Text that you extract from a document or image file by using the text extraction API is written to a JSON file that contains details about various textual and visual elements in the document. You can further process the generated JSON to extract the information you want.
The following JSON objects are always returned when text is extracted by using the text extraction API. The structures within these root objects are optional, meaning they may or may not be returned in the output.
The stylesstyles
You can write code to extract text from the structures of interest to you. For more information, go to the following sections:
- How paragraphs are represented
- How text from images is represented
- How lists are represented
- How tables are represented
For details about the JSON schema, go to Text extraction JSON schema.
Metadata
The metadata
num_pagestitlekeywordsauthorpublication_datesubjectcharset
The following JSON output is an example of the metadata object structure for a PDF file.
"metadata":{
"num_pages":28,
"title":"Put AI to work for HR and talent transformation for the retail industry",
"keywords":"",
"author":"IBM",
"publication_date":"",
"subject":"Apply AI capabilities to drive your HR and talent transformation and generate better business outcomes in the retail industry.",
"charset":"UTF-8"
}
Structures
There are two keys that refer to the data structures in the parsed document:
top_level_structuresall_structures
The all_structures
sectionssection_titleslistslist_itemslist_identifierstablestable_rowstable_cellstokenssubscriptssuperscriptsfootnotesparagraphs
Working with the extracted JSON
You can use a JSON processor library to extract the text from different structures in the generated JSON file.
The following command returns the number of pages in the PDF, which is a value that is stored in a single JSON object:
cat output_retail.json | jq '.metadata.num_pages'
For some structures, such as tables and lists, the extracted text is stored in various objects within the generated JSON. You can use code to traverse the objects and extract the text of interest to you.
How paragraphs are represented
A single paragraph is most commonly associated with multiple tokens in sequence, where each token represents one word.
In some cases, paragraphs are associated with other structures, such as sections and lists.
The following JSON output illustrates how a paragraph and tokens are related in the sentence, Collect, organize, grow data when the text is extracted from a PDF.

//The section is listed in the top_level_structures array.
