Translation not up to date
Dane można zintegrować z notatnikami, uzyskując dostęp do danych z pliku lokalnego, z wolnych zestawów danych lub z połączenia ze źródłem danych. Dane te są ładowane do struktury danych lub kontenera w notatniku, na przykład pandas.DataFrame, numpy.array, Spark RDD lub Spark DataFrame.
Aby pracować z danymi w notatniku, można wybrać jedną z następujących opcji:
| Opcja | Zalecana metoda | Wymagania | Szczegóły |
|---|---|---|---|
| Dodawanie danych z pliku z systemu lokalnego | Użyj wygenerowanego kodu dla wybranego źródła danych, klikając ikonę Fragmenty kodu ( |
Plik musi istnieć jako zasób aplikacyjny projektu | Dodaj plik z systemu lokalnego |
| Dodaj dane z wolnego zestawu danych z galerii | Użyj wygenerowanego kodu dla wybranego źródła danych, klikając ikonę Fragmenty kodu ( |
Zestaw danych (plik) musi istnieć jako zasób aplikacyjny projektu | Użyj bezpłatnego zestawu danych z galerii |
| Załaduj dane z połączeń źródła danych | Użyj wygenerowanego kodu dla wybranego źródła danych, klikając ikonę Fragmenty kodu ( |
Połączenia muszą istnieć jako zasoby aplikacyjne projektu | Ładowanie danych z połączenia źródła danych |
| Programowy dostęp do zasobów aplikacyjnych i metadanych projektu | Użycie ibm-watson-studio-lib |
Źródła danych muszą istnieć jako zasoby aplikacyjne projektu | Korzystanie z biblioteki ibm-watson-studio-lib do interakcji z zasobami danych |
| Tworzenie i używanie danych składnicy składników | Korzystanie z funkcji bibliotecznych systemu assetframe-lib |
Zasoby danych muszą istnieć jako zasoby aplikacyjne w projekcie | Biblioteka assetframe-lib dla języka Python umożliwia tworzenie i używanie danych składnicy składników |
| Dostęp do danych za pomocą funkcji API lub komendy systemu operacyjnego | Na przykład użycie składni Wget |
N/D | Dostęp do danych za pomocą funkcji API lub komendy systemu operacyjnego |
Załaduj dane z plików lokalnych
Aby uzyskać dostęp do danych z pliku lokalnego, można załadować plik z notatnika lub najpierw załadować plik do projektu. W notatniku można dodać automatycznie wygenerowany kod, aby uzyskać dostęp do danych, klikając ikonę Fragmenty kodu (![]() ), a następnie klikając opcję Odczytaj dane. Wygenerowany kod służy do szybkiego rozpoczęcia pracy z zestawami danych.
), a następnie klikając opcję Odczytaj dane. Wygenerowany kod służy do szybkiego rozpoczęcia pracy z zestawami danych.
Kod jest generowany dla typów plików, takich jak CSV, JSON i XLSX. Aby dowiedzieć się, które struktury danych są generowane dla danego języka notatnika, należy zapoznać się z sekcją Obsługa ładowania danych. W przypadku typów plików, dla których generowanie kodu nie jest obsługiwane, można wstawić tylko referencje pliku. Korzystając z referencji, można napisać własny kod ładujący dane pliku do DataFrame lub innej struktury danych w komórce notatnika.
Aby dodać plik z systemu lokalnego do notatnika:
- Otwórz notatnik w trybie edycji, kliknij ikonę Prześlij zasób aplikacyjny do projektu (
 ) na pasku narzędzi, a następnie przejrzyj plik danych lub przeciągnij go na pasek boczny notatnika.
) na pasku narzędzi, a następnie przejrzyj plik danych lub przeciągnij go na pasek boczny notatnika. - Kliknij ikonę Fragmenty kodu (
 ), kliknij opcję Odczytaj dane , a następnie wybierz plik danych z projektu. Użyj ikony ołówka, aby wybrać inny plik danych.
), kliknij opcję Odczytaj dane , a następnie wybierz plik danych z projektu. Użyj ikony ołówka, aby wybrać inny plik danych. - Z listy rozwijanej Ładuj jako wybierz preferowaną opcję ładowania.
- Kliknij pustą komórkę kodu w notatniku, a następnie kliknij, aby wstawić wygenerowany kod. Można również kliknąć, aby skopiować wygenerowany kod do schowka, a następnie wkleić go do notatnika.
