Um ein foundation model abzustimmen, erstellen Sie ein Abstimmungsexperiment, das das foundation model anleitet, die gewünschte Ausgabe in der gewünschten Form zu liefern.
Anforderungen
Das Tuning Studio ist nicht bei allen Tarifen oder in allen Rechenzentren verfügbar. Die für das Tuning im Tuning Studio zur Verfügung stehenden Fundamentmodelle können sich auch je nach Rechenzentrum unterscheiden. Weitere Informationen finden Sie unter watsonx.ai Runtime-Pläne und regionale Verfügbarkeit für Dienste und Funktionen.
Normalerweise ist das Tuning Studio über ein Projekt verfügbar, das automatisch für Sie erstellt wird, wenn Sie sich bei watsonx.ai anmelden. Das Projekt hat den Namen sandbox und Sie können es als Einstieg in das Testen und Anpassen von Basismodellen verwenden.
Wenn Sie kein Projekt haben, erstellen Sie eines. Erweitern Sie im Hauptmenü Projekteund klicken Sie dann auf Alle Projekte.
Klicken Sie auf Neues Projekt.
Benennen Sie das Projekt und fügen Sie optional eine Beschreibung hinzu.
Weitere Informationen zu Projektoptionen wie Berichterstellung oder Protokollierung finden Sie unter Projekt erstellen.
Klicken Sie auf Erstellen.
Vorbereitende Schritte
Treffen Sie Entscheidungen über die folgenden Tuning-Optionen:
- Finden Sie das foundation model, das für Ihren Anwendungsfall am besten geeignet ist. Siehe Auswahl eines foundation model zum Abstimmen.
- Erstellen Sie eine Gruppe von Beispieleingabeaufforderungen, die dem Muster folgen, das die besten Ergebnisse auf der Basis Ihrer Eingabeaufforderungsentwicklungsarbeit generiert. Siehe Datenformate.
Abstimmen eines foundation model
Wählen Sie auf der Homepage watsonx.ai Ihr Projekt aus und klicken Sie dann auf Neues Asset > Ein foundation model mit beschrifteten Daten optimieren .
Benennen Sie das Optimierungsexperiment.
Optional: Fügen Sie eine Beschreibung und Tags hinzu. Fügen Sie eine Beschreibung als Erinnerung an sich selbst hinzu und helfen Sie Mitarbeitern, das Ziel des optimierten Modells zu verstehen. Durch das Zuweisen eines Tags können Sie Ihre Optimierungsassets später filtern, sodass nur die Assets angezeigt werden, die einem Tag zugeordnet sind.
Klicken Sie auf Erstellen.
Klicken Sie auf foundation model auswählen, um das foundation model auszuwählen, das Sie abstimmen möchten.
Klicken Sie auf eine Kachel, um eine Modellkarte mit Einzelheiten über das foundation model anzuzeigen. Wenn Sie das gewünschte foundation model gefunden haben, klicken Sie auf Auswählen.
Weitere Informationen finden Sie unter Auswahl eines zu optimierenden foundation model.
Wählen Sie aus den folgenden Optionen aus, wie die Eingabeaufforderung initialisiert werden soll:
- Text
- Verwendet von Ihnen angegebenen Text.
- Beliebig
- Verwendet Werte, die im Rahmen des Optimierungsexperiments generiert werden.
Diese Optionen beziehen sich auf die Eingabeaufforderungsoptimierungsmethode für Optimierungsmodelle. Weitere Informationen zu den Auswirkungen der einzelnen Optionen auf das Optimierungsexperiment finden Sie unter Funktionsweise der Eingabeaufforderungsoptimierung.
Nur für die Initialisierungsmethode Text erforderlich: Fügen Sie den Initialisierungstext hinzu, den Sie in die Eingabeaufforderung einschließen möchten.
- Geben Sie für eine Klassifikationsaufgabe eine Anweisung an, die beschreibt, was Sie klassifizieren möchten, und listet die zu verwendenden Klassenbezeichnungen auf. Beispiel: Klassifizieren Sie, ob die Stimmung jedes Kommentars positiv oder negativ ist
- Beschreiben Sie bei einer generativen Task, was das Modell in der Ausgabe bereitstellen soll. Beispiel: Geben Sie an, dass Mitarbeiter einige Tage in der Woche von zu Hause aus arbeiten können.
- Geben Sie für eine Zusammenfassungstask eine Anweisung wie die folgende: Hauptpunkte aus einer Besprechungsmitschrift zusammenfassen.
Wählen Sie einen Tasktyp aus.
