. Wybór zasobów można ograniczyć, tworząc listę zasobów do wyeksportowania.
Parametry wejściowe
Parametr Opis Zasoby Wybierz opcję Zasięg , aby wyeksportować wszystkie eksportowalne elementy, lub opcję Lista , aby utworzyć listę konkretnych elementów do wyeksportowania. Projekt lub obszar źródłowy Nazwa projektu lub obszaru zawierającego zasoby aplikacyjne do wyeksportowania Wyeksp. plik Położenie pliku do przechowywania pliku eksportu Tryb tworzenia (opcjonalnie) Wybierz sposób obsługi przypadku, w którym przepływ podejmuje próbę utworzenia zasobu aplikacyjnego o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteParametry wyjściowe
Parametr Opis Wyeksp. plik Ścieżka do wyeksportowanego pliku Uwagi:
- W przypadku eksportowania projektu, który zawiera notatnik, do pliku eksportu dołączona jest najnowsza wersja notatnika. Jeśli w potoku skonfigurowanym z węzłem Uruchom zadanie notatnika skonfigurowano użycie innej wersji notatnika niż najnowsza, wyeksportowany potok zostanie automatycznie ponownie skonfigurowany w celu użycia najnowszej wersji podczas importowania. Może to spowodować nieoczekiwane rezultaty lub wymagać ponownej konfiguracji po zaimportowaniu.
- Jeśli zasoby aplikacyjne są samodzielne w wyeksportowanym projekcie, są zachowywane podczas importowania nowego projektu. W przeciwnym razie po zaimportowaniu wyeksportowanych zasobów może być wymagana pewna konfiguracja.
Importowanie zasobów aplikacyjnych z pliku ZIP zawierającego wyeksportowane zasoby aplikacyjne.
Parametry wejściowe
Parametr Opis Ścieżka do celu importowania Przeglądaj lub wyszukaj zasoby aplikacyjne do zaimportowania Plik archiwum do zaimportowania Podaj ścieżkę do pliku ZIP lub archiwum Uwagi: Po zaimportowaniu pliku ścieżki i odwołania do zaimportowanych zasobów aplikacyjnych są aktualizowane zgodnie z następującymi regułami:
- Odwołania do zasobów aplikacyjnych z wyeksportowanego projektu lub obszaru są aktualizowane w nowym projekcie lub obszarze po zaimportowaniu.
- Jeśli zasoby aplikacyjne z wyeksportowanego projektu odwołują się do zewnętrznych zasobów aplikacyjnych (zawartych w innym projekcie), odwołanie do zewnętrznego zasobu aplikacyjnego zostanie utrwalone po zaimportowaniu.
- Jeśli zasób zewnętrzny już nie istnieje, parametr jest zastępowany pustą wartością i należy zmienić konfigurację pola, aby wskazać poprawny zasób.
Utwórz węzły
Skonfiguruj węzły do tworzenia zasobów w potoku.
Ten węzeł służy do trenowania eksperymentu klasyfikacjiAutoAI lub regresji i generowania potoków kandydackich modeli.
Parametry wejściowe
Parametr Opis Nazwa eksperymentu AutoAI Nazwa nowego eksperymentu Zakres Projekt lub obszar, w którym ma zostać utworzony eksperyment Typ predykcji Typ modelu dla danych: binarny, klasyfikacyjny lub regresyjny Kolumna predykcji (etykieta) Nazwa kolumny predykcji Klasa dodatnia (opcjonalnie) Określ klasę dodatnią dla eksperymentu klasyfikacji binarnej Współczynnik podziału danych uczących (opcjonalnie) Procent danych, które mają zostać wstrzymane przed treningiem i użyte do testowania potoków (liczba zmiennopozycyjna: 0.0 - 1.0) Algorytmy do uwzględnienia (opcjonalne) Ogranicz listę estymatorów, które mają być używane (lista zależy od typu uczenia) Używane algorytmy Określ listę estymatorów, które mają być używane (lista zależy od typu uczenia) Optymalizuj metrykę (opcjonalnie) Metryka używana do rangowania modelu Specyfikacja sprzętu (opcjonalna) Określ specyfikację sprzętu dla eksperymentu Opis eksperymentu AutoAI Opis doświadczenia Znaczniki eksperymentu AutoAI (opcjonalne) Znaczniki identyfikujące eksperyment Tryb tworzenia (opcjonalnie) Wybierz sposób obsługi przypadku, w którym potok próbuje utworzyć eksperyment i istnieje jeden o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteParametry wyjściowe
Parametr Opis Eksperyment AutoAI Ścieżka do zapisanego modelu
Węzeł ten służy do trenowania eksperymentu z szeregami czasowymiAutoAI i generowania potoków kandydackich.
Parametry wejściowe
Parametr Opis Nazwa eksperymentu AutoAI Nazwa nowego eksperymentu Zakres Projekt lub obszar, w którym ma zostać utworzony potok Kolumny predykcji (etykieta) Nazwa co najmniej jednej kolumny predykcji Kolumna daty/godziny (opcjonalnie) Nazwa kolumny daty/godziny Wykorzystanie przyszłych wartości funkcji pomocniczych Wybierz opcję "Prawda", aby włączyć uwzględnianie funkcji pomocniczych (zewnętrznych) w celu poprawy predykcji. Na przykład można uwzględnić funkcję temperatury do przewidywania sprzedaży lodów. Funkcje pomocnicze (opcjonalnie) Wybierz funkcje obsługi i dodaj do listy Metoda podstawiania (opcjonalnie) Wybierz technikę podstawiania braków danych w zbiorze danych Próg podstawiania (opcjonalnie) Określ górny próg dla procentu braków danych, który ma zostać podany przy użyciu określonej metody podstawiania. Jeśli próg zostanie przekroczony, eksperyment nie powiedzie się. Na przykład, jeśli określono, że 10% wartości może być podstawianych, a w zestawie danych brakuje 15% wartości, eksperyment nie powiedzie się. Typ wypełnienia Określ, w jaki sposób określona metoda podstawiania powinna wypełniać wartości null. Określ średnią wszystkich wartości i medianę wszystkich wartości lub określ wartość wypełnienia. Wartość wypełnienia (opcjonalnie) Jeśli wybrano opcję określenia wartości w celu zastąpienia wartości null, wprowadź wartość w tym polu. Końcowy zestaw danych uczących Wybierz, czy trenować końcowe potoki tylko z danymi szkoleniowymi, czy z danymi szkoleniowymi i danymi wstrzymanymi. W przypadku wybrania danych uczących wygenerowany notatnik będzie zawierał komórkę służącą do pobierania danych wstrzymanych Wielkość wstrzymania (opcjonalnie) Jeśli dane uczące są dzielone na dane uczące i wstrzymane, należy określić procent danych uczących do zarezerwowania jako dane wstrzymane na potrzeby sprawdzania poprawności potoków. Dane wstrzymane nie powinny przekraczać jednej trzeciej danych. Liczba operacji wstecz (opcjonalnie) Dostosuj wyniki wstecz, aby sprawdzić poprawność eksperymentu szeregu czasowego Długość luki (opcjonalnie) Skoryguj liczbę punktów czasowych między zestawem danych uczących a zestawem danych sprawdzania poprawności dla każdego procesu wstecz. Jeśli wartość parametru jest niezerowa, wartości szeregów czasowych w luce nie będą używane do trenowania eksperymentu ani do oceny bieżącego wstecz. Okno spojrzenia (opcjonalnie) Parametr, który wskazuje, ile poprzednich wartości szeregów czasowych jest używanych do przewidywania bieżącego punktu czasowego. Okno prognozy (opcjonalne) Zakres, który ma być przewidywana na podstawie danych w oknie spojrzenia wstecz. Algorytmy do uwzględnienia (opcjonalne) Ogranicz listę estymatorów, które mają być używane (lista zależy od typu uczenia) Rurociągi do zakończenia Opcjonalnie dostosuj liczbę potoków do utworzenia. Więcej rurociągów zwiększa czas i zasoby szkoleniowe. Specyfikacja sprzętu (opcjonalna) Określ specyfikację sprzętu dla eksperymentu Opis eksperymentu z szeregiem czasowym AutoAI (opcjonalnie) Opis doświadczenia Znaczniki eksperymentu AutoAI (opcjonalne) Znaczniki identyfikujące eksperyment Tryb tworzenia (opcjonalnie) Wybierz sposób obsługi przypadku, w którym potok próbuje utworzyć eksperyment i istnieje jeden o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteParametry wyjściowe
Parametr Opis Eksperyment dotyczący szeregów czasowych AutoAI Ścieżka do zapisanego modelu
Ten węzeł służy do tworzenia wdrożenia wsadowego dla modelu uczenia maszynowego.
