Model description
The slate.125m.english.rtrvr model is a standard sentence transformers model based on bi-encoders. The model produces an embedding for a given input e.g. query, passage, document etc. At a high level, our model is trained to maximize the cosine similarity between two input pieces of text e.g. text A (query text) and text B (passage text), which result in the sentence embeddings q and p. These sentence embeddings can then be compared using cosine similarity.
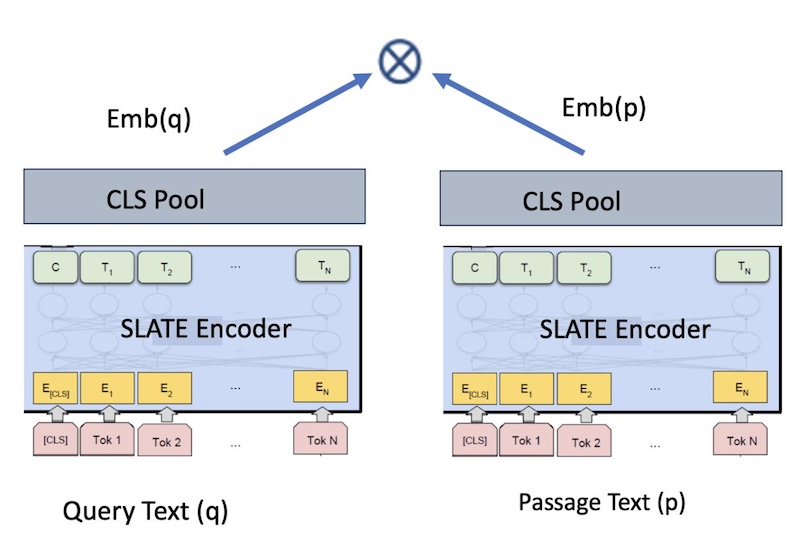
Figure 1. Bi-encoder Embeddings Model for Retrieval
Base language model
The underlying Language Model (LM) for our embeddings is slate.125m.english (formerly, known as WatBERT). It has the same architecture as a RoBERTa base transformer model and has ~125 million parameters and an embedding dimension of 768. Our final model is called “slate.125m.english.rtrvr” - notice the suffix at the end denoting that we fine-tune the underlying model architecture for retrieval-based tasks.
Training algorithm
Most embedding models that are either state-of-the-art or at the top of the MTEB leaderboard are typically trained in 3 stages:
- Task Specific (retrieval-based) pre-training
- Task specific fine-tuning on mined pairs
- Fine-tuning on supervised pairs.
We follow the same approach and finally perform a model fusion by averaging the weights of different trained models.
slate.125m.english.rtrvr is produced by performing “model fusion” - averaging the weights of the following models, both trained in stages but having the following variations:
- Model 1 fine-tuned with large scale unsupervised data
- Model 2 fine-tuned with a smaller subset of supervised data
Task-specific pre-training
This stage uses the RetroMAE framework, to make our underlying LM more retrieval oriented. We initialize our base LM with slate.125m.english and continue with RetroMAE pre-training, using the data in Table 1. Our hyper-parameters are: learning rate: 2e-5, number of steps: 190000, GPUs: 24 A100 40GB. Note: this is our base LM for the following 2 stages.
Model1: Fine-tuning with large scale unsupervised data
This model is initialized with the RetroMAE pre-trained model and is trained in 2 stages.
Stage 1: Unsupervised fine-tuning
We use a bi-encoder framework for training an embedding model, as in Figure 1. The RetroMAE pre-trained LM is fine-tuned with <query, passage> text pairs using a contrastive loss objective. We mine large scale pairs from
various domains, as indicated in Table 2. The model is trained with diverse pairs, including classification tasks such as NLI (Natural Language Inference) which consists of matching a premise to the corresponding hypothesis. Our hyper-parameters
are: learning rate: 2e-5; number of steps: 140000; GPUs: 8 A100_80GB, effective batch size: 4096 pairs
Stage 2: Supervised fine-tuning
Finally, the model is fine-tuned with high-quality supervised training pairs for the retrieval task on the following datasets: SQuAD, Natural Questions, Specter, Stack Exchange (Title, Body) pairs, S2ORC, SearchQA, HotpotQA and Fever. Training hyper-parameters are learning rate: 2e-5; number of steps: 10000; GPUs: 8 A100_80GB, effective batch size: 4096 pairs.
