Translation not up to date
Modele podstawowe w pliku IBM watsonx.ai umożliwiają generowanie dokładnych pod względem faktycznym danych wyjściowych, które są ugruntowane w informacjach znajdujących się w bazie wiedzy, poprzez zastosowanie wzorca generowania rozszerzonego pobierania.
Ten film wideo udostępnia metodę wizualną, która umożliwia poznanie pojęć i zadań w tej dokumentacji.
Rozdziały wideo
[ 0:08 ] Opis scenariusza
[ 0:27 ] Przegląd wzorca
[ 1:03 ] Baza wiedzy
[ 1:22 ] Komponent wyszukiwania
[ 1:41 ] Zachęta rozszerzona o kontekst
[ 2:13 ] Generowanie danych wyjściowych
[ 2:31 ] Pełne rozwiązanie
[ 2:55 ] Uwagi dotyczące wyszukiwania
[ 3:58 ] Uwagi dotyczące tekstu pytania
[ 5:01 ] Uwagi dotyczące wytłumaczalności
Zapewnienie kontekstu w pytaniu poprawia dokładność
Modele podstawowe mogą generować wyniki, które są niedokładne pod względem faktycznym z różnych powodów. Jednym ze sposobów poprawy dokładności generowanych danych wyjściowych jest udostępnienie wymaganych faktów jako kontekstu w tekście podpowiedzi.
Przykład
Poniższa zachęta obejmuje kontekst w celu ustalenia niektórych faktów:
Aisha recently painted the kitchen yellow, which is her favorite color.
Aisha's favorite color is
Chyba że Aisha jest sławną osobą, której ulubiony kolor został wymieniony w wielu artykułach online, które są zawarte w wspólnych zestawach danych pretraining, bez kontekstu na początku zachęty, żaden model fundament może niezawodnie wygenerować prawidłowe zakończenie zdania na końcu zachęty.
W przypadku pytania o model z tekstem, który zawiera kontekst wypełniony twarzą, dane wyjściowe generowane przez model są bardziej prawdopodobne. Więcej informacji na ten temat zawiera sekcja Generowanie dokładnych danych wyjściowych.
Wzorzec generowania rozszerzanego pobierania
Technikę uwzględniania kontekstu w pytaniach można skalować, korzystając z informacji w bazie wiedzy.
Na poniższym diagramie przedstawiono wzorzec generowania rozszerzonego pobierania. Chociaż diagram przedstawia przykład odpowiedzi na pytania, ten sam przepływ pracy obsługuje inne przypadki użycia.
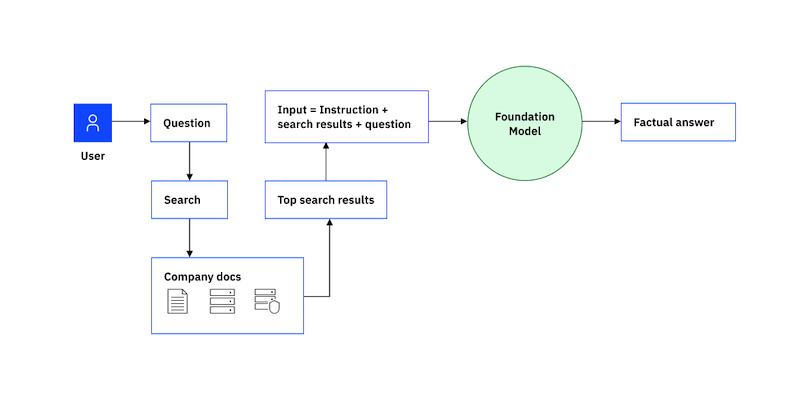
Wzorzec generowania rozszerzonego pobierania składa się z następujących kroków:
- Wyszukaj w bazie wiedzy treść związaną z danymi wejściowymi użytkownika.
- Pobierz najistotniejsze wyniki wyszukiwania do zachęty jako kontekst i dodaj instrukcję, na przykład "Odpowiedz na następujące pytanie, używając tylko informacji z następujących fragmentów".
- Tylko wtedy, gdy używany model podstawowy nie jest dostrojony do instrukcji: dodaj kilka przykładów demonstrujących oczekiwany format wejściowy i wyjściowy.
- Wyślij złożony tekst pytania do modelu, aby wygenerować wyniki.
Źródło generowania-rozszerzenie
W opracowaniu Retrieval-augmented generation for knowledge-intensive NLP taskswprowadzono termin retrieval-augmented generation (RAG).