Parametry wejściowe
Parametr Opis Zasób ML Nazwa lub identyfikator zasobu uczenia maszynowego do wdrożenia Nowa nazwa wdrożenia (opcjonalnie) Nazwa nowej pracy z opcjonalnym opisem i znacznikami Tryb tworzenia (opcjonalnie) Sposób obsługi przypadku, w którym potok próbuje utworzyć zadanie i istnieje jedna z tych samych nazw. Jedna z następujących wartości: ignore,fail,overwriteNowy opis wdrożenia (opcjonalnie) Opis wdrożenia Nowe znaczniki wdrażania (opcjonalnie) Znaczniki identyfikujące wdrożenie Specyfikacja sprzętu (opcjonalna) Podaj specyfikację sprzętu dla zadania Parametry wyjściowe
Parametr Opis Nowe wdrożenie Ścieżka nowo utworzonego wdrożenia
Ten węzeł służy do tworzenia zasobu danych.
Parametry wejściowe
Parametr Opis Plik Ścieżka do pliku w pamięci masowej plików Zasięg docelowy Ścieżka do obszaru docelowego lub projektu Nazwa (opcjonalnie) Nazwa źródła danych z opcjonalnym opisem, krajem pochodzenia i znacznikami Opis (opcjonalny) Opis zasobu Kraj pochodzenia (fakultatywnie) Kraj pochodzenia dla przepisów dotyczących danych Znaczniki (opcjonalne) Znaczniki identyfikujące zasoby Tryb tworzenia Sposób obsługi przypadku, w którym potok próbuje utworzyć zadanie i istnieje jedna z tych samych nazw. Jedna z następujących wartości: ignore,fail,overwriteParametry wyjściowe
Parametr Opis Zasób danych Nowo utworzony zasób danych
Ten węzeł służy do tworzenia i konfigurowania obszaru, którego można użyć do organizowania i tworzenia wdrożeń.
Parametry wejściowe
Parametr Opis Nowa nazwa obszaru Nazwa nowego obszaru z opcjonalnym opisem i znacznikami Nowe znaczniki obszaru (opcjonalnie) Znaczniki identyfikujące obszar Nowa instancja COS obszaru-CRN CRN instancji usługi COS Nowa instancja WML obszaru CRN (opcjonalnie) CRN z instancji usługi Watson Machine Learning Tryb tworzenia (opcjonalnie) Sposób obsługi przypadku, w którym potok próbuje utworzyć obszar i istnieje jeden o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteOpis powierzchni (opcjonalnie) Opis powierzchni Parametry wyjściowe
Parametr Opis Miejsce Ścieżka nowo utworzonego obszaru
Ten węzeł służy do tworzenia wdrożenia w trybie z połączeniem, w którym można wprowadzać dane testowe bezpośrednio do punktu końcowego interfejsu REST API usługi WWW.
Parametry wejściowe
Parametr Opis Zasób ML Nazwa lub identyfikator zasobu uczenia maszynowego do wdrożenia Nowa nazwa wdrożenia (opcjonalnie) Nazwa nowej pracy z opcjonalnym opisem i znacznikami Tryb tworzenia (opcjonalnie) Sposób obsługi przypadku, w którym potok próbuje utworzyć zadanie i istnieje jedna z tych samych nazw. Jedna z następujących wartości: ignore,fail,overwriteNowy opis wdrożenia (opcjonalnie) Opis wdrożenia Nowe znaczniki wdrażania (opcjonalnie) Znaczniki identyfikujące wdrożenie Specyfikacja sprzętu (opcjonalna) Podaj specyfikację sprzętu dla zadania Parametry wyjściowe
Parametr Opis Nowe wdrożenie Ścieżka nowo utworzonego wdrożenia
Oczekiwanie
Węzły w tej sekcji umożliwiają wstrzymanie potoku do czasu, aż zasób będzie dostępny w lokalizacji określonej w ścieżce.
Użyj tego węzła, aby poczekać, aż wszystkie wyniki z poprzednich węzłów w potoku będą dostępne, aby potok mógł być kontynuowany.
Ten węzeł nie przyjmuje żadnych danych wejściowych i nie generuje żadnych danych wyjściowych. Gdy wszystkie wyniki są dostępne, potok jest kontynuowany automatycznie.
Użyj tego węzła, aby poczekać, aż wszystkie wyniki z poprzednich węzłów w potoku będą dostępne, aby potok mógł być kontynuowany. Uruchom kolejne węzły natychmiast po spełnieniu dowolnego z warunków w kierunku przeciwnym.
Ten węzeł nie przyjmuje żadnych danych wejściowych i nie generuje żadnych danych wyjściowych. Jeśli dostępne są jakiekolwiek wyniki, potok jest kontynuowany automatycznie.
Poczekaj, aż zasób zostanie utworzony lub zaktualizowany w lokalizacji określonej w ścieżce z zadania lub procesu wcześniej w potoku. Określ limit czasu oczekiwania na spełnienie warunku. Jeśli 00:00:00 jest określoną długością limitu czasu, przepływ oczekuje w nieskończoność.
