To prompt tune a foundation model, create a tuning experiment that guides the foundation model to return the output you want in the form you want.
Requirements
The Tuning Studio is not available with all plans or in all data centers. The foundation models that are available for tuning in the Tuning Studio can also differ by data center. For more information, see watsonx.ai Runtime plans and Regional availability for services and features.
Typically, the Tuning Studio is available from a project that is created for you automatically when you sign up for watsonx.ai. The project is named sandbox and you can use it to get started with testing and customizing foundation models.
If you don't have a project, create one. From the main menu, expand Projects, and then click All projects.
-
Click New project.
-
Name the project, and then optionally add a description.
For more information about project options, such as reporting or logging, see Creating a project.
-
Click Create.
Before you begin
Make decisions about the following tuning options:
- Find the foundation model that works best for your use case. See Choosing a foundation model to tune.
- Create a set of example prompts that follow the pattern that generates the best results based on your prompt engineering work. See Data formats.
Tune a foundation model
From the watsonx.ai home page, choose your project, and then click New asset > Tune a foundation model with labeled data.
-
Name the tuning experiment.
-
Optional: Add a description and tags. Add a description as a reminder to yourself and to help collaborators understand the goal of the tuned model. Assigning a tag gives you a way to filter your tuning assets later to show only the assets associated with a tag.
-
Click Create.
-
Click Select a foundation model to choose the foundation model that you want to tune.
Click a tile to see a model card with details about the foundation model. When you find the foundation model that you want to use, click Select.
For more information, see Choosing a foundation model to tune.
-
Choose how to initialize the prompt from the following options:
- Text
- Uses text that you specify.
- Random
- Uses values that are generated for you as part of the tuning experiment.
These options are related to the prompt tuning method for tuning models. For more information about how each option affects the tuning experiment, see How prompt tuning works.
-
Required for the Text initialization method only: Add the initialization text that you want to include with the prompt.
- For a classification task, give an instruction that describes what you want to classify and lists the class labels to be used. For example, Classify whether the sentiment of each comment is Positive or Negative.
- For a generative task, describe what you want the model to provide in the output. For example, Make the case for allowing employees to work from home a few days a week.
- For a summarization task, give an instruction such as, Summarize the main points from a meeting transcript.
-
Choose a task type.
Choose the task type that most closely matches what you want the model to do:
- Classification
- Predicts categorical labels from features. For example, given a set of customer comments, you might want to label each statement as a question or a problem. By separating out customer problems, you can find and address them more quickly. This task type handles single-label classification.
- Generation
- Generates text. For example, writes a promotional email.
- Summarization
- Generates text that describes the main ideas that are expressed in a body of text. For example, summarizes a research paper.
Whichever task you choose, the input is submitted to the underlying foundation model as a generative request type during the experiment. For classification tasks, class names are taken into account in the prompts that are used to tune the model. As models and tuning methods evolve, task-specific enhancements are likely to be added that you can leverage if tasks are represented accurately.
-
Required for classification tasks only: In the Classification output field, add the class labels that you want the model to use one at a time.
Important: Specify the same labels that are used in your training data.During the tuning experiment, class label information is submitted along with the input examples from the training data.
-
Add the training data that will be used to tune the model. You can upload a file or use an asset from your project.
To see examples of how to format your file, expand What should your data look like?, and then click Preview template. You can copy or download one of the data templates to populate with your own data.
For more information, see Data formats.
-
Optional: If you want to limit the size of the input or output examples that are used during training, adjust the maximum number of tokens that are allowed.
Expand What should your data look like?, and then scroll to see the Maximum input tokens and Maximum output tokens fields. Drag the sliders to change the values. Limiting the size can reduce the time that it takes to run the tuning experiment. For more information, see Controlling the number of tokens used.
-
Optional: Click Configure parameters to edit the parameters that are used by the tuning experiment.
The tuning run is configured with parameter values that represent a good starting point for tuning a model. You can adjust them if you want.
