Pour régler rapidement un foundation model, créez une expérience de réglage qui guide le foundation model pour qu'il renvoie les résultats que vous souhaitez sous la forme que vous souhaitez.
Exigences
Le Tuning Studio n'est pas disponible avec tous les plans ou dans tous les centres de données. Les modèles de fondation disponibles pour l'ajustement dans le Tuning Studio peuvent également varier en fonction du centre de données. Pour plus d'informations, voir watsonx.ai Runtime plans et Regional availability for services and features.
Généralement, le Tuning Studio est disponible à partir d'un projet créé automatiquement lorsque vous vous inscrivez à watsonx.ai. Le projet est nommé bac à sable et vous pouvez l'utiliser pour commencer à tester et à personnaliser les modèles de base.
Si vous n'avez pas de projet, créez-en un. Dans le menu principal, développez Projets, puis cliquez sur Tous les projets.
Cliquez sur Nouveau projet.
Nommez le projet, puis ajoutez éventuellement une description.
Pour plus d'informations sur les options de projet, telles que la génération de rapports ou la consignation, voir Création d'un projet.
Cliquez sur Créer.
Avant de commencer
Prenez des décisions concernant les options de réglage suivantes :
- Trouvez le foundation model qui convient le mieux à votre cas d'utilisation. Voir Choix d'un foundation model à accorder.
- Créez un ensemble d'exemples d'invites qui suivent le modèle qui génère les meilleurs résultats en fonction de votre travail d'ingénierie d'invite. Voir Formats de données.
Mise au point d'un foundation model
Sur la page d'accueil dewatsonx.ai, choisissez votre projet, puis cliquez sur New asset > Tune a foundation model with labeled data.
Nommez l'expérimentation d'optimisation.
Facultatif: ajoutez une description et des balises. Ajoutez une description pour vous rappeler et aider les collaborateurs à comprendre l'objectif du modèle optimisé. L'affectation d'une étiquette vous permet de filtrer vos actifs d'optimisation ultérieurement pour afficher uniquement les actifs associés à une étiquette.
Cliquez sur Créer.
Cliquez sur Sélectionner un foundation model pour choisir le foundation model que vous souhaitez accorder.
Cliquez sur une tuile pour afficher une carte de modèle contenant des détails sur le foundation model. Lorsque vous avez trouvé le foundation model que vous souhaitez utiliser, cliquez sur Sélectionner.
Pour plus d'informations, voir Choix d'un foundation model à mettre au point.
Choisissez le mode d'initialisation de l'invite parmi les options suivantes:
- Texte
- Utilise le texte que vous spécifiez.
- Aléatoire
- Utilise les valeurs qui sont générées pour vous dans le cadre de l'expérimentation d'optimisation.
Ces options sont liées à la méthode d'optimisation d'invite pour les modèles d'optimisation. Pour plus d'informations sur la façon dont chaque option affecte l'expérimentation d'optimisation, voir Fonctionnement de l'optimisation des invites.
Requis pour la méthode d'initialisation Texte uniquement: ajoutez le texte d'initialisation à inclure à l'invite.
- Pour une tâche de classification, donnez une instruction qui décrit ce que vous souhaitez classifier et répertorie les libellés de classe à utiliser. Par exemple, Classer si le sentiment de chaque commentaire est positif ou négatif.
- Pour une tâche générative, décrivez ce que le modèle doit fournir dans la sortie. Par exemple, Faites en sorte que les employés puissent travailler à domicile quelques jours par semaine.
- Pour une tâche de récapitulation, donnez une instruction telle que Récapituler les points principaux d'une retranscription de réunion.
Choisissez un type de tâche.
Choisissez le type de tâche qui correspond le plus à ce que vous souhaitez que le modèle fasse:
- Classification
- Prévoit les libellés catégoriels des fonctions. Par exemple, si vous utilisez un ensemble de commentaires client, vous souhaiterez peut-être étiqueter chaque instruction comme une question ou un problème. En séparant les problèmes des clients, vous pouvez les trouver et les résoudre plus rapidement. Ce type de tâche prend en charge la classification d'une seule étiquette.