Parametry wejściowe
Parametr Opis Położenie pliku Określ lokalizację w przeglądarce zasobów, w której znajduje się zasób. Należy użyć formatu data_asset/filename, w którym ścieżka jest względna w stosunku do katalogu głównego. Plik musi istnieć i znajdować się w podanym położeniu, w przeciwnym razie działanie węzła nie powiedzie się i zostanie zgłoszony błąd.Tryb oczekiwania Domyślnym trybem jest wyświetlanie pliku. Można zmienić na oczekiwanie na zniknięcie pliku. Długość limitu czasu (opcjonalnie) Określ czas oczekiwania przed kontynuowaniem potoku. Użyj formatu hh:mm:ssStrategia błędów (opcjonalna) Patrz Obsługa błędów Parametry wyjściowe
Parametr Opis Wartość zwracana Wartość zwracana z węzła Status wykonania Zwraca wartość: Zakończone, Zakończone z ostrzeżeniami, Zakończone z błędami, Niepowodzenie lub Anulowane Komunikat o statusie Komunikat powiązany ze statusem
Węzły sterujące
Steruj potokiem, dodając obsługę błędów i logikę.
Pętle są węzłem w potoku, który działa jak pętla kodowana.
Istnieją dwa typy pętli: równoległa i sekwencyjna.
Pętli można używać, gdy liczba iteracji dla operacji jest dynamiczna. Jeśli na przykład nie jest znana liczba notatników do przetworzenia lub użytkownik chce wybrać liczbę notatników w czasie wykonywania, można użyć pętli, aby iterować przez listę notatników.
Za pomocą pętli można również iterować przez dane wyjściowe węzła lub przez elementy w tablicy danych.
Pętle równoległe
Dodaj równoległą pętlę do potoku. Pętla równoległa uruchamia węzły iteracyjne niezależnie i ewentualnie równocześnie.
Na przykład, aby wytrenować model uczenia maszynowego z zestawem hiperparametrów w celu znalezienia najlepszego wykonawcy, można użyć pętli, aby wykonać iterację listy hiperparametrów, która ma być używana do równoległego trenowania wariantów notatnika. Wyniki można później porównać w przepływie, aby znaleźć najlepszy notatnik. Ograniczenia dotyczące liczby pętli, które można uruchomić jednocześnie, można znaleźć w sekcji Ograniczenia.
W poniższym przykładzie węzeł skryptu Uruchom skrypt Bash wyszukuje i pobiera notatniki, które spełniają określone kryteria. Węzeł Uruchom zadanie DataStage pobiera dane z repozytorium Git . Gdy dane wejściowe z każdego węzła są dostępne, rozpoczyna się proces pętli, w którym uruchamiane są wszystkie notatniki pobrane przez funkcję wyszukiwania i przetwarzane są dane pobrane z repozytorium Git .
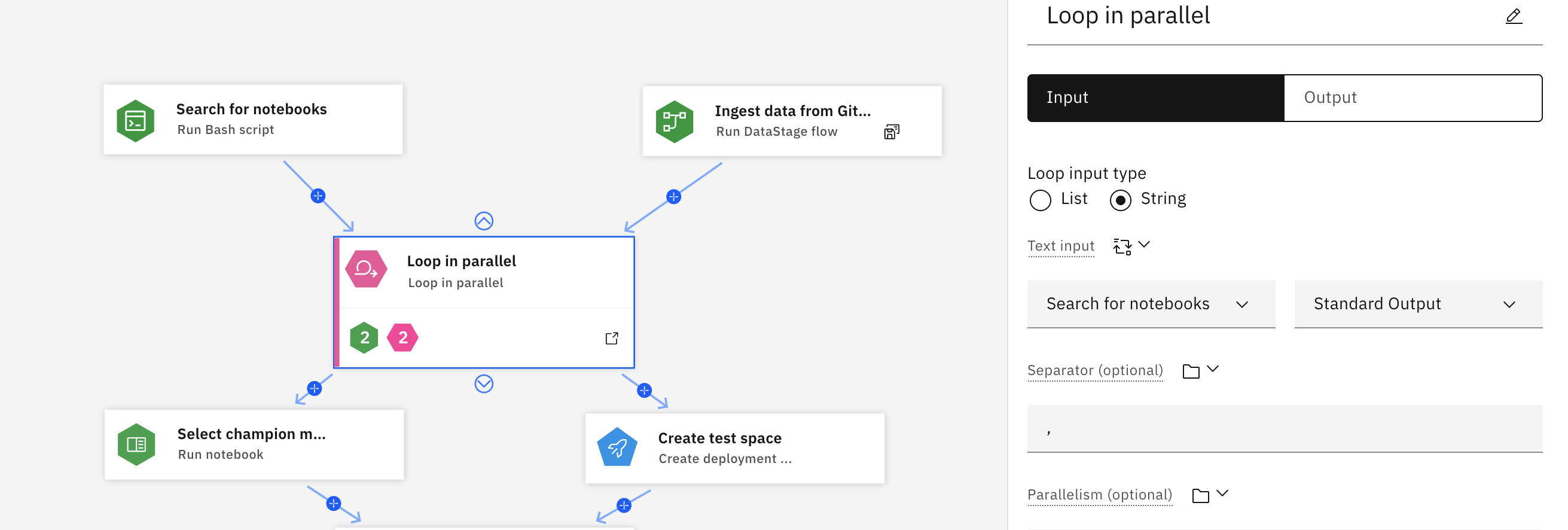
Kliknij opcję Rozwiń, aby dodać węzły lub ikonę wychodzącą w węźle, aby wyświetlić pełny proces pętli. Po uruchomieniu notatników wszystkie błędy w notatniku są przechwytywane w warunku o nazwie Niska jakość. Warunek wyzwala skrypt Bash w celu zwiększenia wartości zmiennej użytkownika o nazwie Zwiększ liczbę błędów. Jeśli wartość zmiennej Zwiększ liczbę błędów osiągnie określoną wartość progową, pętla zostanie zakończona.