"top_level_structures":["PARA_fbdcdd",...,"SECTION_a2ab08",...],
//The section has a list of parapraphs.
{"id":"SECTION_9a3dda","parent_id":"SECTION_a2ab08","children_ids":["PARA_09384c",...
//The paragraph contains a section title.
{"id":"PARA_09384c","parent_id":"SECTION_9a3dda",
"text_alignment":"left","children_ids":["SECTION_TITLE_a5e3c2"],
//Token IDs listed for the section title.
{"id":"SECTION_TITLE_a5e3c2","parent_id":"PARA_09384c",
"text_alignment":"TBD","children_ids":[
"TOKEN_48bbae","TOKEN_cc0b9c","TOKEN_d57d27","TOKEN_a7d6da"
]},
//Consecutive tokens with a shared parent_id contain the text from the sentence of interest.
{"id":"TOKEN_48bbae","parent_id":"SECTION_TITLE_a5e3c2","style_id":"IBM_Plex_Sans_Light_Black_32_0",
"text":"Collect,",
"bbox":{"page_number":8,"x":283.0,"y":775.2945,"width":106.43201,"height":21.44}},
{"id":"TOKEN_cc0b9c","parent_id":"SECTION_TITLE_a5e3c2","style_id":"IBM_Plex_Sans_Light_Black_32_0",
"text":"organize,",
"bbox":{"page_number":8,"x":396.984,"y":775.2945,"width":126.78082,"height":21.44}},
{"id":"TOKEN_d57d27","parent_id":"SECTION_TITLE_a5e3c2","style_id":"IBM_Plex_Sans_Light_Black_32_0",
"text":"grow",
"bbox":{"page_number":8,"x":531.31683,"y":775.2945,"width":69.823975,"height":21.44}},
{"id":"TOKEN_a7d6da","parent_id":"SECTION_TITLE_a5e3c2","style_id":"IBM_Plex_Sans_Light_Black_32_0",
"text":"data",
"bbox":{"page_number":8,"x":608.6928,"y":775.2945,"width":62.880005,"height":21.44}},
How text from images is represented
When you submit a PDF file with images or an image file to the text extraction method of the watsonx.ai API, the text from the image is represented by tokenstokensparagraphsection
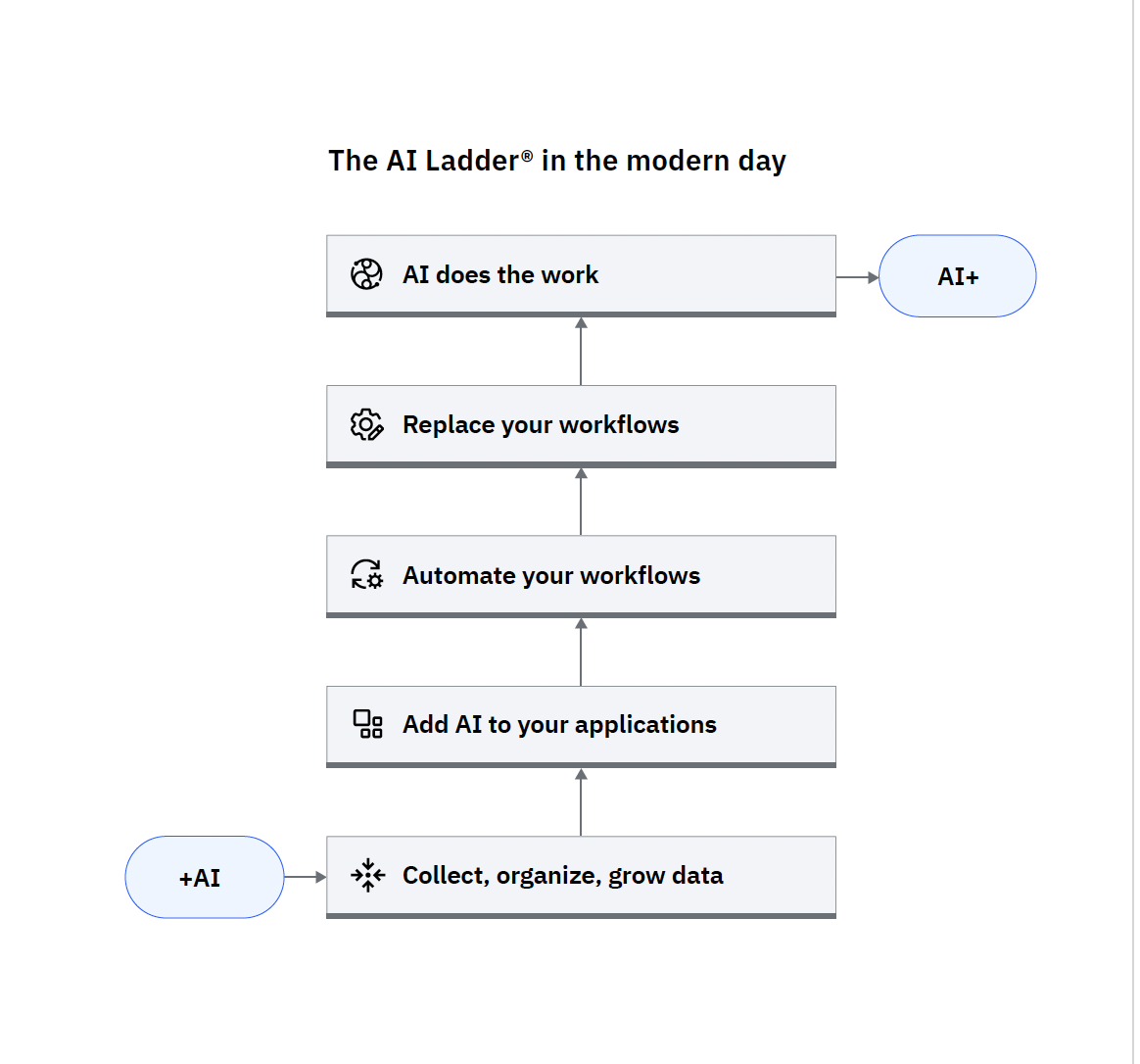
The following JSON excerpt illustrates how a PNG file that you submit to the text extraction method is represented in JSON output. The paragraphs objects that contain the text tokens are available from both the top_level_structuresall_structures
"top_level_structures":
[
"PARA_bc9320","PARA_8e9e62","PARA_b7f5cc","PARA_c75980","PARA_61a6a5","PARA_c8c2a8","PARA_8b8dd6","PARA_8c7c77","PARA_61aa92","PARA_1e6d2a","PARA_6eaa8d","PARA_cc6df5","PARA_4a9fb2"
],
"all_structures":{"sections":[],"section_titles":[],"lists":[],
"list_items":[],"list_identifiers":[],"tables":[],"table_rows":[],
"table_cells":[],"subscripts":[],"superscripts":[],"footnotes":[],
"paragraphs":
[
{"id":"PARA_bc9320","parent_id":"root","text_alignment":"center",
"children_ids":["TOKEN_132783","TOKEN_f0e333","TOKEN_dd48c3",
"TOKEN_c9b25e","TOKEN_080303","TOKEN_ce1aa0","TOKEN_97bf62"]...
