データをノートブックに統合するには、ローカル・ファイル、フリー・データ・セット、またはデータ・ソース接続からデータにアクセスします。 例えば、pandas.DataFrame, numpy.array、Spark RDD、SparkDataFrameなどです。
ノートブックでデータを処理するには、以下のいずれかのオプションを選択できます。
| オプション | 推奨される方法 | 要件 | 詳細 |
|---|---|---|---|
| ローカル・システム上のファイルからのデータの追加 | データをロードする コード・スニペット を追加します。 | ファイルは、プロジェクト内の資産として存在している必要があります。 | ローカル・システムからファイルを追加 してから、 コード・スニペットを使用してデータをロード |
| リソース・ハブからのフリー・データ・セットからのデータの追加 | データをロードする コード・スニペット を追加します。 | データ・セット (ファイル) は、プロジェクト内の資産として存在している必要があります。 | リソース・ハブからフリー・データ・セットを追加 してから、 コード・スニペットを使用してデータをロードします |
| データ・ソース接続からのデータのロード | データをロードする コード・スニペット を追加します。 | 接続はプロジェクト内の資産として存在している必要があります | プロジェクトに接続を追加 してから、 データ・ソース接続からデータをロードするコード・スニペットを追加 します。 |
| プログラムによるプロジェクト資産およびメタデータへのアクセス | 使用ibm-watson-studio-lib |
データ資産がプロジェクト内に存在している必要があります | ibm-watson-studio-lib ライブラリーを使用したデータ資産との対話 |
| フィーチャー・ストア・データの作成および使用 | assetframe-lib ライブラリー関数の使用 |
データ資産がプロジェクト内に存在している必要があります | Python 用の assetframe-lib ライブラリーを使用して、フィーチャー・ストア・データを作成および使用します |
| API 関数またはオペレーティング・システム・コマンドを使用したデータへのアクセス | コマンドの使用例を次に示します。 wget |
該当なし | API 関数またはオペレーティング・システム・コマンドを使用したデータへのアクセス |
ローカル・システムからのファイルの追加
Jupyterlab ノートブック・エディターを使用してローカル・システムからプロジェクトにファイルを追加するには、以下のようにします。
- ノートブックを編集モードで開きます。
- ツールバーから、 「資産をプロジェクトにアップロード」 アイコン
 をクリックし、ファイルを追加します。
をクリックし、ファイルを追加します。
リソース・ハブからのデータ・セットのロード
リソース・ハブ上のデータ・セットには、オープン・データが含まれています。 この短いビデオを視聴して、リソース・ハブでパブリック・データ・セットを操作する方法を確認してください。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
