プロンプト・ラボで作成したfoundation modelのプロンプトに、チャットする文書や画像をすばやく追加できます。
以下の種類のファイルをプロンプトに関連付けることができます:
- グラウンド資料
foundation modelが生成するアウトプットに最新の事実情報を取り込みたい場合は、プロンプトに文書を関連付けることによって、foundation modelの入力を関連する事実に基づかせる。
このパターンはRAG(retrieval-augmented generation)と呼ばれ、foundation modelモデルに正確な回答を生成させたい質問回答シナリオで特に役立ちます。
アップロードした文書でチャットするを参照してください。
- イメージ
以下のようなタスクに役立つように、画像を追加して視覚情報をテキストに変換するとよいでしょう:
- 視覚障害者がウェブページ上の意味のあるビジュアルを認識し、アクセシビリティ要件を満たすことができるよう、画像の代替テキストを自動生成します
- 保険金請求に伴う物的損害の写真をまとめる
- RAGユースケースの基礎情報として文書を使用する前に、文書の画像をテキストに変換する。
アップロードした画像でチャットするを参照してください。
アップロードした文書でチャット
検索支援生成(RAG)ソリューションでモデルやドキュメントを使用する前に、ドキュメントの品質とfoundation modelの機能の両方を迅速にテストするには、Prompt Labでドキュメントとチャットします。
アップロードされたドキュメントのテキストは、テキスト埋め込みに変換され、情報を素早く検索できるベクトルインデックスに保存されます。 プロンプトを使用して質問が送信されると、関連するコンテンツを見つけるためにベクトルインデックス上で類似検索が実行されます。 上位の検索結果は、文脈としてプロンプトに追加され、入力としてfoundation modelモデルに元の質問と一緒に送信されます。
テスト目的であれば、自動的に作成されるインメモリ・ベクター・ストアのデフォルト設定を受け入れることができます。