For more information about the available parameters and what they do, see Tuning parameters.
After you change parameter values, click Save.
-
Click Start tuning.
The tuning experiment begins. It might take a few minutes to a few hours depending on the size of your training data and the availability of compute resources. When the experiment is finished, the status shows as completed.
A tuned model asset is not created until after you create a deployment from a completed tuning experiment. For more information, see Deploying a tuned model.
Controlling the number of tokens used
For natural language models, words are converted to tokens. 256 tokens is equal to approximately 130—170 words. 128 tokens is equal to approximately 65—85 words. However, token numbers are difficult to estimate and can differ by model. For more information, see Tokens and tokenization.
You can change the number of tokens that are allowed in the model input and output during a prompt-tuning experiment.
| Parameter name | Default value | Value options | Value options for flan-t5-xl-3b only |
|---|---|---|---|
| Maximum input tokens | 256 | 1–1024 | 1–256 |
| Maximum output tokens | 128 | 1–512 | 1–128 |
The larger the number of allowed input and output tokens, the longer it takes to tune the model. Use the smallest number of tokens in your examples that is possible to use but still represent your use case properly.
You already have some control over the input size. The input text that is used during a tuning experiment comes from your training data. So, you can manage the input size by keeping your example inputs to a set length. However, you might be getting uncurated training data from another team or process. In that case, you can use the Maximum input tokens slider to manage the input size. If you set the parameter to 200 and the training data has an example input with 1,000 tokens, for example, the example is truncated. Only the first 200 tokens of the example input are used.
The Max output tokens value is important because it controls the number of tokens that the model is allowed to generate as output at training time. You can use the slider to limit the output size, which helps the model to generate concise output.
Evaluating the tuning experiment
When the experiment is finished, a loss function graph is displayed that illustrates the improvement in the model output over time. The epochs are shown on the x-axis and a measure of the difference between predicted and actual results per epoch is shown on the y-axis. The value that is shown per epoch is calculated from the average gradient value from all of the accumulation steps in the epoch.
For more information about how to evaluate the results, see Evaluating the results of a tuning experiment.
When you are satisfied with the tuning experiment results, deploy the tuned foundation model. For more information, see Deploying a tuned model.
Running a tuning experiment again
To rerun a tuning experiment, complete the following steps:
- From the project's Assets page, filter your assets by the Tuning experiments asset type.
- Find and open your tuning experiment asset, and then click New tuned model.
The loss function for the tuning experiment is shown in the same graph with loss functions from previous runs so that you can compare them.
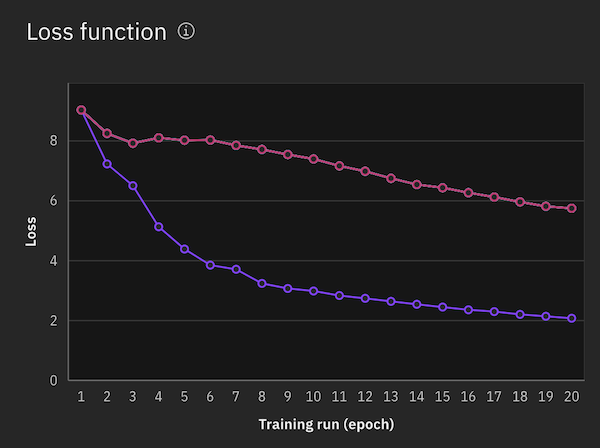
In addition to the tuned foundation model asset, the tuning experiment itself is saved as an asset. If the results from an earlier run of the experiment are better than a later run, you can return to the earlier experiment run and use the resulting model asset to create a new tuned model deployment.
Learn more
- Deploying a tuned model
- Quick start: Tune a foundation model
- Sample notebook: Tune a model to classify CFPB documents in watsonx
- Sample notebook: Prompt tuning for multi-class classification with watsonx
Parent topic: Tuning Studio