Translation not up to date
Ten kurs demonstruje wykorzystanie programu Federated Learning w celu szkolenia modelu uczenia maszynowego z danymi pochodząckami od różnych użytkowników bez konieczności udostępniania danych przez użytkowników. Kroki są wykonywane w środowisku o niskim kodzie w interfejsie użytkownika i w środowisku XGBoost.
W tym kursie nauczysz się:
- Krok 1: Uruchamianie programu Federated Learning jako administrator
- Krok 2: Model pociągu jako strona
Uwagi:
- Jest to kurs krok po kroku dotyczący uruchamiania eksperymentu stowarzyszonego w zakresie uczenia się przez interfejs użytkownika. Aby zapoznać się z przykładową przykładową kodem interfejsu API, należy przejść do strony Federated Learning XGBoost samples(Stowarzyszone przykłady XGBoost).
- W tym kursie admin odnosi się do użytkownika, który uruchamia eksperyment edukacyjny stowarzyszony, a podmiot odnosi się do jednego lub kilku użytkowników, którzy wysyłają swoje wyniki modelu po rozpoczęciu eksperymentu przez administratora. Chociaż kurs może być wykonany przez administratora i wiele podmiotów, pojedynczy użytkownik może również wykonać pełne uruchomienie, zarówno przez administratora, jak i stronę. W przypadku prostszego celu demonstracyjnego, w następującym kursie tylko jeden zestaw danych jest wprowadzany przez jedną ze stron. Więcej informacji na temat administratora i podmiotu zawiera sekcja Terminologia.
Krok 1: Uruchomienie stowarzyszonej nauki
W tej sekcji użytkownik nauczy się rozpocząć eksperyment w zakresie uczenia się federacyjnego.
Zanim rozpoczniesz
Zaloguj się do programu IBM Cloud. Jeśli nie masz konta, utwórz go za pomocą dowolnego adresu e-mail.
Utwórz instancję usługi Watson Machine Learning , jeśli nie została ona utworzona w środowisku użytkownika.
Zaloguj się do katalogu watsonx.
Użyj istniejącego projektu lub utwórz nowy. Użytkownik musi mieć co najmniej uprawnienie administratora.
Powiązanie usługi Watson Machine Learning z projektem użytkownika.
- W projekcie kliknij opcję Manage > Service & integrations(Zarządzaj > usługami i integracjami).
- Kliknij opcję Powiąż usługę.
- Wybierz z listy instancję Watson Machine Learning , a następnie kliknij opcję Powiążlub opcję Nowa usługa , jeśli nie ma potrzeby konfigurowania instancji.

Uruchom agregator
Utwórz zasób aplikacyjny eksperymentu uczenia stowarzyszonego:
Kliknij kartę Zasoby w projekcie.
Kliknij opcję Nowe zadanie > Modele pociągu w danych rozproszonych.
Wpisz wartość w polu Nazwa dla eksperymentu i opcjonalnie opis.
Sprawdź powiązaną instancję Watson Machine Learning w sekcji Select a machine learning instance(Wybierz instancję uczenia maszynowego). Jeśli nie jest widoczna powiązana instancja Watson Machine Learning , wykonaj następujące kroki:
Kliknij opcję Powiąż instancję usługi Machine Learning.
Wybierz istniejącą instancję i kliknij opcję Powiążlub utwórz nową usługę.
Kliknij przycisk Przeładuj , aby wyświetlić powiązaną usługę.