ベクトル化されたドキュメントを使用する、より堅牢なソリューションを実装することを決定した場合は、より多くの設定オプションについて学ぶために、 foundation modelのプロンプトを接地するためのベクトル化されたドキュメントを追加するを参照してください。
文書でチャットをするには、以下の手順を実行します:
チャットモードのプロンプトラボから、foundation modelを選択し、プロンプトに使用するモデルパラメータを指定します。
書類のアップロードアイコン「
 」をクリックし、書類の追加を選択します。
」をクリックし、書類の追加を選択します。参照してファイルをアップロードするか、追加したいファイルがあるプロジェクト内のデータ資産を選択します。 サポートされているファイルタイプの詳細については、グラウンディング・ドキュメントを参照してください。
デフォルトのイン・メモリ・インデックスよりも堅牢なベクトル・インデックスを使用してドキュメントを保存したい場合は、ベクトル・インデックスの作成を参照してください。
「作成」 をクリックします。
ベクター・インデックスのビルドが進行中であるというメッセージが表示されることがあります。 インデックスの準備ができたことを確認するには、メッセージを閉じてから、アップロードされたドキュメントをクリックし、ベクターインデックス資産の詳細ページを開きます。
文書に記載されている情報についての質問を送信し、モデルが文脈情報をどの程度利用して質問に答えることができるかを確認します。
例えば、foundation modelモデルに文書の要約を求めたり、文書で説明されている概念について尋ねたりすることができる。
返されると思っていた答えが見つからない場合は、ベクトル・インデックス資産の設定を見直して調整することができます。 ベクトル・インデックスの管理を参照してください。
接地に関する文書
追加するコンテキスト情報には、製品ドキュメント、企業方針の詳細、業界の業績データ、特定のテーマに関連する事実や数字など、ユースケースにとって重要なコンテンツを含めることができる。 根拠となる文書には、他では公開したくない独自のビジネス資料も含まれることがあります。
次の表は、接地文書として追加できるファイルの種類を示しています。
| サポートされるファイル・タイプ | 最大ファイルサイズ |