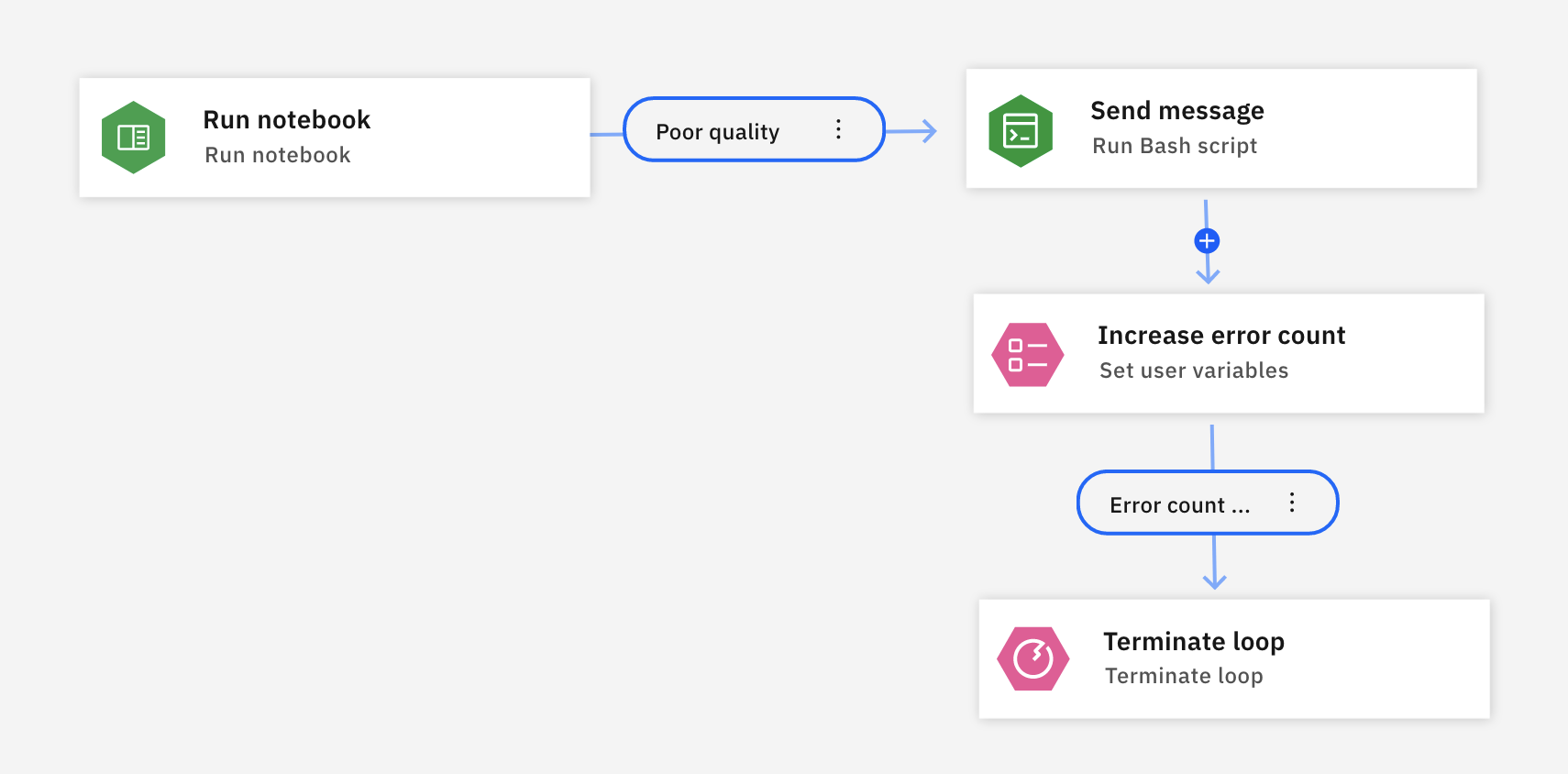
Ponieważ przepływ jest wykonywany równolegle dla każdego notatnika, zwraca wyniki szybciej niż pętla sekwencyjna.
Parametry wejściowe podczas iterowania typów list
Parametr Opis Dane wejściowe listy Parametr Wejście listy zawiera dwa pola: typ danych listy i treść listy, nad którą iteruje pętla, lub standardowe łącze do wejścia potoku lub wyjścia potoku. Zrównoleglenie Maksymalna liczba jednocześnie uruchamianych zadań. Wartość musi być większa od zera Parametry wejściowe podczas iteracji typów łańcuchowych
Parametr Opis Tekst wejściowy Dane tekstowe, z których odczytywane są pętle Separator: Znak używany do dzielenia tekstu Paralelizm (opcjonalnie) Maksymalna liczba jednocześnie uruchamianych zadań. Wartość musi być większa od zera Jeśli typem elementu tablic wejściowych jest JSON lub dowolny typ, który jest reprezentowany jako taki, to pole może dekomponować go jako słownik. Klucze to oryginalne klucze elementów, a wartości są aliasami nazw wyjściowych.
Pętle w sekwencji
Dodaj do potoku pętlę sekwencyjną. Pętle mogą iterować po zakresie liczbowym, liście lub tekście z separatorem.
Przypadek użycia dla pętli sekwencyjnych jest taki, że przed określeniem, czy operacja zakończyła się niepowodzeniem, należy spróbować wykonać operację 3 razy.
Parametry wejściowe
Parametr Opis Dane wejściowe listy Parametr Wejście listy zawiera dwa pola: typ danych listy i treść listy, nad którą iteruje pętla, lub standardowe łącze do wejścia potoku lub wyjścia potoku. Tekst wejściowy Dane tekstowe, z których odczytywane są pętle. Określ znak, aby podzielić tekst. Zakres Określ krok początkowy, końcowy i opcjonalny dla zakresu, który ma być iteracyjny. Domyślnym krokiem jest 1. Po skonfigurowaniu zakresu iteracyjnego pętli należy zdefiniować przepływ podpotoku wewnątrz pętli, który ma być uruchamiany do momentu zakończenia pętli. Na przykład może wywoływać notatnik, skrypt lub inny przepływ dla iteracji.
Przerwij pętlę
W równoległym lub sekwencyjnym przepływie procesu pętli można dodać węzeł Przerwij potok , aby zakończyć proces pętli w dowolnym momencie. Należy dostosować warunki zakończenia.
Uwaga: Jeśli używany jest węzeł pętli Terminate, pętla anuluje wszystkie trwające zadania i kończy działanie bez kończenia iteracji.
Skonfiguruj zmienną użytkownika z parą klucz/wartość, a następnie dodaj listę zmiennych dynamicznych dla tego węzła.
Szczegółowe informacje na temat tworzenia zmiennej użytkownika zawiera sekcja Konfigurowanie obiektów globalnych.
Parametry wejściowe
x
Tabela 1. Parametry wejściowe zmiennej użytkownika Parametr Opis Nazwa Wprowadź nazwę lub klucz dla zmiennej Typ danych wejściowych Jako typ wejściowy wybierz parametr wyrażenia lub potoku. - W przypadku wyrażeń należy użyć wbudowanego programu budowania wyrażeń, aby utworzyć zmienną, która jest wynikiem wyrażenia niestandardowego.
- W przypadku parametrów potoku przypisz parametr potoku i użyj wartości parametru jako danych wejściowych dla zmiennej użytkownika.
Można inicjować i kontrolować zakończenie potoku za pomocą węzła Terminate pipeline z kategorii Control. Po uruchomieniu przepływu błędów można opcjonalnie określić sposób obsługi zadań notatnika lub szkolenia, które zostały zainicjowane przez węzły w potoku. Należy określić, czy czekać na zakończenie zadań, anulować zadania, a następnie zatrzymać potok, czy po prostu zatrzymać wszystko bez anulowania. Określ opcje dla węzła potoku końcowego.
