バージョン 2.0.1 Date: 06/30/2024
モデルの説明
slate.125m.english.rtrvr-v2モデルは、バイエンコーダをベースとした標準的な文型変換モデルである。このモデルは、与えられた入力(クエリー、パッセージ、文書など)に対する埋め込みを生成する。 高いレベルでは、我々のモデルは2つの入力テキスト、例えばテキストA(クエリテキスト)とテキストB(パッセージテキスト)の間の余弦類似度を最大化するように学習され、その結果、文埋め込みqとpが得られる。 これらの文の埋め込みは、コサイン類似度を用いて比較することができる。
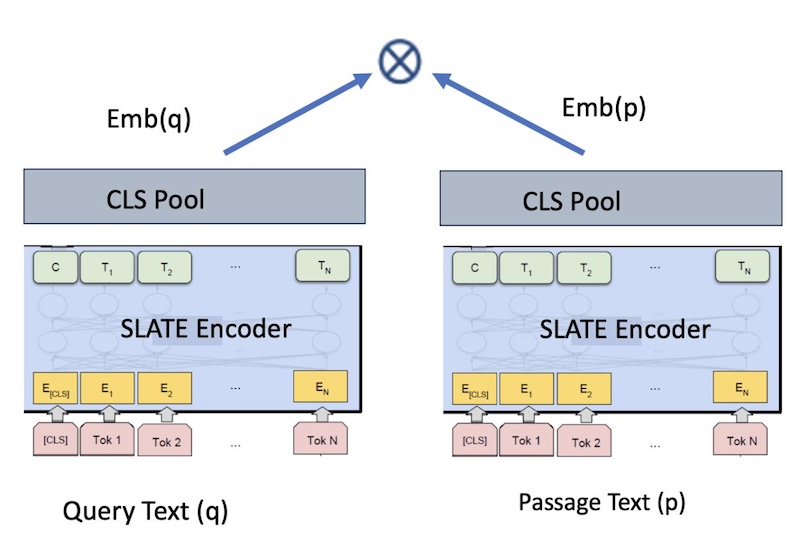
図1: 検索のためのバイエンコーダ埋め込みモデル
基本言語モデル
エンベッディングの言語モデル(LM)は“slate.125m.english”です。 これは、RoBERTa-base トランスフォーマ モデル (12 層) と同じアーキテクチャを持ち、~1 億 2,500 万のパラメータと 768 のエンベッディング次元を持ちます。 具体的には、slate.125m.englishは、“slate.125m.english”(以前は、WatBERT)から微調整されました。 最終的なモデルの名前はslate.125m.english.rtrvrです。 接尾辞は、基本的なモデル・アーキテクチャが検索ベースのタスク用に微調整されていることを示す。
トレーニング・アルゴリズム
最先端の、あるいはMTEBリーダーボードの上位に位置するエンベッディング・モデルのほとんどは、通常3段階でトレーニングされる:
- 課題別(検索ベース)事前トレーニング
- 採掘されたペアのタスク別微調整
- 教師付きペアの微調整
同じアプローチに従い、最終的に異なる学習済みモデルの重みを平均化することで、モデル・フュージョンを行う。
slate.125m.english.rtrvrは、「モデル・フュージョン」(段階的に訓練された以下のモデルの重みを平均化すること)を実行することによって生成されるが、以下のようなバリエーションがある:
- モデル1は上記の3つのステージすべてで微調整を行った
- 上記のすべての段階で微調整されたモデルから抽出されたモデル2。
タスク別の事前トレーニング
このステージでは、RetroMAEフレームワークを使用し、基礎となるLMをより検索指向にする。 slate.125m.englishでベースLMを初期化し、表1のデータを使ってRetroMAEで事前学習を続ける。 ハイパーパラメータは次のとおりである:学習率:2e-5、ステップ数:190000, GPU: 24 A100 40GB.