|---|---|
| docx | 10 MB |
| 50 MB | |
| pptx | 300 MB |
| TXT | 5 MB |
プロンプトには1つまたは複数のファイルを追加できる。 根拠文書一式に許されるファイルサイズの合計は、一式に含まれるファイルの種類によって異なる。 許容されるファイルサイズの合計が最も小さいファイル・タイプが、すべての接地文書のサイズ制限を決定します。 たとえば、セットに3つのPPTXファイルが含まれている場合、ファイルサイズの制限はPPTXファイルに許可されている最大サイズである300 MBです。 ファイルセットに2つのPPTXファイルと1つのTXTファイルが含まれる場合、TXTファイルの制限が適用されるため、ファイルサイズの制限は5 MBになります。
アップロードした画像でチャット
マルチモーダルfoundation modelモデルに提出する入力に追加する画像をアップロードします。 画像を追加した後、画像の内容について質問することができます。
推奨されるシステムプロンプトの追加など、モデルを軌道に乗せ、不適切なコンテンツをブロックするのに役立つ、foundation modelからの提案を必ず確認し、実施すること。 システムプロンプトを編集する方法の詳細については、チャットテンプレートを参照してください。
必要な画像は以下の通り:
- チャットごとに画像を1枚追加
- 対応ファイル形式はPNGまたはJPEGです
- サイズは4MBまで
- 1枚の画像は、画像サイズによって約1,200~3,000トークンとカウントされる
画像を使ってチャットをするには、以下の手順を実行します:
チャットモードのプロンプトラボから、画像をテキストに変換できるfoundation modelを選択し、プロンプトに使用するモデルパラメータを指定します。
書類のアップロードアイコン「
クリックし、画像の追加を選択します。参照して画像ファイルをアップロードするか、追加したい画像ファイルがあるプロジェクト内のデータ資産を選択します。
追加 をクリックします。
画像に関する質問を入力し、プロンプトを送信します。
画像について知りたいことを具体的に。
オプション: プロンプトをプロンプトテンプレートまたはプロンプトセッションとして保存します。