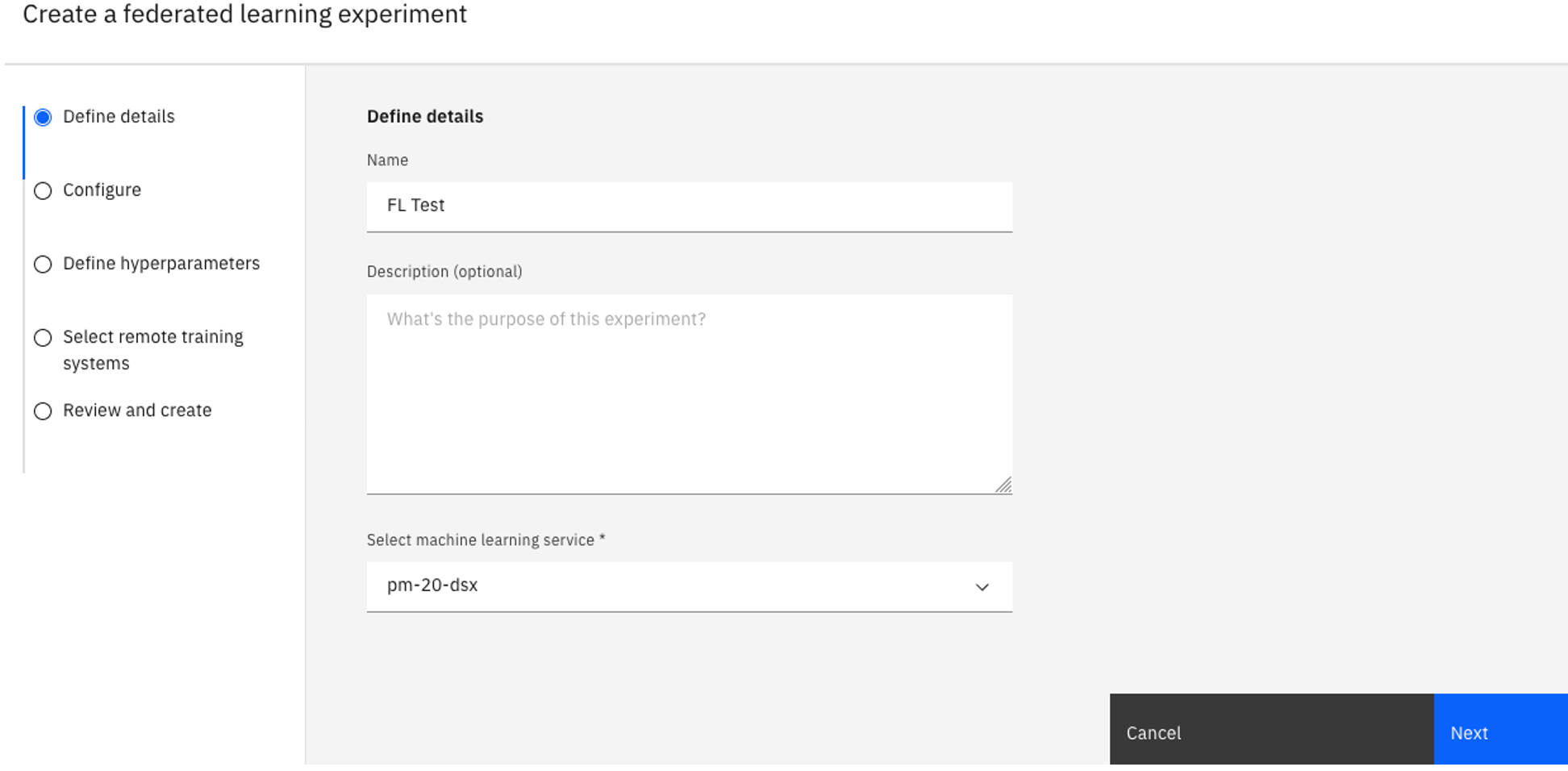
Kliknij przycisk Dalej.
Skonfiguruj eksperyment.
Na stronie Konfiguracja wybierz opcję Specyfikacja sprzętu.
W menu rozwijanym Środowisko uczenia maszynowego wybierz opcję scikit-learn.
W polu Typ modeluwybierz opcję XGBoost.
Dla opcji Metoda Fusionwybierz opcję Fusion klasyfikacji XGBoost .

Zdefiniuj parametry hiperparametrów.
Ustaw wartość w polu Obchody na
5.Zaakceptuj wartości domyślne dla pozostałych pól.
