IBM slate-30m-english-rtrvr 모델 카드
모델 설명
slate.30m.english.rtrvr 모델은 바이 인코더를 기반으로 하는 표준 문장 변환기 모델입니다. 모델은 지정된 입력 (예: 조회, 통과, 문서 등) 에 대한 임베드를 생성합니다. 상위 레벨에서, 모델은 텍스트 A (쿼리 텍스트) 및 텍스트 B (통과 텍스트) 와 같은 텍스트의 두 입력 부분 사이의 코사인 유사성을 최대화하도록 훈련되며, 이는 문장이 q및 p를 임베드하는 결과를 초래합니다. 그런 다음 코사인 유사성을 사용하여 이러한 문장 임베드를 비교할 수 있습니다.
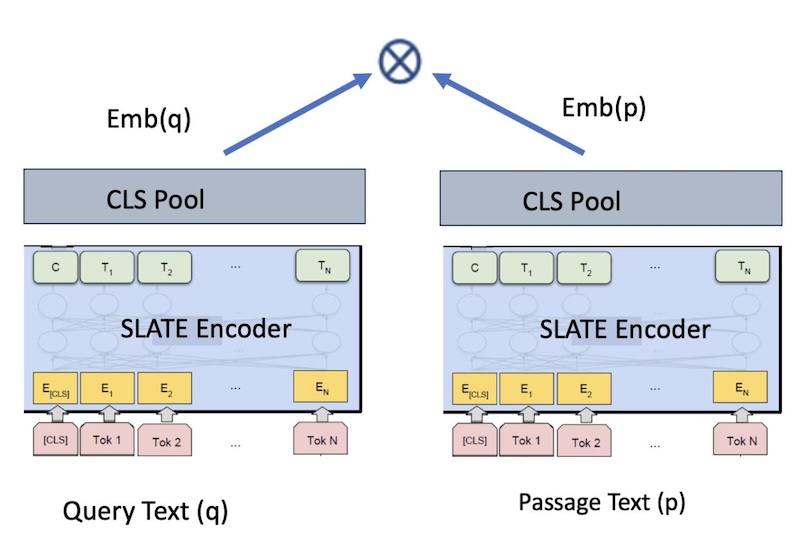
그림 1. 검색을 위한 이중 인코더 임베드 모델
기본 언어 모델
임베드에 대한 기본 언어 모델 (LM) 은 slate.30m.english입니다. small-RoBERTa 기본 변압기 모델(6층)과 동일한 아키텍처를 가지고 있으며 약 3천만 개의 파라미터와 384의 임베딩 치수를 가지고 있습니다. 특히 “slate.30m.english” 는 “slate.125m.english” (이전에는 WatBERT) 에서 추출되었습니다. 최종 모델의 이름은 “slate.30m.english.rtrvr” 입니다. 끝에 접미부가 표시되어 검색 기반 태스크에 대한 기본 모델 아키텍처를 미세 조정합니다.
훈련 알고리즘
최첨단 임베딩 모델 또는 MTEB 리더보드 상위권에 있는 대부분의 임베딩 모델은 일반적으로 3단계로 트레이닝을 받습니다:
- 태스크 특정 (검색 기반) 사전 훈련
- 마이닝된 쌍에 대한 태스크 특정 미세 조정
- 감독되는 쌍에 대한 미세 조정
마지막 두 단계를 하나의 미세 조정 단계로 결합하는 유사한 접근 방식을 따릅니다.
slate.30m.english.rtrvr 은 미세 조정 단계에서 “slate.125m.english.rtrvr” 모델을 추출하여 생성됩니다. 지식 증류는 학생의 출력 확률 분포가 교사의 출력 확률 분포와 가능한 근접하게 일치하도록 훈련하여 고성능 교사 모델에서 더 작은 학생 모델로 지식을 전달하여 독립형 세분화와 비교하여 학생의 성능을 향상시킵니다.