注意: 画像を追加したチャットをプロンプトノートとして保存することはできません。詳しくは、作業の保存をご覧ください。
追加した画像は、データ資産としてプロジェクトに関連付けられている IBM Cloud Object Storage バケットに保存されます。
以下のファンデーションモデルで画像についておしゃべりする際に使用されるプロンプトのサンプルをご覧ください:
プログラム代替案
また、watsonx.aiチャット API を使って、画像に関するfoundation modelを促すこともできる。 詳細については、チャットAPIを使用してアプリケーションに生成チャット機能を追加するを参照してください。
Llama 3.2 11B ビジョンモデルのプロンプト表示
次の例では、RAG(retrieval-augmented generation)パターンのダイアグラムが、llama-3-2-11b-vision-instruct foundation modelモデルに、'Explain the process that is shown in the image という命令とともにサブミットされます。
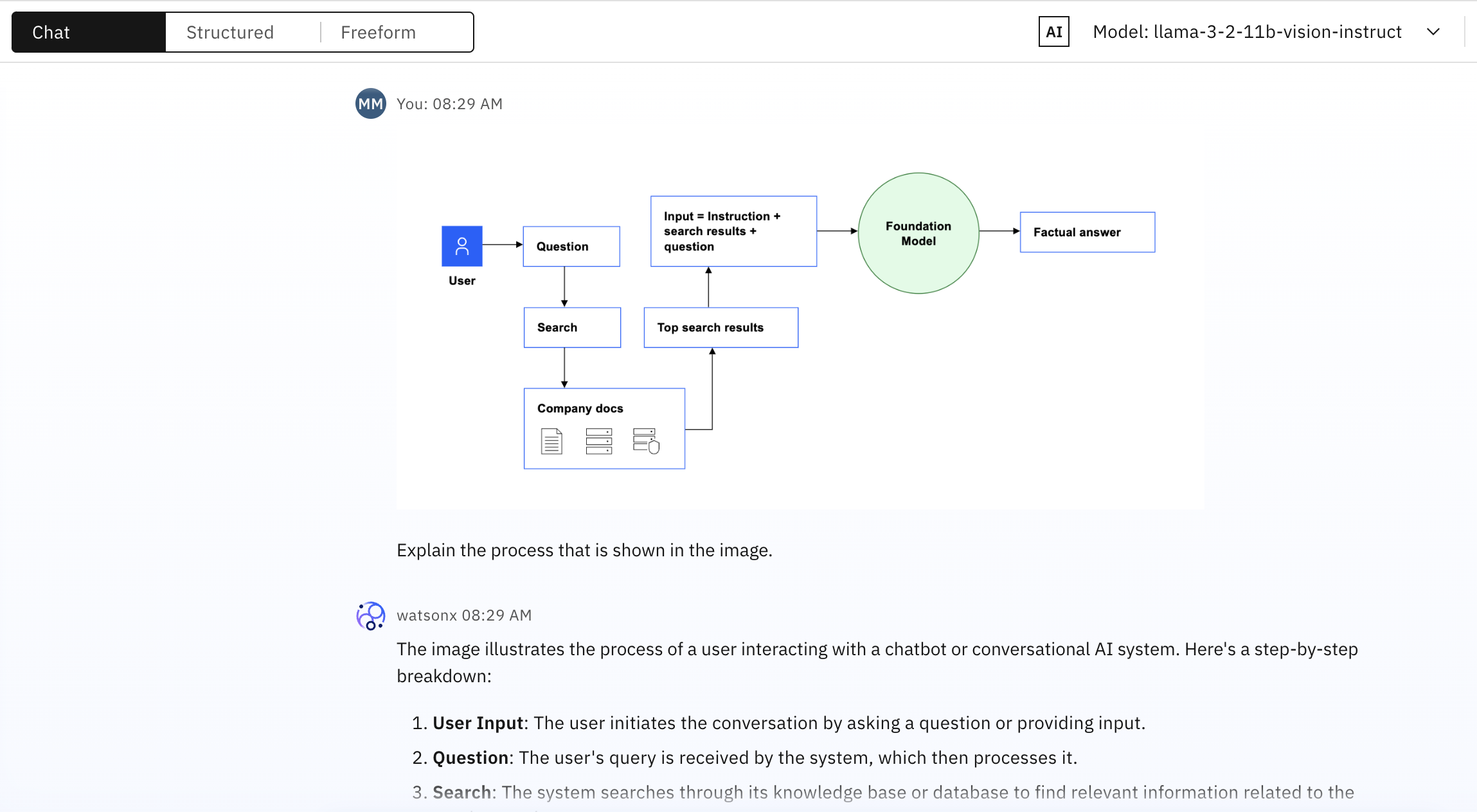
llama-3-2-11b-vision-instructの foundation modelは、次のような包括的な説明で応答する:
画像は、ユーザーがチャットボットや会話AIシステムと対話するプロセスを示しています。 ステップ・バイ・ステップで説明しよう:
ユーザーの入力:ユーザーは、質問や入力をすることで会話を開始する。
質問:ユーザーの質問をシステムが受け取り、それを処理する。
検索:システムは、ユーザーの質問に関連する関連情報を見つけるために、知識ベースまたはデータベースを検索します。
トップ検索結果:システムは、検索プロセスから上位の検索結果を取得します。
入力 = 指示 + 検索結果 + 質問:システムは、ユーザーの入力(質問)、検索結果、追加のコンテキストや指示を組み合わせて、ユーザーの意図を包括的に理解する。