{"id":"PARA_8e9e62","parent_id":"root",...
...
{"id":"PARA_4a9fb2","parent_id":"root",...
]
The extracted text is specified in the tokens within the paragraph. The following tokens represent the words The AI Ladder® from the image as follows:
"tokens":[
{"id":"TOKEN_132783","parent_id":"PARA_bc9320","style_id":"Arial_Black_10_0",
"text":"The","bbox":{"page_number":1,"x":250.65,"y":109.3,"width":38.880005,"height":21.48999}},
{"id":"TOKEN_f0e333","parent_id":"PARA_bc9320","style_id":"Arial_Black_10_0",
"text":"AI","bbox":{"page_number":1,"x":295.82,"y":114.67,"width":24.109985,"height":16.290009}},
{"id":"TOKEN_dd48c3","parent_id":"PARA_bc9320","style_id":"Arial_Black_10_0",
"text":"Ladder®","bbox":{"page_number":1,"x":325.74,"y":110.24,"width":82.66,"height":22.030006}}
How lists are represented
The structure of a list is represented by three separate objects that are part of the all_structures
listslist_itemslist_identifiers
The following JSON output illustrates how the text - Providing transparency in the first bullet of a list is represented.

//The lists object contains the list where the listitem is located.
"lists":[{"id":"LIST_ed036e","parent_id":"SECTION_9a3dda","children_ids":[
"LISTITEM_c802c4",...
//The list_item object contains the list item which contains a list ID followed by several tokens.
"list_items":[{"id":"LISTITEM_c802c4","parent_id":"LIST_ed036e","children_ids":[
"LIST_ID_781ee7","TOKEN_1df44f","TOKEN_1bcdbf",...
//The list_identifiers object contains list IDs with tokens.
"list_identifiers":[{"id":"LIST_ID_781ee7","parent_id":"LISTITEM_c802c4",
"children_ids":["TOKEN_4a66cb"]}
//The list ID token includes a token with a hyphen.
{"id":"TOKEN_4a66cb","parent_id":"LIST_ID_781ee7","style_id":"IBM_Plex_Sans_Black_20_0",
"text":"–","bbox":{"page_number":10,"x":994.0,"y":500.36,"width":11.76001,"height":13.639999}}
//The list item tokens include the text *Providing transparency* in them.
{"id":"TOKEN_1df44f","parent_id":"LISTITEM_c802c4","style_id":"IBM_Plex_Sans_Black_20_0",
"text":"Providing","bbox":{"page_number":10,"x":1014.0,"y":500.36,"width":83.55994,"height":13.639999}},
{"id":"TOKEN_1bcdbf","parent_id":"LISTITEM_c802c4","style_id":"IBM_Plex_Sans_Black_20_0",
"text":"transparency","bbox":{"page_number":10,"x":1102.2799,"y":500.36,"width":117.95801,"height":13.639999}}...
The following Python code extracts text from a list and rebuilds the list to illustrate how you can loop through the list items to extract token text.
