Scheda modello IBM slate-125m-english-rtrvr
Descrizione modello
Il modello slate.125m.english.rtrvr è un modello standard di trasformatori di frasi basato su bi-encoders. Il modello produce un'integrazione per un determinato input, ad esempio query, passaggio, documento e così via. Ad alto livello, il nostro modello è addestrato per massimizzare la somiglianza coseno tra due parti di testo di input, ad esempio il testo A (testo di query) e il testo B (testo di passaggio), che risultano nelle frasi di inserimento q e p. Questi incorporamenti di frasi possono quindi essere confrontati utilizzando la similarità coseno.
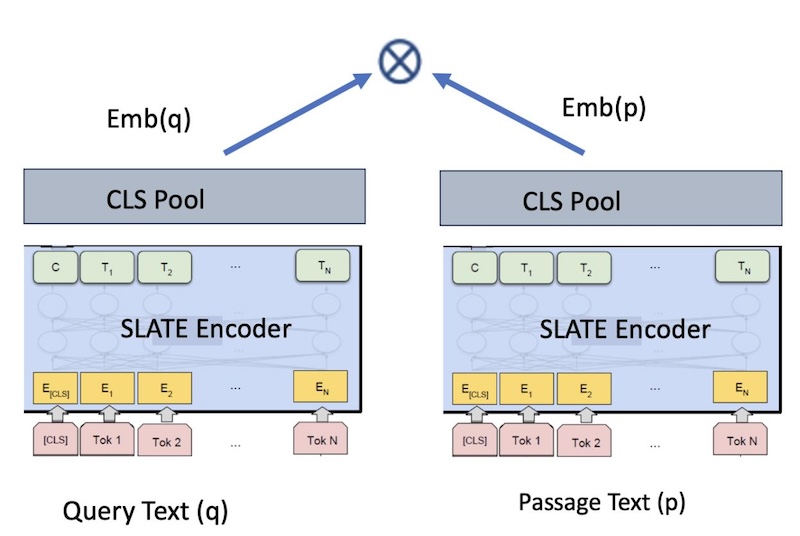
Figura 1. Modello di incorporazione Bi - encoder per Retrieval
Modello lingua base
Il modello lingua (LM) sottostante per le nostre integrazioni è slate.125m.english (precedentemente noto come WatBERT). Ha la stessa architettura di un modello di trasformatore base RoBERTa e ha ~ 125 milioni di parametri e una dimensione di inserimento di 768. Il nostro modello finale è denominato “slate.125m.english.rtrvr” - notare il suffisso alla fine che indica che ottimizziamo l'architettura del modello sottostante per le attività basate sul richiamo.
Algoritmo di addestramento
La maggior parte dei modelli di incorporazione all'avanguardia o ai vertici della classifica MTEB sono in genere addestrati in 3 fasi:
- Pre - addestramento specifico dell'attività (basato sul richiamo)
- Ottimizzazione specifica dell'attività sulle coppie estratte
- Ottimizzazione su coppie supervisionate.
Seguiamo lo stesso approccio e infine eseguiamo una fusione di modelli facendo la media dei pesi di diversi modelli addestrati.
slate.125m.english.rtrvr viene prodotto eseguendo la "fusione del modello" - media dei pesi dei seguenti modelli, entrambi addestrati in fasi ma con le seguenti varianti:
- Modello 1 ottimizzato con dati non supervisionati su larga scala
- Modello 2 ottimizzato con un sottoinsieme più piccolo di dati supervisionati
Pre - formazione specifica del compito
Questo stage utilizza il framework RetroMAE , per rendere il nostro LM sottostante più orientato al richiamo. Inizializziamo il nostro LM base con slate.125m.english e continuiamo con il pre - addestramento RetroMAE , utilizzando i dati della Tabella 1. I nostri iper parametri sono: tasso di apprendimento: 2e-5, numero di passi: 190000, GPU: 24 A100 40GB. Nota: questo è il nostro LM di base per le seguenti 2 fasi.
Model1: ottimizzazione dei dati non supervisionati su larga scala
Questo modello viene inizializzato con il modello preaddestrato RetroMAE e viene addestrato in 2 fasi.
Fase 1: fine-tuning non supervisionato
Utilizziamo un framework bi - encoder per la formazione di un modello di incorporazione, come in Figura 1. Il LM pre - preparato RetroMAE viene ottimizzato con coppie di testo <query, passage>
Fase 2: fine-tuning supervisionato
Infine, il modello viene messo a punto con coppie di addestramento supervisionato di alta qualità per il compito di recupero sui seguenti dataset: SQuAD, coppie Natural Questions, Specter, Stack Exchange (Titolo, Corpo), S2ORC, SearchQA, HotpotQA e Fever. Gli iper - parametri di addestramento sono la velocità di apprendimento: 2e-5; numero di passi: 10000; GPU: 8 A100_80GB, dimensione batch effettiva: 4096 coppie.