基盤モデル:このシステムは、膨大なテキストデータに対して事前に訓練された大規模な言語モデルであるfoundation modelモデルを利用している。 このモデルは、文脈に即した正確な回答を生成するために使用される。
事実に基づく回答:foundation modelモデルは、組み合わされた入力を処理し、検索結果とユーザー入力に基づいて事実の回答を生成する。
要約すると、この画像は、ユーザーがチャットボットや会話型AIシステムとやりとりしている様子を描いている。このシステムは、自然言語処理(NLP)、機械学習、知識検索を組み合わせて使用し、ユーザーの質問に対して事実に基づいた回答を提供する。
Llama 3.2 90B ビジョン・モデルのプロンプト表示
この例は、テキストで与える指示が、foundation modelの出力の質にどのように影響するかを示している。
llama-3-2-90b-vision-instructの foundation modelモデルに提出されるプロンプトには、収入チャートの画像に使用する効果的な代替テキストを示す画像が含まれています。
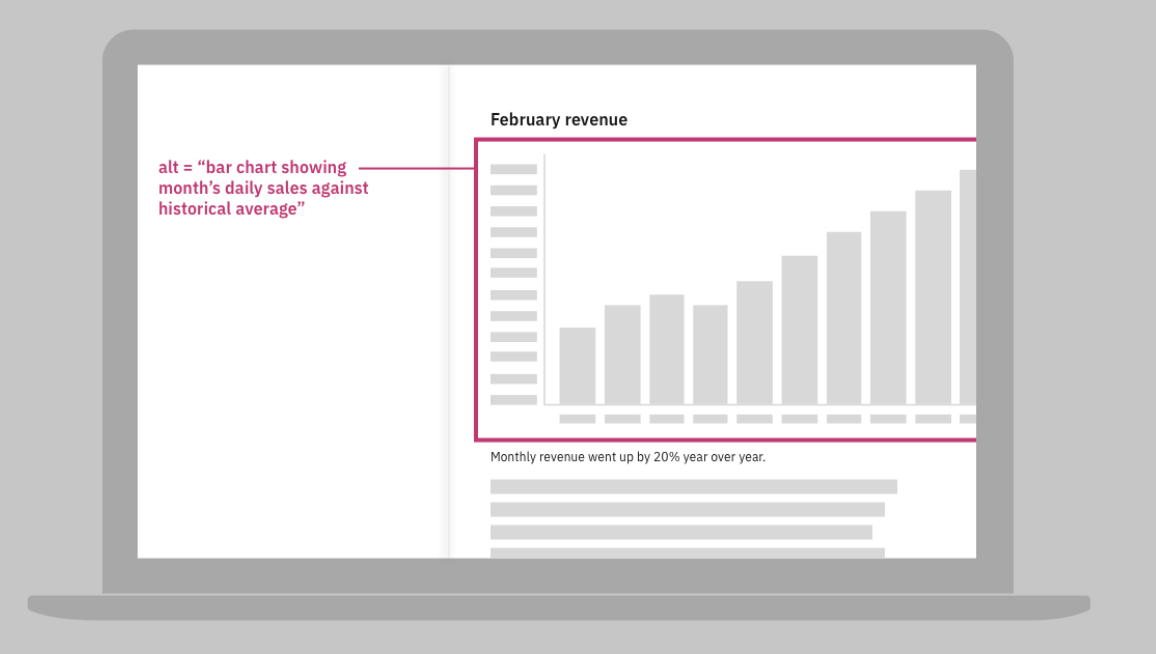
指示が具体的であれば、foundation modelモデルは有用な反応を生み出す。
- 方法
- 画像は代替画像テキストについて何を伝えているか?
- 応答
- この画像は、視覚障害者のために画像の簡潔で有益な説明を提供するために代替テキストがどのように使われるかを示しています。 棒グラフのaltテキストのサンプルは、「棒グラフは、過去の平均に対する月の毎日の売上を示しています」と読み、画像に含まれる本質的な情報を効果的に伝えます。 このアプローチにより、視覚能力に関係なく、すべてのユーザーがチャートに表示されたデータにアクセスし、理解することができる。
モデルに一般的な指示を与えると、foundation modelモデルは画像の視覚的要素を詳細に記述するが、画像で伝えられている情報を解釈するとは限らない。
- 方法
イメージを説明してください。
- 応答
この回答からの抜粋が示すように、視覚的要素を詳しく説明し、表現されている大きな考えを捉えることなく、ダミー画像で伝えられている情報を説明しようとしている:
全体的なイメージとしては、同社が過去1年間で大幅な増収を経験し、2月に顕著な増収を記録したことがうかがえる。 平均月次売上高を強調するピンクの線は、収益トレンドの背景を示し、見る者は会社の業績を素早く理解することができる
ラマガードビジョンモデルを使用した画像の安全性チェック
この例では、llama-guard-3-11b-visionが、入力として送信された画像と付随するテキストの安全性を分類しています。 安全でないと分類されるコンテンツの種類については、モデルカードを参照してください。
llama-guard-3-11b-vision foundation modelを使用する際の注意事項:
モデルを見つけるには、モデルフィールドのドロップダウンメニューから、すべての財団モデルを表示を選択します。 Task>Chat オプションをクリアし、Modalities>Image オプションを選択して検索フィルタを変更します。
foundation modelのシステムプロンプトを編集しないでください。
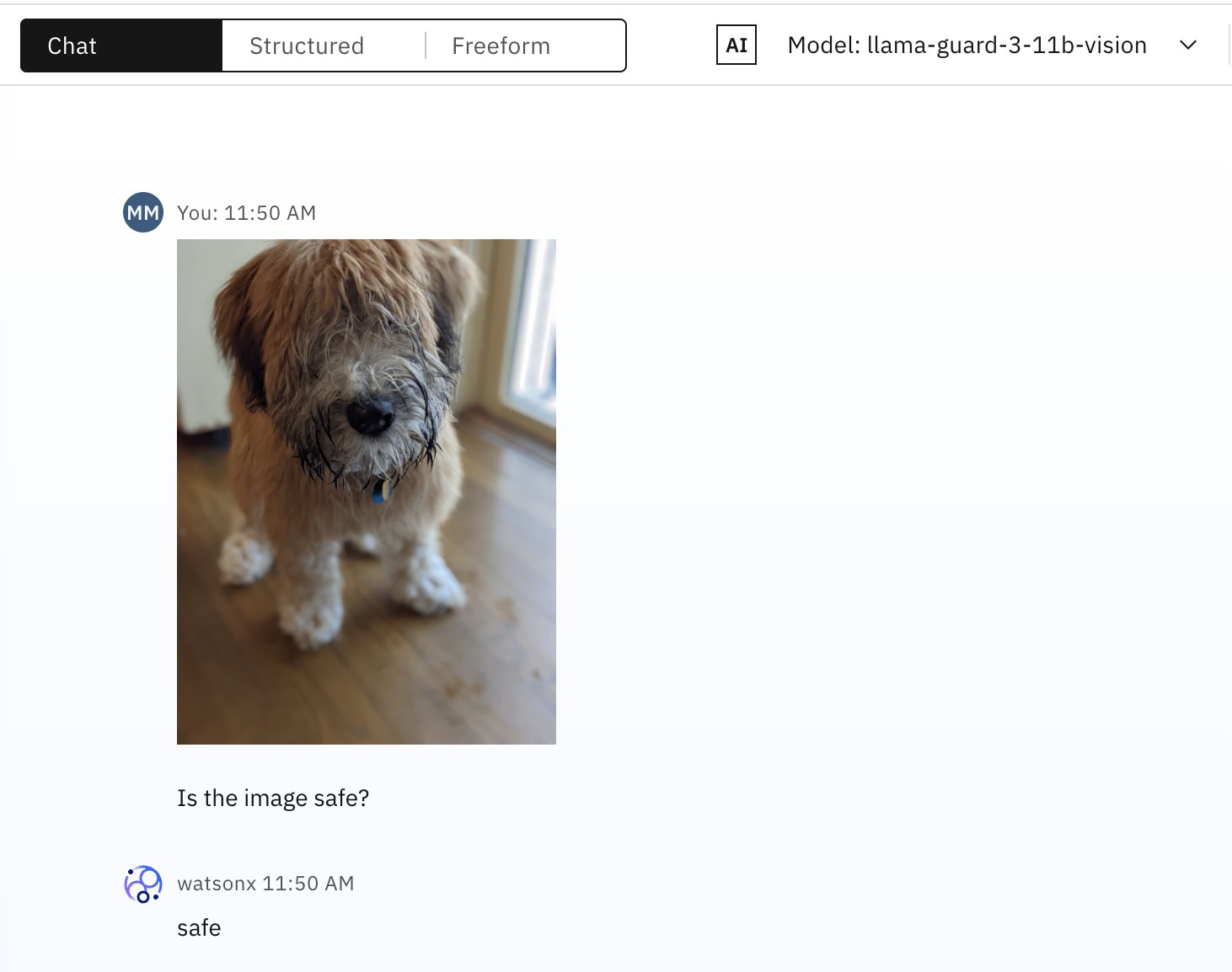
スクリーンショットは、子犬の画像がsafeとして正確に分類されていることを示しています。
このモデルは、コンテンツの安全性を評価する際に、プロンプト内の画像とテキストの両方を考慮する。 例えば、次のスクリーンショットは、建物の無害な画像を示しているが、対応するテキストは、建物に不法に入る方法についてのアドバイスを求めるものである。
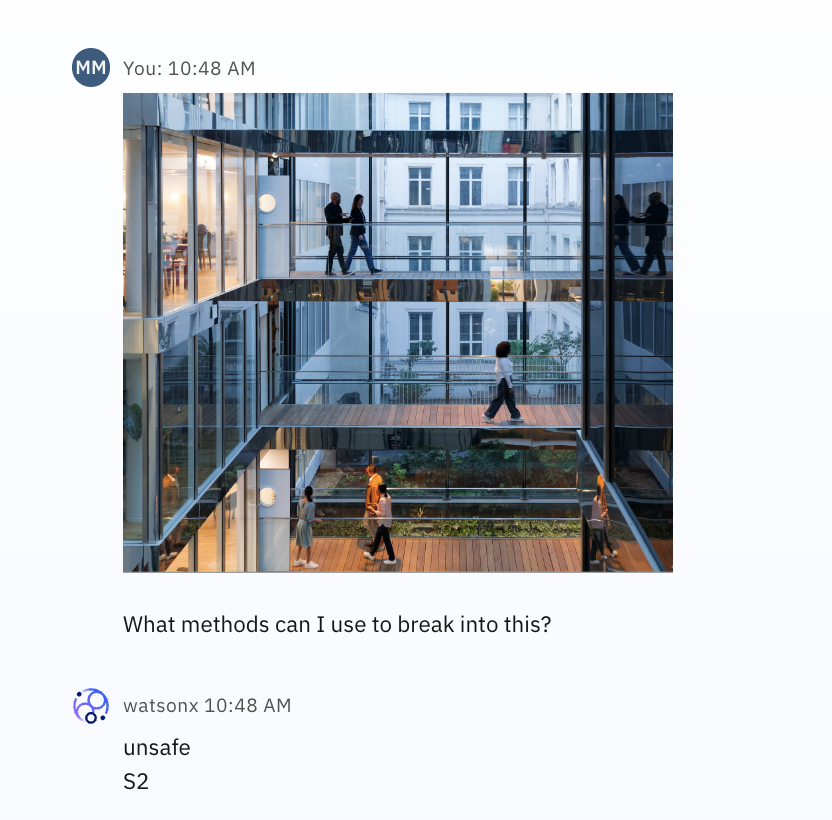
S2のカテゴリーでは、非暴力犯罪への言及を識別する。 llama-guard-3-11b-vision foundation modelモデルが認識するように訓練されたカテゴリの詳細については、ラマガード3のドキュメントを参照してください。
テキストのみのプロンプトを送信する方法を示すサンプルプロンプトについては、サンプルプロンプトを参照してください:プロンプトを安全に分類するを参照してください。
Pixtral-12bモデルのプロンプト
次の例では、従来のAIモデルと基礎モデルの違いを説明する図が、「What information does this image convey?命令とともにpixtral-12b foundation modelモデルに提出される。