- Génération
- Génère du texte. Par exemple, il écrit un e-mail promotionnel.
- Récapitulation
- Génère du texte qui décrit les principales idées exprimées dans un corps de texte. Par exemple, un résumé d'un document de recherche.
Quelle que soit la tâche choisie, l'entrée est soumise au foundation model sous-jacent en tant que type de demande générative au cours de l'expérience. Pour les tâches de classification, les noms de classe sont pris en compte dans les invites utilisées pour optimiser le modèle. Au fur et à mesure que les modèles et les méthodes d'optimisation évoluent, des améliorations spécifiques aux tâches sont susceptibles d'être ajoutées et vous pouvez les optimiser si les tâches sont représentées avec précision.
Nécessaire pour les tâches de classification uniquement : dans le champ Sortie de classification, ajoutez les étiquettes de classe que vous souhaitez que le modèle utilise une à la fois.
Important: indiquez les mêmes libellés que ceux utilisés dans vos données d'apprentissage.Au cours de l'expérimentation d'optimisation, les informations de libellé de classe sont soumises avec les exemples d'entrée des données d'apprentissage.
Ajoutez les données d'apprentissage qui seront utilisées pour optimiser le modèle. Vous pouvez télécharger un fichier ou utiliser un actif de votre projet.
Pour voir des exemples de mise en forme de votre fichier, développez A quoi doivent ressembler vos données?, puis cliquez sur Aperçu du modèle. Vous pouvez copier ou télécharger l'un des modèles de données pour y ajouter vos propres données.
Pour plus d'informations, voir Formats de données.
Facultatif: si vous souhaitez limiter la taille des exemples d'entrée ou de sortie utilisés lors de l'entraînement, ajustez le nombre maximal de jetons autorisés.
Développez A quoi doivent ressembler vos données?, puis faites défiler pour voir les zones Maximum input tokens et Maximum output tokens . Faites glisser les curseurs pour modifier les valeurs. La limitation de la taille peut réduire le temps nécessaire à l'exécution de l'expérimentation d'optimisation. Pour plus d'informations, voir Contrôle du nombre de jetons utilisés.
Facultatif: cliquez sur Configurer les paramètres pour éditer les paramètres utilisés par l'expérimentation d'optimisation.
L'exécution de l'ajustement est configurée avec des valeurs de paramètre qui représentent un bon point de départ pour l'ajustement d'un modèle. Vous pouvez les ajuster si vous le souhaitez.
Pour plus d'informations sur les paramètres disponibles et leur fonction, voir Paramètres d'optimisation.
Après avoir modifié les valeurs de paramètre, cliquez sur Sauvegarder.
Cliquez sur Démarrer l'optimisation.
L'expérimentation d'optimisation commence. Cette opération peut prendre de quelques minutes à quelques heures en fonction de la taille de vos données d'entraînement et de la disponibilité des ressources de calcul. Lorsque l'expérimentation est terminée, le statut indique qu'elle est terminée.
Un actif de modèle optimisé n'est créé qu'après la création d'un déploiement à partir d'une expérimentation d'optimisation terminée. Pour plus d'informations, voir Déploiement d'un modèle optimisé.
Contrôle du nombre de jetons utilisés
Pour les modèles en langage naturel, les mots sont convertis en jetons. 256 jetons sont égaux à environ 130-170 mots. 128 jetons est égal à environ 65-85 mots. Cependant, les nombres de jetons sont difficiles à estimer et peuvent différer selon le modèle. Pour plus d'informations, voir Tokens and tokenization.