"Budujemy modele RAG, w których pamięć parametryczna jest wstępnie wyszkolonym transformatorem seq2seq , a nieparametryczna pamięć jest gęstym indeksem wektorowym Wikipedii, dostępnym z wcześniej wyszkolonym pobieraniem neuronowym."
W tym opracowaniu termin "modele RAG" odnosi się do konkretnej implementacji programu pobierającego (specyficznego kodera zapytań i indeksu wyszukiwania dokumentów opartego na wektorach) i generatora (specyficznego wstępnie wytrenowanego, generatywnego modelu języka). Jednak podstawowe metody wyszukiwania i generowania mogą być uogólnione w celu użycia różnych komponentów programu pobierającego i modeli fundamentowych.
baza wiedzy
Baza wiedzy może być dowolną kolekcją artefaktów zawierających informacje, takich jak:
- Informacje o procesie w wewnętrznych stronach wiki firmy
- Pliki w produkcie GitHub (w dowolnym formacie: Markdown, zwykły tekst, JSON, code)
- Komunikaty w narzędziu do pracy grupowej
- Tematy w dokumentacji produktu
- Fragmenty tekstu w bazie danych, na przykład Db2
- Zbiór umów prawnych w plikach PDF
- Zgłoszenia obsługi klienta w systemie zarządzania treścią
Program pobierający
Program pobierający może być dowolną kombinacją narzędzi wyszukiwania i treści, które niezawodnie zwracają odpowiednią treść z bazy wiedzy:
- Narzędzia wyszukiwania, takie jak IBM Watson Discovery
- Funkcje API wyszukiwania i treści (na przykładGitHub ma takie interfejsy API)
- Wektorowe bazy danych (takie jak chromadb)
Generator
Komponent generatora może używać dowolnego modelu w pliku watsonx.ai, w zależności od tego, który z nich odpowiada przypadkowi użycia, formatowi pytania i treści pobieranej w celu uzyskania kontekstu.
Przykłady
Poniższe przykłady demonstrują zastosowanie wzorca generowania rozszerzanego.
| Przykład | Opis | Powiązanie |
|---|---|---|
| Proste wprowadzenie | Ten przykładowy notatnik korzysta z małej bazy wiedzy i prostego komponentu wyszukiwania, aby zademonstrować podstawowy wzorzec. | Wprowadzenie do pobierania-generowanie rozszerzone |
| Przykład ze świata rzeczywistego | Dokumentacja watsonx.ai zawiera funkcję wyszukiwania i odpowiedzi, która może odpowiedzieć na podstawowe pytania, korzystając z tematów w dokumentacji jako bazy wiedzy. | Odpowiadanie na pytania w pliku watsonx.ai przy użyciu modelu bazowego |
| Przykład z łańcuchem LangChain | Ten przykładowy notatnik zawiera kroki i kod, które mają na celu zademonstrowanie obsługi generowania danych przy użyciu łańcucha LangChain w pliku watsonx.ai. Wprowadza on komendy służące do pobierania danych, budowania bazy wiedzy oraz wykonywania zapytań i testowania modeli. | Użyj watsonx i LangChain , aby odpowiedzieć na pytania za pomocą usługi RAG |
| Przykład z łańcuchem LangChain i wektorową bazą danych Elasticsearch | Ten przykładowy notatnik demonstruje sposób użycia języka LangChain do zastosowania modelu osadzania do dokumentów w bazie danych wektorów usługi Elasticsearch . Następnie notatnik indeksuje i używa składnicy danych do generowania odpowiedzi na pytania przychodzące. | Użyj watsonx, Elasticsearchi LangChain , aby odpowiedzieć na pytania (RAG) |
| Przykład z pakietem Elasticsearch Python SDK | Ten przykładowy notatnik demonstruje sposób użycia pakietu SDK Elasticsearch Python w celu zastosowania modelu osadzania do dokumentów w bazie danych wektorowych usługi Elasticsearch . Następnie notatnik indeksuje i używa składnicy danych do generowania odpowiedzi na pytania przychodzące. | Użyj watsonxi Elasticsearch Python SDK, aby odpowiedzieć na pytania (RAG) |
Więcej inform.
Wypróbuj te kursy:
- Pytaj o model podstawowy przy użyciu narzędzia Prompt Lab (Laboratorium z pytaniami)
- Pytaj o model fundamentów z wzorcem generowania rozszerzania w celu pobrania
Temat nadrzędny: Modele Foundation