リソース・ハブからプロジェクトにデータ・セットを追加するには、以下のようにします。
ナビゲーションメニューからリソースハブを選択します。
追加するデータ・セットのカードを見つけます。
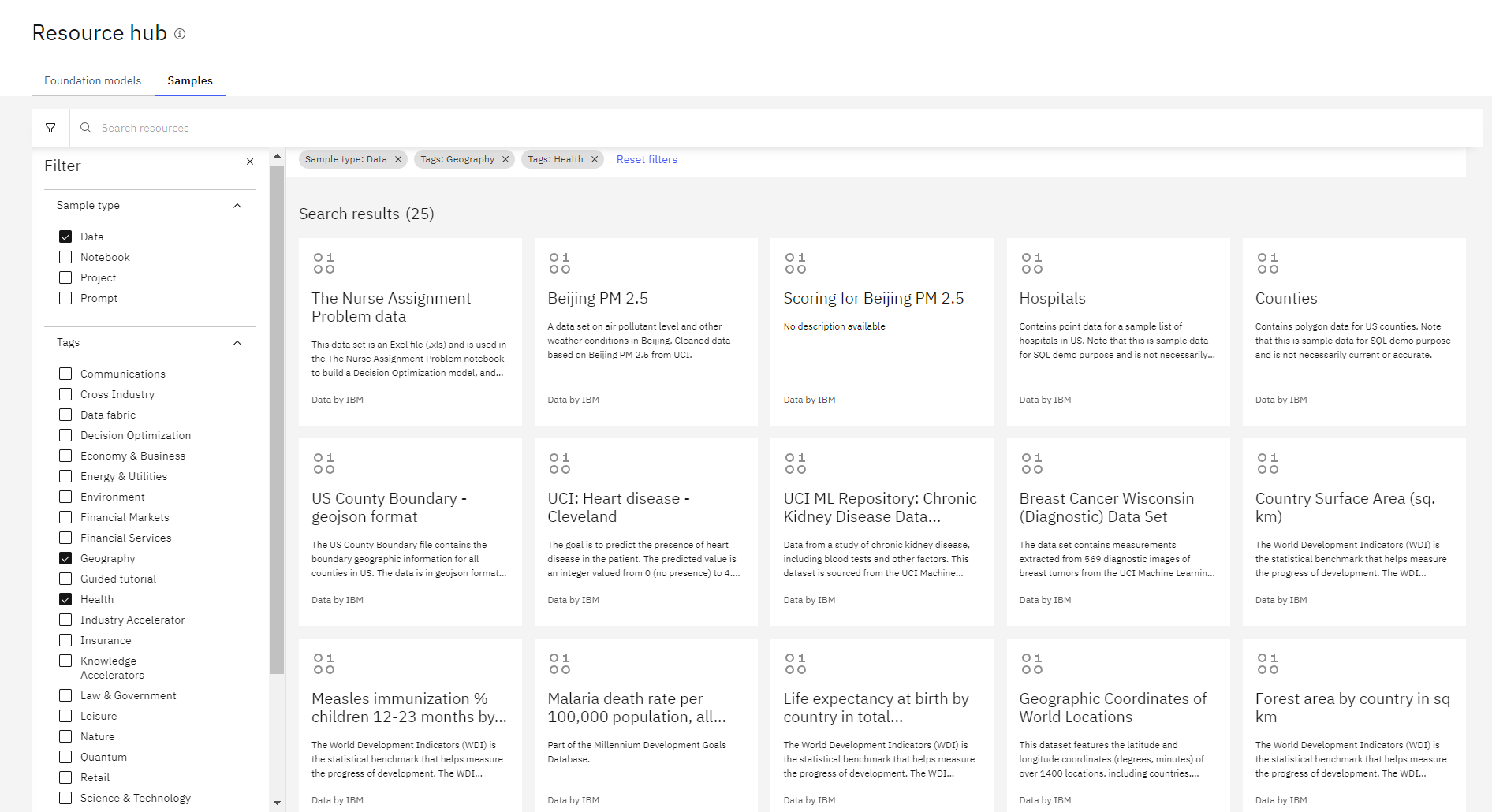
「プロジェクトに追加」をクリックし、プロジェクトを選択して、 「追加」をクリックします。 「プロジェクトの表示」をクリックすると、プロジェクトの「概要」ページが表示されます。 データ資産が、プロジェクトの「資産」ページのデータ資産のリストに追加されます。
ファイルからのデータのロード
前提条件 ファイルは、プロジェクト内の資産として存在している必要があります。 詳しくは、「 ローカル・システムからのファイルの追加 」または「 リソース・ハブからのデータ・セットのロード」を参照してください。
プロジェクト・ファイルからノートブックにデータをロードするには、以下のようにします。
- ノートブックを編集モードで開きます。
- Code snippetsアイコン
 をクリックし、Read dataをクリックして、プロジェクトからデータファイルを選択します。 選択を変更する場合は、 「編集」 アイコンを使用します。
をクリックし、Read dataをクリックして、プロジェクトからデータファイルを選択します。 選択を変更する場合は、 「編集」 アイコンを使用します。 - 「名前を付けてロード」 ドロップダウン・リストから、希望するロード・オプションを選択します。 「資格情報」を選択すると、ファイル・アクセス資格情報のみが生成されます。 詳しくは、 資格情報の追加を参照してください。
- ノートブックの空のコード・セルをクリックし、 「コードをセルに挿入」 をクリックして、生成されたコードを挿入します。 あるいは、生成されたコードをクリックしてクリップボードにコピーし、コードをノートブックに貼り付けます。
生成されたコードは、データ・セットの処理を開始するためのクイック・スタートとして機能します。 実動システムの場合は、挿入されたコードを慎重に検討して、ニーズにより適した独自のコードを作成するかどうかを判断してください。
どのノートブック言語およびデータ・フォーマットに対してどのデータ構造が生成されるかを確認するには、 データ・ロード・サポートを参照してください。
データ・ソース接続からのデータのロード
前提条件 IBM データ・サービスまたは外部データ・ソースからデータをロードする前に、プロジェクトへの接続を作成または追加する必要があります。 『プロジェクトへの接続の追加』を参照してください。
既存のデータ・ソース接続からノートブック内のデータ構造にデータをロードするには、以下のようにします。
- ノートブックを編集モードで開きます。
- Code snippetsアイコンをクリックし、Read dataをクリックして、プロジェクトからデータ・ソース接続を選択します。
- スキーマを選択し、テーブルを選択します。 選択内容を変更する場合は、 「編集」 アイコンを使用します。