Parametry wejściowe
Parametr Opis Tryb terminatora (opcjonalnie) Wybierz zachowanie dla przepływu błędów Trybem terminatora może być:
- Zakończ działanie potoku i wszystkie uruchomione zadania zatrzymuje wszystkie zadania i zatrzymuje potok.
- Anuluj wszystkie uruchomione zadania, a następnie zakończ potok anuluje wszystkie uruchomione zadania przed zatrzymaniem potoku.
- Zakończ działanie potoku po zakończeniu uruchomionych zadań czeka na zakończenie uruchomionych zadań, a następnie zatrzymuje potok.
- Zakończ potok, który jest uruchamiany bez zatrzymywania zadań zatrzymuje potok, ale umożliwia kontynuowanie uruchomionych zadań.
Aktualizuj węzły
Węzły aktualizacji służą do zastępowania lub aktualizowania zasobów w celu zwiększenia wydajności. Na przykład, aby standaryzować znaczniki, można je zaktualizować, zastępując je nowym znacznikiem.
Aktualizacja szczegółów szkolenia dla eksperymentu AutoAI.
Parametry wejściowe
Parametr Opis Eksperyment AutoAI Ścieżka do projektu lub obszaru, w którym znajduje się eksperyment Nazwa eksperymentu AutoAI (opcjonalnie) Nazwa eksperymentu, który ma zostać zaktualizowany, z opcjonalnym opisem i znacznikami Opis eksperymentu AutoAI (opcjonalnie) Opis doświadczenia Znaczniki eksperymentu AutoAI (opcjonalne) Znaczniki identyfikujące eksperyment Parametry wyjściowe
Parametr Opis Eksperyment AutoAI Ścieżka zaktualizowanego eksperymentu
Te parametry służą do aktualizowania wdrożenia wsadowego.
Parametry wejściowe
Parametr Opis Wdrożenie Ścieżka do wdrożenia, które ma zostać zaktualizowane Nowa nazwa wdrożenia (opcjonalnie) Nazwa lub identyfikator wdrożenia, które ma zostać zaktualizowane Nowy opis wdrożenia (opcjonalnie) Opis wdrożenia Nowe znaczniki dla wdrożenia (opcjonalnie) Znaczniki identyfikujące wdrożenie Zasób ML Nazwa lub identyfikator zasobu uczenia maszynowego do wdrożenia Specyfikacja sprzętu Zaktualizuj specyfikację sprzętu dla zadania Parametry wyjściowe
Parametr Opis Wdrożenie Ścieżka zaktualizowanego wdrożenia
Zaktualizuj szczegóły obszaru.
Parametry wejściowe
Parametr Opis Miejsce Ścieżka istniejącego obszaru Nazwa obszaru (opcjonalnie) Aktualizuj nazwę obszaru Opis powierzchni (opcjonalnie) Opis powierzchni Znaczniki spacji (opcjonalnie) Znaczniki identyfikujące obszar Instancja WML (opcjonalnie) Określ nową instancję Machine Learning Instancja WML Podaj nową instancję Machine Learning . Uwaga: Nawet jeśli w interfejsie użytkownika zostanie przypisana inna nazwa instancji, nazwą systemu będzie instancjaMachine Learning. Rozróżnianie różnych instancji przy użyciu nazwy CRN instancji Parametry wyjściowe
Parametr Opis Miejsce Ścieżka zaktualizowanego obszaru
Te parametry służą do aktualizowania wdrożenia w trybie z połączeniem (usługa Web Service).
Parametry wejściowe
Parametr Opis Wdrożenie Ścieżka istniejącego wdrożenia Nazwa wdrożenia (opcjonalnie) Aktualizuj nazwę wdrożenia Opis wdrożenia (opcjonalnie) Opis wdrożenia Znaczniki wdrażania (opcjonalnie) Znaczniki identyfikujące wdrożenie Zasób (opcjonalnie) Zasób (lub wersja) uczenia maszynowego, który ma zostać ponownie wdrożony Parametry wyjściowe
Parametr Opis Wdrożenie Ścieżka zaktualizowanego wdrożenia
Usuń węzły
Skonfiguruj parametry dla operacji usuwania.
Można usunąć:
- Eksperyment AutoAI
- Wdrożenie wsadowe
- Obszar wdrażania
- Wdrażanie w trybie z połączeniem
Dla każdej pozycji wybierz zasób do usunięcia.
Węzły uruchamiania
Węzły te służą do trenowania eksperymentu, wykonywania skryptu lub uruchamiania przepływu danych.
Trenuje i przechowuje potoki i modele AutoAI eksperyment .
Parametry wejściowe
Parametr Opis Eksperyment AutoAI Przejdź do zasobu potoku ML lub pobierz eksperyment z parametru potoku lub wyniku z poprzedniego węzła. Zasób danych treningowych Przeglądaj lub wyszukaj dane, aby wytrenować eksperyment. Należy zauważyć, że dane można podać w czasie wykonywania za pomocą parametru potoku. Zasób danych wstrzymane (opcjonalnie) Opcjonalnie wybierz oddzielny plik do użycia dla danych wstrzymanych na potrzeby testowania wydajności modelu Liczba modeli (opcjonalnie) Określ liczbę modeli, które mają zostać zapisane z najlepiej działających potoków. Limit wynosi 3 modele Nazwa uruchomienia (opcjonalnie) Nazwa eksperymentu oraz opcjonalny opis i znaczniki Przedrostek nazwy modelu (opcjonalnie) Przedrostek używany do nazywania wytrenowanych modeli. Wartością domyślną jest < (nazwa eksperymentu) > Opis uruchomienia (opcjonalnie) Opis nowego przebiegu szkolenia Uruchom znaczniki (opcjonalnie) Znaczniki dla nowego uruchomienia szkolenia Tryb tworzenia (opcjonalnie) Wybierz sposób obsługi przypadku, w którym przepływ potoku próbuje utworzyć zasób, ale istnieje jeden o takiej samej nazwie. Jedna z następujących wartości: ignore,fail,overwriteStrategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Modele Lista ścieżek najwyższego N wytrenowanego i utrwalonego modelu (uporządkowana według wybranej metryki ewaluacji) Najlepszy model ścieżka zwycięskiego modelu (na podstawie wybranej metryki ewaluacyjnej) Metryki modelu lista wytrenowanych metryk modelu (każdy element jest zagnieżdżonym obiektem z metrykami takimi jak: holdout_accuracy, holdout_average_precision, ...) Zwycięska metryka modelu wybrana metryka ewaluacyjna zwycięskiego modelu Zoptymalizowana metryka Metryka używana do strojenia modelu Status wykonania Informacje o stanie zadania: oczekujące, uruchamiane, uruchomione, zakończone, anulowane lub zakończone niepowodzeniem z błędami Komunikat o statusie Informacje o stanie zadania
Uruchom wstawiany skrypt Bash, aby zautomatyzować funkcję lub proces dla potoku. Kod skryptu powłoki Bash można wprowadzić ręcznie lub zaimportować skrypt powłoki bash z zasobu, parametru potoku lub danych wyjściowych innego węzła.