注:これは次の2ステージのベースとなるLMである。
大規模教師なしデータによる微調整
このモデルはRetroMAEプレトレーニングモデルで初期化され、以下のようにトレーニングされる。
埋め込みモデルの学習には、図1のようなバイエンコーダの枠組みを用いる。 RetroMAE あらかじめ訓練されたLMは、<query, passage> テキストペアを用いて、コントラスト損失という目的語を用いて微調整される。 表2に示すように、様々なドメインから大規模なペアをマイニングする。 このモデルは、前提を対応する仮説にマッチさせるNLI(自然言語推論)のような分類タスクを含む、多様なペアで学習される。 ハイパーパラメーターは以下の通り:学習率:2e-4; ステップ数:35000; GPUs:8 A100_80GB, 有効バッチサイズ:16kペア
ハードネガを伴う小規模教師ありデータによる微調整
最後に、検索タスクのために、ハードネガティブマイニングから得た教師付き訓練ペアを用いて、モデルを微調整する。 中間モデルのチェックポイントは、データセット固有のハードネガをマイニングするために繰り返し使用され、その後、教師ありの微調整に使用される。 このプロセスは、モデルに自身の過ちから学ばせることでよりロバストにすることを目的としており、より少ないデータで安定させるのに役立つ。
我々は、トレーニングデータのセクションで述べたデータセットのサブセット(保留されたデータセットで検証実験を行うことで発見された)を以下のように使用することで、モデルを微調整する:AllNLI, Squad、Stackexchange、NQ、HotpotQA, Fever、および5M Specter、S2orc、WikiAnswersの各サブセットです。 さらに、Mixtral-8x7B-Instruct-v0.1を使用して、質問と回答、事実確認などの良質なペアを作成するために、トリプルを合成的に生成します。 IBM 固有のユースケースに対してより良いパフォーマンスを提供するために、IBM Software Support データと IBM Docs から作成されたペアも含まれています。
学習ハイパーパラメータは学習率:2e-5;最大クエリ長: 64; 最大通過長: 512; 最大ステップ数: 5000; 有効バッチサイズ: 512; GPUの学習ハイパーパラメータは以下の通りです:5000; 有効バッチサイズ: 512; GPUs:1A100_80GB です
データの学習
| データ・セット | パッセージ |
|---|---|
| ウィキペディア | 36396918 |
| 書籍コーパス | 3401308 |
| スタックエクスチェンジ | 15999837 |
| データ・セット | ペア |
|---|---|
| SPECTERの3連引用 | 684100 |
| Stack Exchange 重複する質問(タイトル) | 304525 |
| Stack Exchange 重複する質問(遺体) | 250519 |
| Stack Exchange 重複する質問(タイトル+本文) | 250460 |
| ナチュラル・クエスチョン(NQ) | 100231 |
| SQuAD2.0 | 87599 |
| PAQ(質問と回答)ペア | 64371441 |
| スタック・エクスチェンジ(タイトル、回答)ペア | 4067139 |
| スタック・エクスチェンジ(タイトル、本文)ペア | 23978013 |
| スタック・エクスチェンジ(タイトル+本文、回答)ペア | 187195 |
| S2ORC 引用ペア(タイトル) | 52603982 |
| S2ORC(タイトル、アブストラクト) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers 重複する質問のペア | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| フィーバー | 109810 |