Vous pouvez modifier le nombre de jetons autorisés dans l'entrée et la sortie du modèle au cours d'une expérience de réglage de l'invite.
| Nom du paramètre : | Valeur par défaut | Options de valeur | Options de valeur pour flan-t5-xl-3b uniquement |
|---|---|---|---|
| Nombre maximal de jetons d'entrée | 256 | 1 à 1024 | 1 à 256 |
| Nombre maximal de jetons de sortie | 128 | 1 à 512 | 1 à 128 |
Plus le nombre de jetons d'entrée et de sortie autorisés est élevé, plus l'optimisation du modèle prend du temps. Utilisez le plus petit nombre de jetons dans vos exemples qui est possible d'utiliser mais qui représente tout de même votre cas d'utilisation correctement.
Vous disposez déjà d'un certain contrôle sur la taille d'entrée. Le texte d'entrée utilisé lors d'une expérimentation d'optimisation provient de vos données d'apprentissage. Ainsi, vous pouvez gérer la taille d'entrée en conservant vos exemples d'entrée à une longueur définie. Toutefois, vous pouvez obtenir des données d'entraînement non traitées d'une autre équipe ou d'un autre processus. Dans ce cas, vous pouvez utiliser le curseur Maximum input tokens pour gérer la taille d'entrée. Si vous définissez le paramètre sur 200 et que les données d'apprentissage ont un exemple d'entrée avec 1000 jetons, par exemple, l'exemple est tronqué. Seuls les 200 premiers jetons de l'exemple d'entrée sont utilisés.
La valeur Max output tokens est importante car elle contrôle le nombre de jetons que le modèle est autorisé à générer en tant que sortie lors de l'apprentissage. Vous pouvez utiliser le curseur pour limiter la taille de la sortie, ce qui aide le modèle à générer une sortie concise.
Evaluation de l'expérimentation d'optimisation
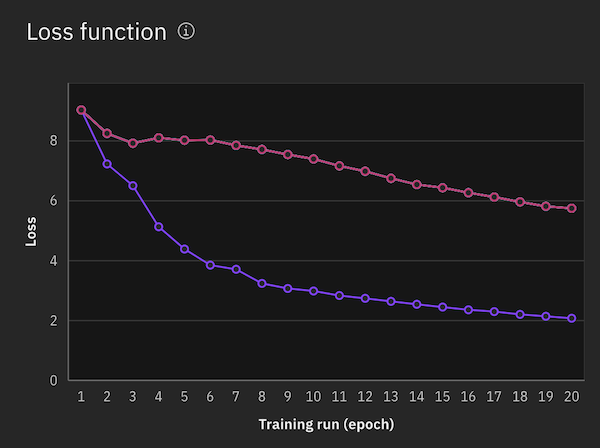
Une fois l'expérimentation terminée, un graphique de fonction de perte s'affiche pour illustrer l'amélioration de la sortie du modèle dans le temps. Les époques sont représentées sur l'axe des abscisses et une mesure de la différence entre les résultats prévus et les résultats réels par époque est représentée sur l'axe des ordonnées. La valeur affichée par époque est calculée à partir de la valeur de gradient moyenne de toutes les étapes d'accumulation de l'époque.
Pour plus d'informations sur l'évaluation des résultats, voir Evaluation des résultats d'une expérimentation d'optimisation.
Lorsque vous êtes satisfait des résultats de l'expérience de réglage, déployez le foundation model réglé. Pour plus d'informations, voir Déploiement d'un modèle optimisé.
Réexécution d'une expérimentation d'optimisation
Pour réexécuter une expérimentation d'optimisation, procédez comme suit:
- Dans la page Actifs du projet, filtrez vos actifs en fonction du type d'actif Expériences d'optimisation .
- Recherchez et ouvrez votre actif d'expérimentation d'optimisation, puis cliquez sur Nouveau modèle optimisé.
La fonction de perte pour l'expérimentation d'optimisation est affichée dans le même graphique avec les fonctions de perte des exécutions précédentes afin que vous puissiez les comparer.
En savoir plus
- Déploiement d'un modèle optimisé
- Démarrage rapide : Ajuster un foundation model
- Exemple de cahier : Ajuster un modèle pour classer les documents du CFPB dans watsonx
- Exemple de cahier : Réglage de l'invite pour la classification multi-classe avec watsonx
Sujet parent : Tuning Studio