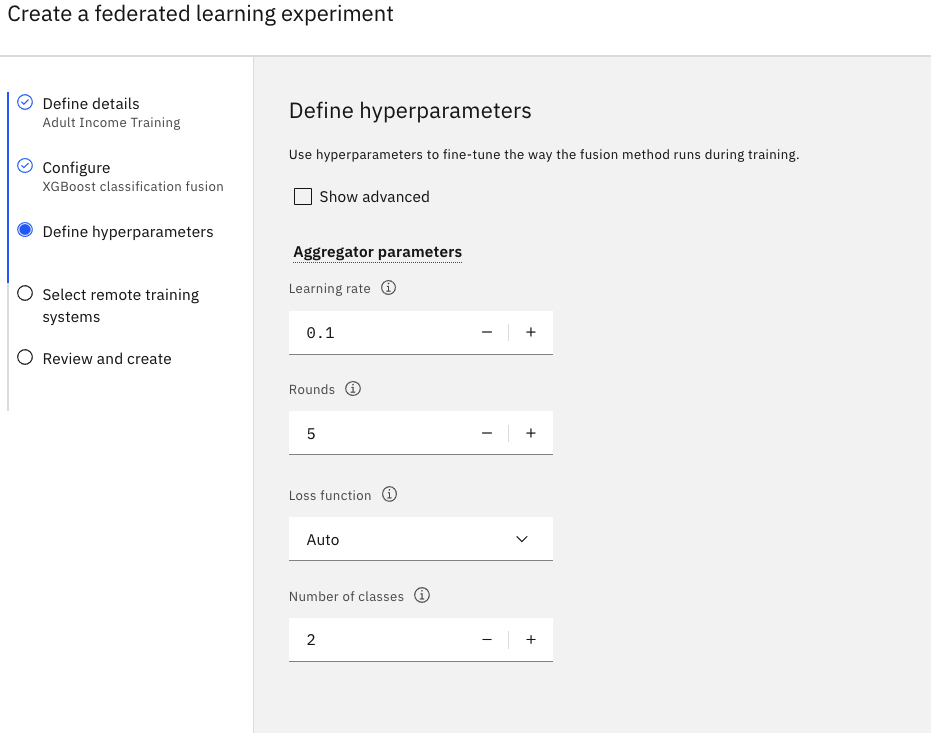
Kliknij przycisk Dalej.
Wybierz zdalne systemy treningowe.
- Kliknij opcję Dodaj nowe systemy.
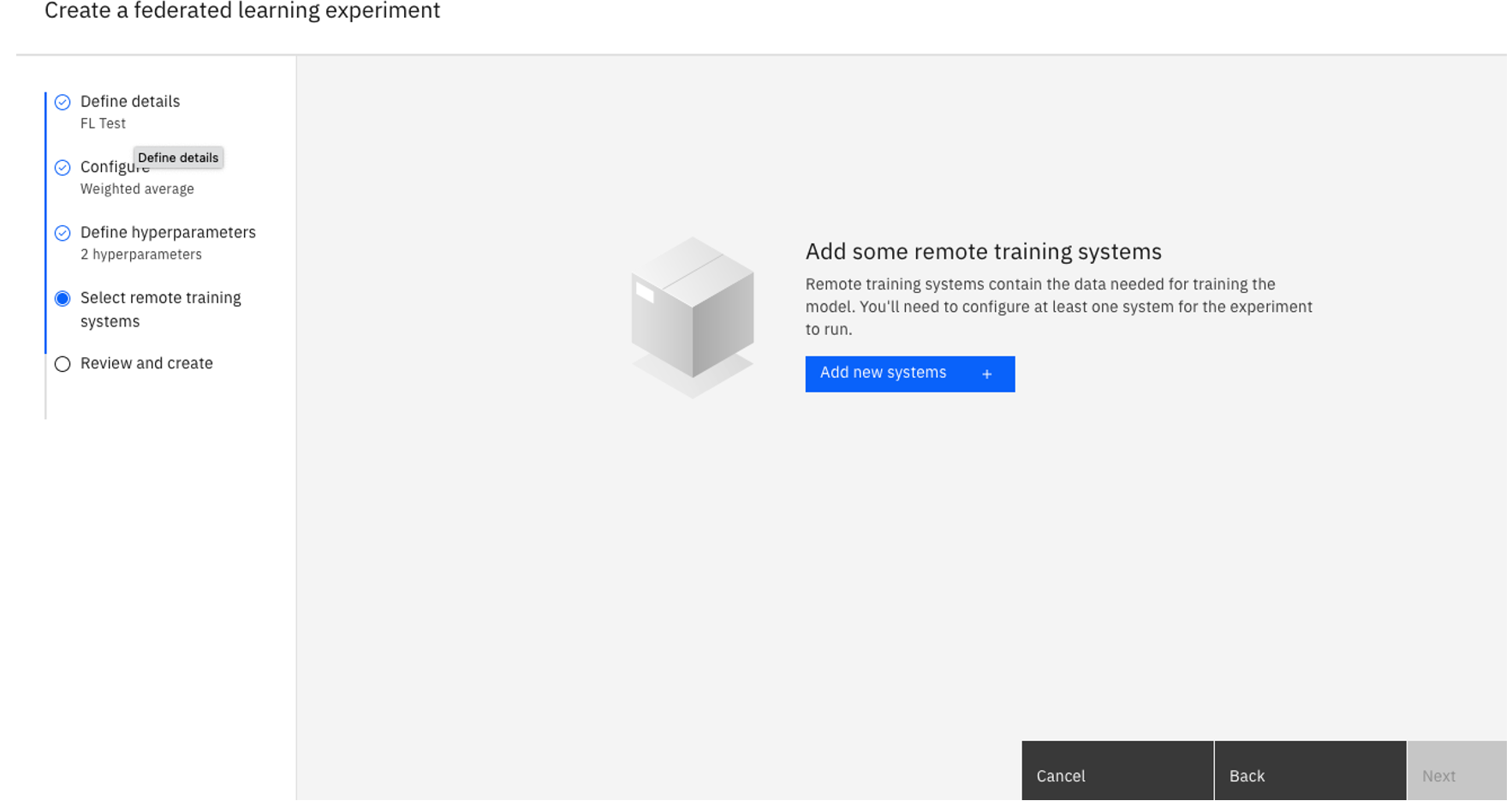
Podaj nazwę systemu zdalnego szkolenia.
W obszarze Dozwolone tożsamościwybierz użytkownika, który będzie uczestniczyli w eksperymencie, a następnie kliknij przycisk Dodaj. Istnieje możliwość dodania tylu dozwolonych tożsamości jako uczestników tej instancji szkoleniowej stowarzyszonej eksperymentów. W tym kursie wybierz tylko siebie.
Wszelkie dozwolone tożsamości muszą być częścią projektu i mieć co najmniej uprawnienieAdministrator .Po zakończeniu kliknij opcję Add systems(Dodaj systemy).

Wróć do strony Select remote training systems (Wybierz zdalne systemy szkoleniowe), sprawdź, czy wybrany system jest wybrany, a następnie kliknij przycisk Next(Dalej).

Przejrzyj ustawienia, a następnie kliknij przycisk Utwórz.
Obserwuj status. Status eksperymentu stowarzyszonego uczenia się to Oczekujące podczas uruchamiania. Gdy eksperyment jest gotowy do połączenia podmiotów, status zostanie zmieniony na Konfiguracja-Oczekiwanie na systemy zdalne. Może to zająć kilka minut.
Krok 2: Model pociągu jako impreza
Upewnij się, że używana jest ta sama wersja Python , co administrator. Użycie innej wersji Python może spowodować problemy z kompatybilnością. Aby zapoznać się z wersjami Python kompatybilnymi z różnymi środowiskami, należy zapoznać się z Frameworkami i kompatybilnością wersji Python.
Utwórz nowy katalog lokalny.
Pobierz zestaw danych Adult do katalogu, w którym znajduje się ta komenda:
wget https://api.dataplatform.cloud.ibm.com/v2/gallery-assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data -O adult.csv.Pobierz procedurę obsługi danych, uruchamiając program
wget https://raw.githubusercontent.com/IBMDataScience/sample-notebooks/master/Files/adult_sklearn_data_handler.py -O adult_sklearn_data_handler.py.Zainstaluj produkt Watson Machine Learning.