태스크 특정 사전 교육
이 단계에서는 RetroMAE 프레임워크를 사용하여 기본 LM을 보다 검색 지향적으로 만듭니다. slate.30m.english 를 사용하여 기본 LM을 초기화하고 표 1의 데이터를 사용하여 RetroMAE 사전 훈련을 계속합니다. 하이퍼 매개변수는 학습 비율: 2e-5, 단계 수: 435000, GPU: 8 A100 (80GB) GPU입니다. 참고: 이는 다음 두 단계에 대한 기본 LM입니다.
비통제형 및 통제형 쌍을 사용한 증류
그림 1과 같이 임베딩 모델을 훈련하기 위해 이중 인코더 프레임워크를 사용한다. RetroMAE 사전 훈련된 모델을 사용하여 초기화하고 배치 (in-batch) 부정이 있는 대비 손실 목표를 사용하여 <query, passage><query, passage>
증류에 사용되는 교사는 아래에 언급된 동일한 데이터에 대해 훈련된 "slate.125m.english.rtrvr” 모델입니다. 교사는 두 모델 간의 모델 융합을 사용하여 형성되며, 각 모델은 RetroMAE 사전 훈련 및 finetuning을 사용하지만 finetuning 데이터에서는 다릅니다. 자세한 정보는 slate.125m.english.rtrvr의 모델 카드를 참조하십시오. 지식 전달의 흐름은 도 2에 그림으로 도시되어 있다.

그림 2. 지식 증류
훈련 데이터 섹션에 표시된 대로 다양한 도메인에서 대규모 쌍을 마이닝합니다. 또한, 다음 데이터 세트에 대한 검색 작업을 위한 고품질 쌍도 포함되어 있습니다: SQuAD, 자연 질문, 스펙터, 스택 교환(제목, 본문) 쌍, S2ORC, SearchQA, HotpotQA 및 Fever입니다. 증류 하이퍼 매개변수는 학습 rate:7e-4, 단계 수: 400000, 유효 배치 크기: 2048, GPU: 2 A100_80GB GPU입니다.
훈련 데이터
| 데이터 세트 | 단락 |
|---|---|
| Wikipedia | 36396918 |
| 서적 코퍼스 | 3401308 |
| 스택 교환 | 15999837 |
| 데이터 세트 | 쌍 |
|---|---|
| SPECTER 인용 트리플렛 | 684100 |
| Stack Exchange 중복 질문 (제목) | 304525 |
| AllNLI (SNLI및 MultiNLI) | 277230 |
| Stack Exchange 중복 질문 (본문) | 250519 |
| 스택 교환 중복 질문 (제목+본문) | 250460 |
| 자연 질문 (NQ) | 100231 |
| SQuAD2.0 | 87599 |
| PAQ (질문, 응답) 쌍 | 64371441 |
| 스택 교환 (제목, 응답) 쌍 | 4067139 |
| 스택 교환 (제목, 본문) 쌍 | 23978013 |
| 스택 교환 (제목+본문, 응답) 쌍 | 187195 |
| S2ORC Citation쌍 (제목) | 52603982 |
| S2ORC (제목, 요약) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers 중복 질문 쌍 | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| 발열 | 109810 |
| 아르시브 | 2358545 |
| Wikipedia | 20745403 |
| PubMed | 20000000 |
사용량
# Make sure the sentence transformers is installed.
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
'Who made the son My achy breaky heart ?',
'summit define']
input_passages = [
"Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings))
이 모델의 최대 시퀀스 길이는 512개의 토큰입니다.
평가
기준선
공정한 비교를 위해 다음 기준선과 비교합니다.
- BM25 (tf-idf를 기반으로 하는 기존 모델).
- ELSER (Elastic에서 제공하는 상업적 검색 알고리즘).
- all-MiniLM-l6-v2: 널리 사용되는 오픈 소스 문장 변환기 모델입니다. 이 모델은 더 작은 임베드 차원 (384) 으로 slate.125m.english.rtvr과 동일한 아키텍처를 공유하며 상업용 라이센스 없이 더 많은 데이터에 대해 훈련되었습니다. 자세한 내용은 Hugging Face 모델 카드https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 참조하세요.
- E5-base: BEIR 벤치마크에서 매우 우수한 성능을 가진 최신 개방형 소스 변환기 모델입니다. 이 모델은 slate.125m.english.rtvr과 아키텍처가 동일한 기본 크기 모델입니다. [참조: Wang et.al., 2022: 부실 감독 대비 사전 훈련에 의한 텍스트 임베드]. 휴깅페이스 모델 카드 (https://huggingface.co/intfloat/e5-base).