| Arxiv | 2358545 |
| ウィキペディア | 20745403 |
| PubMed | 20000000 |
| ミラクル・エン・ペア | 9016 |
| DBPediaタイトルとボディのペア | 4635922 |
| 合成:クエリ-ウィキペディアのパッセージ | 1879093 |
| シンセティック事実の検証 | 9888 |
| IBMです:IBM Docs (タイトル-本文) | 474637 |
| IBMです:IBM サポート (タイトル-本文) | 1049949 |
使用法
# make sure you’ve sentence transformers installed
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
' Who made the song My achy breaky heart? ',
'summit define']
input_passages = [
" Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991. ",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings)
このモデルの最大シーケンス長は512トークンである。
評価
ベースライン
公正な比較のために、以下のベースラインと比較する:
BM25(tf-idfに基づく伝統的モデル)
ELSER(Elastic社が提供する商用検索アルゴリズム)
all-MiniLM-l6-v2:人気のあるオープンソースの文章変形モデルです。 このモデルはslate.30m.english.rtrvrと同じアーキテクチャーを共有し、商用に適したライセンスなしで、より多くのデータでトレーニングされています。 詳しくはハギングフェイスのモデルカードをご覧ください
E5-base:最近のオープンソースのトランスフォーマーモデルで、BEIRベンチマークで非常に優れた性能を発揮します。 これはベースサイズのモデルで、slate.125m.english.rtrvrと同じアーキテクチャを持つ。 [参考文献王 et.al、 2022: 弱教師付き対照事前学習によるテキスト埋め込み]. ハギングフェイス・モデルカード
E5-small:オープンソースのE5ファミリーの中の小型モデル。 このモデルの埋め込み次元はslate.30m.rtrvr(384)と一致するが、レイヤー数が12であるため、より大きく、わずかに遅い。 [参考文献王 et.al、 2022: 弱教師付き対照事前学習によるテキスト埋め込み]. ハギングフェイス・モデルカード
BGE-base:最近のオープンソース変換モデルで、768エンベッディングサイズのBEIRベンチマークで最高の性能を発揮。 ハギングフェイス・モデルカード
BGE-small:384エンベッディングサイズのBEIRベンチマークで最高のパフォーマンスを発揮する、最近のオープンソースのトランスフォーマーモデル。 ハギングフェイス・モデルカード
また、これらのモデルのパフォーマンスを、スレートモデルの旧バージョンであるslate.125m.english.rtrvr-012024とslate.30m.english.rtrvr-012024と比較する。
評価ベンチマークBEIR(MTEBの検索タブ)