Modello 2: fine-tuning con un sottoinsieme più incentrato sulle attività
In questa fase, il modello pre - addestrato RetroMAE viene sottoposto a finetuning supervisionato con un sottoinsieme più piccolo di Table2 con supervisione proveniente dal mining negativo. I punti di controllo del modello intermedio vengono utilizzati iterativamente per estrarre i negativi hard specifici del dataset, che vengono quindi utilizzati per la finetuning supervisionata. Questo processo mira a rendere il modello più robusto lasciandolo imparare dai propri errori e aiuta a stabilizzare con dati molto più piccoli.
Per la messa a punto del modello utilizziamo un sottoinsieme di set di dati (individuati attraverso l'esecuzione di esperimenti di convalida su un set di dati non ancora pubblicato) indicati nella Table2, che sono i seguenti: AllNLI, Squad, Stackexchange, NQ, HotpotQA, Fever e 5M sottoinsieme da ciascuno di Specter, S2orc, WikiAnswers.
Gli iper - parametri di addestramento sono il tasso di apprendimento: 2e-5; lunghezza massima della query: 512; lunghezza massima del passaggio: 512; epoche: 2; dimensione batch effettiva: 384 tripli; GPU: 24 A100_80GB.
Il nostro modello finale: slate.125m.english.rtrvr: Model fusion
Eseguiamo la fusione dei modelli facendo la media dei pesi dei modelli (di cui sopra) addestrati con i dati non supervisionati su larga scala e il modello addestrato con il sottoinsieme più piccolo di dati supervisionati.
Viene utilizzato un set di sviluppo (https://huggingface.co/datasets/colbertv2/lotte) ed eseguita la ricerca della griglia per ottenere la combinazione di pesi ottimale per questi modelli. I pesi del modello vengono medi in base al parametro ottimale: 0.7 per Model1 e 0.3 per Model2.
Dati di formazione
| Dataset | Passages |
|---|---|
| Wikipedia | 36396918 |
| Corpus di libri | 3401308 |
| Scambio stack | 15999837 |
| Dataset | Coppie |
|---|---|
| Triplette di citazione SPECTER | 684100 |
| Domande duplicate (titoli) | 304525 |
| AllNLI (SNLI e MultiNLI) | 277230 |
| Domande duplicate (corpi) | 250519 |
| Domande duplicate (titoli + corpi) | 250460 |
| Domande naturali (NQ) | 100231 |
| SQuAD2.0 | 87599 |
| Coppie PAQ (Domanda, Risposta) | 64371441 |
| Coppie di scambio stack (titolo, risposta) | 4067139 |
| Coppie di scambio stack (titolo, corpo) | 23978013 |
| Coppie di scambio stack (titolo + corpo, risposta) | 187195 |
| S2ORC Coppie di citazione (Titoli) | 52603982 |
| S2ORC (Titolo, Estratto) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers Duplica coppie di domande | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| Febbre | 109810 |
| Arxiv | 2358545 |
| Wikipedia | 20745403 |
| PubMed | 20000000 |
Utilizzo
# Make sure the sentence transformers is installed.
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
'Who made the son My achy breaky heart ?',
'summit define']
input_passages = [
"Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings))
La lunghezza massima della sequenza di questo modello è 512 token.
Valutazione
Baseline
Per un confronto equo, si confronta con le seguenti linee di base:
- BM25 (un modello tradizionale basato su tf-idf).
- ELSER (un algoritmo di ricerca commerciale fornito da Elastic).
- all-MiniLM-l6-v2: : un popolare modello di trasformatori di frasi open-source. Questo modello condivide la stessa architettura di slate.125m.english.rtvr, con una dimensione di inserimento più piccola ed è stato addestrato su più dati senza licenze commerciali. Scheda del modello Huggingface (https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) per ulteriori dettagli.
- E5-base: un recente modello di trasformatore open source con prestazioni molto buone sul benchmark BEIR. Questo è un modello di base, che ha la stessa architettura di slate.125m.english.rtvr. [ Riferimento: Wang et.al., 2022: Incorporazioni di testo da pre - allenamento contrastivo debolmente supervisionato]. Scheda modello Huggingface (https://huggingface.co/intfloat/e5-base).