# Import required libraries
import json
import numpy as np
import pandas as pd
# Define helper functions
## Function, which finds entry in collection by key-value pair
def find_by_key(key: str, value, collection: list, unique=True):
find = list(filter(lambda x: x[key] == value, collection))
if unique:
if len(find) > 1:
raise ValueError(f"Found non-unique key-value pair.\n{find}")
return find[0]
else:
return find
## Function, which flattens iterable collection of dicts
def flatten_collection(collection):
result = []
for val in collection.values():
result.extend(val)
return result
# Load the file with the extracted text
with open("/Users/janedoe/Downloads/output_retail.json") as f:
raw_output = json.load(f)
# Get all list-related structures
all_lists = raw_output['all_structures']['lists']
all_list_items = raw_output['all_structures']['list_items']
all_list_identifiers = raw_output['all_structures']['list_identifiers']
# Get all list items from the first list in the file
list_1 = all_lists[0]
list_1_items = []
for list_item_id in list_1['children_ids']:
list_1_items.append(find_by_key('id', list_item_id, all_list_items))
# Reconstruct the list
recon_list = []
flat_col = flatten_collection(raw_output['all_structures'])
for list_item in list_1_items:
val = []
for list_value_id in list_item['children_ids']:
list_value = find_by_key('id', list_value_id, flat_col)
#print(list_value['id'])
if list_value['id'].startswith("LIST_ID"):
for list_id_value_id in list_value['children_ids']:
list_id_value = find_by_key('id', list_id_value_id, flat_col)
if 'text' in list_id_value:
val.append(list_id_value['text'])
elif list_value['id'].startswith("PARA"):
val.append("\n")
for para_value_id in list_value['children_ids']:
para_value = find_by_key('id', para_value_id, flat_col)
if 'text' in para_value:
val.append(para_value['text'])
elif list_value['id'].startswith("TOKEN"):
val.append(list_value['text'])
else:
pass
print(' '.join(val))
How tables are represented
The structure of a table is represented by three separate objects that are part of the all_structures
tablestable_rowstable_cells
The following JSON output illustrates how the table column title Workflows is represented.

//The all_structures root object contains the table, which has many rows.
"all_structures":{
...
"tables":[{"id":"TABLE_3bfabb","children_ids":[
"ROW_39aa6f",...,"ROW_63472c"]}
//A separate table rows array contains table cells.
"all_structures":{
...
"table_rows":[{"id":"ROW_39aa6f","parent_id":"TABLE_3bfabb","children_ids":[
"CELL_bc1c4b","CELL_3a8cdd","CELL_03b6d3"]}
//One of the table cells is identified as a column header and contains a paragraph.
{"id":"CELL_3a8cdd","parent_id":"ROW_39aa6f","is_row_header":false,
"is_col_header":true,"col_span":1,"row_span":1,"col_start":2,"row_start":1,
"children_ids":["PARA_088d08"]}
//The paragraph has a token.
{"id":"PARA_088d08","parent_id":"CELL_3a8cdd","children_ids":[
"TOKEN_b99851"],"indentation":1}
//The token contains the text *Workflows*.
{"id":"TOKEN_b99851","parent_id":"PARA_088d08","style_id":"IBM_Plex_Sans_SmBld_Black_20_0_bold",
"text":"Workflows","bbox":{"page_number":14,"x":757.0,"y":291.44003,"width":99.15997,"height":13.96}}
The following Python code extracts text from a table and rebuilds the table to illustrate how you can loop through the table rows and cells to extract token text.