- Jeśli używany jest system Linux, uruchom komendę
pip install 'ibm-watson-machine-learning[fl-rt22.2-py3.10]'. - Jeśli używasz systemu Mac OS z procesorem M-series CPU i Conda, pobierz skrypt instalacyjny , a następnie uruchom program
./install_fl_rt22.2_macos.sh <name for new conda environment>.
Teraz masz skrypt konektora partyjnego,mnist_keras_data_handler.py,mnist-keras-test.pklimnist-keras-train.pkl, procedurę obsługi danych w tym samym katalogu.
- Jeśli używany jest system Linux, uruchom komendę
Wróć do strony eksperymentu programu Federated Learning, na której uruchomiony jest agregator. Kliknij opcję Wyświetl informacje o konfiguracji.
Kliknij ikonę pobierania znajdującą się obok zdalnego systemu szkolenia, a następnie wybierz opcję Skrypt konektora podmiotu.
Upewnij się, że masz skrypt konektora podmiotu, zestaw danych Dorosły i procedurę obsługi danych w tym samym katalogu. Jeśli zostanie uruchomiony produkt
ls -l, należy zapoznać się z następującymi podami:adult.csv adult_sklearn_data_handler.py rts_<RTS Name>_<RTS ID>.pyW skrypcie konektora podmiotu:
Uwierzytelniaj przy użyciu dowolnej metody.
Umieść je w następujących parametrach sekcji
"data":"data": { "name": "AdultSklearnDataHandler", "path": "./adult_sklearn_data_handler.py", "info": { "txt_file": "./adult.csv" }, },gdzie:
name: nazwa klasy zdefiniowana dla procedury obsługi danych.path: ścieżka miejsca, w którym znajduje się procedura obsługi danych.info: Utwórz parę wartości klucza dla typu pliku lokalnego zestawu danych lub ścieżkę do zestawu danych.
Uruchom skrypt konektora podmiotu:
python3 rts_<RTS Name>_<RTS ID>.py.Gdy wszystkie uczestniczące strony łączą się z agregatorem, agregator ułatwia szkolenie modelu lokalnego oraz aktualizację modelu globalnego. Jego status to Training(Szkolenia). Istnieje możliwość monitorowania statusu eksperymentu stowarzyszonego uczenia się z poziomu interfejsu użytkownika.
Gdy szkolenie jest zakończone, strona otrzymuje
Received STOP messagena stronie.Teraz można zapisać wyszkolony model i wdrożyć go w obszarze.
Krok 3: Zapisz i wdróż model w trybie z połączeniem
W tej sekcji dowiesz się, jak zapisać i wdrożyć model, który został przeszkolony.
Zapisz model.
- W ramach zakończonego eksperymentu programu Federated Learning kliknij opcję Zapisz model w projekcie.
- Nadaj modelowi nazwę i kliknij przycisk Zapisz.
- Przejdź do domu projektu.
Utwórz obszar wdrażania, jeśli nie ma go.
W menu nawigacyjnym
 kliknij opcję Deployments(Wdrożenia).
kliknij opcję Deployments(Wdrożenia).Kliknij opcję Nowa przestrzeń wdrażania.
Wypełnij pola, a następnie kliknij przycisk Utwórz.

Awanuj model do obszaru.
- Wróć do projektu i kliknij kartę Zasoby .
- W sekcji Modele kliknij model, aby wyświetlić jego stronę szczegółów.
- Kliknij opcję Awansuj na spację.
- Wybierz miejsce wdrożenia dla wyszkolonego modelu.
- Wybierz opcję Idź do modelu w obszarze po jego awansowaniu .
- Kliknij opcję Awansuj.
Po wyświetleniu modelu w obszarze wdrażania kliknij opcję Nowe wdrożenie.
- Wybierz opcję Tryb z połączeniem jako Typ wdrożenia.
- Podaj nazwę wdrożenia.
- Kliknij makro Create.
Krok 4: Ocena modelu
W tej sekcji opisano tworzenie funkcji Python w celu przetwarzania danych oceniania w celu upewnia się, że jest on w tym samym formacie, który był używany podczas szkolenia. Dla porównania można również zaliczyć zestaw danych surowych, wywołując funkcję Python , którą utworzyliśmy.