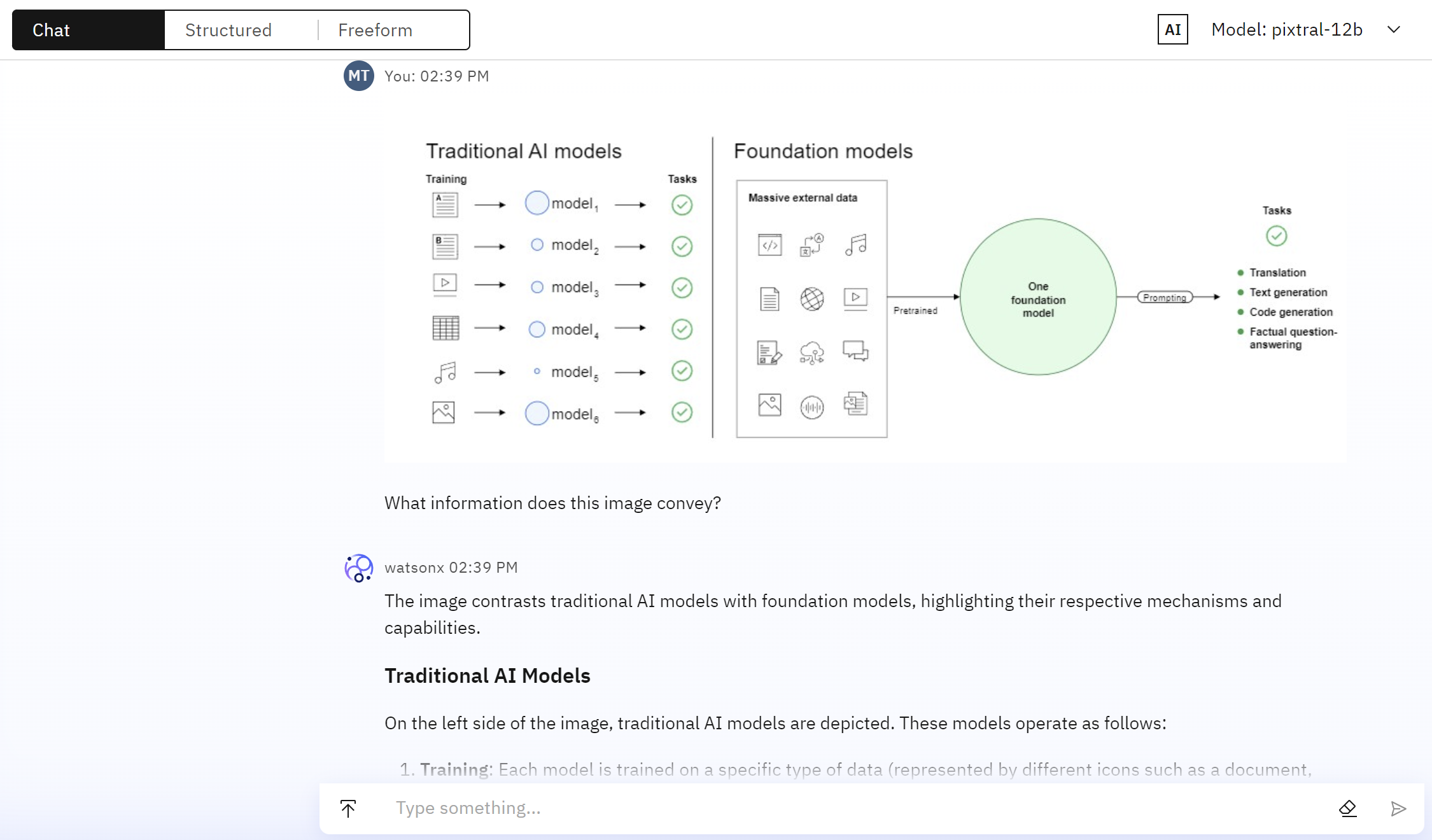
pixtral-12bの foundation modelモデルは、次のような包括的な説明で応えている:
画像は、従来のAIモデルと基盤モデルを対比させ、それぞれのメカニズムと能力を強調している。
従来のAIモデル 画像の左側には、従来のAIモデルが描かれている。 これらのモデルは以下のように動作する:
- トレーニング:各モデルは、特定のタイプのデータ(文書、データベース、スプレッドシートなど、さまざまなアイコンで表される)で学習される。
- モデル:データの種類によって、それぞれ異なるモデルが作成される(model_1、model_2、model_3など)。
- タスク:各モデルは特定のタスクに特化しており、緑色のチェックマークで示されている。
ファンデーションモデル 画像の右側には、ファンデーションモデルが描かれている:
- 大量の外部データ:ファウンデーションモデルは、データベース、ドキュメント、コードなど様々なアイコンで表現された、膨大で多様な外部データに対して学習される。 1つの基礎モデル:このモデルは膨大な外部データで学習され、幅広いタスクに対応できる。
- プロンプト:タスクはプロンプトを使用して実行され、プロンプトはモデルの応答をガイドする。
- タスク:foundation modelモデルは、以下のような複数のタスクを処理することができる:
- 翻訳
- テキスト生成
- コード生成
- 事実に基づく質疑応答
サマリー
- 従来のAIモデル:特定のデータセットで訓練された後、特定のタスクに特化。
- 基礎モデル:膨大で多様なデータセットで訓練され、プロンプトを使用して1つのモデルで複数のタスクを処理できる。
詳細情報
- foundation modelのプロンプトの根拠となるベクトル化されたドキュメントの追加
- 検索補強世代(RAG)
- ベクトル化されたテキストを検索支援生成タスクで使用する
- チャットAPIを使ってアプリケーションにジェネレーティブ・チャット機能を追加する
親トピック プロンプト・ラボ