IBM slate-30m-english-rtrvr-v2 modello di scheda
Versione 2.0.1 Data: 30/06/2024
Descrizione modello
Il modello slate.30m.english.rtrvr è un modello di trasformazione di frasi standard basato su bi-encoder. Il modello produce un embedding per un dato input, ad esempio una query, un passaggio, un documento ecc. Ad alto livello, il nostro modello viene addestrato per massimizzare la somiglianza del coseno tra due testi in ingresso, ad esempio il testo A (testo di interrogazione) e il testo B (testo di passaggio), che risultano nelle incorporazioni di frasi q e p. Queste incorporazioni di frasi possono poi essere confrontate utilizzando la similarità del coseno.
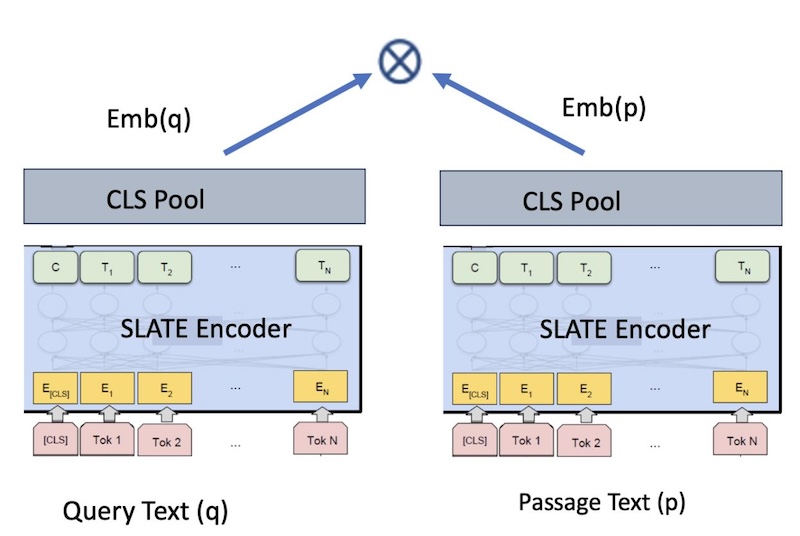
Figura 1. Modello di incorporazioni bi-encoder per il recupero
Modello linguistico di base
Il modello linguistico (LM) sottostante per le nostre incorporazioni è “slate.30m.english”. Ha la stessa architettura di un modello di trasformatore small-RoBERTa (6 strati) e ha ~30 milioni di parametri e una dimensione di incorporazione di 384. In particolare, “slate.30m.english” è stato distillato da “slate.125m.english” (precedentemente, WatBERT). Il nostro modello finale si chiama slate.30m.english.rtrvr. Si noti il suffisso alla fine che indica la messa a punto dell'architettura del modello sottostante per i compiti basati sul reperimento.
Algoritmo di formazione
La maggior parte dei modelli di incorporamento all'avanguardia o in cima alla classifica MTEB vengono in genere addestrati in 3 fasi:
- Pre-training specifico per il compito (basato sul recupero)
- Messa a punto specifica del compito sulle coppie estratte
- Messa a punto delle coppie supervisionate. Seguiamo un approccio simile, combinando le due fasi finali in un'unica fase di messa a punto.
slate.30m.english.rtrvr è prodotto distillando dal modello “slate.125m.english.rtrvr-06-30-2024” nella fase di messa a punto (i dettagli del modello di insegnante più grande sono disponibili a questo indirizzo). La distillazione della conoscenza trasferisce la conoscenza da un modello insegnante ad alte prestazioni in un modello studente più piccolo, addestrando la distribuzione di probabilità di uscita dello studente a corrispondere il più possibile a quella dell'insegnante, migliorando le prestazioni dello studente rispetto alla messa a punto autonoma.
Preformazione specifica per il compito
Questa fase utilizza il framework RetroMAE per rendere il nostro LM sottostante maggiormente orientato al recupero. Inizializziamo la nostra LM di base con “slate.30m.english” e continuiamo con il pre-training RetroMAE, utilizzando i dati della Tabella 1. Qui, invece di usare solo le etichette dei dati, distilliamo anche le previsioni del codificatore RetroMAE usato da slate.125m.english.rtrvr. I nostri iper-parametri sono: tasso di apprendimento: 2e-5, numero di passi: 435000, GPU: 8 A100 (80GB) GPU.
Nota: questa è la nostra LM di base per le 2 fasi successive.
Distillazione con coppie non supervisionate e supervisionate
Per l'addestramento di un modello di embedding utilizziamo un framework bi-encoder, come nella Figura 1. Inizializziamo con il modello pre-addestrato RetroMAE e impieghiamo ulteriormente la Distillazione della conoscenza con <coppie di testo query, passage> utilizzando un obiettivo contrastive loss con negatività in-batch. La Distillazione della Conoscenza addestra la distribuzione di probabilità di uscita dello studente in modo che corrisponda il più possibile a quella dell'insegnante. Nel contesto dei modelli retriever, la distribuzione di output è costituita dai punteggi di somiglianza tra coppie di testi. In particolare, per ogni coppia di frasi < query, passage>, la distribuzione dei punteggi dell'insegnante tra le incorporazioni di query e passage, cioè la somiglianza del coseno tra le incorporazioni, viene distillata nello studente.