Aby ręcznie dodać referencje pliku i zapisać kod dla metody dostępu do pliku i DataFrame :
- Dodaj plik do obiektowej pamięci masowej, klikając ikonę Prześlij zasób aplikacyjny do projektu (), a następnie przeglądając plik danych lub przeciągając go na pasek boczny notatnika.
- Kliknij ikonę Fragmenty kodu (), a następnie kliknij opcję Odczytaj dane.
- Kliknij pustą komórkę kodu w notatniku, wybierz opcję ładowania Referencje, a następnie załaduj referencje do komórki. Można również kliknąć, aby skopiować referencje do schowka, a następnie wkleić je do notatnika.
- Aby uzyskać dostęp do danych w notatniku, należy wstawić referencje do odpowiedniej metody dla danego języka notatnika. Na przykład ten kod można znaleźć w blogu Python.
- Aby załadować dane do DataFrame lub innej struktury danych, należy odwołać się do metody dostępu do danych w odpowiedniej dla danego języka metodzie odczytu.
Załaduj zestawy danych z galerii
Zestawy danych w galerii zawierają otwarte dane. Obejrzyj ten krótki film wideo, aby zobaczyć, jak pracować z publicznymi zestawami danych w galerii.
Ten film wideo zawiera wizualną metodę zapoznawania się z pojęciami i zadaniami opisanymi w tej dokumentacji.
Zapis wideo Czas Transkrypcja 00:00 Ten film wideo przedstawia sposób uzyskiwania dostępu do publicznych zestawów danych w galerii Cloud Pak for Data as a Service . 00:06 Rozpocznij w galerii i użyj filtrów, aby wyświetlić tylko zestawy danych. 00:13 W tym miejscu znajdują się rozbudowane zestawy danych, których można użyć w analizie. 00:17 Na przykład można wyszukać słowa "ekonomia", "populacja", "pogoda" lub "praca". 00:28 To wygląda na interesujący zestaw danych. 00:30 Otwórz go i wyświetl podgląd danych. 00:34 W tym miejscu można współużytkować zestaw danych w mediach społecznościowych, uzyskać bezpośredni odsyłacz do zestawu danych lub pobrać zestaw danych. 00:45 Można również skopiować zestaw danych do konkretnego projektu. 00:52 Teraz przejdź do tego projektu. 00:55 Na karcie "Zasoby" można zobaczyć, że zestaw danych został dodany do sekcji zasobów danych. 01:01 Następnie dodaj nowy notatnik. 01:05 Tytuł tego notatnika to "stopa bezrobocia". 01:09 Wybierz środowisko wykonawcze i język. 01:14 Gdy będziesz gotowy, utwórz notatnik. 01:20 Po załadowaniu notatnika należy uzyskać dostęp do źródeł danych i zlokalizować plik bezrobocia. 01:27 Kliknij przycisk "Wstaw do kodu" i wybierz sposób wstawiania danych. 01:33 Opcje dostępne w tym polu rozwijanym zależą od języka używanego w tym notatniku. 01:38 Należy zauważyć, że wstawiony kod zawiera informacje autoryzacyjne, które będą potrzebne do odczytania pliku danych z instancji Object Storage . 01:45 Po uruchomieniu kodu zostanie wyświetlone pięć pierwszych wierszy. 01:50 Teraz można przystąpić do analizowania dowolnych rozbudowanych zestawów danych w galerii. 01:56 Więcej filmów wideo można znaleźć w dokumentacji Cloud Pak for Data as a Service .
Aby dodać zestaw danych z galerii w notatniku, należy skopiować zestaw danych do projektu:
- W menu nawigacyjnym Cloud Pak for Data as a Service wybierz opcję Galeria.
- Znajdź kartę dla zestawu danych, który chcesz dodać.