BEIRベンチマークは、ゼロショット設定下で評価された15のオープンソース検索タスクで構成されています。 BEIRは、9つの異なる検索タスクを含む多様性に焦点を当てた:ファクトチェック、引用予測、重複質問検索、議論検索、ニュース検索、質問応答、ツイート検索、バイオ・医療IR、エンティティ検索である。 さらに、多様なテキストドメインのデータセット、幅広いトピック(ウィキペディアのような)と専門的なトピック(COVID-19 出版物のような)をカバーするデータセット、異なるテキストタイプ(ニュース記事対.ツイート)、様々なサイズのデータセット(3.6k - 15M documents)、異なるクエリ長(平均クエリ長は3~192語)とドキュメント長(平均ドキュメント長は11~635語)のデータセットがある。 BEIRは評価に正規化累積割引利益(具体的にはnDCG@10)指標を使用する。
ロングNQ
Long NQはIBMのデータセットで、NaturalQuestionsデータセットのサブセットに基づいて、RAGパイプライン全体を評価するために設計されています。 開発セットには、2,345のウィキペディア文書から178,891の文章をコーパスとする300の回答可能な質問がある。 ロングNQはまた、各問題に関連するゴールド・ウィキペディアの文章も提供している。 検索中、タスクはすべての質問に対してコーパスから関連する金文を取得することである。
結果
| モデル | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| エルザー | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES-small-v2 | 49.04 |
| ES-base-v2 | 50.29 |
| BGE-小 | 51.68 |
| BGEベース | 53.25 |
| slate.30m.english.rtrvr 01.20.2024 | 46.91 |
| slate.125m.english.rtrvr-01.20.2024 | 49.37 |
| slate.30m.english.rtrvr 06.30.2024 | 49.06 |
| slate.125m.english.rtrvr-06.30.2024 | 51.26 |
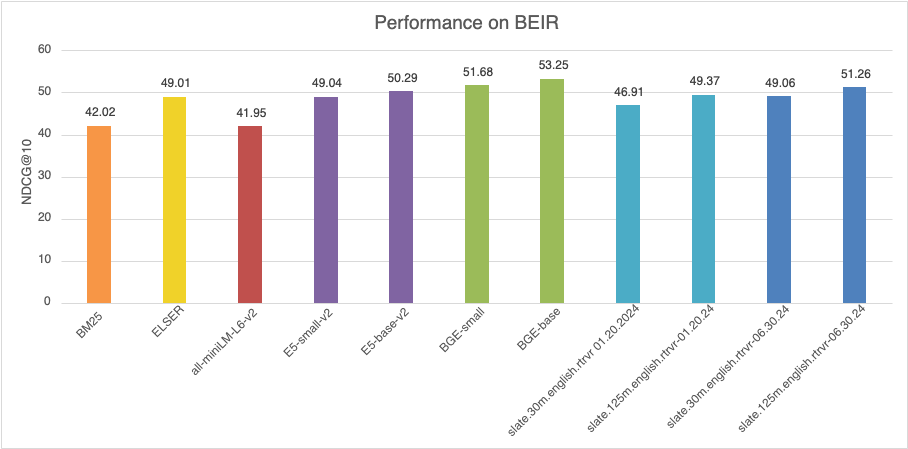
図2: BEIRベンチマークでの性能比較(MTEB検索タブ)
| モデル | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| BGE-小 | 59.33 |
| BGEベース | 61.29 |
| ES-small-v2 | 61.88 |
| ES-base-v2 | 63.80 |
| slate.30m.english.rtrvr 01.20.2024 | 59.94 |
| slate.125m.english.rtrvr-01.20.2024 | 65.01 |
| slate.30m.english.rtrvr 06.30.2024 | 62.07 |
| slate.125m.english.rtrvr-06.30.2024 | 66.80 |
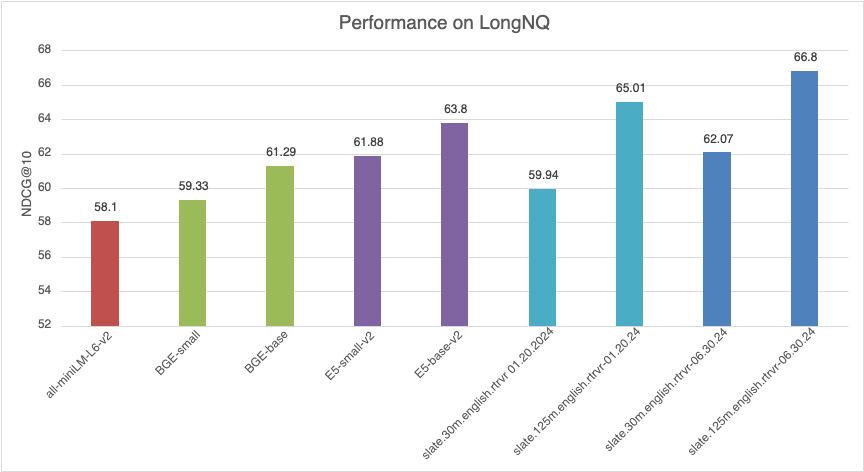
図3: ロングNQデータセットでの性能比較
ランタイム・パフォーマンス
パフォーマンスの実行時間は、466のクエリーを持つ再ランキングタスクで測定された。 各クエリについて、top-100 によって得られたBM25のパッセージを再ランク付けし、全クエリの平均時間を報告する。 再ランキングはA100_40GB GPUで実行された。
| モデル | 時間/クエリー |
|---|---|
| all-miniLM-L6-v2 | 0.18秒 |
| E5-small | 0.33秒 |
| E5-base | 0.75秒 |
| BGE-小 | 0.34秒 |
| BGEベース | 0.75秒 |
| slate.125m.english.rtrvr | 0.71秒 |
| slate.30m.english.rtrvr | 0.20秒 |