L'insegnante utilizzato per la distillazione è il modello "slate.125m.english.rtrvr” addestrato sugli stessi dati menzionati di seguito. Il modello insegnante è stato addestrato utilizzando un paradigma a più stadi in cui un modello RetroMAE preaddestrato ha visto dati non supervisionati nella fase di preaddestramento ed è stato poi perfezionato su dati più puliti, estratti o etichettati in oro per alcune centinaia di passi. Per garantire la robustezza tra i vari set di dati, questo modello perfezionato è stato poi fuso con un altro modello addestrato con iperparametri diversi sugli stessi dati. Per ulteriori dettagli, consultare la scheda modello slate.125m.english.rtrvr.
Il flusso di trasferimento delle conoscenze è illustrato nella Figura 2.
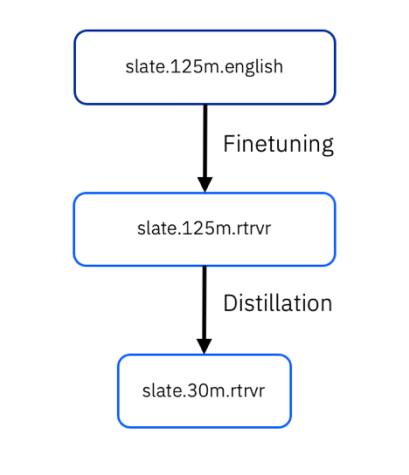
Figura 2. Distillazione della conoscenza
Abbiamo estratto coppie su larga scala da vari domini, come indicato nella sezione Dati di formazione. Inoltre, includiamo anche coppie di alta qualità per il compito di recupero sui seguenti set di dati: SQuAD, Natural Questions, Specter, Stack Exchange (Title, Body), S2ORC, SearchQA, HotpotQA, Fever e Miracl. Per questi set di dati supervisionati, includiamo anche gli Hard Negative estratti con una versione precedente del modello slate.125m.english.rtrvr. Inoltre, generiamo sinteticamente le triple per creare coppie di buona qualità di domande-risposte, verifica dei fatti, ecc. utilizzando `Mixtral-8x7B-Instruct-v0.1`. Per fornire prestazioni migliori per i casi d'uso specifici di IBM, includiamo anche coppie create da dati di IBM Software Support e IBM Docs.
Gli iperparametri di distillazione sono: apprendimento rate:7e-4, numero di passi: 500000, dimensione effettiva del batch: 2048, GPU: 4 GPU A100_80GB.
Dati di formazione
| Dataset | Passages |
|---|---|
| Wikipedia | 36396918 |
| Corpus di libri | 3401308 |
| Stack Exchange | 15999837 |
| Dataset | Coppie |
|---|---|
| Tripletta di citazioni SPECTER | 684100 |
| Stack Exchange Domande duplicate (titoli) | 304525 |
| Stack Exchange Domande duplicate (corpi) | 250519 |
| Stack Exchange Domande duplicate (titoli+corpi) | 250460 |
| Domande naturali (NQ) | 100231 |
| SQuAD2.0 | 87599 |
| Coppie PAQ (domanda, risposta) | 64371441 |
| Scambio di coppie (Titolo, Risposta) | 4067139 |
| Coppie di scambio (titolo, corpo) | 23978013 |
| Scambio di coppie (Titolo+Corpo, Risposta) | 187195 |
| S2ORC Coppie di citazioni (titoli) | 52603982 |
| S2ORC (Titolo, Abstract) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers Coppie di domande duplicate | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| Febbre | 109810 |
| Arxiv | 2358545 |
| Wikipedia | 20745403 |
| PubMed | 20000000 |
| Coppie Miracl En | 9016 |
| Coppie titolo-corpo DBPedia | 4635922 |
| Sintetico: Query-Passaggio di Wikipedia | 1879093 |
| Sintetico: Verifica dei fatti | 9888 |
| IBM: il supporto software triplica | 40290 |
| IBM: IBM Docs (Titolo-Corpo) | 474637 |
| IBM: IBM Supporto (Titolo-Corpo) | 1049949 |
Utilizzo
# make sure you’ve sentence transformers installed
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
' Who made the song My achy breaky heart? ',
'summit define']
input_passages = [
" Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991. ",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings))
La lunghezza massima della sequenza di questo modello è di 512 token.