Do przetwarzania dużych plików wyjściowych można również użyć skryptu Bash. Na przykład można wygenerować dużą listę rozdzielaną przecinkami, którą można następnie iterować za pomocą pętli.
W poniższym przykładzie użytkownik wprowadził kod skryptu wstawianego ręcznie. Skrypt używa narzędzia
cpdctldo wyszukiwania we wszystkich notatnikach ze znacznikiem ustawionej zmiennej i agreguje wyniki w postaci listy JSON. Lista może być następnie używana w innym węźle, takim jak uruchamianie notatników zwróconych z wyszukiwania.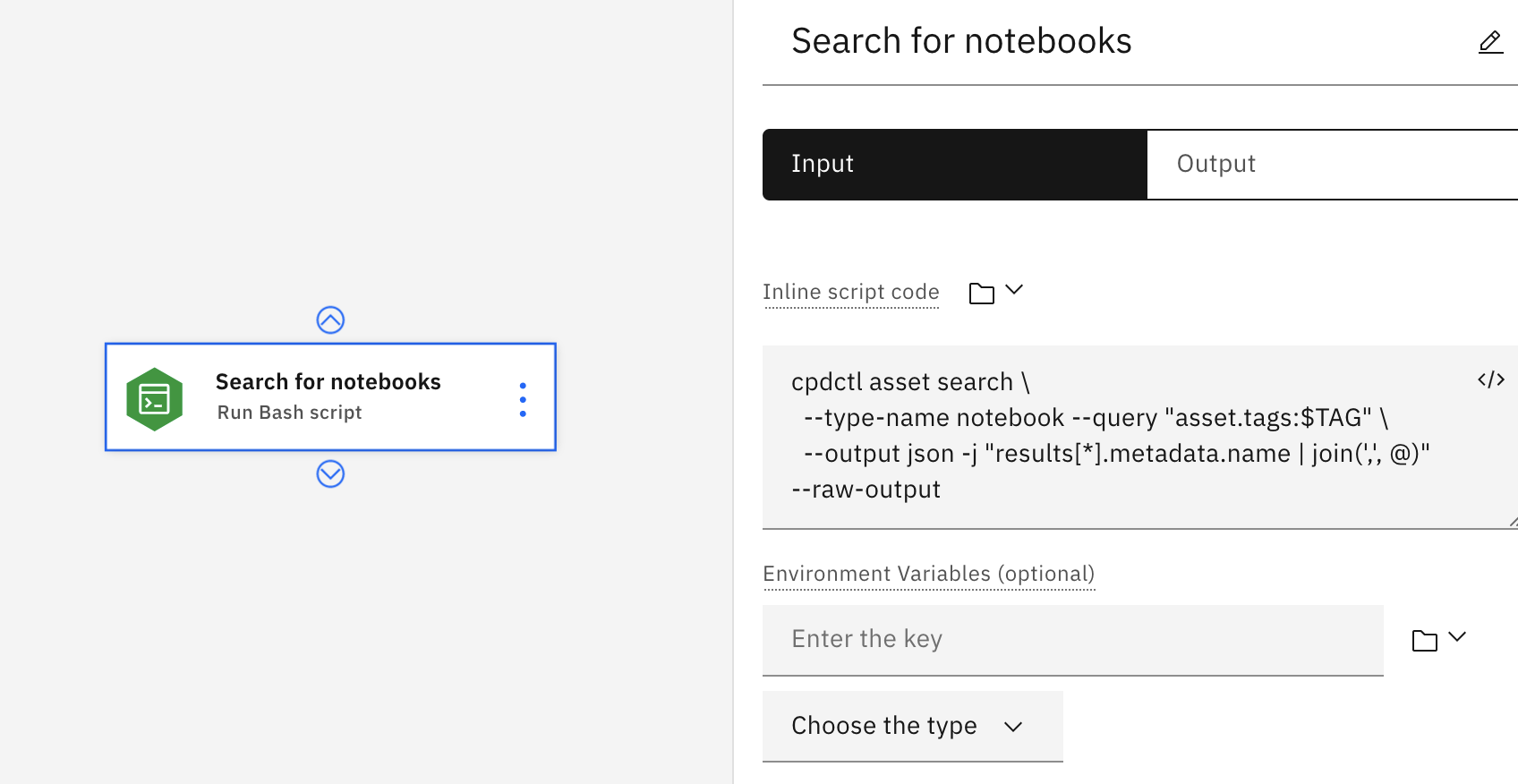
Parametry wejściowe
Parametr Opis Kod skryptu wstawianego Wprowadź skrypt Bash w edytorze kodu wstawianego. Opcjonalnie: Alternatywnie można wybrać zasób, przypisać parametr potoku lub wybrać inny węzeł. Zmienne środowiskowe (opcjonalne) Określ nazwę zmiennej (klucz) i typ danych oraz dodaj do listy zmiennych, które mają być używane w skrypcie. Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Zmienne wyjściowe Skonfiguruj parę klucz/wartość dla każdej zmiennej niestandardowej, a następnie kliknij przycisk Dodaj, aby zapełnić listę zmiennych dynamicznych dla węzła. Wartość zwracana Wartość zwracana z węzła Standardowe wyjście Standardowe wyjście ze skryptu Status wykonania Informacje o stanie zadania: oczekujące, uruchamiane, uruchomione, zakończone, anulowane lub zakończone niepowodzeniem z błędami Komunikat o statusie Komunikat powiązany ze statusem Reguły dla danych wyjściowych skryptu powłoki Bash
Dane wyjściowe skryptu powłoki Bash są często wynikiem obliczonego wyrażenia i mogą być duże. Podczas przeglądania właściwości skryptu z poprawnymi dużymi danymi wyjściowymi można wyświetlić podgląd lub pobrać dane wyjściowe w przeglądarce.
Reguły te określają, jaki typ dużych danych wyjściowych jest poprawny.
- Dane wyjściowe wyrażenia
list_expressionsą obliczane, więc są poprawne dla dużych danych wyjściowych. - Dane wyjściowe łańcucha są traktowane jako wartość literału, a nie wyrażenie obliczane, dlatego muszą być zgodne z limitami wielkości, które zarządzają wyrażeniami wstawianymi. Na przykład użytkownik jest ostrzegany, gdy wartość literału przekracza 1 kB, a wartości 2 kB i wyższe powodują błąd.
Odwoływanie się do zmiennej w skrypcie powłoki Bash
Sposób przywoływania zmiennej w skrypcie zależy od tego, czy zmienna została utworzona jako zmienna wejściowa, czy jako zmienna wyjściowa. Zmienne wyjściowe są tworzone jako plik i wymagają ścieżki do pliku w odwołaniu. Szczegóły:
- Zmienne wejściowe są dostępne przy użyciu przypisanej nazwy
- Nazwy zmiennych wyjściowych wymagają dodania łańcucha
_PATHdo nazwy zmiennej w celu wskazania, że wartości muszą zostać zapisane w pliku wyjściowym wskazywanym przez zmienną{output_name}_PATH.