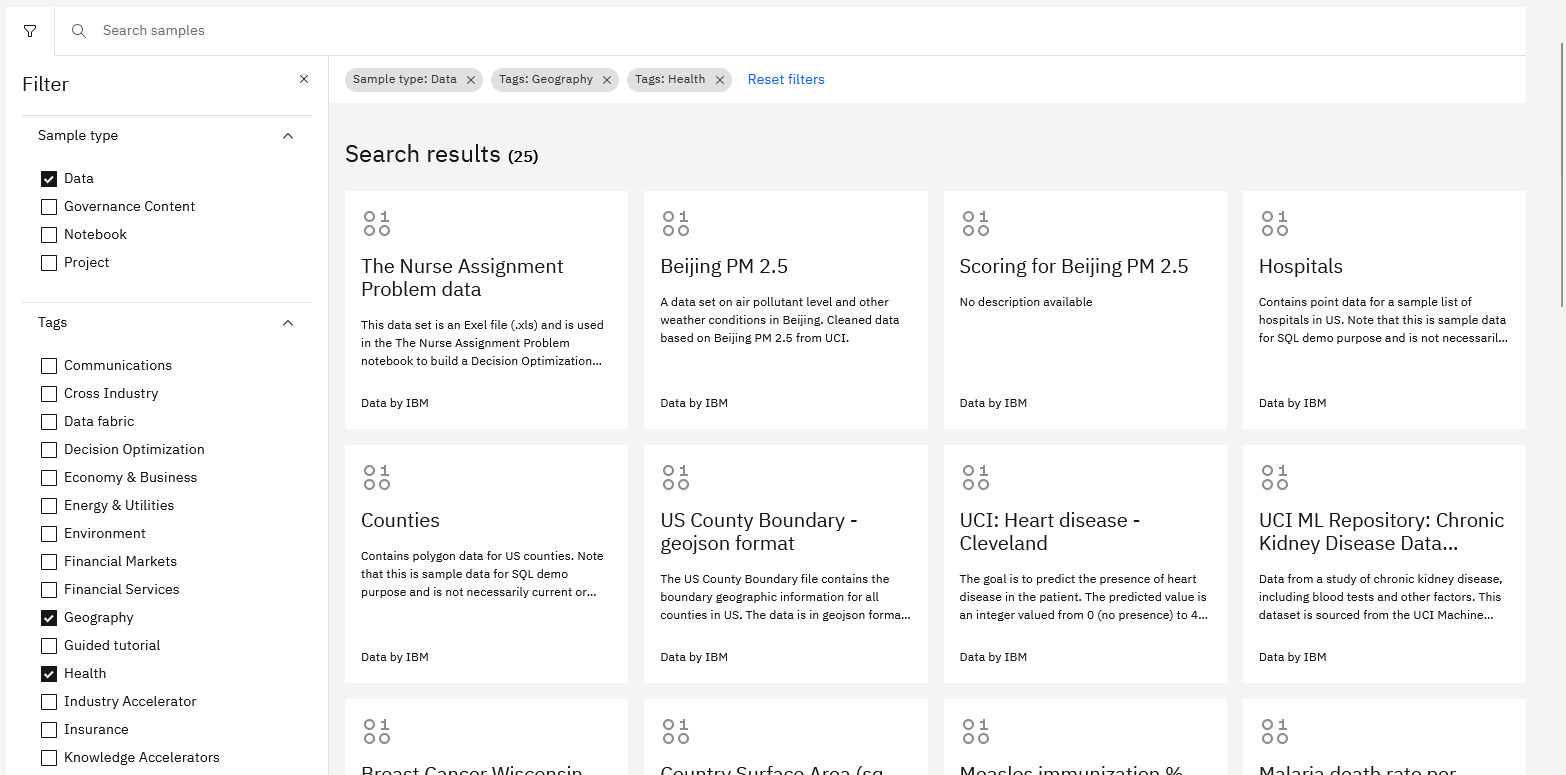
- Kliknij opcję Dodaj do projektu, wybierz projekt i kliknij przycisk Dodaj. Kliknięcie opcji Wyświetl projekt powoduje przejście do strony przeglądu projektu. Zasób danych zostanie dodany do listy zasobów danych na stronie Zasoby projektu.
- Otwórz notatnik w trybie edycji, kliknij ikonę Fragmenty kodu () na pasku narzędzi, kliknij opcję Odczytaj dane , a następnie wybierz zasób danych z projektu.
- Z listy rozwijanej Ładuj jako wybierz preferowaną opcję ładowania.
- Kliknij pustą komórkę kodu w notatniku, a następnie kliknij, aby wstawić wygenerowany kod. Można również kliknąć, aby skopiować wygenerowany kod do schowka, a następnie wkleić go do notatnika. Wygenerowany kod służy jako szybki start do rozpoczęcia pracy z zestawem danych lub połączeniem. W przypadku systemów produkcyjnych należy uważnie przejrzeć wstawiony kod, aby określić, czy należy napisać własny kod, który lepiej odpowiada potrzebom użytkownika.