Valutazione
Baseline
Per un confronto equo, ci confrontiamo con le seguenti linee di base:
BM25 (un modello tradizionale basato su tf-idf)
ELSER (un algoritmo di ricerca commerciale fornito da Elastic)
all-MiniLM-l6-v2: un popolare modello di trasformatori di frasi open-source. Questo modello condivide la stessa architettura di slate.30m.english.rtrvr, è stato addestrato su un maggior numero di dati senza licenze commerciali. Per maggiori dettagli, consultare la scheda modello Huggingface
E5-base: un recente modello di trasformatore open-source con ottime prestazioni nel benchmark BEIR. Si tratta di un modello di dimensioni base, che ha la stessa architettura di slate.125m.english.rtrvr. [Riferimento: Wang et.al.., 2022: Text Embeddings by Weakly-Supervised Contrastive Pre-training]. Modello di carta Huggingface
E5-small: un modello più piccolo della famiglia open source E5. La dimensione di incorporazione di questo modello corrisponde a quella di slate.30m.rtrvr (384), ma ha 12 strati e quindi è più grande e leggermente più lento. [Riferimento: Wang et.al.., 2022: Text Embeddings by Weakly-Supervised Contrastive Pre-training]. Modello di carta Huggingface
BGE-base: un recente modello di trasformatore open-source con una delle migliori prestazioni sul benchmark BEIR per la dimensione di incorporazione 768. Modello di carta Huggingface
BGE-small: un recente modello di trasformatore open-source con una delle migliori prestazioni sul benchmark BEIR per la dimensione di incorporazione 384. Modello di carta Huggingface
Confrontiamo inoltre le prestazioni di questi modelli con le versioni precedenti dei modelli slate, slate.125m.english.rtrvr-012024 e slate.30m.english.rtrvr-012024.
Il nostro benchmark di valutazione: BEIR ( scheda di recupero MTEB )
Il benchmark BEIR contiene 15 compiti di recupero open-source valutati in un'impostazione a zero colpi. Il BEIR si è concentrato sulla Diversità, includendo nove diversi compiti di recupero: Fact checking, citation prediction, duplicate question retrieval, argument retrieval, news retrieval, question answering, tweet retrieval, bio-medical IR e entity retrieval. Inoltre, include dataset provenienti da domini testuali diversi, dataset che coprono argomenti ampi (come Wikipedia) e argomenti specialistici (come le pubblicazioni COVID-19), diversi tipi di testo (articoli di notizie vs. Tweets), dataset di varie dimensioni (3.6k - 15M documenti) e dataset con diverse lunghezze di query (lunghezza media della query tra 3 e 192 parole) e di documenti (lunghezza media del documento tra 11 e 635 parole). Per la valutazione, BEIR utilizza la metrica Normalized Cumulative Discount Gain (in particolare, nDCG@10).
Lungo NQ
Long NQ è un set di dati IBM progettato per valutare l'intera pipeline RAG, basato su un sottoinsieme del set di dati NaturalQuestions. Il dev set è composto da 300 domande a risposta libera con un corpus di 178.891 passaggi da 2.345 documenti di Wikipedia. Long NQ fornisce anche i passaggi di Wikipedia oro che sono rilevanti per ogni domanda. Durante il recupero, il compito è quello di ottenere il passaggio aureo rilevante dal corpus per ogni domanda.
Risultati
| Modello | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| ELSER | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES-small-v2 | 49.04 |
| ES-base-v2 | 50.29 |
| BGE-piccolo | 51.68 |
| BGE-base | 53.25 |
| slate.30m.english.rtrvr 01.20.2024 | 46.91 |
| slate.125m.english.rtrvr-01.20.2024 | 49.37 |
| slate.30m.english.rtrvr 06.30.2024 | 49.06 |
| slate.125m.english.rtrvr-06.30.2024 | 51.26 |

Figura 3 Confronto delle prestazioni sul benchmark BEIR (scheda di recupero MTEB)
| Modello | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| BGE-piccolo | 59.33 |
| BGE-base | 61.29 |
| ES-small-v2 | 61.88 |
| ES-base-v2 | 63.80 |
| slate.30m.english.rtrvr 01.20.2024 | 59.94 |
| slate.125m.english.rtrvr-01.20.2024 | 65.01 |
| slate.30m.english.rtrvr 06.30.2024 | 62.07 |
| slate.125m.english.rtrvr-06.30.2024 | 66.80 |

Figura 4. Confronto delle prestazioni sul set di dati Long NQ
Prestazioni in tempo reale
Il tempo di esecuzione delle prestazioni è stato misurato su un compito di re-ranking con 466 query. Per ogni query ri-arranchiamo i top-100 passaggi ottenuti da BM25 e riportiamo il tempo medio su tutte le query. La riorganizzazione è stata eseguita su una GPU A100_40GB.
| Modello | Tempo/query |
|---|---|
| all-miniLM-L6-v2 | 0.18 sec |
| E5-small | 0.33 sec |
| E5-base | 0.75 sec |
| BGE-piccolo | 0.34 sec |
| BGE-base | 0.75 sec |
| slate.125m.english.rtrvr | 0.71 sec |
| slate.30m.english.rtrvr | 0.20 sec |