- E5-small: un modello più piccolo all'interno della famiglia E5 open source. La dimensione di incorporazione di questo modello corrisponde a quella di all-minilm-l6-v2 (384), tuttavia ha 12 livelli e quindi è più grande e leggermente più lento. [ Riferimento: Wang et.al., 2022: Incorporazioni di testo da pre - allenamento contrastivo debolmente supervisionato]. Scheda modello Huggingface (https://huggingface.co/intfloat/e5-small).
- BGE - base: un recente modello di trasformatore open-source con le migliori prestazioni sul benchmark BEIR per la dimensione di inserimento 768 (a partire da 01.20.2024). Scheda modello Huggingface (https://huggingface.co/BAAI/bge-base-en-v1.5).
Il nostro benchmark di valutazione: BEIR (scheda di recupero di MTEB)
Il benchmark BEIR contiene 15 attività di recupero open-source focalizzate su diversi domini, tra cui nove diverse attività di recupero: controllo dei fatti, previsione della citazione, recupero di domande duplicate, recupero di argomenti, recupero di notizie, risposta alle domande, recupero di tweet, IR bio - medico e recupero di entità. Inoltre, include dataset provenienti da diversi domini di testo, dataset che coprono argomenti ampi (come Wikipedia) e argomenti specializzati (come pubblicazioni COVID-19 ), diversi tipi di testo (articoli di notizie e tweet), dataset di varie dimensioni (documenti3.6k - 15M ) e dataset con lunghezze di query differenti (lunghezza media di query tra 3 e 192 parole) e lunghezze di documenti (lunghezza media di documenti tra 11 e 635 parole). Le prestazioni di tutti i modelli sono indicate nella seguente tabella. BEIR utilizza la metrica Guadagno sconto cumulativo normalizzato (in particolare, nDCG@10) per la valutazione. Si tratta della stessa valutazione utilizzata nella classifica MTEB HuggingFace , ma che si concentra principalmente sulle attività di richiamo.
NQ lunga
Long NQ è un dataset IBM progettato per valutare la pipeline RAG completa, basata su un sottoinsieme del dataset NaturalQuestions . Il set di sviluppo ha 300 domande con un corpus di 178.891 passaggi da 2.345 documenti Wikipedia. Long NQ fornisce anche passaggi di Wikipedia in oro che sono rilevanti per ogni domanda. Durante il recupero, il compito è quello di ottenere il passaggio d'oro pertinente dal corpus per ogni domanda.
Risultati
| Modello | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| ELSER | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES - piccolo | 46.01 |
| ES - base | 48.75 |
| BGE - base | 53.25 |
| slate.125m.english.rtrvr | 49.37 |
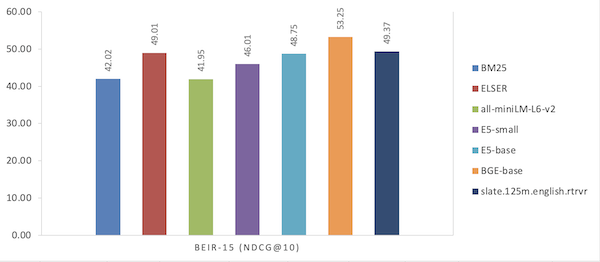
Figura 2. Confronto delle prestazioni sul benchmark BEIR (scheda recupero MTEB)
| Modello | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| ES - piccolo | 66.87 |
| ES - base | 63.95 |
| BGE - base | 61.29 |
| slate.125m.english.rtrvr | 65.01 |
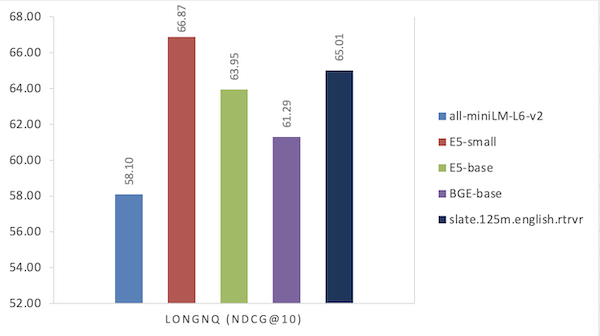
Figura 3 Confronto delle prestazioni sul dataset NQ lungo
Prestazioni runtime
Il runtime delle prestazioni viene misurato su un'attività di riclassificazione con 466 query. Per ogni query, vengono nuovamente classificati i top-100 passaggi ottenuti da BM25 e viene riportato il tempo medio su tutte le query. La nuova classificazione è stata eseguita su una GPU A100_40GB .
| Modello | Ora / query |
|---|---|
| all-miniLM-L6-v2 | 0.18 sec |
| E5-small | 0.33 sec |
| E5-base | 0.75 sec |
| BGE - base | 0.75 sec |
| slate.125m.english.rtrvr | 0.71 sec |