Model 2: Fine-tuning with a more task-focused subset
In this stage, the RetroMAE pre-trained model undergoes supervised finetuning with a smaller subset of Table2 with supervision coming from hard negative mining. The intermediate model checkpoints are iteratively used to mine dataset specific hard negatives, which are then used for supervised finetuning. This process aims to make the model more robust by letting it learn from its own mistakes and helps in stabilizing with much smaller data.
We fine-tune the model by using a subset of datasets (as found via performing validation experiments on a held-out dataset) mentioned in Table2 which are as follows: AllNLI, Squad, Stackexchange, NQ, HotpotQA, Fever and 5M subset from each of Specter, S2orc, WikiAnswers.
Training hyper-parameters are learning rate: 2e-5; max query length: 512; max passage length: 512; epochs: 2; effective batch size: 384 triples; GPUs: 24 A100_80GB.
Our final model: slate.125m.english.rtrvr: Model fusion
We perform model fusion by averaging the model weights (from the above) trained with large scale unsupervised data and the model trained with the smaller subset of supervised data.
We use a dev set (https://huggingface.co/datasets/colbertv2/lotte) and perform grid search for obtaining the optimal weight combination for these models. We average the model weights based on the optimal param: 0.7 for Model1 and 0.3 for Model2.
Training Data
| Dataset | Passages |
|---|---|
| Wikipedia | 36396918 |
| Books Corpus | 3401308 |
| Stack Exchange | 15999837 |
| Dataset | Pairs |
|---|---|
| SPECTER citation triplets | 684100 |
| Stack Exchange Duplicate questions (titles) | 304525 |
| AllNLI (SNLI and MultiNLI) | 277230 |
| Stack Exchange Duplicate questions (bodies) | 250519 |
| Stack Exchange Duplicate questions (titles+bodies) | 250460 |
| Natural Questions (NQ) | 100231 |
| SQuAD2.0 | 87599 |
| PAQ (Question, Answer) pairs | 64371441 |
| Stack Exchange (Title, Answer) pairs | 4067139 |
| Stack Exchange (Title, Body) pairs | 23978013 |
| Stack Exchange (Title+Body, Answer) pairs | 187195 |
| S2ORC Citation pairs (Titles) | 52603982 |
| S2ORC (Title, Abstract) | 41769185 |
| S2ORC_citations_abstracts | 52603982 |
| WikiAnswers Duplicate question pairs | 77427422 |
| SearchQA | 582261 |
| HotpotQA | 85000 |
| Fever | 109810 |
| Arxiv | 2358545 |
| Wikipedia | 20745403 |
| PubMed | 20000000 |
Usage
# Make sure the sentence transformers is installed.
pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('path_to_slate_model')
input_queries = [
'Who made the son My achy breaky heart ?',
'summit define']
input_passages = [
"Achy Breaky Heart is a country song written by Don Von Tress. Originally titled Don't Tell My Heart and performed by The Marcy Brothers in 1991",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
query_embeddings = model.encode(input_queries)
passage_embeddings = model.encode(input_passages)
print(util.cos_sim(query_embeddings, passage_embeddings))
The maximum sequence length of this model is 512 tokens.
Evaluation
Baselines
For a fair comparison, we compare with the following baselines:
- BM25 (a traditional model based on tf-idf).
- ELSER (a commercial search algorithm provided by Elastic).
- all-MiniLM-l6-v2: a popular open-source sentence transformers model. This model shares the same architecture as slate.125m.english.rtvr, with a smaller embedding dimension and has been trained on more data without commercial-friendly licenses. Huggingface model card (https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) for more details.
- E5-base: a recent open-source transformer model with very good performance on the BEIR benchmark. This is a base-sized model, which has the same architecture as slate.125m.english.rtvr. [Reference: Wang et.al., 2022: Text Embeddings by Weakly-Supervised Contrastive Pre-training]. Huggingface model card (https://huggingface.co/intfloat/e5-base).