Zdefiniuj funkcję Python w następujący sposób. Funkcja ładuje dane punktacji w swoim formacie surowym i przetwarza dane dokładnie tak, jak było to zrobione podczas treningu. Następnie należy zaliczyć przetworzone dane.
def adult_scoring_function(): import pandas as pd from ibm_watson_machine_learning import APIClient wml_credentials = { "url": "https://us-south.ml.cloud.ibm.com", "apikey": "<API KEY>" } client = APIClient(wml_credentials) client.set.default_space('<SPACE ID>') # converts scoring input data format to pandas dataframe def create_dataframe(raw_dataset): fields = raw_dataset.get("input_data")[0].get("fields") values = raw_dataset.get("input_data")[0].get("values") raw_dataframe = pd.DataFrame( columns = fields, data = values ) return raw_dataframe # reuse preprocess definition from training data handler def preprocess(training_data): """ Performs the following preprocessing on adult training and testing data: * Drop following features: 'workclass', 'fnlwgt', 'education', 'marital-status', 'occupation', 'relationship', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country' * Map 'race', 'sex' and 'class' values to 0/1 * ' White': 1, ' Amer-Indian-Eskimo': 0, ' Asian-Pac-Islander': 0, ' Black': 0, ' Other': 0 * ' Male': 1, ' Female': 0 * Further details in Kamiran, F. and Calders, T. Data preprocessing techniques for classification without discrimination * Split 'age' and 'education' columns into multiple columns based on value :param training_data: Raw training data :type training_data: `pandas.core.frame.DataFrame :return: Preprocessed training data :rtype: `pandas.core.frame.DataFrame` """ if len(training_data.columns)==15: # drop 'fnlwgt' column training_data = training_data.drop(training_data.columns[2], axis='columns') training_data.columns = ['age', 'workclass', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'class'] # filter out columns unused in training, and reorder columns training_dataset = training_data[['race', 'sex', 'age', 'education-num', 'class']] # map 'sex' and 'race' feature values based on sensitive attribute privileged/unpriveleged groups training_dataset['sex'] = training_dataset['sex'].map({' Female': 0, ' Male': 1}) training_dataset['race'] = training_dataset['race'].map({' Asian-Pac-Islander': 0, ' Amer-Indian-Eskimo': 0, ' Other': 0, ' Black': 0, ' White': 1}) # map 'class' values to 0/1 based on positive and negative classification training_dataset['class'] = training_dataset['class'].map({' <=50K': 0, ' >50K': 1}) training_dataset['age'] = training_dataset['age'].astype(int) training_dataset['education-num'] = training_dataset['education-num'].astype(int) # split age column into category columns for i in range(8): if i != 0: training_dataset['age' + str(i)] = 0 for index, row in training_dataset.iterrows(): if row['age'] < 20: training_dataset.loc[index, 'age1'] = 1 elif ((row['age'] < 30) & (row['age'] >= 20)): training_dataset.loc[index, 'age2'] = 1 elif ((row['age'] < 40) & (row['age'] >= 30)): training_dataset.loc[index, 'age3'] = 1 elif ((row['age'] < 50) & (row['age'] >= 40)): training_dataset.loc[index, 'age4'] = 1 elif ((row['age'] < 60) & (row['age'] >= 50)): training_dataset.loc[index, 'age5'] = 1 elif ((row['age'] < 70) & (row['age'] >= 60)): training_dataset.loc[index, 'age6'] = 1 elif row['age'] >= 70: training_dataset.loc[index, 'age7'] = 1 # split age column into multiple columns training_dataset['ed6less'] = 0 for i in range(13): if i >= 6: training_dataset['ed' + str(i)] = 0 training_dataset['ed12more'] = 0 for index, row in training_dataset.iterrows(): if row['education-num'] < 6: training_dataset.loc[index, 'ed6less'] = 1 elif row['education-num'] == 6: training_dataset.loc[index, 'ed6'] = 1 elif row['education-num'] == 7: training_dataset.loc[index, 'ed7'] = 1 elif row['education-num'] == 8: training_dataset.loc[index, 'ed8'] = 