Korzystanie z protokołu SSH w skryptach Bash
W poniższych krokach opisano sposób użycia programu ` ssh ` do uruchomienia zdalnego skryptu powłoki Bash.- Utwórz klucz prywatny i klucz publiczny.
ssh-keygen -t rsa -C "XXX" - Skopiuj klucz publiczny na zdalny host.
ssh-copy-id USER@REMOTE_HOST - Na zdalnym hoście sprawdź, czy zawartość klucza publicznego została dodana do programu
/root/.ssh/authorized_keys. - Skopiuj klucze publiczne i prywatne do nowego katalogu w węźle Uruchom skrypt powłoki .
mkdir -p $HOME/.ssh #copy private key content echo "-----BEGIN OPENSSH PRIVATE KEY----- ... ... -----END OPENSSH PRIVATE KEY-----" > $HOME/.ssh/id_rsa #copy public key content echo "ssh-rsa ...... " > $HOME/.ssh/id_rsa.pub chmod 400 $HOME/.ssh/id_rsa.pub chmod 400 $HOME/.ssh/id_rsa ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -o GlobalKnownHostsFile=/dev/null -i $HOME/.ssh/id_rsa USER@REMOTE_HOST "cd /opt/scripts; ls -l; sh 1.sh"
Korzystanie z programów narzędziowych SSH w skryptach Bash
W poniższych krokach opisano sposób użycia komendy ` sshpass ` do uruchomienia zdalnego skryptu powłoki Bash.- Umieść plik hasła SSH w ścieżce systemowej, takiej jak ścieżka podłączonego woluminu pamięci masowej.
- Użyj hasła SSH bezpośrednio w węźle Uruchom skrypt powłoki bash :
cd /mnts/orchestration ls -l sshpass chmod 777 sshpass ./sshpass -p PASSWORD ssh -o StrictHostKeyChecking=no USER@REMOTE_HOST "cd /opt/scripts; ls -l; sh 1.sh"
- Dane wyjściowe wyrażenia
Skonfiguruj ten węzeł, aby uruchomić wybrane zadania wdrażania.
Parametry wejściowe
Parametr Opis Wdrożenie Przeglądanie lub wyszukiwanie zadania wdrażania Zasoby danych wejściowych Określ dane używane dla zadania wsadowego Ograniczenie: Dane wejściowe dla zadań wdrożenia wsadowego są ograniczone do zasobów danych. Wdrożenia, które wymagają danych wejściowych JSON lub wielu plików jako danych wejściowych, nie są obsługiwane. Na przykład nie są obsługiwane modele SPSS i rozwiązania Decision Optimization wymagające wielu plików jako danych wejściowych.Zasób wyjściowy Nazwa pliku wyjściowego dla wyników zadania wsadowego. Można wybrać opcję Nazwa pliku i wprowadzić niestandardową nazwę pliku lub Zasób danych i wybrać istniejący zasób w obszarze. Specyfikacja sprzętu (opcjonalna) Przeglądaj w poszukiwaniu specyfikacji sprzętu do zastosowania dla zadania Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Zadanie Ścieżka do pliku z wynikami zadania wdrażania Uruchomienie zadania Identyfikator zadania Status wykonania Informacje o stanie zadania: oczekujące, uruchamiane, uruchomione, zakończone, anulowane lub zakończone niepowodzeniem z błędami Komunikat o statusie Informacje o stanie zadania
IBM DataStage to narzędzie integracji danych służące do projektowania, tworzenia i uruchamiania zadań, które przenoszą i transformują dane. Uruchom zadanie DataStage i użyj wyników w późniejszym węźle.
Na przykład w poniższym przepływie przedstawiono węzeł Wykonaj DataStage , który pobiera dane z repozytorium Git . Jeśli zadanie zostanie zakończone pomyślnie, potok wykona następny węzeł i utworzy obszar wdrażania. Jeśli zadanie nie powiedzie się, zostanie wyzwolona wiadomość e-mail z powiadomieniem i pętla zostanie zakończona.
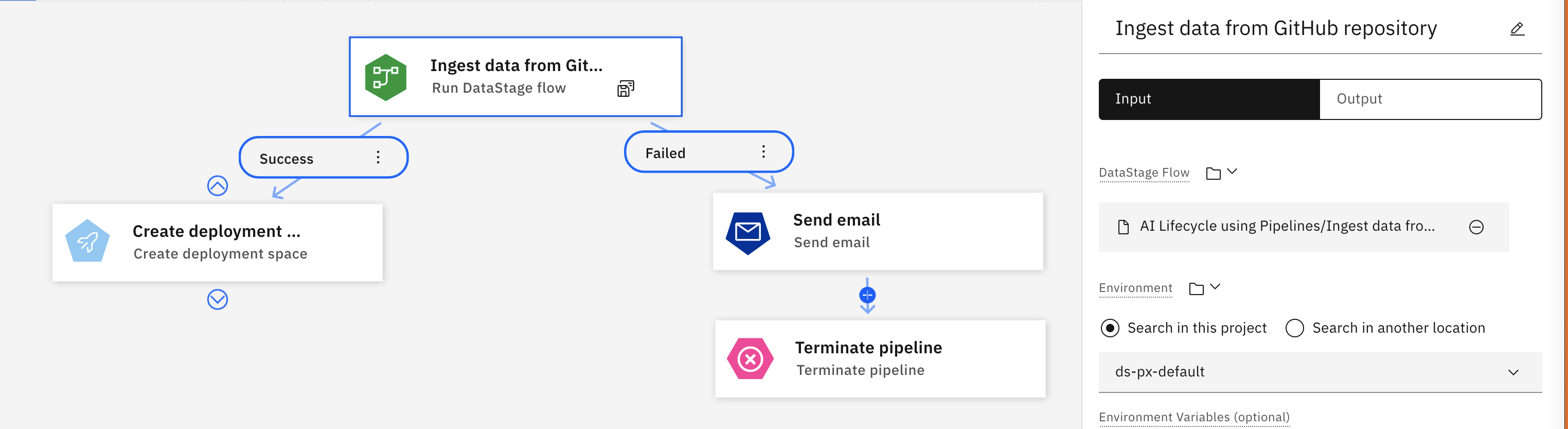
Parametr Opis Zadanie DataStage Ścieżka do zadania DataStage Wartości parametrów lokalnych (opcjonalne) Edytuj domyślne parametry zadania. Ta opcja jest dostępna tylko wtedy, gdy w zadaniu znajdują się parametry lokalne. Wartości z zestawów parametrów (opcjonalne) Edytuj zestawy parametrów używane przez to zadanie. Można użyć parametrów zdefiniowanych domyślnie lub użyć zbiorów wartości z parametrów innych potoków. Środowisko Znajdź i wybierz środowisko używane do uruchamiania zadania DataStage . Uwaga: pozostaw pole środowisk bez względu na to, czy ma być używane domyślne środowisko wykonawcze XS DataStage . Jeśli zostanie wybrana opcja nadpisania, należy określić alternatywne środowisko uruchamiania zadania. Upewnij się, że podane środowisko jest zgodne z konfiguracją sprzętu, aby uniknąć błędu w czasie wykonywania.Zmienne środowiskowe (opcjonalne) Podaj nazwę zmiennej (klucz) i typ danych oraz dodaj do listy zmiennych, które mają być używane w zadaniu Parametry zadania (opcjonalne) Dodatkowy parametr, który ma zostać przekazany do zadania po jego uruchomieniu. Określ parę klucz/wartość i dodaj do listy Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Zadanie Ścieżka do wyników zadania DataStage Uruchomienie zadania Informacje o uruchomieniu zadania Nazwa zadania Nazwa zadania Status wykonania Informacje o stanie zadania: oczekujące, uruchamiane, uruchomione, zakończone, anulowane lub zakończone niepowodzeniem z błędami Komunikat o statusie Informacje o stanie zadania
Ten węzeł uruchamia określone zadanie Data Refinery .
