モデルの説明
slate.30m.english.rtrvrモデルは、バイエンコーダをベースとした標準的な文変換モデルである。 このモデルは、指定された入力 (照会、パッセージ、文書など) の組み込みを生成します。 大まかには、テキスト A (照会テキスト) とテキスト B (パッセージ・テキスト) など、テキストの 2 つの入力部分の間のコサインの類似性を最大化するようにモデルがトレーニングされています。これにより、センテンス埋め込み q と p が生成されます。 これらの文の埋め込みは、コサインの類似性を使用して比較することができます。
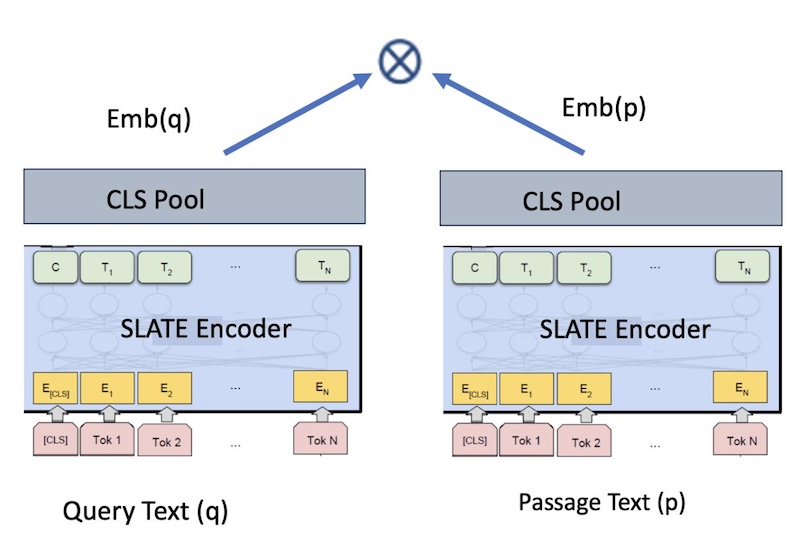
図1: 取得のための bi-encoder 埋め込みモデル
基本言語モデル
埋め込みの基礎となる言語モデル (LM) は、 slate.30m.englishです。 これは、small-RoBERTaベース トランスフォーマ モデル (6 層) と同じアーキテクチャを持ち、~3,000 万のパラメータと 384 の埋め込み次元を持ちます。 具体的には、 “slate.30m.english” は、 “slate.125m.english” (以前は WatBERT) から抽出されました。 最後のモデルは “slate.30m.english.rtrvr” と呼ばれます。末尾の接尾部は、取得ベースのタスク用に基礎となるモデル・アーキテクチャーを微調整することを示しています。
トレーニング・アルゴリズム
最先端の、あるいはMTEBリーダーボードの上位に位置するエンベッディング・モデルのほとんどは、通常3段階でトレーニングされる:
- タスク固有 (取得ベース) のプリトレーニング
- マイニングされたペアに対するタスク固有の微調整
- 監視対象ペアの微調整
最後の 2 つのステージを 1 つの微調整ステップに結合して、同様のアプローチに従います。
slate.30m.english.rtrvr は、微調整ステップで “slate.125m.english.rtrvr” モデルからの蒸留によって生成されます。 Knowledge Distillation は、高性能の教師モデルからの知識を、生徒の出力確率分布を教師の出力確率分布とできるだけ一致するようにトレーニングすることで、生徒のパフォーマンスをスタンドアロンのファイナライズと比較して向上させることにより、より小さな生徒モデルに移します。
タスク固有の事前トレーニング
このステージでは、 RetroMAE フレームワークを使用して、基礎となる LM をより取得指向にします。 slate.30m.english を使用してベース LM を初期化し、表 1 のデータを使用して RetroMAE の事前トレーニングを続行します。 ハイパーパラメーターは次のとおりです。学習速度: 2e-5、ステップ数: 435000、GPU: 8 A100 (80GB) GPU。 注: これは、以下の 2 つのステージの基本 LM です。
教師なしペアおよび教師ありペアを使用した蒸留
図 1 のように、組み込みモデルをトレーニングするためにバイエンコーダー・フレームワークを使用します。 RetroMAE の事前トレーニング済みモデルを使用して初期化し、さらに、バッチ内陰性度を使用した対比損失目標を使用して、 <query, passage> テキスト・ペアを使用した知識蒸留を採用します。 Knowledge Distillation は、生徒の出力確率分布を、教師の出力確率分布とできるだけ一致するようにトレーニングします。 リトリーバー・モデルのコンテキストでは、出力分布はテキストのペア間の類似度スコアです。 具体的には、文の各ペア <query, passage>について、照会の埋め込みとパッセージの間の教師のスコアの分布 (つまり、埋め込み間の余弦の類似性) が学生に蒸留されます。
蒸留に使用される教師は、以下の同じデータに基づいてトレーニングされた「slate.125m.english.rtrvr” 」モデルです。 教師は、2 つのモデル間のモデル融合を使用して形成されます。それぞれのモデルでは、 RetroMAE の事前トレーニングと微調整が使用されますが、微調整データでは異なります。 詳しくは、 slate.125m.english.rtrvrのモデル・カードを参照してください。 図 2 は、ナレッジ・トランスファーの流れを図示しています。
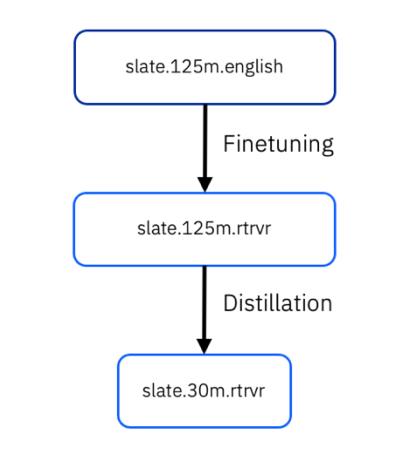
図2: ナレッジ蒸留