1 elif row['education-num'] == 9: training_dataset.loc[index, 'ed9'] = 1 elif row['education-num'] == 10: training_dataset.loc[index, 'ed10'] = 1 elif row['education-num'] == 11: training_dataset.loc[index, 'ed11'] = 1 elif row['education-num'] == 12: training_dataset.loc[index, 'ed12'] = 1 elif row['education-num'] > 12: training_dataset.loc[index, 'ed12more'] = 1 training_dataset.drop(['age', 'education-num'], axis=1, inplace=True) # move class column to be last column label = training_dataset['class'] training_dataset.drop('class', axis=1, inplace=True) training_dataset['class'] = label return training_dataset def score(raw_dataset): try: # create pandas dataframe from input raw_dataframe = create_dataframe(raw_dataset) # reuse preprocess from training data handler processed_dataset = preprocess(raw_dataframe) # drop class column processed_dataset.drop('class', inplace=True, axis='columns') # create data payload for scoring fields = processed_dataset.columns.values.tolist() values = processed_dataset.values.tolist() scoring_dataset = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} print(scoring_dataset) # score data prediction = client.deployments.score('<MODEL DEPLOYMENT ID>', scoring_dataset) return prediction except Exception as e: return {'error': repr(e)} return scoreZastąp zmienne w poprzedniej funkcji Python :
API KEY: klucz API IAM. Aby utworzyć nowy klucz interfejsu API, należy przejść do Serwis WWW IBM Cloudi kliknąć Tworzenie klucza interfejsu API produktu IBM Cloud w sekcji Zarządzanie > Klucze interfejsu API > Access (IAM) >.SPACE ID: ID miejsca wdrożenia, w którym działa wdrożenie dochodu dla osoby dorosłej. Aby wyświetlić identyfikator obszaru, należy przejść do sekcji Obszary wdrażania >YOUR SPACE NAME> Zarządzaj. Skopiuj GUID miejsca.MODEL DEPLOYMENT ID: identyfikator wdrożenia w trybie z połączeniem dla modelu dochodu dla dorosłych. Aby wyświetlić identyfikator modelu, można go wyświetlić, klikając model w projekcie. Znajduje się on zarówno na pasku adresu, jak i na panelu informacyjnym.
Pobierz identyfikator specyfikacji oprogramowania dla języka Python 3.9. Aby wyświetlić listę innych środowisk, należy uruchomić komendę client.software_specifications.list().
software_spec_id = client.software_specifications.get_id_by_name('default_py3.9')Funkcja Python służy do przechowywania danych w obszarze Watson Studio .
# stores python function in space meta_props = { client.repository.FunctionMetaNames.NAME: 'Adult Income Scoring Function', client.repository.FunctionMetaNames.SOFTWARE_SPEC_ID: software_spec_id } stored_function = client.repository.store_function(meta_props=meta_props, function=adult_scoring_function) function_id = stored_function['metadata']['id']Utwórz wdrożenie w trybie z połączeniem za pomocą funkcji Python .
# create online deployment for fucntion meta_props = { client.deployments.ConfigurationMetaNames.NAME: "Adult Income Online Scoring Function", client.deployments.ConfigurationMetaNames.ONLINE: {} } online_deployment = client.deployments.create(function_id, meta_props=meta_props) function_deployment_id = online_deployment['metadata']['id']Pobierz zestaw danych Dochód dla dorosłych. Ta opcja jest ponownie wykorzystywana jako dane punktowe.
import pandas as pd # read adult csv dataset adult_csv = pd.read_csv('./adult.csv', dtype='category') # use 10 random rows for scoring sample_dataset = adult_csv.sample(n=10) fields = sample_dataset.columns.values.tolist() values = sample_dataset.values.tolist()Oceń dane o dochodach dla osób dorosłych za pomocą utworzonej funkcji Python .
raw_dataset = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} prediction = client.deployments.score(function_deployment_id, raw_dataset) print(prediction)
Następne kroki
Tworzenie eksperymentu edukacyjnego stowarzyszonego.
Temat nadrzędny: Kurs nauki stowarzyszonej i przykłady