Parametry wejściowe
Parametr Opis Zadanie Data Refinery Ścieżka do zadania Data Refinery . Środowisko Ścieżka środowiska używanego do uruchamiania zadania Uwaga: Pozostaw pole środowisk bez względu na to, czy ma być używane domyślne środowisko wykonawcze. Jeśli zostanie wybrana opcja nadpisania, należy określić alternatywne środowisko uruchamiania zadania. Należy upewnić się, że podane środowisko jest zgodne z językiem komponentu i konfiguracją sprzętu, aby uniknąć błędu w czasie wykonywania.Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Zadanie Ścieżka do wyników zadania Data Refinery Uruchomienie zadania Informacje o uruchomieniu zadania Nazwa zadania Nazwa zadania Status wykonania Informacje o stanie przepływu: oczekujący, uruchamiany, uruchomiony, zakończony, anulowany lub nieudany z błędami Komunikat o statusie Informacje o stanie przepływu
Te opcje konfiguracyjne umożliwiają określenie sposobu uruchamiania Jupyter Notebook w potoku.
Parametry wejściowe
Parametr Opis Zadanie notatnika Ścieżka do zadania notatnika. Środowisko Ścieżka środowiska używanego do uruchamiania notatnika. Uwaga: Pozostaw pole środowisk bez względu na to, czy ma być używane środowisko domyślne. Jeśli zostanie wybrana opcja nadpisania, należy określić alternatywne środowisko uruchamiania zadania. Należy upewnić się, że podane środowisko jest zgodne z językiem notebooka i konfiguracją sprzętu, aby uniknąć błędu w czasie wykonywania.Zmienne środowiskowe (opcjonalne) Lista zmiennych środowiskowych używanych do uruchamiania zadania notatnika Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Uwagi:
- Zmienne środowiskowe definiowane w potoku nie mogą być używane dla zadań notatnika uruchamianych poza programem Watson Pipelines.
- Notatnik można uruchomić z pakietu kodu w zwykłym pakiecie.
Parametry wyjściowe
Parametr Opis Zadanie Ścieżka do wyników zadania notatnika Uruchomienie zadania Informacje o uruchomieniu zadania Nazwa zadania Nazwa zadania Zmienne wyjściowe Skonfiguruj parę klucz/wartość dla każdej zmiennej niestandardowej, a następnie kliknij przycisk Dodaj , aby zapełnić listę zmiennych dynamicznych dla węzła. Status wykonania Informacje o stanie wykonania: oczekujące, uruchamianie, uruchomione, zakończone, anulowane lub zakończone niepowodzeniem z błędami Komunikat o statusie Informacje o stanie działania notatnika
Uruchom komponent potoku wielokrotnego użytku utworzony za pomocą skryptu Python . Szczegółowe informacje na ten temat zawiera sekcja Tworzenie komponentu niestandardowego.
- Jeśli komponent potoku jest dostępny, skonfigurowanie węzła powoduje wyświetlenie listy dostępnych komponentów.
- Wybrany komponent określa wejście i wyjście węzła.
- Po przypisaniu komponentu do węzła nie można go usunąć ani zmienić. Należy usunąć węzeł i utworzyć nowy.
Dodaj potok, aby uruchomić zadanie zagnieżdżonego potoku jako część potoku zawierającego. Jest to sposób dodawania procesów wielokrotnego użytku do wielu potoków. Dane wyjściowe z zagnieżdżonego przebiegu potoku można wykorzystać jako dane wejściowe dla węzła w zawierającym go potoku.
Parametry wejściowe
Parametr Opis Zadanie rurociągów Wybierz lub wprowadź ścieżkę do istniejącego zadania potoku. Środowisko (opcjonalnie) Wybierz środowisko, w którym ma zostać uruchomione zadanie potoku, i przypisz zasoby środowiska. Uwaga: Pozostaw pole środowisk bez względu na to, czy ma być używane domyślne środowisko wykonawcze. Jeśli zostanie wybrana opcja nadpisania, należy określić alternatywne środowisko uruchamiania zadania. Należy upewnić się, że podane środowisko jest zgodne z językiem komponentu i konfiguracją sprzętu, aby uniknąć błędu w czasie wykonywania.Wartości parametrów lokalnych (opcjonalne) Edytuj domyślne parametry zadania. Ta opcja jest dostępna tylko wtedy, gdy w zadaniu znajdują się parametry lokalne. Wartości z zestawów parametrów (opcjonalne) Edytuj zestawy parametrów używane przez to zadanie. Można użyć parametrów zdefiniowanych domyślnie lub użyć zbiorów wartości z parametrów innych potoków. Strategia błędów (opcjonalna) Opcjonalnie nadpisz domyślną strategię błędów dla węzła Parametry wyjściowe
Parametr Opis Zadanie Ścieżka do wyników zadania potoku Uruchomienie zadania Informacje o uruchomieniu zadania Nazwa zadania Nazwa zadania Status wykonania Zwraca wartość: Zakończone, Zakończone z ostrzeżeniami, Zakończone z błędami, Niepowodzenie lub Anulowane Komunikat o statusie Komunikat powiązany ze statusem Uwagi dotyczące uruchamiania zagnieżdżonych zadań potoku
Jeśli utworzono potok z zagnieżdżonymi potokami i uruchomiono zadanie potoku z najwyższego poziomu, potoki są nazywane i zapisywane jako zasoby aplikacyjne projektu przy użyciu następującej konwencji:
- Zadanie potoku najwyższego poziomu ma nazwę "Zadanie próbne- guid potoku".
- Wszystkie kolejne zadania mają nazwę "pipeline_ guid potoku".
Więcej inform.
Temat nadrzędny: Tworzenie potoku