# Import required libraries
import json
import numpy as np
import pandas as pd
# Define helper functions
## Function, which finds entry in collection by key-value pair
def find_by_key(key: str, value, collection: list, unique=True):
find = list(filter(lambda x: x[key] == value, collection))
if unique:
if len(find) > 1:
raise ValueError(f"Found non-unique key-value pair.\n{find}")
return find[0]
else:
return find
## Function, which flattens iterable collection of dicts
def flatten_collection(collection):
result = []
for val in collection.values():
result.extend(val)
return result
# Load the file with the extracted text
with open("/Users/janedoe/Downloads/output_retail.json") as f:
raw_output = json.load(f)
# Get all table-related structures
all_tables = raw_output['all_structures']['tables']
all_table_rows = raw_output['all_structures']['table_rows']
all_table_cells = raw_output['all_structures']['table_cells']
# Get all of the cells from the first table
table_1 = all_tables[0]
table_1_cells = []
for row_id in table_1['children_ids']:
row = find_by_key('id', row_id, all_table_rows)
for cell_id in row['children_ids']:
table_1_cells.append(find_by_key('id', cell_id, all_table_cells))
# Reconstruct the first table
last_col = table_1_cells[-1]['col_start']
last_row = table_1_cells[-1]['row_start']
recon_table = np.empty([last_row, last_col], dtype=object)
flat_col = flatten_collection(raw_output['all_structures'])
for cell in all_table_cells:
cell_col, cell_row = cell['col_start'], cell['row_start']
for cell_value in cell['children_ids']:
value = find_by_key('id', cell_value, flat_col)
entries = []
for cell_entry in value['children_ids']:
entry = find_by_key('id', cell_entry, flat_col)
if 'text' in entry:
entries.append(entry['text'])
cell_content = " ".join(entries)
recon_table[cell_row-1][cell_col-1] = str(cell_content)
pd.DataFrame(data=recon_table[1:,:], columns=recon_table[0,:])
Text extraction JSON schema
You can refer to the JSON schema when you write code to extract information from the JSON that is generated for your document.
Any structures with a description that mentions Not required
{ "$defs": {
"AssemblyJsonOutput": {
"type": "object",
"properties": {
"metadata": {
"description": "Metadata about this document.",
"$ref": "#/$defs/Metadata"
},
"styles": {
"description": "Font styles used in this document. Not required.",
"type": "array",
"items": {
"$ref": "#/$defs/Style"
}
},
"top_level_structures": {
"type": "array",
"description": "Array of ids of the top level structures which belong directly under the document",
"items": {
"type": "string"
}
},
"all_structures": {
"type": "object",
"description": "An object containing lists of all structures identified in this document.",
"$ref": "#/$defs/Structures"
}
},
"required": [
"metadata",
"top_level_structures",
"all_structures"
]
},
"Metadata": {
"type": "object",
"additionalProperties": true,
"title": "Metadata",
"properties": {
"num_pages": {
"type": "integer",
"description": "Total number of pages in the document"
},
"title": {
"type": "string",
"description": "Document title as obtained from source document. Not required."
},
"keywords": {
"type": "string",
"description": "Keywords associated with document. Not required."
},
"author": {
"type": "string",
"description": "Author of the document. Not required."
},
"publication_date": {
"type": "string",
"description": "Best effort bases for a publication date (may be the creation date). Not required."
},
"subject": {
"type": "string",
"description": "Subject as obtained from the source document. Not required."
},
"charset": {
"type": "string",
"description": "Character set used for the output"
}
},
"required": []
},
"Style": {
"type": "object",
"title": "Style",
"properties": {
"style_id": {
"type": "string",
"description": "Style Identifier which will be used for reference in other objects"
},
"font_size": {
"type": "string",
"description": "Font size"
},
"font_name": {
"type": "string",
"description": "Font name"
},
"is_bold": {
"type": "string",
"description": "Whether or not the the font is bold"
},
"is_italic": {
"type": "string",
"description": "Whether or not the the font is italic"
}
}
},
"Structures": {
"type": "object",
"description": "An object containing all of the flattened structures identified in the document.
None of the items in this object are required.",
"sections": {
"type": "array",
"items": {
"$ref": "#/$defs/Section"
}
},
"section_titles": {
"type": "array",
"items": {
"$ref": "#/$defs/SectionTitle"
}
},
"lists":{
"type": "array",
"items": {
"$ref": "#/$defs/List"
}
},
"list_items":{
"type": "array",
"items": {
"$ref": "#/$defs/ListItem"
}
},
"list_identifiers":{
"type": "array",
"items": {
"$ref": "#/$defs/ListIdentifier"
}
},
"tables":{
"type": "array",
"items": {
"$ref": "#/$defs/Table"
}
},
"table_rows":{
"type": "array",
"items": {
"$ref": "#/$defs/TableRow"
}
},
"table_cells":{
"type": "array",
"items": {
"$ref": "#/$defs/TableCell"
}
},
"subscripts":{
"type": "array",
"items": {
"$ref": "#/$defs/Subscript"
}
},
"superscripts":{
"type": "array",
"items": {
"$ref": "#/$defs/Superscript"
}
},
"footnotes":{
"type": "array",
"items": {
"$ref": "#/$defs/Footnote"
}
},
"paragraphs":{
"type": "array",
"items": {
"$ref": "#/$defs/Paragraph"
}
},
"tokens":{
"type": "array",
"items": {
"$ref": "#/$defs/Token"
}
}
},
"Section": {
"type": "object",
"title": "Section",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the section"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence"
},
"section_number": {
"type": "string",
"description": "Section identifier identified in the document"
},
"section_level": {
"type": "string",
"description": "Nesting level of section identified in the document"
}
}
},
"SectionTitle": {
"type": "object",
"title": "SectionTitle",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the section"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence. Not required."