- ロード・オプションを選択します。 「資格情報」を選択すると、メタデータのみが生成されます。 詳しくは、 資格情報の追加を参照してください。
- ノートブックの空のコード・セルをクリックし、セルにコードを挿入します。 あるいは、生成されたコードをクリックしてクリップボードにコピーし、コードをノートブックに貼り付けます。
- 必要な場合は、鍵アイコン
 が表示されているロックされたデータ接続用の個人認証情報を入力します。 これは、ユーザーに対して永続的に接続のロックを解除する 1 回限りのステップです。 接続をアンロックすると、鍵アイコンは表示されなくなります。 詳しくは、 プロジェクトへの接続の追加を参照してください。
が表示されているロックされたデータ接続用の個人認証情報を入力します。 これは、ユーザーに対して永続的に接続のロックを解除する 1 回限りのステップです。 接続をアンロックすると、鍵アイコンは表示されなくなります。 詳しくは、 プロジェクトへの接続の追加を参照してください。
生成されたコードは、接続の処理を開始するためのクイック・スタートとして機能します。 実動システムの場合は、挿入されたコードを慎重に検討して、ニーズにより適した独自のコードを作成するかどうかを判断してください。
どのノートブック言語およびデータ・フォーマットに対してどのデータ構造が生成されるかを確認するには、 データ・ロード・サポートを参照してください。
資格の追加
IBM Cloud Object Storageにあるファイルや、接続を通じてアクセス可能なファイルにアクセスするための独自のコードを生成できます。 これは、例えば、ご使用のファイル・フォーマットがスニペット生成ツールによってサポートされていない場合に役立ちます。 資格情報を使用して、ノートブック・セル内のデータ構造にデータをロードするための独自のコードを作成できます。
資格情報を追加するには:
- Code snippetsアイコンをクリックし、Read dataをクリックする。
- ノートブックの空のコード・セルをクリックし、ロード・オプションとして 「資格情報」 を選択し、資格情報をセルにロードします。 資格情報をクリックしてクリップボードにコピーし、ノートブックに貼り付けることもできます。
- データにアクセスするには、ノートブックのコードに資格情報を挿入します。 例えば、『Python のブログ』でこのコードを参照してください。
API 関数またはオペレーティング・システム・コマンドを使用してデータにアクセスする
ノートブックで API 関数またはオペレーティング・システム・コマンドを使用してデータにアクセスできます。例えば、HTTP、HTTPS、または FTP プロトコルを使用してデータにアクセスする wget コマンドなどです。 これらのタイプの API 関数およびコマンドを使用する場合は、プロジェクト・アクセス・トークンを設定するコードを組み込む必要があります。 『プロジェクト・アクセス・トークンを手動で追加する』を参照してください。
APIに関する参考情報は、Data and AI Common Core APIを参照。
親トピック: ノートブックおよびスクリプト