Wählen Sie den Tasktyp aus, der den Aufgaben des Modells am ehesten entspricht:
- Klassifizierung
- Sagt kategoriale Beschriftungen aus Merkmalen voraus. Beispiel: Bei einer Gruppe von Kundenkommentaren können Sie jede Anweisung als Frage oder Problem beschriften. Durch die Trennung von Kundenproblemen können Sie diese schneller finden und beheben. Dieser Aufgabentyp dient der Einzellabel-Klassifikation.
- Generierung
- Generiert Text. Schreibt beispielsweise eine Werbe-E-Mail.
- Zusammenfassung
- Generiert Text, der die Hauptideen beschreibt, die in einem Textkörper ausgedrückt werden. Fasst beispielsweise ein Forschungspapier zusammen.
Unabhängig davon, für welche Aufgabe Sie sich entscheiden, wird die Eingabe während des Experiments als generativer Anfragetyp an das zugrunde liegende foundation model übermittelt. Bei Klassifizierungstasks werden Klassennamen in den Eingabeaufforderungen zur Optimierung des Modells berücksichtigt. Bei der Weiterentwicklung von Modellen und Optimierungsmethoden werden wahrscheinlich taskspezifische Erweiterungen hinzugefügt, die Sie nutzen können, wenn Tasks korrekt dargestellt werden.
Nur für Klassifizierungsaufgaben erforderlich: Fügen Sie in das Feld Klassifizierungsausgabe die Klassenbezeichnungen ein, die das Modell nacheinander verwenden soll.
Wichtig: Geben Sie dieselben Beschriftungen an, die auch in Ihren Trainingsdaten verwendet werden.Während des Optimierungsexperiments werden Klassenbeschriftungsinformationen zusammen mit den Eingabebeispielen aus den Trainingsdaten übergeben.
Fügen Sie die Trainingsdaten hinzu, die zum Optimieren des Modells verwendet werden. Sie können eine Datei hochladen oder ein Asset aus Ihrem Projekt verwenden.
Um Beispiele für die Formatierung Ihrer Datei anzuzeigen, erweitern Sie Wie sollen Ihre Daten aussehen?, Klicken Sie anschließend auf Vorlage voranzeigen. Sie können eine der Datenvorlagen kopieren oder herunterladen, um sie mit Ihren eigenen Daten zu füllen.
Weitere Informationen finden Sie unter Datenformate.
Optional: Wenn Sie die Größe der Ein-oder Ausgabebeispiele begrenzen möchten, die während des Trainings verwendet werden, passen Sie die maximale Anzahl zulässiger Tokens an.
Erweitern Sie Wie sollen Ihre Daten aussehen?, Blättern Sie anschließend, um die Felder Maximum input tokens und Maximum output tokens anzuzeigen. Ziehen Sie die Schieberegler, um die Werte zu ändern. Das Begrenzen der Größe kann die Zeit verringern, die zum Ausführen des Optimierungsexperiments erforderlich ist. Weitere Informationen finden Sie unter Anzahl der verwendeten Tokens steuern.
Optional: Klicken Sie auf Parameter konfigurieren , um die vom Optimierungsexperiment verwendeten Parameter zu bearbeiten.
Der Optimierungslauf wird mit Parameterwerten konfiguriert, die einen guten Ausgangspunkt für die Optimierung eines Modells darstellen. Sie können sie bei Bedarf anpassen.
Weitere Informationen zu den verfügbaren Parametern und ihren Funktionen finden Sie unter Parameter optimieren.
Klicken Sie nach der Änderung der Parameterwerte auf Speichern.
Klicken Sie auf Optimierung starten.
Das Optimierungsexperiment beginnt. Je nach Größe Ihrer Trainingsdaten und Verfügbarkeit von Rechenressourcen kann es einige Minuten bis zu einigen Stunden dauern. Wenn das Experiment abgeschlossen ist, wird der Status als abgeschlossen angezeigt.
Ein optimiertes Modellasset wird erst erstellt, wenn Sie eine Bereitstellung aus einem abgeschlossenen Optimierungsexperiment erstellt haben. Weitere Informationen finden Sie unter Optimiertes Modell bereitstellen.
Anzahl der verwendeten Tokens steuern
Bei Modellen mit natürlicher Sprache werden Wörter in Tokens konvertiert. 256 Token entsprechen ungefähr 130-170 Wörtern. 128 Token entsprechen ungefähr 65 bis 85 Wörtern. Tokenzahlen sind jedoch schwer zu schätzen und können je nach Modell unterschiedlich sein. Weitere Informationen finden Sie unter Tokens und Zerlegung in Tokens.