},
"text_alignment": {
"type": "string",
"description": "Text alignment of the section title. Not required."
}
}
},
"List": {
"type": "object",
"title": "List",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the list "
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence"
}
}
},
"ListItem": {
"type": "object",
"title": "ListItem",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the list item"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence. Not required."
}
}
},
"ListIdentifier": {
"type": "object",
"title": "ListIdentifier",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the list item"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence"
}
}
},
"Table": {
"type": "object",
"title": "Table",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the table"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence, in this case, table rows"
}
}
},
"TableRow": {
"type": "object",
"title": "TableRow",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the table row"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence, in this case, table cells"
}
}
},
"TableCell": {
"type": "object",
"title": "TableCell",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the table cell"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"is_row_header": {
"type": "boolean",
"description": "Whether the cell is part of row header or not"
},
"is_column_header": {
"type": "boolean",
"description": "Whether the cell is part of column header or not"
},
"col_span": {
"type": "integer",
"description": "column span of the cell"
},
"row_span": {
"type": "integer",
"description": "row span of the cell"
},
"col_start": {
"type": "integer",
"description": "column start of the cell within the table"
},
"row_start": {
"type": "integer",
"description": "row start of the cell within the table"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence, in this case, underlying paragraphs. Not required."
}
}
},
"Subscript": {
"type": "object",
"title": "Subscript",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the subscript"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence. Not required."
},
"token_id_ref": {
"type": "string",
"description": "Id of the token to which the subscript belongs"
}
}
},
"Superscript": {
"type": "object",
"title": "Superscript",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the superscript"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"footnote_ref": {
"type": "string",
"description": "Matching footnote id found on the page"
},
"token_id_ref": {
"type": "string",
"description": "Id of the token to which the superscript belongs"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence. Not required."
}
}
},
"Footnote": {
"type": "object",
"title": "Footnote",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the footnote"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence. Not required."
}
}
},
"Paragraph": {
"type": "object",
"title": "Paragraph",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the paragraph"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"children_ids": {
"type": "array",
"description": "Unique Ids of first level children structures under this structure in correct sequence, in this case, tokens. Not required."
},
"text_alignment": {
"type": "string",
"description": "Text alignment of the paragraph. Not required."
},
"indentation": {
"type": "integer",
"description": "Paragraph indentation. Not required."
}
}
},
"Token": {
"type": "object",
"title": "Token",
"properties": {
"id": {
"type": "string",
"description": "Unique identifier for the list identifier"
},
"parent_id": {
"type": "string",
"description": "Unique identifier which denotes parent of this structure"
},
"style_id": {
"type": "string",
"description": "Identifier of the style object associated with this token. Not required."
},
"text": {
"type": "string",
"description": "Actual text of the token"
},
"bbox": {
"type":"object",
"description": "Not required.",
"$ref": "#/$defs/BoundingBox"
}
}
},
"BoundingBox": {
"type": "object",
"title": "BoundingBox",
"properties": {
"page_number": {
"description": "which page this represents",
"type": "integer"
},
"x": {
"description": "X coordinate of the bounding box",
"type": "float"
},
"y": {
"description": "X coordinate of the bounding box",
"type": "float"
},
"width": {
"description": "width of the bounding box",
"type": "float"
},
"height": {
"description": "height of the bounding box",
"type": "float"
}
}
}
},
"$ref": "#/$defs/AssemblyJsonOutput"
}
Learn more
Parent topic: Extracting text from documents