「トレーニング・データ」セクションに示されているように、さまざまな領域から大規模なペアをマイニングします。 さらに、検索タスクのための高品質なペアも以下のデータセットに含まれている:SQuAD, Natural Questions、Specter、Stack Exchange (Title, Body)のペア、S2ORC、SearchQA, HotpotQA、Fever。 蒸留ハイパーパラメーターは、以下のとおりです。learning rate:7e-4、ステップ数: 400000、実効バッチ・サイズ: 2048、GPU: 2 A100_80GB GPU。
データの学習
| データ・セット | パッセージ |
|---|---|
| ウィキペディア | 36396918 |
| ブック・コーパス | 3401308 |
| スタック交換 | 15999837 |
| データ・セット | ペア |
|---|---|
| SPECTER サイテーション・トリプレット | 684100 |
| スタック交換の重複する質問 (タイトル) | 304525 |
| AllNLI (SNLI および MultiNLI) | 277230 |
| スタック交換の重複する質問 (本文) | 250519 |
| スタック交換の重複する質問 (タイトル + 本文) | 250460 |
| 自然問題 (NQ) | 100231 |
| SQuAD2.0 | 87599 |
| PAQ (質問、回答) ペア | 64371441 |
| スタック交換 (タイトル、回答) のペア | 4067139 |
| スタック交換 (タイトル、本文) のペア | 23978013 |
| スタック交換 (タイトル + 本文、回答) のペア | 187195 |
| S2ORC 引用のペア (タイトル) | 52603982 |
| S2ORC (タイトル、要約) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers 重複する質問のペア | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| 熱 | 109810 |
| アル14号 | 2358545 |
| ウィキペディア | 20745403 |
| PubMed | 20000000 |
使用法
# Make sure the sentence transformers is installed.
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
'Who made the son My achy breaky heart ?',
'summit define']
input_passages = [
"Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings))
このモデルの最大シーケンス長は 512 トークンです。
評価
ベースライン
公平な比較のために、以下のベースラインと比較します。
- BM25 (tf-idf に基づく従来型のモデル)。
- ELSER (Elastic が提供する商用検索アルゴリズム)。
- all-MiniLM-l6-v2: 一般的なオープン・ソースのセンテンス・トランスフォーマー・モデル。 このモデルは、 slate.125m.english.rtvrと同じアーキテクチャーを、より小さい埋め込みディメンション (384) で共有しており、商用ライセンスなしでより多くのデータについてトレーニングされています。 詳しくはHugging Faceのモデルカードhttps://huggingface.co/sentence-transformers/all-MiniLM-L6-v2を参照。
- E5-base: BEIR ベンチマークで非常に優れたパフォーマンスを発揮する、最近のオープン・ソースのトランスフォーマー・モデル。 これは、 slate.125m.english.rtvrと同じアーキテクチャーを持つ基本サイズのモデルです。 [参照: Wang et.al., 2022: Text Embedding by Weakly-Supervised Contrastive Pre-training]。 ハギングフェイス・モデル・カード (https://huggingface.co/intfloat/e5-base)。