Sie können die Anzahl der Token ändern, die in der Modelleingabe und -ausgabe während eines Prompt-Tuning-Experiments erlaubt sind.
| Parametername | Standardwert | Wertoptionen | Wertoptionen nur für flan-t5-xl-3b |
|---|---|---|---|
| Maximale Anzahl Eingabetoken | 256 | 1-1024 | 1-256 |
| Maximale Anzahl Ausgabetoken | 128 | 1-512 | 1-128 |
Je größer die Anzahl der zulässigen Eingabe-und Ausgabetoken ist, desto länger dauert die Optimierung des Modells. Verwenden Sie die kleinste Anzahl von Tokens in Ihren Beispielen, die verwendet werden können, aber dennoch Ihren Anwendungsfall korrekt darstellen.
Sie haben bereits eine gewisse Kontrolle über die Eingabegröße. Der bei einem Optimierungsexperiment verwendete Eingabetext stammt aus Ihren Trainingsdaten. Sie können also die Eingabegröße verwalten, indem Sie Ihre Beispieleingaben auf eine festgelegte Länge setzen. Möglicherweise erhalten Sie jedoch nicht kuratierte Trainingsdaten von einem anderen Team oder Prozess. In diesem Fall können Sie den Schieberegler Maximale Eingabetoken verwenden, um die Eingabegröße zu verwalten. Wenn Sie den Parameter auf 200 setzen und die Trainingsdaten beispielsweise eine Beispieleingabe mit 1.000 Tokens enthalten, wird das Beispiel abgeschnitten. Nur die ersten 200 Token der Beispieleingabe werden verwendet.
Der Wert Max. Ausgabetoken ist wichtig, da er die Anzahl der Token steuert, die das Modell zur Trainingszeit als Ausgabe generieren darf. Sie können den Schieberegler verwenden, um die Ausgabegröße zu begrenzen. Dies hilft dem Modell, eine kompakte Ausgabe zu generieren.
Optimierungsexperiment auswerten
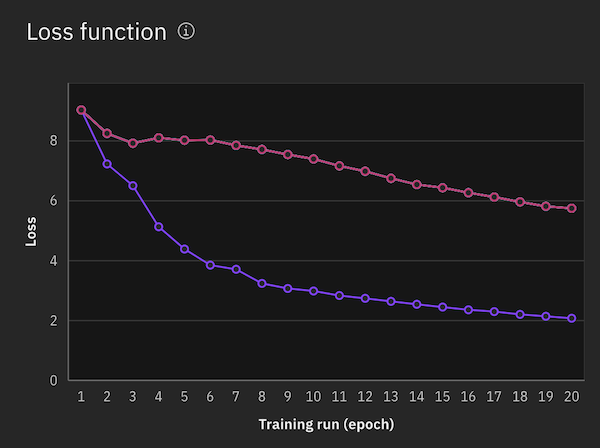
Nach Abschluss des Experiments wird ein Verlustfunktionsdiagramm angezeigt, das die Verbesserung der Modellausgabe im Zeitverlauf veranschaulicht. Die Epochen werden auf der X-Achse und ein Maß für die Differenz zwischen den vorhergesagten und den tatsächlichen Ergebnissen pro Epoche auf der Y-Achse angezeigt. Der pro Epoche angezeigte Wert wird aus dem durchschnittlichen Gradientenwert aus allen Akkumulationsschritten in der Epoche berechnet.
Weitere Informationen zur Auswertung der Ergebnisse finden Sie unter Ergebnisse eines Optimierungsexperiments auswerten.
Wenn Sie mit den Ergebnissen des Abstimmungsexperiments zufrieden sind, setzen Sie das abgestimmte foundation model ein. Weitere Informationen finden Sie unter Optimiertes Modell bereitstellen.
Optimierungsexperiment erneut ausführen
Führen Sie die folgenden Schritte aus, um ein Optimierungsexperiment erneut auszuführen:
- Filtern Sie auf der Seite Assets des Projekts Ihre Assets nach dem Assettyp Optimierungsexperimente .
- Suchen und öffnen Sie Ihr Optimierungsexperimentasset und klicken Sie anschließend auf Neues optimiertes Modell.
Die Verlustfunktion für das Optimierungsexperiment wird in demselben Diagramm mit Verlustfunktionen aus früheren Ausführungen angezeigt, sodass Sie sie vergleichen können.
Weitere Informationen
- Optimiertes Modell bereitstellen
- Schnellstart: Abstimmen eines foundation model
- Beispiel-Notebook: Optimieren Sie ein Modell zur Klassifizierung von CFPB-Dokumenten in watsonx
- Beispiel-Notebook: Prompte Abstimmung für Mehrklassenklassifizierung mit watsonx
Übergeordnetes Thema: Tuning Studio