Załaduj dane z połączeń źródła danych
Przed załadowaniem danych z usługi danych IBM lub z zewnętrznego źródła danych należy utworzyć lub dodać połączenie do projektu. Patrz sekcja Dodawanie połączeń do projektów.
Użytkownik dodaje automatycznie wygenerowany kod w celu załadowania danych z połączeń z bazą danych, klikając ikonę Fragmenty kodu (![]() ) na pasku narzędzi notatnika, a następnie klikając opcję Odczytaj dane. Aby dowiedzieć się, które połączenia z bazą danych są obsługiwane, należy zapoznać się z sekcją Obsługa ładowania danych. W przypadku nieobsługiwanych połączeń z bazą danych można wstawić tylko referencje połączenia z bazą danych. Korzystając z referencji, można napisać własny kod ładujący dane do DataFrame lub innej struktury danych w komórce notatnika.
) na pasku narzędzi notatnika, a następnie klikając opcję Odczytaj dane. Aby dowiedzieć się, które połączenia z bazą danych są obsługiwane, należy zapoznać się z sekcją Obsługa ładowania danych. W przypadku nieobsługiwanych połączeń z bazą danych można wstawić tylko referencje połączenia z bazą danych. Korzystając z referencji, można napisać własny kod ładujący dane do DataFrame lub innej struktury danych w komórce notatnika.
Aby załadować dane z istniejącego połączenia ze źródłem danych do struktury danych w notatniku:
- Otwórz notatnik w trybie edycji, kliknij ikonę Fragmenty kodu () na pasku narzędzi, kliknij opcję Odczytaj dane , a następnie wybierz połączenie ze źródłem danych z projektu. Użyj ikony ołówka, aby wybrać inne połączenie.
- Wybierz schemat i tabelę. Aby zmienić wybór, użyj ikony ołówka.
- Wybierz opcję ładowania. Jeśli po wybraniu schematu i tabeli zostaną wybrane referencje, a nie opcja ładowania danych, zostaną wygenerowane tylko metadane.
- Kliknij pustą komórkę kodu w notatniku, a następnie wstaw kod do komórki. Można również kliknąć, aby skopiować wygenerowany kod do schowka, a następnie wkleić go do notatnika. Wygenerowany kod służy jako szybki start do rozpoczęcia pracy z zestawem danych lub połączeniem. W przypadku systemów produkcyjnych należy uważnie przejrzeć wstawiony kod, aby określić, czy należy napisać własny kod, który lepiej odpowiada potrzebom użytkownika.
- W razie potrzeby wprowadź swoje osobiste referencje dla zablokowanych połączeń danych, które są oznaczone ikoną klucza (
 ). Jest to jednorazowy krok, który trwale odblokowuje połączenie. Po odblokowaniu połączenia ikona klucza nie jest już wyświetlana. Patrz sekcja Dodawanie połączeń do projektów.
). Jest to jednorazowy krok, który trwale odblokowuje połączenie. Po odblokowaniu połączenia ikona klucza nie jest już wyświetlana. Patrz sekcja Dodawanie połączeń do projektów. - Jeśli nie można wygenerować kodu dla połączenia, załaduj referencje i otwórz połączenie z bazą danych, które odwołuje się do referencji. Napisz kod, aby załadować dane.
Użyj funkcji API lub komendy systemu operacyjnego, aby uzyskać dostęp do danych
Aby uzyskać dostęp do danych, można użyć funkcji API lub komend systemu operacyjnego w notatniku, na przykład komendy Wget w celu uzyskania dostępu do danych za pomocą protokołów HTTP, HTTPS lub FTP. Jeśli używane są te typy funkcji i komend interfejsu API, należy dołączyć kod, który ustawia znacznik dostępu projektu. Więcej informacji na ten temat zawiera sekcja Ręczne dodawanie znacznika dostępu do projektu.
Więcej inform.
Biblioteka ibm-watson-studio-lib służy do programowej interakcji z zasobami aplikacyjnymi projektu. Biblioteka
ibm-watson-studio-libjest następcą bibliotekiproject-lib. Aby przejść z programuproject-libdo programuibm-watson-studio-lib, należy zapoznać się z następującymi informacjami:
Temat nadrzędny: Notatniki i skrypty