- E5-small: a smaller model within the open source E5 family. The embedding dimension of this model matches that of all-minilm-l6-v2 (384), however it has 12 layers, and thus is larger and slightly slower. [Reference: Wang et.al., 2022: Text Embeddings by Weakly-Supervised Contrastive Pre-training]. Huggingface model card (https://huggingface.co/intfloat/e5-small).
- BGE-base: a recent open-source transformer model with the best performance on the BEIR benchmark for the 768 embedding size (as of 01.20.2024). Huggingface model card (https://huggingface.co/BAAI/bge-base-en-v1.5).
Our Evaluation benchmark: BEIR (MTEB’s retrieval tab)
The BEIR benchmark contains 15 open-source retrieval tasks focused on different domains including nine different retrieval tasks: Fact checking, citation prediction, duplicate question retrieval, argument retrieval, news retrieval, question answering, tweet retrieval, bio-medical IR, and entity retrieval. Further, it includes datasets from diverse text domains, datasets that cover broad topics (like Wikipedia) and specialized topics (like COVID-19 publications), different text types (news articles vs. Tweets), datasets of various sizes (3.6k - 15M documents), and datasets with different query lengths (average query length between 3 and 192 words) and document lengths (average document length between 11 and 635 words). The performance of all models are noted in the table below. BEIR uses the Normalized Cumulative Discount Gain (specifically, nDCG@10) metric for evaluation. This is the same evaluation that is used in the HuggingFace MTEB leaderboard but mainly focusing on retrieval tasks.
Long NQ
Long NQ is an IBM dataset designed for evaluating the full RAG pipeline, based on a subset of the NaturalQuestions dataset. The dev set has 300 answerable questions with a corpus of 178,891 passages from 2,345 Wikipedia documents. Long NQ also provides gold Wikipedia passages that are relevant for each question. During retrieval, the task is to obtain the relevant gold passage from the corpus for every question.
Results
| Model | BEIR-15 (NDCG@10) |
|---|---|
| BM25 | 42.02 |
| ELSER | 49.01 |
| all-miniLM-L6-v2 | 41.95 |
| ES-small | 46.01 |
| ES-base | 48.75 |
| BGE-base | 53.25 |
| slate.125m.english.rtrvr | 49.37 |
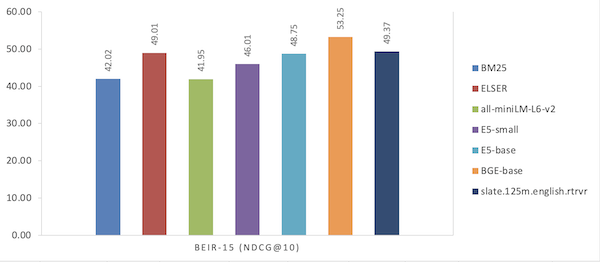
Figure 2. Performance comparison on the BEIR benchmark (MTEB retrieval tab)
| Model | LONGNQ (NDCG@10) |
|---|---|
| all-miniLM-L6-v2 | 58.10 |
| ES-small | 66.87 |
| ES-base | 63.95 |
| BGE-base | 61.29 |
| slate.125m.english.rtrvr | 65.01 |
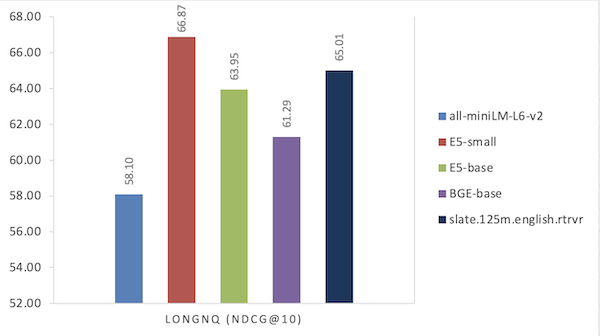
Figure 3. Performance comparison on the Long NQ dataset
Runtime Performance
The performance runtime is measured on a re-ranking task with 466 queries. For each query we re-rank the top-100 passages obtained by BM25 and we report the average time over all queries. The re-ranking was performed on a A100_40GB GPU.
| Model | Time/query |
|---|---|
| all-miniLM-L6-v2 | 0.18 sec |
| E5-small | 0.33 sec |
| E5-base | 0.75 sec |
| BGE-base | 0.75 sec |
| slate.125m.english.rtrvr | 0.71 sec |