- E5-small: オープン・ソースの E5 ファミリー内の小規模なモデル。 このモデルの埋め込みディメンションは、 all-minilm-l6-v2 (384) の埋め込みディメンションと一致しますが、12 個のレイヤーがあるため、より大きく、少し遅くなります。 [参照: Wang et.al., 2022: Text Embedding by Weakly-Supervised Contrastive Pre-training]。 ハギングフェイス・モデル・カード (https://huggingface.co/intfloat/e5-small)。
- BGE-base: 768 埋め込みサイズ ( 01.20.2024現在) の BEIR ベンチマークで最高のパフォーマンスを発揮する、最近のオープン・ソース変換プログラム・モデル。 ハギングフェイス・モデル・カード (https://huggingface.co/BAAI/bge-base-en-v1.5)。
評価ベンチマーク: BEIR (MTEB の取得タブ)
BIR ベンチマークには、ゼロ・ショット設定で評価された 15 のオープン・ソース取得タスクが含まれています。 BEIR は、ファクト・チェック、引用の予測、重複質問の取得、引数の取得、ニュースの取得、質問の回答、ツイートの取得、バイオメディカル IR、エンティティーの取得という 9 つの異なる取得タスクを含む多様性に重点を置いています。 さらに、多様なテキスト・ドメインからのデータ・セット、広範なトピック (Wikipedia など) と特殊なトピック ( COVID-19 資料など) をカバーするデータ・セット、さまざまなテキスト・タイプ (ニュース記事とツイート)、さまざまなサイズのデータ・セット (3.6k - 15M 文書間の平均長さ)、およびデータ・セットも含まれます。照会の長さは 11 語間 (平均長さ)。 BEIR は、正規化された累積割引ゲイン (特に nDCG@10) メトリックを評価に使用します。
長い NQ
Long NQ は、 NaturalQuestions データ・セットのサブセットに基づいて RAG パイプライン全体を評価するために設計された IBM データ・セットです。 この開発セットには、2,345 件のウィキペディアの文書から 178,891 節のコーパスを持つ 300 の回答可能な質問が含まれています。 Long NQ では、各質問に関連するゴールド・ウィキペディア・パッセージも提供されています。 取得時には、すべての質問に対してコーパスから関連するゴールド・パッセージを取得する必要があります。
結果
| モデル | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| エルサー | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES-小文字 | 46.01 |
| ES ベース | 48.75 |
| BGE ベース | 53.25 |
| slate.30m.english.rtrvr | 49.37 |
| slate.30m.english.rtrvr | 46.91 |
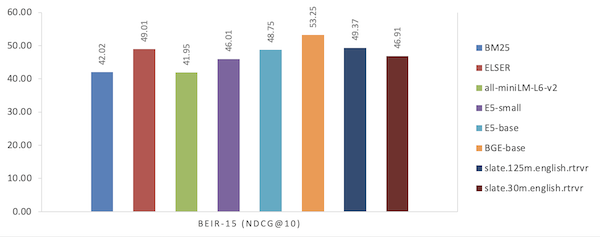
図3: BIR ベンチマークでのパフォーマンス比較 (「MTEB 取得 (MTEB retrieval)」タブ)
| モデル | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| ES-小文字 | 66.87 |
| ES ベース | 63.95 |
| BGE ベース | 61.29 |
| slate.30m.english.rtrvr | 65.01 |
| slate.30m.english.rtrvr | 59.94 |
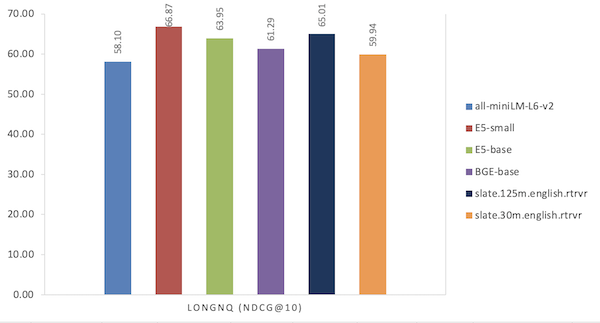
図4: 長い NQ データ・セットでのパフォーマンスの比較
ランタイム・パフォーマンス
パフォーマンス・ランタイムは、466 個の照会を持つ再ランキング・タスクで測定されます。 照会ごとに、 BM25 によって取得された top-100 個のパッセージを再ランク付けし、すべての照会の平均時間を報告します。 再ランキングは A100_40GB GPU で実行されました。
| モデル | 時刻/照会 |
|---|---|
| all-miniLM-L6-v2 | 0.18 秒 |
| E5-small | 0.33 秒 |
| E5-base | 0.75 秒 |
| BGE ベース | 0.75 秒 |
| slate.125m.english.rtrvr | 0.71 秒 |
| slate.30m.english.rtrvr | 0.20 秒 |