- E5-small: 오픈 소스 E5 제품군 내의 더 작은 모델입니다. 이 모델의 임베드 차원은 all-minilm-l6-v2 (384) 의 차원과 일치하지만 12개의 계층이 있으므로 더 크고 약간 느립니다. [참조: Wang et.al., 2022: 부실 감독 대비 사전 훈련에 의한 텍스트 임베드]. 휴깅페이스 모델 카드 (https://huggingface.co/intfloat/e5-small).
- BGE-base: 768임베드 크기 ( 01.20.2024기준) 에 대해 BEIR 벤치마크에서 최상의 성능을 제공하는 최근 개방형 소스 변환기 모델입니다. 휴깅페이스 모델 카드 (https://huggingface.co/BAAI/bge-base-en-v1.5).
평가 벤치마크: BEIR (MTEB의 검색 탭)
BEIR 벤치마크에는 제로 샷 (zero-shot) 설정에서 평가된 15개의 오픈 소스 검색 태스크가 포함되어 있습니다. BEIR은 사실 확인, 인용 예측, 중복 질문 검색, 인수 검색, 뉴스 검색, 질문 응답, 트윗 검색, 생체 의학 IR및 엔티티 검색 등 9개의 다양한 검색 태스크를 포함하여 다양성에 초점을 두었습니다. 또한 다양한 텍스트 도메인의 데이터 세트, 광범위한 주제 (예: Wikipedia) 및 특수화된 주제 (예: COVID-19 서적) 를 다루는 데이터 세트, 다양한 텍스트 유형 (뉴스 기사 대 트윗), 다양한 크기의 데이터 세트 (3.6k - 15M 문서), 다양한 쿼리 길이 (평균 쿼리 길이가 3-192단어) 및 문서 길이 (평균 문서 길이가 11-635단어) 인 데이터 세트를 포함합니다. BEIR은 정규화된 누적 할인 이득 (특히, nDCG@10) 메트릭을 사용하여 평가합니다.
긴 NQ
Long NQ는 NaturalQuestions 데이터 세트의 서브세트를 기반으로 전체 RAG 파이프라인을 평가하기 위해 설계된 IBM 데이터 세트입니다. 개발 세트에는 2,345개의 위키피디아 문서에서 178,891개의 문장으로 구성된 말뭉치가 있는 300개의 응답 가능한 질문이 있습니다. 롱 NQ는 또한 각 질문과 관련된 골드 위키피디아 구절을 제공한다. 검색 중에 태스크는 모든 질문에 대해 말뭉치에서 관련 골드 통로를 확보하는 것입니다.
결과
| 모델 | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| ELSER | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES-소형 | 46.01 |
| ES-기본 | 48.75 |
| BGE-기본 | 53.25 |
| slate.30m.english.rtrvr | 49.37 |
| slate.30m.english.rtrvr | 46.91 |

그림 3. BEIR 벤치마크에서 성능 비교 (MTEB 검색 탭)
| 모델 | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| ES-소형 | 66.87 |
| ES-기본 | 63.95 |
| BGE-기본 | 61.29 |
| slate.30m.english.rtrvr | 65.01 |
| slate.30m.english.rtrvr | 59.94 |

그림 4. Long NQ 데이터 세트의 성능 비교
런타임 성능
성능 런타임은 466조회가 있는 순위 재지정 태스크에서 측정됩니다. 각 조회에 대해 BM25 에서 얻은 top-100 단락의 순위를 다시 지정하고 모든 조회에 대한 평균 시간을 보고합니다. 순위 재지정은 A100_40GB GPU에서 수행되었습니다.
| 모델 | 시간/조회 |
|---|---|
| all-miniLM-L6-v2 | 0.18 초 |
| E5-small | 0.33 초 |
| E5-base | 0.75 초 |
| BGE-기본 | 0.75 초 |
| slate.125m.english.rtrvr | 0.71 초 |
| slate.30m.english.rtrvr | 0.20 초 |